基于注意力機制的雙向生成對抗壓縮網絡
2021-10-21 08:19:00陳旭彪
電視技術 2021年8期
陳旭彪
(福建捷聯電子有限公司,福建 福州 350300)
0 引 言
近幾年,基于深度學習的圖像超分辨率重建算法為了追逐重建圖像客觀質量評價指標,研究者們設計出大量精妙的網絡結構[1-5],但這些網絡結構大體上都是增加卷積神經網絡的深度或寬度,從最初網絡深度僅有3層的SRCNN,發展到首次引入殘差網絡達到20層深度的VDSR,再到80層的超深記憶性網MemNet[6]。盡管這些算法在一定程度上提升了圖像的重建質量,卻大幅度增加了網絡模型消耗的內存容量及網絡前向推理的計算量。另外一個問題是,如VDSR、SRResNet等算法,其網絡結構采用了直接級聯的拓撲結構,網絡中每層輸出的特征圖會被不加區分地輸入到下一層,無法判斷圖像特征的重要程度。
針對以上兩個問題,本文在雙向生成對抗壓縮網絡的基礎上,提出了一種輕量高效的基于注意力機制的雙向生成對抗壓縮網絡(ADSRGAN)。本文所提出的算法引入了深度可分離卷積層及混合注意力機制,在保證圖像超分辨率重建質量的同時加快了網絡模型重建速度。
1 雙向生成對抗網絡弱監督算法
本文的雙向生成對抗網絡旨在解決現實生活中模糊圖像超分辨率重建問題。該算法框架如圖1所示,包括兩個生成對抗網絡,分別為重建網絡(Low-to-High)和下采樣網絡(High-to-Low)。
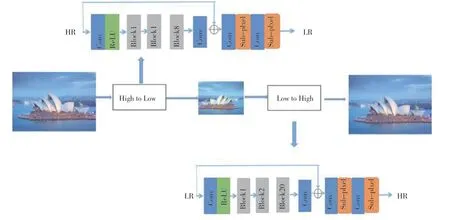
圖1 雙向對抗生成網絡
1.1 下采樣網絡
圖像超分辨率重建面臨的最大問題是缺乏真實的數據集,即低分辨率的噪聲圖像和相應的高分辨率圖像。生成用于訓練的圖像對的困難主要來自兩方面,一方面是對低分辨率(LR)圖像進行建模和仿真,另一方面是生成像素相對應的低分辨圖像。為了解決這兩個問題,本文提出了下采樣網絡(H2L),低分辨率圖片產生的方式為:

式中:LR表示生成的低分辨率圖片,HR表示清晰的高分辨率圖片,θ1表示網絡要學習的參數。
