基于高光譜的黑色簽字筆墨水種類鑒別方法研究
2021-11-03 09:21:24王書越楊玉柱何偉文李潤康
分析測試學報 2021年10期
王書越,楊玉柱,何偉文,李潤康
(中國人民公安大學 偵查學院,北京 100038)
近年來,簽字筆以其書寫流暢、供墨穩定、顏色持久等優勢受到人們的青睞,逐漸取代了圓珠筆和鋼筆在市場上的主導地位。簽字筆可根據墨水成分分為水性筆、油性筆和中性筆,其中,中性筆使用最為廣泛。簽字筆墨跡是文件、證件、支票等造假案件中的重要證據。法庭科學家們通過分析可疑筆跡的墨水種類,可以了解一些書寫行為并推斷書寫工具是否具有同一性[1-2]。因此,設計一種快速、準確的方法鑒別簽字筆墨水種類對解決涉及筆跡檢驗的經濟案件或民事糾紛具有重要的理論和實際意義。
墨水種類的鑒定方法可以分為有損檢驗和無損檢驗。薄層色譜法[3-4]、高效液相色譜法[5]等通過對墨水著色劑成分的分離實現墨水的種類鑒定,但此類方法破壞了樣本的原始性,且耗費大量的時間。紫外-可見光譜法[6]、顯微分光光度法[7]、傅里葉變換紅外光譜法[8]、拉曼光譜法[9-10]和近紅外光譜法[11]等可進行快速、靈敏、無損分析,使墨水的種類鑒定不僅基于著色劑的組成,而且基于添加劑和元素含量的差異。高光譜成像技術(Hyperspectral imaging,HSI)是一種較新的法庭科學分析工具,具有多波段、波長范圍寬、非接觸、圖譜合一等特點,最大限度地減少了試劑消耗和樣本制備過程。利用高光譜相機可以同時獲得待測物的空間和光譜信息,形成一個圖像數據立方體[12]。由于物體反射光譜的唯一性,因此可以區分化學成分相似的墨水之間光譜的細微差異。Reed 等[13]利用HSI鑒別了白色辦公紙上不同品牌型號的藍色、紅色和黑色中性筆墨水,Devassy等[14]在中性筆墨水高光譜數據分析中比較了主成分分析和t-隨機鄰近嵌入算法降維的效果并進行了評價。
