三維視頻跳幀缺幀動態補償方法仿真
2021-11-17 03:56:30孟凡墨
計算機仿真 2021年3期
孟凡墨
(吉林師范大學,吉林 四平 136000)
1 引言
三維視頻缺幀、跳幀是指在視頻播放過程中存在黑屏或閃屏、卡頓不流暢等現象,極為影響視覺感官,通常會動態補償方法來彌補缺失。跳幀、缺幀補償作為三維視頻處理的重要領域,其在視頻的虛擬圖像合成、視頻幀率提升和慢速制造等方面都擁有廣泛使用。傳統補償方法通過光流場檢測完成視頻輸入聚類匹配,然后使用計算出的匹配數據合成中間幀圖像。但因為光流場存在不穩定現象,導致三維視頻缺幀補償后效果不佳,而其它方法在現實應用中經常面臨困難,基于此相關研究者提出如下解決方案。
文獻[1]通過混入統計特性的高斯噪聲,從而提高三維視頻缺幀、跳幀補償精準度,但因為高斯噪聲混入需要大量的時間進行實現,導致該方法在補償效率上并不理想。文獻[2]提出了一種基于結構相似的幀間組稀疏表示重構算法研究,該方法首先將三維視頻的結構相似度作為匹配的標準,再對其參考幀進行搜索匹配,從而生成相似塊組,然后通過相似塊組中關鍵特征實現幀間補償。但該方法步驟過于繁瑣,需要消耗大量的人力、物力資源和時間。文獻[3]提出了一種基于特征匹配與運動補償的視頻穩像算法,通過長度不變的SURE對視頻進行特征提取,并計算描述符,再引入鄰近匹配算法獲得匹配點,從而提高對視頻幀間的補償效率。但SURE算法在特征提取的過程中,容易將重要特征當做冗余干擾并實行剔除,導致最后的補償不夠完整,三維視頻效果差強人意。
針對上述問題本文提出了一種基于幀間投影的補償方法,通過對三維視頻進行投影,有效提高補償過程的完整性。根據投影結果獲得單獨兩種的波形,并利用深度卷積神經網絡對兩個獨立波形進行訓練,有效縮短視頻補償時間,從而實現三維視頻中的跳幀、缺幀進行補償。實驗結果證明,相較于傳統方法,本文提出的方法在補償三維視頻幀間的效率上較為突出,并且不會出現補償遺漏以及補償不完整問題。
2 三維視頻跳幀缺幀動態補償方法
2.1 三維視頻幀間投影
三維視頻跳幀、缺幀的實質就是視頻幀間的丟失或跳過[4]。預算三維視頻幀間的平移運動算法有很多種,比如代表點比較法、匹配算法、邊沿識別算法等。本文提出的幀間投影算法,會依據所獲得的三維視頻總體分布規律來求出當前幀相對于參考幀在水平方向與垂直方向的運動矢量,它擁有計算速度快、效率高等優點。
對于三維視頻輸入預處理的所有幀來說,通過預處理后,將其幀間運動投影成兩個單獨的波形,其投影方法表示為

(1)

