基于特征選擇和標簽相關性的多標簽分類算法?
2021-11-08 06:14:04牟甲鵬余孟池
計算機與數字工程 2021年10期
關鍵詞:特征
蔡 劍 牟甲鵬 余孟池 徐 建
(南京理工大學計算機科學與工程學院 南京 210094)
1 引言
傳統的分類學習處理一個實例與單個類別標簽相關的問題。但是在現實世界中,一個實例可能會具有多個類別標簽。例如,一張圖片可能會被標注上多個關鍵詞;一篇文章可能屬于多個主題;一個基因也可能與多個功能相關。為了表達這些對象擁有的多重語義,經常使用一個標簽子集代替單個標簽來標識該對象,這類使用標簽子集來表達對象語義的學習模式稱為多標簽學習。多標簽分類的目標就是為具有多重語義的對象建立分類模型,讓該模型可以有效預測未知實例的相關標簽子集。
解決多標簽分類問題最經典的方法是BR(Bi?nary Relevance)算法[1],BR將多標簽分類問題轉換成多個二分類問題,為每個標簽分別訓練一個二分類器,最后綜合多個分類器結果作為最終的預測結果。BR算法具有簡單直接的優點,但是也存在一些問題。Zhang等[2]提出標簽相關性(label correla?tion)的概念,即標簽間通常存在依賴關系,指出BR算法未考慮標簽性的問題;Wu等[3]提出類屬屬性(label-specific feature)的概念,即每個標簽具有其特有的屬性特征,指出BR算法存在冗余屬性的問題。
為了解決BR算法存在的冗余屬性問題,現有的改進工作主要有兩種:特征選擇和特征轉化。特征選擇的目的是從原始特征空間中篩選出與標簽相關性強的屬性特征。相關算法有Qu等提出的MLSF算法[4],該算法分別為正、負例集計算特征密度,以此作為特征選擇的指標。特征轉化的目的是將原始特征空間映射到類屬屬性空間中,相關算法有LIFT[5]和其改進算法ELIFT[6]。這些算法雖然都解決了BR算法的冗余屬性問題,但最大的問題是沒有考慮標簽相關性。
