電子鼻檢測常見傷口感染細菌實驗研究
2021-11-04 06:28:58陸彥邑曾琳嚴博文黎敏何慶華
中國醫(yī)學(xué)物理學(xué)雜志 2021年10期
關(guān)鍵詞:檢測
陸彥邑,曾琳,嚴博文,黎敏,何慶華
陸軍軍醫(yī)大學(xué)大坪醫(yī)院/國家創(chuàng)傷燒傷復(fù)合傷重點實驗室,重慶400042
前言
電子鼻是一種利用氣體傳感器陣列來檢測和識別物質(zhì)氣味的檢測技術(shù),其核心部件是各種類型的氣體傳感器。由多個傳感器對檢測物質(zhì)的響應(yīng)構(gòu)成了傳感器陣列對該氣味的響應(yīng)數(shù)據(jù),不同類別的物質(zhì)形成不同類別的數(shù)據(jù),采用合適的模式識別方法可對信號進行分類和識別[1-2]。
基于傳感器的多樣化,電子鼻可用于醫(yī)學(xué)診斷[3]、環(huán)境監(jiān)測[4]、食品檢測[5-6]等領(lǐng)域,具有廣泛的應(yīng)用價值。在醫(yī)學(xué)診斷領(lǐng)域,傷口感染檢測在臨床工作中極其重要,但傳統(tǒng)傷口感染檢測方法速度較慢,無法迅速確定傷口感染類型,快速有效的檢測手段能極大地提高治療效率。臨床中傷口感染細菌種類繁多,常見的有大腸桿菌、金黃色葡萄球菌、銅綠假單胞菌、鮑曼不動桿菌、肺炎克雷伯桿菌等。電子鼻用于傷口感染檢測早已有研究,涉及到的細菌有大腸桿菌和銅綠假單胞菌[7-8]、金黃色葡萄球菌[7-10]、糞腸球菌[11]、梭菌屬和脆弱擬桿菌[12]等。國內(nèi)對電子鼻用于傷口細菌感染檢測已有較多的研究[13-15],主要涉及到大腸桿菌、金黃色葡萄球菌、銅綠假單胞菌3種細菌。
本文在現(xiàn)有的研究基礎(chǔ)上,使用自制電子鼻檢測臨床中的5 種常見傷口感染細菌(大腸桿菌、金黃色葡萄球菌、銅綠假單胞菌、鮑曼不動桿菌、肺炎克雷伯桿菌)的細菌培養(yǎng)液,并使用模式識別算法進行細菌的分類識別,以期為傷口感染的快速檢測提供更多的可能性。
1 實驗
1.1 實驗裝置
采用重慶大學(xué)自制電子鼻裝置作為電子鼻檢測儀器[16],如圖1所示。該電子鼻系統(tǒng)分為樣品單元、檢測單元和控制單元3 個部分。傳感器陣列包括1個溫度傳感器、1個濕度傳感器、1個氣壓傳感器、1個電壓傳感器和30個氣體傳感器(其中傳感器GSBT-11已損壞)。采集過程分為基線采集、樣本采集、系統(tǒng)清潔3 個階段,采集頻率1 Hz。實驗時3 個階段設(shè)置時長分別為180、180、240 s,共600 s。重復(fù)實驗,以收集更多的樣本。

圖1 自制電子鼻實驗裝置Fig.1 Experiment device of self-made electronic nose
1.2 實驗樣品