盡管高光譜成像技術在墨水種類鑒別方面具有優勢,但黑色簽字筆墨水成分基本相同,數據差異小,難以通過觀察進行區分。因此本實驗基于常見黑色簽字筆墨水的高光譜數據,借助機器學習算法建立了線性判別分析模型(Linear discriminant analysis,LDA)和隨機子空間-線性判別分析集成模型(Random subspace method-linear discriminant analysis,RSM-LDA),實現了高光譜數據的深度挖掘和黑色簽字筆墨水種類的準確分類。
1 實驗部分
1.1 儀器與實驗材料
采用深圳中達瑞和科技有限公司SEC-E1100凝視型高光譜成像儀,光譜范圍為450~950 nm,掃描精度為1 nm,采樣間隔通道為10 nm,照明光源為4 盞50 W 鹵素燈(左、右軸各2 盞),照明角度為45°,工作溫度為32.9 ℃,曝光時間為標定光源參數。
實驗材料為我國市場上常見的黑色簽字筆,共15 個品牌36 個型號。將收集到的36 支黑色簽字筆依次編號,在同一規格的白色A4 打印紙上依次書寫“1 號”至“36 號”字樣,每支筆重復書寫3 次,制備過程中避免污染。
1.2 光譜采集與校正
采集時將書寫材料放置于專用平臺中央,調焦清晰后采集高光譜圖像。為消除由光源強度分布不均帶來的噪音,對高光譜設備記錄的所有圖像進行黑白校正。白板標定圖像(W)是由制造商提供的標準聚四氟乙烯白瓷磚得到的圖像,黑板標定圖像(D)為關閉光源并合上鏡頭蓋后采集的圖像,每個樣本的校正圖像(I)通過方程(1)從原始光譜圖像(Isample)中獲得。

1.3 數據提取與預處理
