基于BERT 模型的安全生產事故多標簽文本分類
2021-11-03 14:33:46吳德平王曉東
武漢工程大學學報 2021年5期
吳德平,時 翔,王曉東
1. 江蘇安全技術職業學院網絡與信息安全學院,江蘇 徐州221011;2. 常州工學院計算機信息工程學院,江蘇常州213002;3. 徐州市廣聯科技有限公司,江蘇 徐州221116
安全生產管理是一項復雜而極其重要的工作,對安全生產事故全面剖析和研究十分必要。安全生產中的事故傷害可分為事故類別、傷害方式、不安全行為和不安全狀況,利用自然語言處理(natural language processing,NLP)技術對安全生產事故及原因分類,為安全生產監管、事故隱患排查和分析奠定基礎,對進一步強化安全生產指導具有重要意義。
以往文本分類通過利用稀疏詞匯的特征來表示文本,再用線性模型進行分類。近年來,主要是采用深度學習得到文本的特征表示,如利用word2vec 模型學習文本中詞向量的表示,得到文本的語義表示實現文本分類[1]。 又如利用TextRank 算法把文本分割成若干組成單元,構建節點連接圖,用句子之間的相似度作為邊的權重,通過迭代計算句子TextRank 值,抽取排名高的句子組成文本摘要[2]。采用長短時記憶網絡(long short-term memory networks,LSTM)實現分類。
2018 年google 推出的基于轉換器的雙向編碼表 征(bidirectional encoder representation from trandformers,BERT)模 型 在MultiNLI、SQuAD、SST-2 等11 項NLP 任務中取得卓越的效果。BERT 模型在大規模語料庫或特定領域的數據集上通過自監督學習,進行預訓練以獲得通用的語言表示,在下游任務中進行微調完成相應的任務。BERT 模型的缺點之一是使用詞向量表示文本內容時,最大維度為512。當輸入文本長度小于512時,模型性能良好。BERT 是句子級別的語言模型,該模型能獲得整句的單一向量表示。BERT 預訓練模型對輸入文本進行向量化,能有效提高中文文本語義的捕捉效果[3-4]。
安全生產事故報告或案例文本通常都有事故單位的情況、事故發生經過、應急處理情況、事故原因分析、事故責任認定、事故處理意見等內容,文本從幾百字到數萬字不等,內容長短不一,由于BERT 模型支持的最長序列字數為512,需要對原始文本進行處理。本文結合安全生產事故的文本特點,先對文本進行摘要處理,再利用BERT 模型進行多任務分類,實現安全生產事故分類水平的提升。
1 相關工作
1.1 文本摘要方法
