基于改進型V-net卷積神經網絡的胃壁分割方法
2021-11-04 06:28:52趙呈陸方志軍高永彬王海玲衛子然蔡清萍
中國醫學物理學雜志 2021年10期
趙呈陸,方志軍,高永彬,王海玲,衛子然,蔡清萍
1.上海工程技術大學電子電氣工程學院,上海201620;2.上海長征醫院普外二科,上海200003
前言
胃癌是我國第二大癌癥,一直是困擾中國醫學界的重大疾病之一[1]。胃癌TNM(Tumor Node Metastasis)分期是現階段分析腫瘤侵犯程度的重要手段[2-3]。而TNM 分期中的T(Tumor)分期是TNM分期的關鍵標準,T 分期的結果將直接影響醫生對患者手術的可行性評估與手術的方案制定,更決定著患者術后的存活率。通常情況下,醫院評估患者的胃癌情況要依照專家組對患者的醫學影像結果分析評估,綜合胃鏡影像[4]、增強造影CT[5]等信息進行科學評估,最終給出一個初步的分期結果,并根據分期結果制定手術方案。術后重新對患者的殘留組織進行解剖并給出最終分期結果。而這些流程過于繁瑣,人工智能領域的快速發展為快速準確地給出輔助診斷結果提供了新思路。T 分期的依據是腫瘤侵犯胃壁的深度,通過CT 影像分割出胃壁與腫瘤是利用人工智能技術實現T分期的關鍵一步,本文對上腹部CT影像中的胃壁分割展開研究。
上腹部CT 圖像實現胃壁分割面臨以下問題:(1)醫學影像的數據比較少,尤其是CT 圖像,可以獲取到的有效數據更是有限,如果網絡的結構模型過于復雜、參數過多,就會導致訓練的模型過擬合,從而造成結果偏差。而傳統的數據增強是在圖像的基礎上做旋轉、平移等操作,CT圖像中器官的相對位置是固定的,增強之后的數據已經不在CT 圖像的范疇之內了。(2)CT 圖像中語義信息比較簡單,圖像結構單一,各器官的位置相對固定,器官位置會隨著CT層次的變化而發生相對位置偏移,但根據層次信息仍然有規律可循。(3)圖像對比度低,器官與器官之間的CT 值被平均化,因此需要更好的網絡框架對數據的特征進行提取。
針對上述問題本文主要貢獻如下:(1)針對數據量較少的問題,本文采用在訓練集中加入噪聲的方法對訓練集進行擴充,擴充后的數據不改變原始的胃壁相對位置。(2)現階段CT 圖像分割方法均采用將CT 圖像轉化為普通灰度圖像的方法進行訓練,使得圖像特征信息丟失嚴重。尤其是轉化為二維圖像后,丟失掉了CT 圖像各層次間的信息。