基于RFE+CatBoost模型的異常用電檢測方法研究
2021-10-21 08:18:48李英娜劉愛蓮
電視技術(shù) 2021年8期
冉 哲,李英娜*,劉愛蓮
(1.昆明理工大學(xué) 信息工程與自動化學(xué)院,云南 昆明 650500;2.云南省計(jì)算機(jī)技術(shù)應(yīng)用重點(diǎn)實(shí)驗(yàn)室,云南 昆明 650500)
0 引 言
隨著社會經(jīng)濟(jì)的快速發(fā)展,近年來,供電企業(yè)數(shù)據(jù)平臺不斷發(fā)展,用電信息采集系統(tǒng)不斷完善,不斷累積大量的可供分析的信息。用電信息不僅是企業(yè)向用戶收取電費(fèi)的主要依據(jù),而且能提供大量有價(jià)值的信息,以供分析人員從中獲取信息進(jìn)行分析,從而對電力系統(tǒng)以及用電企業(yè)進(jìn)行更好的改良和指導(dǎo)。
對于供電企業(yè)的用電監(jiān)察工作來說,利用數(shù)據(jù)挖掘技術(shù)對用電采集信息進(jìn)行分析,從數(shù)據(jù)中挖掘用戶用電規(guī)律,結(jié)合機(jī)器學(xué)習(xí)[1]和深度學(xué)習(xí)等技術(shù),構(gòu)造異常用電行為識別模型,識別異常用電行為,以便稽查人員及時(shí)發(fā)現(xiàn)異常用電行為[2],更快地采取應(yīng)對行動,對于企業(yè)降低管理運(yùn)營成本、提升經(jīng)濟(jì)效益、更好地指導(dǎo)電力消費(fèi)行為以及優(yōu)化電網(wǎng)的運(yùn)行具有非常重大的意義。
目前在異常用電行為檢測與識別領(lǐng)域,針對電力數(shù)據(jù)的特性,對于沒有明確指明是否存在異常用電的數(shù)據(jù),采用無監(jiān)督學(xué)習(xí)的方法[3],莊池杰等人在缺乏異常用電數(shù)據(jù)樣本的情況下,分析樣本與總體之間的關(guān)系,找出離群對象,采用特征提取方法、主成分分析(PCA)、網(wǎng)格處理技術(shù)以及計(jì)算局部離群因子等模塊,只需檢測異常度排序靠前的少數(shù)用戶即可查出大部分異常用戶[4]。龔剛軍等人針對用電行為最佳聚類數(shù)目選擇問題,在特征優(yōu)選策略基礎(chǔ)上提出了基于準(zhǔn)確度和有效度的聚類優(yōu)選策略,通過綜合考慮準(zhǔn)確度評價(jià)指標(biāo)和有效度評價(jià)指標(biāo)確定最佳聚類數(shù)目[5],以達(dá)到更好的聚類效果[6]。