缺失標記下基于類屬屬性的多標記特征選擇
2021-11-05 01:29:12張志浩林耀進王晨曦
計算機應用 2021年10期
張志浩,林耀進*,盧 舜,郭 晨,王晨曦
(1.閩南師范大學計算機學院,福建漳州 363000;2.數據科學與智能應用福建省高校重點實驗室(閩南師范大學),福建漳州 363000)
0 引言
多標記學習廣泛應用于機器學習、數據挖掘和模式識別等應用領域[1-3],多標記學習是指構建一個分類模型,將由特征向量描述的樣本映射到多個類標記[4]。例如,在圖像標注中,一幅圖像可能同時具有“湖泊”“房屋”和“藍天”等多個語義;在疾病診斷過程中,每個候診病人可能同時具有心臟病、糖尿病和高血壓等多種慢性疾病;在新聞網頁分類中,一則體育報告同時含有多個相關主題,如:“籃球”“比賽”和“庫里”。
同傳統單標記學習一樣,多標記數據的特征空間通常具有成千上萬個特征[5-6]。例如,從圖像中可以提取出數千個特征來表示其復雜的語義信息;然而,對于分類學習任務來說,許多特征是無關或者冗余的,并且這些無關或冗余特征往往給學習算法帶來計算負擔、性能不佳和過度擬合等問題。為處理該問題,相應的多標記特征選擇算法被提出,用于降低多標記數據的高維性,以及提高分類算法的泛化性能。根據現有研究工作,可將多標記特征選擇算法分成三大類:嵌入式、包裝式和過濾式。嵌入式方法將特征選擇過程嵌入到分類學習過程中,Zhang等[7]提出基于流形正則項約束的多標記特征選擇算法;包裝式方法需利用特定算法或模型評估特征子集,Gharroudi等[8]提出基于隨機森林和標記依賴性的多標記特征選擇算法;過濾式方法利用統計度量(如信息熵)評價特征,且該過程與分類器學習過程相互獨立,Lin 等[9]提出通過最大化特征的依賴度并同時最小化特征間的冗余度來進行特征選擇。
為提高多標記學習算法的性能,尋找每個標記對應的類屬屬性比利用所有屬性進行分類更有效,即每個類標記往往與原始特征空間中一個特定的特征子集密切關聯,該特征子集稱為類屬屬性[10]。例如,在新聞分類中,“足球”“籃球”“奧運會”這類詞(特征)能鑒別一則新聞是否是體育類新聞,而“股市”“貨幣”“證券”等詞能鑒別一則新聞是財經類還是非財經類新聞。標記的類屬屬性是一組與該標記最相關、可辨別性最強的特征子集,可有效地挖掘類屬屬性與標記間的聯系。因此,標記的類屬屬性能為多標記學習提供更加有價值的信息。
現有多標記特征選擇方法一般假設訓練樣本的標記空間為完備的,并未考慮到標記缺失的情況,即訓練樣本的整個標記空間是提前給定的[7-9]。然而,在實際任務中獲得完整的標記空間是非常困難的,原因在于為每個樣本打上所有的類標記需要花費大量的人力物力;另外,類標記之間的歧義性容易導致漏標情況的出現。眾所周知,標記空間的缺失會破壞原有的語義結構,使得標記的語義發生一定程度的變化,導致對挖掘標記之間的關系產生負面影響。為了解決缺失標記所帶來的影響,根據多標記信息熵、線性回歸和標記一致性等理論,許多缺失標記環境下的多標記特征選擇算法被提出。例如,Wang 等[11]定義多標記信息熵和多標記互信息兩個新概念,并運用特征交互進行特征選擇;Zhu 等[12]運用魯棒的線性回歸模型選擇最具區分性的特征,并且在特征選擇的同時恢復缺失標記;Wu 等[13]用零元素為無符號標記定義缺失標記,利用標記一致性和標記平滑度假設重構不完整的標記矩陣。上述算法在處理缺失標記環境下的特征選擇問題上具有一定成效,但未考慮每個類標記具有固有類屬屬性的情況,并且也未考慮如何利用標記固有類屬屬性恢復缺失標記。
根據以上分析可知,利用每個類標記的類屬屬性對提高缺失標記環境下多標記特征選擇算法性能具有重要意義。基于類屬屬性固有性質,利用樣本具有相同的特征值往往擁有一致標記的準則來最小化真實標記與預測標記間的差異,可實現缺失標記恢復。為此,本文提出一種缺失標記下基于類屬屬性的多標記特征選擇(Multi-label Feature Selection based on Label-specific feature with Missing Labels,MFSLML)算法。該算法主要貢獻如下:首先,通過稀疏學習方法為每個類標記選擇類屬屬性;然后,在此基礎上,利用線性回歸模型構建標記與其類屬屬性的映射關系,用于恢復缺失的標記空間;最后,在7 組數據集上的實驗結果表明,與現有特征選擇算法相比,MFSLML性能更優。
1 所提模型
在多標記學習中,X=[x1,x2,…,xN]T代表樣本的特征空間,其中xi∈Rd,d為特征維度,代表第i個樣本共有d個特征;Y=[y1,y2,…,yN]T代表樣本的標記空間,其中yi∈Rl,l為標記個數,所以N個樣本可以表示為:S={(xi,yi)}。將標記值設置為yij=1、yij=0和yij=-1,yij表示矩陣Y中第i行第j列的元素,如果第i個樣本具有第j個標記,則yij=1,反之,yij=-1,如果yij=0則無法明確第i個樣本是否具有第j個標記,表示該標記缺失。
在本章中,提出一種缺失標記下基于類屬屬性的多標記特征選擇算法,該算法主要有兩個步驟:首先,考慮到每個類別標記具有固有類屬屬性,因此通過稀疏學習方法為每個類別標記選擇固有類屬屬性;其次,為恢復缺失標記,根據所選類屬屬性,利用線性回歸模型構建標記與其類屬屬性的映射關系用于恢復缺失標記。
1.1 類屬屬性學習
在實際多標記分類任務中,標記空間中每個類標記只與特征空間中一個特定的特征子集相關。于是,在特征選擇過程中,可采用線性回歸模型和平方損失函數學習一個特征權重的系數矩陣W。為保證選擇的特征數量少且有代表性,在系數矩陣W上添加?1范數正則項,則目標函數為:
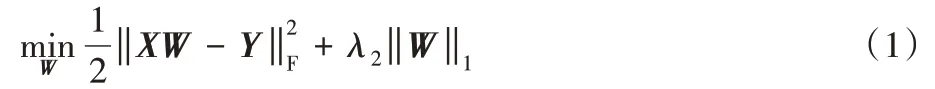
其中:X是樣本的特征矩陣,Y是標記隨機缺失的標記矩陣,W是學習得到的系數矩陣,λ2是參數。對于矩陣W,第i行表示為wi,第j列表示為wj,wij代表第i行第j列的元素值。wj中的非零元素決定了每個類標記的類屬屬性:若wij=0則表示第i個特征和第j個標記沒有任何聯系;若wij≠0,則表示第i個特征對于第j個標記具有鑒別能力。
1.2 缺失標記下基于類屬屬性的多標記特征選擇
標記空間不完整會破壞原有語義結構,導致無法完整構建類屬屬性,使得樣本特征信息難以準確刻畫標記信息。針對缺失標記問題,采用恢復缺失標記的方法進行處理。首先,定義一個新矩陣Y*,在標記已知處,令在標記缺失處,設值為0。其次,在每一次迭代過程中,根據式(2)用學習得到的系數矩陣W以及特征矩陣X,更新Y*=XW中的缺失值,更新后的Y*將用于后續迭代過程。最后,利用式(3)將標記恢復成離散值,并令Y=Y*。