文本摘要方法主要為抽取式摘要和生成式摘要,抽取式摘要方法根據單詞和句子的特征從文檔中選擇核心語義句,并將它們組合以生成摘要,句子的重要性取決于句子的特征統計。抽取式摘要最大化地保證摘要內容來自于原文,避免生成不準確甚至是錯誤的信息。抽取式摘要的缺點是抽取對象是文本中的句子,當要抽取的數值確定時,會有正確的摘要句沒被抽取,造成摘要內容的丟失,而被抽取的摘要內容也會有一定的冗余。生成式摘要則使用了一系列自然語言處理技術,用于理解給定文檔中的主要內容,生成更加簡明精煉的句子來構成摘要。生成式摘要與抽取式摘要相比,摘要更準確,更靈活,更符合編寫習慣。結合安全生產事故文本較長的特點以及BERT 模型對算力較高的要求,本文采用抽取式+生產式摘要相結合的方法完成文本的摘要。
1.2 基于BERT 模型的中文長文本處理及分類
對于長文本的處理,一般分為3 種方法:截斷法,Pooling 法,壓縮法。截斷法大致分為頭截斷、尾截斷、頭+尾截斷3 種。截斷的比例參數是一個可以調節的參數。Pooling 法將整段的文本拆分為多個片段,進行多次編碼。壓縮法是在斷句后將整個篇章分割成片段,通過訓練小模型,將無意義的片段剔除,如剪枝法、權重因子分解法、知識蒸餾法等方法。
為提高處理效率,本文采用截斷法,對原始文本首先按照頭+尾截斷,然后去停用詞,進一步精簡文本,最后構建數據集。針對中文長文本摘要和多標簽分類的難點,設計分3 步實現多標簽分類:第一步使用基于BERT 預訓練模型實現抽取式文本摘要;第二步使用基于華為的中文預訓練語言模型——哪吒訓練模型實現生成式文本摘要;第三步通過基于精簡的BERT(a lite bidirectional encoder representation from transformers,AlBERT)訓練模型,借助遷移學習的思想進行多標簽多任務分類,最終在數據集上取得了較好的多標簽分類效果[5-6]。
2 文本摘要模型及實驗
2.1 抽取式文本摘要模型
抽取式文本摘要,生成摘要不連貫、字數難以控制、目標句主旨不明確。而BERT 預訓練模型能在一定程度上克服以上缺點。BERT 模型應用于具體領域的任務是通過使用預訓練和微調實現,預訓練的目的是在輸入的詞中融入上下文的特征,微調的目的是使BERT 適應不同的任務。其創新點在于將注意力模型Transformer 的雙向訓練應用于NLP,經過雙向訓練的語言模型比單一向語言模型能更好地理解語言環境和流程。BERT 中文長文本摘要模型如圖1。
模型中數據集經過分詞并添加一些標識符。在第一個句子前面添加[CLS]標識符,借助首句最前面的特殊符[CLS],用來分類輸入的兩個句子間是否有上下文關系。每個句子的最后添加[SEP]標識符,起到分割句子的作用。整個模型結構通過BERT 接一個平均池化層得到句子向量[7],即通過預訓練獲取一個句子的定長向量表示,將變長的句子編碼成定長向量。Average pooling 主要對整體特征信息進行抽取,local 主要是對特征映射的子區域求平均值,然后滑動這個子區域。模塊間采用average pooling 既能在一定程度上減少維度,更有利于下一級模塊進行特征提取。利用膨脹門卷積神經網絡(dilate gated convolutional neural network,DGCNN),它是基于CNN+ Attention的高效模型。Attention 用于取代池化操作來完成對序列信息的整合。Dense 層將前面提取的特征,經dense 層作非線性變化,再映射到輸出空間。對于圖1 中的句子對,句子的特征值是1,則保留的摘要,句子的特征值是0,則該句舍棄,從而達到文本抽取式摘要的目的。