下采樣網絡的網絡架構如圖2所示。高分辨率圖片首先經過一個卷積層和ReLU激活函數層提取圖像低層特征,然后將提取的低層特征輸入到后面8個殘差塊中。每個殘差塊包含兩層卷積層和一層激活函數層,相比于SRGAN的殘差塊,本文設計的殘差塊遵循EDSR[7]去除了歸一化層以減少網絡參數量并加快網絡訓練速度。每兩個殘差塊間的設計運用ResNet中的跳躍連接(Short-Cut)方式,同時將低層特征與殘差塊輸出的高層特征進行融合操作,促使網絡模擬生成更逼真的、帶噪聲的低分辨率圖片。最后,融合的特征圖經過卷積層和亞像素卷積層生成低分辨率圖片。
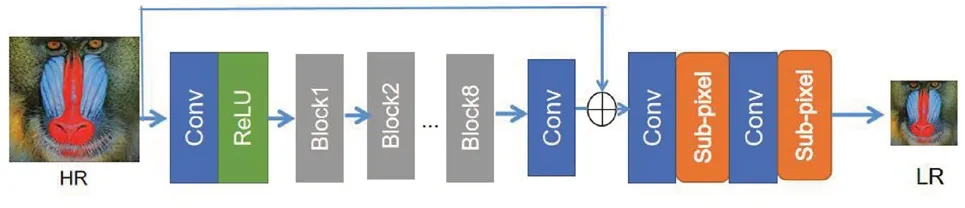
圖2 下采樣網絡
下采樣網絡的損失函數由兩部分組成,分別為生成對抗網絡的對抗損失及結構感知損失。下采樣網絡的生成器生成的低分辨率圖片需要騙過判別器,因此產生了對抗損失函數。為了保證雙向生成對抗網絡訓練的穩定性,本文引入了WGAN的對抗損失函數,其定義為:
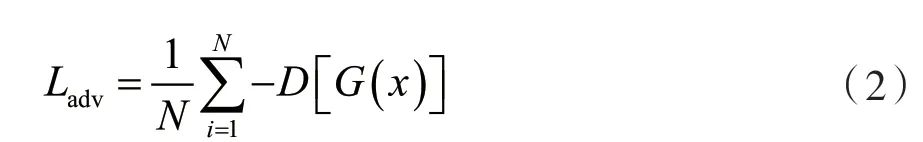
式中:D表示下采樣網絡的判別器,G代表下采樣網絡的生成器,N代表了圖像的數量。
為了保護生成的圖像與原圖像之間的空間結構信息不發生改變,本文引入了用于風格遷移工作的結構感知損失函數,其定義為:
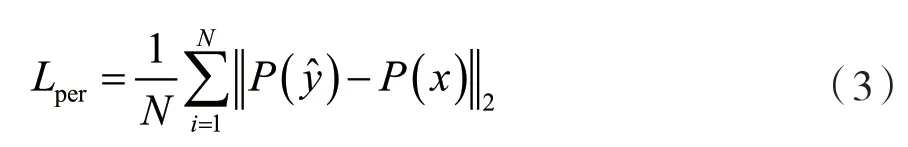
式中:N代表了圖像塊的數量,P表示VGG網絡的卷積層的特征圖,y是生成的低分辨率圖片,x是輸入的高分辨率圖片。在計算損失的時候,圖片會被裁剪到同一尺寸。
1.2 重建網絡
本文提出的重建網絡(L2H)實現了低分辨率圖像超分辨率,可以描述為:

式中:HR表示重建的超分辨率圖片,LR表示輸入的低分辨率圖片,θ2表示重建網絡要學習的參數。
重建網絡的網絡架構如圖3所示,和下采樣網絡架構類似。低分辨率圖片首先經過一個卷積層和ReLU激活函數層以提取圖像的低層特征。低層特征經過20層殘差塊學習高分辨率圖片的高頻細節部分,最后將融合了低層和高層的特征圖輸入到亞像素卷積層進行圖像超分辨重建。反卷積層利用亞像素卷積層替代經典的轉置卷積,以避免重建圖像出現棋盤效應和邊緣模糊。
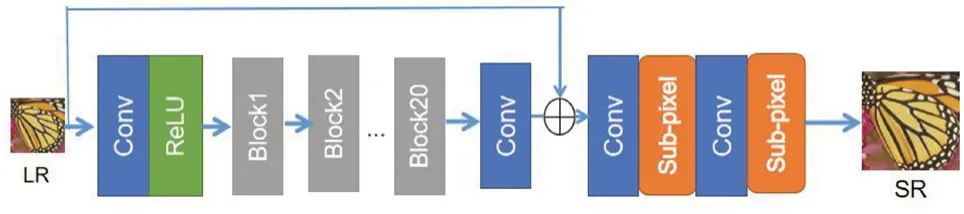
圖3 重建網絡
重建網絡的損失函數由3部分組成,分別為生成網絡的對抗損失、結構感知損失和L1像素損失組成。其中,對抗損失及結構感知損失與下采樣一致。L1像素損失的定義為:
式中:N表示圖像塊數量,y表示重建的超分辨率圖像,x表示真實的標簽高分辨率圖片。

2 深度可分離卷積和自注意力機制
2.1 深度可分離卷積
隨著人工智能產品落地需求的產生,訓練輕量高效的卷積神經網絡逐漸成為研究者關注的焦點。輕量級神經網絡模型的設計一般通過減少網絡中參數數量、減少網絡模型前向推理計算量等方法實現。2017年,針對減少網絡模型計算量這一問題,Google公司的Sifre等人提出了輕量級小型化網絡MobileNetV1[8],其最重要的創新就是提出了使用深度可分離卷積代替標準卷積操作,該算法在保證圖像分類精度的同時大大減少了網絡的計算量,并實現了將基于MobileNet網絡的圖像分類應用部署在移動平臺端。
深度可分離卷積層把普通卷積拆分為深度卷積(Depthwise Convolution)與逐點卷積(Pointwise Convolution)兩部分,它屬于因式分解卷積的一類。傳統卷積操作如圖4所示。若輸入圖片是5×5像素大小且通道數為3的彩色圖片,經過卷積核大小為3×3的傳統卷積層(假設該層卷積層包含4個濾波器),最終將輸出5×5×4大小的特征圖。該普通卷積操作中包含的參數量為3×3×3×4,計算量為3×3×4×3×5×5。若傳統卷積層將特征圖為DH×DW×M作為輸入,經傳統卷積操作后其輸出尺寸為DH×DW×N(假設卷積過程中添加了Same Padding,即輸入輸出寬高保持不變),其中DH表示輸入特征圖的高,DW表示的輸入特征圖的寬,M和N分別代表了輸入通道數和輸出通道數。最終可得出該傳統卷積的參數量為DK×DK×M×N,DK代表卷積操作中卷積核的尺寸,總計算量為DK×DK×M×N×DH×DW。

圖4 傳統卷積示意圖
深度卷積操作與傳統卷積操作最大差異之處在于前者的一個卷積核只負責一個通道。具體來說,深度卷積一個通道與一個卷積核做運算,而傳統卷積的每個卷積核都需要同時與每個通道做運算,深度卷積如圖5所示。與傳統卷積計算類似,深度卷積的參數量為DK×DK×M,計算量為DK×DK×M×DW×DH。從計算量及參數量對比可知,深度卷積操作比傳統卷積更為高效,但經深度卷積操作后輸出的特征圖的數量與通道數的數量一致,且特征在卷積過程中無法組合不同通道的圖像特征,因此需要逐點卷積來融合不同通道間 的信息。