使用ENVI 5.3 軟件讀取校正后的高光譜圖像信息,為確保所選特征點均勻、不重復且具有代表性,對每支黑色簽字筆的3 份平行高光譜圖像分別手動選取6 個含50 個像元的感興趣區域(Region of interest,ROI),即每支黑色簽字筆高光譜圖像可提取18個ROI,得到相應的平均光譜值。最終,從36支黑色簽字筆筆跡的高光譜圖像中共提取到648個原始平均光譜值,作為樣本集。
在采集過程中,由于書寫材料背景和雜散光等的影響,會產生其他無關信息和噪音,直接建模時將影響建模效果[15]。因此,光譜預處理采用Savitzky-Golay 平滑(S-G 平滑)、Z-Score 標準化和兩者組合的預處理方法。S-G 平滑是最常用的去噪聲方法,其實質是一種加權平均法。本實驗采用7 點S-G平滑,以窗口內中心波長點k及前后w點處的測量值按照(2)式計算所得的平均值-xk代替波長點的測量值,自左至右依次移動k,完成對所有點的平滑。

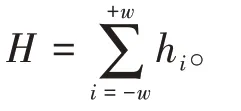
此外,不同樣品在同一儀器參數下得到的高光譜相對強度差異較大,為使數據指標之間具有可比性,旨在消除數據量綱影響的標準化對模型的建立至關重要。Z-Score標準化為常用方法,其公式為:

式中,x~ 為標準化后的觀測值,x為某一觀測值,xˉ為所有觀測值的平均值,σ為所有觀測值的標準差。
數據預處理和建模分析軟件使用Matlab 2019a。
1.4 模型建立
線性判別分析(LDA)是一種泛化性能良好且應用廣泛的分類模型,其原理是將高維的樣本投影到某個空間,使訓練樣本在新空間具有最大的類間距離和最小的類內距離[16],而在測試階段,該模型可將新樣本識別為新空間下最近類中心的一類[17-18]。在多分類問題中,為了得到新空間的投影向量,一般定義類間散度矩陣為:

式中,L為類別數,Pi為第i類別的先驗概率,mi為第i類別的均值,m為整個樣本集的均值。
