社會化搜索情境下用戶信息素養量表構建研究
2021-11-03 01:54:24張莉宋小康孫霄凌朱慶華
現代情報 2021年11期
張莉 宋小康 孫霄凌 朱慶華
關鍵詞:社會化搜索;用戶;信息素養;測評量表;測評工具;探索性因子分析;驗證性因子分析;評價
由WeAreSocial和Hootsuite共同發布的報告“Digital2021”(數字2021)[1]顯示截至2021年1月,全球有42億社會化媒體活躍用戶,其中中國為9.3億。報告指出,用戶使用社會化媒體的主要目的是搜索信息。CNNIC公布的《2019年中國網民搜索引擎使用情況研究報告》[2]指出,2017年5月微信發布的“搜一搜”功能已成為用戶在手機端搜索信息的重要工具。可見社會化搜索已成為用戶獲取信息的重要途徑。
與此同時,值得關注的是在社會化搜索情境下,用戶信息處理能力出現了兩極分化。社會化搜索平臺上存在海量、動態的用戶原創內容,有些用戶能夠快速在平臺上找到符合需求的內容,而有些用戶卻如同陷入“信息荒漠”無法獲得所需信息。有些用戶擅長信息核查,而有些用戶則可能經常轉發虛假信息而不自知[3]。造成這一現象的根本原因在于用戶的信息素養水平參差不齊。2020年新冠疫情期間,社會化搜索平臺成為網民獲取疫情信息的重要渠道,人們一方面通過平臺進行相關信息搜索;另一方面也在平臺上傳遞自己所了解的疫情信息,分享、評價及轉發行為頻繁。然而由于用戶信息素養的水平不同,造成了真實和虛假信息同時在平臺上大量蔓延,為用戶的信息使用帶來了困擾,甚至影響社會安定。由此可見,提升用戶的信息素養水平對社會化搜索用戶以及社會化搜索平臺的發展都有著極其重要的影響。在此之前需要先通過評價工具了解用戶的信息素養水平,進而開展針對性的培育以達到提升信息素養的目的。
隨著信息技術的發展,信息生態環境隨之改變,信息素養的內涵也發生了相應的變化。不同于圖書館或搜索引擎情境下的信息素養,社會化搜索情境下的信息素養更加關注情境特有的動態交互特征。而現有的信息素養評價工具絕大多數針對大學生而開發,且主要以了解和提升學習情境中的信息素養為測評目的,并且缺乏對用戶在社會化搜索環境中信息交互行為的衡量[4]。因此,本文通過對相關文獻梳理和專家訪談,構建出社會化搜索情境下的用戶信息素養初始測評工具,并使用探索性因子分析和驗證性因子分析方法進行量表修正,以期用于測度社會化搜索情境下的用戶信息素養水平,為今后社會化搜索及信息素養等相關研究提供借鑒和參考。
1文獻回顧
1.1社會化搜索
在高度數字化的信息環境中,以去中心化為特點的各種Web2.0應用不斷涌現發展,這些社會化應用平臺鼓勵用戶創造信息、分享信息,并在此過程中交互協作,使得用戶的信息實踐活動前所未有的頻繁和復雜。人們不再滿足于借助傳統搜索引擎僅僅依靠算法的排序和結果的羅列而得到搜索結果,還期望通過在線人際關系合作尋找用戶生成的信息,社會化搜索成為人們獲取信息的重要途徑。
