基于注意力機制網絡的航運監控圖像識別模型
2021-11-05 01:30:02張凱悅
計算機應用 2021年10期
張凱悅,張 鴻
(1.武漢科技大學計算機科學與技術學院,武漢 430081;2.智能信息處理與實時工業系統湖北省重點實驗室(武漢科技大學),武漢 430081)
0 引言
深度學習和計算機視覺技術的發展讓智能監控的應用越來越廣泛,航運監控圖像識別是對江海上運輸能源的船舶的狀態進行實時判斷,是深度學習在能源運輸領域的應用。當航運識別服務判斷出作業中的船舶處于異常狀態時,可以及時地向指揮中心發出預警,實現對異常狀態船舶的快速定位。這極大地減輕了人力的負擔,切實地保障了運輸能源的安全。
航運監控圖像識別不僅具有通用圖像識別的難點,而且具有航運領域特有的困難和挑戰。江海上的霧氣、水面反射的陽光會干擾對識別主體有效特征的提取。在實際應用過程中,由于攝像頭放置角度的問題,處于同一狀態類別的船舶的視覺特征差異很大。運輸的煤炭沾上雨水熱值會損失,在運輸過程中需要覆蓋雨布,為了規范覆蓋雨布的行為,航運圖像識別服務需要判斷船上的雨布是否完全蓋好,黑色的雨布和煤炭很容易混淆,因此,處于不同狀態類別的船舶視覺特征差異很小。經過上面的討論可知,航運監控圖像識別具有類間差異小、類內差異大和噪聲干擾多的問題。
已有的航運監控圖像識別模型C3D(Convolutional 3D)[1]是傳統的圖像識別模型,其將連續的圖片處理成一段視頻后輸入到三維卷積神經網絡,由于過多地關注時空特征且對圖像有效特征的提取能力較弱,識別結果容易受到天氣、背景、攝像頭角度的影響,識別性能較差。本文方法基于注意力機制,屬于細膩度圖像分類方法的范疇,能夠提取出航運圖像中微小而有判別性的細節特征,有效解決了航運監控圖像類間差異小、類內差異大和噪聲干擾多的問題。本文模型在卷積神經網絡(Convolutional Neural Network,CNN)框架的特征提取層之后訓練一組1×1大小的卷積濾波器,用于提取出航運圖像中具有判別性的區域,設計了一種多模塊的網絡結構,各模塊分別提取圖像全局紋理特征、局部判別性特征、融合特征,各個模塊的輸出分別輸入到各自的損失層計算損失。
概括地來說,本文的主要工作包括3個方面:
1)局部判別性特征的提取不需要手工的定位標注或額外的目標定位網絡,使用弱監督學習訓練一組1×1大小的卷積濾波器實現對局部判別性特征的提取。
2)本文提出的模型使用多分支的網絡結構,綜合利用圖像的全局紋理特征和局部判別性特征,增強了卷積神經網絡學習中級表征的能力。
3)考慮到局部判別性特征和全局紋理特征的交互作用,本文設計了一個特征融合模塊用于融合局部判別性特征和全局紋理特征。
所提出的模型在真實數據集上進行了驗證,實驗結果表示,該模型在預測精度上達到91.8%,可以有效地應用到實際航運監控項目中。
1 相關工作
