基于主成分分析的電網用戶分類指標管理體系設計
2021-11-10 05:27:22趙雙鄧楚然潘徽謝瀚陽江疆
電子設計工程 2021年21期
趙雙,鄧楚然,潘徽,謝瀚陽,江疆
(廣東電網有限責任公司,廣東廣州610106)
在目前的電網用戶分類指標中,指標之間相似度過大,導致評價時存在重復指標,因此提出用戶分類指標管理。在對指標進行相似度管理時,大多使用的是聚類方法,但聚類方法無法實現對用戶指標中的概率變量的分析,為實現電網用戶分類指標相似度管理,已有相關領域學者對電網用戶分類指標管理體系做出了研究。
文獻[1]提出監管視角下的電力市場用戶分類指標體系,通過考慮用戶需求響應及負荷曲線,構建分類指標體系,對數據降維,濾除無關信息,完成指標結果可視化。文獻[2]提出高壓企業客戶電力信用綜合評價體系。構建用戶電力信用指標,利用大數據聚類算法構建電力信用評價體系,并通過電力信用等級和信用分計算,驗證所設計評價體系的準確性。
主成分分析是一種可以通過正交變換將一組可能存在相關性的變量轉換為一組線性不相關的變量的一種統計方法。主成分分析可以直接將相關變量轉換為不相關變量,而對不相關變量可以直接使用其他方法來進行相似度分析,無需進行變量轉換[3-5],因此提出基于主成分分析的電網用戶分類指標管理體系設計。
1 系統設計
1.1 量化規則構建
在已有文獻的基礎上,提出了兩級電力用戶的分類指標體系,如圖1所示。

圖1 電網用戶分類指標體系
圖1中共包括3 個一級指標,20 個二級指標。電壓等級B1代表用來衡量電網用戶的負荷線路電壓,并根據電壓的負荷情況劃分等級。年用電量B2代表當前電網用戶的用電規模,指標采用年用電量來評判。年最大負荷B3表示電網用戶在當年內,所有用電設備使用時的最大用電負荷。而在用電情況指標中存在量級差異性,因此文中將上述的電壓等級B1、年用電量B2、年最大負荷B3并這3 個指標按照量化規則進行量化[6]。年用電負荷率B4用來衡量年平均負荷以及最高負荷之間的差異度,用電波動率B5表示該用戶對用電穩定性的需求程度。而其中B4的量化,根據相關文獻提供的數值差別,使用10 000 和年用電量B2的乘積,除以8 760 與年最大負荷B3乘積的值,即為用戶在當年的年用電負荷率。設Li為第i個月的用電量,可將B5量化為:

式中,代表i月中的用電量均值。在得出式(1)的值后,對數據中的B5指標取倒數,并使其指標同樣具有數值越大越好的性質。而用戶功率因數B6反映用戶的用電品質,表示為:

式中,d代表當月的平均功率因數,月平均功率因數作為調整力率電費的數值,指標依據為該用戶每個月的實用有功電量。式(2)中,d1和d2分別代表月平均功率因數的下限和上限。
1.2 主成分分析分類指標
在保證不同指標可以相同量化后,針對每個方面的候選指標進行主成分分析,得到每個主成分的方差貢獻值。以每個主成分中的方差貢獻率,作為主成分分析中的權重和候選指標的載荷系數,在方差貢獻率絕對值處于指標方差和之間時,對該指標進行計算[7-10]。同時反映實驗對象信息的重要水平[11]。將某一指標設為X,指標采用X1,X2,…,Xn來表示,若按照其中某一個指標Xp為例,則Xp的重要水平即:
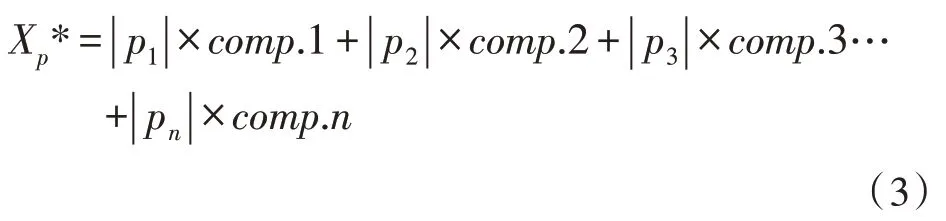
式中,p1,p2,…,pn代表Xp的載荷系數,comp.1,comp.2,…,comp.n作為主成分的方差貢獻率,而在數值接近零時則任務指標的重要性較小,并在候選指標里刪除,剩余指標進入下一步。而對剩余的候選指標可以使用相關系數法對候選指標之間的相關系數進行檢驗[12-13]。文中將閾值設置為0.3,也就是說在該指標和其他指標之間的相關系數均小于0.3 時,候選指標可以直接進入最后的用戶分類指標中,而剩余指標則進行進一步地分析。對存在相關關系的指標再次使用主成分分析,并分析指標的重要程度,同時對剩余指標進行運算,建立相關系數矩陣[14-15]。
1.3 剩余指標曲線聚類分析
對剩余的指標使用負載曲線聚類進行處理,根據常用的MIA指標對各聚類算法進行比較,其中MIA指標可以代表在各聚類中心與對應聚類中的所有元素中的聚類平均值,MIA指標計算如下:

