基于改進YOLOv4-Tiny的成捆原木端面檢測算法
2021-11-22 02:47:04蔡瑞星林培杰林耀海余平平
電視技術 2021年9期
蔡瑞星,林培杰,林耀海,余平平
(1.福州大學 物理與信息工程學院,福建 福州 350108;2.福建農林大學 計算機與信息學院,福建 福州 350002)
0 引 言
森林資源作為陸地生態系統的主體,是人類賴以生存的重要資源之一。根據國家林業局在2014年發布的第八次全國森林資源清查結果[1],我國森林資源仍存在總量相對不足、質量不高以及分布不均的情況,因此需要合理地規劃現有的森林資源。在中國的木材生產、流通過程中,原木材積的準確和有效測量不僅直接影響原木工程的經濟效益[2],還能有效防止木材資源的浪費。原木的材積計算由木材端面徑級和木材長度兩個參數決定,同一批原木長度往往相對固定[3],因此,原木端面檢測作為獲取原木徑級的第一步就顯得尤其重要。然而,成捆原木圖像中原木端面的形狀大小不一、異物遮擋、陰影等問題會給原木端面檢測帶來嚴峻的挑戰。
現有的原木端面檢測方法可以大致分為傳統圖像處理方法和深度學習方法兩個部分。東北林業大學梅振榮等人根據原木端面的圖像特征,結合面積閾值法和數學形態學,檢測原木端面點[4]。廈門大學林靜靜等人提出了基于鏈碼的原木端面圖像檢尺徑級識別算法,其較依賴于原木端面的分割效果[5]。東北林業大學趙亞鳳等人針對在光照下原木之間陰影相互遮擋的問題,采用了遺傳算法確定圖像增強的三階段線性變換的兩個轉折點,然后用同態濾波器進行圖像分割,達到較好的識別效果,但是遺傳算法的使用也帶來了較大的耗時[6]。河北農業大學唐浩等人針對自然環境對原木端面檢測的影響,通過色差值聚類對原木圖像進行分割,提取原木端面特征,采用逐級開運算并且改進分水嶺算法對原木端面實現計數,但是該方法在復雜背景下的魯棒性會受影響[7]。
