畜牧業動物圖像目標檢測改進研究
2021-10-24 23:52:55更桑吉安見才讓
計算機時代 2021年10期
更桑吉 安見才讓


摘要: 根據不同的放牧方式有多種畜牧業管理模式,文章通過研究和改進圖像識別模型來提高畜牧業動物圖像檢測技術及畜牧業管理水平。選擇YOLOv3-Darknet53模型作為對象進行研究和改進,通過k-means++算法重新進行聚類分析,提高YOLOv3-Darknet53模型對畜牧業動物圖像目標檢測的檢測精度。實驗表明,改進模型對畜牧業動物圖像目標檢測的精度達到86.179%。F特征值在yak上提高了1%,S特征值在yak和sheep上分別提高了0.2%、1%,mAP提高了0.3%。
關鍵詞: YOLOv3; 畜牧業; 目標檢測; 維度聚類
中圖分類號:TP399? ? ? ? ? 文獻標識碼:A? ? 文章編號:1006-8228(2021)10-20-03
Research on the improvement of animal image target detection in animal husbandry
Geng Sangji, Anjian Cairang
(School of computer, Qinghai University for Nationalities, Xining, Qinghai 810007, China)
Abstract: According to different grazing methods, there are many animal husbandry management modes. This paper studies and improves the image recognition model to improve the animal husbandry image detection technology and animal husbandry management level. YOLOv3-Darknet53 model is chosen as the object to be studied and improved, by redoing the clustering analysis with k-means++ algorithm, the detection accuracy of YOLOv3-Darknet53 model in animal husbandry image target detection is improved. The experimental results show that the accuracy of the improved model is 86.179%. The F eigenvalue is increased by 1% on yak, the S eigenvalue is increased by 0.2% on yak and 1% on sheep, and the mAP is increased by 0.3%.
Key words: YOLOv3; animal husbandry; target detection; dimension clustering
0 引言
隨著硬件設備和網絡技術的不斷發展,人們獲取圖像的渠道一直在增加,圖像的數據量也呈指數型增長,在一定程度上逐漸滿足著研究者們對數據的需求量。圖像本身自帶著豐富的信息,并且圖像可以直觀地將信息內容展現出來,圖像作為一種傳播信息的介質已融入到我們的日常生活。利用深度學習圖像處理技術自動從圖像中定位目標,被廣泛應用于交通、醫學、身份認證等領域,并且扮演著很重要的角色。
目前青海省的畜牧業管理模式有單戶放牧、連戶放牧、雇人放牧等多種形式,草場面積和家庭的勞動力影響著畜牧的數量和品種,也影響著畜牧業管理的便利度,因此,人們所采取的管理方法也各不相同。不管采用何種放牧形式,都需要投入大量的財力物力去管理,若要改善管理畜牧業的管理安全和管理水平就要從傳統的管理模式走向現代化管理模式,本課題通過研究和改進圖像識別模型[1-2],來提高畜牧業動物圖像檢測能力及畜牧業管理水平。
1 卷積神經網絡概述
卷積神經網絡(Convolutional Neural Network,簡稱CNN)是一個在計算機視覺、自然語言處理、圖像處理等領域得到普及應用的一種典型的深度學習網絡架構,集中了感受野的思想。采用局部鏈接和權值共享降低模型的復雜度,且網絡易于優化。在圖像識別中卷積神經網絡的這種特性表現的更加明顯,它改變了傳統的特征提取過程,能夠自動提取圖像的特征,對輸入的信息具有高度不變性,縮放和傾斜的情況下也有一定的不變性。
2 感受野與池化
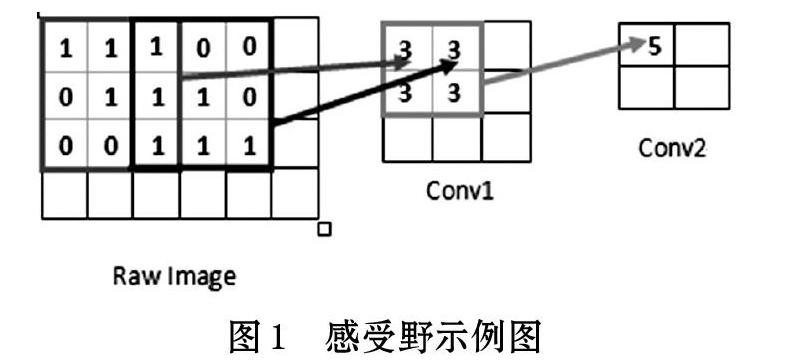
感受野(Receptive Field)在卷積神經網絡中是個既基礎又重要的概念,感受野表示在卷積網絡中某一層輸出的結果中一個元素對應輸入層上映射的區域,即特征圖(Feature Map)上的一個點所對應的輸入圖上的區域,再通俗點講,就是例如人的視覺感受中對某個事物感受的區域大小,如圖1所示。
如果某個神經元受到N*N的神經元區域的影響,該神經元的感受野就是N*N,因為該神經元反映了N*N區域的信息,特征圖中某一位置的特征向量是由前層某固定區域的輸入計算來的,那么這個區域就是這個位置的感受野。如圖1中像素點5是由前一層2*2區域計算而來,而2*2區域又是前一層中5*5區域計算而得來,因此該像素的感受野是5*5,在一幅圖像中感受野之外的圖像像素不會影響特征向量,感受野越大,得到的信息就越有全局性。
