燃氣負荷預測技術發展及應用現狀研究
2021-11-12 01:45:10劉金源陳傳勝王壽喜
工業加熱 2021年10期
關鍵詞:模型
尹 恒,劉金源,陳傳勝,全 青,王壽喜,
(1.中石化川氣東送天然氣管道有限公司,湖北 武漢 430020;2.西南石油大學 石油與天然氣工程學院,四川 成都 610500;3.西安石油大學 石油工程學院,陜西 西安 710065)
隨著近幾年天然氣消費量的持續增長,我國的天然氣產業得到了飛速發展,天然氣管道事業也必將迎來新的機遇與挑戰[1]。然而,長輸天然氣管道的調度管理、規劃運營和運行優化,都必須依賴于準確的負荷預測技術[2]。特別是在管道公司與下游用戶簽訂“照付不議合同”的前提下,長輸天然氣管道準確的負荷預測技術就顯得極其重要,它涉及供氣系統的安全性、可靠性和管道公司的經濟效益等諸多方面的因素,是智能管網系統實現規劃、建立、調峰與調度等功能的關鍵技術[3]。因此,準確的燃氣負荷預測值對提高長輸天然氣管網供氣系統管理水平、保證安全平穩供氣、提高供氣系統的經濟性均有著十分重要的意義[4]。
我國對于長輸天然氣管道下游用戶負荷預測方面的研究起步較晚,過去幾十年間,預測算法由于受到科技發展瓶頸的限制,始終停留在人工經驗分析、傳統預測模型以及結構簡單的神經網絡預測模型上,雖然部分模型可以獲得較好的預測結果,但其適用性及穩定性均有待提高[5]。隨著近幾年計算機科學技術的迅猛發展,“AlphaGo”人工智能程序、面部識別系統、汽車無人駕駛系統等高精尖技術的研發,掀起了人工智能和全球各個領域相結合的發展浪潮[6]。對于燃氣負荷預測領域,算法結構更加復雜、更加先進的人工智能模型,以及將不同預測模型和人工智能領域相結合,或用各種優化算法對人工智能模型進行優化的組合預測模型憑借其更高的預測精度和穩定性正在迅速崛起[7]。
為了確保燃氣負荷預測技術在實際應用過程中的準確性、穩定性和適用性,本文對預測模型的發展現狀、應用特點和衍生出的預測產品進行研究,并對燃氣負荷預測技術未來的發展方向做了進一步分析,以期為長輸天然氣管道企業的用氣量規劃、儲氣調峰和運行優化提供參考意見。
1 燃氣負荷預測技術發展現狀
20世紀中葉,Verhulst等人對法國人工煤氣需求開展調查研究,建立了需求預測模型(包括需求方程、資源供應方程以及氣價、收入的平衡方程),開創了燃氣市場需求預測的先河[8]。半個多世紀以來,國內外學者在燃氣負荷預測領域開展了大量的研究工作,應用不同數學方法進行了嘗試。從文獻檢索情況看,燃氣負荷預測技術按照算法理論的不同整體上可分為兩類:傳統預測模型和基于AI的預測模型[9]。
1.1 傳統預測模型
傳統預測模型大多以統計學理論為基礎,通過對歷史負荷數據進行分析,發掘出數據間存在的潛在規律,從而建立可以表現負荷數據發展規律的數學模型,對未來燃氣負荷值進行預測。燃氣負荷預測領域常用的傳統預測模型包括時間序列模型、回歸預測模型和灰色預測模型三種[10]。此外,部分學者為了取得更高的預測精度,對傳統預測模型進行了改進和組合,得到了多種預測效果更好的組合預測模型[11]。