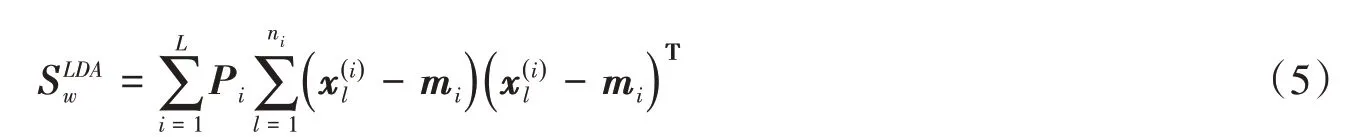
式中,ni為第i類別的樣本個數,為第i類別的第l樣本。線性判別函數即最佳投影向量e可以表示為:

這相當于找到下列廣義特征值問題的最大特征值λ:

在找到最佳投影向量后,將投影后的新樣本分配到距離最小的類別。本實驗最終得到35個判別函數,其中方差貢獻度最大的為第一判別函數,如下:y= 0.08x1-0.04x2+ 0.27x3+ 0.15x4-0.31x5-0.09x6+ 0.11x7+ 0.10x8+ 0.06x9-0.09x10-0.17x11-0.01x12+ 0.20x13-0.14x14+ 0.13x15+ 0.18x16-0.32x17+0.22x18-0.05x19-0.20x20-0.04x21+0.17x22+0.12x23+0.14x24-0.16x25-0.27x26-0.03x27+0.01x28-0.11x29+0.12x30-0.09x31+0.26x32-0.15x33+0.09x34+0.10x36-0.01x37+0.03x38+0.11x39+0.02x40+0.01x41+0.01x42-0.21x43+0.01x44+0.03x45+0.06x46+0.15x47-0.03x48-0.09x49-0.12x50+0.07x51。
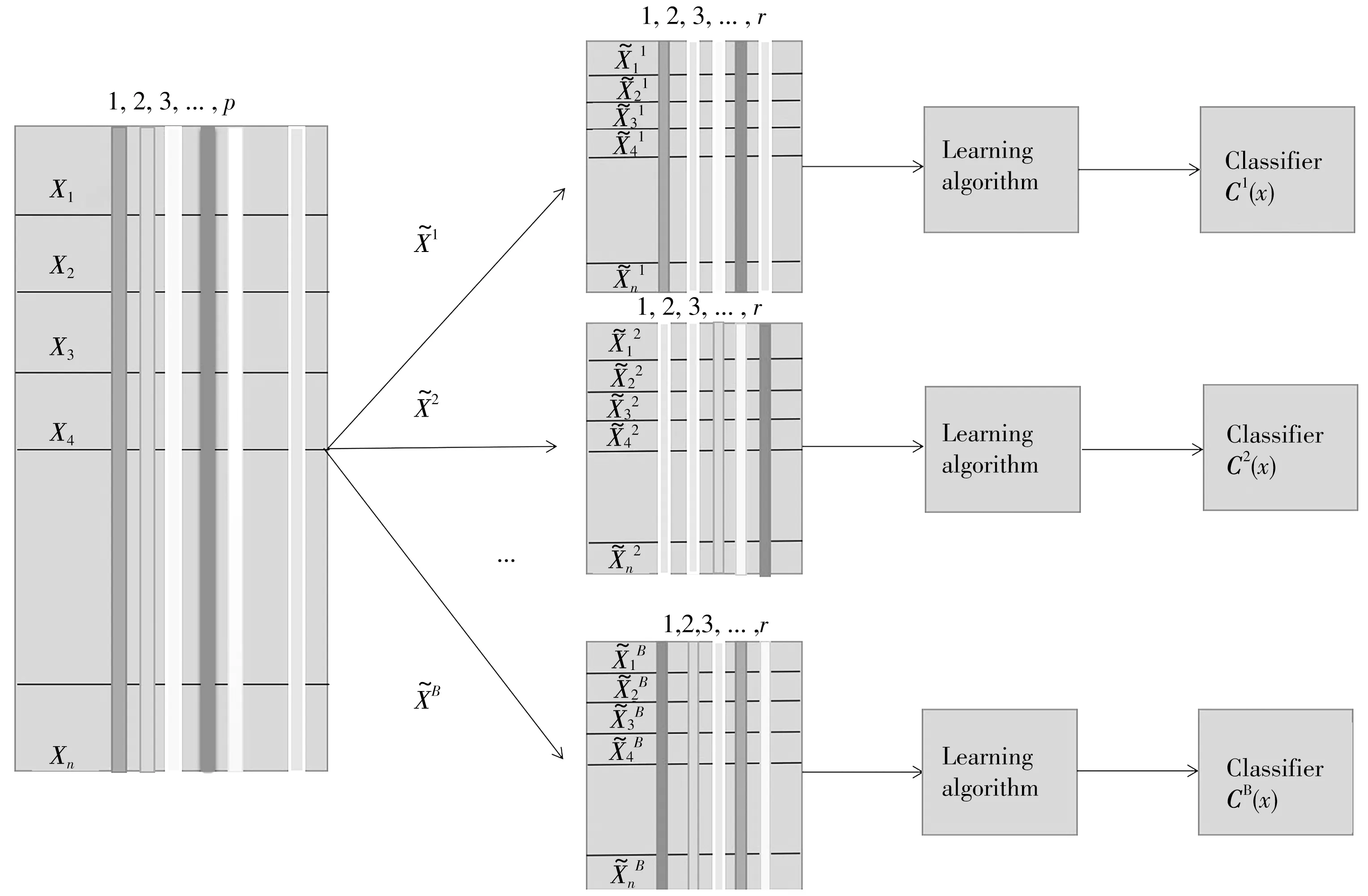
圖1 RSM-LDA工作流程Fig.1 Workflow of RSM-LDA
2 結果與討論
2.1 原始光譜分析
648 個樣本的平均原始光譜見圖2,其在470~550 nm 波段內呈緩慢下降趨勢,550 nm 處有一個小的吸收峰;550~680 nm 波段內的變化幅度小,曲線較為平緩;當波長大于680 nm 之后,光譜反射率增強,光譜曲線總體呈上升趨勢,其中一部分迅速上升,在890 nm 后較為平緩;其余大多數曲線緩慢上升,在740 nm 處有一個小的吸收峰。