冗余慣性導航系統信息一致性判斷方法
2021-11-16 14:44:14趙欣藝高曉穎李宇明
航天控制 2021年3期
趙欣藝 高曉穎 蹤 華 李 冰 李宇明
1.北京航天自動控制研究所,北京 100854 2.宇航智能控制技術國家級重點實驗室,北京 100854
0 引言
由于運載火箭、飛機、艦船等運動體的可靠性要求越來越高,任務越來越復雜,需要導航系統在運載火箭任務中,在提供可靠、高精度導航信息的同時具備成本低、重量輕、功耗低的優點。
冗余設計是提高導航系統可靠性的技術途徑之一。以運載火箭為例,目前國內運載火箭CZ-3A系列、CZ-2C采用雙七表冗余激光慣組,CZ-5、CZ-7運載火箭采用2套六表激光慣組和1套六表光纖慣組的方案。常采用主從模式和投票模式進行傳感器信息的判斷[1]。歐洲阿里安火箭采用了雙冗余設計,Space X的獵鷹火箭采用分布式冗余慣組設計[2]。一般冗余設計的判別準則是少數服從多數的閾值判別方法。即預先設置閾值,在一定時間區間對測量同一參數的多個傳感器輸出結果進行比較,當差值大于設定閾值時,根據少數服從多數的原則進行取舍,最終結果可以采用取平均值或者中間值的方式決定[3-4]。這種方法可以實時給出冗余系統的傳感器輸出結果,但由于閾值是事先通過經驗設置的,一般要求測量同一物理量的傳感器精度一致,才可以通過閾值判斷。而隨著運載火箭等對體積、重量、功耗等的要求越來越高,三個同樣高精度慣組的冗余模式,勢必會存在體積重量大,成本高的影響。因此傳統冗余方案一般只用在大型運載火箭中,小型商業運載火箭一般只采用一套高性能的慣組。