楊聞宇通過分析濟南東部地區短、中期燃氣負荷特性,建立了基于指數平滑法的日負荷和年負荷預測模型,經實例驗證,模型預測結果均可達到預期目標[12];李楠根據中長期燃氣負荷變化特點,針對中期負荷建立了基于時間序列和RBF神經網絡的分解-組合模型,針對長期負荷建立了基于殘差修正的GM(1,N)模型,預測精度較高[13];武海琴等通過分析北方某城市各類天然氣用戶歷史數據,在回歸預測法的基礎上建立了供暖、居民、商業等各類用戶的單獨預測模型及總體預測模型[14];鄒文波通過分析北京首都機場2012—2013年供暖季燃氣日負荷和大氣溫度二者的相關性,建立了基于日最高溫和最低溫的燃氣日負荷一元線性回歸預測模型[15];吳峰利用灰色理論對某市的燃氣年負荷進行預測,取得了較好的預測結果[16]。
上述傳統預測模型雖然在應用過程中獲得了較好的預測結果,但模型自身存在的缺陷以及模型應用范圍的局限性也尤為顯著。如:灰色預測模型只能挖掘少量歷史負荷數據中潛在的發展規律,無法從積累的大量數據中擬合出燃氣負荷完整的變化情況,其預測結果為趨勢穩定上升或下降的曲線,與燃氣負荷實際變化情況的誤差呈穩定增加趨勢。時間序列模型相較于灰色預測模型有所改進,預測結果不再是趨勢穩定的曲線,但該模型同樣無法考慮其他因素對燃氣負荷的影響,擬合能力較弱。回歸預測模型只能考慮少量影響因素,一旦加大模型輸入的歷史負荷數據量和影響因素維度,預測結果就會產生較大偏差,即模型的擬合能力會隨著數據量的增加而變弱。三種常用傳統預測模型的應用特點見表1。

表1 傳統預測模型應用特點對比表
傳統預測理論的出現,填補了當年燃氣負荷預測領域的空白,使得燃氣企業對于未來一段時間內天然氣可能的消費情況,有了一定程度的把握。然而,傳統預測模型的應用雖然促進了國內外預測領域的發展,但其無法同時考慮多種負荷影響因素、模型參數選擇依賴于技術員的操作經驗、模型擬合能力較弱等缺陷,使得模型的發展受到了限制。以負荷影響因素為例,燃氣負荷數據的規律性特征并非自然形成,而是在很大程度上受到氣象狀況、日期狀況(法定節假日、冬季供暖等)以及國家政策等因素的影響,如果在不考慮影響因素的基礎上建模,模型對于預測結果的擬合能力勢必變弱。此外,部分傳統預測模型的參數選擇也沒有特定的優化方法,建模過程中參數的設定完全依賴于人的經驗,預測結果時好時壞,穩定性和適應性較差,無法在實際應用過程中起到一定的指導作用。
1.2 基于AI的預測模型
隨著科學技術的迅猛發展,計算機的海量數據存儲能力及分布式運算能力得到大幅度提升,全球科技正式步入大數據時代。與此同時,以大數據為背景的人工智能技術也逐漸開始和燃氣負荷預測領域相結合,誕生了許多基于AI的智能化預測模型[17]。目前,應用較多的AI預測模型包括基于人工神經網絡(Artificial Neural Networks,簡稱ANN)的預測模型、基于支持向量機(Support Vector Machine,簡稱SVM)的預測模型、基于深度學習(Deep Learning,簡稱DL)技術的預測模型以及利用各種優化算法對AI預測模型進行優化的組合模型[18]。
相比于傳統預測模型,AI預測模型強大的自主學習能力和非線性擬合能力使得模型預測結果具有更高的精度。