由于航運圖像類內差異大、類間差異小、噪聲干擾多的特點,將航運圖像識別歸結到細膩度圖像識別的范疇。在傳統的計算機視覺研究中,圖像識別只是在粗粒度上判斷目標對象的元類別,例如判斷一個目標對象是貓還是狗。細膩度圖像識別是在元類別下對目標對象進行更加細致的劃分,例如區分不同種類的鳥、不同型號的汽車。與傳統的元類別級別的分類相比,細膩度圖像識別要困難得多,因為從屬類之間的視覺差異是很微妙的,往往需要提取目標對象高度局部化的判別性特征,例如不同種類的鳥的差異僅僅表現在鳥喙上的圖案或羽毛的紋理。因此,從存在細微差異的局部區域提取有效信息已經成為解決細膩度圖像識別問題的關鍵[2-3]。
1.1 細膩度識別
為了注意到圖像的局部特征,早期的工作利用手工的標注框或注釋作為訓練時的附加局部特征信息[4-5],然而專家注釋很難獲得并且很容易出現人為的錯誤。基于局部信息的區域卷積神經網絡(Part based Region Convolutional Neural Network,Part-RCNN)方 法[6]擴展了區域卷積神經網絡(Region Convolutional Neural Network,RCNN)方法[7],在幾何先驗條件下,它可以檢測到目標對象并定位局部特征,然后從一個正則化表示中預測一個細粒度的類別。Lin 等[8]提出一種反饋控制框架Deep-LAC(Deep Localization,Alignment and Classification),將對齊和分類誤差反向傳播到定位模塊;還提出了用于連接定位模塊和分類模塊的閥門連接函數(Valve Linkage Function,VLF)。
為了減少額外的局部定位標注成本,一些方法只需要圖像級別的標注,于是不同的特征池化方法被提出。Lin 等[9-10]提出雙線性池化方法和改進的雙線性池化方法,上述方法考慮到兩個不同位置特征的成對交互作用,兩個不同位置的特征通過矩陣外積的方式被融合。矩陣冪歸一化協方差池網絡(Matrix Power Normalized COVariance pooling ConvNets,MPNCOV)[11]通過矩陣平方的方式改進了二階池化并且達到了當時最高的預測準確度。
空間變換卷積神經網絡(Spatial Transformer Convolutional Neural Network,ST-CNN)[12]旨在通過學習適當的幾何變換并在分類前對齊圖像來獲得精準的分類性能,該方法還可以同時定位多個對象的各個部分。Fu 等[13]提出了循環注意力卷積神經網絡(Recurrent Attention Convolutional Neural Network,RA-CNN)來遞歸地預測一個注意力區域的位置并提取相應的特征,該方法只關注一個局部區域;為了同時產生多個注意力區域,Zheng 等[14]提出了多注意力卷積神經網 絡(Multi-Attention Convolutional Neural Network,MACNN),它可以同時定位多個局部區域,他們提出通道分組損失,通過聚類算法生成多個注意力區域。
然而上述方法只是單一地提取圖像全局特征或局部特征,沒有考慮全局特征和局部特征的交互作用。本文方法使用多分支的網絡結構和一個特征融合模塊,綜合利用圖像全局特征和局部特征,實現了對圖像局部信息和全局信息的同步學習。
