大規(guī)模高階張量與向量相乘的一種并行算法
2021-11-01 08:53:08張正東
現(xiàn)代計(jì)算機(jī) 2021年26期
張正東
(貴陽學(xué)院數(shù)學(xué)與信息科學(xué)學(xué)院,貴陽 550005)
0 引言
隨著大數(shù)據(jù)和人工智能技術(shù)的快速發(fā)展,其應(yīng)用范圍越來越廣,產(chǎn)生和匯集了海量數(shù)據(jù),數(shù)據(jù)屬性越來越多,維度越來越大,如何表示和處理海量高維數(shù)據(jù)以挖掘數(shù)據(jù)價(jià)值是我們面臨的一大挑戰(zhàn)[1]。張量因其多維特性是解決這一問題的有效方法。張量在數(shù)學(xué)上是多維數(shù)組或多維陣列,可用多個(gè)下標(biāo)表示,是向量和矩陣概念向高維空間的推廣。張量的維數(shù)稱為階(order)或模(mode)[2],高階張量具有多個(gè)維度,非常適合用來表示現(xiàn)實(shí)世界中的多維、復(fù)雜數(shù)據(jù),如復(fù)雜網(wǎng)絡(luò)、多維社交關(guān)系等。張量在人工智能中得到了廣泛應(yīng)用,現(xiàn)在流行的深度學(xué)習(xí)框架TensorFlow就將張量作為一種基本數(shù)據(jù)模型[3]。高階張量隨著維度的增加,表示的多維關(guān)系越來越復(fù)雜,存儲(chǔ)的數(shù)據(jù)量也越來越大,如5階張量,每階數(shù)據(jù)量為1 000,總數(shù)據(jù)量為103*103*103*103*103=1015,如此海量數(shù)據(jù)對(duì)存儲(chǔ)和計(jì)算提出了更高要求。實(shí)際應(yīng)用中,高階張量往往是稀疏的,也即只有一部分元素是非0值。在此情況下,我們需要設(shè)計(jì)一種有效的存儲(chǔ)方案以擴(kuò)大張量的應(yīng)用范圍,并能以并行計(jì)算或分布式計(jì)算方式進(jìn)行數(shù)據(jù)處理。
并行計(jì)算是處理海量數(shù)據(jù)的常用方法之一。隨著CPU和GPU技術(shù)的發(fā)展,其核心數(shù)越來越多,特別是在GPU計(jì)算中,可以開啟幾十、幾百上甚至千個(gè)線程并行處理數(shù)據(jù)[4],能大大降低計(jì)算時(shí)間。采用并行方式處理數(shù)據(jù),數(shù)據(jù)在本地完成處理,可避免數(shù)據(jù)在集群中傳播、計(jì)算任務(wù)分發(fā)和結(jié)果收集的時(shí)間開銷,同時(shí)也能更好的發(fā)揮機(jī)器算力。在集群環(huán)境中,計(jì)算節(jié)點(diǎn)上開啟多線程進(jìn)行并行計(jì)算能更好的提高數(shù)據(jù)處理效率[5],這也是很多流行的分布式計(jì)算框架采用的方法,比如分布式內(nèi)存計(jì)算框架Spark。
張量的一種基本運(yùn)算是與向量相乘,以此達(dá)到對(duì)張量降維的目的,是最頻繁的張量運(yùn)算之一,該步驟的計(jì)算速度對(duì)整體性能有較大影響。本文的研究?jī)?nèi)容即是如何用key-value對(duì)表示高階張量并實(shí)現(xiàn)張量與向量的并行相乘。
1 算法實(shí)現(xiàn)
1.1 算法描述
對(duì)于N維空間張量X∈RI1×I2×…×I N和1維空間向量v∈RI n,張量和向量的mode-n相乘規(guī)則為公式(1)。mode-n是指向量和張量的哪個(gè)維度相乘。
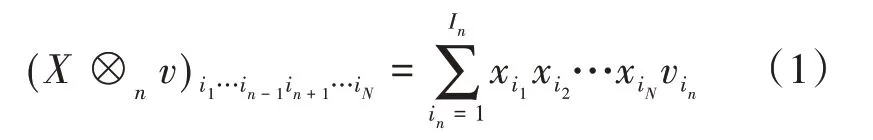
從公式(1)可以看出,張量與向量相乘的結(jié)果也是張量,但已經(jīng)沒有n維度了,即消去了n維度,結(jié)果張量少了一個(gè)維度,對(duì)張量進(jìn)行了降維。張量和向量mode-n相乘的過程是固定張量其他維度下標(biāo),遍歷n維度下標(biāo),用此下標(biāo)到向量中取值并和張量元素值相乘,最后將下標(biāo)相同的元素求和。這就要求張量n維度的元素個(gè)數(shù)和向量元素個(gè)數(shù)相同。如張量X∈R2×2×2和向量v∈R2的mode-2相乘,結(jié)果為張量X'∈R2×2,如公式(2)所示。其中,張量和向量元素值用下標(biāo)表示。
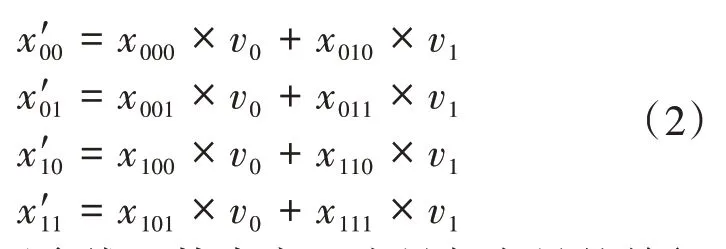