為了解決BR未考慮標簽相關性的問題,現有的改進工作主要分兩種[7]:鏈結構(chaining struc?ture)和堆疊結構(stacking structure)。鏈結構是假定隨機的標簽相關性,每個標簽的預測僅考慮鏈之前標簽的影響。堆疊結構是假定所有標簽的相關性,每個標簽的預測需要考慮其他所有標簽的影響。這兩種策略雖然都考慮了標簽相關性,但是未考察加入的特征與標簽間的實際關系,因此都存在冗余依賴的問題。此外,由于預測過程需要加入其它標簽的預測值,如果預測值有誤,則還會引發錯誤傳播的問題。
以上算法都只是單獨解決了BR算法的一個問題,鑒于這種情況,本文提出基于特征選擇和標簽相關性的二元關聯算法(Binary Relevance with Fea?ture selection and Label correlation,FLBR)。該算法先使用信息增益為每個標簽選擇與其相關的特征屬性,然后引入新的“控制結構”(controlled struc?ture)的方式考察標簽相關性,最后為每個標簽訓練二分類器。這里的控制結構指的是對加入特征空間的標簽進行“控制”,僅添加與預測標簽相關性強并且不容易被預測錯誤的標簽,從而解決鏈結構和堆疊結構中存在的無關依賴和錯誤傳播問題。實驗結果表明,該算法的預測性能明顯優于其它的BR改進算法。
2 相關工作
2.1 多標簽問題的定義
在本文中,多標簽學習描述如下:已知X=Rd表示實體的d維特征空間,標簽空間L={y1,y2,…,yq}表示實體可能屬于的q個標簽。多標簽學習的目標是從訓練集L}中學習得到一個映射模型h:X→2L。對于每個待預測的未知實例x∈X,多標簽分類器做出預測,所得結果即為與實體x相關的標簽。
2.2 標簽相關性的利用
在改進BR算法的研究工作中,針對標簽相關性的改進是最多的,因此接下來對改進BR標簽相關性問題常用的兩種策略進行具體的介紹。