近幾年,得益于深度學習領域以及相關硬件設備的快速發展,深度學習越來越廣泛地應用于目標檢測任務中。深度學習算法相比于傳統圖像處理方法具有更強的魯棒性,能夠在原木端面形態差異較大的情況下仍然具有較高的識別率。目前的目標檢測網絡模型主要可以分為二階段網絡和一階段網絡兩種[8],其中,二階段網絡是基于區域推薦的一種模型,區域卷積神經網絡(Regions with convolution neural network,R-CNN)[9]作為二階段網絡的代表模型,首先通過區域推薦生成候選區域,其次通過卷積網絡提取每個候選區域的特征,再次,R-CNN把這些特征輸入到支持向量機(Support Vector Machine,SVM)進行分類,最后通過線性回歸來調整預測框的位置。這種方法在最近幾年也進行了一系列的改進,例如Faster R-CNN[10],Grid R-CNN[11]等,這些方法也同樣被應用于各個領域的檢測中,但是R-CNN系列的網絡結構比較復雜,會帶來巨大的模型參數。一階段網絡是基于回歸的方法,主要以YOLO(You Only Look Once)[12-13]系列和SSD(Single Shot Multibox)系列為代表,這些一階段網絡將物體的分類和定位放在一個步驟中進行,直接在輸出層回歸目標檢測框的位置和類別。福建農林大學的林耀海等人利用YOLOv3-Tiny結合霍夫變換(HoughTransform)設計出一種等長原木材積檢測系統[3],達到了較高的準確率。但是YOLOv3-Tiny采用固定的學習率衰減,容易陷入到局部最優點,其結果是,在原木端面污漬較小、差異不大時檢測效果很好,當原木端面差異較大時,檢測準確率明顯下降。相比于YOLOv3-Tiny,YOLOv4-Tiny采用了余弦退火的學習率衰減,能夠有效地逃離局部最優點,訓練出更好的模型。河北農業大學唐浩等人采用SSD網絡實現不同尺度的目標特征提取,克服了傳統算法在不均勻光照下的原木間互相遮擋的問題,達到很高的檢測精度。然而SSD網絡由于結合了多個尺度的目標特征,不免帶來參數冗余問題。
