課程資源的融合知識圖譜多任務特征推薦算法
2021-11-12 15:03:58徐行健孟繁軍
計算機工程與應用 2021年21期
吳 昊,徐行健,孟繁軍
內蒙古師范大學 計算機科學技術學院,呼和浩特011500
2020年4月28號中國互聯網信息中心(CNNIC)發布的第45次《中國互聯網絡發展狀況統計報告》顯示,截止2020年3月,我國在線教育的用戶規模已經達到4.23億,較2018年底增長約110.2%,占整體網民人數的46.8%,尤其是在2020年初的新冠肺炎疫情期間,在各種在線教育應用平臺的日活躍用戶更是達到千萬以上[1]。
在線教育爆發式增長改變了傳統的教學模式,使人們隨時隨地學習成為現實。但是,伴隨著大數據時代的到來,在線教育平臺的課程數量龐大,學習方向繁多,課程類型應有盡有,對學習者也產生了很多弊端。一是學習者很難短時間內找到適合自己的課程;二是學習者個人所感興趣的學習路線復雜,而學校的培養方案里的課程又趨于單一化和重復化,學習者滿意度低,無法達到預期的教學效果[2];三是大多數在線教育平臺不像傳統教育那樣對學習者提供有效的學習指導、課程規劃,學習者自身缺少對總體知識結構的深入理解互聯網學習資源數量冗雜,導致學習者陷入大量的課程選擇中,從而造成了信息過載,甚至出現了課程的通過率較低的狀況[3],最后,傳統教育模式難以及時有效地發現學習者的學習目標。針對上述問題,一些在線教育平臺通過課程搜索和熱門課程推薦等方法也未能較好的解決。然而,由于知識圖譜作為輔助信息的推薦算法得到充分的關注和研究,使得基于知識圖譜的課程推薦算法進一步地提升推薦效果成為可能[4]。
個性化推薦技術現在已經廣泛運用到各大領域,如電子商務、在線視頻、新聞頭條、自媒體短視頻等領域,有效地解決了各大領域的信息過載問題。對于教育領域方面存在的問題,國內外諸多在線教育團隊也紛紛在探討和研究,近年來取得的研究成果往往都是通過學生選擇課程的歷史和熱門課程大數據分析進行推薦,雖然推薦結果也較為實用,但缺乏對學習者整個學習過程的支持和結合學校的培養方案進行推薦,并且現有算法對課程推薦方面的數據稀疏和冷啟動問題也沒有很好的方法。
本文基于edX公開的課程數據集構建現有課程結構關系的知識圖譜[5],利用多任務特征學習方法模型,提出一個多任務課程推薦算法(Multi-Layer Knowledge graph Recommendation,MLKR),并且與基于內容的協同過濾推薦算法對比,以表征算法性能。
1 課程推薦算法概述
1.1 課程推薦算法
課程個性化推薦技術是在線教育與教育大數據領域的研究熱點之一,國內外眾多研究團隊紛紛提出個性化網絡教育的概念、研究個性化課程推薦算法,目的是降低在線學習的輟學率,激發和調動學習者主動學習的積極性,充分發揮不同學習者的學習個性。