鏈結構的算法在BR算法中考慮了標簽間鏈式的相關性,其代表算法是CC(Classifier Chains)算法[8~9]。圖1表示標簽鏈為y1,y2,y3時算法的分類預測過程,與BR算法類似,CC也會依次為每個標簽訓練分類器,但區別是CC訓練每個分類器時需要添加標簽鏈中在預測標簽前的標簽作為額外屬性。由于使用的標簽鏈順序是隨機的,算法性能會受到鏈順序的影響。因此,算法作者在CC基礎上使用集成學習的思想提出了ECC算法[8~9],從而弱化標簽鏈選取對性能的影響。此外,Cheng等[10]通過計算概率分布來選擇最優的鏈順序,提出PCC和EPCC算法。Huang等[11]通過構建有向無環圖來尋找合適的鏈順序,提出GCC算法。
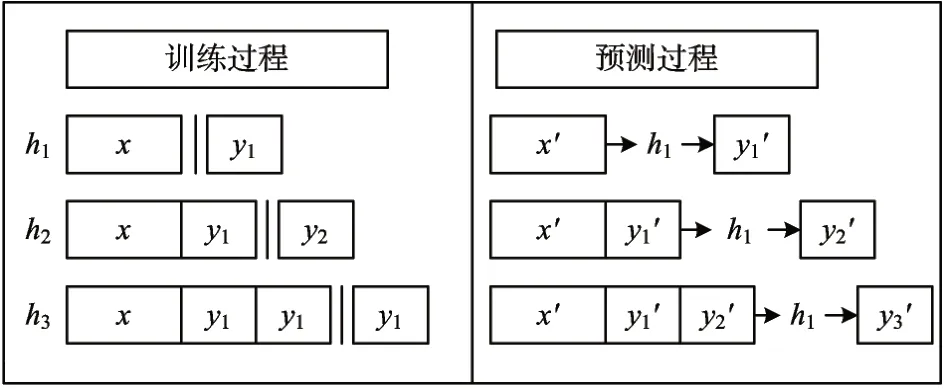
圖1 鏈結構代表算法CC分類示例
堆疊結構的算法在BR算法中考慮了其它所有標簽的相關性,其代表算法是DBR(Dependent Bi?nary Relevance)算法[12]。DBR算法的分類預測過程如圖2所示,需要首先用BR算法為每個標簽訓練一個二分類器作為基分類器,然后再依次為每個標簽訓練一個元分類器,元分類器的構建需要添加其它所有標簽作為額外屬性。由于某些標簽之間并不存在依賴關系,DBR算法考慮所有標簽相關性會來帶冗余依賴的問題。針對這樣的問題,Zhang等[13]提出一種基于DBR的剪枝算法(Correla?tion-Based Pruning of DBR,CPDBR),通過計算標簽間相關性系數phi來量化標簽相關性,最后通過閾值來排除冗余依賴的影響。此外,為了解決DBR算法仍會存在的錯誤傳播問題,Alali等[14]提出Pru?Dent算法。
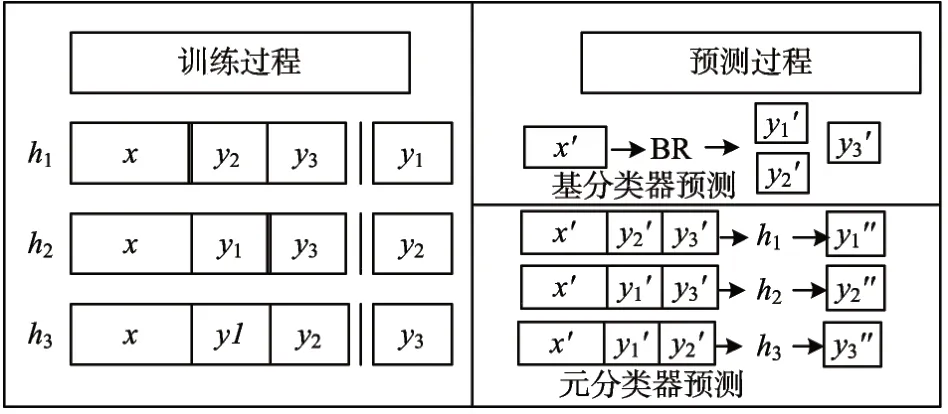
圖2 堆疊結構代表算法DBR分類示例
3 本文算法
針對BR未考慮標簽相關性以及存在冗余屬性的問題,本文提出基于標簽相關性和特征選擇的FLBR算法。同時針對現有考察標簽相關性方法存在的冗余依賴和錯誤傳播問題,FLBR采用控制結構的方式考察標簽相關性。以下是算法的具體介紹。
3.1 特征選擇步驟