社會化搜索(SocialSearch)將社會化屬性引入信息搜索行為,其意義在于重建人與信息的關聯[5]。2004年,FreyneJ等首先對SocialSearch一詞進行了定義,是較早對社會化搜索展開的比較全面的研究。他們指出,社會化搜索是一種網絡搜索模式,集合網絡搜索、社交網絡以及個性化服務的理念,旨在使用戶基于搜索活動獲得更加精確的信息[6]。此后,不少學者對社會化搜索這一概念進行了解釋,概括而言,學者們認為社會化搜索即用戶利用社會化交互和協作通過在線社會網絡進行信息搜索的活動[7-12]。從社會化搜索活動的載體即平臺角度看,社會化搜索主要表現為以下4種:①社會化搜索引擎,如SocialMention和SocialSearcher。社會化搜索引擎不僅考慮到搜索結果的內容相關性,還蘊含著信息搜索者和提供者的社交關系;②社會化媒體,如微信、QQ、Facebook等。社會化媒體是Web2.0技術環境下充分體現參與性、共享性、社區性的信息交流平臺;③在線問答社區,如知乎、Quora等,是以問答形式為主的供公眾交流的知識平臺;④社會化標注系統,如大眾美食、小紅書、Flickr等[13]。在這些社會化平臺上用戶可以對網絡資源進行開放自由的標注,形成社會化標簽。
1.2信息素養
信息素養最初植根于圖書館用戶教育,其概念始于美國圖書檢索技能的演變。1974年,美國信息產業協會主席ZurkowskiPG率先提出了信息素養這一概念,將其解釋為利用大量的信息工具及主要信息源解答問題的技能[14]。信息素養概念一經提出,便得到廣泛傳播和使用。隨著Web2.0技術日益影響人們生活、學習及工作,改變人們獲取和創造信息的環境,學者們提出信息素養2.0這一說法[15],認為信息素養2.0以創造為核心,用戶通過主動參與社會性互動,運用批判性思維,促進終身學習。2011年MackeyT等[16]首次提出“元素養(Metaliteracy)”這一集成概念,并認為元素養是信息素養的核心基礎,可以將元素養理解為“提升其他一切素養的素養”。盡管人們對信息素養這一概念有各種角度的理解,但對其基本內涵的分析都圍繞著信息意識、信息能力及信息倫理等方面。
1.3信息素養評價工具
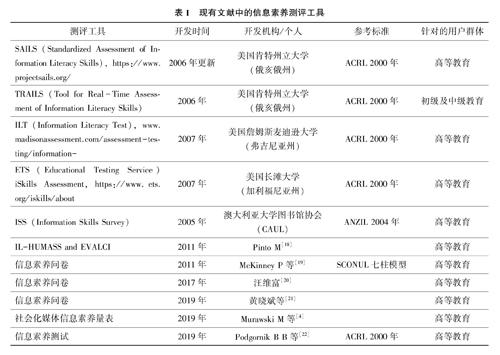
信息素養評價是驗證信息素養教育成果及揭示未來教育方向的工具,是信息素養研究的重要組成部分。信息素養評價工具多基于信息素養標準設計,目前較有影響力的是美國ACRL標準、澳大利亞與新西蘭ANZIL標準以及英國SCONUL標準。我國則于2006年由研究者制定出北京地區高校信息素質能力指標體系[17]。本文梳理了現有研究中的主要信息素養測量工具,如表1所示。
綜合現有研究成果可以發現,目前的信息素養量表具有以下特點:
①測評對象基本以大學生為主。除了偶見對老年人、特定疾病患者、農村人口及中小學生等進行信息素養測評,絕大部分量表的開發和使用都以大學生為研究對象;②測評情境和目的主要是為了解和提升測評對象在學校、圖書館或專業學習情境中的信息素養;③測評內容主要以ACRL2000年頒布的信息素養標準為依據,進行量表的開發構建,強調信息需求、信息獲取、信息評價、信息利用及信息倫理等方面技能的發展[23-26]。