王婷通過引入幾種生物學領域的參數尋優算法來對BP神經網絡進行參數尋優,最終確定布谷鳥搜索算法(Cuckoo Search,簡稱CS)對BP神經網絡(CS-BP)的參數尋優效果更好,預測精度更高[19];Nan Wei等將改進后的奇異譜分析(Singular Spectrum Analysis,簡稱SSA)算法和LSTM(Long Short-Term Memory,簡稱LSTM)模型相結合,構建了ISSA-LSTM組合預測模型,并對倫敦、墨爾本、卡地亞和香港四個不同氣候帶上典型城市的燃氣負荷值進行預測,預測結果驗證了ISSA-LSTM組合模型良好的魯棒性和精確性[20];張少平在改進粒子群算法ACLSPSO的基礎上,引入經驗模式分解(Empirical Mode Decomposition,簡稱EMD)算法對BP神經網絡優化,建立了EMD-ACLSPSO-BP組合預測模型,達到了更好的預測效果[21];董明亮等應用遺傳算法(GA)對SVM模型的懲罰因子c及核函數g進行優化,構建GA-SVM組合預測模型,并以某省實際樣本數據為例進行驗證,說明了GA-SVM組合預測模型的準確性[22];Omer Faruk Beyca等利用多元線性回歸模型(MLR)、人工神經網絡模型(ANN)和支持向量回歸模型(SVR)對土耳其最大的天然氣消費城市伊斯坦布爾的月負荷和年負荷進行預測,預測結果顯示SVR模型的預測結果與其他模型相比更為準確[23];黃維針對燃氣負荷序列非線性、非平穩的特性,采用優化后的EMD(Empirical Mode Decomposition,簡稱EMD)算法將負荷數據序列分解成多個本征模向量,再分別進行DBN(Deep Belief Network,簡稱DBN)建模和預測,得到各個分量的預測結果,最后使用線性神經網絡將各分量的結果擬合得出最終預測結果。結果表明,EMD-DBN組合預測模型能夠避免單一模型過擬合的問題,提高預測精度[24];Nan Wei等首先將主成分分析法(Principal Component Analysis,簡稱PCA)和相關分析法結合,構建了主成分相關分析法(Principal Component Correlation Analysis,簡稱PCCA),PCCA可以在提取負荷影響因素主要成分的同時,剔除弱相關性數據。隨后利用PCCA對LSTM模型進行優化,并通過與單一的LSTM、PCA-LSTM、BPNN、SVR模型進行對比,驗證了PCCA-LSTM組合預測模型的精確性[25]。
王婷[19]21、張少平[21]212等采用參數尋優算法和分解重構的方式對神經網絡模型進行了優化,但針對神經網絡模型隱含層數的選擇以及隱含層神經元數量多少的問題并未得到解決,僅憑參數尋優算法對神經網絡的權值和閾值進行優化就能提升網絡最重要的收斂能力也存在質疑。董明亮等[22]98同樣應用參數尋優算法對SVM模型的懲罰因子和核函數進行了優化,但預測結果僅限于作者所列舉的樣本數據,優化模型的泛化能力尚未得到驗證,且SVM模型自身對大規模訓練樣本難以實施的缺點也并未得到克服。Nan Wei等[25]利用目前火熱的深度學習算法對燃氣負荷進行了預測,深度學習算法可以從上萬個數據中學習影響因素和燃氣負荷之間潛在的規律,模型結構更加復雜,收斂能力相比于神經網絡模型和支持向量機模型也得到了顯著提升。因此,能夠學習到燃氣負荷更加完整的規律,得到更高的預測精度。三種AI預測模型的應用特點見表2。
AI預測模型的出現,逐漸取代了傳統預測模型在國內外預測領域的地位。從文獻檢索情況看,自2017年步入大數據時代以來,傳統預測模型的發展呈穩定下降趨勢,取而代之的人工神經網絡、支持向量機和深度學習等AI預測模型,因其能夠考慮多種燃氣負荷影響因素,以及強大的自學習能力和非線性擬合能力得到了大力發展。特別是得益于科技的迅猛發展和大數據的時代背景,可以綜合考慮幾千、幾萬甚至幾十萬輸入數據,可以考慮更多中間層數和更多神經元個數的深度學習技術,在燃氣負荷預測領域應用之初就獲得了大量學者的青睞。