該結果表明有兩類黑色簽字筆的墨水成分差異很大。其余不同種類黑色簽字筆墨水的高光譜圖像形態高度一致,需要借助機器學習對高光譜數據進行分析。
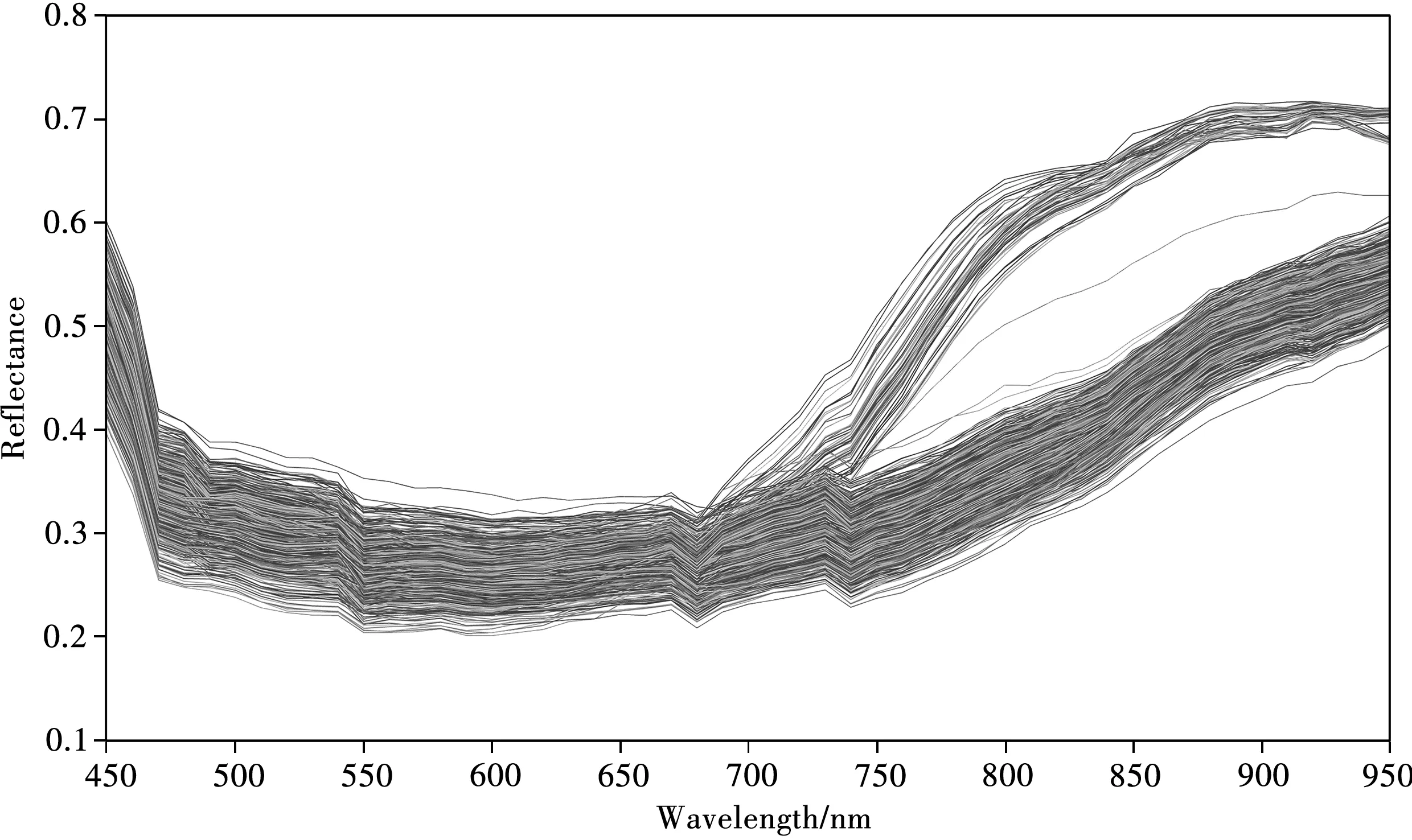
圖2 648個樣本的原始光譜圖Fig.2 Raw spectra of 648 samples
2.2 數據預處理
對原始光譜進行Savitzky-Golay 平滑、Z-Score 標準化和兩者組合的光譜預處理,以預處理后數據所建模型的交叉驗證準確率(ACCCV)作為預處理方法的選擇依據。圖3A 展示了不同預處理方法下光譜的LDA 模型分類結果,未進行預處理的準確率達98.61%,單獨使用S-G 平滑后,準確率上升到98.88%,表明S-G 平滑可以有效提高光譜的平滑性,降低噪音干擾;單獨使用Z-Score 標準化,準確率無明顯提升;兩種預處理方法同時使用,準確率達99.07%。圖3B 展示了不同預處理方法下光譜的RSM-LDA 模型分類結果,不難發現,預處理對模型的分類準確率無影響,表明該模型的學習能力和穩健性強。最終采用S-G 平滑和Z-Score 標準化組合方法對原始光譜進行預處理,結果如圖4所示。
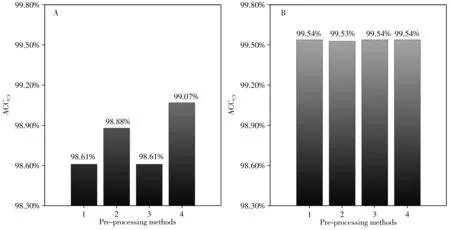
圖3 不同預處理方法的分類結果Fig.3 Classification results of different pre-processing methods
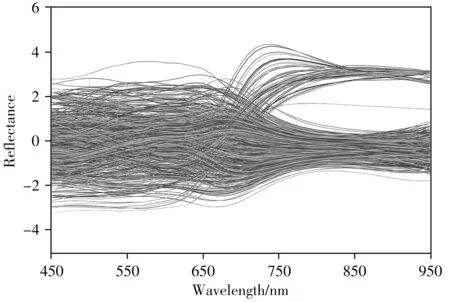