MEMS作為一種微型慣組器件,雖然精度不如光學慣組高,但在體積重量和成本上有很大優勢,可以考慮作為冗余慣組設計的一部分,然而由于與激光光纖慣組等高精度慣組的精度不同,兩種慣組進行冗余設計時,不能簡單地采用閾值設置通過少數服從多數的方式進行判斷。
在多傳感器一致性數據融合的研究中,LUO R C提出置信距離測度,作為衡量傳感器一致性的判斷依據[5]。之后,很多學者對該方法進行改進和優化[6-7]。但是沒有改變的是,基于置信距離測度的一致性判斷過程中依然需要設置閾值,且對傳感器性能的先驗知識要求嚴格,要求傳感器的測量結果符合正態分布,且方差已知。因此在應用中有諸多不便,針對慣組測量量短時間內變化快的特點,實際工程應用中并沒有采用這種判斷模式。
而在冗余慣性器件故障隔離的研究中,奇偶向量檢測法研究比較多,文獻[8]針對冗余三捷聯慣組提出最優奇偶向量法,該方法與設置閾值法相比有一定優勢,但最優奇偶向量法針對的是噪聲特性一致的慣性器件,對于本文所提出的精度差異較大的冗余慣組設計并不適用。
文獻[9]針對精度差異懸殊的平臺、捷聯式慣組的主從冗余模式,提出冗余故障診斷及決策方法。但兩慣組系統不進行信息互判,只是通過各種門限的設置判別常見故障,一方面,閾值選擇依靠經驗,另一方面,沒有充分利用測量信息。
相對于傳統方法,人工神經網絡在圖像處理,語音識別等方面均表現出了優勢。因此,針對以上問題,本文以冗余慣性導航系統為研究對象,利用神經網絡,實現冗余慣性導航系統信息的一致性判斷,提高導航系統的可靠性。該方法可應用于不同精度導航信息一致性的判斷,同時避免了依靠人工經驗選擇閾值帶來的不便。
1 神經網絡的構建
1.1 Siamese網絡