深度學習模型不僅可以考慮幾維至幾千維度的影響因素數據,其模型所能承載的網絡復雜程度和超越一般神經網絡的非線性擬合能力,使得預測結果的精確性、穩定性和適用性都得到了大幅度提升。因此,深度學習技術完全可以作為未來燃氣負荷預測領域新的發展方向,能夠對燃氣企業合理規劃燃氣用量起到很好地指導作用。
呼吸道肺炎支原體感染即為臨床中十分普遍的病癥,其大多產生在嬰幼兒與學齡以前的幼兒中[5-6]。現階段,其患病機制依舊沒有確定,然而,多認為是由于免疫功能紊亂而引發的免疫損傷。有研究人員指出了,在產生肺炎支原體感染后,大多會具備異常免疫應答,使得白三烯等各類炎性因子被釋放,在呼吸道中產生慢性炎癥而引起氣道高反應,臨床表現主要就包括了慢性咳嗽、氣喘等[7-8]。同時,支原體肺炎可以在傷害呼吸道的同時引發腎炎、心肌炎等各類系統性病癥,如果沒有立即且高效地對患兒開展治療,就會對其平日的生活、學習等帶來過多的威脅。
2 燃氣負荷預測軟件應用現狀
歐美等發達國家的天然氣市場發展較快,目前已逐漸趨于成熟階段。市場用氣結構穩定、用氣規律顯著等特點,使其對天然氣負荷特性的分析以及預測模型的搭建都已達到較高水平[26]。許多燃氣企業結合下游用戶用氣特點,自主研發負荷預測軟件,用于預測未來一段時間內的天然氣需求,幫助企業管理者制定購銷方案、調峰方案以及運行優化方案等,實現企業利潤最大化[27]。
2.1 慕達數據分析預測系統
德國OGADO公司開發的慕達數據分析預測系統在歐洲擁有莫斯科,柏林,維也納,法蘭克福等眾多成功案例。在國內已與中國石油、中國石化、新奧燃氣等大型能源企業建立戰略合作,為陜京線、西氣東輸、北京、上海、深圳、青島、杭州、廊坊等數十個省和城市進行了區域燃氣預測及決策管理支持[28]。
慕達數據分析預測系統包含多種負荷預測模型,內容涉及統計學、概率學、專家經驗干預控制、動態數學模型、氣象學、人工智能、機器學習等多個專業領域。該系統通過分析歷史數據和幾個至幾千個維度的負荷影響因素來確定有針對性的預測模型。隨后結合數據預處理、機器學習和關聯規則分析技術,建立預測模型,通過對預測概率進行優化調整,得出未來精確的負荷預測值。慕達數據分析預測軟件的工作平臺架構見圖1。
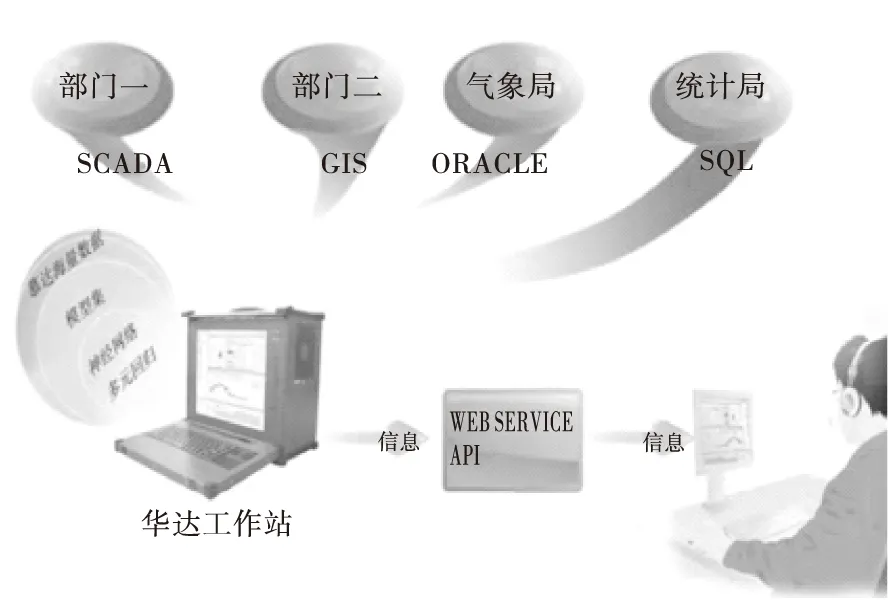
圖1 慕達工作平臺架構圖
2.2 Gas Load Forecaster
英國Emerson能源集團開發的Gas Load Forecaster燃氣負荷預測軟件,已廣泛應用于美國佛羅里達、殼牌等多個世界級大型輸氣企業。GLF軟件在分析歷史負荷數據、氣象數據、日歷數據、經濟數據等負荷影響因素的基礎上,建立神經網絡模型,通過讓神經網絡對歷史負荷數據的復雜規律進行反復自學習,實現對未來燃氣負荷數據的準確預測[29]。
GLF軟件擁有同SCADA系統進行連接的數據接口,可實時讀取SCADA數據對未來燃氣負荷值進行實時預測。GLF軟件還具有模型優化選擇和敏感度分析功能,可在對歷史數據進行分析后自動篩選出最合適的預測模型,預測結果也不是直接作為輸出結果,而是優先對結果進行敏感度分析,基于敏感度分析繼續調整預測結果,再輸出至用戶界面。GLF軟件操作示例見圖2。