1.2 卷積神經網絡高階特征表示
文獻[15]對卷積神經網絡中間隱藏層提取到的特征可視化后發現,隨著網絡層數的變深,提取到的特征從邊緣和角落逐漸變為局部區域和整個目標對象;文獻[16]發現通過對卷積層生成的所有特征圖進行適當的加權平均,可以有效地可視化輸入圖像的所有局部區域;文獻[17-19]對卷積神經網絡的中間層進行監督,通過另一個全連接層和一個損失層來轉換全連接層的輸出,學習更多的局部區分性表示;文獻[20]提出單階段多尺度探測器(Single Shot MultiBox Detector,SSD),它將卷積濾波器和特定的寬高比的對象或特定的位置坐標相關聯。
受到上述研究的啟發,本文方法對卷積神經網絡中間層提取到的特征進行1×1的卷積特征映射和線性變換,提取圖像局部判別性特征。
2 多尺度特征融合注意力網絡
本章將詳細介紹多尺度特征融合注意力網絡的整體框架和各模塊構成。圖1 是多尺度特征融合注意力網絡的整體框架圖。它包含4 個并行的模塊:局部注意力提取模塊、局部注意力監督模塊、全局紋理特征提取模塊、融合全局紋理特征和局部特征的特征融合模塊。
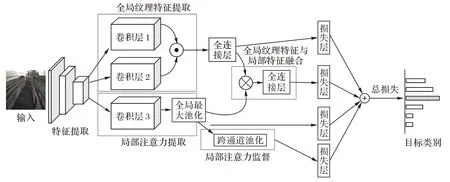
圖1 多尺度特征融合注意力網絡整體框架Fig.1 Overall framework of multi-scale feature fusion attention network
局部注意力提取模塊用于提取圖像局部判別性特征,生成局部注意力圖;局部注意力監督模塊以監督學習的方式保證局部注意力提取模塊提取區分性特征的能力;全局紋理特征提取模塊通過雙流卷積神經網絡生成兩個特征圖,再以矩陣外積的方式融合兩個特征圖生成全局紋理特征圖;特征融合模塊使用雙線性池化融合全局紋理特征圖和局部特征圖。4個模塊的輸出分別輸入到各自的損失層計算損失,對4個損失進行加權求和獲得總的損失。
2.1 局部注意力提取
圖2是將局部注意力可視化的效果圖。如圖2所示,通過局部注意力模塊提取到航運監控圖像中的吊塔、裸露的煤塊等具有判別性的有效區域特征,這些區域性特征經過特征映射輸入到分類器,對于提升圖像識別的準確性具有重要意義。例如:局部注意力模塊提取到吊塔,可以大概率判斷圖像的類別屬于船舶靠港;提取到裸露的煤塊,可以判斷圖像的雨布沒有蓋好。局部注意力提取模塊的核心組成部分是一組1×1×C大小的卷積濾波器和一個全局最大池化層。卷積特征的每個通道對應于一個視覺模式[21],然而,由于缺乏一致性和魯棒性,這些特征映射不能充當注意力映射[22]。受到文獻[21-23]的啟發,本文根據特征通道的空間關系,通過1組1×1×C大小的卷積濾波器將特征映射轉化為局部注意力映射。將輸入圖像通過若干個卷積層和池化層,獲得尺寸為C×H×W的特征圖,其中C是特征圖的通道數,H和W分別是特征圖的高度和寬度。假設1×1×C的卷積濾波器通過監督學習已經具有發掘局部區分性特征的能力,通過這個卷積濾波器對特征圖進行卷積獲得注意力熱力圖,再對注意力熱力圖進行全局最大池化,在注意力熱力圖上選取最大的響應值,就可以獲得具有判別性特征的區域。

