基于自學習優化模型的定制化居民需求響應預測研究
2021-11-18 02:05:20劉向向趙振佐趙文輝鄧娜娜
電力需求側管理 2021年6期
盧 婕,劉向向,趙振佐,趙文輝,鄧娜娜,王 博
(1.國網江西省電力有限公司 供電服務管理中心,南昌 330001;2.北京理工大學 管理與經濟學院,北京 100081)
0 引言
近年來因家庭電力消費帶來的能源消耗與碳排放問題日益嚴峻[1—2]。居民用電迅速增長是造成電網高峰時段用電負荷呈現兩位數增長、峰谷差不斷增大的重要原因[3—4]。我國電力系統面臨緩解供需矛盾、節能減排的雙重壓力,在“雙碳”的目標下,電網供應側的規模擴張受到了極大的束縛,因此我國迫切需要從需求側開展居民用能管理,提高需求側互動能力。
電力需求響應作為需求側管理的重要舉措,在全世界范圍內得到了廣泛的應用[5—6]。國內外學者圍繞園區[7],以及工、商業用戶[8]的電力需求響應開展了一系列的研究和試點應用。居民電力消費具有單體負荷小、分布散、隨機性強、可控性低等特點,為針對家庭用戶開展需求側管理帶來了挑戰。
因此,本文基于長短期記憶神經網絡(long shortterm memory,LSTM)構建居民電力需求響應自學習優化模型。需求響應開展情況如下:每天早上通過短信的方式發送信息給用戶,通知當天19:00—20:30將開展需求響應活動,對于有意愿參與的用戶,若這1.5 h內比前一天(基準日)用電量減少1 kWh,將給予相應的紅包獎勵。需求響應實驗針對迎峰度夏與迎峰度冬場景多次開展,涉及居民百萬余戶。
此后,在相應時間段采集需求響應數據,通過構建基于時間卷積神經網絡模型的多變量時間序列模型,對居民用戶響應電量進行預測;針對特定削峰填谷目標,基于居民需求響應行為預測結果,得到微觀家庭差異化響應策略優先級排序,基于優化算法制定個性化需求響應調控指標分配方案,以最小的成本實現需求響應目標。
1 參與需求響應用戶關鍵特征識別
1.1 關鍵特征提取
為了詳細分析回復邀約用戶、節電響應用戶與不同響應程度用戶的特征,在采集數據后,開展特征工程,充分挖掘歷史用電序列信息構建特征,再運用機器學習方法,對所構建的特征與響應標簽(是否回復邀約、是否行動響應、響應程度高、中、低)進行模型擬合,最終對擬合的響應結果進行評估和優化,流程圖如圖1所示。
1.2 特征工程
1.2.1 數據預處理
首先通過最小二乘法擬合缺失的用電量,對數據進行補充。其次通過經驗模態分解方法對原始用電時間序列進行分析,基于日用電特征(由高速寬帶載波(high power line carrier,HPLC)智能電能表每15 min采集得來)、年用電序列特征與調查問卷中關于居民的社會與經濟屬性,通過對歷史用電序列信息進行充分的挖掘,分別構建歷史時間序列整體特征與局部特征。整體序列特征包括居民平均用電量、居民用電序列標準差、歷史用電峰度、居民用電長短期趨勢等。局部特征包括時間序列的周期性及波動性的近似熵和分位數。
1.2.2 特征篩選
首先對用戶基準電量等變量做歸一化處理,其次,由于影響居民節電響應程度的原因極為復雜,因此選用機器學習中應用廣泛的神經網絡模型對數據進行擬合。通過反復地構建模型,將篩選出的特征放入列表中,在剩余特征上重復該過程,貢獻度特征重要性前6名如表1所示。

排名123456貢獻度特征重要性用戶基準電量需求響應實驗日期歷史用電中位數歷史用電25%分位數用電長期增長率歷史平均用電量
2 居民需求響應自學習優化模型
2.1 需求響應用戶行為分析
用戶在參與需求響應過程中,主要目標是在保證生活舒適和電力設備穩定的基礎上,實現電力消費最小化。針對多方面因素對用戶的需求響應潛力進行評估并形成潛力優先級順序,從而在一定裕度下優選合適數量用戶參與需求響應,使得在精確達成削減負荷目標的前提下,合理控制需求響應成本。
根據電力削減負荷的目標,結合居民智慧用能標本庫中用戶負荷數據和參與需求響應的歷史信息,通過構建基于時間卷積神經網絡模型的多變量時間序列模型,對上述居民用戶響應電量進行預測。在不同的邀約比例下,對上述的居民排序進行仿真模擬得到用戶響應負荷潛力的情況。
2.2 基于LSTM的用戶需求響應預測建模
本文采用LSTM對需求響應用戶的響應程度進行預測。輸入數據選擇對用戶用電影響最大的環境因素(溫度和濕度)、零售電價、需求響應激勵、用戶特征等,輸出數據為用戶聚合體的用電負荷。
遺忘門ft決定上一時刻的狀態單元中要舍棄和保留的信息
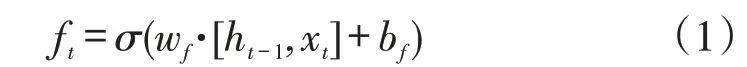
式中:ft為遺忘門輸出變量;σ為sigmoid函數;xt為輸入數據,指溫度和濕度、零售電價、需求響應激勵、用戶特征等信息;ht為用戶用電情況;wf為權值;bf為偏值,分別是各層的神經元系數。
輸入門使用上一個時刻的輸出和本次輸入計算當前輸入單元狀態,算法如式(2),對于當前的輸入狀態計算如式(3)
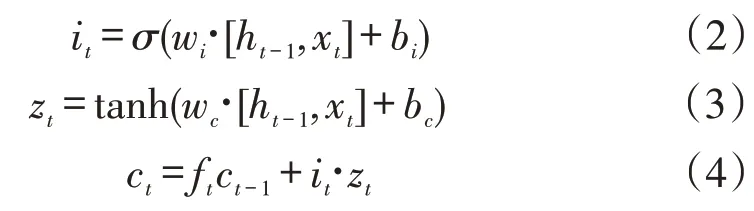
式中:it為更新的狀態單元,是LSTM能夠長期保持記憶的關鍵;wi、wc為權值;zt為當前輸入狀態;bi,bc為偏值;ct-1為上一時刻單元狀態;ct為本時刻單元狀態;tanh為雙曲正切函數,將ct控制在[-1,1]之間,表示輸出門狀態更新。輸出門使用上一個時刻的輸出和本次輸出計算當前輸出單元狀態,算法如式(5),當前輸出狀態如式(6)
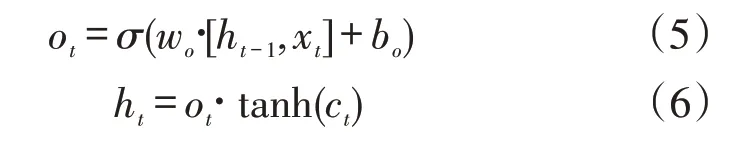
具體預測結果為