本實驗有6 種樣品:使用巰基乙酸酯(Thioglycolate,TH)培養(yǎng)液培養(yǎng)的大腸桿菌、金黃色葡萄球菌、銅綠假單胞菌、鮑曼不動桿菌、肺炎克雷伯桿菌的細菌培養(yǎng)液及純TH 培養(yǎng)液,其中大腸桿菌(ATCC25922)、金黃色葡萄球菌(ATCC25923)、銅綠假單胞菌(ATCC27853)為陸軍軍醫(yī)大學(xué)大坪醫(yī)院檢驗科提供的ATCC 標準菌株,肺炎克雷伯桿菌為陸軍軍醫(yī)大學(xué)大坪醫(yī)院檢驗科提供的從臨床患者傷口分泌物中分離出來的菌株,鮑曼不動桿菌(ATCC19606)為陸軍軍醫(yī)大學(xué)西南醫(yī)院燒傷科提供的標準菌株。所有細菌均轉(zhuǎn)種至規(guī)格為5 mL 的TH培養(yǎng)液中培養(yǎng)16~20 h得到用于檢測的細菌培養(yǎng)液。
2 數(shù)據(jù)處理
基于儀器特性,本研究所用的電子鼻典型傳感器響應(yīng)曲線(傳感器MQ135)如圖2所示,每一個傳感器有一組響應(yīng)曲線,共600個數(shù)據(jù)點。
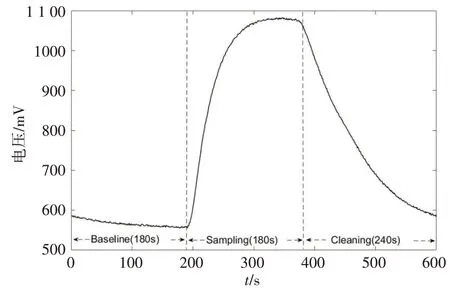
圖2 典型的傳感器響應(yīng)曲線Fig.2 A typical response curve of a sensor
傳感器GSBT-11 已損壞,溫度傳感器、濕度傳感器、氣壓傳感器及電壓傳感器響應(yīng)較為恒定,因此剔除這5 個傳感器的響應(yīng)數(shù)據(jù),使用剩余29 個傳感器響應(yīng)數(shù)據(jù)進行分析。每一個類別每個傳感器均有一組響應(yīng)數(shù)據(jù),一組響應(yīng)數(shù)據(jù)有600 個數(shù)據(jù)點,因此原始樣本數(shù)據(jù)維度為m× 600 × 29,m為收集到的樣本組數(shù),600 為一組數(shù)據(jù)的長度,29 為傳感器個數(shù)。本研究中,每類樣本各收集到200組數(shù)據(jù),m=1 200。由于原始樣本數(shù)據(jù)量較大且存在干擾,因此對樣本數(shù)據(jù)先進行預(yù)處理再進行分類識別,數(shù)據(jù)處理流程見圖3。
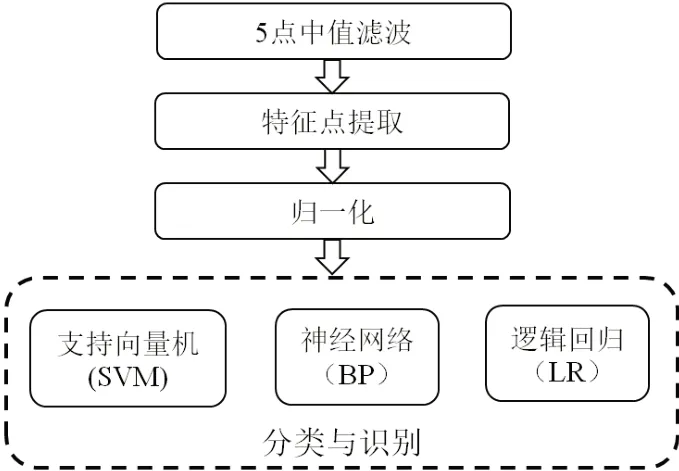
圖3 數(shù)據(jù)處理流程圖Fig.3 Flowchart of data processing
2.1 預(yù)處理
2.1.1 濾波實驗數(shù)據(jù)存在異常干擾,對于每個傳感器的每一組響應(yīng)數(shù)據(jù),按傳感器依次采用5點中值濾波來減小干擾。
2.1.2 特征點提取濾波后,對于每個傳感器的響應(yīng)數(shù)據(jù)v=(v1,v2,…,v600)T,特征點xfeature提取方法如下:

