混合信息雙數(shù)組的未登錄詞動(dòng)態(tài)識(shí)別模型
2021-10-18 00:59:22陳皓宇洪嘉偉陳致然
電腦知識(shí)與技術(shù) 2021年26期
陳皓宇 洪嘉偉 陳致然

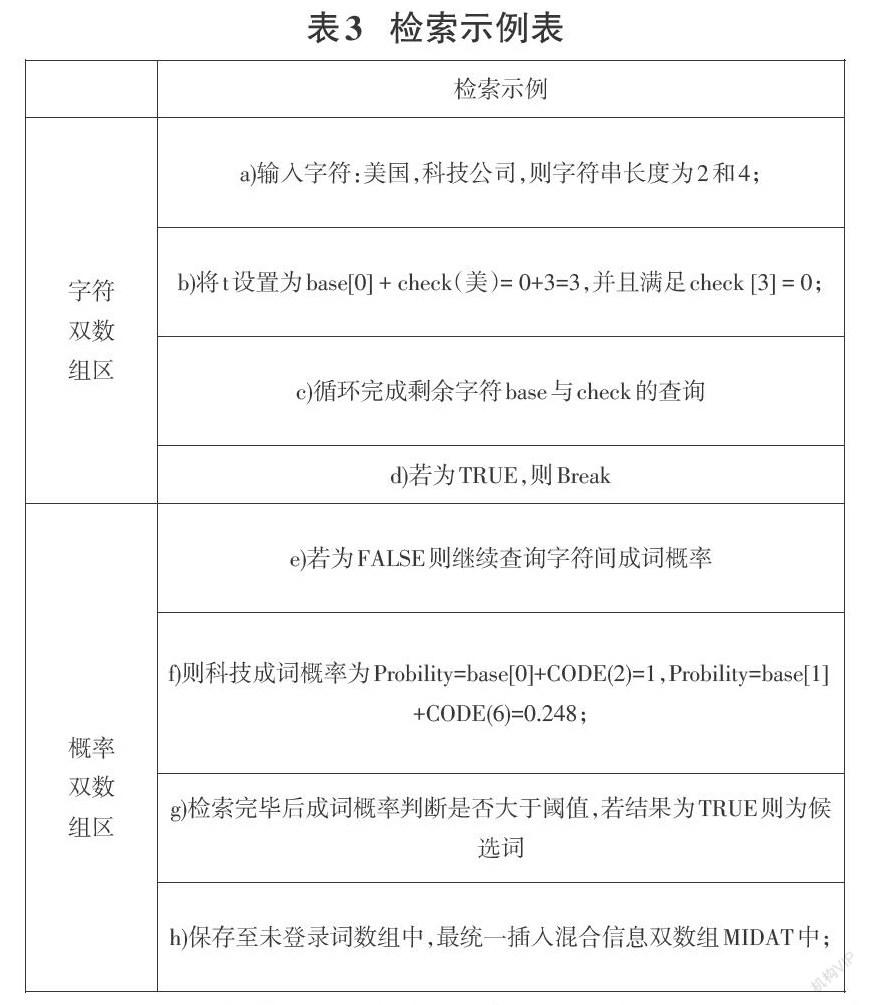

摘要:未登錄詞是影響命名實(shí)體識(shí)別效果的重要因素,現(xiàn)有分詞工具在處理未登錄詞時(shí)不僅識(shí)別效果欠佳,且存在識(shí)別時(shí)間較長等問題。為提高分詞效果,在現(xiàn)有分詞器基礎(chǔ)上結(jié)合未登錄詞識(shí)別模型,提出了一種基于改進(jìn)雙數(shù)組Trie的混合信息未登錄詞動(dòng)態(tài)識(shí)別模型MIDAT,將雙數(shù)組Trie擴(kuò)展為字符雙數(shù)組與概率雙數(shù)組,利用字符雙數(shù)組存儲(chǔ)字符串詞段信息,概率雙數(shù)組存儲(chǔ)字符串節(jié)點(diǎn)間的成詞概率信息,通過不斷識(shí)別未登錄詞,動(dòng)態(tài)更新兩個(gè)雙數(shù)組Trie。實(shí)驗(yàn)結(jié)果表明,在相同的數(shù)據(jù)集下,結(jié)合MIDAT的分詞器后對(duì)于未登錄詞的分詞效果要優(yōu)于結(jié)巴等常用分詞器,同時(shí)在時(shí)間效率上相比傳統(tǒng)的未登錄詞識(shí)別模型提升約8倍。
關(guān)鍵詞: 未登錄詞; 雙數(shù)組Trie; 互信息; 信息熵 ; N-gram
中圖分類號(hào):TP18? ? ? 文獻(xiàn)標(biāo)識(shí)碼:A
文章編號(hào):1009-3044(2021)26-0001-05
開放科學(xué)(資源服務(wù))標(biāo)識(shí)碼(OSID):
Dynamic Recognition Model of Unknown Words Based on Mixed Information Double Array Trie
CHEN Hao-yu,HONG Jia-wei,CHEN Zhi-ran
(Faculty of Computer, Guangdong University of Technology, Guangzhou 510006, China)
Abstract:Unknown words are an important factor affecting the recognition effect of named entities. When existing word segmentation tools deal with unknown words which not only have poor recognition results, but also have problems such as longer recognition time. In order to improve the effect of word segmentation,combined the unregistered word recognition model on the basis of the existing word segmenter, and proposes a dynamic unregistered word recognition model MIDAT based on the improved double array trie. On the basis of expanding the double array trie into a character double array and a probability double array, the character double array is used to store the word segment information of the string, and the probability double array is used to store the word formation probability