式中:ot為更新的輸出單元;xt為輸入數據;wo、wd為權值,bo、bd為偏值,為輸出神經元系數;每個時刻輸入變量包含上一時刻單元狀態ct;yt為最終輸出的用戶用電情況。
3 算例分析
在給定削減負荷目標場景下,若向全部用戶發送邀約,則成本高、效果存在不確定性,產生不必要的需求響應成本。根據需求響應用戶特點,針對給定削減負荷目標,依次選擇合適比例的用戶進行邀約,能夠以最小成本實現需求響應目標。
3.1 用戶響應預測
本研究基于2019年7月19日至2019年8月19日在江西多地開展的6次居民電力需求響應試點數據,結合158 000戶邀約用戶24個月的月度用電量以及上述居民參與需求響應前后7天HPLC智能電能表每15 min的用電數據。同時,集成12 600份參與需求響應用戶微觀調查問卷數據(包含家庭收入、家庭人口結構、家庭常用電器等多種信息)。
將具有完整標簽的用戶數據匯聚成數據集,將數據集合按照7∶3的比例分為訓練集與測試集,對訓練結果進行驗證。關于用戶是否進行需求響應的判別模型中的目標變量,取用戶響應為1,不響應為0,進行模型訓練,驗證結果如表2。

類別/指標模型準確度未響應用戶0.82響應用戶0.90
模型在未響應用戶判斷的準確率為82%,模型在響應用戶的判別上,準確率為90%,說明設置的模型能夠較高程度識別用戶響應情況。
依據對居民進行的特征工程分析,繼續衡量居民是否接受邀約的影響因素。本文進一步對重要信息與預測結果的關系進行探究,得出用戶基準電量與用戶是否接受邀約有正相關關系,而歷史用電中位數等信息對判斷用戶是否接受邀約作用較小,具體關系如圖2,根據分析結果,為居民響應預測提供參考。
3.2 需求響應潛力預測
為了構建電力數據和需求響應潛力之間的關聯,或通過電力消費數據反推用戶需求響應潛力,構建神經網絡模型,對標簽進行學習,進而外推到其他未獲取到問卷的用戶。采取LSTM方式,輸入環境溫度、濕度、電價等數據,進行月度數據的自動特征提取。訓練過程中的均方根誤差為
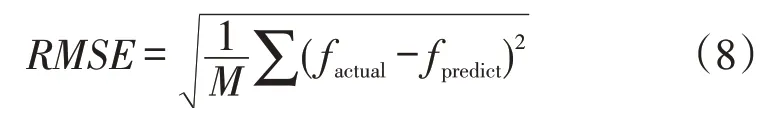
式中:RMSE為均方根誤差值;M為測試樣本總數;factual,fpredict分別為消費數據的實際值與預測值。
從模型訓練結果來看,模型很快就達到收斂狀態,損失函數穩定在0.000 015左右。模型快速收斂,且誤差較小。從預測結果看,整體預測效果較好,可以進一步推廣應用。預測結果如圖3所示。
根據居民用戶特征工程后的標簽,對居民實際響應量進行模擬預測,推斷用戶需求響應潛力,使需求響應潛力更大的用戶排序更靠前,并不斷修正排序結果,最終得到目標水平下的最優激勵水平。
3.3 定制化需求響應策略生成
目前,江西應用自學習優化模型開展了居民電力需求響應試點工作。逐步形成分地區、分層次的需求響應調節潛力方案,根據電網調節需求,在削峰負荷目標確定的情況下確定合適的邀約比例,根據居民需求響應潛力自動優化形成精準的目標客戶推送策略。
4 結束語
本文針對特定削峰目標,基于大規模激勵型居民需求響應試驗數據,應用特征工程,分析居民用戶特點,標簽化用戶各類屬性;結合神經網絡構建居民電力需求響應自學習優化模型,對用戶響應情況以及響應潛力進行預測,提供有針對性的需求響應優化策略,為電力公司需求響應工作開展提供了高效細致的解決方案,降低了需求響應的成本。此研究成果在江西省進行試用,取得了較為良好的成效。本研究針對用電量進行預測,受限于樣本庫質量,在后續研究中會進一步擴大樣本庫規模,不斷提高預測效果,實現需求響應管理智能化決策。D
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