Siamese網絡即孿生神經網絡[10]。與普通神經網絡的區別在于,孿生網絡有兩個成對的輸入,兩個同樣的共享權值的網絡結構,且沒有目標輸出。其樣本標簽不作為目標輸出直接用于網絡權值調整。最初提出該算法是為了解決簽名的識別問題,現在多用于各種圖像匹配[11-12],目標追蹤[13]等圖像處理領域。文獻[14]也將其應用在礦物質光譜識別分類上。
本文采用的Siamese網絡結構如圖1所示。成對信息輸入后,經過神經網絡的處理,提取出低維度的特征向量,通過計算特征向量的“距離”,作為輸入信息對的相似性度量。即網絡訓練的目的是使得具有一致性的樣本對提取的特征向量的距離盡可能小,不一致性的則盡可能大。從而對樣本對的一致性實現判斷。
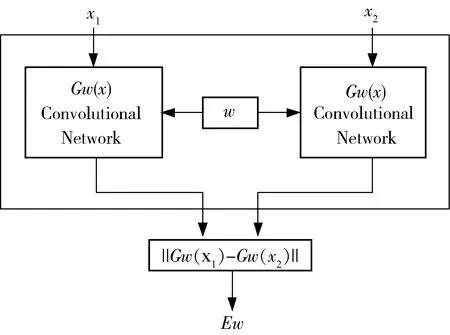
圖1 Siamese網絡結構圖
圖中,Gw(x)為網絡映射函數,x1和x2分別為由2個慣組系統某段時間內的輸出構成的數據信息,在Siamese網絡中作為輸入參數,Ew為特征向量之間的距離。Siamese網絡的訓練樣本是成對存在的,一致的樣本對標簽設為0,不一致的樣本對標簽設為1。
1.2 網絡結構選擇
Siamese網絡只是一種網絡框架,具體的神經網絡設計根據要解決的問題采用合適的結構設計。
為有效利用慣組一段時間內的數據趨勢,設計卷積神經網絡,該網絡由三層卷積層和三層全連接層組成,參數見表1。
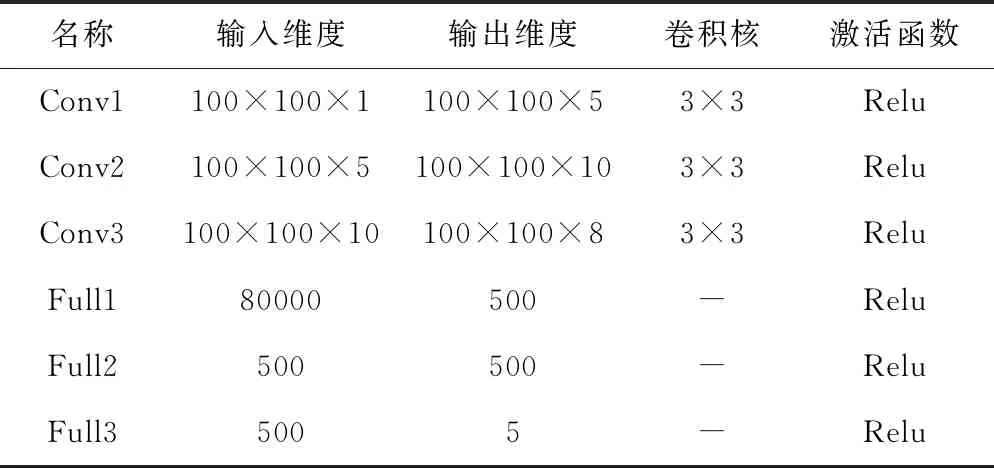
表1 神經網絡參數設計
1.3 損失函數設計
神經網絡的訓練中,需要定義損失函數,由于孿生神經網絡的訓練樣本中,標簽不作為目標輸出,因此,傳統用于分類的網絡常采用的交叉熵函數不再適用。損失函數的形式為:
L(w)=(1-Y)LG(Ew(x1,x2))+YLI(Ew(x1,x2))
(1)