本文使用可視化分割和注冊工具包(The Insight Segmentation and Registration Toolkit, ITK)[6]保留了原始CT 圖像的CT值,將CT值做成256×256×32的矩陣塊,極大保留了數據的原始特征。(3)提出正則化水平集損失函數,并在改進的V-net 網絡框架上,首次實現上腹部CT影像的胃壁區域分割,將原始V-net在胃壁的分割精度提高了6%。
1 相關工作
分割是人工智能理解CT圖像信息的基礎環節,也是計算機輔助診斷技術的重要任務。分割根據圖像中的像素信息以及分割目標中的像素劃分為前景和背景。而對于CT圖像而言,每張CT圖像包含了人體各器官因為對X光的反射密度不同而產生的影像,并將其轉化為-1 000~1 000的CT值。使得本文通過利用CT值的信息來實現器官的分割任務成為可能。
相對于傳統圖像而言CT 圖像的處理具有一定的難度,一方面要保留原始數據的數據量不丟失,另一方面還要統一與RGB 圖像之間的位數關系(例如CT 值轉8 位的像素值)方便神經網絡處理。現階段醫學圖像分割領域有很多成熟的網絡,如V-net 采用全卷積網絡的形式,不添加任何連接層即可實現圖像的分割[7]。Shen 等[8]利用V-net 在CT 影像上實現心臟動脈分割并達到了90%的分割精度,Hu 等[9]的U-net腫瘤分割均采用神經網絡的方法取得了較好的分割效果。而為了進一步提高分割的準確度和泛用性,CE-net[10]、CLCI-net[11]為了解決MRI圖像分割中下采樣過程圖像梯度消失的問題,分別將殘差模塊和深度連接層的思想融入到全卷積神經網絡中去。與CE-net、CLCI-net采用的MRI數據不同的是,CT圖像具有更低的對比度,多器官在掃描成像時產生容積效應而引起器官邊緣模糊。尤其是胃壁區域,邊緣特征與總體特征均不明顯,加之胃壁厚度在整個圖像中的比例很小,這無疑對單純改變網絡結構來實現胃壁分割造成了較大的挑戰。
2 本文提出方法
本文的方法首先通過數據增強的方法擴充訓練集,然后送入搭建好的卷積神經網絡中訓練,保留訓練的模型參數。測試時,將模型參數導入原始神經網絡框架,將測試集輸入神經網絡獲取預測結果,最后通過Dice參數和交并比(Intersection Over Union,IOU)評估測試的結果。
2.1 數據增強
