基于SoftLexicon的醫療實體識別模型
2021-11-01 12:51:52朱艷輝梁文桐
湖南工業大學學報 2021年5期
張 旭,朱艷輝,梁文桐,詹 飛
1 研究背景
近年來,自然語言處理技術(natural language processing,NLP)的應用越來越廣泛。醫療行業信息化迅速發展,其中電子病歷(electronic medical record,EMR)在臨床治療、疾病預防等方面扮演著重要角色。EMR 是醫務人員在病人治療過程中(該過程包括臨床診斷、檢查檢驗、臨床治療等),利用醫療機構信息系統生成患者的數字化信息,并進行存儲、管理、傳輸和醫療記錄的再現[1]。對電子病歷進行數據處理,構建專業且全面的醫療知識庫,更有利于發揮其在“智慧醫療”中的作用。但是,目前電子病歷大多處于非結構化狀態,因而嚴重制約了其開發與利用[2]。
命名實體識別(named entity recognition,NER)是自然語言處理技術的一個分支,屬于信息抽取的子任務,它將具有特定意義的實體從非結構文本中提取出來,并將其歸入預定類別,例如從文本中識別出與人名、地名和機構名相關的實體。NER 本質上可以被看成是一種序列標注問題,在許多下游任務中扮演著重要的角色,包括知識庫建設[3]、信息檢索[4]和問答系統[5]。
隨著醫療AI 技術的發展,信息抽取技術在醫療信息化的進程中扮演著不可或缺的角色,這一定程度上與國內外開展的相關評測任務密不可分,它們推動了大批學者對前沿技術的探索;國外的I2B2 會議催生了一系列優秀的研究成果,HMM(hidden markov model)、CRF(conditional random field)等基于統計的機器學習方法首次被應用于醫療NER 任務中,且有不錯的性能表現;國內的全國知識圖譜與語義計算大會(China Conference on Knowledge Graph and Semantic Computing,CCKS)自2017年起,已經連續4a 組織中文電子病歷命名實體識別相關評測。在CCKS-2017 面向中文電子病歷的命名實體識別任務中,參評者均有對Bi-LSTM(bidirectional long shortterm memory)算法模型的實現[6]。Zhang Y.等[7]分別采用CRFs 和BiLSTM-CRF 從電子病歷數據集中識別疾病、身體部位和治療等類型實體,對比發現后者的性能更好。CCKS-2018 評測中,何云琪等[8]通過結合一系列句法和語義特征表示,作為CRF 層的輸入進行標簽預測;Luo L.等[9]基于多特征(如標點符號、分詞和詞典等特征)融合,整合多種神經網絡模型,完成對電子病歷命名實體的識別,且取得不錯的效果。潘璀然等[10]通過Lattice-LSTM 網絡表示句子中的單詞,將字符與詞序列的語義信息整合到基于字符的LSTM-CRF 中,在CCKS-2018 任務一上進行實驗,其F1值優于之前的最高結果。