其中,LG只計算一致輸入的損失函數,LI計算不一致輸入損失函數。在最小化損失函數的過程中,理論上,將LG設計為有效區域內的增函數,LI設計為有效區域內的減函數,可以使得訓練過程中逐漸擴大一致與不一致樣本對提取的特征向量的差距。
本文采用的損失函數如式(2)所示。式中,m為設置的邊界,當不一致樣本對的特征向量的距離大于m時,該樣本對不對損失函數產生影響。特征向量的距離計算采用歐氏距離計算,其公式如式(3)。
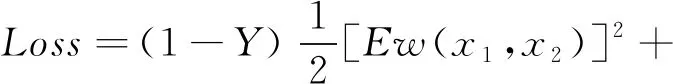
(2)
Ew(x1,x2)=‖Gw(x1)-Gw(x2)‖
(3)
2 訓練樣本的構建方法
本文以高低精度慣組冗余模式的導航系統作為信息一致性研究對象,驗證本文方法在不同精度的慣組冗余設計中的有效性。采用模擬飛行的慣組脈沖數據作為訓練樣本生成的基礎,通過建立慣組測量模型,模擬慣組輸出。
2.1 慣組測量模型
模擬軌跡的理論脈沖值對應載體系下的真實角增量、視速度增量的值。如式(4)。
(4)
陀螺測量模型為:
(5)
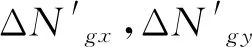
(6)
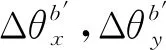
加速度計測量模型與陀螺類似,不再贅述。
在慣組測量模型中加入不同的誤差即設置不同的零次項系數模擬高低精度慣組數據。為更貼近真實情況,兩慣組所涉及的模型參數均考慮了與安裝等客觀因素的相關影響。
2.2 訓練樣本的構成
Siamese網絡多用于圖像處理方面的分類問題,采用Siamese網絡實現慣組數據的一致性識別問題。沿用圖像數據的格式,將待分類數據構造成n×n的矩陣形式,本文采用100×100的矩陣。將六表(3個陀螺,3個加速度計)的慣組作為一個慣組系統,在系統級層面對數據一致性進行判斷。