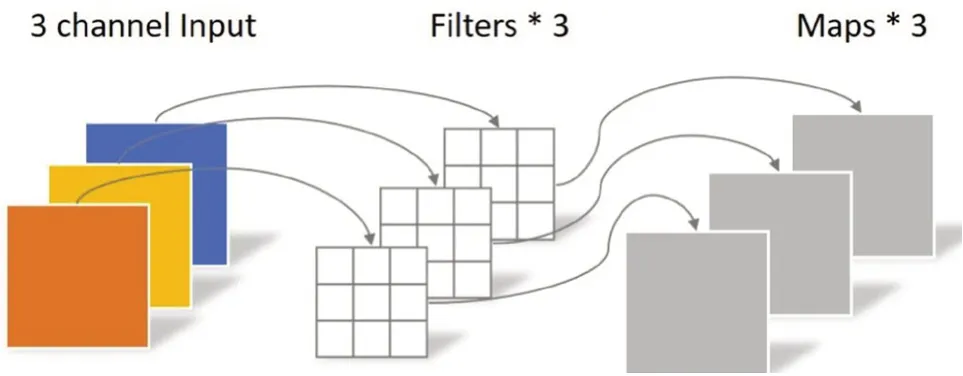
圖5 深度卷積示例圖
逐點卷積操作的原理與傳統卷積原理是相同的,但是其卷積核的尺寸是固定的1×1×M大小,M代表上一層輸出特征圖的通道數。逐點卷積的實質是對上一步深度卷積產生的特征圖進行深度上的加權融合,產生具有信息交融的特征圖,其原理如圖6所示。與傳統卷積類似,逐點卷積的參數量為1×1×M×N,計算量為M×N×DH×DW。
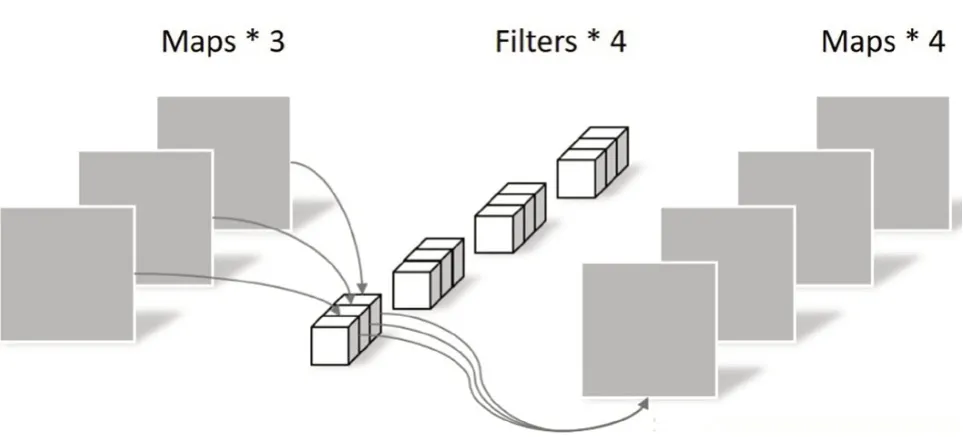
圖6 逐點卷積示例圖
綜上所述,深度可分離卷積可分解為提取特征和組合特征兩部分,相對于傳統卷積而言,其計算量和參數量的對比為:
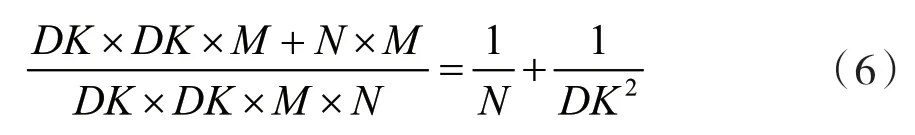
式中:N表示輸出通道數,其數值一般很大,DK表示卷積核的尺寸。因此,如果卷積神經網絡使用3×3大小的卷積核,深度可分離卷積操作可將網絡的參數量及計算量減少到1/8至1/9,而相應的代價是網絡的預測精度輕微下降。本文所提出的算法中,網絡結構的卷積操作將利用深度可分離卷積操作代替。
2.2 自注意力機制
自注意力機制(Self-attention Mechanism)來源于人類感知神經學科。自注意力機制是指在人類感知視覺中,由于大腦處理信息的能力具有一定瓶頸,人腦會選擇性地關注一部分重要的信息,忽略一些無關緊要的信息。自2014年Mnih等人將自注意力機制引入進計算機視覺領域獲取目標任務效果提升,自注意力機制開始受到科研人員的廣泛關注。2014年,Bahdanau[9]將自注意力機制與機器翻譯相結合。圖像超分辨率重建屬于低層計算機視覺領域,其核心任務是恢復圖像中的高頻細節,而重建的高分辨率圖像與低分辨率圖像存在相似圖案,因此可引入自注意力機制,將更多的精力用于恢復丟失的高頻細節,使重建圖像更符合人眼視覺效果。本文將引入自注意力機制,與雙向生成對抗網絡 相結合。