FLBR算法首先需要進行特征選擇,考察標簽和特征之間的關系,從而去除冗余屬性。這里的特征選擇使用信息增益法,用信息增益來量化兩集合的相關程度,集合A、B之間的信息增益可以由式(1)計算。對于數值型的數據集需要先對數據進行離散化,這里使用基于信息熵的方法[15]進行數據的離散化。
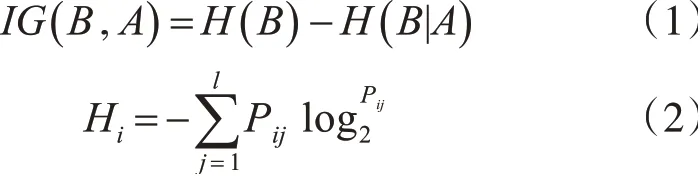
其中,H(B)表示集合的熵,其值可以由式(2)計算。H(B|A)表示A集合發生的條件下,B集合的條件熵,其值可以由式(3)計算。
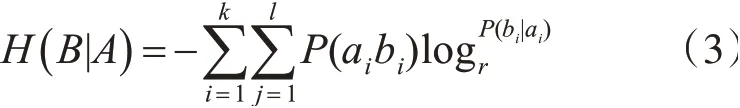
特征選擇過程中需要先用公式(1)分別計算每個特征跟標簽的信息增益值,然后根據值的大小產生特征排名,最后通過閾值法刪除信息增益值小于給定閾值t1的特征,留下的特征集合即為標簽的相關特征子集。這里標簽yi的相關特征集合Fi可由式(4)得到。
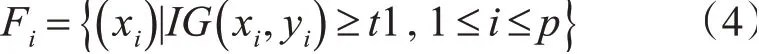
3.2 基分類器構建步驟
經過上一步驟后可以得到每個標簽的相關特征集合Fi,接下來使用該特征集合為每個標簽分別構建基分類器h(i)←B({Fi,yi}),其中B表示二分類學習算法。
在訓練元分類器之前,需要考察每個標簽基分類器的預測性能,找出預測準確率低的標簽集合。本文將這些標簽稱為“易錯標簽”,通過去除相關標簽中的易錯標簽來避免錯誤傳播問題。
為了考察每個標簽被預測成功地難易程度,需要為每個標簽分別訓練分類器t(i)。首先從訓練集選擇一個子集Ds?D作為t(i)的訓練集,然后使用測試集DDs對分類器進行驗證。這里使用預測精確率作為評價指標,統計每個標簽的預測精確率pi。預測概率小于閾值t的標簽即為易錯標簽,易錯標簽集合記為Le。
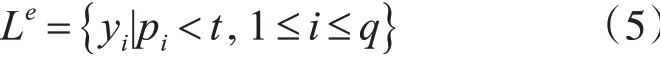
3.3 元分類器構建步驟