但是,以上基于深度神經網絡的NER 模型,都存在不同程度的缺陷。首先,與英語NER 相比,中文NER 的一大難點在于中文句子不是自然地被分隔開,傳統深度學習NER 模型在中文特征提取過程中,可分為基于詞粒度和基于字符粒度兩大類,但由于中文電子病歷實體的特殊性,即存在跨度較長的實體,因此常用分詞工具無法精準識別實體邊界,由此產生的分詞錯誤會延續到上層模型的預測;基于字粒度的模型解決了分詞錯誤的問題,但無法利用到句中單詞的信息,尤其對于中文,相同字符在不同詞中可能有不同的涵義,例如“燈光”和“爭光”中的“光”字分別代表了“光線”和“榮譽”的含義;其次,研究者較少關注先驗知識對識別效果的輔助作用[11],在Zhang Y.[12]的工作中證明了詞典信息對提高NER準確率的重要性,但是現有引入詞典的方法無一例外都建立了復雜的模型結構,導致運算效率低下,實用性不高。
綜合以上問題,本文利用字符粒度Bi-LSTMCRF 模型的優勢,提出一種基于“BMES”標簽的詞典簡化方案,將單詞詞典整合到字符表示層中,SoftLexicon 方法避免了設計復雜的序列建模結構,通過對字詞向量的拼接來完成詞典信息引入,無需動態對句子序列進行編碼,具體工作將在2.2 節中展開介紹;同時,由于字符與詞典的匹配不與LSTM 編碼層同步進行,因此很大程度上解決了引入詞典帶來運算效率低的問題。詞典作為一種已有的先驗知識,可以為字符信息提供很好的補充,增強神經網絡模型對先驗知識的學習,以便更完整地獲取電子病歷文本句中的實體特征,通過實驗驗證了基于SoftLexicon的中文電子病歷實體識別模型無論在準確率還是效率上都有不錯的表現。
本文后續結構如下:首先,對SoftLexicon 方法進行概述,并對字符表示層以及序列建模層實現過程展開介紹;然后介紹本文實驗的相關工作,包括本文實驗所用數據集,以及實驗軟硬件和參數設置,并對不同模型的對比實驗效果進行分析;最后總結現有工作并提出后續工作設想。
2 基于SoftLexicon 的中文電子病歷實體識別模型
2.1 中文電子病歷實體識別任務
CCKS-2020 面向中文電子病歷的醫療實體抽取是CCKS 圍繞中文電子病歷語義化開展的系列評測的一個延續,本文采用CCKS-2020 評測提供的中文電子病歷實體數據集,標注數據包括了醫療實體的名稱、起始和結束位置以及預定義類別,其中6 類預定義類別定義如表1 所示。