圖4 預處理后的樣本光譜曲線Fig.4 Spectral curves after combination of S-G smoothing and Z-Score pretreatment for sample
2.3 黑色簽字筆的LDA及RSM-LDA分析
將數據集以均勻隨機抽樣的方式按4∶1 的比例分為訓練集(Train set)和測試集(Test set),其中訓練集用于訓練模型的參數和評估模型的擬合能力,測試集用于評價模型的泛化能力。對每個模型進行五倍交叉驗證,根據求得的誤分類率的均值調整模型參數。由于黑色簽字筆墨水大部分譜圖規律高度一致,為了防止圖像中的細微信息丟失,本實驗選擇直接對全譜圖數據進行分析。
研究表明,LDA 和RSM-LDA 模型訓練集的平均分類準確率分別為99.54%和100%,交叉驗證平均分類準確率分別為98.16%和99.09%,兩種模型測試集的分類結果如圖5所示。對于測試集的129個樣本,LDA模型有20個樣本被誤判,RSM-LDA模型有12個樣本被誤判。綜上所述,LDA模型測試集平均分類準確率為84.50%,RSM-LDA 模型測試集平均分類準確率為90.70%,比LDA 模型提高了6.20%。兩種分類模型均可有效區分不同品牌型號的黑色簽字筆墨水,其中,RSM-LDA模型的分類效果更佳。
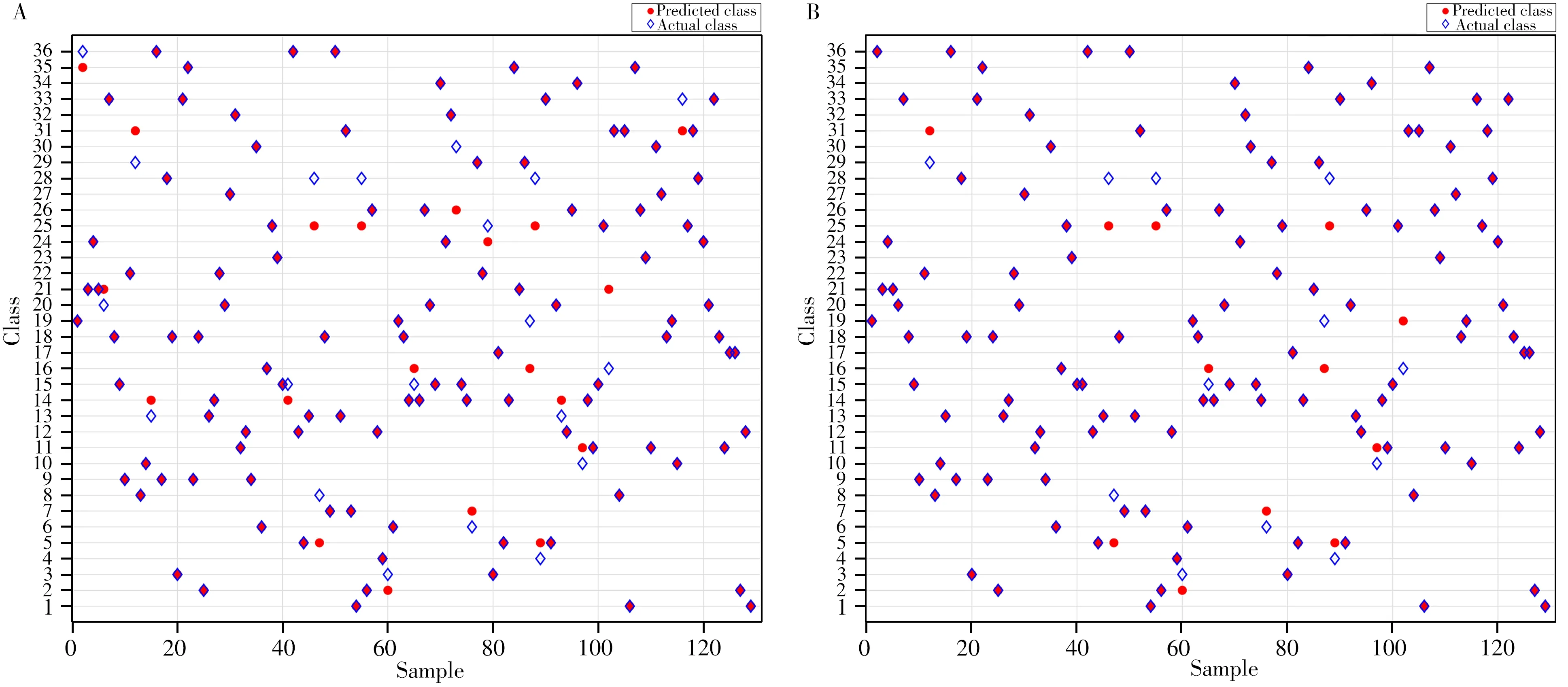
圖5 LDA(A)和RSM-LDA(B)測試集分類結果Fig.5 Classification results of test set of LDA model(A)and RSM-LDA model(B)blue hollow diamonds represent the actual category,and red solid circles represent the predicted category
2.4 模型評估