對于明確標(biāo)明異常用電[7]的數(shù)據(jù),采用有監(jiān)督學(xué)習(xí)或者半監(jiān)督學(xué)習(xí)的方法,程超鵬等人提取用戶用電特征后,采用四種相異模型構(gòu)建Stacking集成模型,提升用電異常識別的準(zhǔn)確性,針對單一模型識別率不高的問題做出了改進(jìn)和提升[8]。趙文清等人利用深度學(xué)習(xí)框架,基于長短期記憶特征提取網(wǎng)絡(luò),構(gòu)建異常用電識別模型[9]。徐瑤等人提出一種GNN-GSSVM的用戶異常用電識別模型,采用卷積神經(jīng)網(wǎng)絡(luò)提取用戶特征,然后通過SVM檢測異常用電行為[10]。上述方法多沒有考慮到異常用電樣本中特征選取對模型識別準(zhǔn)確度影響的問題,樣本差異對于最后構(gòu)建的模型的識別效果有著很大的影響,大部分模型構(gòu)建趨于復(fù)雜化,所提取的特征與實(shí)際用戶用電行為習(xí)慣不一定具有相關(guān)性。最后雖能達(dá)到較好的識別準(zhǔn)確率,但在識別時(shí)間和識別難度上較為復(fù)雜。
鑒于此,本文提出一種基于遞歸特征消除(Recursive Feature Elimination,RFE)和CatBoost相結(jié)合的異常識別模型。首先根據(jù)用電采集系統(tǒng)采集的數(shù)據(jù),從中提取電能特征,其次構(gòu)建特征矩陣,采用遞歸特征消除方法選取有利于模型的最佳特征,利用CatBoost模型進(jìn)行異常用電的識別[11],最后利用所得模型對云南某地真實(shí)用電數(shù)據(jù)集進(jìn)行驗(yàn)證,證明所提模型的有效性。
1 算法理論介紹
1.1 Boosting算法
Boosting算法是集成算法的代表,它通過將一些基分類器組合起來得到分類性能較強(qiáng)、針對特定問題能夠有很好解決效果的模型。首先用初始權(quán)重訓(xùn)練出一個(gè)基分類器,以基分類器的學(xué)習(xí)誤差率作為更新訓(xùn)練樣本的權(quán)重的依據(jù),調(diào)高學(xué)習(xí)誤差表現(xiàn)率高的訓(xùn)練樣本點(diǎn)的權(quán)重,使這些誤差表現(xiàn)率高的點(diǎn)在之后的基分類器的學(xué)習(xí)中得到更多的重視。其次,基于調(diào)整權(quán)重后的訓(xùn)練集來訓(xùn)練下一個(gè)基分類器。重復(fù)進(jìn)行上述步驟,直到基分類器數(shù)目達(dá)到指定的數(shù)目。最后將這些基分類器通過集合策略進(jìn)行整合,得到最終的強(qiáng)分類器。Boosting算法的原理如圖1所示。
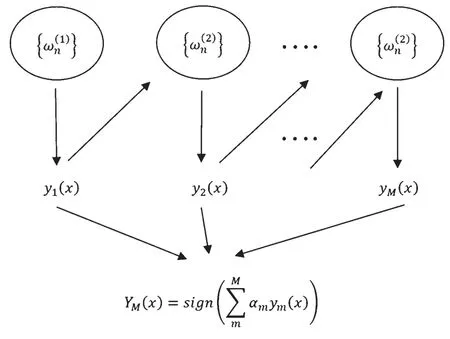
圖1 Boosting原理圖