國內學者在心理學層面研究得出[6]:每個學習個體客觀存在的個體差異使得個性化課程規劃對于學習有積極的意義。雖然我國在個性化課程推薦算法起步較晚,但在推薦算法的優化和改進方面有許多成果。王忠華等通過學習資源的協同預測方法,基本緩解協同推薦算法中的擴展性計算和松散型計算等問題[7]。李星雨等利用師生之間的交流,改進基于物品的協同過濾算法,對學生的特征進行分析,提出適合學生的個性化推薦算法,進而緩解推薦結果與學習者貼合度低的問題[8]。檀曉紅等對在線學習者在學習的過程中的動態數據獲取并分析,提取了學習者個性化學習的需求,再通過專業教師對課程進行整體規劃,最后使用遺傳分層推薦算法為學習者推薦課程,顯著提高課程推薦精準度[9]。
國外學者在2008年開始對課程推薦算法進行研究,Jose等通過分析選課系統和電商平臺的差異性和相似性,通過生物啟發算法改進知識和發現關聯規則[10],而近年來的研究大多利用在探討學習者的行為特點來表示學習者的特征,從而產生推薦結果。Pang等把每個學習者行為特征提取并轉換成相同維度的向量,將其分散放在包含相似用戶之中,這些學習者具有更多共同的課程,提出了多層存儲推薦算法(Multi-Layer Bucketing Recommendation,MLBR)和MapReduce技術擴展,使傳統的協同推薦算法性能得到提升[11]。郭清菊等根據學習者的行為和偏好進行學習者瀏覽日志的挖掘,采用AprioriAll算法提出的混合推薦策略,實現了對學習者個性化推薦[12]。
目前,現有應用研究主要集中在采用協同推薦或數據挖掘方法,提高課程推薦準確率,但上述方法常涉及到推薦算法冷啟動的問題,無法建立性能較好的推薦模型以及在沒有初始數據時,無法精準推薦[13]。
1.2 傳統課程推薦算法存在問題
(1)推薦課程準確度問題。使用精確程度高的推薦算法可以為學習者提供更加適合自己的課程,增強滿意度。推薦結果的準確性是一個推薦算法的重要指標。假如一個推薦算法產生的推薦結果不會產生良好的推薦結果,推薦結果將不會有存在意義[14]。
(2)數據稀疏問題。利用傳統協同過濾方法時的相似度計算主要依靠學習者對課程的評分矩陣,實際過程中對課程的評分很少,有些情況僅僅為2%[15]。使得課程評分矩陣過于稀疏,課程與學習者找到相似的鄰居成為困難,造成了課程推薦的質量變低。
(3)冷啟動問題。現在課程平臺會隨著新的學習者和課程需求不斷更新內容,但是在更新之前沒有任何新加入的學習者或者新的課程內容的記錄,造成了推薦算法無法進行及時有效的推薦。
2 知識圖譜輔助的多任務特征學習方法
2.1 課程知識圖譜的構成
