
Tesseract-OCR的文檔掃描識別系統
2021-11-17 07:01:20深圳技師學院楊思怡付相祥吳曉華
電子世界 2021年20期
關鍵詞:檢測
深圳技師學院 楊思怡 付相祥 吳曉華 夏 清
在高速信息化的時代,針對海量文檔數據處理效率低下的問題,提出了一種基于OCR技術的識別系統,首先利用OpenCV對文檔數據進行預處理濾波,邊緣計算,灰度化等一系列預處理,然后使用Canny算子找到圖片邊緣信息后應用一個透視的轉換去獲取一個文檔的自頂向下的正圖,最后完成了一個基于Tesseract-OCR的文檔掃描識別項目,該實驗表明此方法具有準確的識別率,提供多種語言開發調用,以及具備高可用性;可以有效提升數據錄入的效率,大大減輕人工的消耗。
隨著信息技術的快速發展,數字化時代已然來臨。人們不再滿足傳統的紙質辦公而是將需求投放在了電子文稿上,在現如今的商業事務中,資金的往來以及員工的報銷將會產生大量的紙質票據,而將紙質的票據進行保存及錄入成為了一大難題。在傳統的票據錄入中往往需要耗費大量人工進行手動錄入,但其卻存在效率低下,差錯率高,成本昂貴等弊端。為了有效提高票據錄入的效率,本項目將提出Tesseract-OCR引擎所給出的一套自適應識別方法。利用OpenCV函數庫對圖像進行濾波,灰度化,閾值化處理后得到二值圖像。再通過透視變換對圖像進行擺正,應用一個透視的轉換去獲取一個票據的自頂而下的正圖,最后再通過OCR技術對票據進行識別。具體過程如圖1所示。
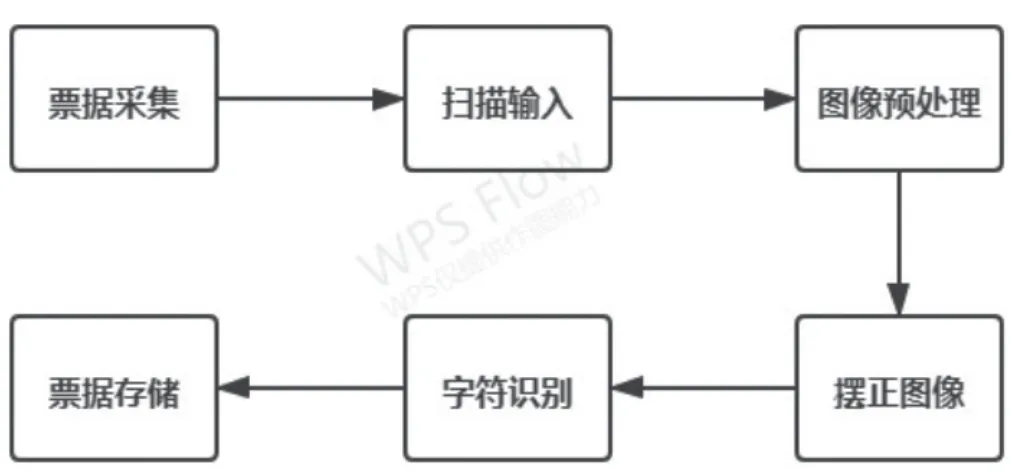
圖1 文檔掃描識別具體過程圖
1 OpenCV和Tesseract-OCR識別
1.1 OpenCV
OpenCV是一個跨平臺計算機視覺和機器學習的軟件庫,它可以運行在各大操作系統上,并且能提供多種語言的接口。例如Python語言就是其中之一,它的應用領域非常的廣泛,比如物體識別、人機互動、圖像分割、等各種領域,因此被大量使用。
1.2 Tesseract-OCR識別
Tesseract的OCR引擎是由惠普實驗室于1985年到1955年進行研發的,自2006年開始谷歌改進了其算法,通過消除bug,優化其相關工作。它可以獲取圖像并將它們轉譯成多種語言(包括中文)的文本,并支持用戶能不斷的訓練字庫,使用圖像轉換文本的能力不斷增強。Tesseract在本項目中的作用是進行字符識別。
2 透視變換-擺正圖像
透視變換也可以稱作投影映射,它是將成像投影到另一個視頻里,它是二維(x, y)到三維(X, Y, Z),再到另一個二維(x', y' )空間的映射。校正對畸變圖像,它需要獲取圖像的一組4個點的坐標,和目標圖像的一組4個點的坐標,再利用兩組坐標點則可以計算出透視變換的變換矩陣,最后對原始圖像執行變換矩陣,就可以實現圖像校正功能。
如圖2所示的公式可以看出變換之前的點是z值為1的點,它在三維平面上的值是x, y,1,在二維平面上的投影是x, y,通過矩陣變換成三維中的點X, Y, Z,再通過除以三維中Z軸的值,從而轉換為二維中的點x', y',代碼如下:

圖2 透視變換公式