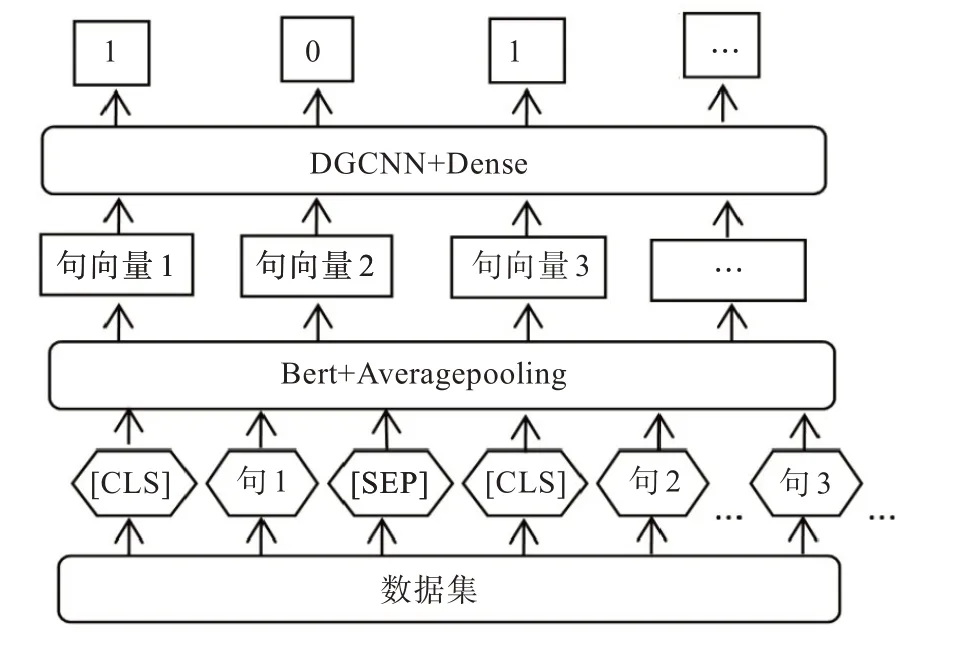
圖1 抽取式文本摘要模型Fig. 1 Extractive summarization model
2.2 生成式文本摘要模型
為了進一步減小文本的長度,通過抽取式模型輸出的摘要,再作為生成式摘要模型的輸入,最終生成輸出得摘要。 生成式摘要通過改進型BERT 來實現,模型如圖2 所示。BERT 使用的是訓練出來的絕對位置編碼,有長度限制,為便于處理長文本,采用基于華為的NEZHA 預訓練語言模型,利用改模型相對位置編碼,通過對位置差做截斷,使得待處理詞、句相對位置在有限范圍內,這樣,輸入序列的長度不再受限,處理后的語句再通過生產式指針網絡(pointer generator networks,PGN)模型生產摘要。 PGN 模型[8]可視為基于attention 機制的seq2seq 模型和pointer network 的結合體,該模型既能從給定詞匯表中生成新token,又能從原輸入序列中拷貝舊token,其框架如圖2 所示。圖2 中原文本中各token 的Wi經過單層雙向LSTM 將依次得到編碼器隱藏狀態序列,各隱藏層狀態表示為Ht。對于每一個時間步長t,解碼器根據上一個預測得到單詞的embeding,經LSTM 得到解碼器隱藏層狀態St,為了在輸出中可以復制序列中的token,將根據Ht,St和解碼器輸入Xt計算生成概率:
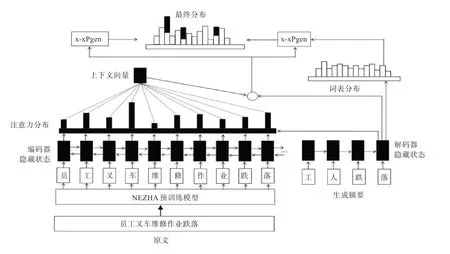
圖2 生產式文本摘要模型Fig. 2 Abstractive summarization model
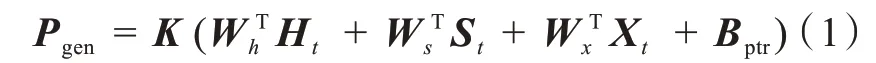
式(1)中,WTh、WTs、WTx、Bptr均為 模型要 學習的 參數。Pgen的作用是判斷生成的單詞是來自于根據Pvocab在輸出序列的詞典中采樣,還是來自根據注意力權重ai,t在輸入序列的token 中的采樣,最終token 分布表示如式(2):
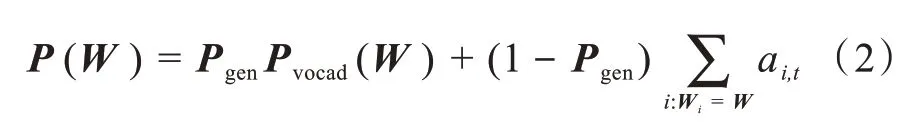
其中i:Wi=W表示輸入序列中的token 的W,模型會將在輸入序列中多次出現的W的注意力分布相加。當W未在輸出序列詞典中出現時,Pvocab(W)=0;而當W未出現在輸入序列中時,

顯然,該模型基于上下文向量,解碼器輸入及解碼器隱藏層狀態來計算生成詞的概率p,對應Copy 詞的概率為1-p,根據概率綜合編碼器注意力和解碼器輸出分布得到一個綜合的基于input 和output的token 分布,從而確定生成的語句。