在圖像處理領域中,常用的注意力機制包括硬(Hard)注意力機制及軟(Soft)注意力機制。硬注意力機制(Hard Attention)通常只選擇對目標任務最重要的某些特征,將其他未被選擇的特征忽略。硬注意力機制在一定程度上對減少網絡計算量有益,但更大的劣勢是原圖像中的部分信息將丟失。在圖像超分辨率重建中,低分辨率圖像中的所有像素對重建圖像都是有影響的。因此,硬注意力機制在圖像超分辨率重建任務中并不適用。軟注意力機制(Soft Attention)相對于硬注意機制而言,采用了根據圖像特征的重要性來分配權重的方式。軟注意力機制考慮到所有的圖像特征,符合圖像超分辨率重建任務的原始出發點,因此本文將軟注意力機制與雙向對抗生成網絡結合。
軟注意力機制在計算機視覺應用領域中又分為通道注意力機制及位置注意力機制,本文使用的是通道注意力機制。在深度學習訓練過程中,訓練集中的輸入圖像通過若干層卷積神經網絡,最終將得到多張不同的特征圖(Feature Map)。通道注意力機制主要關注的是不同通道之間的關聯性。具體來說,通道注意力機制會賦予每張特征圖不同的權重,其原理如圖7所示。輸入特征圖首先需改變特征維度,其次經過全局平均池化層獲取單個通道C的初始權重。兩層全連接層分別對通道進行下采樣和上采樣操作以提升網絡學習通道特征的能力,同時Sigmoid激活函數將通道權重歸一化得到通道注意力特征圖,最后將通道注意力特征圖與輸入特征圖加權相乘。
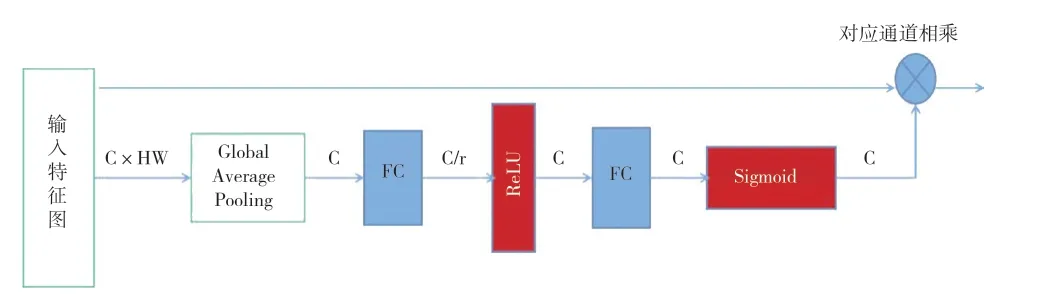
圖7 通道注意力機制
3 基于注意力機制的雙向生成對抗壓縮網絡(ADSRGAN)模型結構
本文提出的基于注意力機制的雙向生成對抗壓縮網絡(ADSRGAN)在雙向對抗生成網絡模型引入了深度可分離卷積層和混合注意力機制。
(1)利用深度可分離卷積層代替普通卷積層。將重建網絡及下采樣網絡中的普通卷積層替換成深度可分離殘差層,深度可分離殘差模塊如圖8 所示。
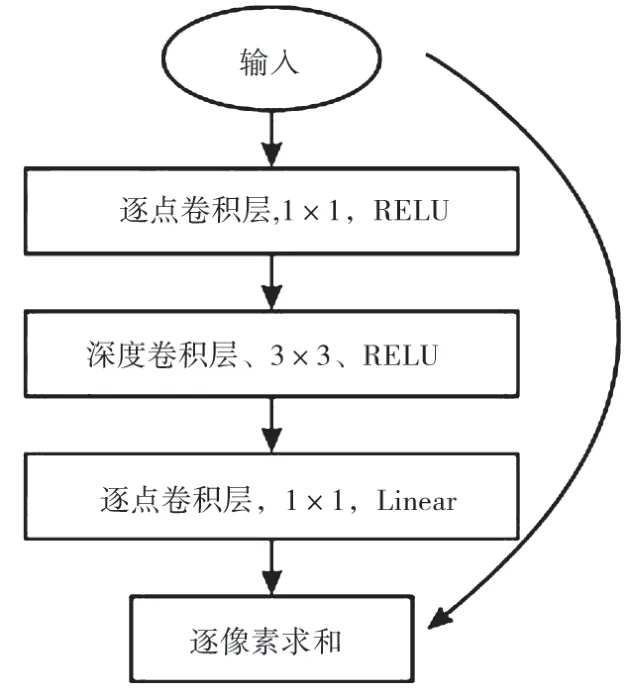
圖8 深度可分離殘差模塊
(2)引入混合注意力機制。為了不增加重建網絡的參數量,本文算法僅在下采樣網絡的殘差塊中引入通道注意力模塊,并在下采樣網絡的降采樣層引入位置自注意力模塊,促使生成的低分辨率圖片更貼近于現實生活。引入混合注意力的下采樣網絡結構如圖9所示。