同時,為提高模型準確率,根據特征值相近的兩個樣本具有一致類別標記的準則,故目標函數可重寫為:

其中:tr((XW)TL(XW))代表一致性準則,L是Laplacian 矩陣,λ1和λ2是參數。參數λ1是控制模型中一致性準則的系數,而參數λ2控制每個類別標記固有類屬屬性的稀疏性。
為了清晰地闡述模型的計算過程,下文給出一個計算實例進行說明。


1.3 模型優化
由于式(4)中存在?1范數正則項,且?1范數是不光滑凸優化問題,因此,可利用加速近端梯度方法[14]進行求解,于是式(4)可變化為如下表達式:

由于f(W)是一個凸優化問題,g(W)是一個不光滑凸優化問題,故上述優化問題可以轉換成二次逼近序列優化問題進行求解:

1.3.1 更新W
在式(4)中優化目標只有一個未知變量W,故采用迭代優化方法進行求解。因式(5)中存在不光滑凸優化目標,則可定義以下優化目標求解W:

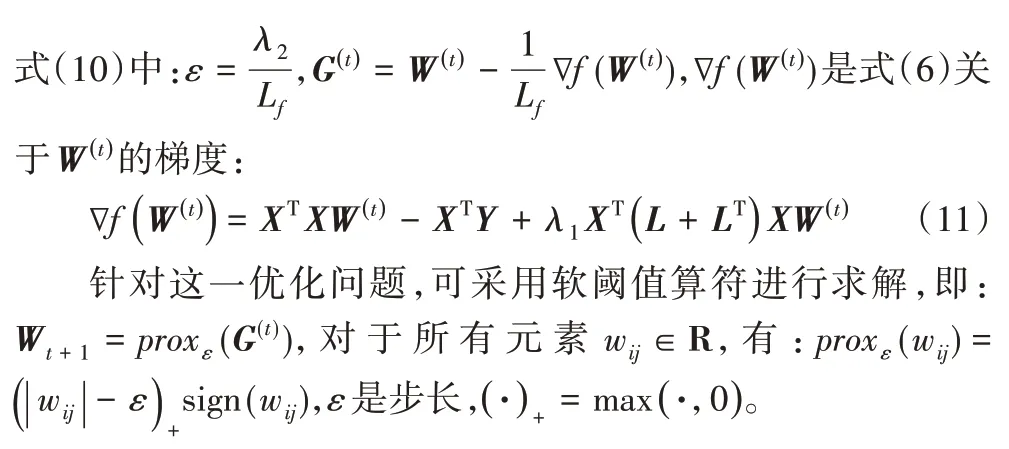
綜上,可將W更新過程整理如下:
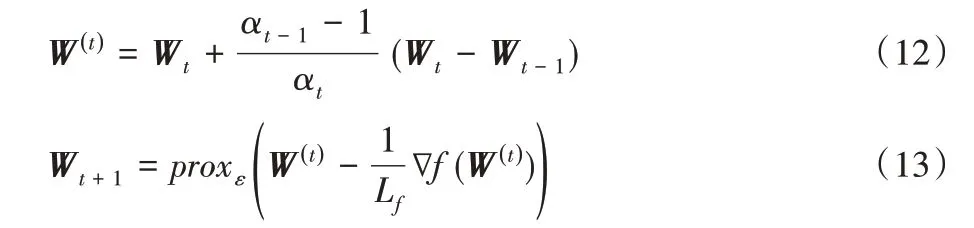
1.3.2 證明Lipschitz連續性
本節給出利普希茲連續性證明過程。假設存在參數W1和W2,將這兩個參數分別代入式(11),可得:

其中Lf為Lipschitz常量。
根據式(4)所表示的優化目標,可提出缺失標記下基于類屬屬性的多標記特征選擇算法,如算法1所示。
算法1 缺失標記下基于類屬屬性的多標記特征選擇算法(Multi-label Feature Selection based on Label-specific feature with Missing Labels,MFSLML)。
輸入 訓練樣本矩陣X∈Rn×d,不完整訓練樣本標記矩陣Y∈Rn×l,參數λ1和λ2。
輸出 系數矩陣W*,恢復后的樣本標記矩陣Y。


1.4 時間復雜度分析
在MFSLML 中,時間復雜度主要取決于步驟1、4和6。在步驟1 中,涉及到初始化,因此時間復雜度為O(d2n+d3+dnl+d2l);在步驟4 中,計算Lipschitz 常量的時間復雜度為O(d3+l3);在步驟6 中,需要計算f(W)的梯度,該步驟復雜度為O(d2l+dl2),故t次迭代后總復雜度為O(t(d2l+dl2)) 。綜上,算法時間復雜度為O(d2n+d3+dnl+d2l)+O(d3+l3)+O(t(d2l+dl2)) 。
2 實驗設計與結果比較
2.1 實驗數據
為了證明MFSLML 算法的有效性,從http://mulan.sourceforge.net/datasets.html 選取7 組標準多標記數據集,其中,Arts、Computer、Entertainment、Recreation 和Reference 數據集被廣泛用于文本分類任務中,Emotions 是音樂數據集,Scene 是場景圖像數據集。表1 給出數據集的描述信息,訓練樣本和測試樣本按照Mulan網站中的默認設置劃分。

表1 多標記數據集例子Tab.1 Example of multi-label dataset

表2 本文所用的多標記數據集Tab.2 Multi-label datasets used in this paper
2.2 評價指標與對比算法
在本文實驗中,采用平均查準率(Average Precision,AP)、覆蓋范圍(Coverage,CV)、海明損失(Hamming Loss,HL)和單錯誤(One Error,OE)四個評價指標,其中,AP指標取值越大越好,而CV、HL以及OE的取值則是越小越好。
給定一個測試集T={(xi,yi)|1 ≤i≤N},假設yi?L為真實標記集合,?L為預測標記集合。4個評價指標具體計算公式如下:

其中ri(γ)代表預測標記γ的排序。
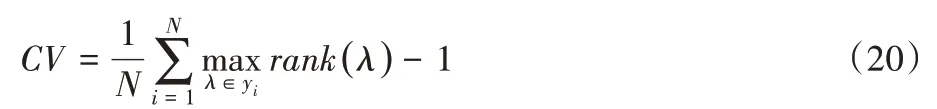
其中rank(λ)代表預測標記λ可能排序位置。