加速度計和陀螺的綜合測量結果,解算后會通過飛行器的速度、位置和姿態角反映出來,當其中一個慣組系統測量出錯時,兩慣組系統解算出的速度、位置和姿態角的變化趨勢會出現差別。樣本生成中,除考慮測量脈沖數據直接轉化的物理量之外,也考慮結合解算后的速度、位置和姿態數據。
訓練樣本由導航系速度、位置、姿態角,體坐標系角增量、角增量累積量、視速度增量、視速度增量的累積量共7類數據組成。每類數據包括3個方向上的數值,共21維。
利用一段時間內慣組測量數據的變化趨勢提取特征用于識別。因此采用一段時間內的導航數據進行樣本構造。慣組解算更新時間為0.02s,兩慣組采用同初值進行慣導解算。解算4000次(80s),等時間間隔取出100組數據,分別得到兩個100×21的矩陣,矩陣構造示意圖如圖2所示。由于網絡設計的輸入是100×100,因此將其余部分補零。即產生一組樣本對。步長設置為2000,再次統一初值并進行解算得到下一組樣本對,以此類推。
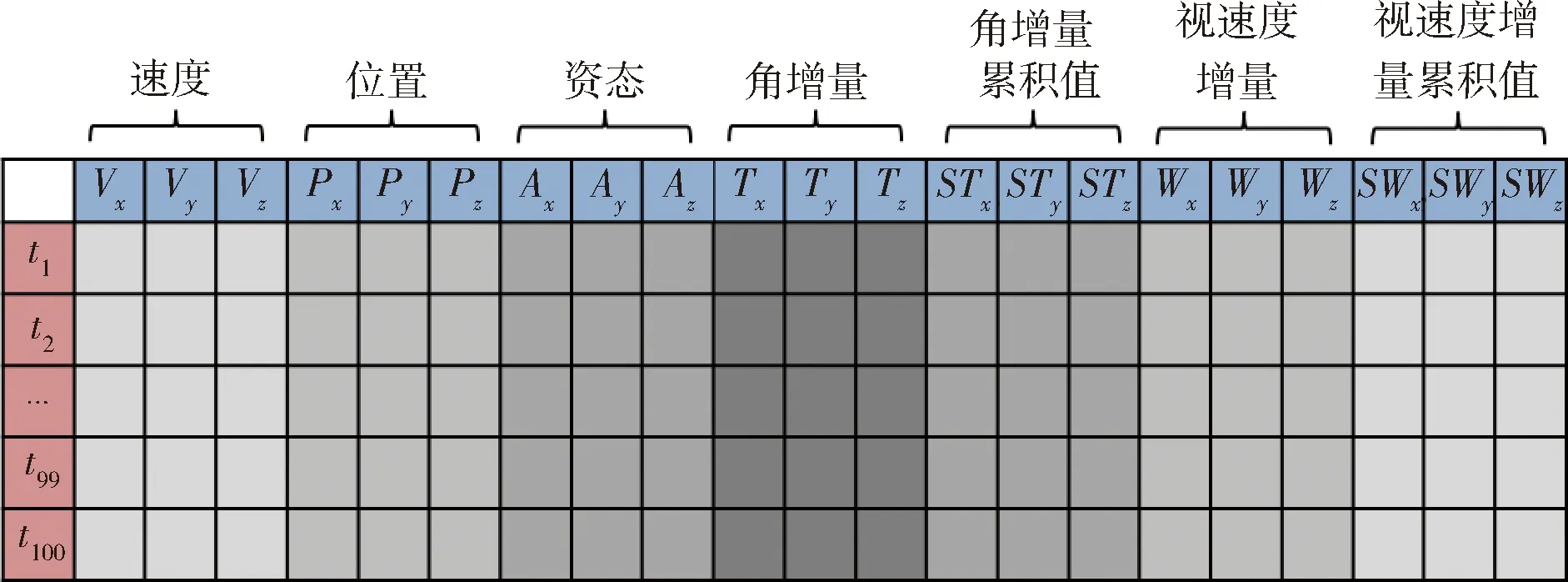
圖2 輸入數據矩陣示意圖
由測量模型加不同誤差生成的測量值得到的樣本對為一致性樣本對,標簽設置為0。
模擬不一致樣本對生成時,主要模擬慣性器件經常出現的故障模式,即極性相反、常零值和常峰值3種情況,標簽設置為1。
為測試網絡訓練結果的泛化能力,即能否適應未出現過的故障模式,能夠從相似度方向上解決一致性判別問題,訓練樣本和測試樣本分開生成,且加入不同的故障模式,例如,在不一致樣本生成的過程中,訓練樣本中加入正向峰值,測試樣本中加入負向峰值。
3 仿真試驗
導航系統一致性判斷網絡模型基于Pytorch平臺,使用Python語言實現。訓練樣本如2.2節所述構建。