本文選用的學習框架基于3D V-net 全卷積神經網絡,由于CT 圖像是有序的圖像序列,普通的二維卷積網絡只是從單張圖像中提取特征信息。而3D網絡可以同時將有序的CT 圖像進行多層卷積,可以捕捉到各層次胃壁結構之間的相關特征信息。本網絡的輸入為經過人工篩選后選取的52位胃癌患者的含有胃壁特征信息的CT 圖像,共包含1 664 張有效數據。通過特殊處理,每組數據做成一個256×256×32的圖像塊。由于數據量相對較少,為了能夠提高訓練效率,抑制過擬合,本文采用數據增強的方法來擴充一部分數據。
普通RGB 圖像的處理方法往往采用數據增強的方式來擴充數據,例如旋轉、裁剪、放射變換等。但是這些方法并不適用于本研究領域,主要原因是胃壁一般在上腹部的上方位置,胃壁的規則不一。CT圖像往往是逐層掃描獲得的,在掃描的過程中獲取到的圖像層次間具有一定的規律性,一般前幾層的胃壁總是出現在下方(賁門的位置),隨著掃描的進行,胃壁會由右下方逐漸變換到右上方(幽門和胃底的位置)。而數據增強的方法產生的圖像已經不屬于胃部CT 的圖像特征領域。本文采用加入隨機噪聲的方法產生新的圖像,能更好地模擬原始的CT 圖像,在擴充數據的同時能更好地抑制過擬合。為了不破壞圖像的原始結構,本文采用插入線性隨機擾動的方法,使得像素值在一定范圍內變化,插值公式如下:
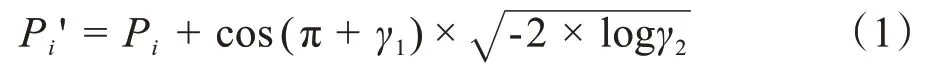
其中,Pi'為插入的像素值,Pi為當前像素值。γ1、γ2為隨機生成的0~1之間的浮點數,加入噪聲后生成的圖像如圖1所示。
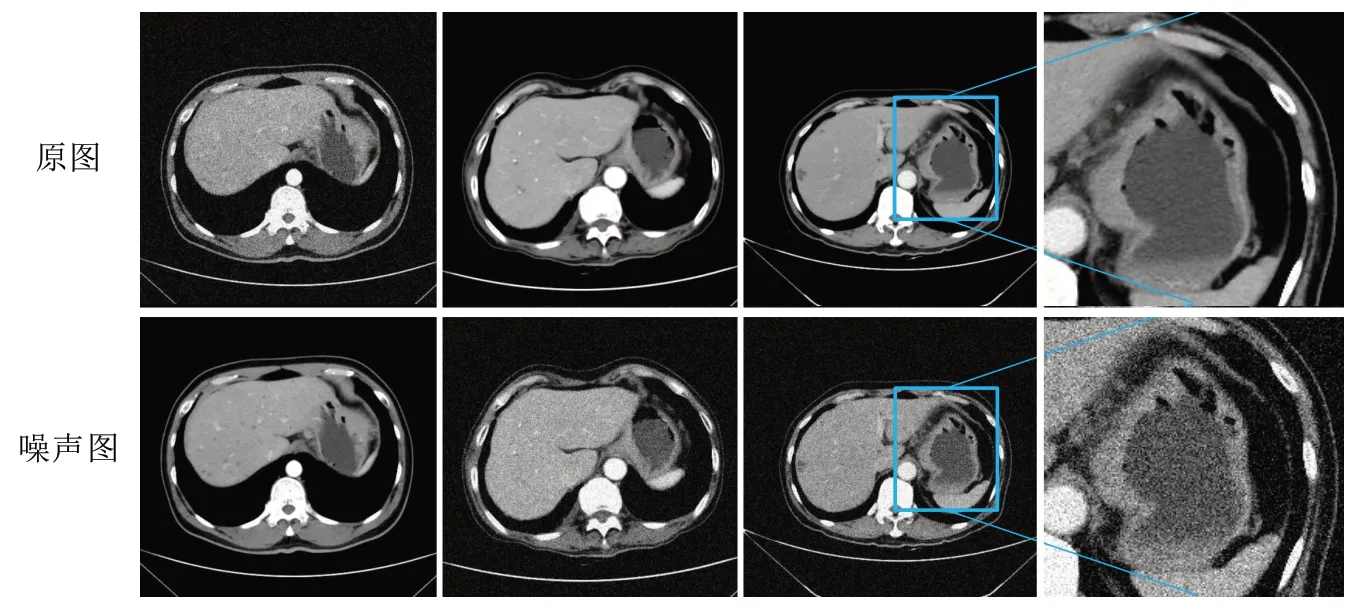
圖1 數據加入噪聲前后對比Fig.1 Comparison of data before and after adding noise
從圖1可以看出,圖像在增加噪聲后,沒有破壞原始圖像的結構與特征。本文通過上述方法對原始數據進行翻倍擴充,最終獲得74組訓練數據,每組數據含有32 張CT 圖像;15 組測試數據,每組有32 張CT圖像。
2.2 改進型V-net網絡框架
本文采用上腹部CT 圖像,從食管開始掃描,向下每隔5 mm 進行一次圖像采集。因此CT 圖像序列可以看作是一個離散的三維圖像。每一層圖像之間具有一定的空間關系,目前的圖像分割網絡在形式上均是編碼-解碼的方式,也稱為下采樣編碼再上采樣解碼,但是傳統的二維卷積網絡在編碼時會丟失大量的空間域信息,因此本文選用的是3D V-net 全卷積神經網絡,3D 卷積神經網絡能夠同時對32 層的CT圖像進行卷積,在學習圖像特征的同時,能夠學習胃壁在各層次之間的位置變化信息。