對于現有數據集中學習者和課程之間交互的信息稀疏甚至缺少的問題而導致的冷啟動問題,可以通過在推薦算法中引入其他的信息,即輔助信息(Side Information)來緩解。在電影、商品等常見的推薦中引入的輔助信息有:社交網絡(Social networks)、用戶或者商品屬性特征(User/Item attributes)、多媒體信息(Multimedia)、上下文信息(Contexts)等[16]。在本文采用的輔助信息是知識圖譜,用三元組(c1,r,c2)來表示,課程的知識圖譜為G:
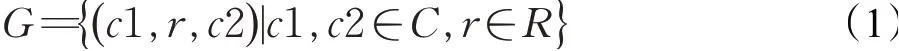
其中,c1和c2∈C,C為edX數據集的所有課程,r∈R,R中構造了5個關系:same.instructor(擁有同一個教師)、same.subject(屬于同一種學科)、hour.low(課程交互時間≤30 h)、hour.mid(30 h<課程交互時間≤100 h)、hour.high(課程交互時間>100 h),如圖1所示。當一個學習者與四門課程有過交互:Java程序設計、數據結構、計算機網絡、操作系統,在知識圖譜中就可以將三門課程關聯到其他的事件中,并連接到其他眾多non-item實體上,再從這些non-item實體又連接到課程實體上,如最右邊的無線網絡技術、網絡信息安全、J2EE架構與應用、編譯原理。
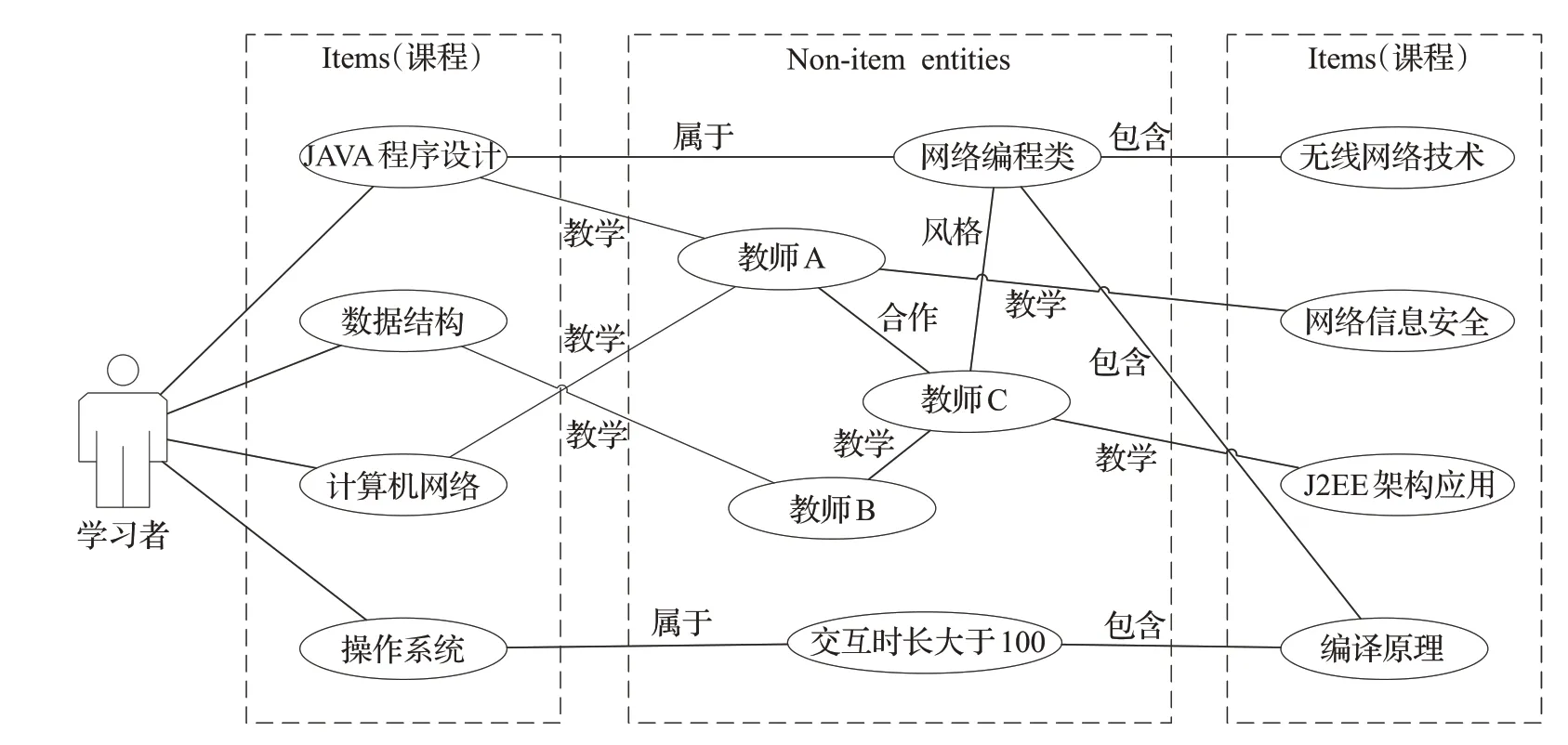
圖1 課程知識圖譜三元組Fig.1 Three tuples of curriculum knowledge map
傳統協同過濾算法就是將中間non-item實體部分替換為其他學習者,其他學習者通過歷史學習記錄等交互過程得到連接,構造的知識圖譜實質是建立一個從學習者已經交互過的課程到未交互過的課程的連接,這些連接不是由其他學習者的交互歷史記錄得來,而是通過non-item實體進行連接。構造知識圖譜的方法提供額外的在課程之間連接的信息來源以及算法中item相似度更準確的計算方式,從而提高推薦課程的精確度[15]。
2.2 MLKR算法
為了緩解傳統課程推薦算法的局限性,提出了基于端對端通用深度推薦框架的MLKR算法,其采用知識圖譜嵌入任務作為輔助推薦任務,其中兩個任務不是相互獨立的,具有較高相關性。主要是由于在推薦算法中的單個課程(item)可能與知識圖譜中單個或者多個實體(entity)相互關聯,所以單個item和其所對應的實體在推薦算法以及知識圖譜中可能存在相似結構,在初始階段非任務特征的潛在空間中也存在相似特征。為了對item和entity之間的共享特征進行建模,在MLKR算法中加入交叉壓縮單元(Cross&Compress)[17],交叉壓縮單元確定了item和entity特征之間的高階交互,并自動控制兩個任務的交叉知識轉移。使用交叉壓縮單元后,item和entity的表征可以相互補充,避免兩個任務產生過擬合和噪聲,并提高泛化能力[18]。整體框架通過交替優化兩個任務的不同頻率進行訓練,以提高MLKR算法在真實環境中的靈活性和適應性。