其中:⊕代表異或運算,M代表集合中標記數目。
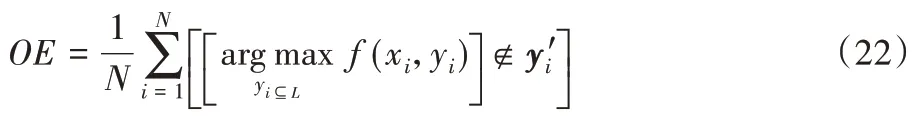
為了有效地驗證MFSLML 算法性能,本文選擇6 種流行的多標記特征選擇算法進行比較:
MDDM(Multi-label Dimensionality reduction via Dependence Maximization)[15]該算法通過最大化特征和類標記之間的依賴關系,將原始特征空間投影到更低維的特征空間,其中包括MDDMspc和MDDMproj兩種投影策略。
PMU(Pairwise Multi-label Utility)[16]該算法運用所選特征和標記集之間的互信息來處理特征選擇問題。
MDMR(multi-label feature selection algorithm based Max-Dependency and Min-Redundancy)[9]該算法通過最大化特征的依賴度并同時最小化特征間的冗余度來進行特征選擇。
MFML(Multi-label Feature selection with Missing Labels via considering feature interaction)[11]該算法定義多標記信息熵和多標記互信息兩個新概念,并運用特征交互來進行特征選擇,該算法能處理缺失標記環境下的特征選擇問題。
MLMLFS(robust Multi-Label Feature Selection with Missing Labels)[12]該算法運用魯棒的線性回歸模型選擇最具區分性的特征,該算法能處理缺失標記環境下的特征選擇問題,并且在特征選擇的同時恢復缺失標記。
2.3 參數設置
對于MFSLML 有兩個參數,參照文獻[17]將參數λ1和λ2設置在{10-6,10-5,…,103}范圍內搜索最優值;對于MDDMspc和MDDMproj,根據文獻[15]將參數μ設置為0.5;對于MDMR和PMU,采用等寬策略離散化連續型特征;對于MLMLFS,根據文獻[12]將參數λ和α都設置為10-6。對于標記的缺失率,設置為0%,20%,40%。對于實驗中用到的多標記分類器,與所有對比算法一樣,采用經典的ML-KNN分類器[18],其中參數Num和Smooth分別設置為10和1。
2.4 實驗結果與分析
由于實驗中算法最終都是得到特征排序,為了達到特征選擇的目的,參照文獻[9],Arts、Computer 和Emotions 數據集取前15%個特征,剩下4 個數據集則取前20%個特征。表3~14 中運用“↑”符號來表示該評價指標的取值越大越好,運用“↓”符號來表示該評價指標的取值越小越好。此外,在每個表中,將最優的實驗結果用黑粗體標出。
表3~5列出了7種特征選擇算法在不同標記缺失率下,在評價指標Average Precision 上的實驗結果;表6~8 列出了7 種特征選擇算法在不同標記缺失率下,在評價指標Coverage 上的實驗結果;表9~11 列出了7 種特征選擇算法在不同標記缺失率下,在評價指標Hamming Loss 上的實驗結果;表12~14列出了7 種特征選擇算法在不同標記缺失率下,在評價指標One Error上的實驗結果。
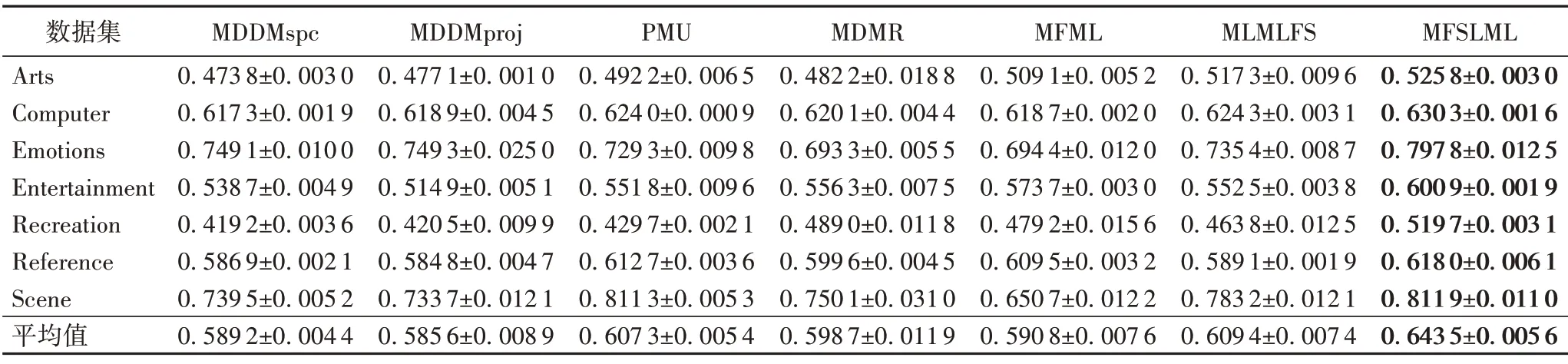
表3 0%標記缺失率下,7種特征選擇算法的對比結果(Average Precision↑)Tab.3 Comparison results of 7 feature selection algorithms under 0%missing labels(Average Precision↑)
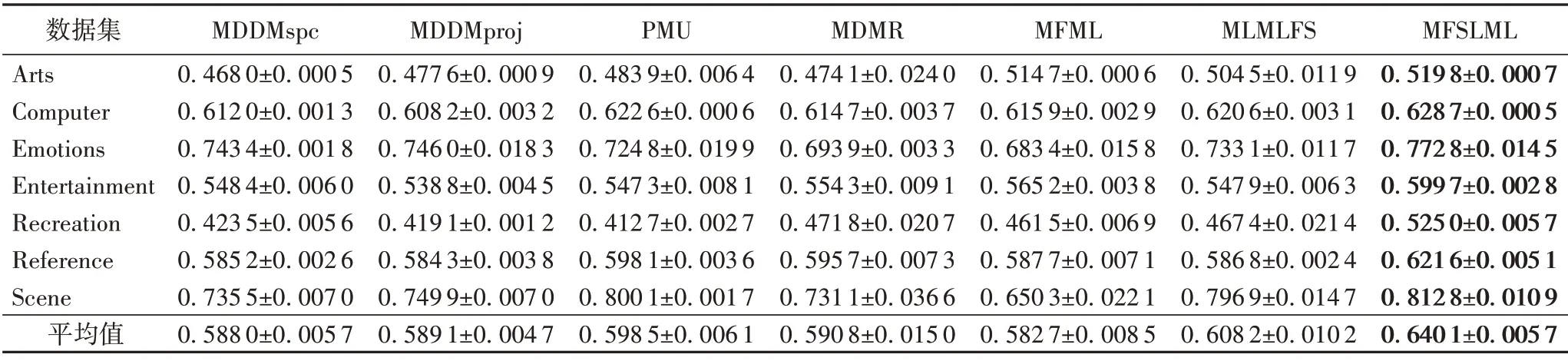
表4 20%標記缺失率下,7種特征選擇算法的對比結果(Average Precision↑)Tab.4 Comparison results of 7 feature selection algorithms under 20%missing labels(Average Precision↑)
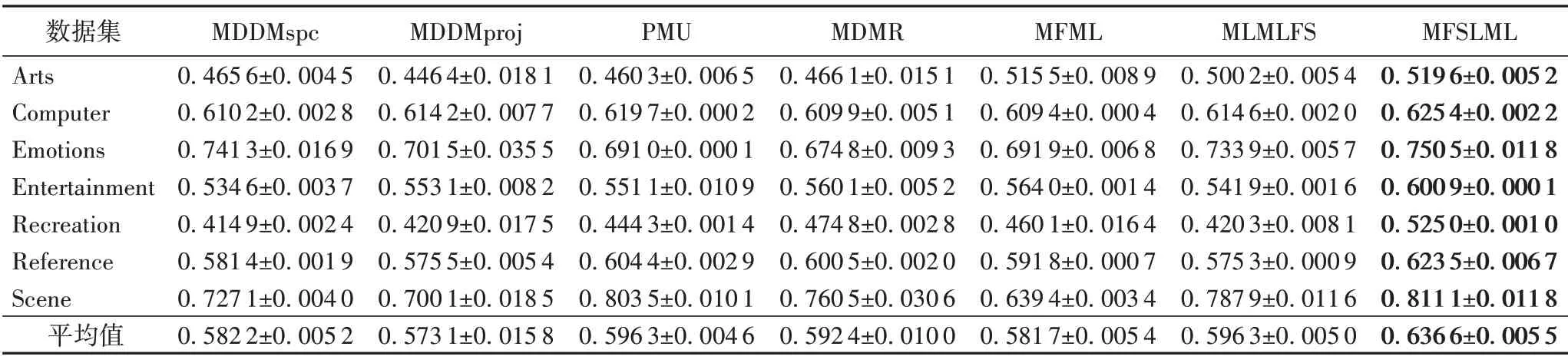
表5 40%標記缺失率下,7種特征選擇算法的對比結果(Average Precision↑)Tab.5 Comparison results of 7 feature selection algorithms under 40%missing labels(Average Precision↑)
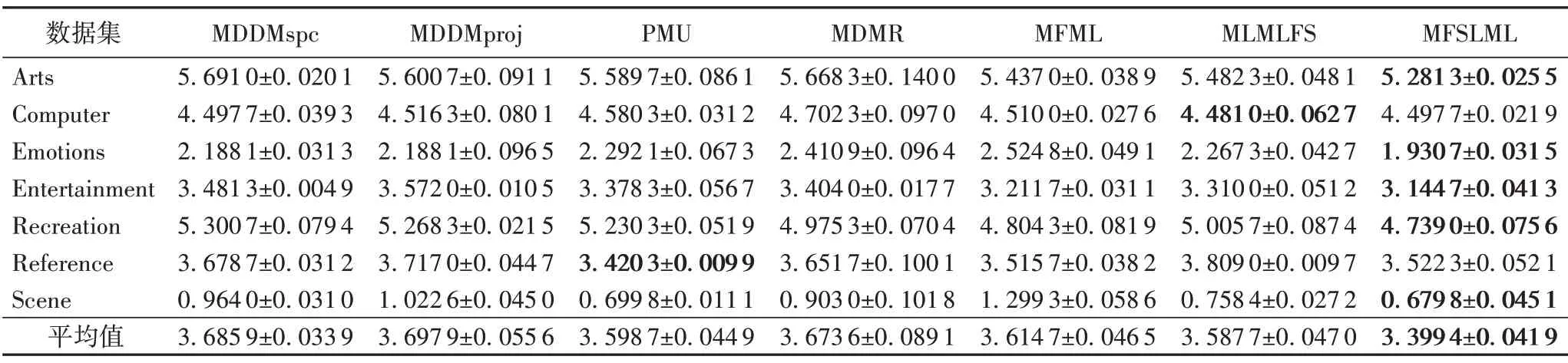
表6 0%標記缺失率下,7種特征選擇算法的對比結果(Coverage↓)Tab.6 Comparison results of 7 feature selection algorithms under 0%missing labels(Coverage↓)