2.3 文本摘要實驗及討論
實驗對2 000 個20 種事故類別的案例集進行處理,采用基于召回率的摘要評價(recalloriented understudy for gisting evaluation,ROUGE)作為評價指標,以衡量生成的摘要與參考摘要之間的“相似度”,采用ROUGE-1、ROUGE-2和ROUGE-L作為標準,即計算一元詞、兩元詞及最長公共子序列的重疊程度。本文提出的模型在訓練集上得到ROUGE 評價結果如表1 所示,同時還給出了其他模型的ROUGE 結果[9-11]。
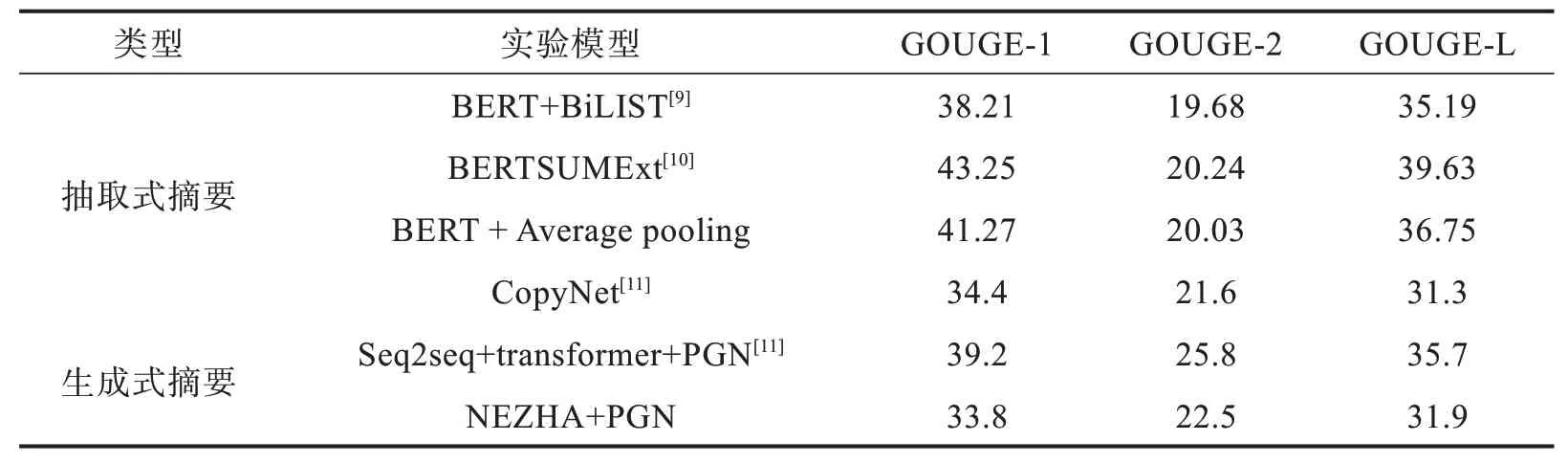
表1 不同模型實驗結果對比Tab. 1 Comparison of experimental results of different models %
第一個抽取式模型BERT+BiLIST 是將BERT預處理后的文本向量經過一個基于規則的基本篇章單元識別模型,再經過基于Transformer 的神經網絡抽取模型,生成最終的摘要。第二個抽取式模型BERTSUMExt,將多層Transformer 應用于句子表示,從輸出中抽取文檔特征,再經LSTM 層學習特定摘要特征。本文抽取式中文摘要采用的NER 模型式chinese_L-12- H-768_A-12 預訓練模型,通過BERT + Average pooling 計算文本向量表示,最后通過CNN+ Attention 的模型抽取摘要。
第一個生產式摘要模型CopyNet 通過深度遞歸生成解碼器的Seq2seq 模型,利用遞歸學習目標摘要中隱含信息來提高摘要質量。第二個生產式摘要模型Seq2seq +transformer+PGN 采用基于自注意力的transformer 機制,組合指針生成網絡input-feeding 方法。本文生成式中文摘要采用華為的NEZHA 預訓練語言模型,經過基于attention機制的Seq2seq 模型生產摘要。
實驗數據如表1 所示,本文提出的模型較其他模型相比,最終結果相差不大,一方面,其他模型的評價結果當前已達到很高水平[12],另一方面,采用的數據集存在的差異,包括中文和英文差異,也存在不同領域之間的差異。同時,考慮到算力等因素,本實驗采用的兩個模型能夠提取文本的關鍵信息,為長文本進行多標簽分類提供可能。
3 文本多標簽分類及實驗
多標簽分類就是要將安全生產的事故案例標記為物體打擊、車輛傷害等20 類事故類別之一;碰撞、爆炸等15 種傷害方式之一;防護、保險等裝置缺乏或缺陷等4 大類不安全狀態之一;操作失誤等13 大類不安全行為之一,共有52 個標簽。
3.1 分類模型