其中,vmax為響應(yīng)曲線中樣本采集階段的最大值,vbaseline為響應(yīng)曲線中基線采集階段其中一段的平均值,定義如下:
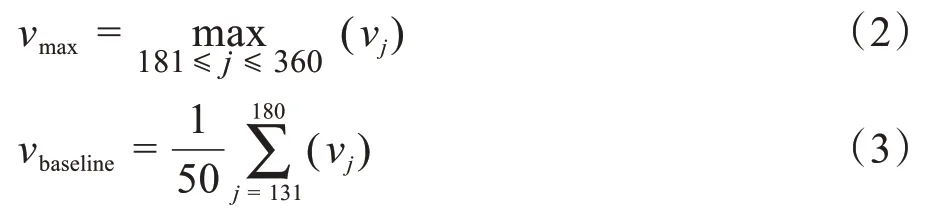
對每個樣本的一組數(shù)據(jù),有多少個傳感器就有多少個特征點,此時一組完整的傳感器相應(yīng)特征點可表示如下:

其中,n為特征點總數(shù)。
2.1.3 歸一化特征點提取后的樣本數(shù)據(jù),依然按組進行歸一化,方法如下:

2.2 分類與識別
經(jīng)過以上處理的數(shù)據(jù),去除了干擾,提取了特征點,可進行樣本的分類和識別。使用邏輯回歸(Logistic Regression, LR)、BP(Back propagation)神經(jīng)網(wǎng)絡(luò)、支持向量機(Support Vector Machine,SVM)3種算法對6種樣品進行分類識別。
2.2.1 LRLR是一種根據(jù)預(yù)測函數(shù)hθ(x)來實現(xiàn)二分類的分類算法,通過樣本訓(xùn)練得到預(yù)測函數(shù),后使用預(yù)測函數(shù)對未知樣本進行預(yù)測和歸類。hθ(x)定義如下:
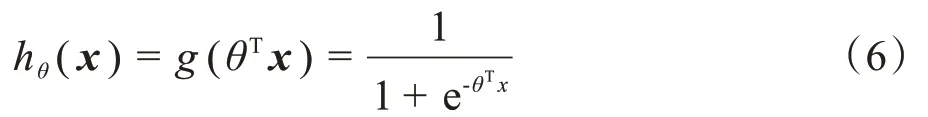
x為樣本特征向量,θ為各個特征的參數(shù)。當hθ(x) ≥0.5 時,樣本屬于正類(第一類);hθ(x) < 0.5時,樣本屬于反類(第二類)。
模型的損失函數(shù)為:
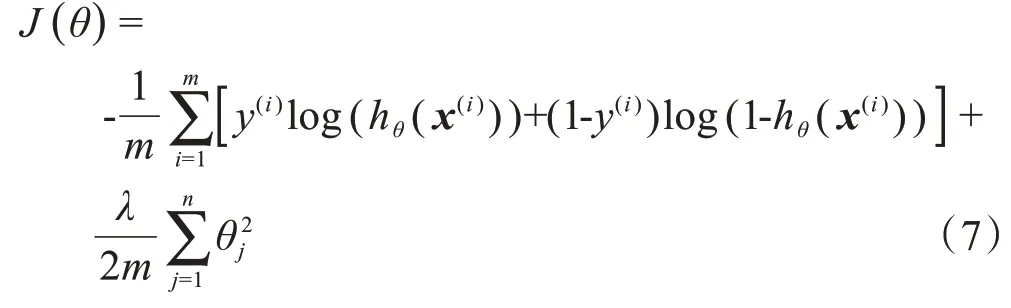
其中,m為訓(xùn)練樣本總數(shù),n為特征總數(shù)。為避免過擬合,引入正則化項,λ為正則化系數(shù)。損失函數(shù)用于評估預(yù)測的準確性,損失函數(shù)值越小,代表預(yù)測越準確。可使用梯度下降算法對J(θ)求偏導(dǎo)數(shù),尋找最優(yōu)的θ使得J(θ)最小,此時的預(yù)測函數(shù)hθ(x)即為最優(yōu)預(yù)測函數(shù)。
本研究屬于多分類問題,可以使用一對多(onevsrest)的方式對每個類別訓(xùn)練一個二元分類器:對類別①,類別①為正類,其余為反類,搭建二分類器h1θ(x);對類別②,類別②為正類,其余為反類,搭建二分類器h2θ(x)。對需要預(yù)測的新樣本,依次使用以上二分類器預(yù)測輸出,輸出值最大的那組預(yù)測結(jié)果即為新樣本的所屬類別。