圖2 局部注意力模塊提取效果Fig.2 Effect of local attention extraction module
2.2 局部注意力監督
通過在1×1×C的卷積濾波器后接入1 個跨通道池化層和1 個Softmax 損失層,局部注意力監督模塊以監督學習的方式保證局部注意力模塊提取區分性特征的能力。局部注意力監督模塊主要使用了跨通道平均池化算法。
將航運圖像分成正常行駛、未蓋雨布、無效雨布、重載停泊、空倉停泊、船舶靠港等6 個類別,分類數目用M表示,M=6。對于某一個特定類別使用10 個局部注意力圖來表示,局部注意力圖的數目用k表示,k=10。因此一共需要kM個1×1 大小的卷積濾波器,kM個卷積濾波器生成kM個注意力圖。經過特征提取器提取到的特征圖經過kM個卷積濾波器卷積后,輸出維度為kM×H×W的特征矩陣F,H和W分別是生成的特征矩陣的高度和寬度。
特征矩陣F以集合的方式表示為:F=,經過全局最大池化層,對每個特征矩陣求最大值,輸出的特征矩陣的維度變為kM×1×1,輸出的特征矩陣用G表示,G=。跨通道平均池化層將輸出的特征矩陣分成M組,每組含有k個1×1 維的特征矩陣。每組用于表示一個特定的類別,如式(1)所示。再分別對每組的k個特征矩陣計算平均值,最終輸出1×M維的特征矩陣,用h表示。將h輸入到M路的Softmax 損失層計算損失以鼓勵卷積濾波器對某一特定類別產生較大的響應,Softmax損失公式如式(2)所示,hi和hj是h中的元素。

2.3 全局紋理特征提取
受到文獻[9]和文獻[24]的啟發,本文使用雙流卷積神經網絡提取圖像的全局紋理特征,雙流卷積神經網絡通過對兩個卷積神經網絡提取到的特征進行特征融合生成二階特征。文獻[9]的研究結果表明二階特征是一種有效的圖像紋理表示,因此本文模型使用雙流卷積神經網絡提取圖像全局紋理特征,圖3是全局紋理特征提取模塊的示意圖。
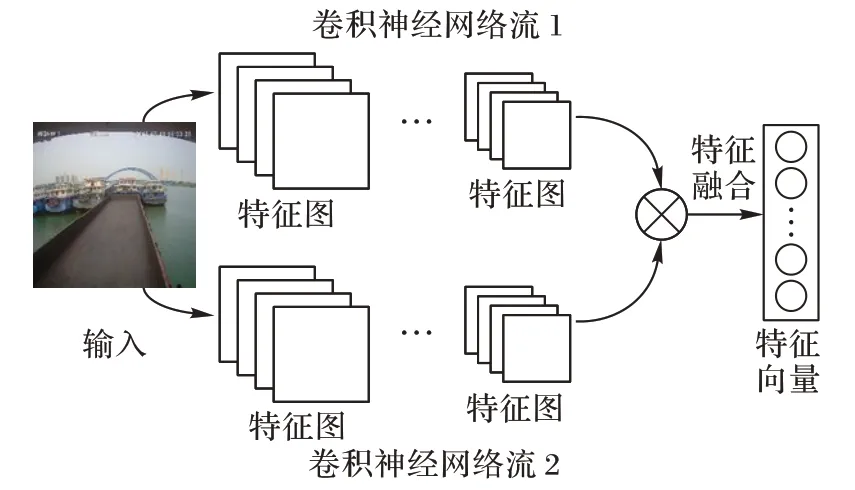
圖3 全局紋理特征提取模塊示意圖Fig.3 Schematic diagram of global texture feature extraction module
下面將詳細闡述全局紋理特征提取的過程。qA(l,I)和qB(l,I)分別表示特征提取函數qA和qB對圖像I進行特征提取后,在位置l提取到的特征。首先對兩個特征矩陣在同一位置的特征表示進行雙線性組合,如式(3)所示:
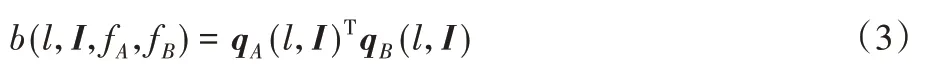
假設經過特征提取器獲得的特征圖的維度是H×W×C,H、W、C分別表示特征圖的高度、寬度、通道數。經過雙線性組合,特征圖上的每一個位置對應的特征矩陣的維度是C×C,在本文提到的算法中通道數是512,因此特征圖上的每一個位置對應的特征矩陣的維度是512×512,特征向量的維度過大,需要對特征矩陣降維。
本文使用Sum Pooling 池化方法對每一個位置對應的特征矩陣求和,將高維的特征矩陣投影到低維空間,如式(4)所示:
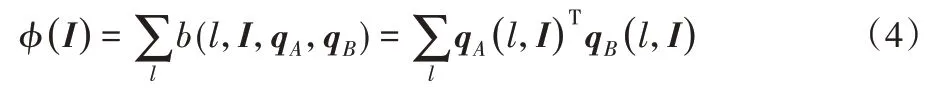
假設qA和qB提取的特征圖的維度分別是M×N和N×Q,經過雙線性池化生成的特征圖?(I)的維度是M×Q,再將M×Q矩陣形式的特征表達轉換為向量x后輸入到分類器計算損失,如式(5)所示:

最后對特征向量進行歸一化和正則化操作,生成特征向量z,如式(6)和式(7)所示。z就是需要的全局紋理特征表示。

2.4 全局紋理特征與局部特征融合
為了使模型學習到全局紋理特征和局部特征的關系和交互作用,本文模型使用雙線性注意力池化[25]融合全局紋理特征圖和局部特征圖。特征融合過程如圖4 所示。FH×W×N是使用特征提取器獲得的全局紋理特征圖,H、W和N分別表示特征圖的高度、寬度和通道數。AH×W×M是使用2.1 節提到的局部注意力提取模塊獲得的局部特征圖。局部特征圖指向圖像的特定部位。
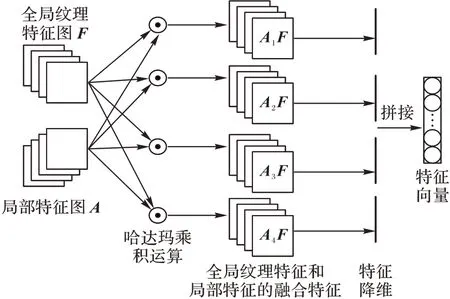
圖4 特征融合模塊示意圖Fig.4 Schematic diagram of feature fusion module
將每一個全局紋理特征圖Fk與局部特征圖Α作Hadamard 積進行特征融合,生成融合特征圖PM×N×H×W,M個全局紋理特征圖與N個局部特征圖融合后生成M×N個融合特征圖,雙線性注意力融合的計算式如式(8)所示:
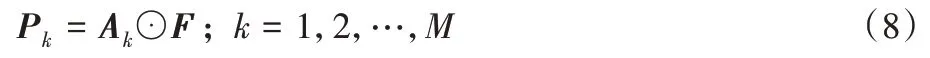
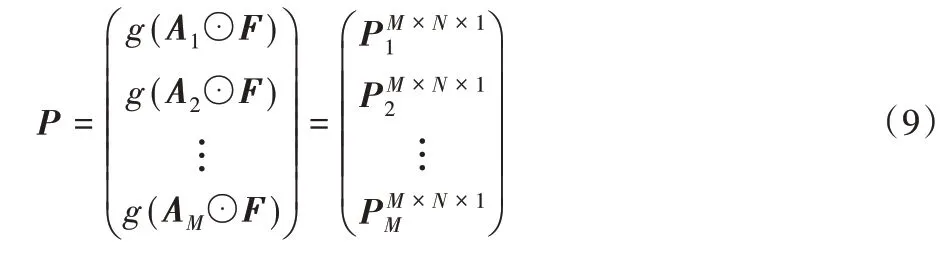
使用全局最大池化對生成的融合特征圖降維,用g(Pk)表示池化過程,池化過程如式(9)所示:
最后對生成的融合特征表示進行歸一化和正則化處理。
2.5 損失函數
上述4 個模塊的輸出分別輸入到各自的損失層計算損失值,總的損失值是4 個模塊的損失的加權和,總的損失函數如式(10)所示:
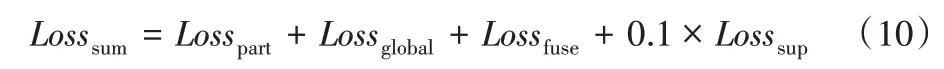
其中:Losspart是局部注意力提取模塊的損失,Lossglobal是全局紋理特征提取模塊的損失,Lossfuse是特征融合模塊的損失,Losssup是局部注意力監督模塊的損失。
損失函數為交叉熵損失(Cross Entropy Loss Error,CE),交叉熵損失用于計算兩個概率分布之間的差異。交叉熵損失的公式如式(11)所示:

其中:yi是真實標簽;pi是預測概率。
使用Softmax 函數計算某特定類別的預測概率,模型的損失函數結合了Softmax 函數和交叉熵損失函數,損失函數公式如式(12)所示:

其中:y是真實值是分類器輸出的分類向量;N是類別數目。
3 實驗與結果分析
3.1 實驗數據
本文將航運過程中累積的監控視頻制作成航運圖像數據集,數據集一共有126 336張圖像。根據航運監控項目的業務需求和船舶的運動狀態,將航運圖像分成6 個類別,分別是正常行駛、無效雨布、未蓋雨布、重載停泊、船舶靠港、空倉停泊。圖5 是航運監控圖像數據集示例圖像。然而在劃分數據集的過程中,空倉停泊類別的圖像數量較少,因此對空倉停泊類別的圖像進行了隨機的平移、縮放、水平翻轉以擴充空倉圖像類別的數據,使得數據集的分布均勻。