在圖1中,n個(gè)訓(xùn)練樣本在初始狀態(tài)下為每一個(gè)訓(xùn)練樣本賦上權(quán)重ωn(i)(1≤i≤n),在訓(xùn)練迭代的過程中,每次訓(xùn)練得到的結(jié)果會根據(jù)上一次基學(xué)習(xí)器ym(1≤m≤M)的情況進(jìn)行調(diào)整,重復(fù)訓(xùn)練之后直到基學(xué)習(xí)器的數(shù)量達(dá)到M,最后每個(gè)基學(xué)習(xí)器結(jié)合之后得到Boosting的數(shù)學(xué)模型:
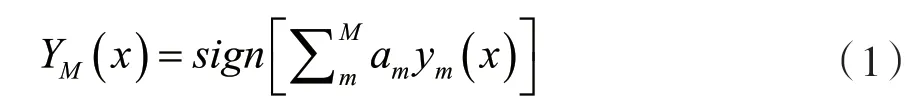
1.2 梯度提升算法
梯度提升算法(Gradient descend boosting)是一種基于Boosting算法的代表性算法之一,它通過對弱預(yù)測模型的集成產(chǎn)生預(yù)測模型,組合為一個(gè)強(qiáng)學(xué)習(xí)器。在梯度提升的每個(gè)階段m,(1≤m≤M),假設(shè)已經(jīng)有一個(gè)不太完美的模型Fm,通過在模型Fm上增加一個(gè)新的估計(jì)量h得到一個(gè)更好的模型:
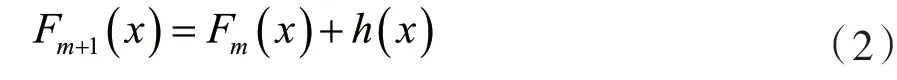
為了求得h的值,梯度提升算法基于以下作為觀察:一個(gè)完美的h可以預(yù)測當(dāng)前此模型的殘差,滿足:
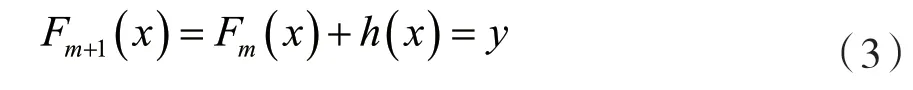
等效的式子有:

梯度提升通過擬合殘差y-Fm(x)得到h。與其他提升方法的改進(jìn)方法一樣,F(xiàn)m+1通過糾正Fm的誤差逐漸達(dá)到想要的效果。模型的殘差y-Fm(x)就是損失函數(shù)關(guān)于F(x)的負(fù)梯度。所以梯度提升思想在算法上的表現(xiàn)可以代入除了均方損失之外的不同的損失函數(shù),以得到不同的梯度。在有監(jiān)督學(xué)習(xí)問題中,一個(gè)輸出變量y和一個(gè)輸入變量x通過聯(lián)合概率分布P(x, y)描述。給定訓(xùn)練集{(x1, y1),(x2, y2),…,(xn, yn)},旨在在所有具有給定形式的函數(shù)F(x)中找到一個(gè)F^(x)使得損失函數(shù)L[y,F(x)]的期望值最小:
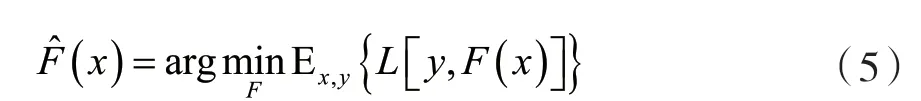
梯度提升方法通過某一類H中基學(xué)習(xí)器hi(x)帶權(quán)重和的形式來表示對實(shí)值變量y做出估計(jì)的F^(x):
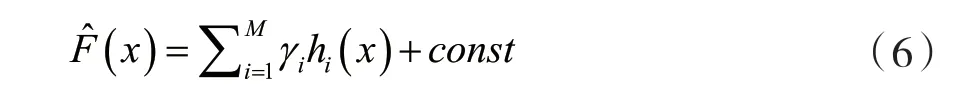