而事實上,在高度數字化的社會生活中,信息和所有人的生活都密切相關。聯合國信息素養專家會議在2003年9月發表的《布拉格宣言》中指出,信息素養既是人們的基本權利,又是人們終身學習的保障,若要有效參與信息社會,必須具備一定的信息素養[27]。而在社會化搜索情境下,用戶群體不單單限于大學生。Digital2021報告顯示,中國社交媒體活躍用戶達9.3億人,男女比例為51.0∶49.0,其中10歲以下用戶占總人數的3.5%,10~19歲用戶占總人數的14.8%,20~29歲用戶占19.9%,30~39歲用戶占20.4%,40~49歲用戶占18.7%,50~59歲用戶占12.5%,60歲以上用戶占10.3%[1]。可見,僅有針對大學生的信息素養評價是遠遠不能滿足整個社會各類人群信息素養的評價需求的。
此外,信息搜索情境也遍布學習生活娛樂等不同場景。無論是尋找學習資料、聯系工作伙伴、關注新聞、尋找美食還是制定旅游攻略,人們都習慣于使用社會化搜索方式來發掘有用的信息。而用戶的信息素養對于能否在這些情境中快速準確地獲取目標信息有很大的影響。有學者認為,隨著大數據和云計算等信息技術的不斷發展,現有信息素養指標不足以體現新的信息技術給信息環境帶來的變化,未能匹配社會化媒體環境中信息的動態特征[4,21]。現有評價工具盡管看似合理且結合了教育的目標,然而其主要缺點在于理解的片面性,在很大程度上將實際上復雜的能力和知識結構簡化為有限且被割裂的技能[28],并且忽視社會、政治或歷史背景對信息素養的影響。片面的信息素養標準并不符合社會建構主義的觀點,當前社會環境下的學習不再僅僅發生在單個個體和知識之間,而是發生在人群和社區之間[29-30]。隨著信息環境的變化,用戶的信息素養內涵特征也在隨之改變,因此信息素養測評工具也應與時俱進,才能有效衡量當前信息環境下用戶的信息素養水平,使用戶或利益相關方了解其信息素養水平并可作為將來信息素養教育的參考。
2初始量表構建
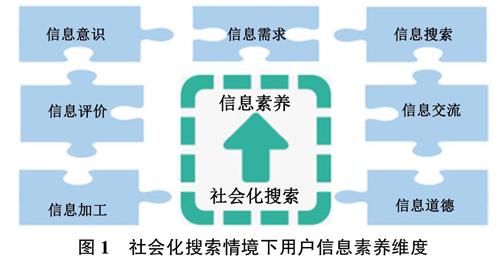
本研究選擇學術數據庫(如WebofScience、Scopus、ScienceDirect、ProQuest、JISTOR、EBSCO和Emerald)進行信息素養和社會化搜索相關文獻的檢索,通過對333篇相關文獻的閱讀和梳理對社會化搜索情境下的信息素養內涵進行了總結,在與相關專家討論的基礎上,本研究認為社會化搜索情境下用戶的信息素養是社會化搜索用戶所具備的一系列能力,包括信息意識、信息需求、信息搜索、信息評價、信息交流、信息加工和信息道德與法律。具體模型如圖1所示。
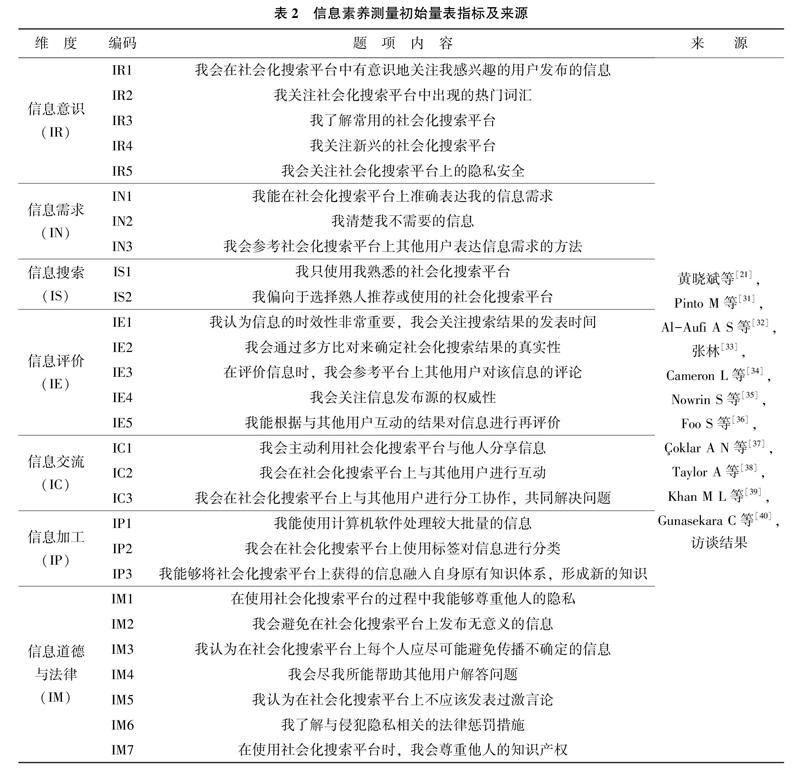
本研究首先通過對現有文獻進行系統梳理,挖掘出有代表性并適用于本研究情境的題項,力圖較為全面地表達構念所體現的內容。之后邀請了3位社會化搜索領域和信息素養研究領域的專家進行深入訪談,基于梳理出的社會化搜索情境下的信息素養定義及已有研究結果經過探討設計出適合的題項,并對題項語義表述反復斟酌進行調整形成含有7個維度,28個題項的量表初稿,指標及來源如表2所示。
以上所有7個方面的測量指標設計較為完整地覆蓋了信息搜索行為的整個過程。同時考慮到社會化搜索與使用搜索引擎的區別與聯系,更多強調與衡量的是社會化搜索特有的交互特征。比如在搜索方面,沒有過多強調用戶搜索技巧,因為在這個信息過載的時代,不僅信息源過度膨脹,平臺功能設計及人工智能也為搜索信息提供了極大便利,單純搜索信息已不再是用戶最強烈的需求或缺失的能力,用戶能否通過社會化搜索平臺的交互行為去溝通、評價及加工信息,形成并維護平臺上良好的道德氛圍是本量表測量重點。