(2)
式中,Gk(i)和Gk(j)分別代表為k幀視頻第j列和第i行,Gk(i,j)表示第k幀視頻上的(i,j)的位置。經過分別匹配行、列的投影矢量,就能求得在水平方向和垂直方向的運動矢量。因為投影匹配算法可以把三維視頻轉化為兩個一維的矢量,因此很大程度上提高了計算效率。
分別將參考視頻和當前視頻分成若干的子區域,當子區域劃分較少時,會省略旋轉運動,使用投影匹配算法可以精準的求出子區域在垂直方向和水平方向的局部運動矢量。
如何確準子區域的大小是一個非常重要的問題。如果區域劃分的越多,理論上最終實現的視頻旋轉補償精準度就越高,如果區域選擇過大,那么區域的旋轉運動則不能忽略,同時會缺失一些局部運動信息[5-6]。考慮到現實的應用,對一些分辨率為650*490像素的三維視頻來說,能夠選擇子區域的大小為6*65像素,即將一幀三維視頻分成25個子區域,對于分辨率為353*289像素的三維視頻來說,能偶分成17個子區域,子區域的大小則選為51*65像素。
因為三維視頻上存在的背景和景物不同,區分以后,有的區域會產生不明顯變化,不具有足夠的信息量,尤其是航攝三維視頻[7]。比如,某一個區域只存在幀間單一的景物,出現該區域,能夠使用各子區域運動矢量的均衡值作為該區域的運動矢量[8]。
2.2 視頻的仿射變換
三維視頻幾何變換就是視頻中點和點之間的空間投影關系,這屬于初始圖像和其變形之后圖像中所有各點間的投影關系函數,可表示為
[x,y]=[X(u,v),Y(u,v)]
(3)
或
[u,v]=[U(x,y),V(x,y)]
(4)
式中,[u,v]代表輸入三維視頻中像素的坐標,[x,y]代表輸出視頻中像素的坐標。X、Y、U、V代表唯一確準的空間變換函數,就是它們定義了輸出視頻和輸入視頻中的全部點間幾何對應關系,X、Y把輸入投影到輸出,叫做向前投影,U、V把輸出視頻投影到輸入,叫做逆向投影。
仿射變換是一種常見是平面投影方法,但其轉化方式比較特殊,表達公式為

(5)
逆變轉化能夠限制三維視頻的旋轉、平移與基礎的變形,減少后續補償的干擾向量。
2.3 深度卷積神經網絡設計
相對于傳統的深度神經網絡,構建用于三維視頻跳幀、缺幀動態補償的深度卷積神經網絡需要對下述三個問題進行考慮:
1)和僅為目標分類概率的目網絡不同,本文的任務是為了將輸入視頻分辨率和輸出視頻分辨率進行相同的匹配,從而融合出完整一幀[9-10]。
2)考慮到三維視頻中使用場景的視頻長度比,經常會各不相同的情況,用于三維視頻中跳幀、缺幀補償的卷積神經網絡,需要擁有處理不同長度視頻的能力,提升方法適用性。
3)設計出的卷積神經網路需要擁有視頻細節處理能力,并且還要考慮在視頻中幀數較多的情況下,如何使用優化卷積神經網絡降低幀分散現象,使得卷積神經網絡能夠對幀間進行優質的訓練,提升跳幀、缺幀補償效果[11-12]。
本文提出的三維視頻跳幀、缺幀動態補償深度卷積神經網絡總體構造如圖1所示。

圖1 深度卷積神經網絡結構示意圖
對于給定的一幅圖像,第1次卷積選取5個卷積核,經過遍歷輸入圖像,經過采樣處理,得到下采樣特征圖,下采樣層一般采用均值處理,每6個像素進行平均;第2個卷積層再次使用卷積核,再經過2次卷積處理后,和最終的輸出層實現全連接。
利用初始卷積神經網絡構建反卷積模塊,通過激活卷積層和函數層進行三次重復交替,訓練模塊最后在融入池化層內組合。本文深度卷積層的設定跨步尺寸和內部邊距為1,3,1。啟用函數層使用參數修正現單元作為激活函數,池化層的預感跨步為1,尺寸為3。
2.4 訓練及跳幀缺幀補償
如上文所述,本文可以使用現有的三維視頻對上節建造的深度卷積神經網絡進行訓練,并且去掉了人工標注環節,在節省了大量時間的同時,減少人力物力資源的浪費。因為三維視頻中含有時序一致性,就是在短時間內可以對拍攝物體與攝像機進行快速運動,所以建造的深度卷積神經網絡較為適合對本文三維視頻進行訓練。
本文使用Durian來建造訓練樣本,其中原始數據是KITTI。KITTI是三維視頻中安放在汽車上的攝影機,它是公開的數據集,可以對自動駕駛、像視覺里程計算、Stereo、光流場計算和圖像分割等進行應用。相較于KITTI和Sintel數據,本文只使用起始的三維視頻數據對訓練樣本進行提取。
KITTI數據集包含58個視頻序列,總計15942幀圖像。在全部序列中,使用三幀連續的圖像建造為一個訓練樣本,第一幀和第三幀當做輸入視頻,第二幀則表示為運動插值視頻的真值。并且對事項中包含上下翻轉、左右翻轉跡象的方式通過訓練來構建新的樣本,同時該樣本一共生成了123517個訓練樣本。對三維視頻,還是使用65個視頻序列進行采集,序列中含有5891幀圖像。使用和KITTI數據類似的方法建造36541個訓練樣本。對KITTI數據的輸入圖像采樣為280*248,對Sintel數據,使用的視頻尺寸為275*137。
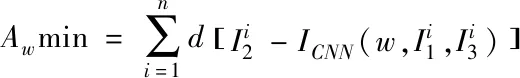
(6)