表1 CCKS-2020 預定義實體類別及定義Table 1 CCKS-2020 predefined entity classes
中文電子病歷命名實體識別任務要求在純文本電子病歷文檔中,識別并抽取出與符合預定義類別的實體,及其在文本中的位置信息,并將它們以字典的形式表示。
2.2 基于SoftLexicon 的實體識別模型
在進行關鍵詞自動抽取時,以HMM、CRF 為代表的傳統機器學習方法依賴人工構建大量特征工程。隨著計算機硬件的快速發展,再加上醫療標注語料的逐漸完善,深度神經網絡模型表現其優勢,它通過模擬人類神經網絡,運用多層的網絡運算[13],能有效挖掘文本潛在語義信息,對人工難以識別的特征提取效果更好。基于SoftLexicon 的實體識別模型如圖1 所示。
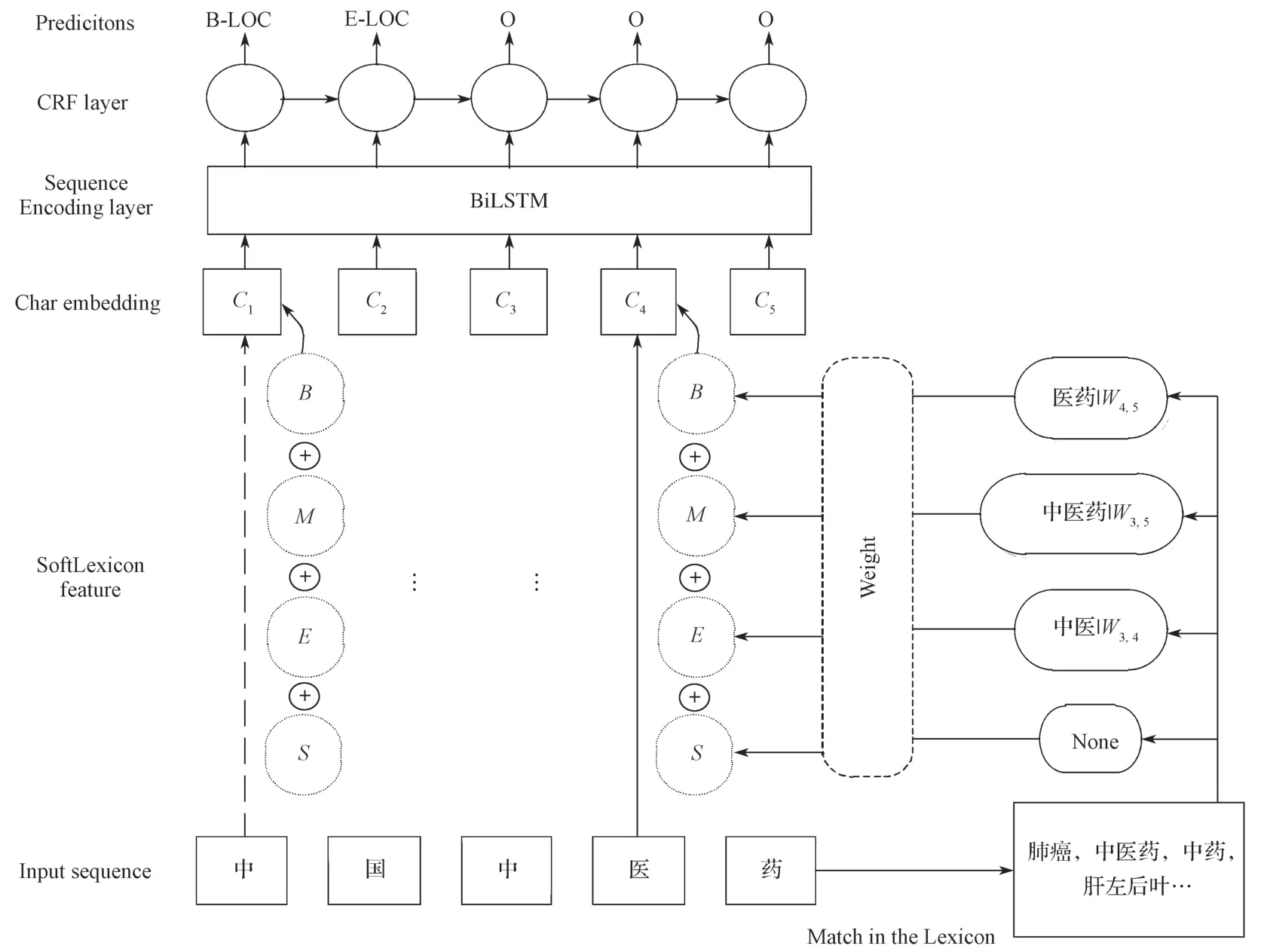
圖1 SoftLexicon 模型結構圖Fig.1 SoftLexicon model structure
圖1 中,以輸入序列“中國中醫藥”為例:(此圖僅為流程展示,具體詞典匹配結果以實驗為準),整個神經網絡共有4 層結構:輸入層構建輸入句子的特征向量序列,分別將字符對應的4 個單詞集的表示形式組合成一個一維特征集,并將其添加到每個字符的表示形式中,例如圖中的“醫”字與詞典匹配后得到的相關詞,進行embedding lookup,經線性變換拼接到其字向量表示上;隱藏層為一個雙向的LSTM網絡,前向的LSTM 用于獲取前文信息,反向傳播的LSTM用于獲取下文信息,再將雙向信息拼接整合;在雙向LSTM 層之上,應用CRF(條件隨機場)層為字符序列執行標簽推斷,CRF 能夠考慮到標簽之間的連續性,獲得最優輸出序列。
2.2.1 SoftLexicon
單純基于字符NER 方法的缺點是單詞信息未被充分利用。考慮到這一點,Zhang Y.[12]提出了Lattice-LSTM 模型,用于將單詞詞典合并到基于字符的NER 模型中。Lattice-LSTM 有兩個優點,首先它保留了與單個字符有關的所有可能的詞典匹配結果,解決了詞邊界不確定的問題。其次,它可以引入預訓練的詞向量模型,從而極大地提升了性能。然而,Lattice-LSTM 模型復雜的結構導致其運算速度十分有限。如圖2 所示,它在不相鄰的字符之間額外增加了一個詞級別LSTM通路,對字符組成的詞進行編碼,再輸入到對應字符的Cell 中,由此可能產生單字符對應多輸入的情況,因此在模型解碼階段就增加了計算復雜度;同時Lattice-LSTM 在引入詞典過程中,依舊存在信息缺失的問題,例如圖2“中醫藥”中的“醫”字,它只能獲取到“中醫”的詞信息,而無法獲取“醫藥”和“中醫藥”對應的詞信息。