3前測問卷及量表調整
由于社會化搜索情境下用戶信息素養水平測度在現有文獻中研究成果不多,尚無成熟的針對社會化搜索情境的量表可以參考,因此在形成正式量表之前需要進行小規模前測以檢驗量表的合理性,通過信度、效度分析以發現問卷存在的問題并進行修改。
3.1問卷設計
前測所采用的問卷由4部分構成,①問卷說明:用來簡要說明問卷調查的目的,并對社會化搜索這一概念及相關平臺進行了簡要介紹;②人口統計學信息調查:包括受訪者的性別、年齡、受教育程度及專業等信息;③社會化搜索使用情況調查:包括受訪者使用社會化搜索的年限、使用偏好、平臺選擇及使用目的等信息;④信息素養測量部分:要求受訪者根據自身使用社會化搜索的實際情況做出選擇,打分采用常用的李克特(LikertScale)五分尺度,1~5分別表示“非常符合”“有些符合”“不確定”“有些不符合”“非常不符合”。
3.2前測問卷信度與效度檢驗
本研究借助“問卷星”(www.sojump.com)共發放前測問卷269份,經過數據清洗,去除答題邏輯、答題時間及選項存在明顯問題的問卷后,共獲得有效問卷239份,有效回收率為88.9%。
1)信度檢驗
信度是心理學測量中的一個基本指標,通過信度檢驗可以判斷測量結果的一致性和可靠性,從而反映測量工具的穩定性。一般采用Cronbach.sAl?pha系數對數據進行可靠性分析,FornellC等[41]指出,量表的Cronbach.sAlpha系數大于0.7則表明量表的測量問題之間具有良好的內部一致性。本研究通過SPSS軟件對以上信度指標進行分析,前測問卷總體Cronbach.sAlpha=0.881,說明問卷總體具有較好的信度。7個維度的Cronbach.sAlpha分別為0.700、0.797、0.755、0.757、0.751、0.704和0.784,可見每個維度的信度均不低于0.7,說明每個維度的測量題項間均具有良好的內部一致性和可靠性。
除了Cronbach.sAlpha外,本研究還計算了每個題項在所屬維度上的總計相關性(CorrectedItemTotalCorrelation,CITC)以及刪除該題項后所屬維度的Cronbach.sAlpha(CronbachAlphaifItemDele?ted,CAID),CITC值可以描述一個題項與其所屬維度的總體相關性,CAID值可以描述假設刪除該題項后其所屬維度的Cronbach.sAlpha值,二者相結合則可以作為判斷一個題項是否合適的依據。已有研究指出,如果CITC系數小于0.4并且CAID系數大于所屬維度的整體Cronbach.sAlpha值的指標,應當予以剔除[42-43]。從計算結果發現,信息意識(IR)維度的題項IR5、信息評價(IE)維度的題項IE5,以及信息道德與法律(IM)維度的題項IM4的CITC值小于0.4,且刪除該項后對應維度整體的Cronbach.sAlpha值會有提升。因此,考慮刪除IR5、IE5和IM4這3個指標。
2)效度檢驗