為了采用多線程技術(shù)實(shí)現(xiàn)張量與向量的并行相乘,我們可以用key-value對(duì)表示張量元素,其中key為張量元素下標(biāo)組合,value為元素值。這樣張量就可以轉(zhuǎn)換成Map或者列表(列表元素是自定義的JavaBean,包含key和value屬性)。通過將Map或者列表均勻分割,開啟多線程,每個(gè)線程處理一部分,最后匯聚,從而實(shí)現(xiàn)張量和向量并行相乘。公式(1)表明,采用分割-匯聚策略,對(duì)最終結(jié)果沒有影響。我們只對(duì)張量中非0值元素進(jìn)行轉(zhuǎn)換,對(duì)于0值元素,根據(jù)公式(1),其和向量元素相乘結(jié)果也為0,對(duì)求和結(jié)果沒有影響。張量與向量并行相乘過程如算法1。算法1采用了線程池技術(shù)對(duì)線程進(jìn)行管理和復(fù)用,避免多次創(chuàng)建線程開銷,并在每個(gè)線程中進(jìn)行局部匯聚,實(shí)現(xiàn)局部?jī)?yōu)化,進(jìn)而提高計(jì)算效率。
算法1張量與向量并行相乘。
1.定義包含key和value屬性的JavaBean,表示張量非0值元素。
2.將張量轉(zhuǎn)換為列表。
3.將列表均勻分割,啟動(dòng)線程池,每部分用一個(gè)線程計(jì)算。
4.對(duì)于每一個(gè)計(jì)算線程,遍歷列表元素:
5. 對(duì)于每一個(gè)key-value對(duì),將key分割成張量下標(biāo)。
6. 用n維度下標(biāo)到向量中取值并和value相乘,得到新值value'。
7.去除n維度下標(biāo),重新生成key'。
8.將key'-value'放到Map中,進(jìn)行局部匯聚。
9.收集線程計(jì)算結(jié)果,進(jìn)行全局匯聚。
10.生成結(jié)果。
1.2 實(shí)現(xiàn)代碼
算法1程序?qū)崿F(xiàn)主要包括兩部分,一是均勻分割張量元素列表,每部分對(duì)應(yīng)一個(gè)計(jì)算線程,通過線程池管理;二是在每個(gè)線程內(nèi)部實(shí)現(xiàn)張量和向量相乘。第一部分實(shí)現(xiàn)程序?yàn)椋?/p>
private Map<String,Integer>computeInThread(List<Element>dataList,int threadCount,final int[]vector,final int modeN){
int cpuCore=Runtime.get Runtime().availableProcessors();//獲取CPU核心數(shù)
//計(jì)算線程池最大容量
int pool Size=threadCount<=cpuCore?thread-Count:cpuCore;
int threadSize=dataList.size()/threadCount;//每個(gè)線程處理數(shù)據(jù)量
//創(chuàng)建固定大小的線程池
ExecutorService executorService = Executors.new-FixedThreadPool(poolSize);
for(int index=0;index<threadCount;index++){
//根據(jù)線程數(shù)量,計(jì)算每部分開始和結(jié)束下標(biāo)
int fromIndex=index*threadSize;
int toIndex=(index+1)*threadSize;
if(index==threadCount-1){
toIndex=dataList.size();
}
if(fromIndex<toIndex){
//通過下標(biāo)取列表部分,分割列表
final List<Element>tensor=dataList.subList(fromIndex,toIndex);
//以lambda表達(dá)式形式向線程池提交一個(gè)計(jì)算線程任務(wù)
executorService.execute(()->ttv(tensor,vector,modeN));
}
}
executorService.shutdown();//關(guān)閉線程池,等待計(jì)算完成
while(true){
if(executorService.isTerminated()){
break;
}
}
//全局結(jié)果
Map<String,Integer>result Map=new HashMap<>();
//tmpResultList是全局列表,存放了每個(gè)線程計(jì)算結(jié)果
for(Map<String,Integer> tmpResult Map:tmpResultList){
for(String key:tmpResultMap.keySet()){
int tmpValue=tmpResultMap.get(key);