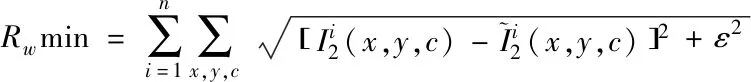
(7)
式中ε為0.2。
3 仿真研究
3.1 實驗環境
仿真環境為:操作系統為Windows7Ultimate,處理器為Intel T6400,內存為2GB,仿真軟件為Matlab7.8a。
3.2 不同方法三維視頻補償效率
為了更好的檢驗本文方法的性能,采用文獻[1]的方法和本文方法進行比較,因為MPEG-1輸出三維視頻碼率是固定的1.3MBIT/s,所以標準的MPEG-1三維視頻編碼器擁有碼率控制能力。在進行視頻補償仿真過程中,取消了碼率控制,并定義量化參數,對IP于B幀都固定為Q=30,其中,運動估值使用的是全搜索算法,下表給出實驗比較結果。

表1 不同方法的對比結果
從表1能夠看出本文方法較比文獻[1]在三維視頻補償效率上要高出很多,分析其原因,本文方法使用了幀間投影算法,通過簡單的投影就可以節省大量時間,較比文獻[1]通過特征提取來分類三維視頻要快。
3.3 三維視頻跳幀缺幀動態補償完整性
首先為了檢驗方法補償完整性,將本文方法于文獻[2]、文獻[3]的方法進行對比,使用常見的Comer Planes與Punctured Sphere模型,如圖2所示。

