基于改進免疫遺傳算法的近紅外光譜變量選擇方法
2021-11-03 09:21:20陶煥明高美鳳
分析測試學報 2021年10期
陶煥明,高美鳳
(江南大學 輕工過程先進控制教育部重點實驗室,物聯網工程學院,江蘇 無錫 214122)
近紅外光譜分析檢測技術具有快速、無損以及低成本的優勢,已經廣泛運用于眾多領域。如何快速有效地提取出有用光譜信息,即光譜變量選擇,是近紅外光譜技術研究的重點之一。目前,許多國內外學者提出了大量基于不同原理、策略的變量選擇方法,如通過無信息變量消除法(UVE)對偏最小二乘(PLS)回歸系數設定閾值限制來選擇有效變量[1];區間偏最小二乘(iPLS)[2]、移動窗口偏最小二乘(MWPLS)[3]、向前和向后間隔偏最小二乘(FB-iPLS)[4]、區間隨機蛙跳(iRF)[5]等則均為以光譜區間為篩選對象的方法。近年來,以智能算法及其改進算法為核心進行波長組合優化的算法研究較多,主要有遺傳算法(GA)[6-8]、粒子群算法(PSO)[9]、模擬退火算法(SAA)[10]、蟻群算法(ACO)[11]等。GA算法具有群體搜索特性,廣泛應用于多種領域,但易過早收斂。劉鑫等[12]將改進的GA 算法用于土壤養分預測,采用一種改進的實數編碼差分變異算子,擴大了全局最優解搜索空間,加快了收斂速度,提高了預測精度。免疫遺傳算法(IGA)在GA 算法的基礎上引入了生物免疫機制,本質也是對GA 算法的一種改進[13-15]。相較于GA算法及其改進算法,IGA算法避免了容易過早收斂的缺點,維持了種群中個體的多樣性,可有效防止算法陷入局部最優,但其精度性能仍存在提升空間。國內外對IGA 算法的研究也從未停止腳步[16-17]。
本文提出了一種改進免疫遺傳算法(iIGA)用于近紅外光譜變量選擇。IGA 算法結合了適應度(親和度)和抗體濃度形成聚合適應度進行后續的遺傳操作來維持種群的多樣性以及免疫平衡,抗體濃度越高,越受抑制,反之亦然。其中抗體濃度是指與抗體相似的個體總數和群體總數的比值,其中抗體之間相似度達到相應的閾值判定抗體相似。原算法中固定了抗體相似度閾值,可能會存在閾值過大或者過小而導致抗體濃度不具備差異性,使得引入的抗體濃度失去意義。本文提出自適應相似度閾值,所選取的閾值可使群體抗體濃度的標準差達到最大,完全體現出抗體濃度的差異性;同時采用精英保留策略,將親和度高的若干個抗體存入到記憶細胞中,直接復制到下一代;另外在算法中引入貪心算法思想,將算法由局部最優擴展到全局最優。將每一次迭代中的親和度最優基因隨機反轉一位基因位進行局部性探優,并且保證探優之后的基因親和度值大于探優之前;然后以探優成功后的基因替換本次迭代中親和度最差基因,使得算法朝著正確的方向進行局部性探優,最終達到全局最優,提升模型預測精度。