因此,本文采用YOLOv4-Tiny網絡,通過引入注意力機制中的壓縮和激勵(Squeeze and Excitation,SE)模塊[14],在保證不會加入更多模型參數的前提下提升網絡的識別性能,減少原木端面圖像中的漏檢原木數量,使得模型能夠更加完整地檢測出原木端面圖像中的原木。同時,考慮便攜式手持設備在實際成捆原木端面檢測任務中更具有實用性,引入深度可分離卷積(Depthwise Separable Convolution,DSC)[15]來替換YOLO模型中解碼網絡的卷積步驟,以縮減模型的參數量,提高該深度學習模型在嵌入式設備應用的可行性。通過實驗結果對比,本文所提出的改進的YOLOv4-Tiny網絡能夠在保證召回率的同時,降低模型的參數量,使其更易于移植。
1 材料與方法
1.1 數據集
實驗數據總共177張圖片,其中一部分來自福建永安某林場的成捆原木圖像集,另一部分來自互聯網。124張圖片作為訓練集,53張圖片作為測試集。每一張圖片的原木數量從3到100根不等,訓練集總共有5 112根原木,測試集總共有1 846根原木。部分原木圖像如圖1所示。原木圖像數據采用Pascal VOC2007標準格式,采用LabelImage進行數據標注,標注過程如圖2所示,標簽設置為log。

圖1 部分成捆原木圖
YOLOv4-Tiny有一種馬賽克(Mosaic)數據增強方式,該數據增強方法包括以下4個步驟:
(1)隨機讀取四張圖片;
(2)對讀取圖片進行隨機的縮放、色域變換以及翻轉等操作;
(3)將變換后的圖片擺放在左上、左下、右上、右下四個位置;
(4)將真實標注框進行整合。
Mosaic數據增強的結果如圖3所示。測原理如圖4所示。
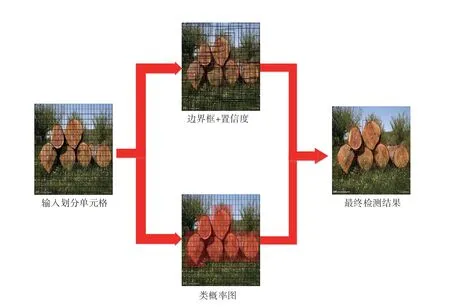
圖4 YOLO系列檢測原理圖
經過縮放之后,原始圖片被分為N×N個單元格,如果目標中心落在單元格內,單元格內目標的位置和類別信息就會被預測。每個單元格預測類別的條件概率C,邊界框B的位置信息以及置信度,邊界框置信度包含預測框內是否包含目標Pr(Object)以及預測框和真實框的交并比(Intersection Over Union,IOU)
1.2 YOLOv4-Tiny原理