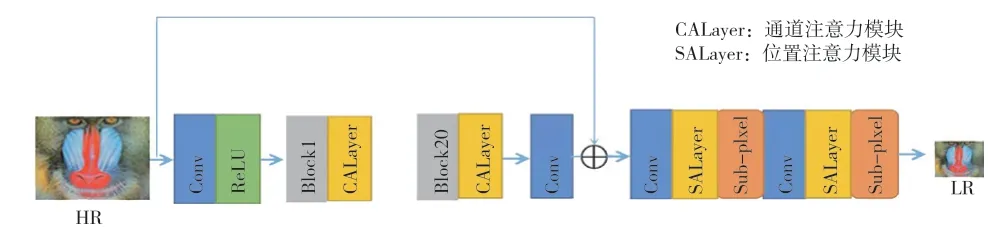
圖9 引入混合注意力的下采樣網絡結構
4 實驗結果及分析
為了驗證本文提出的基于注意力機制的雙向生成對抗壓縮網絡算法(ADSRGAN)的有效性,將本文算法的重建模型與其他基于卷積神經網絡的單幅圖像超分辨率重建方法進行比較。這些方法是專門為基于雙三次插值退化的超分辨率設計的,比如SRCNN、SRGAN、ESGANG等。
本文提出的ADSRGAN算法與其他算法在測試集Urban100上基于i7 8700 CPU的重建速度對比結果如表1所示。由表1可知,本文提出的算法重建效率比SRGAN提升近5倍。

表1 本文方法與其他重建算法時間對比
本文提出的ADSRGAN算法與其他算法在測試集Urban100、DIV2K及數據集RMSR上的峰值信噪比(Peak Signal to Noise Ratio,PSNR)對比結果如表2所示。所有算法在測試集Urban100、DIV2K上的測試過程為:首先對測試集中全部圖像運用雙三次插值方法進行4倍的下采樣,其次將下采樣得到的低分辨率圖像輸入進不同的重建模型中得出重建結果。在Urban100、DIV2K數據集上,本文的ADSRGAN算法相對于ESRGAN算法,PSNR值分別提升了0.05 dB、0.06 dB,在真實生活數據集RMSR上,本文算法的PSNR值相比于其他算法平均提升了1.51 dB。由實驗數據定量分析可知,本文設計的壓縮算法比雙向生成對抗網絡算法精度略微下降一點,仍優于其他基于生成對抗網絡的超分辨率重建算法。
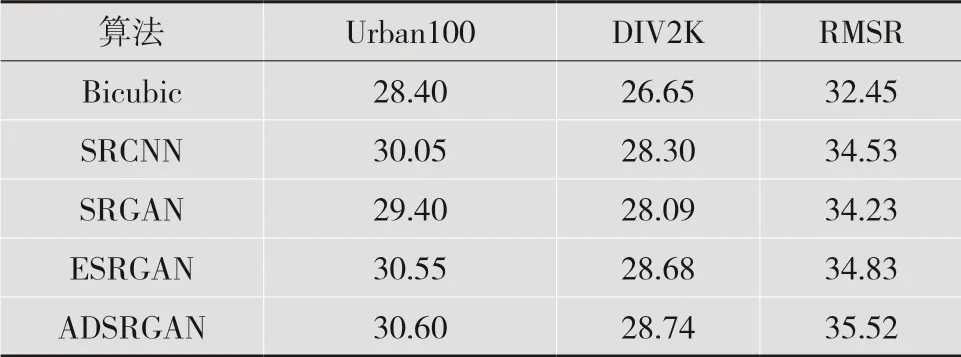
表2 不同重建算法在不同數據集上的PSNR結果對比(單位:dB)
本文提出的ADSRGAN算法與其他算法在測試集Urban、DIV2K及數據集RMSR上的結構相似性(Structural Similarity,SSIM)對比結果如表3所示。在Urban100數據集上,ADSRGAN算法相對于ESRGAN算法平均SSIM值提升了0.009 5;在DIV2K測試集上,平均SSIM值提升了0.021;在RMSR測試集上,平均SSIM值提升了0.012。由實驗數據定量分析可知,本文設計的壓縮算法比雙向生成對抗網絡算法精度略微下降一點,但仍優于其他基于生成對抗網絡的超分辨率重建算法。