在元分類器的構建階段,FLBR使用控制結構的方式考察標簽相關性,避免冗余依賴的影響。這里的標簽相關性還是通過信息增益方法進行衡量,利用式(1)計算每個標簽跟其它標簽的信息增益值,標簽間的相關性小于給定閾值將會判定為無關標簽,無關標簽集合記為Lu。這里相關標簽的判定閾值仍選用式(4)中使用的t1。
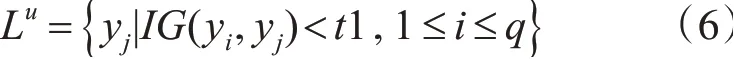
經過上面的處理后,可以得到每個標簽中的相關標簽集合Li=L-Le-Lu,結合特征選擇的結果可以得到新的特征集合為每個標簽訓練元分類器h′(i)←B(Fi')。FLBR算法的訓練過程描述如下。
算法1 FLBR算法的訓練過程
判定易錯標簽的閾值t
二分類學習算法B
輸出:為每個標簽yi訓練的兩個分類器hi,h'i
算法步驟:
1)fοr i=1tοq dο
2)根據公式(4)得到每個標簽i的相關特征集合Fi;
3)為標簽i訓練基分類器h(i)←B({Fi,yi});
4)end for
5)對訓練集D隨機采樣得到子集Ds?D;
6)fοr i=1tοq dο
7)為每個標簽i訓練驗證分類器t(i)←B(Ds);
8)end for
9)根據公式(5)得到易錯標簽集合ye;
10)fοr i=1tοq dο
11)根據公式(6)得到標簽新的特征集合
12)為標簽i訓練元分類器
13)end for
14)返回每個標簽的分類器(h'1,h'2,…,h'q)。
在對實例x分類時,需要先去除其特征集合中的冗余特征,得到其基分類器的預測結果。然后將每個標簽相關的正確標簽加入到特征集合中,最后獲取元分類器的最終分類結果。
4 實驗分析
4.1 數據集介紹
本文在六個多標簽基準數據集上進行實驗對比。所選數據集涉及多標簽學習的音樂標注、基因功能預測、文本分類和聲學分類四個不同應用領域。表1給出了數據集的統計信息,這些數據集可以從http://mulan.sourceforge.net/上獲取。
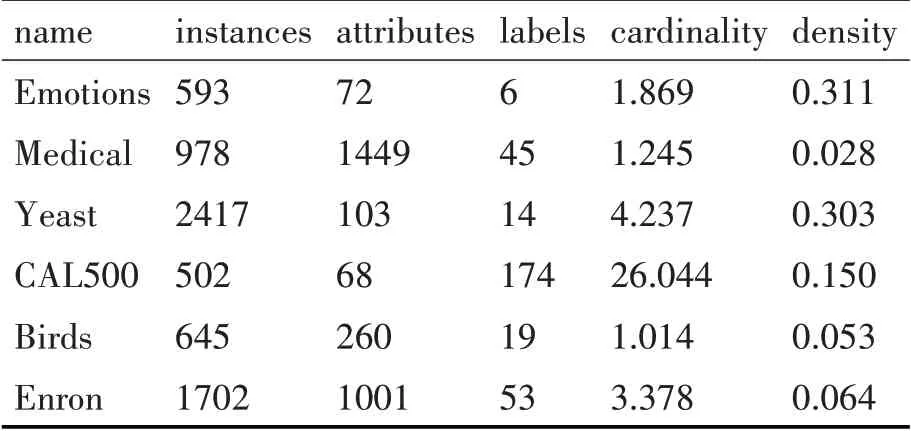
表1 實驗數據集信息
4.2 評價指標