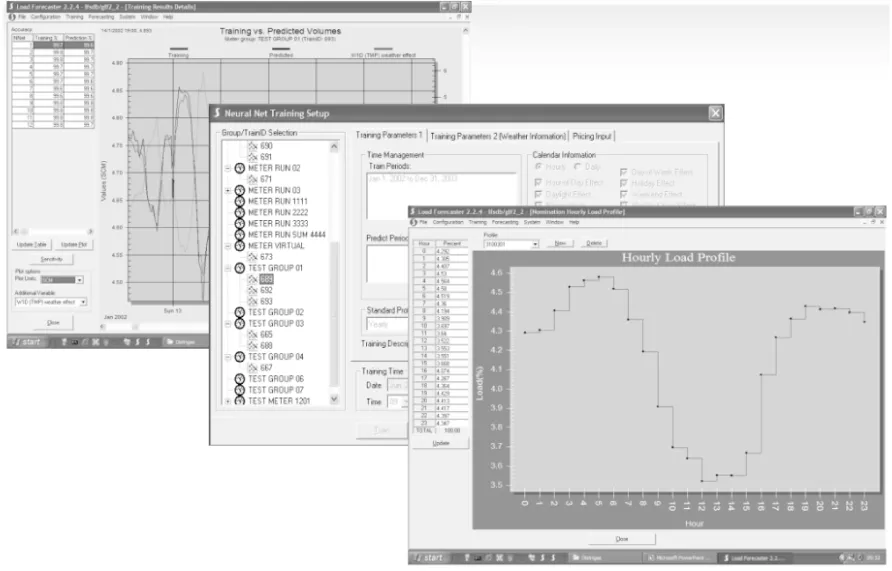
圖2 GLF軟件操作示例圖
2.3 Load Forecaster
美國Gregg Engineering集團開發的Load Forecaster燃氣負荷預測軟件,主要應用于北美市場。LF同GLF和慕達數據分析預測系統一樣,具有數據分析、數據預處理、模型訓練以及預測等主要功能,但LF不同于其他預測軟件,該軟件既可單獨作為燃氣負荷預測軟件使用,也可作為預測模塊集成于Gregg公司自主研發的NextGen管網仿真軟件中。和NextGen集成后的LF不僅能夠進行離線預測,還可以利用SCADA系統讀取到的管網實時數據對未來某一時段內的燃氣負荷值進行實時預測,進而對燃氣企業的儲氣調峰策略進行實時分析和有效指導。LF軟件操作示例見圖3[30]。
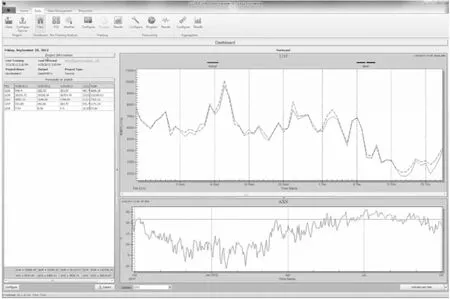
圖3 LF軟件操作示例圖
3 燃氣負荷預測技術展望
隨著我國天然氣消費量的增加、下游用戶增多和天然氣產業鏈的不斷延伸,天然氣的穩定供應成為供用氣雙方共同關注的問題。在天然氣市場發展迅速、基礎設施尚不完善的形勢下,負荷預測在管網安全經濟運行中將發揮越來越重要的作用。結合當前負荷預測技術應用現狀,為提高需求預測精度,未來燃氣負荷預測技術應在下述幾個方面做進一步工作:
對燃氣負荷進行準確預測的前提是歷史負荷數據及其影響因素數據的完整性。然而,現場統計得到的月、日、小時等歷史負荷數據總是存在人為的或系統臨時中斷造成的缺失現象,數據質量不穩定,嚴重影響了預測結果的精確性。因此,有必要完善信息上報渠道,建立完備的歷史燃氣負荷數據庫,為后期預測提供可靠的數據支撐。
2)合理劃分負荷數據類型
多數企業在預測未來一段時間的用氣負荷時,取到的數據是工業、民用等混合用戶的用氣量,并非單一用氣類型的數據。工業、民用氣的用氣規律不同,如果混在一起預測,無疑會加大預測結果的誤差。因此,應按用氣結構合理劃分負荷數據類型,分用戶建立預測模型。
3)利用深度學習技術建立負荷預測模型
在大數據的時代背景下,深度學習技術的出現取代了以往應用廣泛的傳統預測模型和部分AI預測模型。深度學習技術憑借其所能承載的網絡復雜程度和超越一般神經網絡的非線性擬合能力,在應用之初就取得了不菲的成績。利用深度學習技術建立的燃氣負荷預測模型,模型的泛化能力和預測結果的精確程度都能得到大幅度提升,可以將深度學習技術作為未來燃氣負荷預測領域新的發展方向。
4)研發國產化燃氣負荷預測軟件
目前,全國天然氣跨區域骨干管網已基本形成,但管網調度系統不夠健全,干線之間無法做到及時的靈活調用,在出現極端氣象條件或頒布某些對燃氣負荷影響較大的政策時,局部地區依然會出現供氣緊張的局面。歐美等發達國家雖然已經研發出多種負荷預測軟件,但并不適用于國內復雜的用氣特點。國內燃氣企業迫切需要研發一款可以結合本國居民、企業用氣特點的,成熟、可靠的負荷預測軟件。
可以預見,隨著天然氣市場的日益成熟,歷史負荷數據的有效積累和科學處理,以及信息上報渠道的日益完善,燃氣負荷預測技術與人工智能領域的交叉滲透,研究人員對燃氣負荷變化規律會有更加深入準確的認識,燃氣負荷預測將更加準確快捷。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