1 算法原理
1.1 IGA算法實現原理
GA算法中通過模擬種群個體對環境適應度大小的不同進行優勝劣汰,經過不斷的迭代更新,使種群個體對環境的適應度不斷提升,最終達到群體適應度的最佳表現。但在算法迭代后期,種群個體之間的差異性越來越小,導致算法陷入局部最優。因此,免疫遺傳算法在個體對環境的適應度中引入抗體濃度,促使抗體濃度越高,適應度反遭抑制,維持了種群中個體的多樣性,可有效防止算法陷入局部最優。
1.1.1 產生初始解 在種群中設置N個個體,作為算法模型的抗體角色。將需篩選的近紅外光譜波段均分為L個波段,每個波段包括多個波長點,對應抗體基因上的基因位,按照0-1 形式對其進行隨機編碼,1表示選中該波段,0表示未選中。
1.1.2 計算親和度 對抗體基因進行編碼后,將選中的波段與對應的理化值進行PLS建模,親和度即以建模得到的校正集均方根誤差(RMSEC)和相關系數(R)為變量的函數值,本文設定親和度Z為:

1.1.3 計算抗體濃度 抗體濃度用與抗體i相似的抗體個數ci與群體總個數N的比值di來表示,即:

抗體之間相似度達到一定閾值,即判定抗體相似。相似度是抗體與其他抗體之間的相似程度,其度量方法可基于信息熵、歐氏距離、基因值距離以及海明距離。其中海明距離主要用于計算離散編碼,符合本文的0-1編碼形式。因此本文采用海明距離作為抗體相似度的度量方法,具體公式如下:


式(5)表示抗體pi和pj的相似度,L為抗體基因編碼長度;式(4)中分別表示第i個抗體基因上的第k位基因位和第j個抗體基因上的第k位基因位。
1.1.4 計算聚合適應度 將親和度和抗體濃度融合成聚合適應度。在種群更新的過程中,抗體被選擇的概率與聚合適應度成正比。因此,聚合適應度也反映了親和度與抗體濃度在種群更新中的影響力。親和度越高的個體,聚合適應度也越高;抗體濃度越高的個體應被抑制,以保證種群的多樣性,因此聚合適應度越低。本文設定的聚合適應度PZ為:

式中λ、μ為某一常數,分別反映了親和度和抗體濃度期望被選擇到下一代的相對重要的參數。
1.1.5 遺傳操作 通過輪盤賭選擇法進行基因的復制。在輪盤賭中,種群中個體被選擇的概率與對應的聚合適應度成正比,即聚合適應度越高的個體被選擇的概率越大,反之,聚合適應度越低的個體被選擇的概率越小。第i個個體被選擇的概率Pi可表示為:

式中,PZi和PZj分別為第i個個體和第j個個體所對應的聚合適應度,n為種群大小。通過單點交叉對種群個體進行交叉處理。設定交叉概率為pc,單點交叉操作即交換兩個個體的部分基因值。最后設定變異概率pm,對于0-1基因鏈碼,隨機挑選c個基因位,以變異概率pm對這些基因位上的值取反,即0變1,1變0。