表7 20%標記缺失率下,7種特征選擇算法的對比結果(Coverage↓)Tab.7 Comparison results of 7 feature selection algorithms under 20%missing labels(Coverage↓)
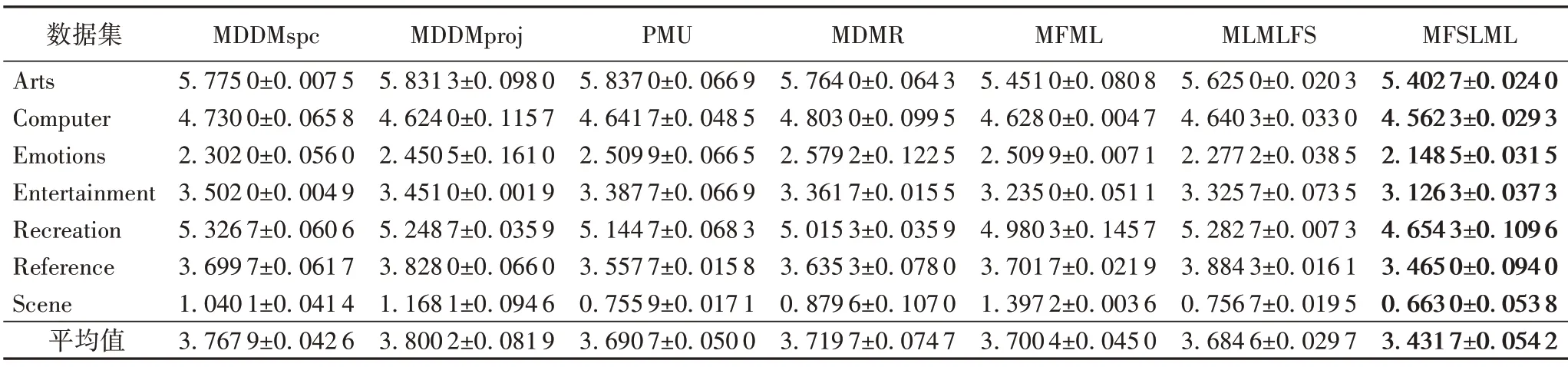
表8 40%標記缺失率下,7種特征選擇算法的對比結果(Coverage↓)Tab.8 Comparison results of 7 feature selection algorithms under 40%missing labels(Coverage↓)
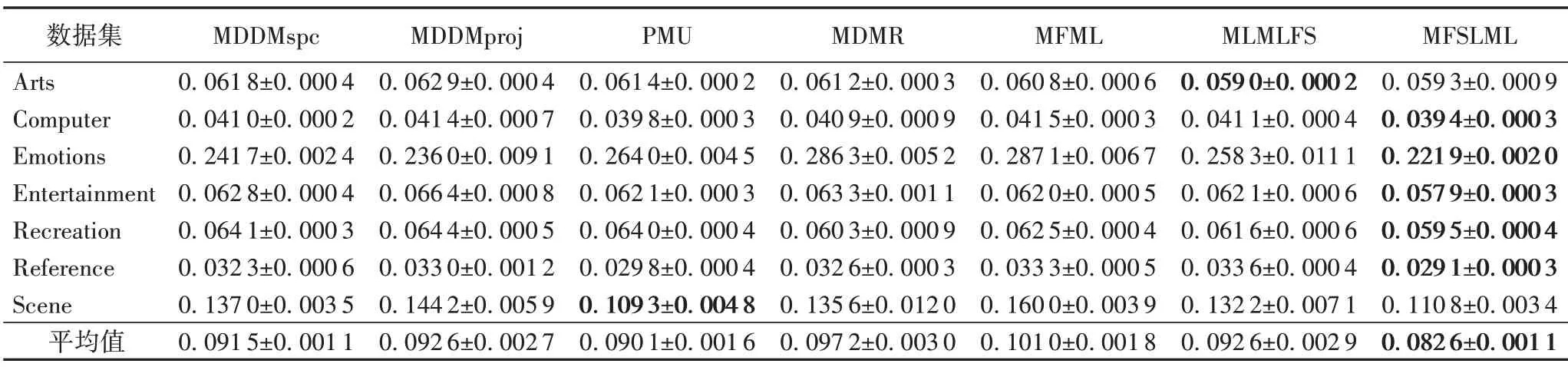
表9 0%標記缺失率下,7種特征選擇算法的對比結果(Hamming Loss↓)Tab.9 Comparison results of 7 feature selection algorithms under 0%missing labels(Hamming Loss↓)

