私播課論壇中學習者會話行為建模研究
2021-11-26 03:01:44張思高倩倩馬鑫倩魏艷濤楊海茹
電化教育研究 2021年11期
張思 高倩倩 馬鑫倩 魏艷濤 楊海茹
[摘? ?要] 私播課(Small Private Online Course, SPOC)論壇中的非結構性文本蘊含學習者認知和內部心理加工過程,對其分析有助于理解和解釋學習結果的成因。以64名學生在SPOC論壇中的會話文本為對象進行數據挖掘,結合LDA主題建模和隱馬爾可夫模型對學習者會話行為進行實體建模,并比較高低績效組會話行為差異,最后運用回歸分析和卡方檢驗探索了影響學習績效的行為模式。結論表明高低績效組的學習行為轉移存在明顯差異,高績效組的行為轉移具有漸進性和平滑性,傾向于序次解決問題,而低績效組的行為轉移則更傾向于淺層回溯。信息查閱、信息加工、信息發布、協作交互、問題解決和信息評價行為均與學習成績有關,但信息查閱行為對學習成績有著顯著正向影響,且較多的協作交互和信息評價行為能夠觸發學習者的高階認知。通過教育文本數據挖掘,教師能夠發現不同群體的行為特征,從而進行適應性指導和精準教學,促進學習者高階思維發展。
[關鍵詞] LDA主題模型; 隱馬可夫模型; 學習行為; 學習績效
[中圖分類號] G434? ? ? ? ? ? [文獻標志碼] A
[作者簡介] 張思(1983—),男,湖南長沙人。副教授,博士,主要從事計算機支持的協作學習與學習分析技術研究。E-mail:djzhangsi@mail.ccnu.edu.cn。楊海茹為通訊作者,E-mail:yang.hairu@qq.com。
一、引? ?言
教育大數據在教育的發展與變革中正起著顛覆性的作用,從海量的教育信息中發現規律、診斷問題以及準確預測具有重要價值。在線教學中學生通過文本進行交流,學習平臺上大量的非結構性文本數據是學生內隱行為的外化,文本數據往往更能夠反映學習者的認知、學習動機、情感態度和學習體驗[1]。不同認知水平的學習者其認知模式不同,在信息的加工與處理、接受學習的成效上都有所不同[2]。利用大數據技術對文本數據進行挖掘和分析可以得出與學習者學習狀況相關的行為、認知等信息,同時能夠對教學中的問題和現象進行解釋。利用文本挖掘開展學習分析有助于教師進行個性化學習設計和教學決策,從而優化教與學,但僅僅通過分析學習者在任務上的投入時間和精力并不能細致判別學習者的投入程度,而通過細粒度的學習行為序列挖掘更能體現學習者的認知過程和行為軌跡。
本研究以學習者發布在SPOC論壇中的會話文本數據為研究對象進行數據挖掘,對文本數據進行主題建模及行為轉移概率分析,并探索行為序列和學習成績的關系,目的是厘清影響在線學習績效的關鍵因素,提升在線學習質量。
二、文獻綜述
(一)學習行為識別與建模
1. LDA主題分析
在自然語言處理領域,主題模型廣泛應用于文本聚類和分類[3]、文本情感分析[4]、話題的檢測與演變[5]等。潛在狄利克雷分布(Latent Dirichlet Allocation,LDA)是一種文檔主題生成模型,由Blei等人首先提出,其包含了文檔、主題和詞三層結構,是一個降低文本表示維度的三層貝葉斯概率模型,廣泛應用于語義挖掘領域。LDA非監督模型能夠得出主題分布,通過計算相似度進行聚類,在計算準確度和聚類效果上優勢明顯。
2. HMM建模