在給出各個評價指標的數學定義之前,先介紹使用到的數學符號。給定一個測試實例xi,h表示分類器,f表示排序函數,rank f則表示指定標簽的排名,p表示實例個數,Δ表示兩個集合中不同元素的數量。本實驗所使用的評價指標主要包括以下五種:
1)漢明損失(Hamming Loss):實例被誤判的次數,包括屬于所給實例的標簽未被預測,以及預測出的標簽不屬于所給實例,其定義如下:
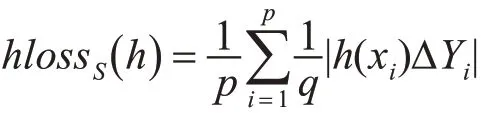
2)單一錯誤(One-Error):排名第一的標簽不屬于所給實例的次數,其定義如下:
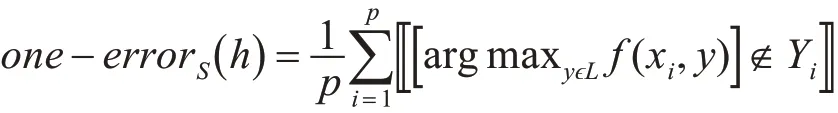
3)覆蓋距離(Coverage):預測標簽序列中,平均走多少步才能覆蓋所給實例的所有相關標簽,其定義如下:
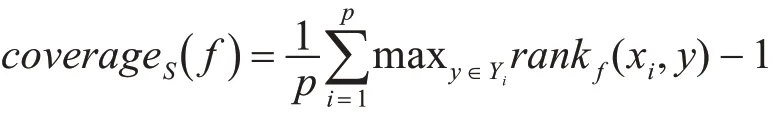
4)平均精確度(Average Precision):統計標簽在預測的標簽序列中排名在其前面的相關標簽的個數,其定義如下:
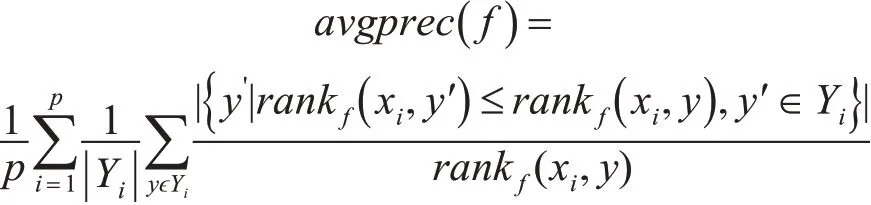
5)排序損失(Ranking Loss):考察標簽排名中出現排序錯誤的情況,其定義如下:
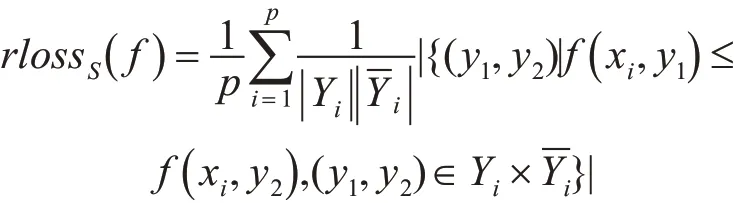
上述五種評價指標中,除平均準確率是取值越大了算法性能越好外,其他四個指標都是取值越小越好。
4.3 實驗結果及分析
實驗主要包括兩部分:第一部分是特征選擇過程的實驗,用以確定最佳的特征選擇百分比;第二部分是FLBR算法和其他BR改進算法的對比實驗,用以驗證FLBR算法的有效性。
首先進行第一部分實驗,研究特征選擇百分比t對算法結果的影響。這里選擇C4.5分類器作為基礎分類器,在6個數據集上進行實驗。實驗采用10重交叉驗證方法,統計10次交叉驗證結果的均值作為最終結果,實驗結果如圖3所示。
