基于改進OctConv的車道線檢測算法研究
2021-11-17 08:35:38陳樂庚肖晨晨
計算機仿真 2021年5期
蒙 雙,陳樂庚,肖晨晨
(桂林電子科技大學電子工程與自動化學院,廣西 桂林 541000)
1 引言
隨著經濟和科技的高速發展,汽車行業發展呈迅猛趨勢。據中華人民共和國國家統計局統計,2018年中國私人汽車擁有量達20730.00萬輛,車輛數量的遞增意味著交通事故的發生更加頻繁,其中約90%的交通事故中是人為錯誤釀成的。因此,為減少汽車駕駛中的人為錯誤而導致的交通事故,無人駕駛汽車應運而生。無人駕駛汽車最為關鍵的技術之一,是能夠對道路信息進行檢測識別[1]。而道路信息中,車道線是最為直觀的信息,為確保車輛始終行駛在車道線以內的安全區域,車道線的檢測就尤為重要。
傳統車道線檢測方法,多是對圖像預處理、canny算子邊緣提取后,基于卷積濾波方式,識別分割出車道線區域,同時結合霍夫變換、隨機抽樣一致等算法完成車道線檢測[2-5]。然而,基于傳統方法的車道線檢測魯棒性較差,不能夠適應場景多變且復雜的交通場景。
針對傳統車道線檢測算法魯棒性差的問題,文獻[6-14]提出基于深度學習的車道線檢測方法,收集不同環境條件下的圖片作為訓練樣本,利用深度學習框架搭建卷積神經網絡(Convolutional Neural Network, CNN),提取車道線特征信息,完成對車道線的語義分割,經檢驗,基于深度學習的車道線檢測具有更好的魯棒性,適應場景廣泛。然而,就當前語義分割現狀而言,具有較高的語義分割精度的網絡模型有FCN[15],SegNet[16],DeepLab[17]等,但由于模型復雜和計算量大,導致硬件要求高,實時性差,不適合應用于需要高實時性的車道線檢測。
針對以上車道線檢測方法存在的檢測速度慢、魯棒性差和模型復雜的問題,本文使用了一種新型卷積方式octave convolution(OctConv)結合FCN網絡來提升圖像分割性能,并通過空洞卷積與OctConv相結合的方式解決OctConv存在的圖像信息丟失問題,實現車道線檢測性能的進一步提升。
2 基于OctConv的語義分割算法
2.1 OctConv算法原理
在卷積神經網絡中,由于圖像中相鄰像素的特征相似性,卷積核掃描過每個像素點,獨立的存儲自己的特征描述,忽略了空間一致性,使得特征圖存在大量的冗余信息。為了減少空間冗余,Facebook AI、新加坡國立大學、奇虎360的研究人員聯合提出一種新型卷積OctConv[18]。
在自然圖像中,信息以不同的頻率進行傳輸。同理,圖像經過卷積層的輸出也可以看作是不同頻率的信息混合。在圖像檢測中,高頻信息為空間上變化迅速的部分,即檢測圖像的細節信息,低頻信息為空間上變化緩慢的部分,即檢測圖像的整體信息。顯然,低頻信息是冗余的。因此,可以通過壓縮在空間上變化緩慢的低頻信息,來處理冗余的低頻信息,從而降低內存和計算成本。之后,通過高、低頻率內的信息更新與頻率間的信息交流,使得檢測準確性提高。但由于對圖像的低頻分量進行壓縮處理操作,導致高、低頻信息維度不一致,從而不同頻率間的信息交換無法完成。
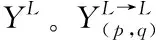
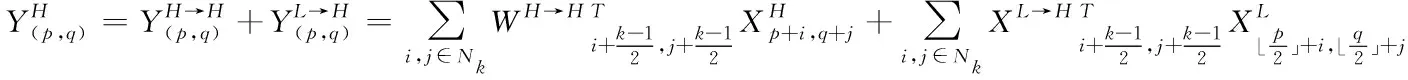
(1)

(2)
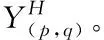
OctConv實現示意圖,如圖1所示。
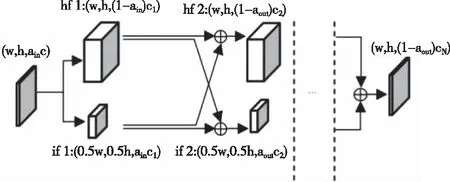
圖1 OctConv實現