表10 20%標記缺失率下,7種特征選擇算法的對比結果(Hamming Loss↓)Tab.10 Comparison results of 7 feature selection algorithms under 20%missing labels(Hamming Loss↓)
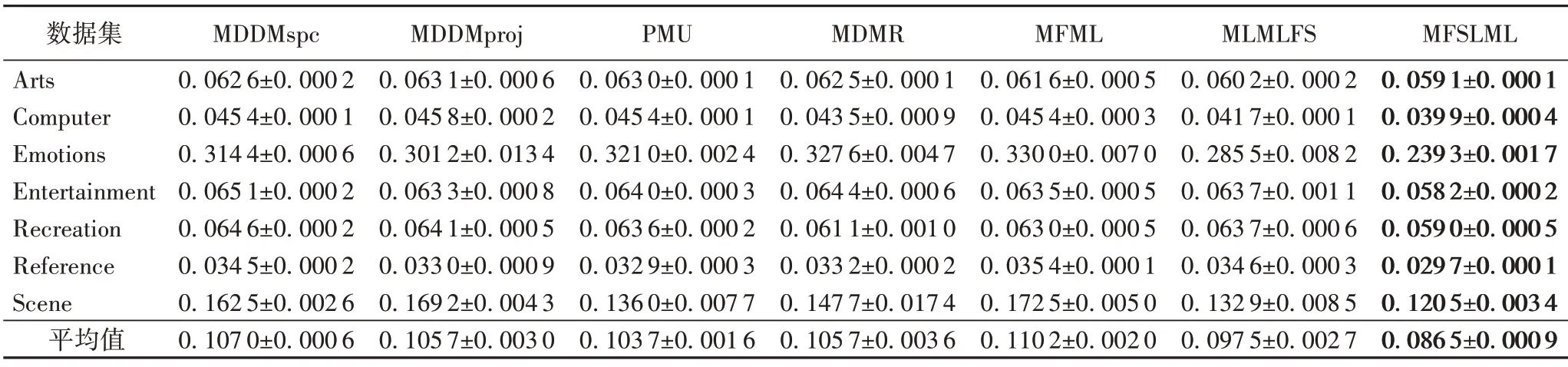
表11 40%標記缺失率下,7種特征選擇算法的對比結果(Hamming Loss↓)Tab.11 Comparison results of 7 feature selection algorithms under 40%missing labels(Hamming Loss↓)
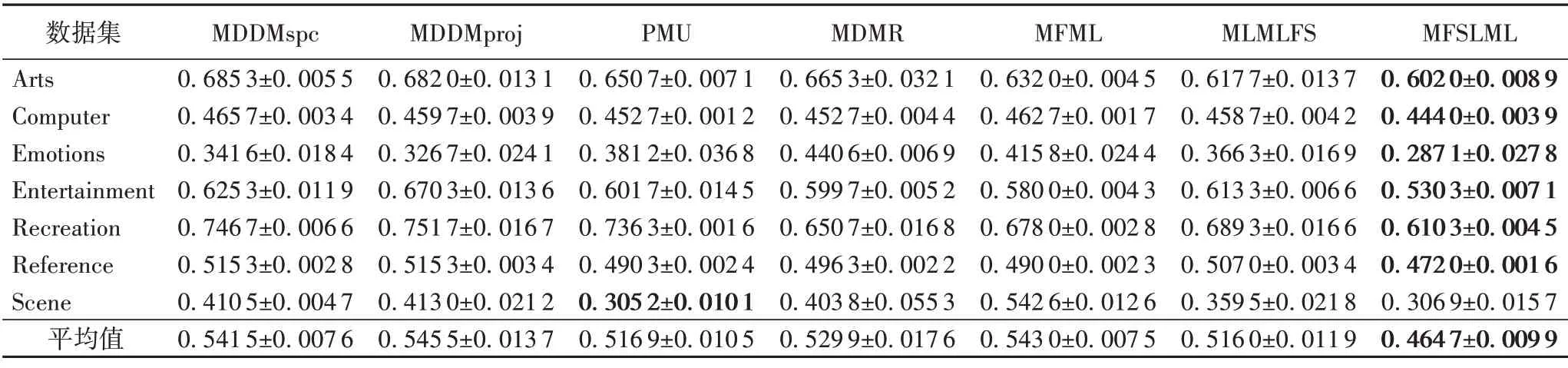
表12 0%標記缺失率下,7種特征選擇算法的對比結果(One Error↓)Tab.12 Comparison results of 7 feature selection algorithms under 0%missing labels(One Error↓)
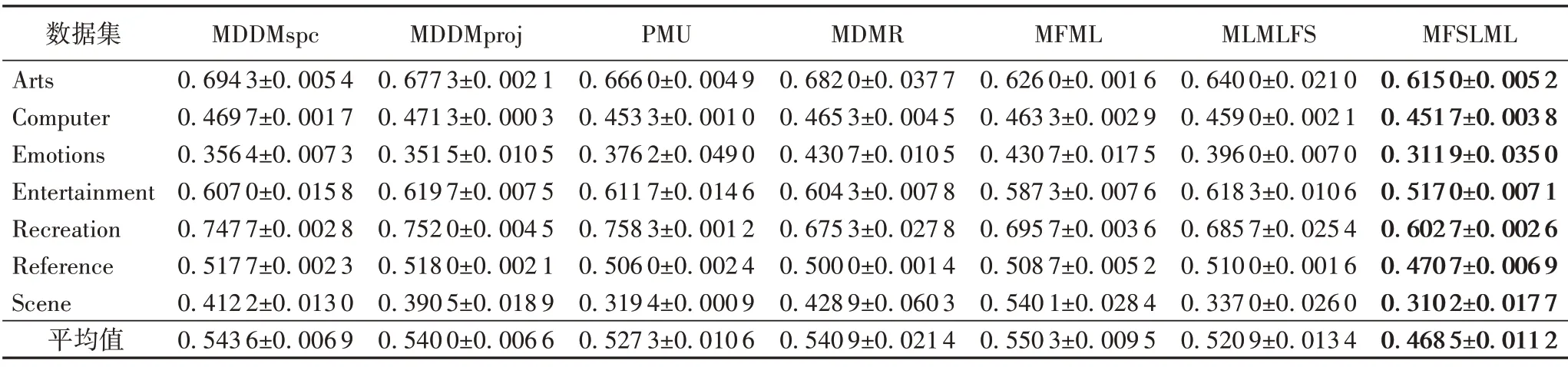
表13 20%標記缺失率下,7種特征選擇算法的對比結果(One Error↓)Tab.13 Comparison results of 7 feature selection algorithms under 20%missing labels(One Error↓)