3D卷積神經網絡是一個含有龐大參數體系的網絡模型,為了使模型更好地發揮其性能,本文方法的整體流程如圖2所示。
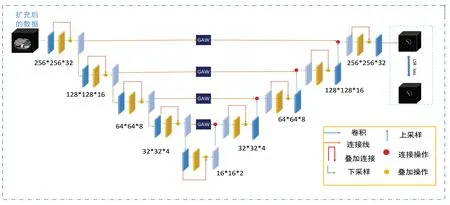
圖2 改進V-net模型訓練原理圖Fig.2 Schematic diagram of improved V-net model training
下采樣過程中,高層特征圖包含語義類別信息,低層特征圖保留圖像細節信息。卷積神經網絡在下采樣的過程中,會丟掉重要的類別信息。隨著下采樣過程的進行,圖像梯度逐漸消失,為了解決該問題,并且保留高層圖像的語義信息,本文將高層的卷積結果通過連接層送入到上采樣過程,但是完全送入上采樣過程無疑增加了訓練難度,本文通過全局平均權重模塊將下采樣過程中的特征圖通過乘以一定的權重值連接到上采樣過程中,具體做法是首先將下采樣過程中前4層輸出的特征圖進行平均池化,然后通過Softmax 函數計算出對應的權重值。計算權重的公式如下:
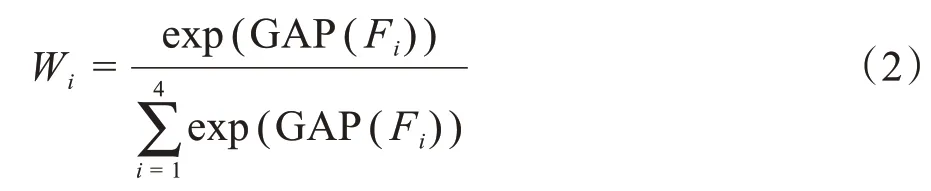
其中,Fi表示第i層的卷積輸出結果。采用全局平均池化(Global Average Pooling,GAP)的目的是為了消除下采樣過程中因尺度不同對權重值產生的影響,采用全局平均權重模塊(Global Average Weight,GAW)有效利用多尺度的特征信息提高了深度學習的學習效率。權重獲取過程如圖3所示。
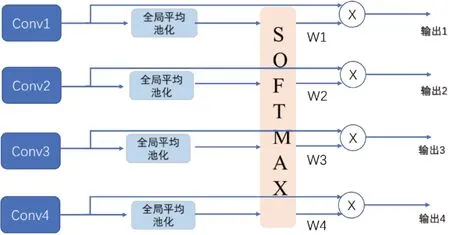
圖3 全局平均權重(GAW)模塊Fig.3 Global average weight module
2.3 損失函數
傳統的醫學圖像分割網絡一般采用交叉熵[12](Cross Entropy, CE)或者Dice coefficient 損失函數(Dice loss)。這些損失函數應用于很多領域,如Shen 等[8]在CT 冠脈分割領域利用Dice loss 取得了較好的結果。但CE或者Dice loss在本研究的胃壁分割中效果均不理想。原因是上述損失函數在尚未獲得準確的胃壁邊緣時就已經陷入了局部最優。