2.4.1 準確率、精準率及召回率 為了解模型的泛化能力,考察了LDA 和RSM-LDA 分類模型每類樣本的準確率、精準率和召回率,如表1 所示。準確率即預測正確的結果占總樣本的百分比;精準率指所有被預測為正的樣本中實際為正的樣本的概率;召回率指實際為正的樣本中被預測為正樣本的概率。以上3 個指標越大,則說明模型分類能力越強。
從表1可以看出,36類黑色簽字筆墨水樣本的LDA模型和RSM-LDA模型準確率均不低于97.9%,可以有效區分樣本。在LDA 模型中,1 號晨光牌(ARP50904)、12 號晨光牌(AGPA3903)和23 號得勁牌(17A)的樣本準確率最高,達到100%;16號成田良品牌(80)和31號愛好牌(47920)的樣本準確率最低,為97.9%。而在RSM-LDA 模型中,有11 類樣本可100%準確分類,準確率最低為97.9%,為28 號樣本。在精準率方面,LDA 模型有10 類樣本可達100%,80%及以下的有11 類,最低的是31 號樣本,為58.8%;而RSM-LDA 模型有15類樣本精準率可達100%,80%以下的只有5類,最低的是3號和5號樣本,為62.5%。其中,有19 類樣本在使用了RSM-LDA 模型后精準率有所提升,只有5 類樣本略有下降。就召回率而言,LDA模型有10類樣本達100%,80%以下的有11類,最低的是28號真彩牌(0221B)和29號三菱牌(UB-150)的樣本,為50.0%;而RSM-LDA 模型有15類樣本召回率達100%,80%以下的有7類,最低為50.0%,同樣是28號和29號樣本。其中,有15類樣本在使用了RSM-LDA模型后召回率有所提升,只有3 類樣本略有下降。由此可見,RSM-LDA 模型可以更有效地區分黑色簽字筆墨水種類且泛化能力良好。
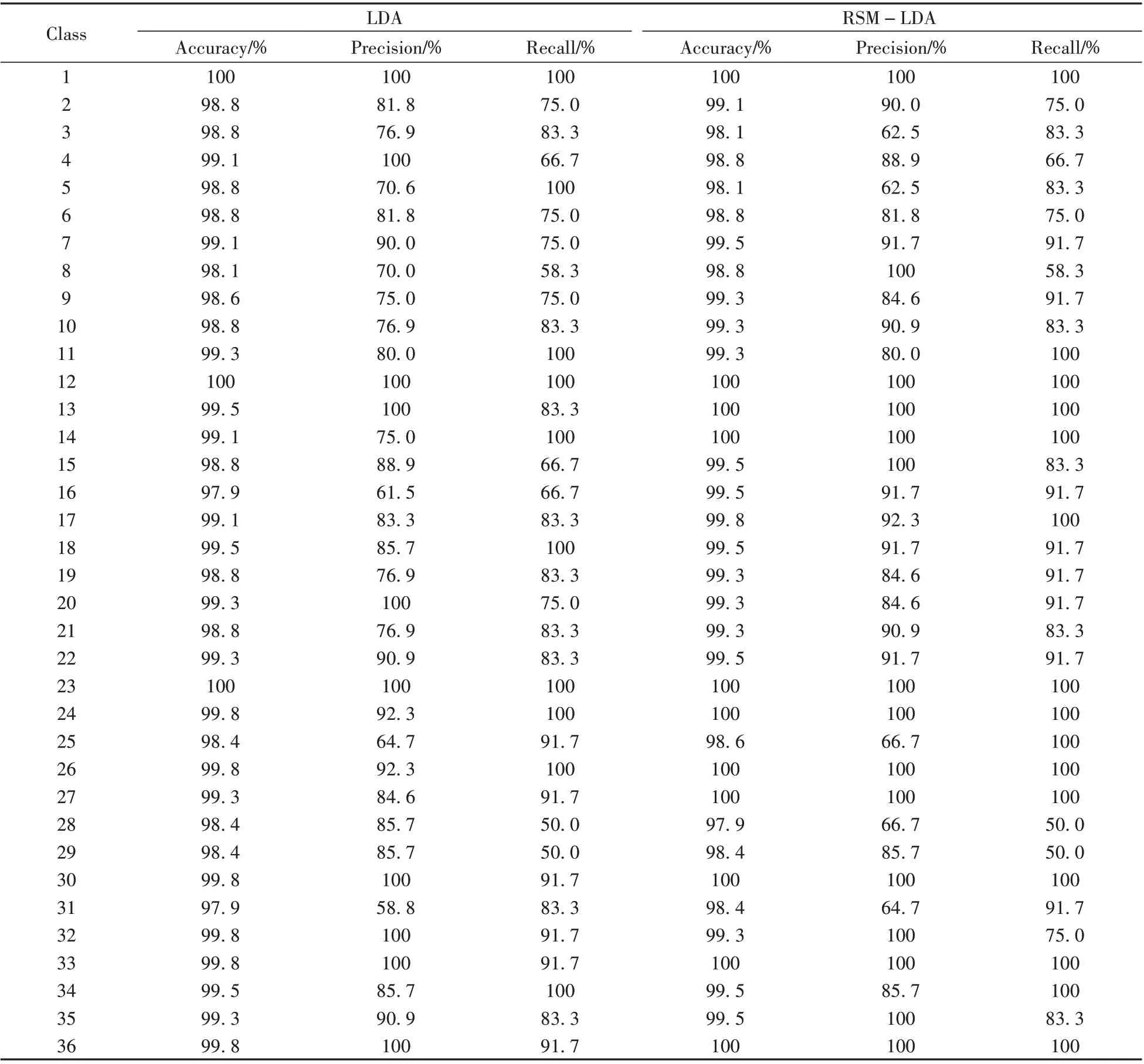