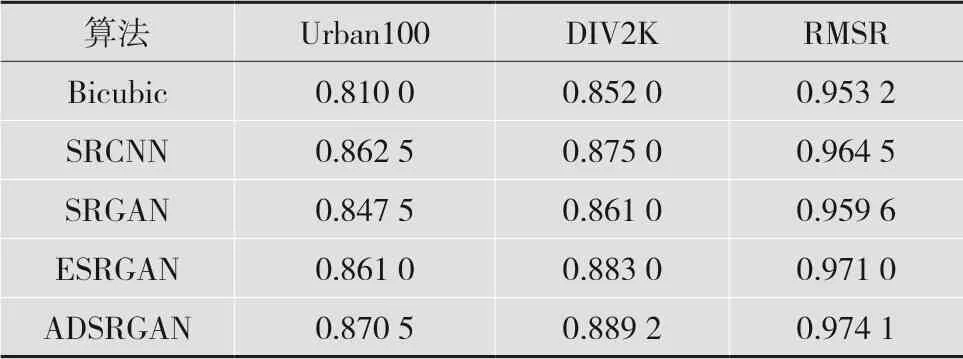
表3 本文方法與其他重建算法的SSIM
基于測試集Urban100、DIV2K上的圖片,分別對各種深度學習模型進行超分辨率重建的結果對比如圖10和圖11所示。從重建圖像的對比結果可看出,雙三次插值算法的重建效果最模糊,SRGAN算法會產生偽影,ESRGAN算法在邊緣部分也會有一些較少的偽影部分出現。本文的ADSRGAN算法重建的圖像細節清晰,邊緣明顯,與原圖最為相近。

圖10 本文算法與其他算法在Urban100測試集上的對比

圖11 本文算法與其他方法在DIV2K測試集上的對比
圖12 為Real-World數據集中的禁止抽煙測試圖像,通過對比各模型超分辨率重建結果圖可以看出,本文提出的算法在人眼感知視覺的效果最好,邊界明顯、細節清晰,與原始高分辨率圖像最相近。

圖12 現實世界圖像的重建結果對比
綜上所述,本文提出的基于注意力機制的雙向對抗生成壓縮網絡重建算法可處理現實世界模糊、低分辨率圖像并重建出視覺良好、細節豐富的高分辨率圖片,同時,本文設計的壓縮網絡在i7 8700 CPU上對Urban100測試集中的圖像放大4倍時,重建速度比SRGAN算法提升了約5倍。
5 結 語
本文介紹了注意力機制及深度可分離卷積的基本概念及主要特性。由于注意力機制在自然語言處理領域方向的成功應用,本文基于注意力機制提出了混合注意力模塊與可減少參數的深度可分離卷積層相結合的雙向生成對抗壓縮網絡。在實驗部分,與SRGAN方法和ESRGAN方法進行比較,實驗結果表明,本文提出的方法能夠有效地提高圖像重建質量及重建速度。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
文苑(2018年21期)2018-11-09 01:23:06
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國衛生(2015年9期)2015-11-10 03:11:12
中國衛生(2014年3期)2014-11-12 13:18:12