OctConv中,壓縮低頻特征信息需要定義變量α,α表示所使用的低頻特征信息占總特征信息的比例。圖1表示,第1層OctConv中,尚未分離的輸入圖像根據α將其特征分離為高、低頻特征信息,并壓縮低頻特征尺寸。第2層至第(N-2)層OctConv中,對高、低頻分量進行信息更新,并將更新后的高、低頻分量分別通過下采樣卷積和上采樣卷積進行頻率間的信息交換。第N層OctConv,通過將高頻分量下采樣卷積和低頻特征信息卷積后,使得尺寸與輸出通道數一致后,兩者特征融合為最終特征圖。
OctConv中α的取值,如式(3)所示。式(3)中,αin、αout表示當前OctConv層的輸入輸出α,m表示當前OctConv層數,N表示OctConv的總層數。
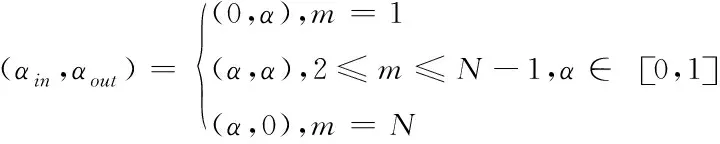
(3)
2.2 改進OctConv的語義分割網絡
OctConv的卷積方式存在著一個不可避免的問題,就是在壓縮低頻分量的過程中,由于直接使用池化層對圖像進行尺寸壓縮而導致的圖像細節信息丟失問題,從而影響語義分割的準確性。
空洞卷積能夠膨脹卷積核,使其能夠在不增加參數和不壓縮分辨率的條件下獲得更大的感受野。因此,對原始圖像使用空洞卷積,作為圖像細節信息的補充,并將其與所提取到的特征圖進行融合,便能在一定程度上解決圖像細節信息丟失的問題。
就車道線檢測而言,考慮到車道線特征明顯和實時性需求較高,不必使用參數數量和網絡層數過多的神經網絡。因此,本文車道線語義分割網絡主要是基于FCN的思想建立一個適用于車道線檢測的語義分割網絡,并將OctConv融合到網絡模型中。在此基礎上,引入空洞卷積,極大程度地彌補由于OctConv壓縮低頻分量所造成的圖像細節信息的損失,改進OctConv的語義分割網絡結構,如圖2所示。
圖2中,圖像輸入Input經過OctFirstConv層,分為高頻分量和低頻分量。高、低頻分量通過OctConv層,完成自身頻率內的信息更新與頻率間信息交換,以提取圖像主要特征。然后將由OctConv層得到的特征圖通過OctLastConv層,把高頻分量下采樣至與低頻分量尺寸一致后,兩者特征融合,再對其進行分類,得到初步特征圖。為了盡可能的補充網絡圖像細節信息,將OctConv1、OctConv2各自的高低頻信息特征融合后,將其同空洞卷積特征圖與初步特征圖特征融合。最后,將得到的最終特征圖通過Argmax層,得到概率最大的類,即為圖像打上對應標簽類別的灰度值,得到最終的預測圖結果,實現對車道線像素級別的分類,從而提取出車道線標志區域。
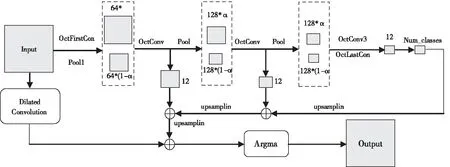
圖2 改進的OctConv語義分割網絡結構
3 實驗與分析
實驗平臺為Tensorflow,實驗的硬件配置為Intel(R)Core(TM)i5-8300H CPU, NVIDIA GeForce GTX1050Ti GPU;軟件環境為Windows10操作系統,Cuda9.0,Cudnn7.0,Tensorflow-gpu1.4,Python3.5。
3.1 圖像預處理
數據集使用KITTI路面數據集762張路面信息圖像,圖像預處理步驟如下:
1)對數據集灰度化處理后裁剪至[448,448,3]尺寸;
2)將裁剪后的數據集通過中值濾波器抑制噪聲的影響后,通過逆透視變換為鳥瞰圖,以消除車道線由于透視而導致的近大遠小的影響。
3)對鳥瞰圖使用標注軟件Labelme進行車道線圖像信息標注。
4)對標注好的762張數據集進行關于X軸方向的鏡像反轉,使得數據集圖像數量擴充至1524張。
5)將處理完畢后的車道線圖像分為訓練集與驗證集。
需要注意的一點是,為了驗證本文算法在不同環境下的檢測性能,驗證集圖像不能簡單的隨機選取或者只選取易于檢測的車道線圖像,而是應該把訓練集中出現的各個交通環境條件,各自提取一小部分作為車道線檢測的驗證集,通過在不同交通環境條件下檢測車道線,才能得到較為全面的檢測結果。
3.2 車道線檢測結果與分析