水平集損失函數(LS loss)是Kim 等[13]在2019年提出的一種基于水平集方法的損失函數[14],第一次將水平集方法應用在深度學習網絡的損失函數中。LS loss定義為:
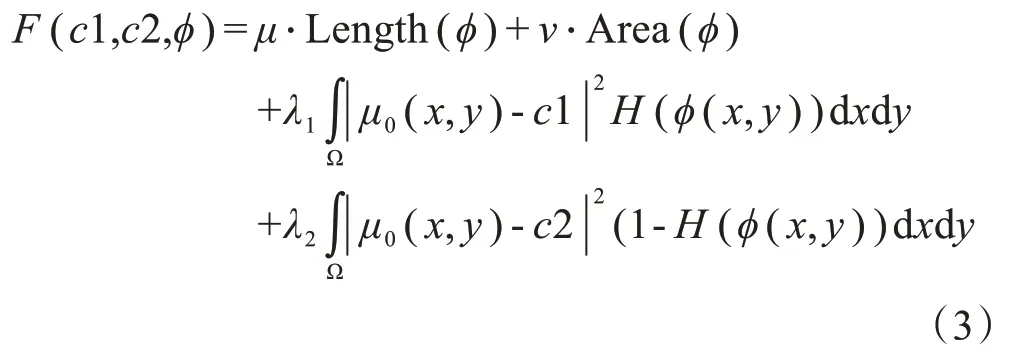
其中,μ≥0,v≥0,λ1,λ2> 0 為定值參數,Ω 是整個圖像區域,φ是水平集函數,c1、c2 是φ= 0 曲線內、外各自像素平均值。Length(φ)和Area(φ)分別表示曲線長度和面積正則化項,μ0(x,y)為圖像中(x,y)處的像素值。H為可微分的階躍函數,其中α為超參數,用于提高函數的梯度,實驗中設置為2.5。
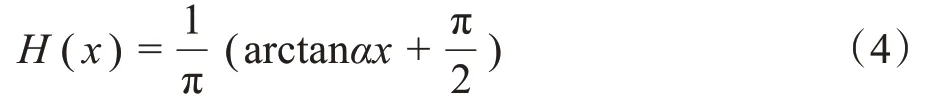
LS loss 的思想是首先利用階躍函數將預測結果和Ground truth 的外壁邊緣以內全部置1,邊緣外部置0,在計算損失時,與預測結果和Ground Truth相乘然后累加求和計算損失,取反后再執行同樣的操作。這樣做的目的是給邊緣加足夠的權重,這種損失函數適用于單外邊緣物體的分割,不適用于胃壁這種內外雙邊緣物體的分割。本文在水平集的基礎上,提出了一種正則化水平集損失函數(LSR loss),可以通過LS loss 優化邊緣的同時,通過正則化來約束胃壁的內部細節特征,較好地發揮了水平集方法和深度學習方法各自的優點。LSR loss定義為:
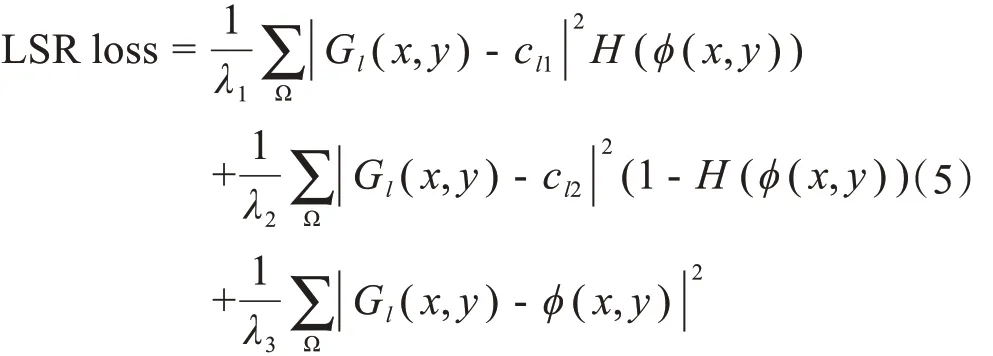
其中,Ω 表示整個圖像區域,GI(x,y)表示Ground Truth 中的像素值,φ(x,y)表示網絡預測出的圖像的像素值。其中:
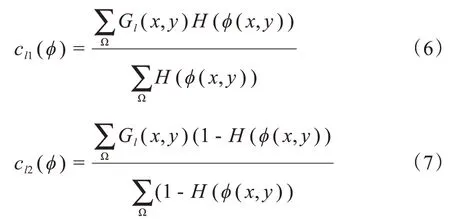
當神經網絡的預測值φ(x,y)與胃壁的對應位置越精確時,cl1、cl2的值會越接近1,那么Ground Truth與其做差就會相當于取反,再與預測值φ(x,y)對應相乘就會接近于0。但是當胃壁邊界有誤差時,該損失值會非常的大,因此本文添加λ1、λ2來約束該損失函數的大小,使其歸一化。實驗時,由于胃壁邊緣權重大,H(φ(x,y))會將預測結果中接近0的像素點置1,導致內部非胃壁區域誤判為1,因此本文在損失函數最后添加了L2正則化項,來約束內部的預測損失,并用參數λ3來約束正則項的大小。