information between the string nodes. Through continuous identification of unknown words , dynamically update the two double array trie. The experimental results show that under the same data set, the word segmentation effect of the word segmenter combined with MIDAT is better than that of common word segmenters such as stuttering. At the same time, the time efficiency is improved by about 8 times compared with the traditional unknown word recognition model.
Key words:unknown words ;double array trie ;mutual information ; nformation entropy ; N-gram
隨著互聯(lián)網(wǎng)的快速發(fā)展,網(wǎng)絡(luò)新聞媒體中的熱點(diǎn)話題與重大新聞層出不窮,其中蘊(yùn)含著豐富的未登錄詞[1],然而現(xiàn)有的分詞器并不能有效地識(shí)別出這些詞,分詞后容易產(chǎn)生字符串碎片,而大量的未登錄詞和字符串碎片會(huì)導(dǎo)致命名實(shí)體識(shí)別[2]的準(zhǔn)確率降低,因此在自然語言處理任務(wù)中,如何有效識(shí)別出未登錄詞便成為一個(gè)熱點(diǎn)和難點(diǎn)問題。
其根本體現(xiàn)在下述兩個(gè)方面,一方面現(xiàn)有的未登錄詞發(fā)現(xiàn)算法效果不太理想,算法在實(shí)體識(shí)別過程中存在一定的偏差。另一方面,由于文本數(shù)據(jù)中存在大量的重復(fù)前綴,使得原有識(shí)別算法的時(shí)間復(fù)雜度非常高,進(jìn)行識(shí)別需要花費(fèi)大量時(shí)間。故本文在改進(jìn)雙數(shù)組Trie的基礎(chǔ)上提出了一種基于改進(jìn)混合雙數(shù)組、互信息和信息熵的混合信息雙數(shù)組未登錄詞識(shí)別模型MIDAT。
1 相關(guān)工作
目前未登錄詞識(shí)別[3]的研究方法大致有兩類:基于規(guī)則的方法和基于統(tǒng)計(jì)學(xué)的方法。基于規(guī)則的方法是通過字符串詞段間的結(jié)構(gòu)與構(gòu)詞原理,結(jié)合詞性與語義信息[4]來進(jìn)行匹配,對(duì)文本語料中的未登錄詞進(jìn)行識(shí)別[5]。這種方法精確率較高,但是針對(duì)性較強(qiáng),適用的領(lǐng)域較為單一,適用度受限,并且維護(hù)十分困難。而基于統(tǒng)計(jì)的方法,通過使用統(tǒng)計(jì)模型對(duì)語料中的各種信息[6]進(jìn)行未登錄詞識(shí)別,這種方法靈活性較高,具有較好的普適性,但需提前對(duì)統(tǒng)計(jì)模型進(jìn)行大量的訓(xùn)練,準(zhǔn)確率也有待提高。

- 電腦知識(shí)與技術(shù)的其它文章
- 基于C語言下培養(yǎng)高校學(xué)生計(jì)算思維的研究
- “互聯(lián)網(wǎng)+”背景下計(jì)算機(jī)專業(yè)的“訂單式”人才培養(yǎng)策略初探
- 現(xiàn)代信息教育技術(shù)下混合式教學(xué)的課程改革探索——以“電力系統(tǒng)分析”為例
- 高職院校計(jì)算機(jī)課程案例教學(xué)法應(yīng)用研究——以A校Python課程案例教學(xué)為例
- 基于MOOC的混合式教學(xué)模式研究——以《大學(xué)計(jì)算機(jī)基礎(chǔ)》為例
- 比較法在信號(hào)與系統(tǒng)課程教學(xué)中的應(yīng)用