YOLO系列提供將目標檢測問題轉換為回歸問題的端到端的目標檢測框架。它的分類和回歸任務在同一個網絡中實現,直接預測目標的位置和類別信息,有著較快的檢測速度。YOLO系列的目標檢兩個部分。邊界框的位置和大小信息包括中心點坐標(x,y),目標寬度w,目標高度h。其中,中心點坐標是相對于單元格左上角的偏移量,而目標寬高則是相對于整張圖片的大小,因此,預測值(x,y,w,h)屬于[0,1]。對于分類任務,每個單元會輸出C個預測類別的概率值,表示目標屬于各個類的條件概率Pr(Classi|Object),因此每個邊界框的類別置信度可以表示為:
對于分類和回歸任務,YOLO模型中每一個單元格的輸出為(B×5+C),如果輸入被分為N×N個單元格,那么YOLO模型的最終輸出結果為N×N×(B×5+C)。
相比較于YOLOv3,YOLOv4網絡主要對數據處理、主干特征提取網絡、網絡訓練方法、激活函數以及損失函數等做了一系列的改進,在數據處理上采用馬賽克數據增強方式,主干特征提取網絡采用CSPDarknet53替換了原來的Darknet53,采用余弦退火的學習率衰減和標簽平滑的訓練方法、Mish激活函數替換原來的Leaky Relu激活函數以及使用CIOU損失函數等。
1.3 改進的YOLOv4-Tiny
如圖5所示,本文將SE模塊用于YOLOv4-Tiny的主干特征提取網絡的輸出特征中,用以加強特征的表達,同時在YOLOv4-Tiny的解碼網絡中,采用深度可分離卷積代替原有的卷積層,降低整個模型的解碼參數
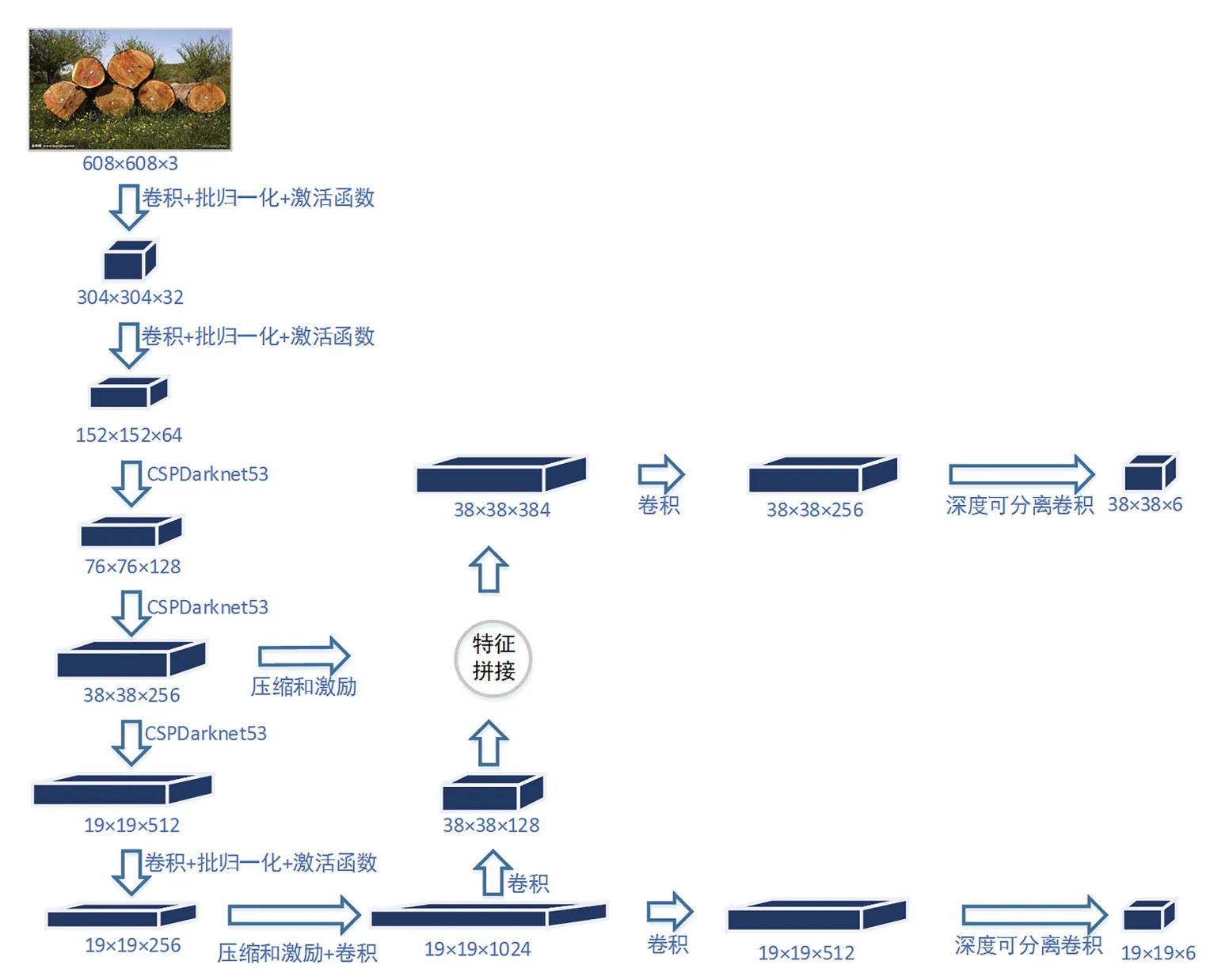
圖5 改進YOLOv4-Tiny的網絡結構
1.3.1 壓縮和激勵模塊
如圖6所示,SE模塊加入到YOLOv4-Tiny的輸出特征的網絡中,通過一個全局平均池化,將特征圖壓縮成1×1×C(C為特征通道數)尺度,使用特征通道比例系數r縮放,最后經Sigmoid激活函數,將取值范圍歸到0和1之間,用來表示每個通道特征的權值。最后通過與YOLOv4-Tiny的輸出特征進行按位相乘相加,放大對識別原木有用的 信息特征。
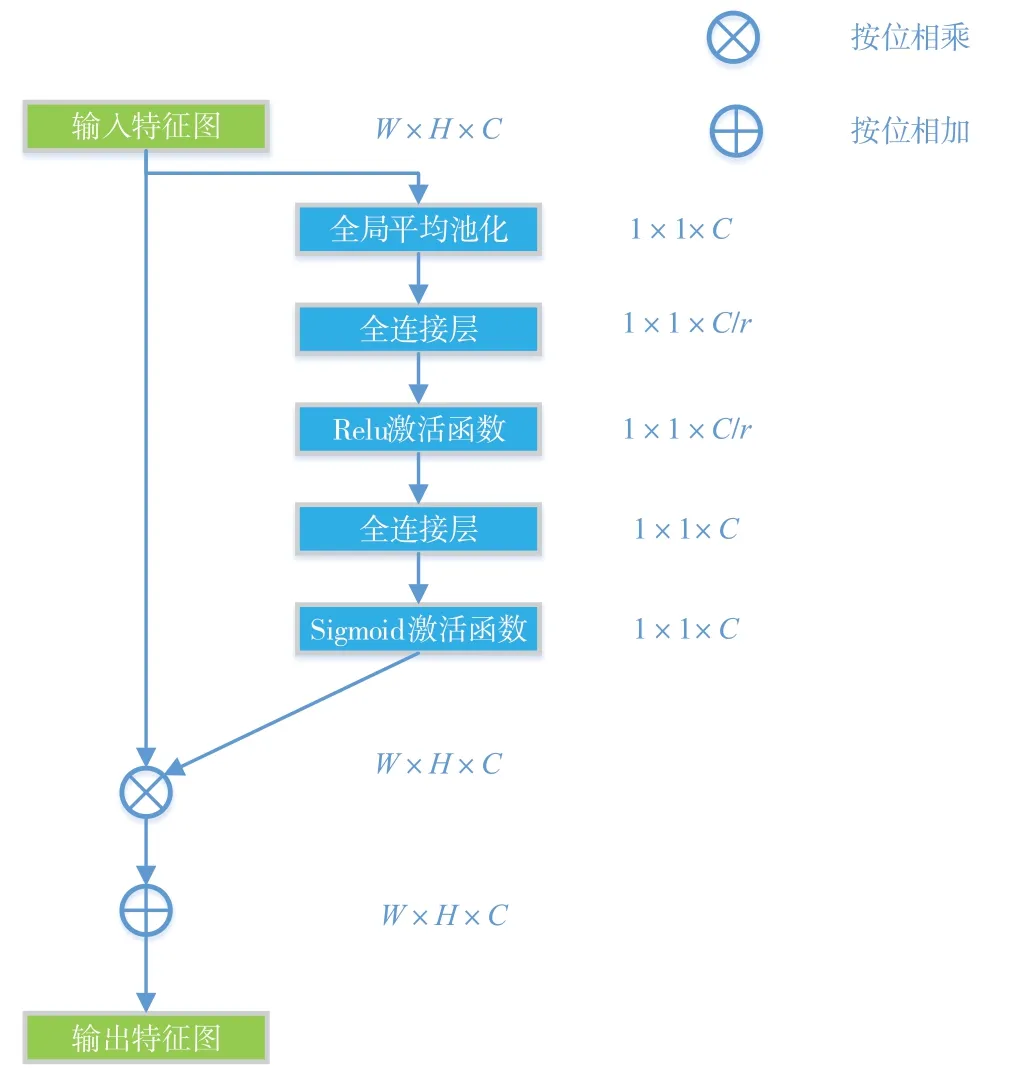
圖6 SE模塊結構圖
1.3.2 深度可分離卷積