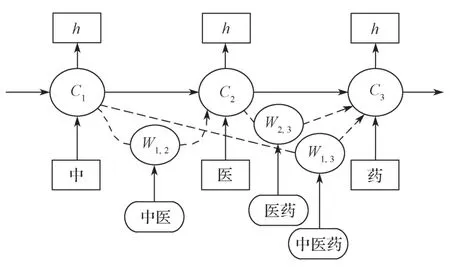
圖2 Lattice-LSTM 模型結構示意圖Fig.2 Lattice-LSTM structure
針對上述不足,本文做了以下相關工作。課題組提出在中文電子病歷NER 上使用一種輕量級詞典匹配方法,首先將輸入序列s={c1,c2,…,cn}與詞典進行匹配,得到所有相關的詞Wi,j(表示s子序列{c1,c2,…,cj}),為了保留分段信息,將每個字符ci的所有匹配單詞分類為4 個單詞集“BMES”,這4 個集合的構造如下,其中,L表示本文所使用的詞典:
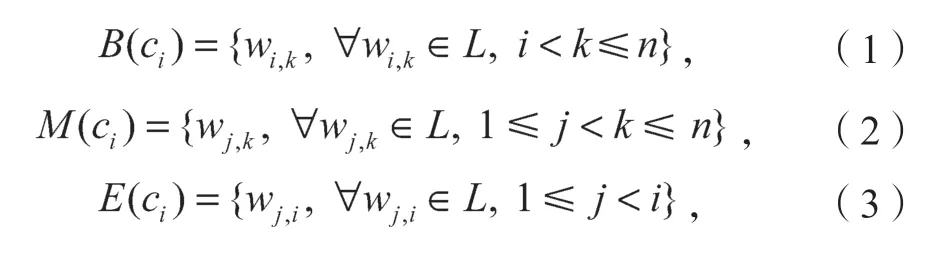
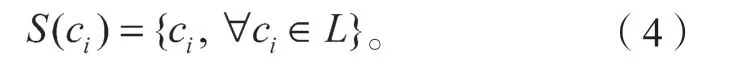
圖3 所示為“中醫藥”的Lexicon 匹配示意圖。
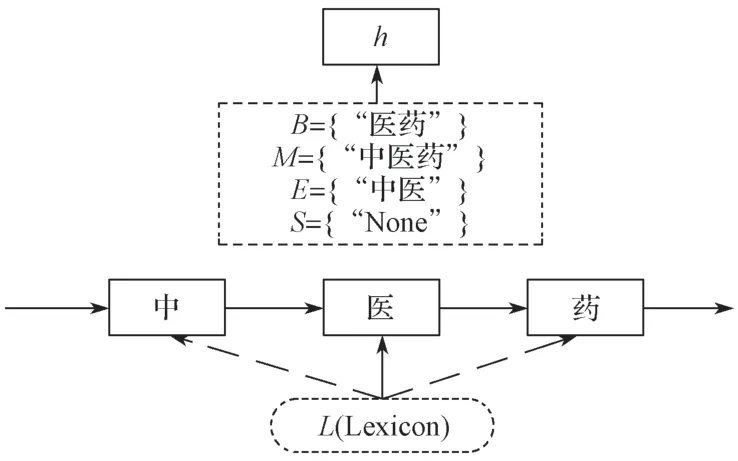
圖3 Lexicon 匹配示意圖Fig.3 Lexicon matching
如圖3 中所示,以“中醫藥”為例,字符“醫”與預先構造的詞典進行單詞匹配,得到對應的4 個單詞集:B={W2,3(“醫藥”)},M={W1,3(“中醫藥”)},E={W1,2(“中醫”)},S={(“None”)}(如果沒有與之匹配到的詞語,就用“None”來表示該集合)。同時本文引入了預先訓練好的詞向量,單詞集中的每個單詞都會轉化成對應的詞向量;然后對四個單詞集中的所有單詞執行權重歸一化,此處使用基于統計的靜態加權方法[14],即靜態數據中每個詞出現的頻率,這種頻率能一定程度上反映該詞的重要程度,靜態數據可以來源于醫療領域相關的文章等,其加權方法如式(5):
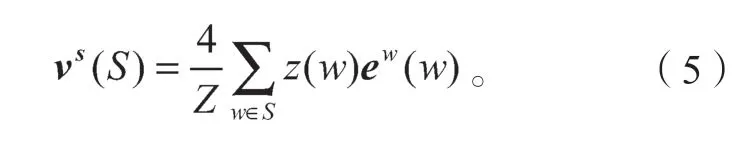
式中:S為“BMES”單詞集;
z(w)為詞典中單詞w在靜態數據統計中出現的頻率;
Z為單詞集中所有詞出現頻率之和;
ew為用于embedding lookup 的詞向量矩陣。
最后將4 個單詞集的表示形式組合成一個一維特征,再拼接到該字符向量的表示上,從而得到最終的輸入向量。
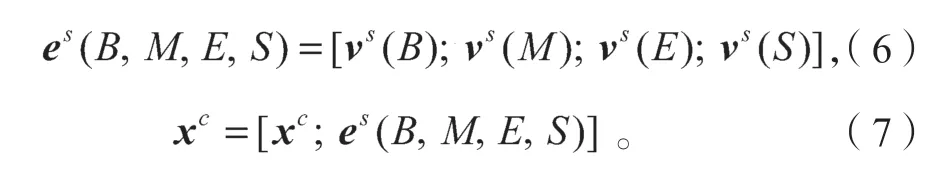
式中:xc代表字符c對應的字向量;es(B,M,E,S)代表字符c匹配的單詞集加權組合后的詞向量。
2.2.2 LSTM 網絡
RNN(recurrent neural network)模型由于可以自動保存歷史信息并將其應用到當前輸出中,易于捕獲長距離依賴關系,這些特性十分適合處理時序信息,如序列標注問題[15],但是在上下文距離過長的情況下,容易產生梯度爆炸或梯度消失的問題。由此衍生而來的LSTM,在RNN 模型基礎上增加了門控機制和一個用于保存長距離信息的memory cell,本文使用的Bi-LSTM 是在單向LSTM 的基礎上,增加一層反方向的LSTM,這樣能夠有效捕獲某一時刻的前后文信息。