表14 40%標記缺失率下,7種特征選擇算法的對比結果(One Error↓)Tab.14 Comparison results of 7 feature selection algorithms under 40%missing labels(One Error↓)
根據表3~14的實驗結果可得出以下結論:
1)當缺失率為0%時,MFSLML 算法相當于完備的多標記特征選擇算法。無論從4 個評價指標來看還是從平均性能來看,MFSLML 算法相比其他算法具有更優的分類性能,原因是在系數矩陣W上添加?1范數正則項,能為每個類標記選擇一組最有代表性的特征子集,即類屬屬性。
2)傳統的多標記特征選擇算法需要對特征空間和標記空間的關系進行建模,例如MDDM 算法考慮了特征和類標記之間的依賴關系,PMU 算法考慮了所選特征和類標記之間的互信息。但在缺失標記環境下,標記空間在一定程度上受到破壞,無法準確建模。對MFSLML算法而言,利用稀疏學習的方式學習每個標記的類屬屬性,然后通過線性回歸模型恢復缺失標記,降低缺失標記帶來的影響。故在五種缺失率的情況下,MFSLML 算法在7 組數據集上各個指標的平均分類性能都排第一。
3)隨著缺失率增加,各方法的分類性能都出現不同程度的下降。與其他算法相比,MFSLML 算法的分類性能是緩慢下降的,原因在于該算法采用線性回歸模型構建類屬屬性與標記的映射關系用于恢復缺失標記,因此MFSLML 算法在大多數情況下能取得最優結果。總體上看,MFSLML 算法的分類性能要優于其他算法,并且在缺失標記環境下進行特征選 擇時,恢復缺失標記非常重要。
由于所有對比算法均有采用Arts數據集展現所選特征數量對各算法分類性能的影響,為了公平比較,選取Arts數據集展示在3 種缺失率情況下不同算法在4 個評價指標上分類性能隨著特征數目的變化趨勢,具體做法如下:將各算法在Arts數據集下產生的特征排序中的特征依次放入MLKNN 分類器中訓練,每放入一個特征記錄一次結果。最終實驗結果在圖1~3中給出。
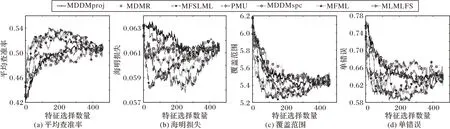
圖1 0%標記缺失率下,在Arts數據集上的預測分類情況Fig.1 Predictive classification situation on Arts dataset under 0%missing labels
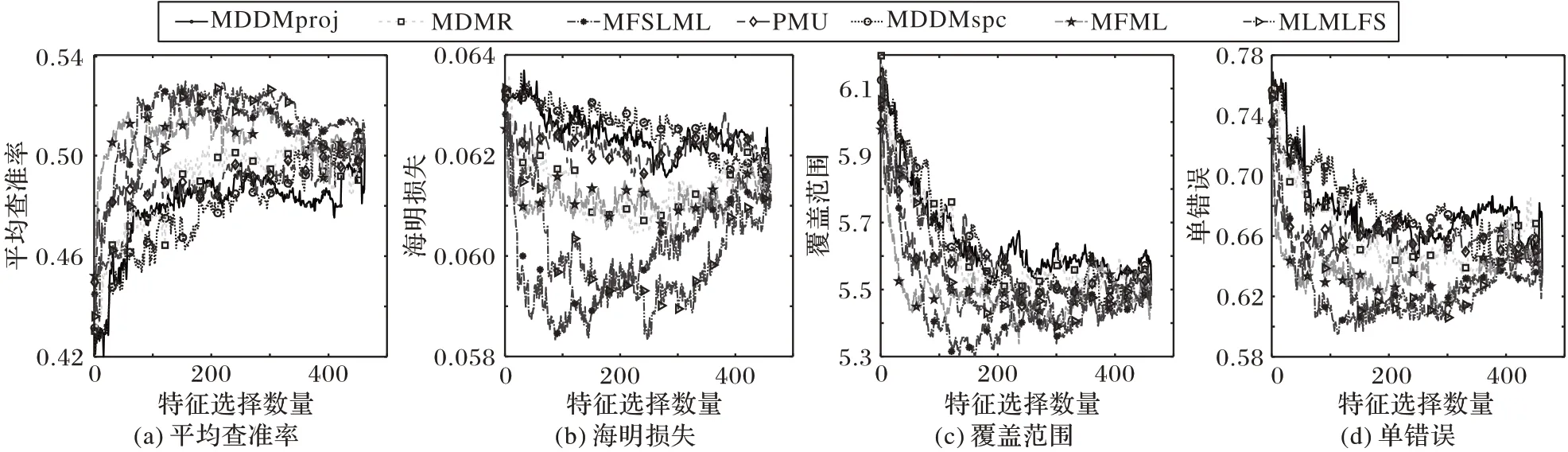
圖2 20%標記缺失率下,在Arts數據集上的預測分類情況Fig.2 Predictive classification situation on Arts dataset under 20%missing labels