3.1 仿真參數設定
慣組測量模型1誤差參數:
激光陀螺零偏誤差:0.05(°)/h;石英加速度計零偏誤差:0.0001m/s2。
慣組測量模型2誤差參數:
MEMS加速度計零偏誤差:0.01m/s2;MEMS陀螺零偏誤差:5(°)/h。
安裝誤差設置一致。隨機產生,為10-4rad量級。
慣組數據更新周期為0.02s;全時長為1542s。
訓練樣本數據:552對,其中,包含一致樣本對316對,不一致樣本對236對。
測試樣本數據:497對,其中,包含一致樣本對275對,不一致樣本對222對。
3.2 閾值選擇
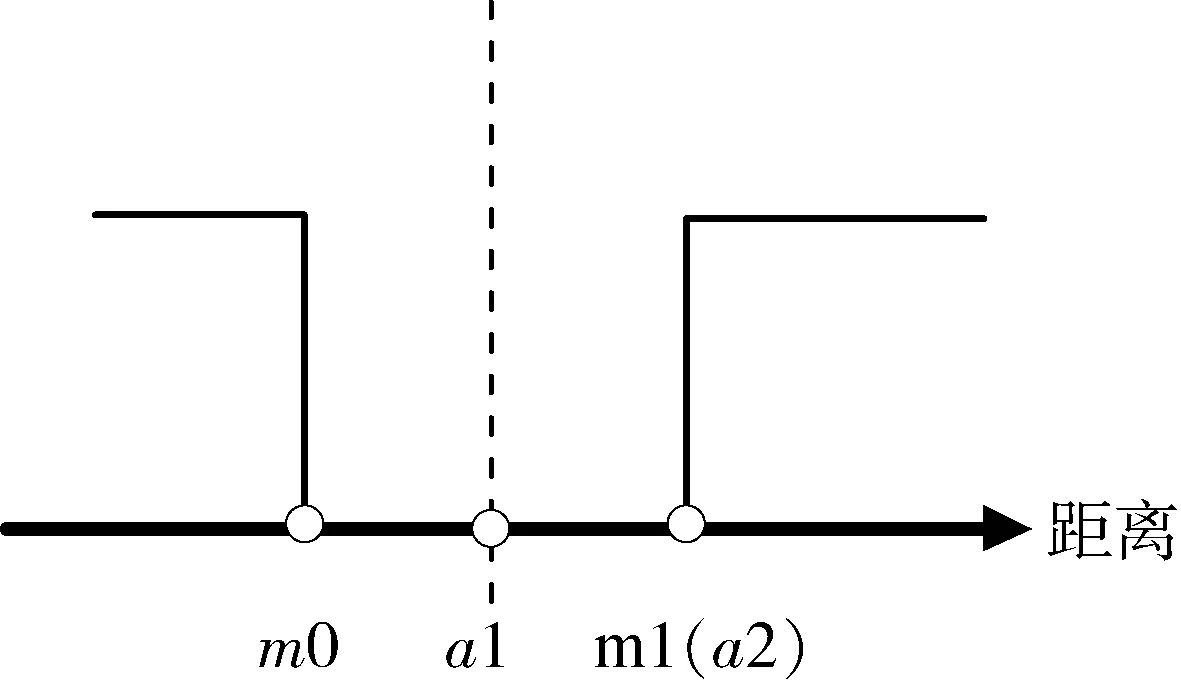
由于Siamese網絡最終實現增大一致樣本對之間和不一致樣本對之間提取出的特征向量的距離的差別。因此,最終判斷時需要設計閾值,該閾值由網絡訓練得出。
閾值選擇:(1)綜合準確度較高;(2)不一致樣本對漏檢率為0。
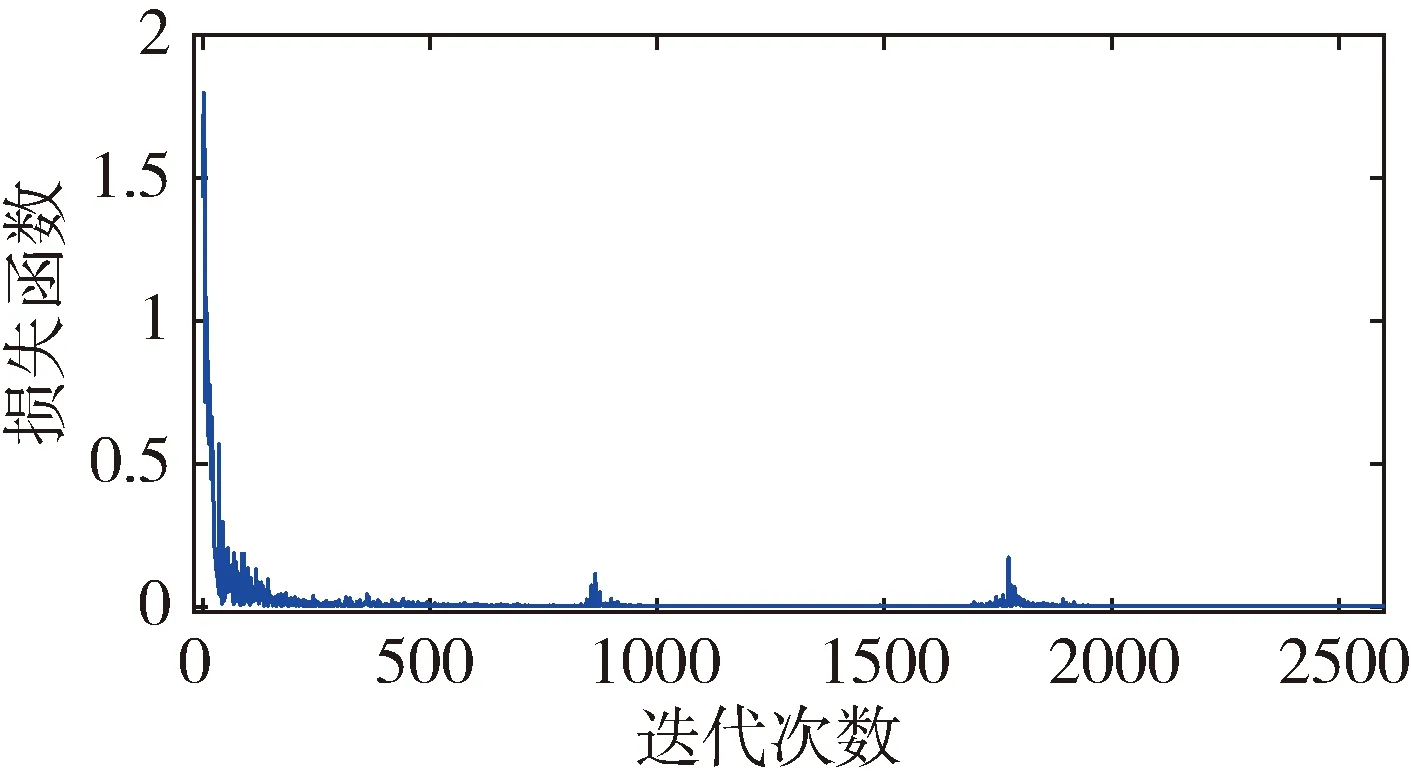
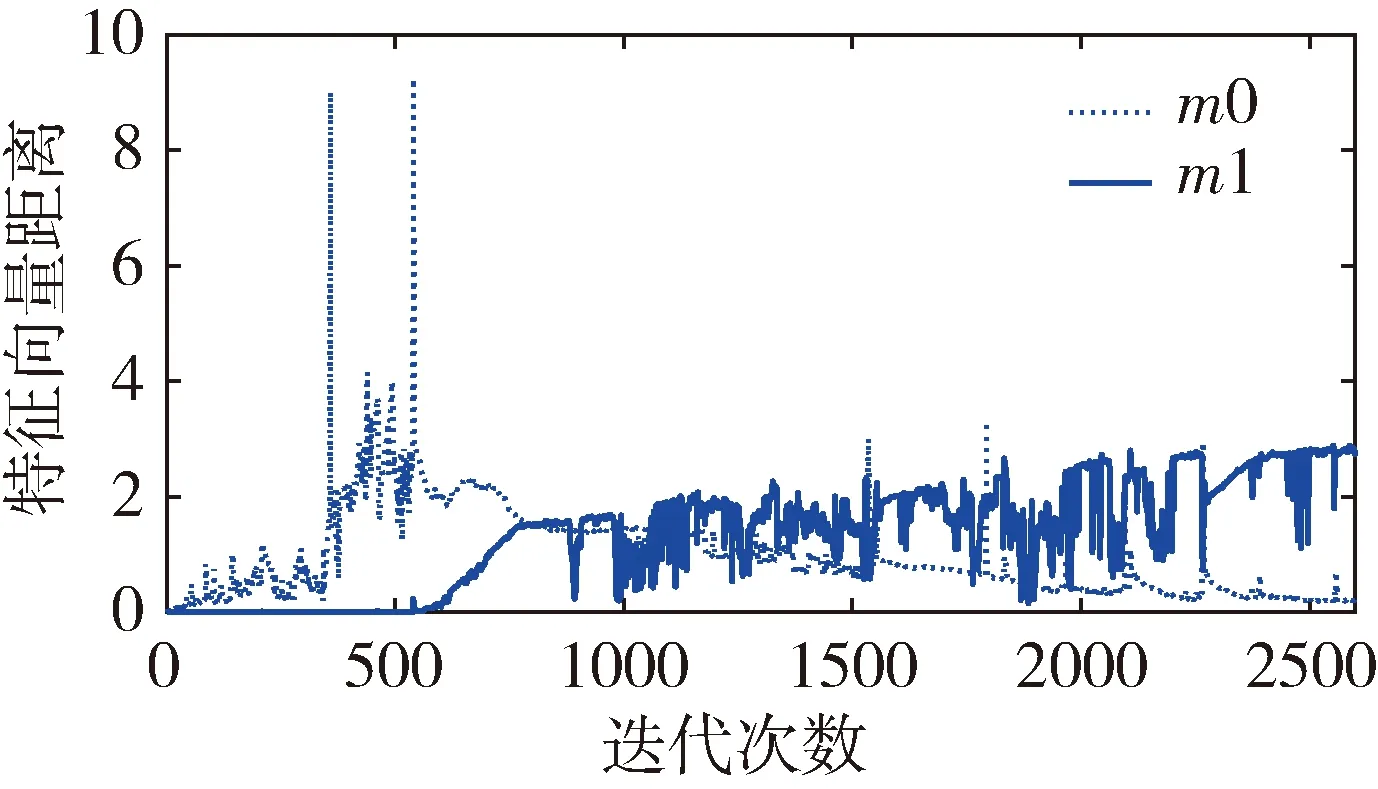
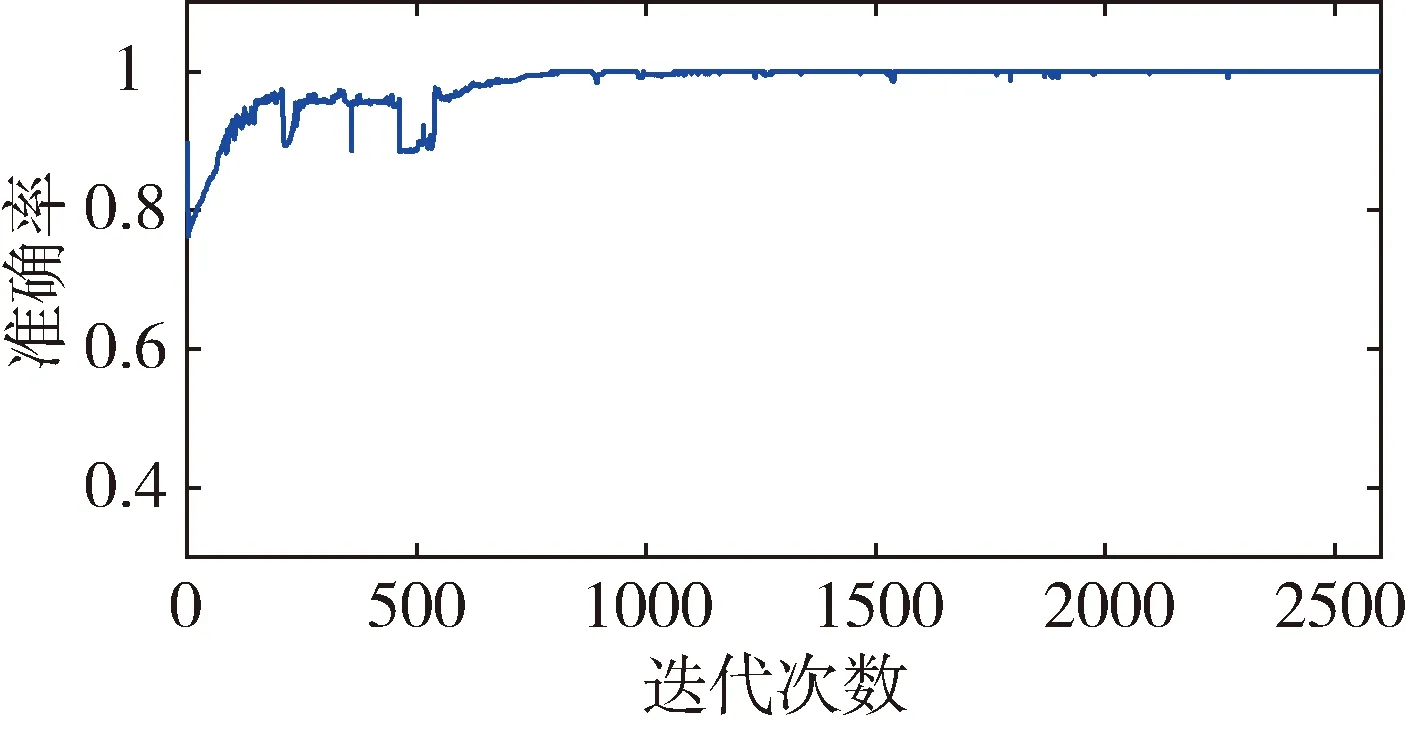
定義所有一致樣本對特征向量距離的最大值為m0,所有不一致樣本對特征距離的最小值為m1。訓練過程中有如圖3和圖4兩種情況。數軸上小于m0以及大于m1的兩區域分別表示樣本中所有一致樣本對和不一致樣本對經過神經網絡提取的特性向量的距離范圍。以m1作為閾值,可滿足不一致樣本對漏檢率為0。當訓練結果可以滿足m0 圖3 樣本對特征距離示意圖1 圖4 樣本對特征距離示意圖2 因此閾值分別選擇a1=0.5(m1+m0),a2=m1。 