3 圖像二值化
OpenCV圖像處理模塊中常用的閾值化處理有三種:普通閾值化,自適應閾值,和Otsu二值化。
光影環境對效果的影響非常大,當同一幅圖像上的不同地方具有不同的亮度時,應用局部閾值的處理方法會出現一塊黑,一塊白的情況,并且黑的區域下無法對特征進行提取。在這種情況下我們將采用自適應閾值的處理方法,它是根據圖像上的每一個小區域計算與其對應的閾值,所以在一幅圖像上不同的區域將會采用不同的閾值,極大降低了陰影對于圖片本身的影響,從而我們在亮度不同的情況能獲取到更好的結果。
本項目將在OpenCV中運用thresh3 = cv2.adaptiveThreshold(img,255,cv2.ADAPTIVE_THRESH_GAUSSIAN_C,cv2.THRESH_BINARY,11,2)
函數進行自適應閾值的處理。
4 Canny算子邊緣檢測
獲取圖片的邊緣信息是圖像處理當中的基本任務之一。主要應用于一些數據信息的處理,從中提取想要的目標,剔除一些干擾及不相關的信息,通過精簡的數據去獲得更準確的信息。Canny于1986年開發的一個多級邊緣檢測算法,被許多人們認為時邊緣檢測的最優算法,不容易受噪聲干擾是它的一大優點,能夠真正的檢測到軟邊緣。
Canny邊緣檢測算法包含以下四個步驟。
4.1 高斯濾波
濾波的主要作用是降噪,防止噪聲引起的錯誤檢測。將使用高斯濾波與圖像進行卷積,平滑圖像,減少邊緣檢測器上噪聲的影響。
4.2 計算梯度的幅值以及梯度的方向
圖像中的邊緣將指向各個方向,因此用Canny算法中的四個算子去檢測圖像中的水平,垂直,和對腳邊緣。它的集合包含的都是灰度值變化較大的像素點,白邊和黑邊的中間就是它的邊緣。檢測的算子將會返回Gx和Gy的一階導數值,這樣就可以知道像素點的G和theta。
4.3 非極大值抑制
非極大值抑制是一種邊緣稀疏的技術,它的處理方法就是找到局部中的最大值像素點,再把非極大值所對應的灰度值設為0再將非極大值點對應的灰度值設置為0,就可以將非邊緣的點剔除掉一大部分。完成操作后將會得到一個二值圖像,結果會包含大量的噪聲和一些外界因素所造成的假邊緣。所以我們還要對圖像做進一步的處理。
4.4 雙閾值檢測
對圖像處理之后,余下的像素將更準確的表示出圖像中的實際邊緣,但還是會存在因為顏色及噪聲所引起變化的一些邊緣像素。雙閾值的處理方法是設置一個maxval,以及minval。例如一個像素點的位置的超過了它的高閾值,這個像素點就會保留為邊緣像素;但如果某一個像素點小于低閾值,這個像素點就會被排除;但如果某一個的像素點位置的幅度在兩個閾值的中,像素只連接到一個高于高閾值的像素時會被保留。
本文在python語言的基礎上對字符識別算法進行了初步的研究,在基于Tesseract-OCR開源引擎和OpenCV庫對文檔進行掃描與識別。但仍然存在很多不足的地方,還有待之后的進一步該進。
項目只能對在普通環境下的文檔進行掃描,對清晰的圖像進行識別且只能是英文字符,對其它語種的字符還有待考究。
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