//全局匯聚
processMapElement(resultMap,key,tmpValue);
}
}
return result Map;
}
上述程序中的processMapElement函數(shù)進(jìn)行Map中元素匯聚,將相同key的元素值求和,程序代碼為:
private void processMapElement(Map<String,Integer>map,String key,int value){
int rValue=value;
if(map.containsKey(key)){
//若key已經(jīng)存在,將值求和
rValue+=map.get(key);
}
map.put(key,rValue);
}
ttv函數(shù)為張量和向量相乘,也即第二部分,程序代碼為:
private void ttv(List<Element>tensor,int[]vector,int modeN){
Map<String,Integer>resultMap=new HashMap<>();
//局部結(jié)果map
for(Element element:tensor){//遍歷張量元素
String[]keySplits=element.getKey().split("#");
//分割key
int value=element.getValue();
//到向量中取值并和張量值相乘
int mValue=value*vector[Integer.parseInt(key-Splits[modeN-1])];
String mKey="";
//去除相乘維度下標(biāo),組合新的key
for(int index=0;index<keySplits.length;index++){
if(index!=modeN-1){
mKey=mKey+keySplits[index]+"#";
}
}
//去除結(jié)尾的分隔符
if(mKey.endsWith("#")){
mKey=mKey.substring(0,mKey.length()-1);
}
//局部匯聚
processMapElement(result Map,mKey,mValue);
}
tmpResultList.add(resultMap);
}
ttv函數(shù)中,我們定義了一個(gè)全局列表,用于收集每個(gè)線程的計(jì)算結(jié)果。由于多個(gè)線程都會(huì)向全局列表中添加數(shù)據(jù),為了避免數(shù)據(jù)混亂,我們采用了具有線程寫安全性的CopyOnWriteArray List。我們將張量與向量乘積結(jié)果放在Map中,其中key為張量元素下標(biāo)組合,value為值。結(jié)果Map可以很容易轉(zhuǎn)換為元素列表,或者將key拆分還原到張量中,以進(jìn)行下一步處理。
2 結(jié)果與分析
算法采用了Java實(shí)現(xiàn),JDK版本為8u181,機(jī)器內(nèi)存為16 G,CPU為Intel i7-7700HQ,核心數(shù)為8。我們進(jìn)行了兩次運(yùn)算,一次是低階張量和向量相乘,用于測(cè)試算法的準(zhǔn)確性,張量X∈R2×2×2和向量v∈R2,元素值隨機(jī)產(chǎn)生,進(jìn)行mode-2相乘,結(jié)果如圖1所示。
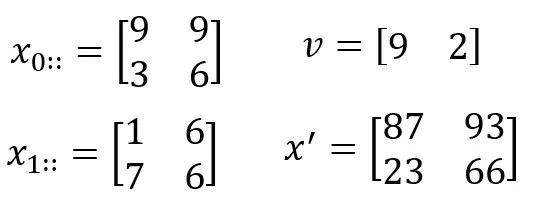
圖1 張量和向量mode-2相乘的結(jié)果
其中,冒號(hào)(:)表示所有下標(biāo),x是原張量,v是向量,x'是結(jié)果張量。
另一次運(yùn)算是測(cè)試計(jì)算規(guī)模和時(shí)間,我們分別設(shè)置計(jì)算線程數(shù)為6、10和16,線程池容量為線程數(shù)和機(jī)器核心數(shù)的最小值,非0元素下標(biāo)和值以及向量值均隨機(jī)產(chǎn)生,對(duì)于每個(gè)線程數(shù)計(jì)算三次,取平均時(shí)間,計(jì)算結(jié)果如表1所示。數(shù)據(jù)表明,我們實(shí)現(xiàn)的并行算法可用于大規(guī)模張量與向量相乘,隨著線程數(shù)的增加,計(jì)算的并行度提高,計(jì)算時(shí)間也進(jìn)一步降低。實(shí)際應(yīng)用中可根據(jù)機(jī)器配置,設(shè)置合適的線程數(shù)量。因?yàn)樗惴?只對(duì)張量中的非0值進(jìn)行處理,對(duì)于稀疏張量,由于大部分是0值,算法的性能會(huì)更高,能處理的數(shù)據(jù)規(guī)模也更大。

表1 大規(guī)模高階稀疏張量與向量相乘數(shù)據(jù)