LSTM 的門控機制由輸入門、遺忘門、輸出門3部分組成。以前向LSTM 為例,具體計算公式如下:
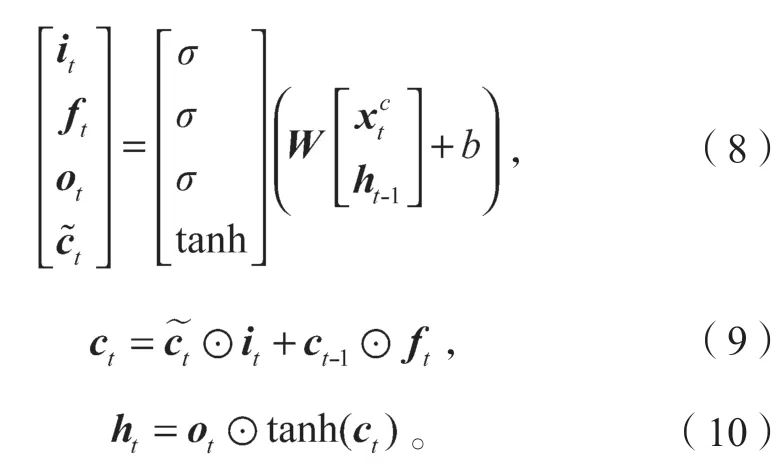
式(8)~(10)中:σ為sigmoid 函數;
W和b為訓練過程不斷更新的參數。
前向LSTM 與反向LSTM 具有相同的定義,但以相反的順序對序列進行建模。在向前和向后LSTM的第i時刻處的級聯隱藏狀態形成ci的上下文相關表示。
2.2.3 CRF 模型
一個簡單有效的標簽模型是使用hi的特性為每個輸出yi做出獨立的標簽決策。但當輸出標簽之間有很強的依賴性時,獨立的分類決定顯示出局限性。CRF 是一種基于無向圖的判別式概率模型,它是指在給出一組隨機輸入變量的條件下,推斷出另一組輸出隨機變量的條件概率分布模式[15];對于序列標注任務,CRF 輸入序列為一個句子,輸出序列是句中每個字符的標簽,采用CRF 可以添加對標簽序列的預測約束(例如,在B-PER 后面不能接I-LOC),提高NER 的識別準確率。
對于一個給定的輸入序列X,預測序列為y,本文定義如式(11)所示的打分函數,它由兩部分組成,其中,A是轉移概率矩陣,Ayi,yi+1代表從yi標簽到yi+1 標簽的得分;P是經過BiLSTM 網絡輸出的字符標簽分數矩陣,Pi,yi代表第i個字符作為標簽yi的分數。
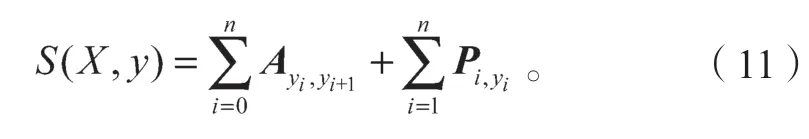
在訓練過程中,對正確標簽序列進行最大似然概率估計:
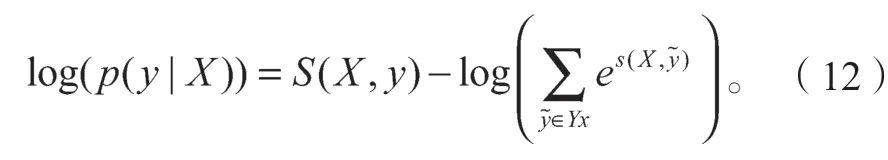
式中:YX是輸入序列X中所有可能的標注序列。在解碼階段,利用動態規劃算法,找到最高的條件概率標簽序列y*,即得分函數取得最大值對應的序列:
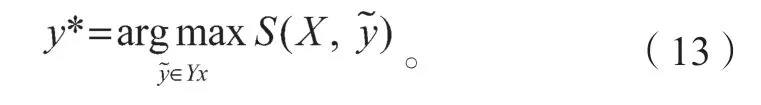
3 實驗設計與結果分析
3.1 實驗數據分析及預處理
本文實驗的數據集來自于CCKS-2020 的評測任務,官方提供的已標注訓練數據共1 050 條文本,為了更好地掌握數據集以便模型建模,本文對訓練數據中各類別的實體數量以及長度進行了統計,具體如表2 所示。
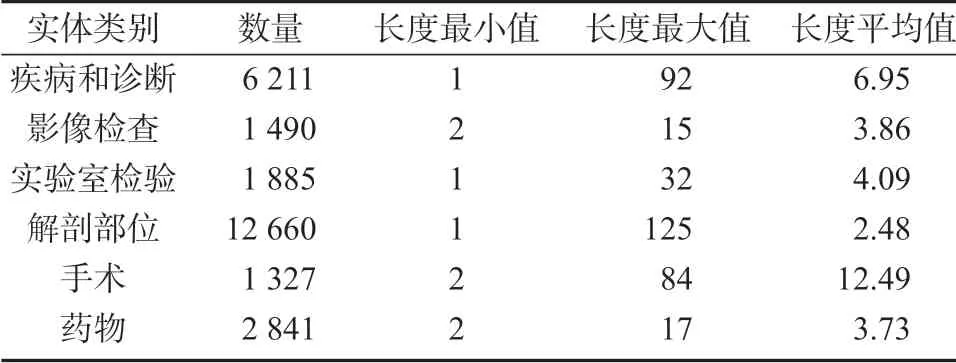
表2 訓練語料實體統計結果Table 2 Entity statistics of training corpus