效度檢驗旨在確認研究的準確性程度,用于評價量表是否能對測評對象進行有效測量。探索性因子分析法(ExploratoryFactorAnalysis,EFA)常用于檢驗量表的構建效度,KMO檢驗和Bartlett球形檢驗是用于判斷是否適合進行因子分析的兩個指標[44]。本文首先用SPSS對量表的前測問卷數據進行KMO檢驗和Bartlett球形檢驗,計算結果顯示KMO值為0.847,Bartlett球形檢驗的近似卡方顯著性Sig.=0.000<0.01,表明量表構念間具有較好的相關性,存在公共因素,適合進行因子分析。之后依然使用SPSS軟件進行探索性因子分析,在抽取選項中選擇主成分分析法進行因素抽取,在旋轉選項中選擇最大方差法進行因子旋轉,使用具有Kaiser標準化的正交旋轉法來測量量表各題項在公共因子上的載荷系數,從而探索量表的內部結構,旋轉在7次迭代后達到了收斂。共得到7個公共因子,解釋總方差為62.178%,具有較好的解釋度,具體數據如表3所示。
從表3可以得出,量表的28個題項在7個公共因子上有較為明確的隸屬關系。隸屬于公共因子1的題項包括:IM1、IM2、IM3、IM5、IM6、IM7,隸屬于公共因子2的題項包括:IE1、IE2、IE3、IE4,隸屬于公共因子3的題項包括:IC1、IC2、IC3、IM4、IE5,隸屬于公共因子4的題項包括:IR1、IR2、IR3、IR4、IR5,隸屬于公共因子5的題項包括:IP1、IP2、IP3,隸屬于公共因子6的題項包括:IN1、IN2、IN3,隸屬于公共因子7的題項包括:IS1、IS2。本文構建的初始量表中的7個維度信息意識(IR)、信息需求(IN)、信息搜索(IS)、信息評價(IE)、信息交流(IC)、信息加工(IP)和信息道德與法律(IM)與探索性因子分析得到的7個公共因子基本吻合,只有IM4和IE5兩個題項的歸屬存在問題,結合信度檢驗的結果決定將IM4和IE5刪除掉,雖然IR5在探索性因子分析中與其他信息意識維度的題項同屬于公共因子4,但考慮到信度檢驗的結果以及內容層面的含義,決定將該題項予以刪除。
4正式問卷及量表調整
通過對前測問卷進行信度和效度分析,在刪除3個不符合要求的題項后,剩下的25個題項形成本次研究的正式問卷。
4.1正式問卷數據收集
本次調查對象為社會化搜索用戶,通過社會化媒體平臺向調查對象發放問卷的鏈接及二維碼,同時以“滾雪球”的方式擴散問卷獲取充分的樣本量。整個數據收集及分析過程歷時兩周完成,共回收問卷1298份,經過數據清洗,去除所有選項完全相同、答題明顯不符合邏輯及答題時間過短的無效問卷,最終獲得928份有效數據進行數據分析,問卷回收的有效率為71.5%。
經過對問卷結果中人口統計學信息及社會化搜索使用情況部分的信息進行整理,發現本次調查的樣本中年齡低于35歲的占70%左右,半數以上調查對象有6年以上社會化搜索使用經驗。說明調查對象對社會化搜索接觸較多,較為了解社會化搜索這一信息獲取方式。