2.2.2 BP神經(jīng)網(wǎng)絡(luò)BP網(wǎng)絡(luò)即反向傳播網(wǎng)絡(luò),是目前應(yīng)用非常廣泛的神經(jīng)網(wǎng)絡(luò)模型之一。神經(jīng)網(wǎng)絡(luò)典型結(jié)構(gòu)如圖4所示,分為輸入層、隱含層、輸出層。BP網(wǎng)絡(luò)的訓(xùn)練過程可分為前向傳播和反向傳播兩個過程。前向傳播根據(jù)輸入的樣本特征向量(x1,x2,…,xn),通過各隱含層的權(quán)重值w和偏置項b計算輸出值(y1,y2,…,yc),以及輸出值與實際值之間的誤差項δ,其中,c為總類別數(shù)。若誤差值在給定范圍內(nèi),則網(wǎng)絡(luò)訓(xùn)練完畢。若誤差項不在給定的范圍內(nèi),則進行反向傳播,通過誤差項δ回傳給各級隱含層,重新計算各級的權(quán)重值w和偏置項b,數(shù)次迭代直到誤差項在給定范圍內(nèi),此時網(wǎng)絡(luò)訓(xùn)練完畢。
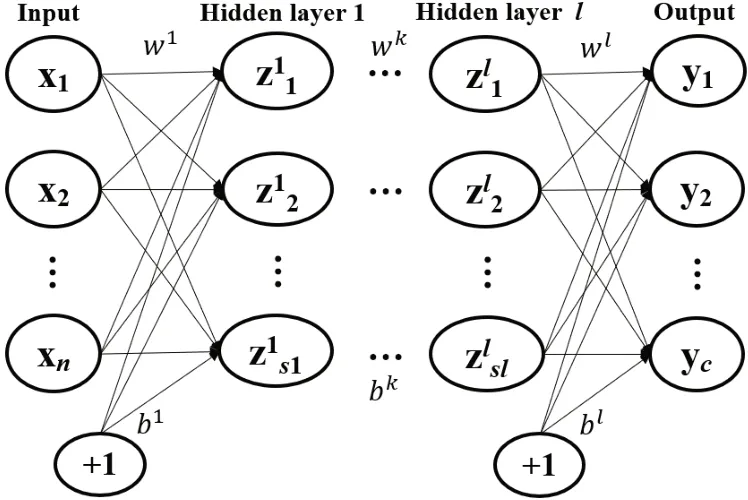
圖4 BP神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)圖Fig.4 Structure of BP neural network
設(shè)隱含層共有l(wèi)層,各隱含層節(jié)點數(shù)為(s1,s2,…,sl),zk、hk、f(zk)分別為第k層的節(jié)點值、輸出值、激活函數(shù),k=(1,2,…,l),則各隱含層的節(jié)點值和輸出值計算如下:
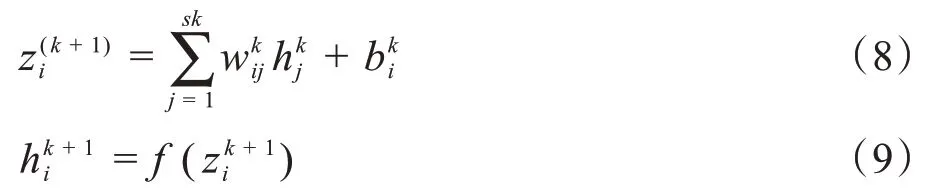
其中,zi(k+1)為第(k+ 1)層第i個節(jié)點的值,wkij為第k層第i個節(jié)點上第j個輸入的權(quán)重值,bki為第k層第i個節(jié)點的偏置項值。給定各級網(wǎng)絡(luò)初始權(quán)重值和偏置項值,根據(jù)以上公式即可算出各級隱含層和輸出層的節(jié)點值和輸出值。
網(wǎng)絡(luò)訓(xùn)練方法有多種,常見的訓(xùn)練方法有梯度下降法、共軛梯度法、擬牛頓算法、列文伯格-馬夸爾特法(Levenberg-Marquardt, LM)法等。網(wǎng)絡(luò)訓(xùn)練完畢,將待測試的樣本輸入網(wǎng)絡(luò),即可預(yù)測出其類別。
2.2.3 SVMSVM本身是一個二分類器,其目的是找到一個最優(yōu)超平面,使兩類數(shù)據(jù)點正確地分在超平面的兩側(cè)。如圖5所示,樣本線性可分時,可以用一條直線(在高維空間則是一個決策曲面)把兩類樣本分開。圖5中虛線上的點稱為支持向量,當兩類樣本的支持向量到該直線(決策曲面)的間隔d最大時,該直線(決策曲面)即為最優(yōu)超平面。決策曲面定義如下:
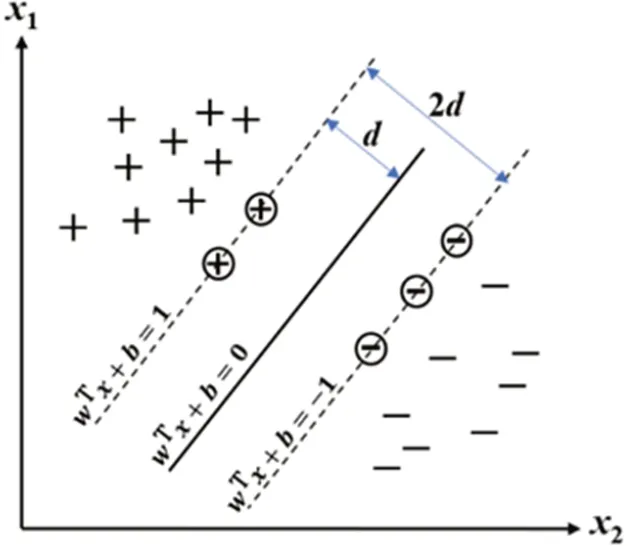