根據(jù)經(jīng)驗(yàn)風(fēng)險(xiǎn)最小化原理,此方法的目的是找到一個(gè)近似F^(x)可以最大程度減少訓(xùn)練集上損失函數(shù)的平均值,從一個(gè)由常數(shù)函數(shù)組成的模型F0(x)開始,以貪心的方式逐步擴(kuò)展:
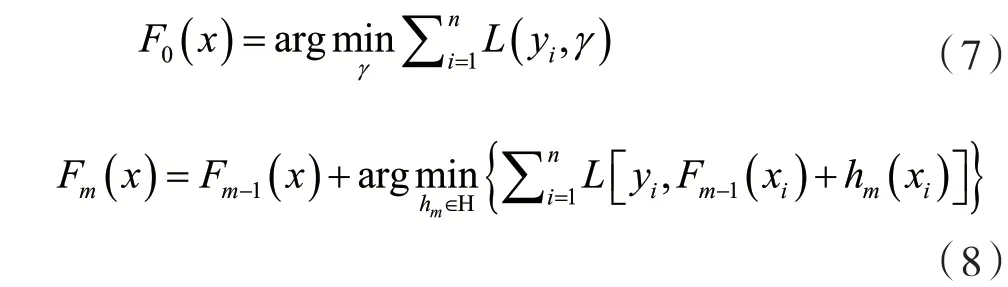
式中:hm∈H是基學(xué)習(xí)器。
通常,在每個(gè)步驟中為任意的損失函數(shù)L選擇最佳函數(shù)h在計(jì)算上不可行,有以下優(yōu)化方法。
對這個(gè)最小化問題,應(yīng)用梯度下降步驟,如果考慮連續(xù)情況,即H是任意微分函數(shù)的集合',根據(jù)以下方程更新模型:
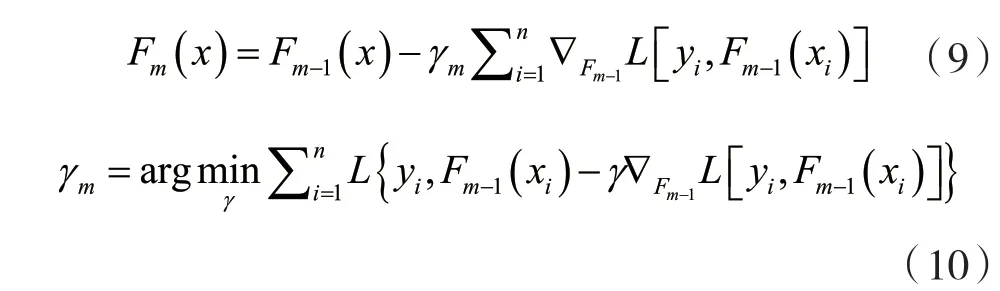
式中,對于i∈(1,…,m)是關(guān)于函數(shù)Fi求導(dǎo),γm是步長。但是在離散情況下,即如果H是有限的,就選擇最接近L梯度的候選函數(shù)h,然后根據(jù)上述等式通過線搜索來計(jì)算系數(shù)γ。
1.3 梯度增強(qiáng)樹算法
梯度增強(qiáng)通常與固定大小的決策樹(一般是CART樹)一起作用于基學(xué)習(xí)器。對于這種特殊情況,F(xiàn)riedman提出了對梯度增強(qiáng)方法的改進(jìn),以提高每個(gè)基礎(chǔ)學(xué)習(xí)者的適應(yīng)質(zhì)量。
第m步的通用梯度提升將適合決策樹hm(x)擬合近似殘差,Jm是葉子節(jié)點(diǎn)數(shù)。則模型樹將空間分為Jm個(gè)不相交的區(qū)域R1m,…,Rjmm并預(yù)測每個(gè)區(qū)域的恒定值。利用指標(biāo)函數(shù)I,對于輸入x,輸出hm(x)可以有以下和的形式:
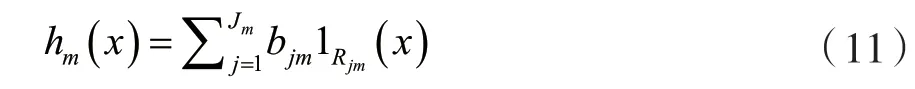
式中:bjm是區(qū)域Rjm的預(yù)測值。
系數(shù)bjm乘上某一值γm,通過線性搜索最小化損失函數(shù)得到該值,模型更新為:
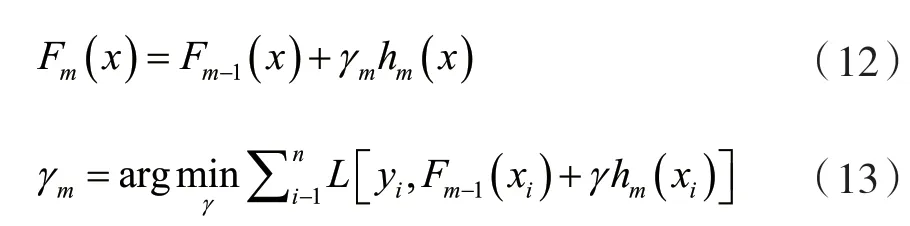
Friedman建議修改此算法,以便為每棵樹的區(qū)域選擇單獨(dú)的最優(yōu)值γmj,而不是單個(gè)γm。他稱修改后的算法為“TreeBoost”。修改后,可以簡單地舍棄來自樹擬合過程的系數(shù)bjm,模型更新規(guī)則變?yōu)椋?/p>
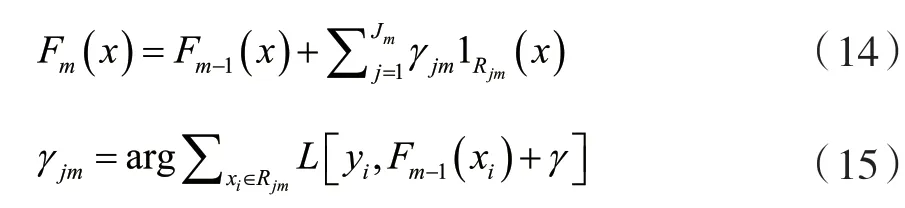
1.4 CatBoost算法