MLKR算法框架如圖2所示,主要包括三個模塊:推薦模塊、知識圖譜嵌入模塊與交叉壓縮單元。

圖2 MLKR推薦算法框架Fig.2 MLKR algorithm framework
推薦模塊的輸入為學習者向量U與課程向量Cr,輸出為學習者對于課程的選課率p。
模塊分為low-level(低階)和high-level(高階)兩部分,其中low-level部分使用多層感知器MLP(Multi-Lay Perceptron)處理學習者的特征UL,課程部分使用交叉壓縮單元來進行處理,返回一門課程的特征CrL,最后將UL與CrL拼接,通過推薦算法中的函數fRS,輸出選課預測值。對于給定學習者的初始特征向量U,使用L階的MLP提取其特征:

知識圖譜嵌入模塊就是將實體和關系嵌入到一個向量空間中,同時保留結構,對于知識圖譜嵌入模型,現有的研究提出了一個深度語義匹配架構[18],與推薦模塊類似,給定知識圖譜G以及三元組(h,r,t),其中分別通過交叉壓縮單元與非線性層處理三元組頭部h和關系r的初始特征向量[19]。之后將潛在特征關聯在一起,最后用K階MLP預測尾部t:
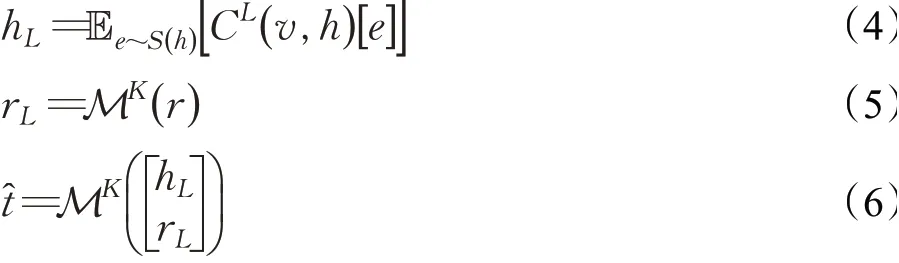
其中,S(h)為h的關聯項集合,t?為根據尾部t得出的預測向量。
最后加入交叉單元是為了模擬item和entity之間的特征交互,其只存在于MLKR算法的初始階層中,由于課程推薦算法中的課程和知識圖譜嵌入模塊的中的實體有著對應關系,并且有著對同一item的描述,其中的embedding(嵌入)是相似度極高的,即可以被連接,于是中間每一層都使用交叉壓縮單元作為連接的結合。如圖3所示,L層的輸入為課程item的embeddingCrL和實體的embeddingeL,下一層的輸出為embedding,交叉壓縮單元模塊分為兩部分:Cross(交叉)和Compress(壓縮),其中Cross將CrLCrL,eL進行一次交叉,CrL為d×1的向量,eL為1×d的向量,矩陣計算后獲得d×d的矩陣CL。Compress將交叉后的矩陣CL重新壓縮回Embeddingspace(嵌入空間),并通過參數WL壓縮輸出CrL+1、eL+1[20]。

圖3 交叉壓縮單元Fig.3 Cross and Compress unit
MLKR算法主要的訓練過程如下:構建打分文件和知識圖譜,通過MLKR模型對數據進行學習,得出預測模型,能夠有效地預測學習者U對課程Cr感興趣的概率,由于在打分中的item和知識圖譜中的實體實質上指向相同的內容,其具有高度的重合性和相關性,采用多任務學習的框架將推薦算法和知識圖譜分別視作兩個分離任務,同時兩者可以通過item和entity進行相關,從而對兩個模塊進行交替學習。
在推薦算法部分中,輸入的是學習者和課程的特征表示,輸出為學習者對課程的感興趣的概率。