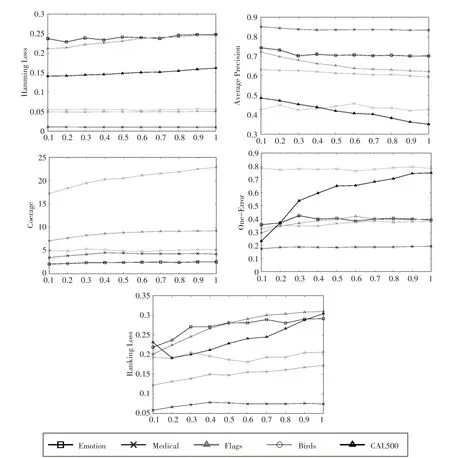
圖3 特征選擇閾值t1的實驗結果
從以上結果可以看出,隨著t1的增大,CAL500和Yeast數據集的各項評價指標都明顯變差,Emo?tion、Enron和Medical數據集的各項評價指標有變差的趨勢,變化幅度相對較小,這五個數據集最佳的特征選擇百分比在0.1~0.2之間。Birds數據集的各項指標一直在小范圍內波動,沒有明顯的變化趨勢,但是其在0.2處的評價指標優于多數其他取值。因此,當t1取0.2時,各個數據集都具有較好的表現。
接下來進行第二部分的實驗,將FLBR算法和典型的BR改進算法進行對比。實驗中采用的對比算法有BR,MLSF,FBR,DBR和CPDBR算法。其中FBR是第一部分實驗所用算法,僅進行了特征選擇。FBR和MLSF是針對冗余特征問題的改進方法,DBR、CPDBR和GCC是針對標簽相關性問題的改進方法。本文算法在Weka-3.7.10系統平臺上設計和實現,各算法統一使用C4.5分類器作為基礎分類器。FLBR算法中涉及到兩個參數,易錯標簽的判定閾值t取0.6,特征選擇百分比使用上文得到的結果0.2。其他算法涉及到的閾值均使用原文中選取的閾值。各算法統一使用10重交叉驗證后的結果,各算法在6個基準數據集上的實驗結果如表2~表6所示。
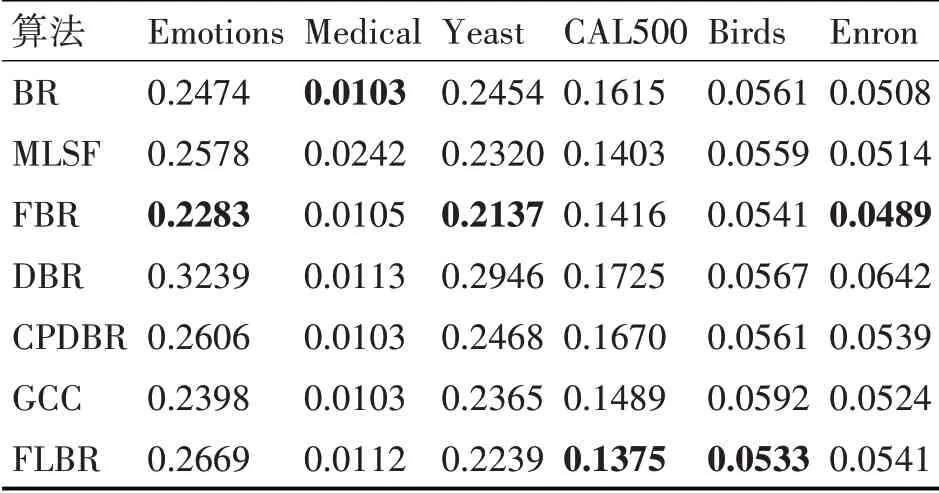
表2 各算法在數據集上的漢明損失
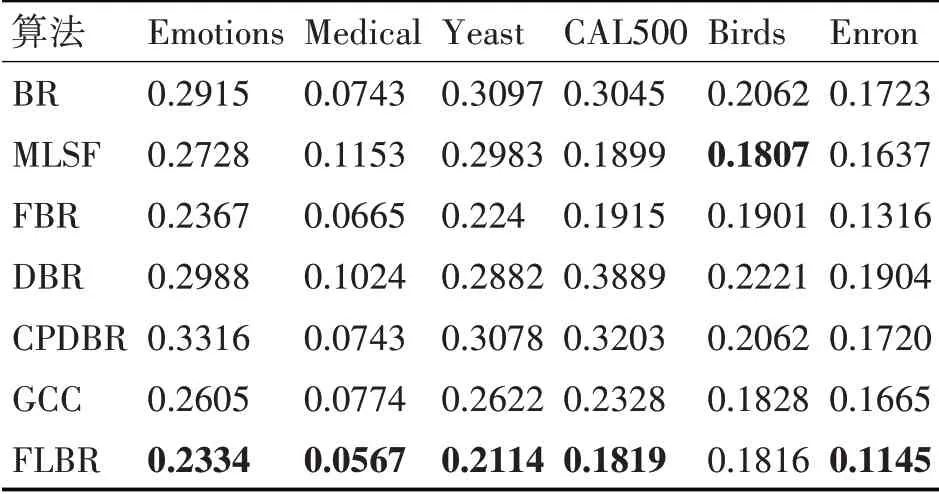
表6 各算法在數據集上的排序損失
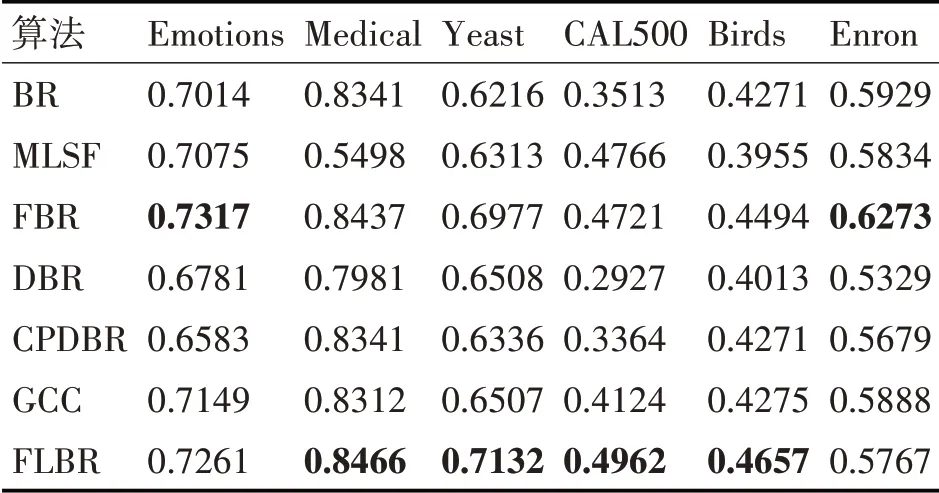
表3 各算法在數據集上的平均準確率
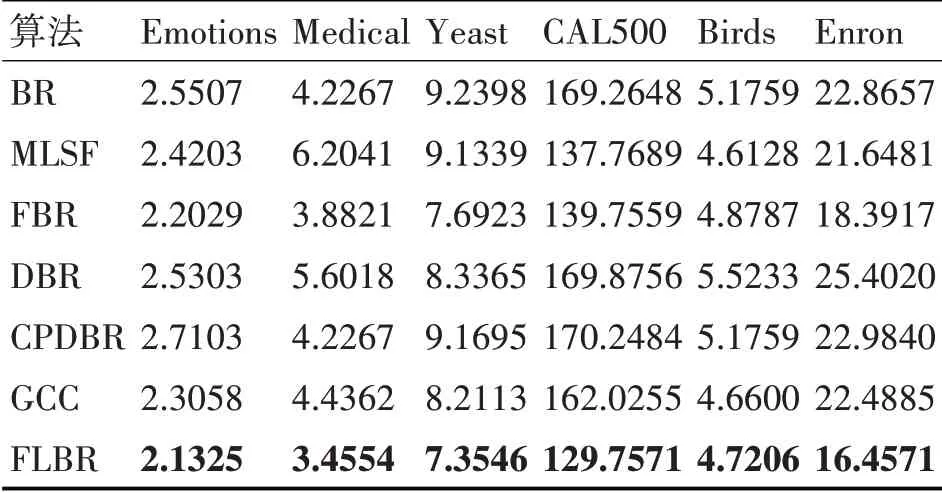
表4 各算法在數據集上的覆蓋距離
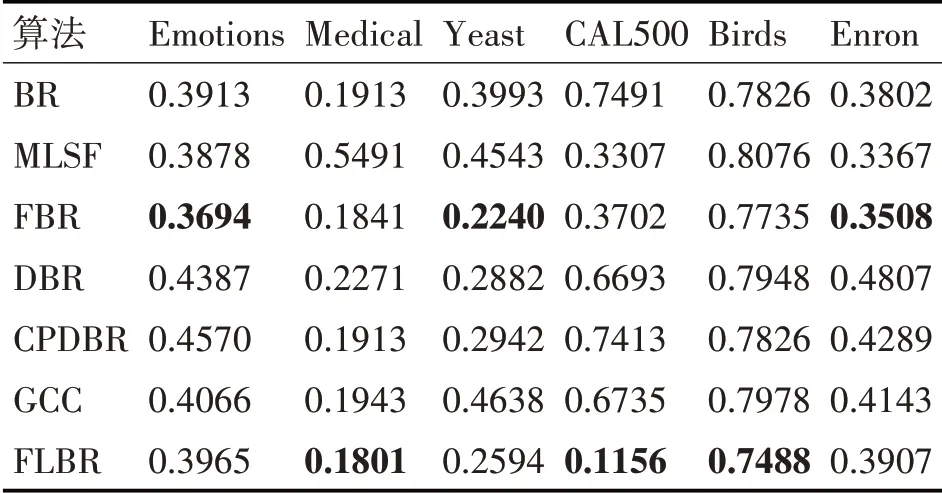
表5 各算法在數據集上的單一錯誤