由于采用被調查者自評價的問卷調查,所有問項都由被調查者一人填寫,在此過程中可能產生共同方法變異(CommonMethodVariation)問題。為保證研究結果不受共同方法變異影響,在數據分析前使用Harman單因子鑒定法(Single-FactorTest)[45]進行檢驗,將本量表中所有測量題項進行探索性因子分析,并檢驗未旋轉因素的解。結果顯示,第一主成分解釋了總方差的30.052%,在可接受范圍之內。正式問卷的總體Cronbach.sAlpha=0.899,說明問卷總體信度較好。再對每個維度進行信度檢驗,7個維度的Cronbach.sAlpha分別為0.735、0.754、0.708、0.836、0.876、0.839和0.814,可見每個維度的信度均不低于0.7,說明每個維度的測量題項間均具有良好的內部一致性和可靠性。在進行探索性因子分析和驗證性因子分析之前,使用SPSS進行KMO和Bartlett球形檢驗,計算結果為KMO=0.905,Bartlett球形檢驗的近似卡方顯著性Sig.=0.000<0.01,表明量表構念間存在公共因素,適合進行因子分析。根據AndersonJC等[46]的建議,探索性因子分析和驗證性因子分析需要基于不同的數據進行檢驗,因此,本文將正式問卷收集到的928份有效問卷數據隨機分成兩部分,每部分464條數據,分別用于EFA和CFA分析。
4.2探索性因子分析
本部分依然使用SPSS進行探索性因子分析。參照前測問卷探索性因子分析的方法和步驟,共得到7個公共因子,解釋總方差為68.917%,具有較好的解釋度,具體數據如表4所示。
經過前測問卷的調整后,正式問卷探索性因子分析結果與構建的量表體系結構具有很好的一致性,公共因子1包含的指標有:IM1、IM2、IM3、IM4、IM5和IM6,與量表信息道德與法律(IM)維度的題項一致;公共因子2包含的指標有IE1、IE2、IE3和IE4,與量表信息評價(IE)維度的題項一致;公共因子3包含的指標有IC1、IC2和IC3,與量表信息交流(IC)維度的題項一致;公共因子4包含的指標有IP1、IP2和IP3,與量表信息加工(IP)維度的題項一致;公共因子5包含的指標有IR1、IR2、IR3和IR4,與量表信息意識(IR)維度的題項一致;公共因子6包含的指標有IN1、IN2和IN3,與量表信息需求(IN)維度的題項一致;公共因子7包含的指標有IS1和IS2,與量表信息搜索(IS)維度的題項一致。
4.3驗證性因子分析
之后使用剩下的464條數據進行驗證性因子分析,本部分選用AMOS軟件進行CFA,原因在于AMOS是一款強大的結構方程建模軟件,能夠降低估算值偏差,獲得更準確的計算結果,適合進行探索性因子分析。首先需要根據問卷量表維度和指標構成在AMOS軟件界面構建出量表結構模型,然后導入數據,最后對模型進行數據計算。所構建的量表結構模型和驗證性因子分析路徑系數結構如圖2所示。
AMOS中的一些指標常用于衡量量表結構的合理性,包括卡方與自由度之比(CMIN/DF)、擬合優度指數(GFI)、比較擬合指數(CFI)、近似誤差均方根(RMSEA)、規范擬合指數(NFI)、增量擬合指數(IFI)和調整擬合優度指數(AGFI)。基于IacobucciD[47]、HuLT等[48]、宋小康等[43]、孫曉寧等[5]研究的建議,CMIN/DF一般要小于3,GFI、CFI和IFI一般要大于0.9,NFI和AGFI一般要大于0.8,RMSEA一般要小于0.09。本研究探索性因子分析得到的相關指標值如表5所示,所有指標均達到了要求,說明本研究構建的正式問卷的量表結構合理。