CatBoost由Categorical和Boosting組成,針對分類問題主要解決的重點(diǎn)是高效合理地處理類別型特征。此外,CatBoost著重解決預(yù)測偏差以及梯度偏差的問題,對減少過擬合的發(fā)生有很好的效果,準(zhǔn)確性和泛化能力能得到較大提升[12]。傳統(tǒng)Boosting算法計(jì)算的是平均數(shù),而CatBoost在這方面采用其他算法做了改進(jìn)優(yōu)化,這些改進(jìn)能更好地防止模型過擬合。CatBoost算法的目標(biāo)是在處理GBDT特征中的Categorical features[13]時(shí)能達(dá)到更好的效果。在決策樹算法中,標(biāo)簽的平均值作為節(jié)點(diǎn)分裂的標(biāo)準(zhǔn),此方法被稱為Greedy Target-based Statistics,用公式表達(dá)為:
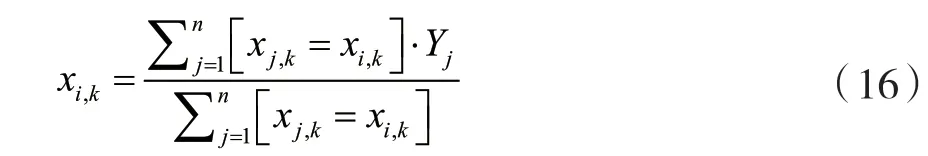
在式(16)的基礎(chǔ)上添加先驗(yàn)分布項(xiàng)進(jìn)行改進(jìn),可以減少低頻數(shù)據(jù)以及噪聲在數(shù)據(jù)分布上面的 影響:
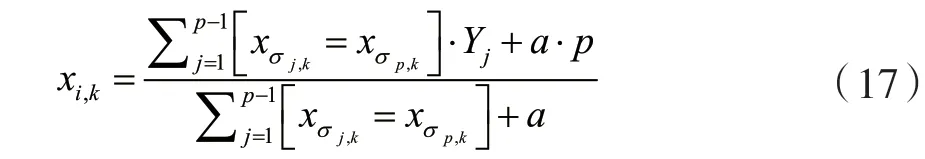
式中:p是添加的先驗(yàn)項(xiàng),a通常是大于0的權(quán)重系數(shù)。
2 算例分析
2.1 數(shù)據(jù)來源
本文數(shù)據(jù)是采集自云南某地用戶5個(gè)月用電在線監(jiān)測數(shù)據(jù)集,在線監(jiān)測數(shù)據(jù)每60 min采集一次,采集信息主要包括正向有功總電能、無功總電能,反向有功總電能、無功總電能,三相電壓,三相電流(電表、表前、一次),三相有功功率,三相功率因數(shù)以及總功率因數(shù)等電參量。
2.2 數(shù)據(jù)處理與特征提取
在實(shí)際用電和采集用電信息的過程中,由于計(jì)量系統(tǒng)故障、人為干擾等因素,導(dǎo)致采集到的數(shù)據(jù)有很多缺失值、異常值。需要對這些數(shù)據(jù)進(jìn)行剔除和篩選。對于缺失值達(dá)到30%的用戶進(jìn)行標(biāo)記,經(jīng)過篩查如果數(shù)據(jù)缺失值達(dá)到50%以上、沒有特別進(jìn)行標(biāo)明的數(shù)據(jù),按照計(jì)量系統(tǒng)異常處理進(jìn)行剔除。數(shù)據(jù)經(jīng)過篩選剔除處理后,最終剩余正常數(shù)據(jù)2 593條,異常數(shù)據(jù)537條。
針對數(shù)據(jù)中所提取的特征做相關(guān)性分析,得到的矩陣如圖2所示。