從表2 數據中可以看出,“疾病和診斷”和“解剖部位”兩類實體出現最為頻繁,其余各類別的實體數量分布在1 000~3 000 個。這是由電子病歷的特點所決定的,患者就醫都需要進行臨床診斷,檢查的方式有兩種,輕微病癥只需藥物治療,特定疾病需手術配合藥物治療,因此藥物實體總數與檢查實體總數基本持平。同時,手術類實體的平均長度為12.49,且最大實體長度達84,這些表明了電子病歷中實體的特殊性,存在許多領域詞匯,因此對模型的識別準確率提出較高要求。
對于深度神經網絡模型來說,1 050 條訓練數據不足以滿足模型對數據量的需求,本文分析訓練數據后發現,數據均由多個短句組成,導致文本長度過長,且相鄰短句之間語義弱關聯,因此本文以“。”作為分隔符結合句末分隔,對訓練數據進行拆分,最終得到10 305 個句子序列。
同時為了驗證模型訓練參數效果以及結果預測效果,采用交叉驗證法。如表3 所示,本文對訓練數據按照6:2:2 的比例,將其劃分為訓練集、驗證集和測試集。

表3 實驗數據集劃分Table 3 Experimental data division
本文對評測任務兩階段中發布的醫療詞典文檔進行去重融合,得到一個包含6 類實體、6 293 個醫療實體的詞典,將其作為本文實驗所需詞典。
3.2 實驗環境及參數設置
本實驗基于TensorFlow 計算框架,使用GPU 加速,具體環境配置如表4 所示。

表4 實驗環境配置Table 4 Experimental environment configuration
本文設置字向量維數為200,進行字詞融合的詞向量維度為50;考慮模型的收斂速度,將學習率設為0.001 5,同時,為了兼顧訓練效率和后期穩定性,設置warm up 占整個訓練輪次的0.1,0.90 的學習率指數衰減,即迭代1 000 輪次后,學習率變為原來的0.90;隱藏層節點數設為300,為防止過擬合現象,Dropout 調整為0.5,具體見表5。經過多次實驗后,驗證了所設參數的合理性。

表5 實驗超參數設置Table 5 Experimental hyperparameter setting
3.3 評價指標
本實驗評價體系包括準確率(P)、召回率(R)和F1值,各指標具體公式如下:
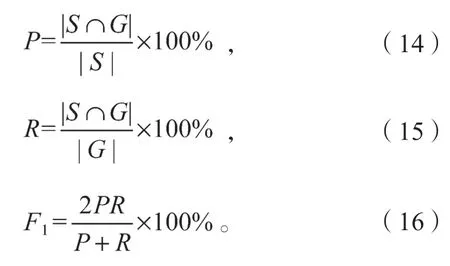
式(14)~(16)中:S為模型輸出結果,記為S={S1,S2,…,Sm};
G為人工標注結果,記為G={G1,G2,…,Gn}。
用嚴格的等價關系確定S∩G為S和G的交集。當且僅當一個實體的內容、所屬類別、起始下標和終止下標4 個要素全部一致時,才認為該實體的標注結果是正確的。
3.4 實驗設計與結果分析
3.4.1 模型對比實驗