驗證性因子分析結果還得到了25個測量指標在其所屬維度上的因子載荷,具體數據如表6所示。其中S.E.為測量指標在所屬維度上的估計值標準誤差,C.R.為測量指標在所屬維度上的未標準化路徑系數與標準誤差的比值,通過C.R.或者P值可以看出參數估計的顯著性,從結果可以看出,所有系數評估的顯著性均達到了0.001的顯著水平。從標準化路徑系數看,測量指標在所屬維度上的路徑系數基本在0.5以上,只有IR4“我關注新興的社會化搜索平臺”在信息意識維度的路徑系數較小,僅為0.317。從指標內容上看,雖然平臺對于社會化搜索非常重要,但關注新興的社會化搜索平臺并不一定能夠反映用戶具有較好的信息意識,因此將此題項刪除。
研究最初參考已有研究和訪談結果共同組合形成了包含28個題項的初始量表,在對前測問卷進行信度和效度檢驗(探索性因子分析)后刪除了與所屬維度相關度不高的3個題項,形成25個題項構成的正式問卷,通過正式問卷的探索性因子分析和驗證性因子分析后刪除了在所屬維度上路徑系數不高的1個題項。綜上,經過3個階段的量表開發過程,最終獲得包含7個維度和24個指標的社會化搜索情境下用戶信息素養測評量表,如表7所示。最終量表的信度、效度和結構合理性都通過了檢驗,達到良好的水準,可以作為社會化搜索情境下用戶信息素養水平的測評工具。
5結語
用戶在信息搜索活動中體現的信息素養不僅影響個體搜索活動的效率和效果,同時還塑造著整個社會化搜索的環境。本研究立足社會化搜索這一特定情境,嚴格按照量表開發步驟構建信息素養量表,形成了包含信息意識、信息需求、信息搜索、信息評價、信息交流、信息加工和信息道德與法律7個維度以及對應24個指標的信息素養測量工具。本研究為有效衡量社會化搜索用戶的信息素養水平提供了較為匹配的評價工具,具有一定的普適性。
本研究主要存在幾點局限:①由于篇幅所限,未能對量表中7個維度之間的相互影響展開探索,以挖掘信息素養各個維度之間的深層關系;②本量表具有一定的普適性,但同時也意味著缺乏針對性。性別、年齡、學歷、職業、性格、亞文化等具體情境都可能影響信息素養的構成及評價角度;③本量表采用自報告形式獲得用戶對自己信息素養的評價,這種方法雖然被普遍使用,然而研究發現,自報告受到參與者自我效能評價的影響,與其實際水平可能存在一定的差異[31],后續研究中可以考慮采用量表和客觀評價指標相結合的測評方式來綜合評價用戶的信息素養水平。
猜你喜歡
福建中學數學(2023年5期)2024-01-25 17:41:36
中學生數理化·中考版(2022年10期)2022-11-10 09:37:46
新世紀智能(高一語文)(2020年10期)2021-01-04 00:44:12
新世紀智能(高一語文)(2020年10期)2021-01-04 00:44:10
新世紀智能(高一語文)(2020年12期)2020-06-01 08:14:28
新世紀智能(高一語文)(2020年12期)2020-06-01 08:14:26
護士進修雜志(2017年3期)2017-02-14 07:19:35
商用汽車(2016年11期)2016-12-19 01:20:16
小學生作文(中高年級適用)(2016年3期)2016-11-11 06:30:23
商用汽車(2016年6期)2016-06-29 09:18:54