本文提出的損失函數繼承了傳統水平集函數良好的邊緣優化特性,又很好的抑制了過擬合現象。這一方法很好的解決了胃壁外邊緣損失的問題,同時也更好的降低了多器官的容積效應對分割結果的影響。后面的實驗中也證實了使用該損失函數的方法要優于單獨使用水平集損失函數方法。
2.4 評估指標
本文采用的評估指標是Dice 系數和IOU。其中Dice 系數通過計算預測圖像與Ground Truth 之間的匹配度來比較不同分割方法的精確度。IOU 則比較預測圖像與Ground Truth 之間的交集和并集的比值。Dice 系數和IOU 值的范圍都在0~1 之間,數值越高,證明分割的精度越高,計算公式分別如下:
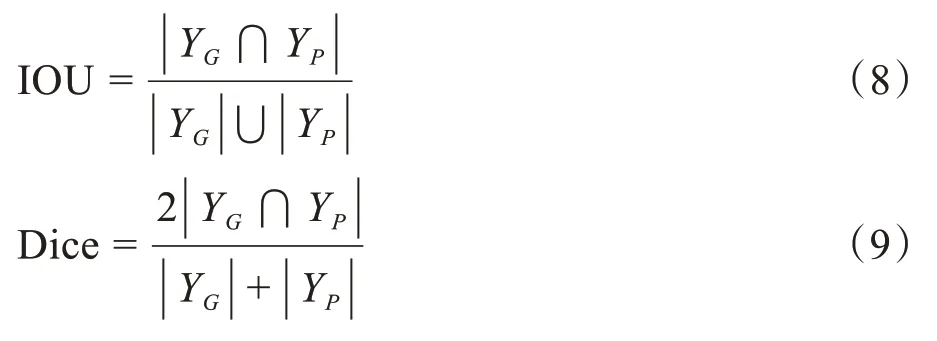
其中,YG代表Ground Truth,Yp代表神經網絡輸出的預測值。
3 實驗
3.1 實驗平臺與數據集
實驗環境:ubuntu16.04 操作系統,英特爾Xeon(至強)E5-2678 v3 處理器,32 GB 內存,Nvidia GeForce GTX 1080 Ti顯卡,實驗網絡使用的Adam優化,初始學習率為0.000 01。訓練2 000個epoch。
數據來自長征醫院醫學影像組,包含52位胃癌患者的醫學診斷圖像,共計1 664張包含胃壁信息的CT數據。擴充后,74組訓練數據作為訓練集,15組作為測試集。每組數據由32張連續大小為256×256像素的CT圖像組成。
本實驗獲取的上腹部CT 圖像有4 個掃描周期:門靜脈期、動脈期、平衡期、延遲期。動脈期主動脈由于靜脈注射的高密度造影劑通過心臟左心室流入動脈,使得動脈密度很高,在CT 上、相對于其他區域顯現出較高亮度。脾臟呈花斑樣,肝動脈有明顯邊界,肝臟一般沒有強化。各器官在動脈期由于造影劑尚未完全到達各器官內血管,胃周動脈會有不均勻強化現象[15]。動脈晚期門靜脈期可以有密度稍高,下腔靜脈及肝靜脈沒有顯示密度升高,腎臟顯示皮質強化明顯,髓質沒有強化。門靜脈期是門靜脈血管充盈顯影期,此時肝臟由于主要由門靜脈供血,而造成肝臟增強,這個時期看門靜脈比較清晰。平衡期是一定時間后血管都已充盈顯影,這個時期的整體腹部血管系統增強顯影。延遲期是影像增強后,隨著時間推移,血管內造影劑持續通過腎臟過濾回流膀胱導致造影劑明顯減少的時期。但如果有腫瘤等富血管組織,由于腫瘤內血管混雜,其內的造影劑衰退比較慢,延遲期腫瘤區域部分造影劑殘留,形成相對高密度區域。充分考慮各時期的特點,本實驗選取了動脈期作為胃壁分割的重要時期。主要考慮到動脈期胃周動脈不均勻強化,使得胃壁和腫瘤與其他組織區域亮度不一致,利用上述方法從動脈期胃部圖像分割出胃壁,可以獲得更好的效果。