為驗證基于SoftLexicon 模型在中文電子病歷命名實體識別上的表現,課題組設計了如下對比實驗方案:
1)BiLSTM-CRF 模型。通過訓練語料生成200維的字向量,將待預測字符序列導入BiLSTM-CRF中進行訓練,最終得到序列預測標簽。實驗參數設置同表5。
2)IDCNN-CRF 模型。 基于IDCNN(iterated dilated convolutional neural networks)的特征抽取和CRF 的約束模型。該模型卷積核個數設置為“256,512,512”卷積膨脹率為“1,2,2”,其余實驗參數設置同表5。
3)Lattice-LSTM 模型。在BiLSTM-CRF 基礎上引入外部詞典,為字符向量加入詞特征,并利用門結構引導信息的流動。實驗參數設置同表5。
4)SoftLecicon 模型。在Lattice-LSTM 基礎上通過優化輸入表示層編碼,將字符的4 類詞典集合,結合到字符的表示中。
表6 統計了4 種模型在測試集上的實驗表現。
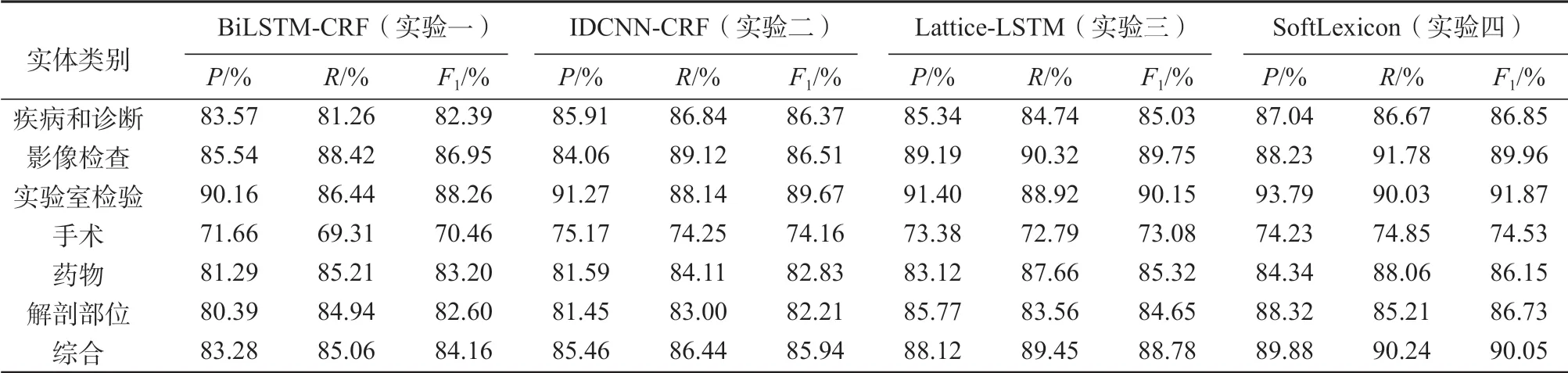
表6 模型對比實驗結果Table 6 Model performance experimental results
通過分析發現,與基于BiLSTM-CRF 模型識別的準確率對比,在引入外部詞典信息后,實驗三、四所用模型在同類別實體上的識別效果表現出色,綜合F1值分別提升了4.62%和5.89%。據分析可能是由于電子病歷中實體的特殊性,單純基于字符向量的BiLSTM-CRF 模型不能準確定位實體的邊界,導致實體識別會出現缺漏、多余的現象,這體現了引入先驗詞典資源的必要性。IDCNN-CRF 模型在引入卷積膨脹因子后,可以獲取到長距離依賴信息,適合處理長本文句子,SoftLexicon 模型在“疾病和診斷”和“手術”類實體識別上與實驗二基本持平甚至有超越。四種模型對“手術”類別實體的識別效果較差,F1值均低于75.00%。分析表2 可知,“手術”類實體總數為1 327 個,數據量不足,導致模型參數訓練效果不佳,且平均實體長度為12.49,易產生邊界預測錯誤的現象。此外,4 種模型均存在不同程度的識別錯誤問題,例如,部分相似度高的實體被錯誤分類、樣本稀疏導致未識別出實體等。
與Lattice-LSTM模型識別效果對比,SoftLexicon 模型在對字符表示層進行調整后,保留了更完整的詞典匹配信息,基于SoftLexicon 的識別模型綜合F1值達到90.05%,相比Lattice-LSTM 的F1值88.78%,有1.27%的提升;同時,SoftLexicon在各類實體識別效果上,P值和R值比較均衡,體現了模型的穩定性。
3.4.2 模型效率對比實驗