圖3 40%標記缺失率下,在Arts數據集上的預測分類情況Fig.3 Predictive classification situation on Arts dataset under 40%missing labels
根據圖1~3的實驗結果可得出以下結論:
1)缺失率為0%時,MFSLML 算法在Hamming Loss 和Coverage 兩個指標上優于其他算法,在其他兩個指標上與其他算法無明顯差距;缺失率為20% 時,MFSLML 算法在Hamming Loss 和Coverage 兩個指標上表現優秀,在其他兩個指標上只以微小優勢勝出;缺失率為40%時,MFSLML算法在所有指標上均能得到更好的結果。
2)通過觀察所有曲線,實驗中每個評價指標都不是單調遞增或者單調遞減,表明并不是所有特征都有效,只有一個特征子集對分類性能影響最大。在大部分情況下,MFSLML 算法的最優預測分類性能都是在所選特征數量較少的情況下取得,說明MFSLML算法得到的特征排序更具代表性。
3)隨著缺失率提升,所有算法的分類性能都呈下降趨勢,但MFSLML 算法表現出更穩定的分類性能,從Coverage 這個評價指標可以看出,MFSLML 算法的效果要優于其他對比算法,特別是在缺失率較高時,這種優勢更加明顯,故相比其他算法MFSLML算法的預測分類性能具有更強的魯棒性。
2.5 參數敏感性分析
在本文所提算法MFSLML 中,共有兩個參數λ1和λ2。其中,參數λ1是控制模型中一致性準則的系數,參數λ2是控制類別標記固有類屬屬性稀疏性的系數。
為了分析MFSLML 對于參數的敏感性,固定參數λ1的值,在{10-6,10-5,…,103}范圍內變化參數λ2的值。在Emotions 數據集上,缺失率為20%的情況下進行5 次實驗,取平均值作為實驗結果。最終在4 個評價指標上的實驗結果如圖4所示。

圖4 參數敏感性分析實驗結果Fig.4 Experimental results of parameter sensitivity analysis
從實驗結果可知,MFSLML 的分類性能對于參數值較不敏感。當參數取值過大時,算法的分類性能會出現一定程度的下降,原因在于參數λ2是控制類別標記固有類屬屬性稀疏性的系數,取值過大會使得所提算法在為每個類別標記選擇類屬屬性時忽略重要特征。
3 結語
本文提出一種缺失標記下基于類屬屬性的特征選擇算法,首先通過學習一個系數矩陣W來獲得每個類標記的類屬屬性;其次利用學習到的系數矩陣W和線性回歸模型,將不完整的標記矩陣補全;最后在7 組基準數據集上并且在多種標記缺失率情況下進行廣泛實驗,得出的結果證明MFSL-ML 算法是有效的多標記特征選擇算法。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