式中,假設通過聚類分析和分類電網用戶類數為K,則CK代表在每個聚類中包含的單位集合,nk代表每個聚類中的單位數目,而在每個聚類中的代表線CTK代表該聚類方法的聚類中心,其中k=1,2…k。d代表剩余指標經過主成分分析后得出的相關系數。而其中:
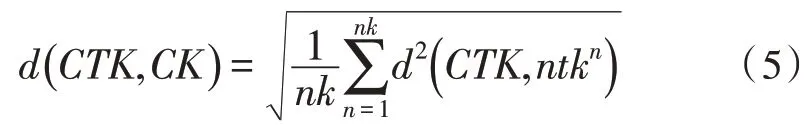
式中,ntk代表在該集合中的所有元素。通過MIA指標來對同一類的負荷曲線之間的聚類進行表示,而其中MIA數值越小則說明該指標類的重要性越高。這里可以參考在主成分分析中的相關系數矩陣表得出全不相關指標,在通過聚類后,要考慮聚類后的指標與全不相關指標是否相似或相關。在定義相似度時則使用曲線聚類分析,將定義相似度作為兩條曲線之間的距離s,在曲線中兩條曲線之間距離越小,則相似度越大,其中用c來代表48 個時刻點,p總,i與p分,i則代表總負荷曲線和各類負荷曲線所對應的時刻負荷值,即:
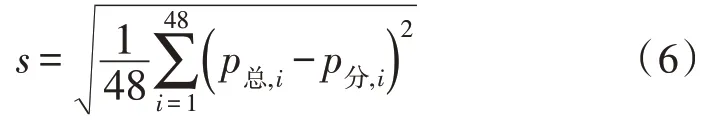
通過公式(6)確立在聚類指標間的相似度,而對兩個聚類指標間相似度過高的指標進行修改或移除。而使用曲線聚類處理無法將指標中概率出現的變量相似度進行分析,因此需要使用Helinger 距離分類變量運算法來對指標之間的相似度實現運算[16]。
1.4 指標相似度管理
考慮在被聚類的指標中的變量,而使用曲線聚類分析難以確認分類指標中變量的相似度,因此對已經完成的聚類指標中的變量間的相似度進行計算。文中使用Helinger 距離的分類變量運算,在概率論中,f散度是用來度量兩個以概率分布的變量E與Q之間的差異性的函數,設f(t)作為定義在t>0區間上且f(1) =0 的凸函數,這時若指標中的變量E與Q呈現概率分布式,那么E與Q之間的f散度則為:

式中,y為未知的概率出現的變量,而當f(t)=1-時,得出的f散度稱為Hellinger 距離,在該情況下E與Q之間的Hellinger 距離的計算公式為:

式中,d2H(E,Q)即為得出的Hellinger 距離,而當指標中出現離散變量時,E與Q之間的Hellinger 距離公式變為:
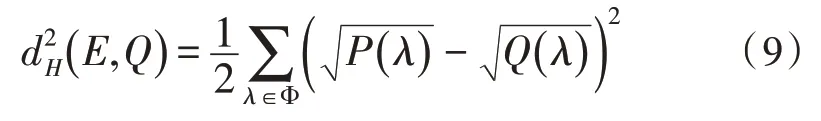
式中,將E與Q在可度量空間上的變量設為λ,根據式(8)和式(9)的計算即可得出兩個分類指標中變量的相似度。根據上文的聚類分析與Hellinger 對用戶分類指標中的相似度實現管理,提高用戶分類的效率[17]。
2 實驗論證分析
為了驗證該文分類指標管理體系的可行性,使用該文用戶分類指標管理體系以及文獻[1]中的分類指標管理、文獻[2]分類指標和無管理的分類指標進行分類。
2.1 實驗算法
實驗中,通過對4 種分類指標得出的用戶分類指標之間進行相似度計算,得出實驗對象的優劣性。實驗中使用的相似度計算法為歐式距離系數,如圖2所示。