為了保證模型的檢測性能,同時降低模型的參數量,本文采用深度可分離卷積來替換YOLOv4-Tiny解碼網絡中普通的卷積層,其結構如圖7所示。深度可分離卷積將卷積具體可以分成兩個計算 步驟:
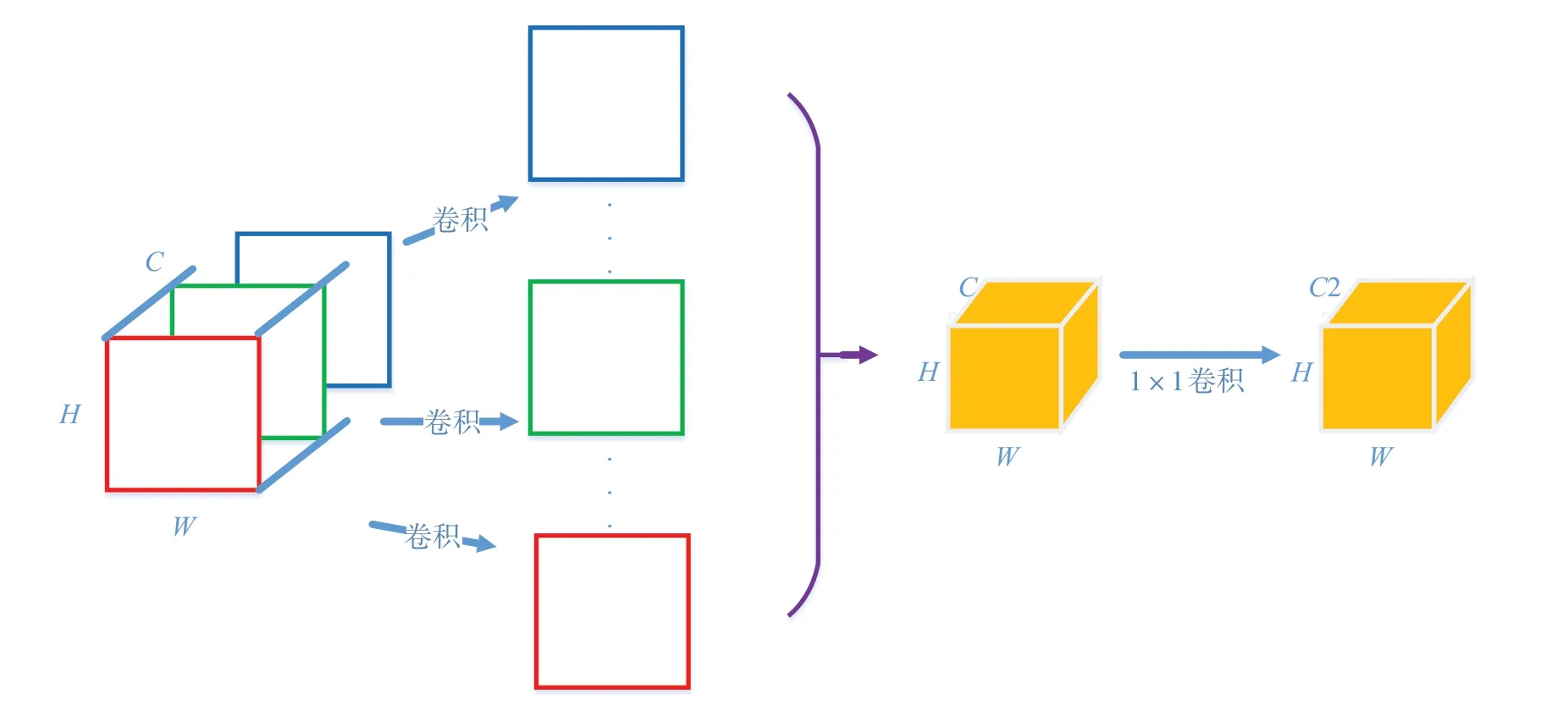
圖7 深度可分離卷積結構
(1)對每一個特征通道進行卷積提取特征;
(2)利用多個1×1的卷積來進行特征的升維,以達到所需的特征維度
2 實驗結果與分析
2.1 實驗環境與網絡訓練預處理
2.1.1 實驗平臺
本文實驗在一臺配有顯卡的工作站上完成,工作站的主要配置如表1所示。

表1 實驗平臺配置
2.1.2 實驗參數設置
由于YOLOv4-Tiny模型需要對輸入圖片進行5次下采樣,因此輸入圖片大小需要是32的倍數,同時考慮到實驗設備的性能,本文選用608×608作為改進YOLOv4-Tiny模型的輸入大小,Batch的大小為32,選擇Adam作為模型的優化器,初始學習率為0.000 1,權重衰減值為0.000 5。對于YOLOv4-Tiny先驗框的選取,本文采用K-means聚類算法對訓練集的數據進行聚類,獲取模型的先驗框,以IOU作為K-means的距離函數,K的取值采用YOLOv4-Tiny的建議值6,最后得到的先驗框為(18,25)、(29,41)、(44,56)、(55,82)、(80,111)、(127,162),其他參數均為YOLOv4-Tiny原始的模型參數。
2.2 評價指標
為了分析模型對于成捆原木端面的檢測性能,本文選用平均精準率(Average Precision,AP)、召回率(Recall)、精準率(Precision)、F1得分(F1-score)以及對數平均誤檢率(Log Average Miss Rate,LAMR)來進行評價。采用模型的權重大小來分析模型的參數量。相關計算公式如下:

式中:TP為正確的檢測的正樣本數目,FP為錯誤的正樣本數目,FN為錯誤的負樣本數目,Miss為誤檢率,FPPI為每張圖片錯誤的檢測數目,N是測試樣本的總樣本數,K是錯誤的檢測數目。