1.1.6 更新迭代 迭代次數達到K時,選取種群中最優個體作為最終候選個體,其對應的波段作為最終篩選波段。
1.2 iIGA算法
1.2.1 自適應相似度閾值 原算法中固定了抗體相似度閾值,而每次更新迭代,抗體相似度都會發生變化,這可能會導致閾值過大或者過小而使抗體濃度不具備差異性,使得引入的抗體濃度失去意義。本文提出自適應相似度閾值,將相似度閾值以一定的間隔從群體相似度最小值遍歷至群體相似度最大值,所選取的相似度閾值使得群體抗體濃度的標準差達到最大,可完全體現出抗體濃度的差異性。
1.2.2 精英保留策略 在種群中另外設置M個個體,作為算法模型中的記憶細胞角色,并對其基因進行0-1 隨機編碼,同時計算其親和度。由于種群的選擇具有不確定性,可能造成最優個體的丟失。因此將親和度最高的M個個體,作為記憶細胞儲存起來,直接以概率1 復制到下一代種群中。在每一次迭代中,將當前代數中親和度最高的M個個體,存入到記憶細胞中以進行記憶細胞更新。
1.2.3 引入貪心算法思想 貪心算法在求最優解時,不必考慮整體最優,而是尋找在某種意義上僅是局部最優的解,用局部最優構造全局最優,一步一步逼近全局最優解。在算法的每一次更新迭代中,對親和度最優個體基因進行局部性探優,即隨機取反一個基因位并且保證探優之后的親和度大于原先個體的親和度,如果小于,則恢復被改變的基因位,再隨機重取一個基因位進行探優,直到探優之后該個體的親和度大于探優前個體的親和度。如果重取次數達到上限值,則將原先最優個體直接替換最差個體。
1.3 iIGA算法實現步驟
Step1:初始化種群。在種群中設置N個個體,作為抗體角色。將光譜波段均分并進行0-1 隨機編碼。
Step2:計算親和度。對抗體基因進行編碼后,將選中的波段與對應的理化值進行PLS 建模,并利用式(1)計算親和度。
Step3:初始化記憶細胞。在種群中設置M個個體,作為算法模型的記憶細胞角色,并對其基因進行0-1隨機編碼,同時計算親和度。
Step4:計算抗體相似度。采用海明距離作為抗體相似度的度量方法,公式如式(3)~(5)所示。
Step5:自適應相似度閾值計算抗體濃度。采用自適應相似度閾值對抗體進行相似判定,將群體抗體濃度標準差達到最大時,即抗體濃度差異性最大時的閾值作為最終自適應相似度閾值。抗體濃度由式(2)計算。
Step6:計算聚合適應度。如式(6)所示,將親和度和抗體濃度融合成聚合適應度。
Step7:引入貪心算法思想。對每一次迭代中親和度最優的個體基因進行局部性探優,即隨機取反一個基因位并保證探優之后的親和度大于原先的個體。