由于目前并沒有形成一個很完善的車道線檢測性能評判標準,因此,本文為驗證改進OctConv的車道線檢測算法的可行性,主要從3個方面進行測試分析:整體檢測精度、車道線檢測精度和檢測時間。
整體檢測精度,通過對預測圖像與標簽圖像對應位置像素進行類別對比,計算類別一致像素的數量占圖像總像素數量的比例得到,如式(4)所示。但由于整體檢測精度存在大面積的背景信息,并且車道線信息僅占圖像總體信息的小部分,故用整體檢測精度來判定車道線檢測的準確率不太理想。
車道線檢測精度,通過對標簽圖像的車道線像素與預測圖像對應位置的像素進行類別對比,計算類別一致像素的數量占標簽圖像的車道線像素總數量的比例得到,如式(5)所示。
檢測時間,即檢測單幅車道線圖像所花費的時間。

(4)
(5)
將路面圖像訓練集通過神經網絡層數與深度一致的不同神經網絡結構訓練5000次,完成對車道線圖像的檢測驗證,得到不同神經網絡結構下的車道線檢測性能,如表1所示。
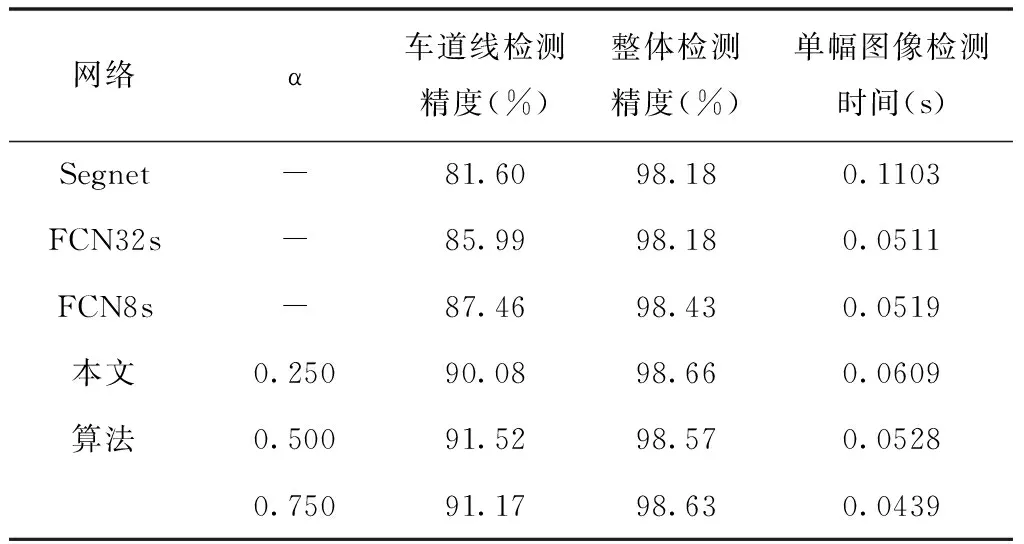
表1 車道線檢測性能對比
由表1分析得:
1)就不同算法而言,本文算法相較于其它算法,車道線檢測性能更好。
2)就不同α值而言,容易看出,當取α=0.500時,車道線檢測精度最好。
3)本文算法中,車道線檢測時間與α的值呈反比。這是由于隨著α值增大,所使用的低頻特征信息占總低頻特征信息的比例也越大,因此,OctConv能夠壓縮更多的圖像低頻分量,使得所處理的圖像信息減少,從而使得車道線檢測時間縮減。另一方面,圖像信息的減少也意味著檢測精度的下降。
4)就檢測時間而言,本文算法相較于其它算法的檢測時間,減少的程度不是很明顯。造成這樣結果的原因有兩點:其一,是由于本文算法所使用的神經網絡結構層數不多與節點數量較少,在使用OctConv的卷積方式進行特征提取時,能夠減少的檢測時間有限;其二,是空洞卷積是原始圖像上的卷積,所占用的檢測時間相對于整體檢測時間較多。故兩者檢測時間的正負抵消下,導致車道線檢測時間縮減不是很明顯。
綜上可知,本文算法雖然增大圖像信息能夠在一定程度上提升檢測精度,但需要考慮計算準確度和計算耗時,選取適當的α值以匹配神經網絡模型,使得圖像高、低頻信息達到一個較好的比例,通過在大感受野下處理冗余的背景信息和頻率間的信息交換,從而提升圖像檢測性能。
3.3 車道線檢測效果
考慮到不同交通環境下的車道線檢測,檢測結果可能會出現偏差,因此,驗證集圖像的選取需要具備多個限制條件。在有限的路面情況數據集下,可將限制條件簡單分為:遮擋、彎道、陰影和變道四種。不同交通環境條件下的車道線檢測的效果圖,如圖3所示。

圖3 車道線檢測效果圖
4 結束語
本文針對當前主流車道線檢測算法實時性較差和復雜度高的問題,提出一種改進OctConv的車道線語義分割改進方法,通過新型卷積方式OctConv將圖像分為高頻分量和低頻分量后,通過壓縮低頻分量,節省內存和計算成本,提升車道線檢測性能,并使用空洞卷積來彌補由于壓縮低頻分量而造成的圖像細節信息的丟失。在KITTI數據集下的實驗結果表明,雖然改進OctConv的車道線語義分割算法具有更高的語義分割精度和更好的實時性,但不足的方面有兩點:
1)沒有使用更為豐富的車道線圖像數據集,不能夠完全適應復雜的交通場景,如非結構化道路、交通標識繁多的路面、雨天車道線、道路破損車道線和霧天車道線等;
2)使用的神經網絡結構層數和節點數較少,以至于實驗結果沒能較大程度地體現出本文算法相較于其它算法耗時較少的優點。
就目前的檢測結果而言,所提出的方法能夠實現像素級別的車道線語義分割并具有良好可擴展性,適用廣泛,實時性好,魯棒性強。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
海峽科技與產業(2016年3期)2016-05-17 04:32:12
大連民族大學學報(2015年2期)2015-02-27 08:28:11