由圖2可以直觀地看出所提各項(xiàng)特征之間存在的線性相關(guān)關(guān)系,可以得知部分特征的相關(guān)程度較高,表明這些特征包含了較多的重疊信息。通過遞歸特征消除可以進(jìn)行特征篩選,消除原始變量之間的信息重疊。
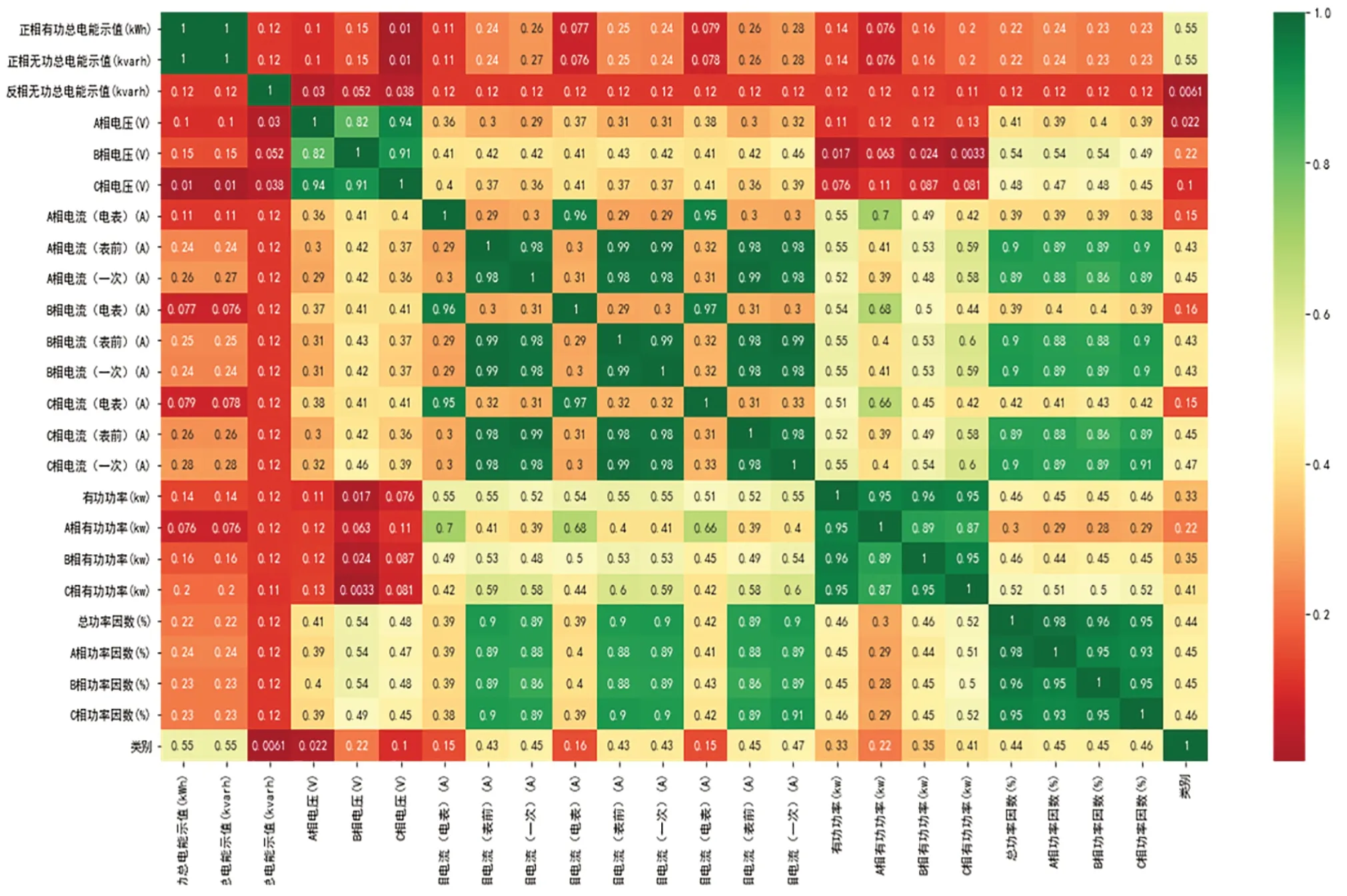
圖2 特征集的相關(guān)矩陣
2.3 特征遞歸消除
特征遞歸消除[14]是一種基于wrapper包裹的型模式下的后向搜索算法,常用在特征選擇[15]上面。特征遞歸消除方法使用一個(gè)機(jī)器學(xué)習(xí)模型來進(jìn)行多輪訓(xùn)練,每一次訓(xùn)練結(jié)束后,就會消除若干權(quán)值系數(shù)所對應(yīng)的特征,之后在新的特征集上面進(jìn)行下一輪訓(xùn)練。重復(fù)該過程直至產(chǎn)生最優(yōu)的特征子集。基本步驟如下:
(1)使用所有特征變量訓(xùn)練模型;
(2)計(jì)算每個(gè)特征變量的重要性并進(jìn)行排序;
(3)對每一個(gè)變量子集s_{i},i=1,…,s,提取前 s_{i}個(gè)最重要的特征變量,基于新數(shù)據(jù)集訓(xùn)練模型,重新計(jì)算每個(gè)特征變量的重要性并進(jìn)行排序;
(4)計(jì)算比較每個(gè)子集獲得的模型的效果;(5)決定最優(yōu)的特征變量子集;(6)選擇最優(yōu)變量集合集合的模型為最終模型。經(jīng)特征遞歸消除后篩選出來的特征為正向有功總電能、三相電流(電表)、三相電壓、有功功率以及總功率因數(shù)。特征指標(biāo)如表1所示。這些特征從用電角度考慮也能全面反映用戶用電情況,將上述特征數(shù)據(jù)作為模型的輸入。
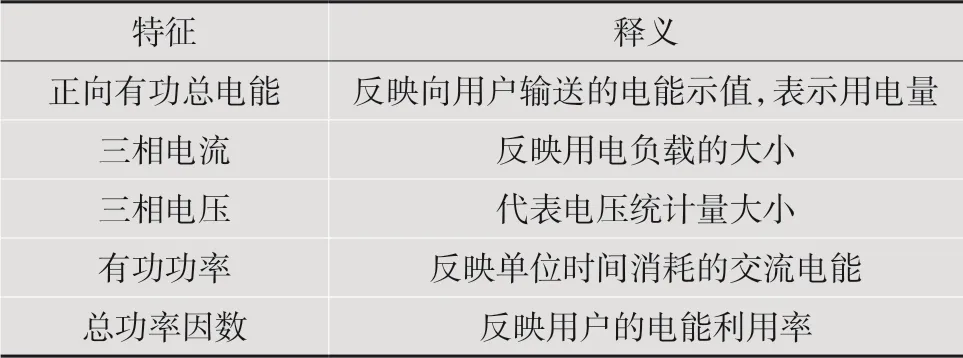
表1 用戶用電特征指標(biāo)
2.4 實(shí)驗(yàn)結(jié)果分析
將數(shù)據(jù)以7∶3的比例劃分訓(xùn)練集和測試集。在本實(shí)驗(yàn)中,采用CatBoost算法的優(yōu)勢降低了對于超參數(shù)的依賴,無需進(jìn)行過多的參數(shù)設(shè)置。為了驗(yàn)證本文提出的RFE+CatBoost模型的分類性能,將模型識別結(jié)果與隨機(jī)森林(Random Forest)模型、邏輯回歸(Logistic