Step8:更新記憶細胞。重新計算群體中個體的親和度,選取最高的M個個體作為記憶細胞儲存起來,直接以概率為1復制到下一代種群中。
Step9:進行遺傳操作。通過輪盤賭選擇法進行基因的復制。在輪盤賭中,個體被選擇的概率如式(7)所示。然后通過單點交叉、變異對種群個體進行處理。
Step10:更新迭代。迭代次數達K時,選取種群中最優個體作為最終候選個體,其對應的波段作為最終篩選波段。
2 實驗部分
2.1 實驗數據
2.1.1 數據來源 本研究引用于eigenvector 網站上開源的一組標準玉米近紅外光譜數據集。該數據集由80 個玉米樣品組成,分別用m5spec、mp5spec、mp6spec 3 種不同的近紅外光譜儀進行測試,包含了其淀粉、蛋白質、水分以及油脂含量。以間隔為2 nm在1 100~2 498 nm波長范圍上收集(700 波長點)。本文選用mp5spec 儀器掃描得到的光譜數據,并選擇其中的淀粉和蛋白質含量進行研究。
2.1.2 樣本劃分 圖1 為原始光譜圖,數據集由80 個玉米樣品光譜組成。
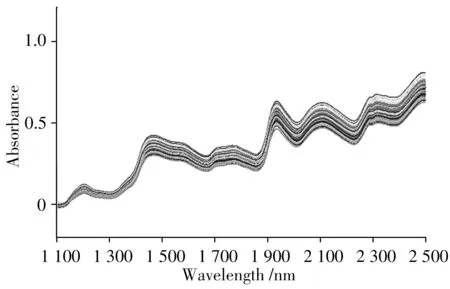
圖1 原始光譜圖Fig.1 Original spectrogram
采用Kennard-Stone(KS)方法將80個樣本分成校正集和預測集。劃分結果為校正集樣本52個,預測集樣本28 個。校正集和預測集的淀粉和蛋白質含量值統計見表1。由表1 可知,校正集樣本與預測集樣本的平均值(Avg)和標準差(Std)相差不大,通過KS 方法劃分的數據集,保證了校正集樣本均勻分布。

表1 校正集和預測集中淀粉和蛋白質含量值統計Table 1 Statistics of starch and protein content in correction set and prediction set(g/100g)
2.2 實驗設備
本研究使用的是一臺戴爾計算機,處理器是Intel(R)Core i5-9400,CPU 主頻為2.90 GHz,Windows10、64位操作系統,顯卡為GT710,所有計算均在MATLAB 2016a中進行。
2.3 實驗方法
為了考察本文提出的iIGA 算法對建模預測的效果,驗證該算法的有效性和優越性,分別用全譜波長、GA、IGA 以及iIGA 算法對數據集中玉米淀粉和蛋白質含量的建模效果進行了對比。由于原始光譜波長點數較多,如對波長點進行優選組合,運算效率將會非常低,因此將原光譜均分為若干個子區間,分別用上述算法進化迭代,獲取最大適應度值所對應的優選子區間組合。根據基因優選的波段建立PLS 模型,計算出模型的相關系數(R)和預測集均方根誤差(RMSEP),適應度函數F為:

將原光譜在1 100~2 498 nm 范圍之間的700 個波長點數劃分為175 個等距區間,即遺傳編碼長度為175,每一個基因位包含4個波長點數。設定群體個數為50個,交叉概率為0.85,變異概率為0.05,最大迭代數為100代。在種群進化過程中尋找最大迭代次數內進化過程的最優適應度個體。
對于iIGA 算法,通過實驗選取的最佳記憶細胞數目為8 個。相似度閾值從抗體相似度最小值遍歷至抗體相似度最大值,遍歷跨度設置為0.001,當所選取的相似度閾值使得群體抗體濃度的標準差達到最大時,即為最終的相似度閾值。經過多次實驗測試,設定聚合適應度最佳參數λ為0.7,μ為1.25。設定貪心尋優時的重取次數上限為20 次。由于上述算法存在隨機性,因此將以上3種算法分別運行50次求平均。程序地址為https://github. com/thmguai/Journal_of_analytical_testing_thm.git。
3 結果與討論
3.1 算法優化結果
3.1.1 自適應相似度閾值 相似度閾值從群體相似度最小值遍歷至群體相似度最大值。如圖2 所示,以玉米淀粉含量數據集為例,每取一個閾值,都會有與之一一對應的群體抗體濃度標準差(STD),當所選取的閾值使得標準差達到最大值時,表示群體抗體濃度差異性達到最大,可使IGA算法中提出的保留物種多樣性思想(引入抗體濃度)最大化。
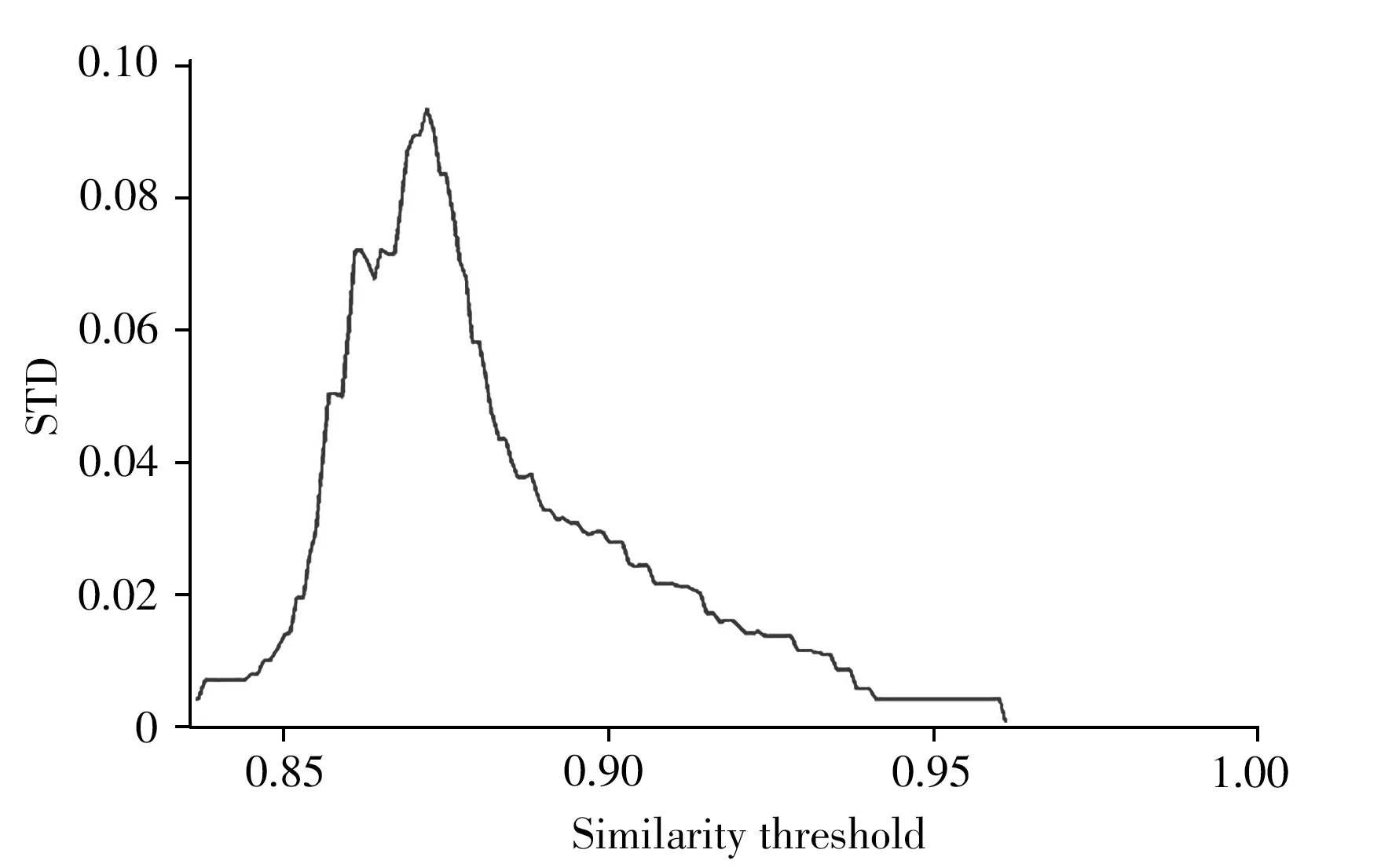
圖2 群體抗體濃度標準差隨抗體相似度閾值的變化Fig.2 Variation of antibody concentration STD with the threshold of antibody similarity
3.1.2 精英保留策略 將親和度最高的8 個個體作為記憶細胞儲存起來,直接以概率為1 復制到下一代種群中。如圖3 所示,以玉米淀粉含量數據集為例,記憶細胞中儲存的精英群體的親和度均值遠高于總群體,并且隨著迭代次數逐漸提升,可防止某些最優個體的丟失,使種群朝著正確的方向進行更新,有效地避免了陷入局部最優。
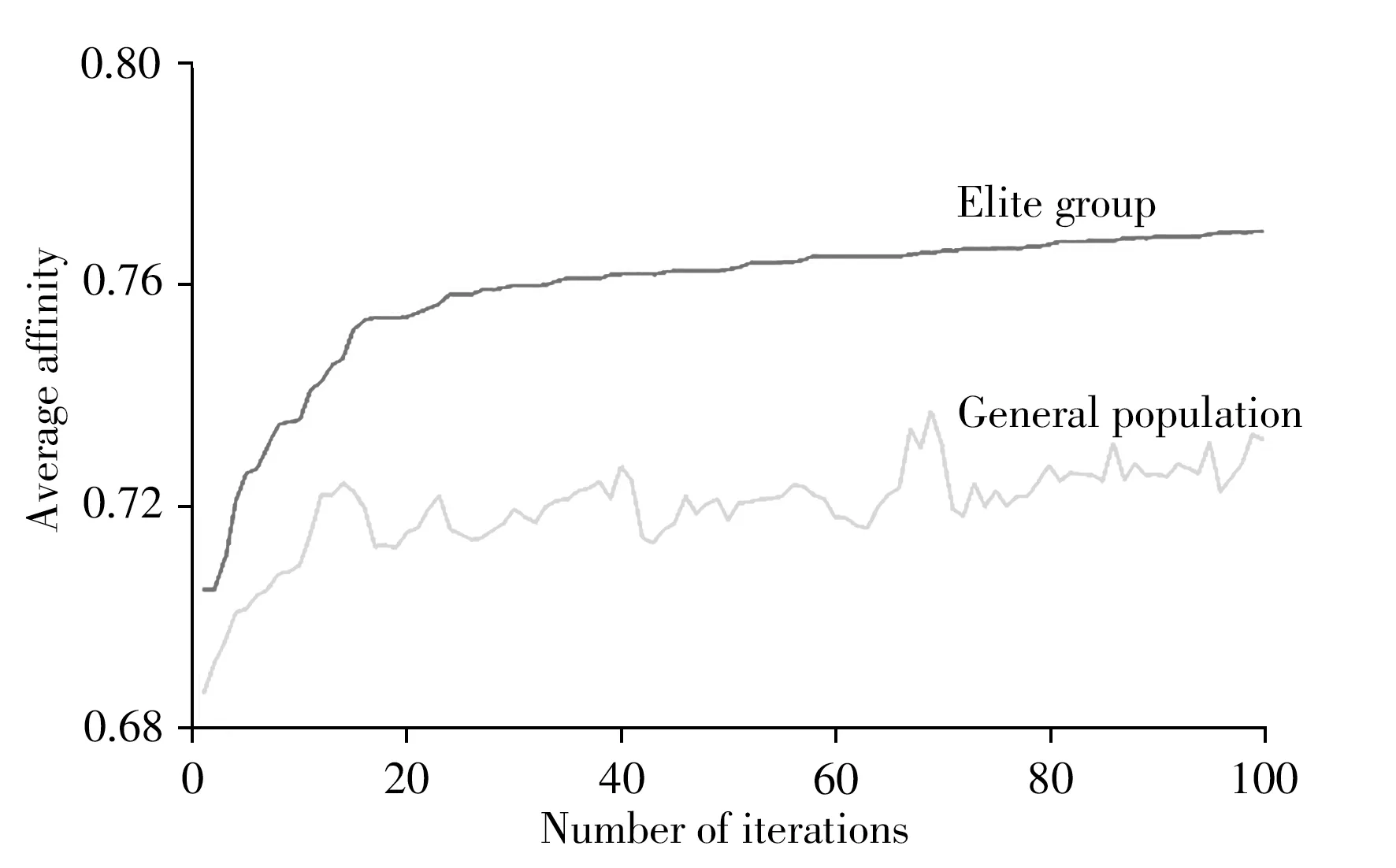
圖3 精英群體和總群體的抗體親和度均值隨迭代次數的變化圖Fig.3 Variation of the mean antibody affinity of elite group and general population with the number of iterations