在知識圖譜的模塊中,輸入為三元組的頭結點和關系,輸出為預測的尾結點。利用項目和實體的相似性,設計交叉壓縮單元連接兩個模塊。
通過交叉壓縮單元,兩個模塊間可以共享信息,彌補自身的信息不足。在交替學習的過程中,分別固定推薦算法模塊的參數和知識圖譜的參數,同時訓練另一個模塊的參數,通過來回交替訓練的方式,使損失不斷減小。
MLKR算法具體實現步驟如圖4所示。利用模型進行學習的過程包括多次迭代,為了將推薦算法的性能盡可能達到最優,在每次迭代過程中,交替對課程推薦模塊和知識圖譜模塊進行訓練。對于每次的迭代中兩個模塊的訓練而言,均是通過以下的幾個步驟:首先從輸入的數據中提取小部分,然后對課程item和課程head提取特征值,利用梯度下降(Gradient Descent)算法更新最終預測函數的值,即模型收斂,獲得MLKR算法訓練模型。

圖4 MLKR算法訓練步驟Fig.4 MLKR algorithm training steps
3 實驗結果與分析
3.1 實驗環境與數據集處理
實驗環境為Inteli5-10210U CPU@1.60 GHz,8 GB內存,Window10操作系統。利用Pycharm中Anaconda3與TensorFlow框架。
實驗采用Kaggle上Online Courses from Harvard and MIT作為數據集。其中edX是MITx和HarvardX創建的大規模開放在線課堂平臺,類似于國內的網易公開課、騰訊課堂。該數據集的數據字段包含23個,數據信息290個,文件大小64 KB左右。實驗中,隨機選取60%作為訓練集,20%作為驗證集,20%作為測試集。根據推薦算法需求,抽取實驗所使用到數據集中的7個屬性:課程名、教師、學科、總交互時長、播放視頻時間占比、發帖占比、高于零分占比。抽取后數據集部分片段如表1所示。
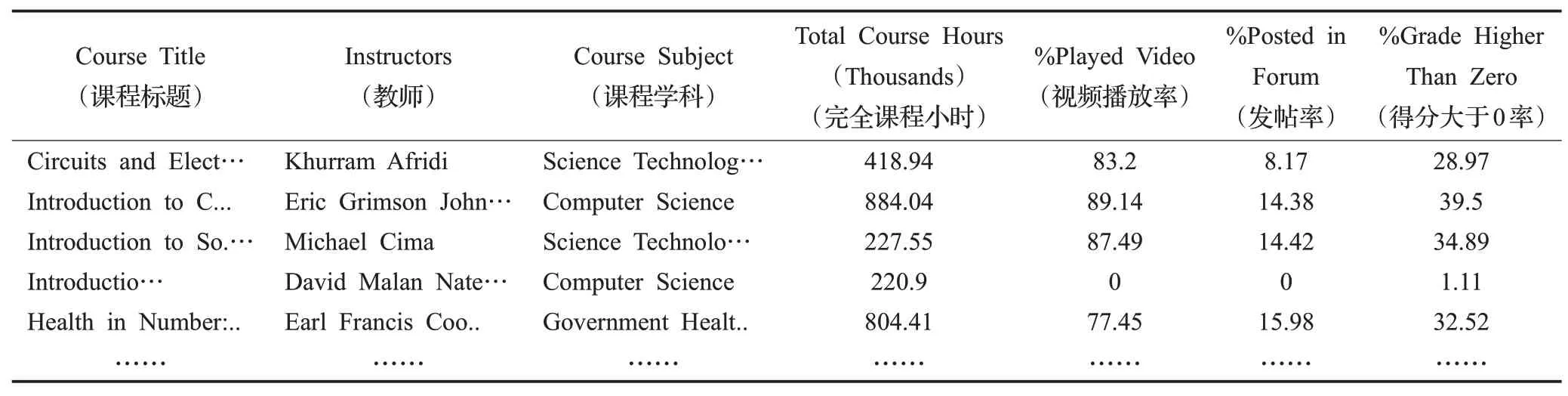
表1 課程推薦所需edX數據集片段Table 1 Recommended edX dataset fragments for course
最后利用neo4j構建知識圖譜,并做鏈路預測的任務,通過頭部實體、關系來預測尾實體,使用有監督訓練來得到更好的item向量表示。
3.2 評價指標
使用準確率(ACC)、精確率(Presicion)、召回率(Recall)、F1值(F1-Score)作為評價指標,用以衡量各個算法的性能,實現MKLR算法數值表征,具體計算見式(7)~(10)。在固定訓練集情況下,模型ACC、Presicion、Recall和F1計算越高,表明推薦模型更加高效[21]。