2.3 結果與分析
2.3.1 檢測結果對比
為了評估所提出的模型對于成捆原木圖像中的檢測效果,本文將其與二階段模型Faster RCNN、一階段模型SSD以及YOLOv4-Tiny進行對比,實驗結果如表2和表3所示。
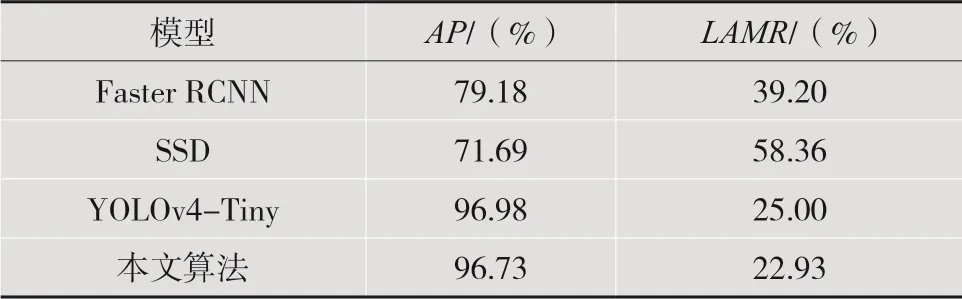
表2 不同探測器整體性能對比
表2中,本文算法無論是AP值還是LAMR值,相比較Faster RCNN和SSD模型都有明顯的改善。相比較Faster RCNN,AP值提升了17.55%,LAMR值降低了16.27%;相比較SSD模型,AP值和LAMR值改善得更加明顯,AP值提高了25.04%,LAMR值降低了35.43%。雖然本文算法在AP值上相比較YOLOv4-Tiny模型只有少許的下降,但在LAMR上降低了2.07%,達到了22.93%。這表明通過SE網絡來實現的注意力機制,能夠有效地增強主干特征提取網絡的輸出特征,顯著降低原木端面的誤檢率,增強了模型的魯棒性。
表3中,本文算法具有最優的TP、FN、F1-score和Recall,分 別 達 到 了1 755、91、0.94和95.07%,TP指標達到了最高,FN指標達到了最低,說明所改進的模型相比較Faster RCNN、SSD及YOLOv4-Tiny模型,在測試集上的漏檢原木數達到了最低,能夠更多地檢測到一張圖片中的原木端面;F1-score指標則說明本文算法相比較其他3種模型能夠在精準率和召回率之間達到一個最好的平衡;Recall指標則意味著該模型能夠更加完整地檢測出一張圖片中的所有原木。本文算法的精準率達到了93.3%,相比較SSD模型雖然有一些下降,但在召回率上,本文算法相比較SSD模型有了大幅度的提升,提高了16.96%,同時,SSD的漏檢原木數目達到了404根,占測試集所有原木的21.89%,存在明顯的漏檢。這是因為SSD融合了各個尺度的特征,追求識別的精度,注重所檢測到的目標必須都是原木的情況,這在模型優化過程中就容易忽略和背景相似、原木間遮擋、異物遮擋情況下的原木,造成了Recall的嚴重下降。