3.1.3 貪心算法思想 在算法的每一次迭代中,對抗體親和度最優個體進行局部性探優,以局部最優逐漸構建出全局最優。如圖4 所示,以玉米淀粉含量數據集為例,在對親和度最優抗體進行局部尋優后,群體中最優個體較之前幾乎都有了提升,突破了局部探優之前的最優領域,避免了過早陷入局部領域最優,使算法朝著通往全局最優的較合理的路徑進行更新迭代。
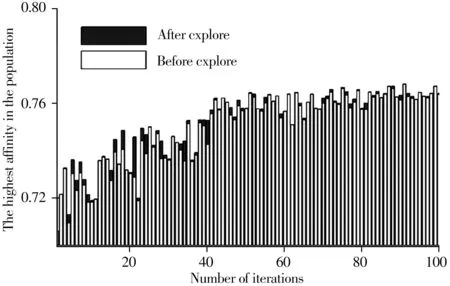
圖4 局部探優前后群體中最優抗體的親和度隨迭代次數的變化圖Fig.4 Variation of the affinity of the optimal antibody with the number of iterations before and after local optimization
3.2 結果比較
iIGA 算法合理地優化了算法的性能,同時增強了算法全局尋優能力。圖5 為用GA、IGA 以及iIGA算法篩選之后的變量分別與淀粉和蛋白質含量測試50次進行建模分析的預測均方根誤差值。
由圖5 可知,用iIGA 算法進行建模,預測玉米淀粉和蛋白質含量的精度較IGA 算法有著明顯的提升,證明了該算法較原算法提升了性能,增強了全局尋優能力。表2和表3分別為各算法測試淀粉含量和蛋白質含量的各項性能數據。
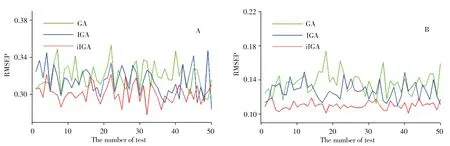
圖5 GA、IGA以及iIGA算法運行50次的淀粉預測RMSEP值(A)和蛋白質預測RMSEP值(B)Fig.5 Starch predicted RMSEP value(A)and protein predicted RMSEP value(B)after GA,IGA and iIGA run 50 times

表2 不同變量篩選算法對玉米淀粉含量的預測結果Table 2 Prediction results of corn starch content by different variable screening methods

表3 不同變量篩選算法對玉米蛋白質含量的預測結果Table 3 Prediction results of corn protein content by different variable screening methods