Regression)模型、XGBoost模型、LightGBM模型、SVM模型進(jìn)行對比,針對用電特征屬性,5種模型的調(diào)參結(jié)果如下:隨機(jī)森林模型設(shè)置max_depth為15,max_leaf_nodes設(shè)置為2;LightGBM模型reg_lamba設(shè)置為0.9,max_depth設(shè)置為3,max_bin設(shè)置為3;XGBoost模型設(shè)置max_depth為3,reg_lamba設(shè)置為0.9;邏輯回歸(Logic Regression)模型超參數(shù)設(shè)置max_iter為3;SVM模型則采用默認(rèn)的超參數(shù)設(shè)置。
將所提取的用戶特征集作為模型的輸入,通過混淆矩陣(confusion matrix)、準(zhǔn)確率(Accuracy)[16]、AUC(Area Under Curve)指數(shù)3個(gè)指標(biāo)來評判不同檢測模型的好壞,ROC曲線下的面積占比就是AUC值。AUC值越大,說明模型檢測效果越好。AUC對比結(jié)果如圖3~圖8所示。
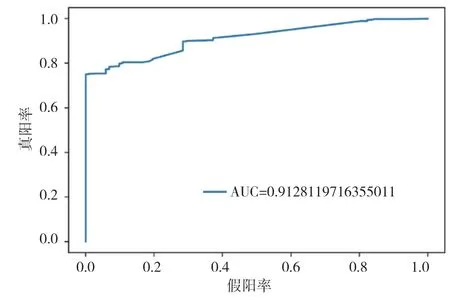
圖3 Random Forest模型ROC曲線圖
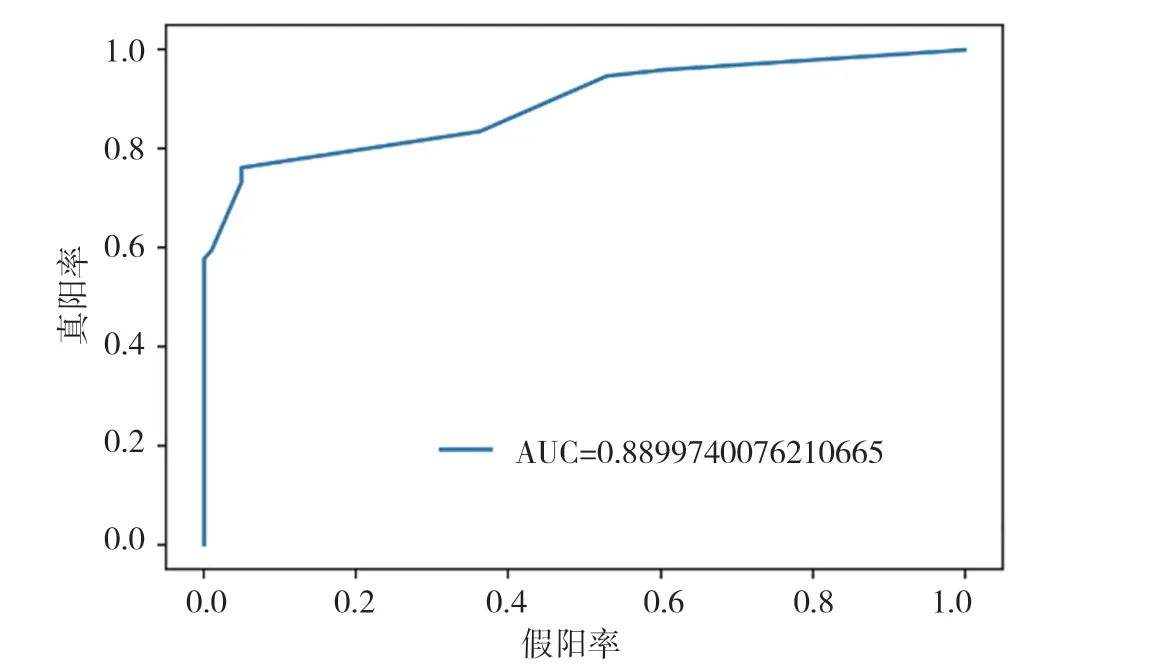
圖4 LightGBM模型ROC曲線圖
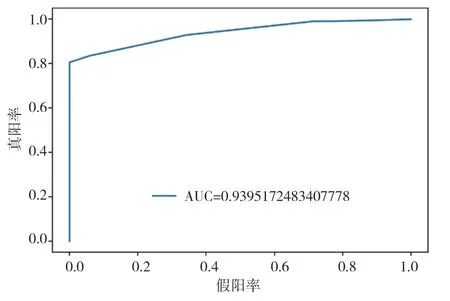
圖5 XGBoost模型ROC曲線圖
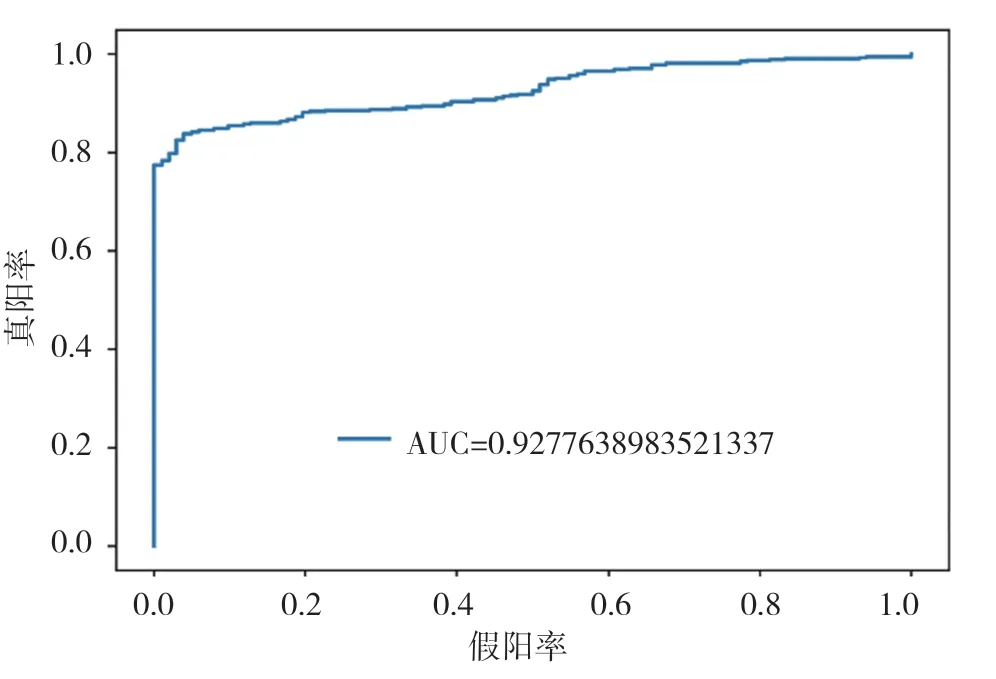
圖6 SVM模型ROC曲線圖
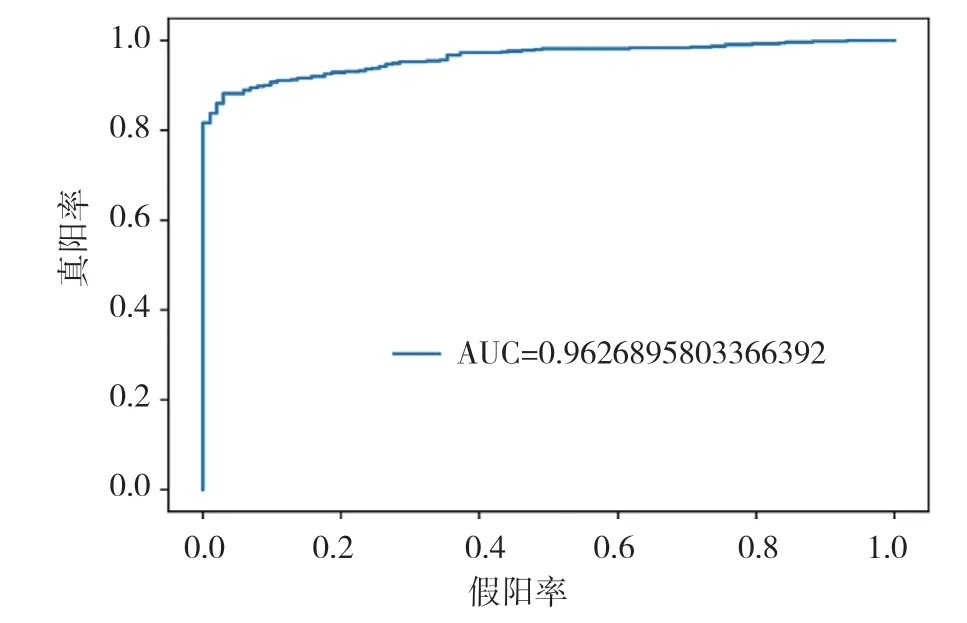
圖8 CatBoost模型ROC曲線圖
通過以上模型對比AUC值可知,識別效果最好的是CatBoost模型,AUC的值為96.3%,SVM算法、XGBoost算法、隨機(jī)森林(Random Forest)算法也有較好的識別效果,AUC的值分別為92.8%,94.0%,91.3%。各個(gè)模型對比可知,CatBoost模型的AUC值要高于其他模型。
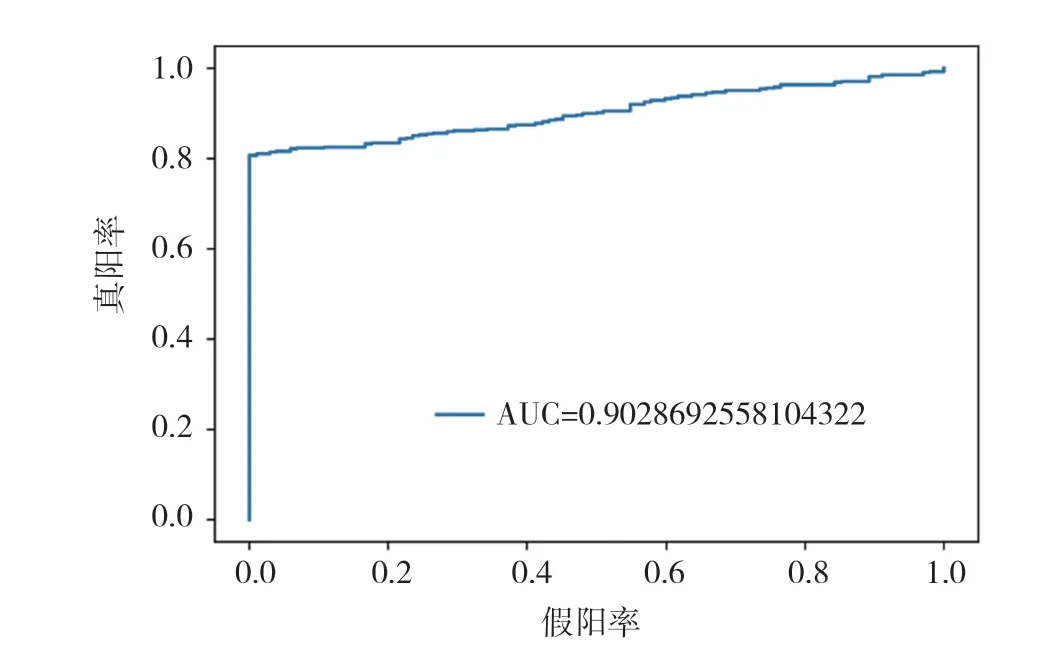
圖7 Logistic Regression模型ROC曲線圖
6種模型在用電特征集上的實(shí)驗(yàn)結(jié)果如表2 所示。
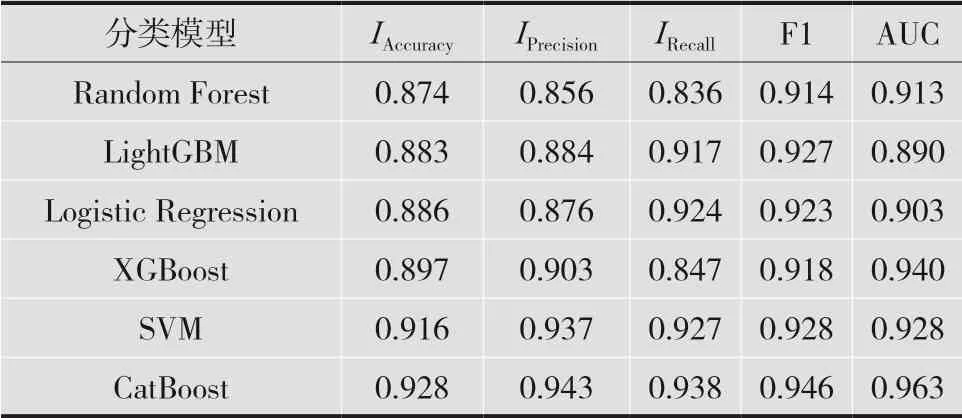
表2 各分類模型結(jié)果對比