網絡優化方式采用Adam方式,學習速率設為0.0005。訓練結束條件:(1)訓練樣本迭代中連續300次滿足m0 訓練過程中,損失函數的值隨迭代次數的變化率如圖5所示,可以看出,損失函數的值穩步減小并在最后趨近于0。 圖5 損失函數隨迭代次數的變化情況 為更直觀地表現訓練效果,圖6是m1和m0隨網絡迭代次數的變化情況。 圖6 m1和m0隨迭代次數的變化情況 由圖6可以看出,訓練過程中,m1和m0的值隨迭代次數向m0 訓練樣本和測試樣本隨網絡迭代次數的準確度如圖7~10。 圖7 采用a1為閾值時訓練集樣本隨迭代次數的變化情況 圖8 采用a2為閾值時訓練集樣本隨迭代次數的變化情況 圖9 采用a1為閾值時測試集樣本隨迭代次數的變化情況 圖10 采用a2為閾值時測試集樣本隨迭代次數的變化情況 由圖7~8 可以看出,訓練后期網絡對訓練集的判斷準確率達到100%。 由圖9~10可以看出,基于訓練集訓練后的網絡可以很好地應用到測試集上。雖然準確度不如訓練集穩定,但經過1000次迭代以后的網絡,已經可以滿足在測試集上大于98.19%的準確率。 本文測試集與訓練集樣本是分開生成的,針對不一致樣本對,部分區別測試加入的故障模式與訓練集的故障模式。在加入峰值故障時,訓練集加入的是正向峰值,測試集加入的是負向峰值。對應測試樣本對約占總測試樣本對的1/3,但網絡在測試樣本上的實驗識別準確率依然可以達到98.19%,說明網絡具有一定的泛化能力。本文的訓練樣本只有552對,屬于小樣本。仿真證明,該方法具有一定的小樣本需求優勢。 本文采用Siamese網絡架構進行了基于學習的冗余慣性導航系統信息一致性分析研究,以冗余的不同精度的慣性導航系統為研究對象,驗證了該方法在冗余慣性導航系統信息一致性判斷中的有效性。