其中,TP(True Positive)表示真陽性,即課程的樣本被正確推薦給學習者的數量;TN(True Negative)表示真陰性,即不屬于正確推薦課程的樣本被正確推薦給學習者以外的其他課程的數量;FP(False Positive)表示假陽性,即不屬于正確推薦課程的樣本被錯誤推薦給學習者的數量;FN(False Negative)表示假陰性,即屬于正確推薦課程的樣本被錯誤推薦給學習者以外的其他課程的數量[22]。
3.3 實驗過程與結果分析
首先,系統運行數據處理模塊preprocess.py,將知識圖譜文件kg.txt和構造的學習者打分文件user_mooc.dat轉化成數值文件,構造打分文件的部分數據如表2所示,UserID為構造的學習者ID,ArtistID為課程ID。然后,根據對應權重得到和構造學習者模型打分權重Wg,計算如下:

表2 根據edX數據集構造的打分數據片段Table 2 Scoring data fragment constructed from edX dataset
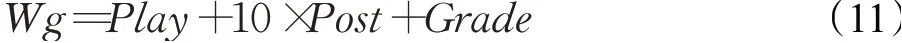
其中,Play為播放視頻時間占比取整,Post為發帖占比取整、Grade則為高于零分占比的取整。
得到構造打分文件后生成ratings_final.npy以及kg_final.txt,接著將上述文件作為模型的輸入,main.py文件作為模型訓練和超參數調整文件,對課程數據集超參數進行調整[23]。由于打分預測的實現存在困難,為了保證實驗結果的可信程度,同時也為了降低模型訓練耗時、增加模型參數調整精度,本實驗中超參數學習率Ir_rs選取0.001、Ir_kge選取0.002。由圖5可以看出,當超參數Batchsize為2 048、AUC、ACC、Presicion、Recall和F1評價指標表現較好。當Batchsize大于2 048時,Presicion、Recall和F1降低,是由于模型訓練出現過擬合。當大于4 096時,盡管由于評價指標Presicion、Recall和F1數值提高,但是會造成訓練時間過長。結合數據集中word出現次數和圖6可以看出,embedding維度選取32時,模型評價指標表現較好。最后設置Batchsize為2 048,embedding維度為32,圖7結果也驗證了Ir_rs選取0.001、Ir_kge選取0.002時,模型性能表現較好。
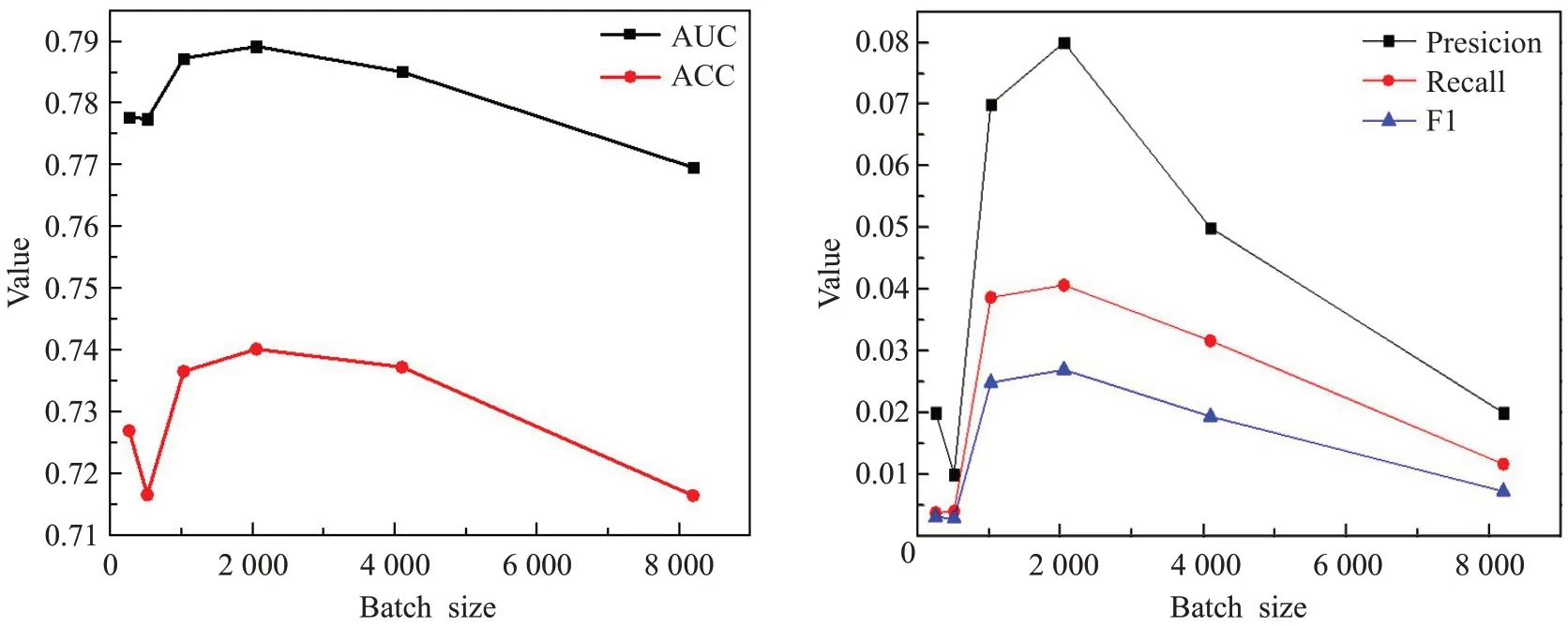
圖5 調整超參數BatchsizeFig.5 Adjust hyperparameter Batchsize

圖6 調整embedding維度Fig.6 Adjusting embedding dimension

圖7 當固定Batchsize=2 048,Dim=32時調整IrFig.7 When fixed batchsize=2 048,dim=32,adjust Ir