3 YOLOv3網絡結構
YOLOv3在Darknet-19上添加殘差網絡和卷積層將其擴充為Darknet-53全卷積特征提取網絡,殘差塊共有23個并進行五次降采樣操作。根據卷積核的步長設定改變張量的尺寸大小,圖1-5網絡結構圖中特征提取網絡的卷積步長為2,經過卷積操作后將輸入圖像縮小為原來的1/2的大小。步長為2的卷機操作總共有五次,輸入圖像在經過五次步長為2的卷積后,將特征圖縮小為原來的1/32,因此,網絡輸入圖像的尺寸大小應為32的倍數,如圖2所示。
圖2結構圖中輸入圖像的大小為416*416,經過多層卷積后會降維到52和26,13,通過特征提取網絡得到三個特征尺度,分別為1024*13*13、512*26*26、256*52*52。對應上圖1-5右邊的Convolutional Set,表示特征提取器的內部卷積結構,其中1*1卷積作用于降維操作、3*3卷積用于特征提取,多個卷積通過交叉達到特征提取器的最終目的。圖2中Concatenate表示當前特征層的輸入來自上一層輸出的一部分,因此表明了每個特征層關聯性,每個特征層都有一個輸出即圖2中Predict表示的部分,表示預測結果。
4 k-means聚類分析
“物以類聚”,其類的含義就是具有相似特征的集合,聚類指的就是把數據的集合根據研究的需求分組成多個類,同類的對象都是彼此相似的。從YOLOv2算法開始為了選取更理想的預測框,引入K-means算法進行聚類分析選出最理想的K個初始聚類中心,然后計算每個對象與K值的距離,按照最近原則進行鄰近聚類,YOLOv2聚類為五個anchor值,它衡量的是覆蓋率,因此使用交并比(IOU)方法來進行計算。建議目標的質量將直接影響預測框的準確與否,因此YOLOv3延續聚類分析方法的基礎上做了相應的改進,其做法是設置三個預測尺度,每個預測尺度分配三個錨框值,以此將原本五個anchor值增加至九個錨框值,此操作對目標檢測的精確度提供了進一步的提升。
下面將通過圖3和圖4對k-means與k-means++算法的思想進行對比。
5 k-mean++聚類算法對預測框的改進
本文以YOLOv3模型為研究基礎為了改進建議目標(object proposal)對預測框準確的影響,引入k-means++聚類算法重新對數據集進行聚類分析[3],并選擇了理想的anchor值。引發這一操作的原因是原YOLOv3的anchor值是根據COCO數據集80個類為對象而聚類得到的值,而本文使用的數據集(青藏高原畜牧業動物圖像數據集)是依據青海地區采集的圖像,與COCO數據集的目標有所差距,因此為了得到更適用于本實驗數據集的anchor值引發了這一系列操作。
首先引入k-means++算法,然后在經過20多次反復操作最終選擇平均出現率最高的兩組數值作為本次實驗的anchor值,其值為如表1所示,F(first),S(second)。
選擇兩組數據的原因是第一組數值的出現率為二十分之十三,第二組數值的出現率為二十分之七。因此分別將兩組數值都作為anchor值進行訓練,最終兩組數值在測試中的表現為F特征值在yak上提高了1%,S特征值在yak和sheep上分別提高了0.2%、1%,mAP提高了0.3%,測試結果如表2所示。
6 結束語
YOLOv3是目標檢測的研究領域中有著很大突破的一種算法,不管是在檢測精度還是檢測速度方面都擁有著很大的優勢和貢獻,雖然現階段的目標檢測技術已經在很大程度上成熟了,但仍處于探索的階段,算法成熟了不代表沒有缺點,因此目標檢測算法還有許多的缺點和不足。本文以YOLOv3模型為核心,基于深度學習的畜牧業動物圖像識別模型作為研究基礎與對照目標,為了提高畜牧業動物圖像的目標檢測精度,進行了提升檢測精度的研究和改進。
實驗結果表明,本文改進的模型對畜牧業動物圖像目標檢測在AP和mAP評價指標上都得到了相應的提升。下步可考慮引入注意力機制[4-5]、簡化網絡[6-8]等方法,改進算法和網絡結構,以提高畜牧業動物圖像的目標檢測的精確率、速率和模型的泛化能力。
參考文獻(References):
[1] 譚俊.一個改進的YOLOv3目標識別算法研究[D].中華科技大學,2018.
[2] 韓伊娜.基于深度學習的目標檢測與識別算法研究[D].西安科技大學,2020.
[3] 王灃.改進yolov5的口罩和安全帽佩戴人工智能檢測識別算法[J].建筑與預算,2020.11:67-69
[4] 劉丹,誤亞娟,羅南超,鄭伯川.潛入注意力和特征交織模塊的Gaussian-YOLOv3目標檢測[J].計算機應用,2020.40(8):2225-2230
[5] 徐誠極,王曉峰,楊亞東.Atttention-YOLO:引入注意力機制的YOLO檢測算法[J].計算機工程與應用,2019.55(6):201306
[6] 徐利鋒,黃海帆,丁維龍,范玉雷.基于改進DenseNet的水果小目標檢測[J].浙江大學學報(工學版),2021.55(2):377-385
[7] 張偉,莊幸濤,王雪力,陳云芳,李延超. DS-YOLO:一種部署在無人機終端上的小目標實時檢測算法[J].南京郵電大學學報(自然科學版),2021.41(1):86-98
[8] 程葉群,王艷,范裕瑩,李寶清.基于卷積神經網絡的輕量化目標檢測網絡[J/OL].激光與光電子學進展. https://kns.cnki.net/kcms/detail/31.1690.TN.20201229.1435.008.html.