圖5 支持向量機原理圖Fig.5 Schematic diagram of support vector machine

其中,x為樣本特征向量;w為可調(diào)權(quán)值;b為偏置,代表決策面相對于原點的偏移。求解決策曲面的過程即是尋找最優(yōu)超平面的過程。經(jīng)過計算可得間隔d:

因此,最大化d等價于最小化權(quán)值向量w的歐幾里得范數(shù)‖w‖。最終計算可得:

其中,αi是拉格朗日乘子;xi表示特征向量x中某一個特征值,i=(1,2,…,n),n表示特征向量維度;yi表示相應(yīng)類的標識,yi為+1 時代表第一類(正類),yi為-1時代表第二類(反類)。式(12)作為SVM的支持向量和最優(yōu)超平面分類器。多數(shù)情況下,樣本是線性不可分的,此時可以通過核函數(shù)將樣本映射到高維空間,變?yōu)榫€性可分樣本再進行分類。常見的核函數(shù)有線性核、多項式核、徑向基函數(shù)核(Radial Basis Function,RBF)以及sigmoid核。
當使用SVM 用于多分類時,本文采用一對一的方式進行分類。其實現(xiàn)方式是用SVM對任意兩類設(shè)計一個二分類器,從而得到c(c- 1)/2 個二分類器,c為總類別數(shù)。對于一個需要分類的樣本,用所有二分類器對其進行預(yù)測,得票最多的類別即為該樣本所屬類別。
3 結(jié)果與討論
3.1 樣品檢測結(jié)果
在同一實驗條件下,使用電子鼻檢測6種樣品,6種樣品的典型電子鼻雷達圖譜如圖6所示,可看出6種樣品各有其圖譜特征。
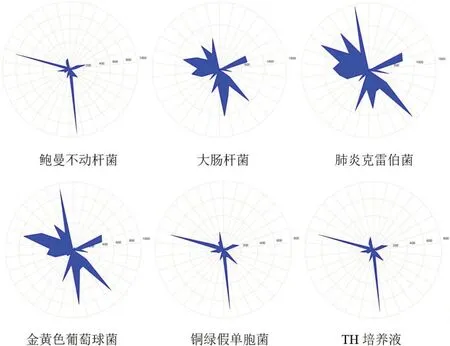
圖6 6種樣品電子鼻雷達圖譜Fig.6 Radar patterns of 6 types of samples detected by electric nose
3.2 數(shù)據(jù)處理結(jié)果
6 類樣品每類共收集到200 組樣本數(shù)據(jù),經(jīng)過濾波、特征值提取和歸一化的預(yù)處理后得到了200×29的特征值矩陣。
對于每類的200 組樣本數(shù)據(jù),隨機選取其中100組為訓(xùn)練集,剩余100 組為測試集,分別使用SVM、BP、LR 來進行分類識別。經(jīng)過多次實驗可分別得到3 種算法的最優(yōu)參數(shù):BP 選擇一層隱含層,隱含層節(jié)點數(shù)為輸入層的1.5 倍,隱含層和輸出層的激活函數(shù)分別為tan-sigmod 和purelin,網(wǎng)絡(luò)訓(xùn)練方法為LM 算法;SVM 算法的核函數(shù)類型為RBF 核;為避免擬合,LR 引入正則化參數(shù),參數(shù)最優(yōu)值為1。由于訓(xùn)練樣本為隨機選取,因此每一次運行識別率略有不同,運行10次取平均可得平均識別率,見表1。