表1 36類樣本的準確率、精準率和召回率Table 1 The accuracy,precision and recall of 36 classes samples
2.4.2 接受者操作特征曲線 為進行更全面的評估,本實驗考察了兩種模型的接受者操作特征曲線(Receiver operating characteristic curve,ROC),如圖6 所示。ROC 曲線下方面積(Area under ROC curve,AUC)可用于評估模型的性能,AUC 越大,模型分類性能越強[22]。結果表明RSM-LDA 模型具有更大的AUC(0.998 3),這是因為隨機特征選擇產生多個分類器,RSM-LDA模型比LDA模型對噪聲的抵抗力更強,對頻譜的穩定性要求更低。
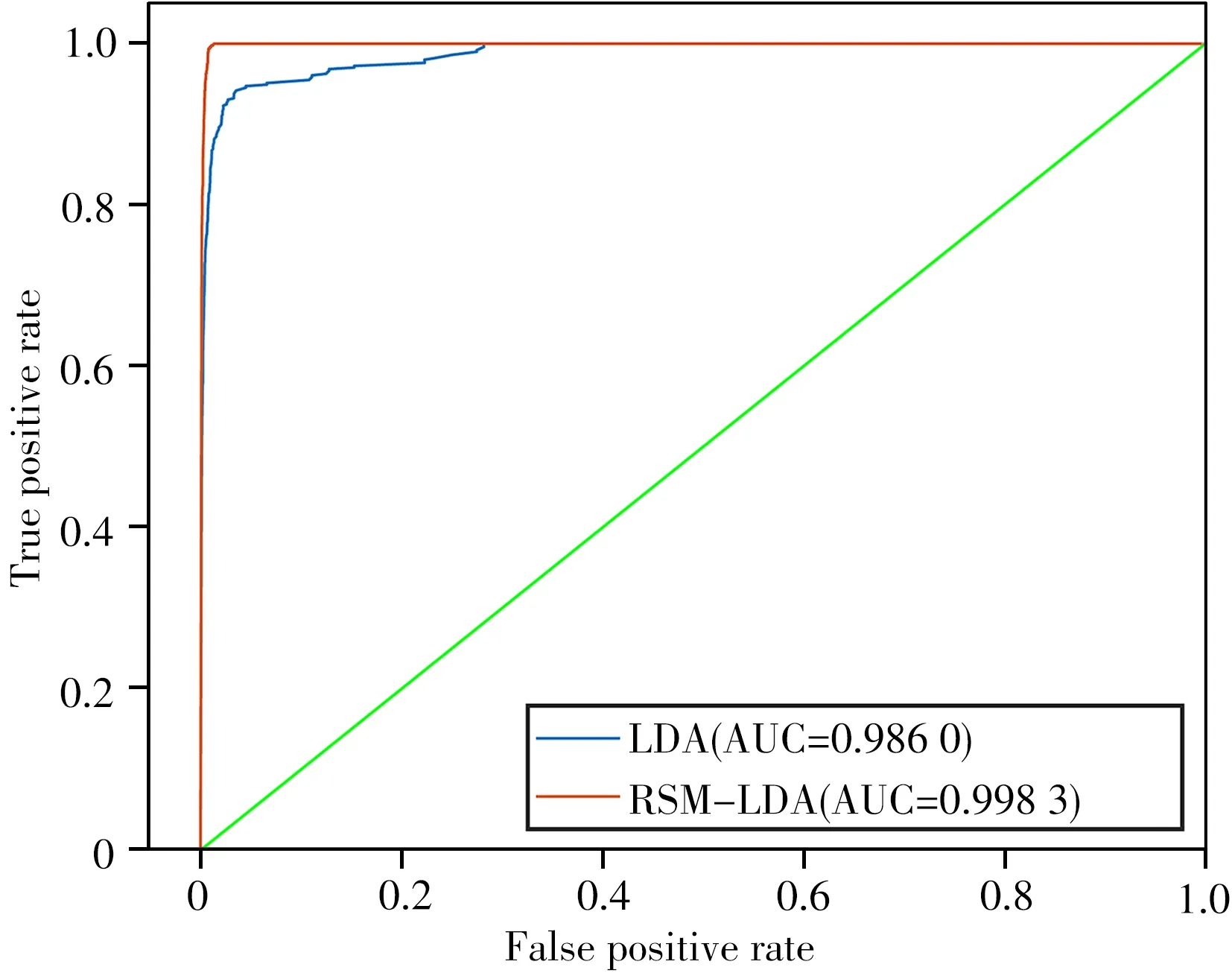
圖6 ROC曲線Fig.6 ROC curve
3 結 論
高光譜成像技術結合RSM-LDA 模型可用于不同品牌、同品牌不同型號黑色簽字筆的快速分類鑒別。本研究對36 支黑色簽字筆墨水的原始光譜數據進行S-G 平滑和Z-Score 標準化組合預處理后,分別采用LDA 和RSM-LDA方法建立了黑色簽字筆墨水種類的鑒別模型。兩種方法分類結果均較好,且RSM-LDA 模型的分類效果和穩健性優于LDA 單一模型,其訓練集的平均分類準確率為100%,交叉驗證平均分類準確率為99.09%,測試集的平均分類準確率為90.70%,模型的AUC 值達0.998 3,模型性能良好,為筆跡檢驗提供了一種新的快速、無損方法。后續應擴大樣本類型及數量,建立完備的樣本庫,以期為法庭科學墨水檢驗構建新平臺。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