圖2 兩用戶之間的距離系數
如圖2所示,假設實驗分類得到的兩個用戶為S1和S2,在橫坐標中的Z1表示其中的特征屬性1,縱坐標Z2表示特征屬性2,對特征屬性來說,期間差異越大則距離越大。分類指標的相似系數計算如式(10)所示:
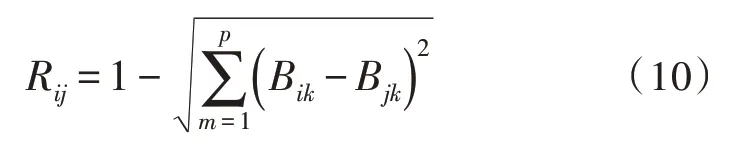
式中,每個分類指標樣品中存在有p個變量,而Bik表示在第i個分類指標樣品中的第m個指標的標準化數值。而Bjk則代表在第j個樣品中的第m個指標的標準化值,其中,在第i個樣品和第j個樣品之間的歐氏相似系數設為Rij。
2.2 實驗結果
實驗中使用了4 種分類指標進行管理,并根據電網用戶的分類依據,使用上述算法,將所分的每兩個指標作為一個指標對比分組,并將指標對比分組使用上述算法進行相似度分析,根據集中指標分組最終得出的平均相似度系數來判斷指標管理體系的優劣性。圖3是經所提方法、文獻[1]方法及文獻[2]方法管理后的分類指標之間的相似度。
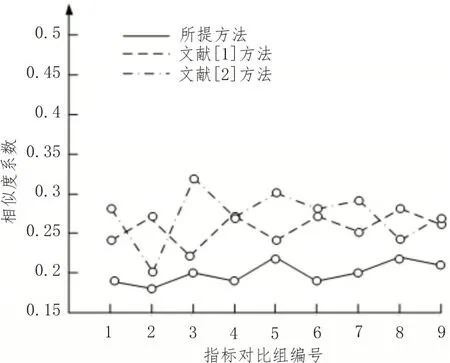
圖3 經體系1管理后的指標相似度
分析圖3可知,經所提分類指標管理后指標之間的平均相似度為0.197。且每組指標對比組之間相似度系數差距不明顯。經文獻[1]方法管理后的用戶分類指標之間的平均相似度為0.261。因體系管理后,分類指標數不同,因此實驗中的指標對比組數量也不同。而僅文獻[1]方法管理后的指標相似度之間差別較為明顯。在經文獻[2]方法管理后的分類指標之間的平均相似度為0.257,且每個指標對比分組之間的相似度系數明顯。
為了進一步判斷用戶分類指標管理的有效性,使用無指標管理的用戶分類法來進行指標分類,實驗結果如圖4所示。
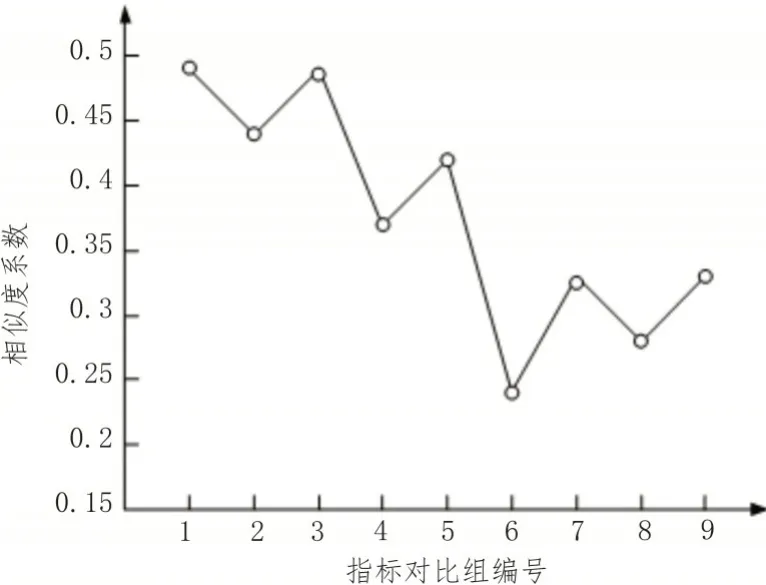
圖4 不使用指標管理的指標相似度
分析圖4可知,在不使用指標管理情況下的指標之間平均相似系數為0.370。其原因在于不使用指標管理,導致指標之間的相似度系數差別很大,因此存在高相似度的分類指標。經由實驗證明,文中設計的基于主成分分析的電網用戶分類指標管理體系可以有效地對指標之間的相似度實現管理,具有可行性。
3 結束語
文中對電網用戶的分類指標,設計了基于主成分分析的電網用戶分類指標管理體系。通過主成分分析的變量轉換,并使用Hellinger 距離分類變量運算,實現對分類指標的管理[18]。但在設計中因使用Hellinger 對概率出現的指標變量進行運算,導致運算結構繁瑣,運算時間較長,仍需進一步地改進。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:24
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
商用汽車(2016年11期)2016-12-19 01:20:16
山東工業技術(2016年15期)2016-12-01 05:31:22
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