圖5 航運監控圖像數據集示例圖像Fig.5 Example images of shipping monitoring image dataset
3.2 實驗環境及設置
實驗環境的軟硬件配置如下:Intel Core i9-9900k CPU 3.6 GHz處理器,Nvdia GeForce RTX 2080Ti 12 GB顯卡,64GB內存。操作系統是Windows Server 2019,編程語言是Python 3.6.8,深度學習框架是Pytorch 1.5.0。
本文使用十折交叉驗證法進行模型的訓練,將數據集均分為10 份,在訓練過程中,依次地將其中1 份作為測試集,其余9份作為訓練集,訓練結束后得到10個模型,最終的性能指標是10 個模型的性能指標之和的平均值。每張圖像在輸入到模型前被預處理為448×448 大小。在模型訓練過程中使用隨機梯度下降(Stochastic Gradient Descent,SGD)優化算法,初始學習率設置為0.1,動量(momentum)設置為0.9,權重衰減系數設置為1E-4,batch size 設置為32,使用GPU 訓練300個epoch。
3.3 對比模型及評價標準
選用了其他常用的圖像識別模型與本文的模型進行對比,這些模型包括:
1)微調的視覺幾何組網絡(Fine-Tuned Visual Geometry Group Network,FT VGGNet)[26],VGGNet 通過反復堆疊3×3 大小的卷積核和2×2 大小的池化層構建整個網絡,在保證感受野大小不變的情況下,減少網絡參數。
2)微調的殘差網絡(Fine-Tuned Residual Network,FT ResNet)[27],ResNet模型通過殘差連接的方式解決網絡模型中不同層級的特征組合問題或者說淺層信息的遠距離傳輸問題。
3)C3D[1]:將時序上連續的圖像制作成視頻段,使用三維卷積核提取視頻段的時空特征。
4)雙流卷積神經網絡(Bilinear Convolutional Neural Network,B-CNN)[9]:用雙線性池化融合兩個分支的特征輸出。
5)RA-CNN[13]:循環注意力卷積神經網絡模型,以遞歸的方式關注同一個注意力區域。
6)MA-CNN[14]:多尺度注意力卷積神經網絡模型,可以同時關注多個注意力區域。
7)判別濾波器組卷積神經網絡模型(Discriminative Filter Learning within a Convolutional Neural Network,DFL-CNN)[23]。
8)判別關鍵域深度學習模型(Discriminating key domains and deep Learning Convolutional Neural Network,DL-CNN)[28]。