圖2 實驗中使用的兩種模型
求三維視頻模型的缺幀、跳幀補償誤差結果,對比結果如圖3所示。其中曲線InvErr是文獻[2]的補償結果。
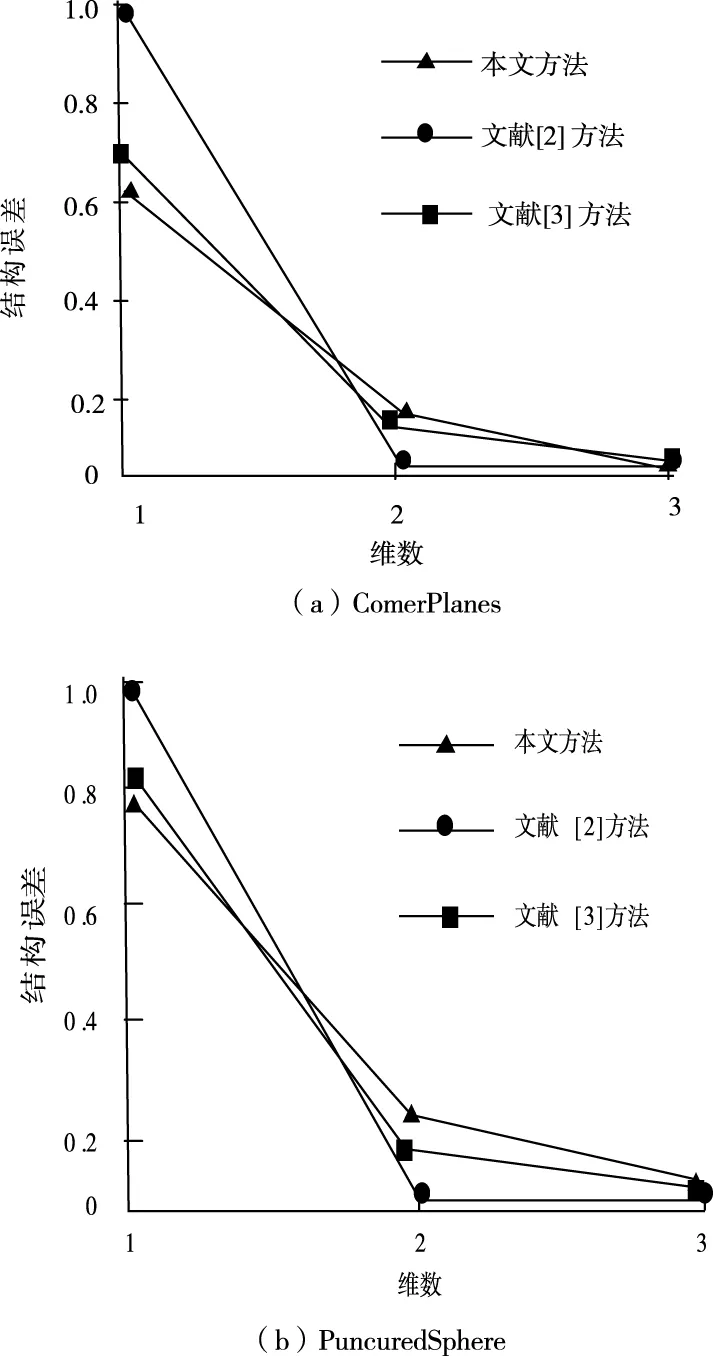
圖3 不同方法相同模型的誤差圖
從圖3能夠看出,其中本文的結果對于幀間誤差不大,這代表鄰近圖能夠用來更好的模擬高維數據低維流形結構。文獻[2]、文獻[3]中因為鄰近圖使用的順序為搜索策略,留下的是完全滿足條件的數據點,但滿足部分條件的有效點被刪除,所以比較降維前后鄰近圖中相似性時會出現一定的偏差,使補償誤差大幅度增加,三維視頻補償后視覺效果差。
然后構建最優質的映射矩陣,考慮到三維視頻和數據在時間上存有聯系,同時也是為了盡量保持三維視頻的流行結構,使用鏡頭樣本來獲取映射矩陣。首先來獲得三維視頻鏡頭的最優質維度數,建造鄰近結構矩陣。通過在實驗中對不同方法進行降維處理,獲得了降維前后的流行結構誤差圖,如圖4所示。

圖4 兩種方法的完整性對比
通過圖4能夠看出,本文方法比較文獻[2]方法的補償完整度更高,主要原因是,深度卷積神經網絡在分類兩種波形時擁有具體的分類形式,不會出現檢測遺漏波形,所以本文補償三維視頻的跳幀、缺幀時不會出現傳統方法的遺漏現象,從而更加完整的補償三維視頻的幀間運動。
從上述可以看出本文提出的方法在三維視頻跳幀、缺幀方面擁有非常好的性能,并且效率更高。
4 結論
為了解決三維視頻缺幀、跳幀補償的效率過慢,補償不完整問題,提出了一種通過幀間投影和深度卷積神經網絡的補償方法。通過仿真結果證明,所提方法具有良好應用性能,可以在該領域得以廣泛應用。但三維視頻幀間補償是一種非常復雜的程序,需要涉及到很多種學科問題,由于作者的水平限制,研究時間較短,雖然在三維視頻的跳幀、缺幀補償方面小有成就,但以下問題仍然沒有做到滿意:
1)動態補償方法還沒有成熟。動態補償可以從理論上解釋三維視頻幀間治理、視頻資源提取思想,但針對三維視頻動態補償模式研究還不夠成熟,會限制實際使用。
2)如何改進算法使其進一步提高三維視頻跳幀缺幀補償性能也是未來需要研究的方向。
3)本文中的補償研究大部分都是圍繞著跳幀、缺幀進行的,但三維視頻中出現的問題不止是跳幀和缺幀,還有很多的問題等待的廣大學者的研究。
猜你喜歡
今日農業(2021年9期)2021-11-26 07:41:24
發明與創新·小學生(2021年3期)2021-03-25 11:48:49
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
電測與儀表(2015年5期)2015-04-09 11:30:52