由表2可知,相比于其他檢測模型,特征優(yōu)選后的CatBoost模型對于異常用電行為的識別率高達(dá)93%,在準(zhǔn)確率、召回率、F1值上面的效果都要優(yōu)于其他模型。LightGBM在F1值上面則要比邏輯回歸模型和XGBoost模型要好。3種模型的召回率中,XGBoost最低,所以綜合F1值來看,這3種模型中XGBoost的識別效果要更好,在分類方面有較強(qiáng)的數(shù)據(jù)挖掘能力。SVM模型的識別效果僅次于本文所提模型,與XGBoost模型相比也能有很好的識別效果。在準(zhǔn)確率上SVM模型效果更好。XGBoost模型在AUC值上要好于SVM模型,也有很好的識別效果。總體來說,從各項(xiàng)評價(jià)指標(biāo)來看,RFE+CatBoost模型對于異常用電具有很好的識別效果。
3 結(jié) 語
針對包含復(fù)雜統(tǒng)計(jì)量的用戶側(cè)歷史用電數(shù)據(jù),本文提出了一種經(jīng)RFE特征優(yōu)化后的CatBoost模型的異常用電識別,選取用戶5個(gè)月的用電監(jiān)測數(shù)據(jù)用于異常用電行為的識別,將預(yù)測結(jié)果與其他傳統(tǒng)分類模型進(jìn)行對比,通過實(shí)驗(yàn)驗(yàn)證所提方法的有效性,可得出如下結(jié)論。
將CatBoost算法應(yīng)用于電力數(shù)據(jù)針對用戶側(cè)的異常檢測領(lǐng)域,能夠減少模型對于超參數(shù)的依賴,有效降低模型過擬合的幾率,增強(qiáng)了算法的魯棒性,針對于異常檢測進(jìn)行合理的特征篩選再經(jīng)模型識別能夠得到很好的準(zhǔn)確率。
采用的樣本數(shù)據(jù)為異常用電的小樣本數(shù)據(jù),所提模型能夠勝任小樣本異常用電數(shù)據(jù),在樣本數(shù)據(jù)不夠多的情況下也能夠有很好的識別效果。所提方法適用于復(fù)雜統(tǒng)計(jì)量的用電數(shù)據(jù),有助于對各種類型異常用電數(shù)據(jù)進(jìn)行很好的識別,以供電力企業(yè)稽查人員或分析人員識別檢測異常用電。
在下一階段的工作中,將針對異常用電行為的檢測進(jìn)行進(jìn)一步的細(xì)分,通過劃定閾值或者箱型圖判定等方法,結(jié)合數(shù)據(jù)類型進(jìn)一步精確識別異常用電,進(jìn)而為電網(wǎng)電力監(jiān)察工作提供更加可 靠的支持。
猜你喜歡
中老年保健(2021年12期)2021-11-30 02:58:01
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中華詩詞(2018年11期)2018-03-26 06:41:34
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
Coco薇(2016年8期)2016-10-09 02:11:50
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