9)基于特征重標定的生成對抗模型(Feature Recalibration Generative Adversarial Network,FR-GAN)[29]。
本文使用準確率作為模型評價標準,對預測結果進行統計后,準確率計算式如式(13)所示:
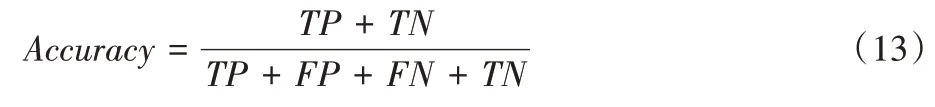
其中:TP(True Positive)是將正類預測為正類的數目;FN(False Negative)是將正類預測為負類的數目;FP(False Positive)是將負類預測為正類的數目;TN(True Negative)是將正類預測為負類的數目。
3.4 結果分析
3.4.1 不同模塊組合識別準確率的對比
為了驗證多尺度特征融合網絡的有效性和檢驗模型中不同模塊的貢獻大小,單獨使用網絡中某一模塊或某些模塊進行實驗,實驗結果如表1所示,不同模塊的簡稱表示如下:
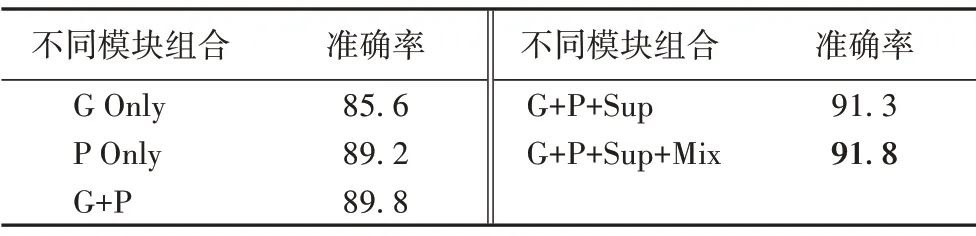
表1 本文模型不同模塊在數據集上的實驗結果對比 單位:%Tab.1 Experimental results of different modules of the proposed model on the dataset unit:%
1)G Only:只使用全局紋理特征提取模塊。
2)P Only:只使用局部注意力提取模塊。
3)G+P:使用全局紋理特征提取模塊和局部注意力提取模塊。
4)G+P+Sup:使用全局紋理特征提取模塊、局部注意力提取模塊和局部注意力監督模塊。
5)G+P+Sup+Mix:使用完整的多尺度融合注意力網絡模型。
實驗結果表明,與單獨使用模型某個分支或某些分支相比,完整的多尺度融合注意力網絡模型的識別性能最優,證明了4 個分支的協同作用有利于學習與理解圖像的有效特征。單獨使用全局紋理特征提取模塊的識別準確率最低,證明局部注意力機制在圖像識別模型中產生了重要的作用。
不同模塊組合的準確率隨迭代次數的變化曲線如圖6所示。
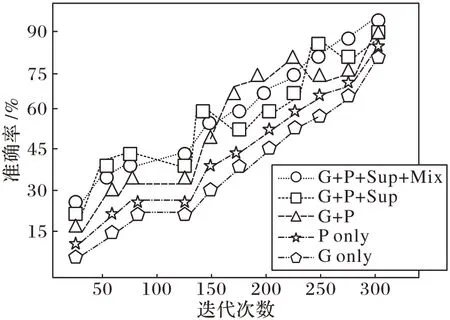
圖6 使用不同模塊組合的準確率變化情況Fig.6 Variation of accuracy by using different combinations of modules
從圖6 可以看出,從整體上看,使用不同的模塊組合進行訓練,準確率都在逐漸上升,而使用完整的多尺度融合注意力網絡模型,曲線變化最平穩,波動最小,并且完整的多尺度融合注意力網絡模型能到達到最高的識別準確率。實驗結果表明,本文提出的多尺度融合注意力網絡模型在訓練過程中更加穩定,并能達到最好的收斂效果。
3.4.2 不同模型識別準確率的對比
本文將提出的模型與其他主流的圖像識別模型在航運監控圖像數據集上進行了對比驗證,實驗結果如表2 所示。實驗結果顯示,本文提出的模型和其他的9 個對比模型相比,本文提出的模型表現出最優的識別性能。
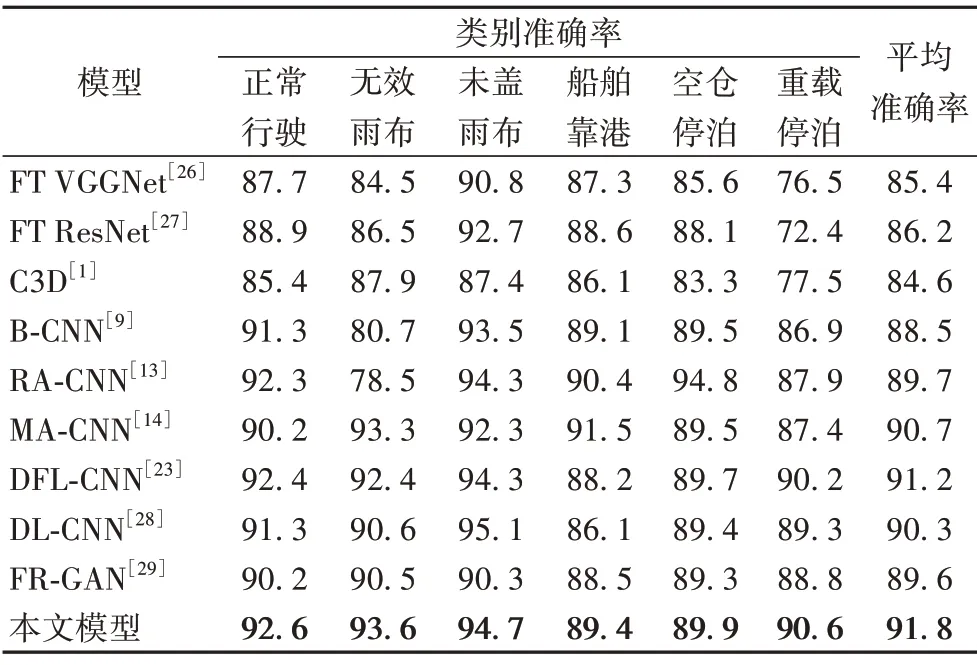