為了分析SoftLexicon 模型在引入詞典后對運算效率的影響,本文以4 個模型在同一機器上的運行時間作為對比,結果如表7 所示。
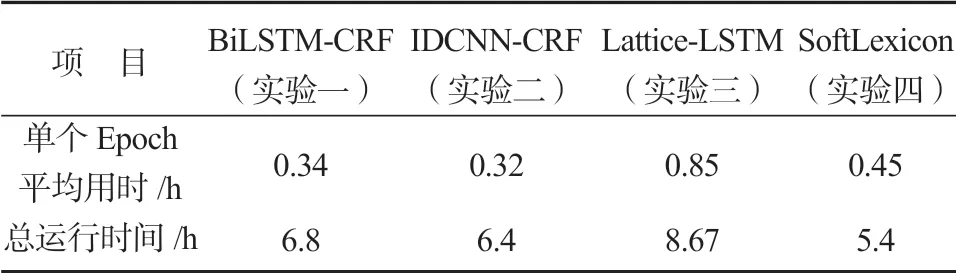
表7 模型效率對比實驗結果Table 7 Model efficiency experimental comparison
實驗效率上,前兩個模型均迭代20 個Epoch,實驗三和實驗四引入詞典的方法,為防止過擬合現象,在運行12 個Epoch 后提前終止了迭代;通過分析表格,實驗四單個Epoch 的平均運行時長約0.45 h,總運行時間為5.4 h,相比實驗三的單個Epoch 所用時長減少0.40 h,總時長縮短約3.2 h。引入外部詞典的NER 方法相比實驗一、二的方法,不可避免地會增加運算量,但SoftLexicon 方法在計算速度上仍有不錯的表現。這可能是由于Lattice-LSTM 在不相鄰的字符之間額外增加了一個詞級別LSTM 通路,對字符組成的詞進行編碼,再輸入到對應字符的Cell中,因此解碼階段需耗費大量運算時間;而SotfLexicon方法是通過簡化詞典使用,只需將整合后的字向量輸入序列建模層,易于實現。
綜上所述,基于SoftLexicon 的方法無論在識別性能還是運行效率上,均有良好的表現,在中文電子病歷命名實體任務上具有可行性。
4 結語
為了解決傳統中文電子病歷NER 方法對字符信息遺漏以及引入外部詞典資源的效率問題,本文提出了一種簡單有效地整合詞典信息到字符表示層中的方法,優化了字符表示層的模型結構,該方法融合了深度學習和基于詞典方法兩者的優勢,將更完整的字符信息輸入到序列建模層中,在中文電子病歷NER評測任務中,取得了不錯的效果。后續工作可從如下3 方面改進:
1)針對中文電子病歷中存在實體類別不均衡的現象,采取過采樣或欠采樣的方法,均衡各類別數量,以提升效果較差的實體識別效果[11];
2)尋找字符信息更簡單且準確的特征表示;
3)BERT、ALBERT 等預訓練語言模型在NLP多個任務中均取得不錯效果,考慮引入合適的預訓練語言模型。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
中華手工(2017年2期)2017-06-06 23:00:31
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
中外會展(2014年4期)2014-11-27 07:46:46
七彩語文·低年級(2011年19期)2011-04-12 00:00:00
海外英語(2006年8期)2006-09-28 08:49:00