多標簽文本分類ALBERT 預訓練模型,該模型最小的參數只有十幾兆字節,能較好解決模型參數量大、訓練時間過長的問題,效果比BERT 低1%~2%。同時,在沒有足夠的安全生產類標注數據的情況下,采用遷移學習來提高預訓練的效果。本文采用基于樣本的遷移學習方法,模型如圖3 所示。模型主要通過自制的安全生產事故數據集對模型進行預訓練,建立分類精度較高、特征提取能力強的學習模型。TextCNN 模型能有效抓取文本的局部特征,經過不同的卷積核提取文本信息,再通過最大池化來突出各個卷積操作,從而提取特征信息,拼接后利用全連接層對特征信息進行組合,最后通過binary crossentropy 損失函數來訓練模型,將標量數字轉換到[0,1]之間,再對52 個標量分組分類。
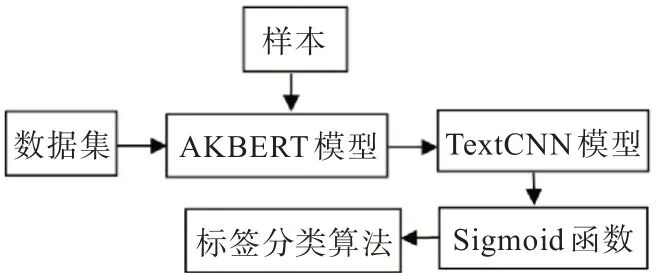
圖3 多標簽文本分類模型Fig. 3 Multi-label text classification model
3.2 分組分類算法及實驗
當前多標簽的學習算法[13-15],按解決問題的方式可以分為基于問題轉化法和基于算法適用法兩類。問題轉化法通常只考慮標簽的關聯性。而考慮多標簽的相關性時可將上一個輸出的標簽當成下一個標簽分類器的輸入。對于事故類別、傷害方式等52 個標簽,若采用類似于二分類方法,所有標簽將分布在[0,252-1]空間內,數據會很稀疏,耗費大量資源。因此,采用基于算法適用法來實現多標簽分類算法。設置TextCNN 參數字長為300,卷積核數目為256,卷積核尺寸為5,標簽為52。再利用tf.argmax()對模型訓練獲得的52 個標量,求得4 組列表[0,19:1]、[20,34:1]、[35,38:1]、[39,51:1]中最大數的索引,最后映射到相應標簽即可,分類結果如表2所示。可以看出,同一事故類別的標簽數越多,分類的準確率越低。另外,考慮算力的因素,本文安全生產事故文本數據集數量上相對偏少,也導致分類準確率不夠高。
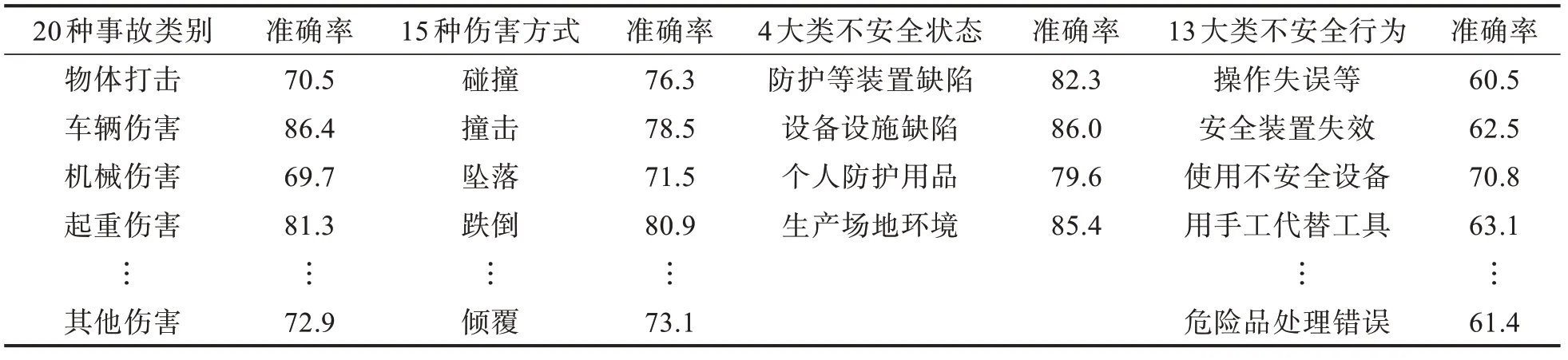
表2 多標簽分類準確率Tab. 2 Multi-label classification accuracy %
4 結 論
目前,雖然在一定程度上實現了安全類中文長文本的多標簽分類,但數據集的構建需要做大量的工作,事故傷害類別多,成因復雜,要做好安全生產傷害事故及原因的文本分類,還面臨不少挑戰。數據是研究的基石,只要進一步完善大規模、高質量的數據集,優化各種模型及參數,就能進一步提升文本分類準確性。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
小學科學(學生版)(2020年10期)2020-10-28 07:52:12
中國化肥信息(2020年7期)2020-03-19 01:54:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
中國軍轉民(2017年6期)2018-01-31 02:22:28
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
小學教學參考(2015年20期)2016-01-15 08:44:38