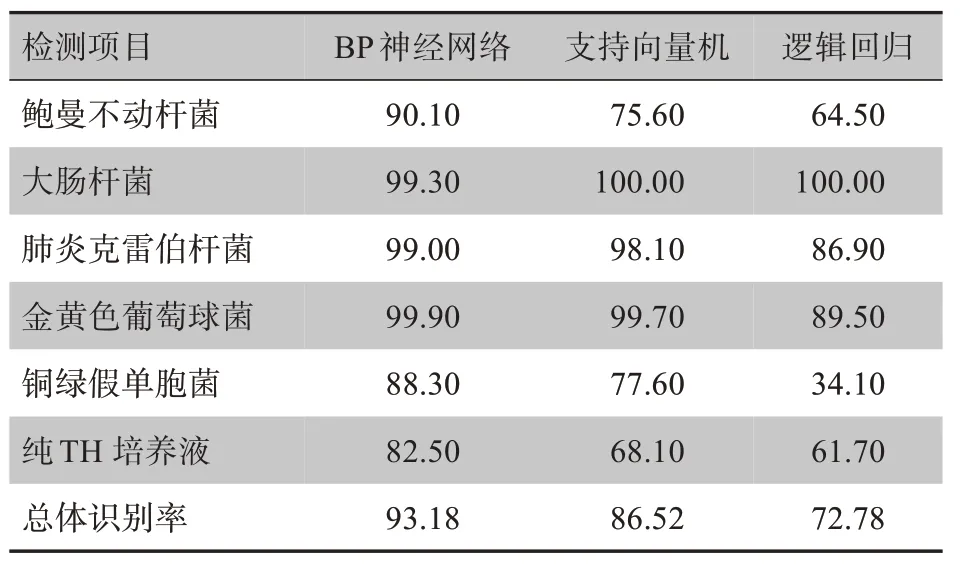
表1 3種算法平均識別率(%)Tab.1 Average recognition rates of 3 algorithms(%)
3種算法中,總體識別率BP最高(93.18%),SVM次之(86.52%),LR 最低(72.78%)。對于單個類別的識別率,BP 依然最高。從單個類別識別率可看出,BP 和SVM 對大腸桿菌、肺炎克雷伯桿菌和金黃色葡萄球菌具有良好的識別效果,能達到98%以上。鮑曼不動桿菌和銅綠假單胞菌識別率不如以上3 種細菌,但使用BP 算法也能達到88%以上。以上結(jié)果表明,對于常見傷口感染細菌的培養(yǎng)液,使用BP算法識別率和可分性更高。
本研究為電子鼻用于快速篩查常見傷口感染細菌類型提供了一定的實驗基礎(chǔ)和可行性,但也有其局限性,需改進和繼續(xù)研究的地方有以下兩個方面。一是傳感器數(shù)量較多,可能存在冗余,需要篩選和優(yōu)化傳感器組合以減小傳感器部分體積和復(fù)雜度。二是本研究只對細菌培養(yǎng)液進行了檢測,實際的臨床傷口細菌感染是復(fù)雜且多樣的,需進一步開展臨床樣本研究,探索更多的可能性。
4 結(jié)論
本研究使用自制電子鼻檢測大腸桿菌、金黃色葡萄球菌、銅綠假單胞菌、鮑曼不動桿菌、肺炎克雷伯桿菌細菌培養(yǎng)液和純TH培養(yǎng)液共6種樣品,得到具有各自圖譜特征的電子鼻雷達圖譜。對6類樣本數(shù)據(jù)進行預(yù)處理和提取特征后,使用SVM、BP、LR 3種算法進行了分類識別。結(jié)果表明,BP算法識別效果最好,SVM次之,LR最低,提示BP算法對大腸桿菌、肺炎克雷伯桿菌、金黃色葡萄球菌、鮑曼不動桿菌、銅綠假單胞菌的細菌培養(yǎng)液具有良好的可分性,為電子鼻用于傷口細菌感染類型的快速篩查進一步提供了可能性。
猜你喜歡
中國設(shè)備工程(2022年12期)2022-07-11 04:33:00
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年9期)2019-11-25 07:34:36
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年9期)2019-11-25 07:34:34
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年12期)2019-05-21 02:53:50
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年12期)2019-05-21 02:53:48