代替了一般冗余慣性導航系統設計中,僅考慮當前值,以設置閾值的方式判斷信息一致性的方法。為慣性導航冗余設計不再局限于同精度慣組冗余的模式提供支持。用神經網絡模擬人腦判斷數據一致性的方式,神經網絡訓練結果穩定,準確度超過98.19%。為冗余慣性導航信息的一致性判斷提供了新思路。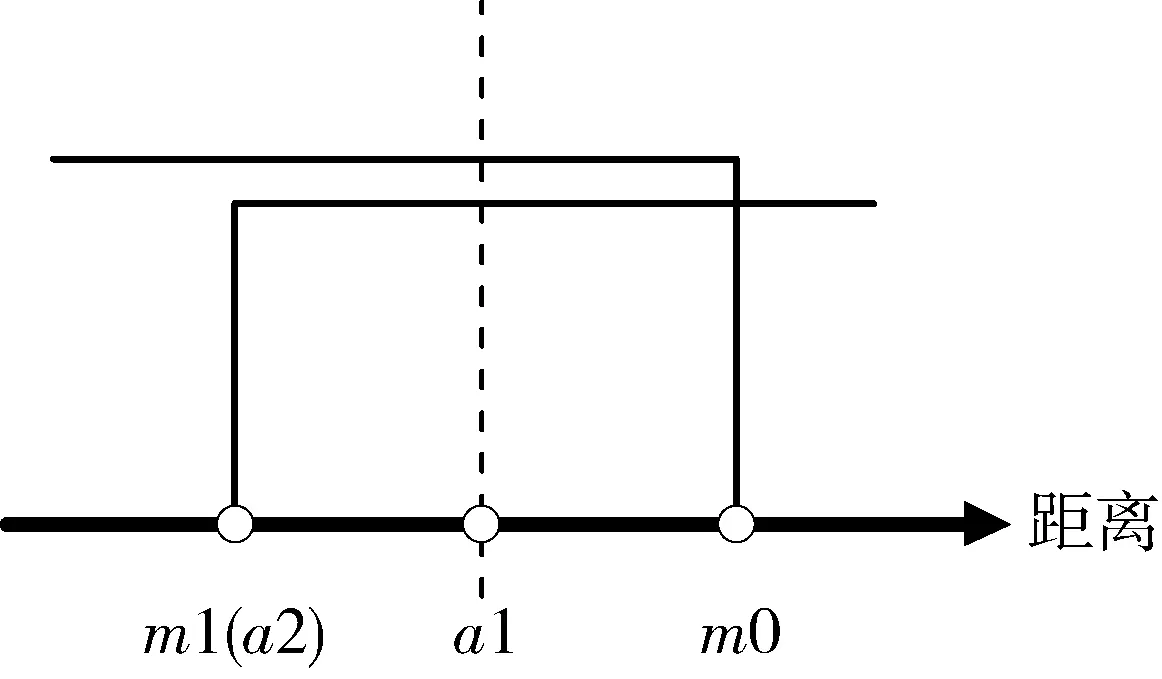
3.3 仿真結果
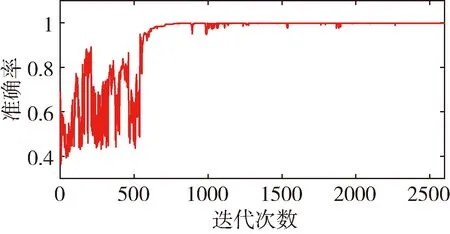
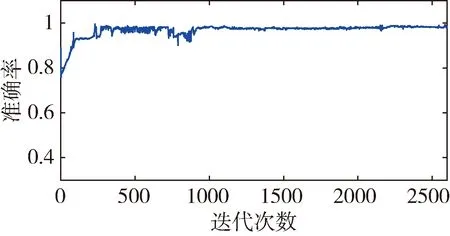
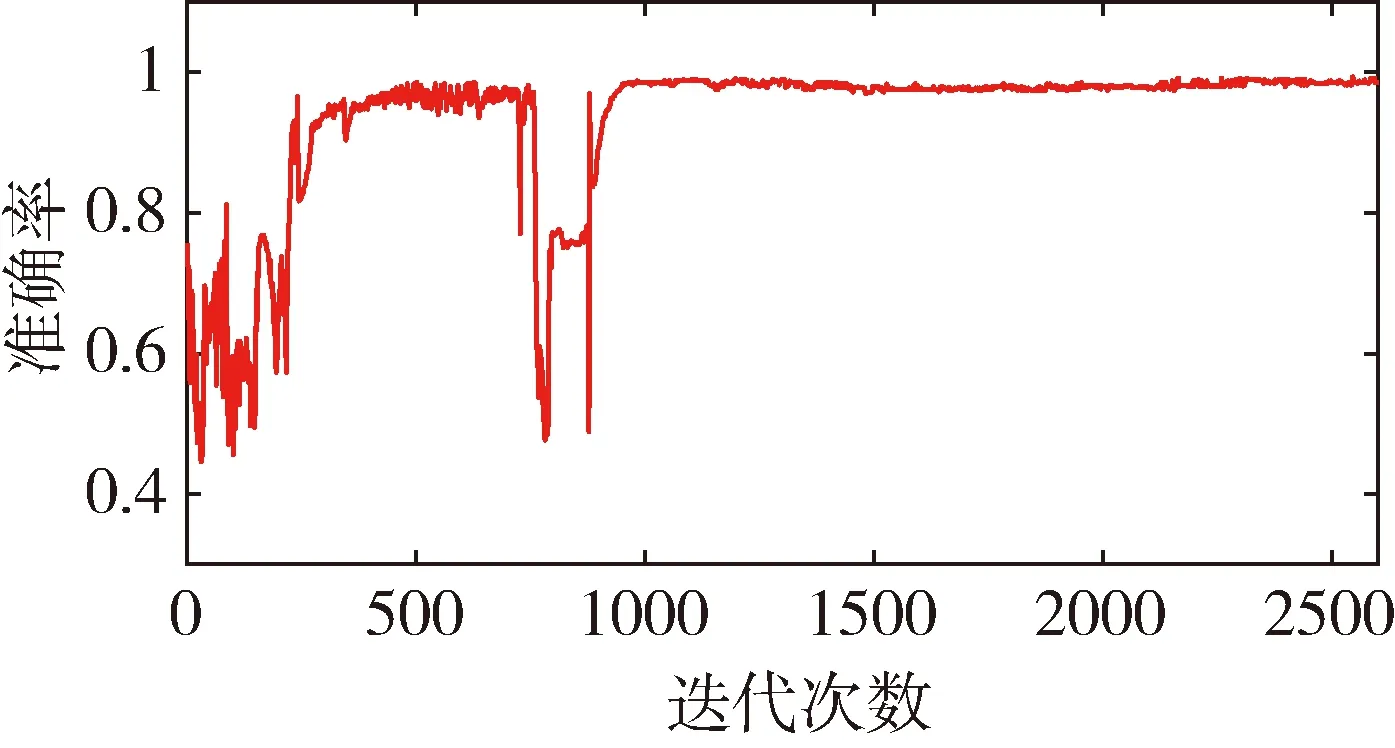
4 結論
猜你喜歡
公民與法治(2022年5期)2022-07-29 00:47:28教學考試(高考物理)(2021年5期)2021-11-08 10:31:22歷史教學問題(2021年4期)2021-11-05 07:02:34中醫眼耳鼻喉雜志(2021年1期)2021-07-22 07:38:14中學生數理化·八年級物理人教版(2019年9期)2019-11-25 07:33:02中學生數理化·八年級物理人教版(2019年3期)2019-04-25 06:20:54中學生數理化·八年級物理人教版(2018年3期)2018-05-31 08:52:45數學小靈通(1-2年級)(2017年10期)2017-11-08 08:39:45中國公共安全(2017年11期)2017-02-06 05:28:08少兒科學周刊·兒童版(2016年1期)2016-03-14 03:52:21