這對于原木端面檢測來說是不利的。原木檢測需要將一張圖片中的原木盡可能地檢測出來,才能有效地代替人工檢測,因此SSD的Recall顯然不滿足實際需求。同時,本文算法相比較于YOLOv4-Tiny網絡,由于結合了SE模塊,加強了網絡的特征提取能力,豐富了特征的表達,誤檢數目(FP)降低了18.71%,Precision提升了1.43%。如圖9所示,本文所提出的模型能夠比較完整地檢測出一張圖片中的所有原木,并且在有異物遮擋、光線較暗的情況下也能夠準確地檢測出原木目標。因此,本文所提模型相比于其他3種模型,更加適合應用于成捆原木端面檢測任務。

表3 不同模型檢測結果統計表(置信度閾值為0.5,IOU閾值為0.5)

圖9 部分檢測結果圖
2.3.2 模型參數量對比
本文通過模型權重的大小來比較模型的參數量,結果如表4所示。本文所提出的模型結合了DSC,減少了YOLOv4-Tiny解碼網絡的參數,因此整個模型權重大小只有15.7 MB,是Faster RCNN的14.54%,是SSD的17.33%。相比較YOLOv4-Tiny模型,本文網絡模型減少了29.91%,明顯降低了模型的參數量,更加適合在嵌入式平臺上移植。
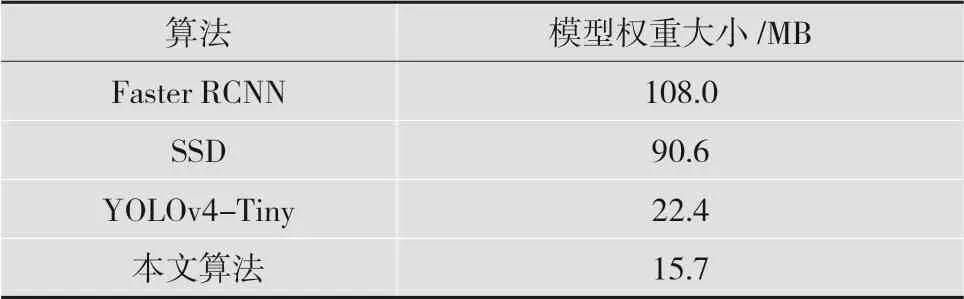
表4 不同模型權重的大小
3 結 語
原木端面的有效檢測是原木徑級測量的重要環節。為了提高原木端面檢測模型的識別性能,增強模型的可移植性,本文提出了基于改進YOLOv4-Tiny的成捆原木端面檢測模型,借助壓縮和激勵模塊,能夠更加完整地識別出一張圖片中的所有原木,適用于有異物遮擋、光線較暗的場景,同時使用深度可分離卷積降低了模型的整體參數量,更利于在嵌入式系統上的運行,實現設備的便攜和方便使用。本文改進了YOLOv4-Tiny在應用上的一些不足,但YOLOv4-Tiny模型還存在小目標檢測能力低、某些情況下預測框和真實目標貼合度小等問題,因此將在今后的工作中進一步優化和改進網絡結構。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