表2 不同模型在數據集上不同類別情況的準確率對比 單位:%Tab.2 Accuracy comparison of different models on different situations of the dataset unit:%
本文提出的模型和傳統的卷積神經網絡模型VGG-Net和ResNet相比,識別準確率分別提高了6.4個百分點和5.6個百分點,識別性能提升較大,這是因為傳統的卷積神經網絡模型中級表征學習能力較差,只能學習到圖像的淺層次特征,本文提出的模型引入了注意力機制,模型的注意力可以聚焦到最具有區分性的區域,加強了卷積神經網絡對中級表征的學習能力。
B-CNN模型融合兩個特征提取器輸出的特征圖得到圖像的全局紋理表示,本文提出的模型在B-CNN 模型的基礎上增加了提取局部區分性特征的子網絡,本文模型既學習到全局紋理特征,又學習到局部區分性特征,因此相較于B-CNN 模型,本文提出的模型表現出更優的識別性能。
RA-CNN 模型以遞歸的方式關注同一個區分性區域,而本文模型能夠同時提取多個區分性區域,綜合利用多個區分性區域的特征。
MA-CNN 模型進行分類時只利用到圖像的局部區分性特征,而本文模型使用多流的網絡結構,不僅利用到局部區分性特征,還利用到全局紋理特征。
DFL-CNN 模型以非對稱式多流的網絡結構,同時學習圖像的局部區分性特征和全局紋理特征,而本文模型相較于DFL-CNN 模型,增加了1個特征融合子網絡,能夠學習到整體特征和局部特征內在的聯系。
DL-CNN 模型對圖像進行語義分割,分割出判別性的關鍵區域,但其對關鍵區域的劃分比較粗糙,對于未蓋雨布等關鍵區域較大的類別識別效果較好,但對于關鍵區域較小的類別識別效果劣于本文模型。
FR-GAN 模型使用生成對抗算法學習有效特征,但生成對抗算法的鑒別器的訓練比較困難,而本文模型訓練更容易且表現出更優的分類性能。
4 結語
針對已有的航運監控圖像識別模型無法解決航運監控圖像的特征提取容易受到噪聲和拍攝角度的影響的問題,本文提出了一種基于注意力機制和多尺度特征融合的航運監控圖像識別模型。該模型使用多分支的神經網絡結構,既學習到圖像局部區分性特征,又學習到圖像全局紋理特征。局部區分性特征的提取不需要額外的人工標注,通過一組卷積濾波器和全局最大池化層,發掘出圖像中若干個區分性區域。為了有效提取圖像全局紋理特征,在全局紋理特征提取模塊中使用雙流卷積神經網絡結構和雙線性特征組合算法。考慮到全局特征和局部特征的交互作用,本文方法使用雙線性注意力池化算法融合圖像局部特征和全局特征。實驗結果表明,本文模型的識別準確率優于其他對比模型,可以有效地應用于航運監控圖像識別任務。然而,本文提出的模型參數數量較多,模型訓練容易受到計算資源的限制并且模型較難擬合,在接下來的工作中將探索如何對模型進行適當的剪枝和壓縮以減少參數數量。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
現代出版(2020年3期)2020-06-20 07:10:34
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