3.2 實驗結果
本實驗在本文的數據集之上,分別在不同的網絡上實驗并分析,實驗結果如圖4所示。本文的方法較好的保留了腫瘤區域和胃壁褶皺區域,相對于其他方法也有一定的優勢。其中V-net分割方法誤將水識別為胃壁區域,導致分割效果較差,外邊緣的效果相對于Ground Truth 以及本文的方法也相對差一些。CE-net 的邊緣效果較好,但是個別位置胃壁有缺損,效果相對于本文的方法也略差。本文的方法比較接近Ground Truth,但是腫瘤區域相對于Ground Truth略厚,還是沒有達到很高的精度,有一定的提升空間。而本文的方法,外邊緣由于損失函數計算邊緣的權重較大,相對于其他方法有一定的優勢,整體分割結果也相對較好。
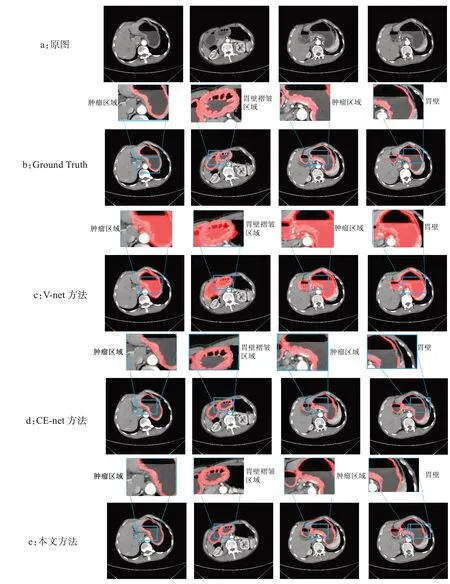
圖4 本文方法胃壁分割的效果展示Fig.4 Results of gastric wall segmentation
評估指標的結果如表1所示。從表1中可以看出,本文網絡結構平均Dice相對于采用LS loss的V-net分割結果提升了6%,相對于最新的CE-net 和Dense U-net 也都有一定的優勢,其中相對于CE-net 提升了2.7%,相對于Dense U-net提升了3.1%。
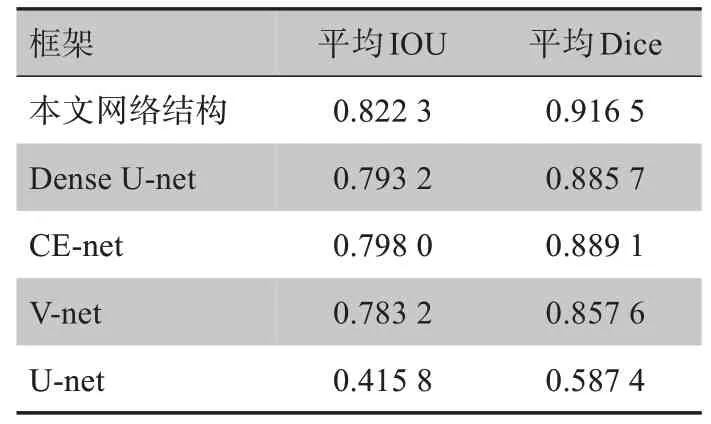
表1 不同網絡結構分割結果對比Tab.1 Comparison of segmentation results obtained by different network structures
3.3 消融實驗
為了驗證各模型的功能及作用,本文采用消融研究的方法去驗證各個模型在框架中起到的作用,本文的消融研究方法在基礎框架之上,按圖5的順序逐步添加各個模塊,實驗結果如圖5所示。