從表2可得,在玉米淀粉含量的預測上,相比于全譜PLS(F-PLS),GA 算法模型的校正集均方根誤差RMSEC從0.335 7降到0.272 9,校正集預測精度提升18.7%。模型的預測集均方根誤差RMSEP從0.391 4 下降到0.319 3,預測集預測精度提升18.4%。而IGA 算法作為GA 的改進算法,預測精度有所提升。IGA 算法的RMSEC 為0.267 3,RMSEP 為0.312 0,預測精度分別較GA 算法提升了2.0%和2.3%。本文提出的iIGA 算法相較于IGA 算法,預測速度有所降低,但校正集相關系數Rc從0.941 3 提升至0.950 9,預測集相關系數Rp從0.920 4提升至0.927 7,RMSEC從0.267 3降到0.244 9,校正集預測精度提升8.4%;RMSEP 從0.312 0降到0.298 0,預測集預測精度提升4.5%。對IGA-PLS和iIGAPLS兩組分別測試50次的RMSEP值進行顯著性檢驗,F值為165.22,P值為9.5×10-23,P值小于0.05,因此兩組數據存在顯著性差別。由表2 數據分析可得,在淀粉含量光譜數據集中,iIGA 算法相較于原算法預測精度有了明顯的提升。
從表3 可得,在玉米蛋白質含量的預測上,相比于全譜PLS,GA 算法模型的校正集均方根誤差RMSEC 從0.147 4 降到0.116 0,校正集預測精度提升21.3%。模型的預測集均方根誤差RMSEP 從0.178 9 下降到0.136 8,預測集預測精度提升23.5%。而IGA 算法的RMSEC 為0.112 4,RMSEP 為0.124 4,預測精度分別較GA 算法提升了3.1%和9.1%。本文提出的iIGA 算法相較于IGA 算法,預測速度有所降低,但校正集相關系數Rc從0.972 2 提升至0.976 4,預測集相關系數Rp從0.966 9 提升至0.974 2,RMSEC 從0.112 4降至0.103 7,校正集預測精度提升7.7%,RMSEP 從0.124 4降至0.110 3,預測集預測精度提升11.3%。同樣對IGA-PLS 和iIGA-PLS 兩組分別測試50 次的RMSEP 值進行顯著性檢驗,F值為182.05,P值為4.5×10-24,P值小于0.05,因此兩組數據存在顯著性差別。由表3數據分析可得,iIGA算法應用在蛋白質含量光譜數據集中相較于原算法預測精度有了明顯的提升。
4 結 論
提出了一種近紅外光譜波長變量選擇算法,即改進的免疫遺傳算法,對原算法進行了3 個方面的改進優化,分別是自適應相似度閾值、引入精英保留策略和貪心算法思想。采用該算法進行波長選擇后,建立了更加穩健、預測精度更高的PLS 模型。在對玉米光譜數據集中淀粉和蛋白質含量的預測建模中,模型的預測均方根誤差RMSEP 分別為0.298 0和0.110 3,相比原算法,模型的預測精度分別提高了4.5%和11.3%,證實了iIGA 算法的優越性。在要求預測精度的場景下,本文提出的改進IGA波長變量選擇算法是一個更佳的選擇。