在固定模型超參數條件下對比不同算法之間的性能表現,表3為MLKR推薦算法與協同過濾算法以及排序學習算法代價對比,包括訓練和預測時間對比,結果表明,在訓練速度方面,ItemCF速度最快,訓練時間最短,由于MLKR算法采用深度學習的多任務處理,時間復雜度O(n)較高,與協同過濾算法相比訓練時間較長。但比排序學習推薦算法(LR)速度快。對比不同算法性能,實驗結果如表4所示,MLKR算法對于UserCF算法和LR排序學習模型相比有著更好的準確性。

表3 MLKR推薦算法與協同過濾算法代價比較Table 3 Cost comparison of MLKR algorithm and collaborative filtering algorithm
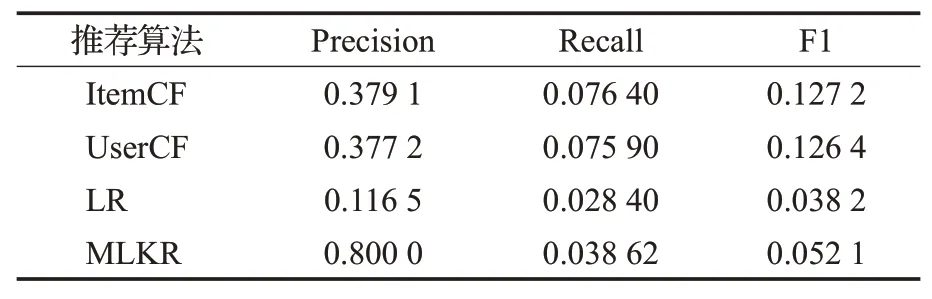
表4 MLKR推薦算法與協同過濾算法比較Table 4 Comparison of MLKR algorithm and collaborative filtering algorithm
由于構建的輔助信息是根據高校的學生培養方向所定制學習的課程學習路線,有些必修的課程無法滿足所有學習者的興趣,所以與ItemCF算法相比Recall值較低,并且相比與傳統協同過濾推薦算法,MLKR算法需要通過相應本體構建知識圖譜進行推薦,需要相應的構建過程代價,而協同過濾算法更適用于數據量多、偏向于多數用戶喜愛的推薦環境[23]。最終實驗結果表明MLKR算法更符合實際課程推薦的環境,且性能優于傳統推薦算法。
4 結束語
面向課程資源的融合知識圖譜與多任務特征推薦算法MLKR通過推薦模塊和知識圖譜嵌入模塊提取課程資源的相關特征,使用交叉壓縮單元學習實體之間的高階交互,并在兩個任務之間傳遞,解決了推薦算法中數據稀疏和冷啟動的問題。與傳統基于用戶的協同過濾算法和多層存儲推薦算法相比,提出的MLKR算法可以更加精準、高效地實現課程資源推薦。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
云南化工(2021年6期)2021-12-21 07:31:42
內蒙古教育(2021年20期)2021-03-08 01:09:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
計算機教育(2020年5期)2020-07-24 08:53:38
數學物理學報(2020年2期)2020-06-02 11:29:24
家庭影院技術(2019年11期)2019-12-09 09:14:30
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
教育與職業(2014年1期)2014-04-17 14:28:07