在特征選擇方面,MLSF算法在4個數據集上的表現比BR算法好,而FBR算法在6個數據集上的表現都優于BR算法,并且FBR在每個指標上的提升效果更明顯。這一方面表明通過解決冗余屬性問題可以有效提升算法性能,另一方面也說明FBR是一種有效的特征選擇方法。
在考慮標簽相關性方面,DBR算法僅在Yeast數據集上優于BR算法,說明無關依賴的引入會誤導分類結果。CPDBR算法除了Yeast外,各項指標都優于DBR,但是相較于BR算法并未有明顯提升,說明其并未徹底解決冗余屬性的問題。而FL?BR算法在4個數據集上的表現優于FBR算法,說明FLBR算法通過控制結構考察標簽相關性的方式有效解決了冗余屬性和錯誤傳播問題,從而驗證了控制結構的有效性。在Emotion和Enron數據集中,FLBR算法的表現比FBR略差。究其原因,第一部分實驗結果表明Enron和Emotions數據集最佳的特征選擇百分比在0~0.1之間,因此使用0.2作為閾值仍會引入無關依賴,從而導致FLBR算法的預測性能變差。
總體來看,算法在6個基準數據集上的總體表現都優于其他典型的BR改進算法。這說明FLBR算法通過同時解決BR存在的冗余屬性和未考慮標簽相關性兩個問題,更有效地提升了BR算法的性能。
5 結語
改進BR算法的方法主要有兩種:考慮標簽和特征間關系以及考慮標簽間相關性,現有的改進工作大多只考慮其中一個方面。針對這樣的問題,本文提出基于特征選擇和標簽相關性的FLBR算法。算法首先進行特征選擇,而后將相關標簽加入特征集合中,通過這兩步操作較好地解決了BR算法存在的問題。此外,針對現有標簽相關性改進工作中存在的無關依賴和錯誤傳播問題,FLBR算法使用控制結構的考察方式予以解決。實驗表明,FLBR算法取得了比BR的相關改進算法更好的性能。算法在考察標簽依賴關系時未考慮其他標簽影響,未來將研究更有效的考察方式,以期獲得更好的分類效果。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