其中,圖5a是原始的CT影像;圖5b是普通的V-net網絡加交叉熵損失函數(CE loss)的方法;圖5c是V-net網絡加LS loss 的分割方法;圖5d 是數據擴充后加入LSR loss 的結果;圖5e 為在前面的基礎之上加入GAW 模塊的實驗結果;圖5f 為Ground Truth。從圖5b 可以看出,原始的分割方法很難學到胃壁的邊緣信息,從而使得分割效果不佳,在圖5c 加入LS loss后,邊緣信息比較完整,但是內壁邊緣有較嚴重的過擬合現象,圖5d 在擴充數據的同時,加入LSR loss 再加入L2正則化后,胃壁內邊緣開始有所增強,補全了單獨使用LS loss 學習導致的胃壁缺失部分,但是在優化的同時,胃壁出現了缺損。最后圖5e 在加入GAW 模塊后,缺失有所改善。通過對比,可以發現,本文提出的方法很好的實現了胃壁分割。而水平集損失函數對外邊緣的區域優化明顯。
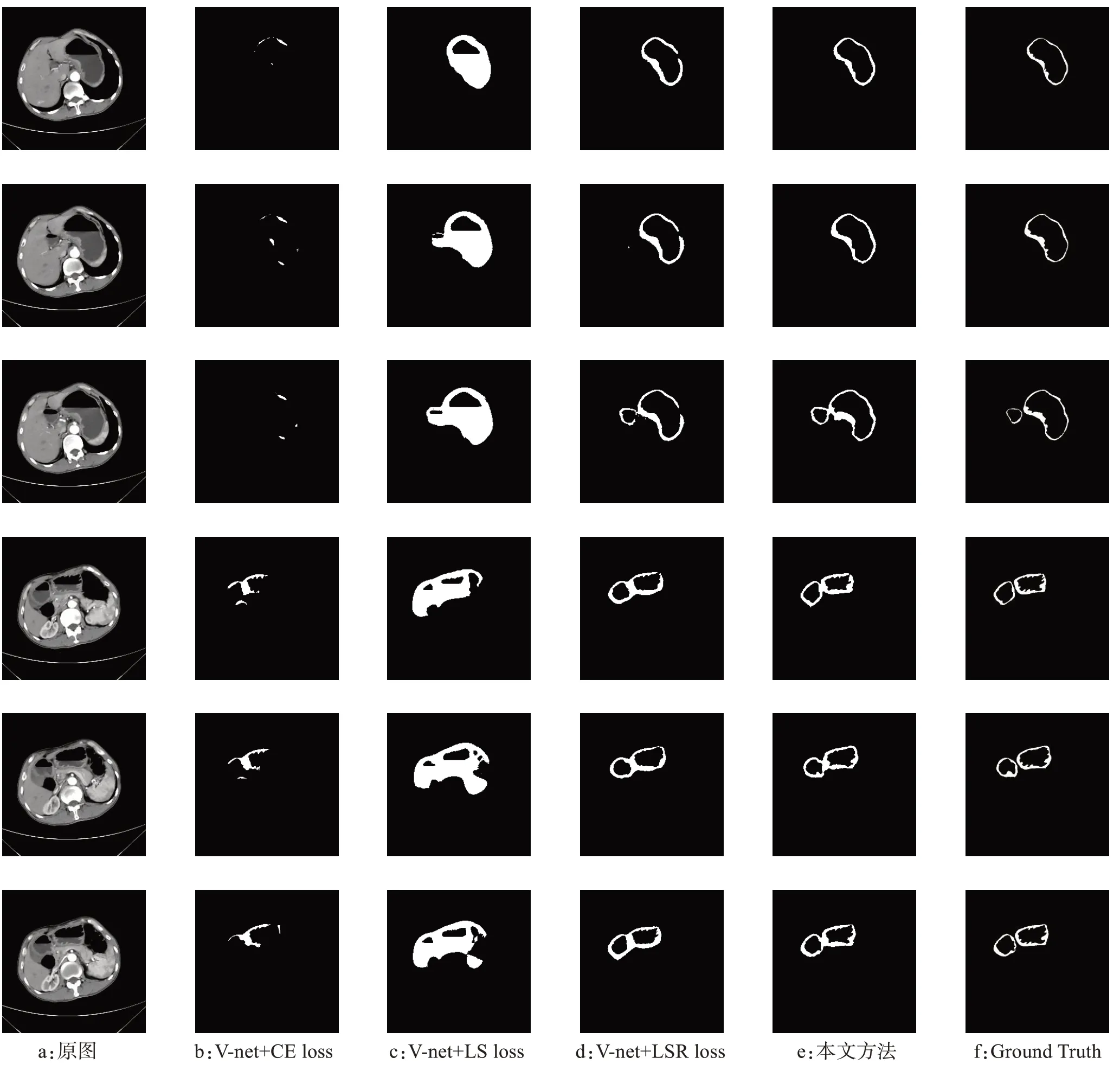
圖5 消融實驗結果對比Fig.5 Comparison of ablation results with ground truth
消融分析的具體實驗數據見表2。從表2可以看出,各模塊對效果都有一定的提升,尤其是數據擴充后加入LSR loss,相對于只加入LS loss平均Dice提高了4%。最后加入GAW模塊也有1.9%的提升。
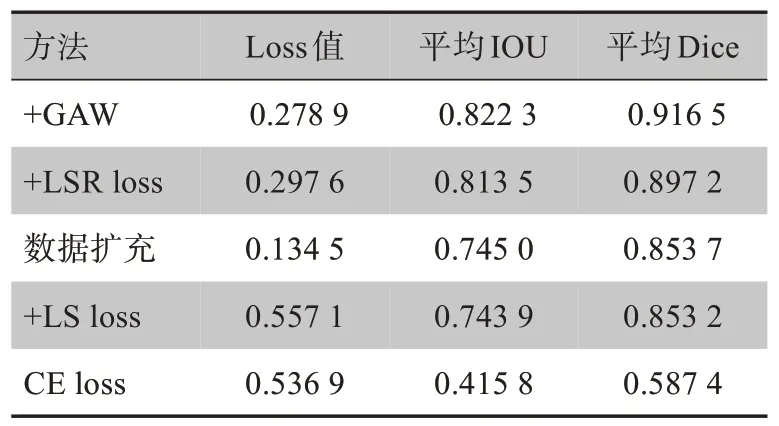
表2 消融分析Tab.2 Ablation analysis
4 結束語
通過上述實驗數據對比,本文提出的方法在胃壁分割領域取得了較高的分割精度,可完整的保留胃壁邊緣與腫瘤信息,并且能夠在一定程度上識別胃壁褶皺區域。本文提出的方法較好的保留了原始CT圖像的信息,很好的解決了數據量較少的問題,引用GAW 模塊很好的解決了下采樣過程的類別信息損失問題,采用正則化損失函數更好的保留了胃壁的邊緣信息并很好的抑制了過擬合。本文的方法為胃癌腫瘤分期研究奠定了良好的基礎。但是本文的方法中參數和運算復雜度略高于其它方法,主要是因為本文采用3D 卷積以及更復雜的損失函數,因此本文的方法還有進一步的優化空間。因此,我們還會在此基礎上深入研究,找到更好的方法,并下一步計劃實現胃癌T 分期,為中國醫療事業貢獻出綿薄之力。
猜你喜歡
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中華手工(2017年2期)2017-06-06 23:00:31
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
祝您健康(1987年2期)1987-12-30 09:52:28