隱馬爾可夫模型(Hidden Markov Model,HMM)是一種概率統計模型,由Baum等人提出,能夠應用在多種領域中。HMM模型包含觀察層和隱藏層,可以用五元組λ=(V,Q,π,A,B)進行表示,在五元組中,可觀測值的序列集合是V,隱狀態序列集合是Q,初始狀態轉移向量是π,狀態轉移概率的矩陣是A,生成的觀測概率矩陣是B。隱馬爾可夫模型可用于解決評估、學習和解碼三類問題,并識別出隱狀態之間的轉移概率。同時,通過隱藏狀態對數據結構的潛在變化進行表示,HMM能夠更好適應和解釋模型。隱馬爾可夫模型在語言識別、詞性標注等方面得到了廣泛應用,是一種重要的統計模型。在線學習中,通過HMM模型可以識別不同學習群體的交互活動序列。
(二)數據驅動的學習行為建模
學習行為是學習者為了獲得某種學習結果,在動機的指引下與周圍環境雙向交互活動的總和。在SPOC論壇中,學習者利用信息技術在豐富的學習環境中進行溝通交流,開展自主與協作學習的活動總和稱為網絡學習行為,也稱在線學習行為。在學習行為分類上,彭文輝等將網絡學習行為分為低級、中級和高級三個層次,并將在線學習行為分為收集信息、加工整理信息、發布信息、交流信息和使用信息五類。莊科君將網絡學習行為分為操作行為、信息交互行為、意義建構行為和問題解決行為。王海麗對網絡學習行為進行劃分并構建了六層模型,從底層至上層依次為信息查閱行為、信息加工行為、信息發布行為、信息交互行為、問題解決行為和信息評價行為。相關研究從理論視角探討了在線學習行為的分類方法,在線學習行為分類和標記依賴人工方法解決問題,缺乏從底層數據出發的會話行為自動建模方法與技術。對于在線教育的分析和干預而言,需要精準、可復制、具備較強通用性和解釋力的模型,但適配的學習分析技術亟待出現。
(三)學習行為與學習成效的關系研究
在線學習行為與學習成效密切相關,是預測學習成效的重要指標,分析學習者的在線學習行為能夠促進學習者的有意義和有效學習。研究表明學習者發布的討論數量與其在線課程的學習成效具有顯著的關系,通過探索觀看視頻次數、提交測驗次數、發帖與回帖次數等行為特征與學習成績間的關系,可以預測學習者的學習成績。Cerezo從學習者在六個不同任務中分別花費的時長出發,將學習者進行聚類和分類并比較不同類別間的差異。趙呈領從學習資源的視角出發,依據觀看視頻、瀏覽文檔、發布討論主題、閱讀回復討論和參考作業模板等網絡學習行為的時長進行聚類,探究了在線學習者學習行為模式和學習成效之間的關系。江波等人利用虛擬仿真平臺從學生的學習行為特征出發進行定量描述,得出九種行為中五種學習行為與學習成績相關。相關研究較多探索了學習者外在行為表現與學習績效的關系,而學習者內隱行為特征與學習績效的關系則較少關注。隨著人工智能與大數據技術的發展,學習者內隱行為特征的智能分析成為可能,結合學習者內隱行為特征探索學習行為與學習績效的關系,其結果將更具準確性和可解釋性。
三、研究設計
(一)研究情景、對象與數據源
研究對象為某師范院校的高年級本科生。數據來源于“信息技術教學應用”課程。課程采用協作學習的模式,師生共同探討信息技術和課程教學深度融合的方法和技術。所有小組通過SPOC論壇進行討論與交流。協作活動流程分為教學設計初稿、教學設計互評、教學設計修改與完善、教學課件初稿、教學課件互評、教學課件修改與完善六個階段。本研究收集了學生于2020年2月至2020年7月在SPOC論壇中討論的帖子。一共有64名學生,分為13個小組參與了課程的討論和學習,并最終取得了成績,平均分是86.81,標準差為3.605。SPOC論壇上共產生6616條討論帖,處理和篩選后最終獲得4928條討論帖。
(二)數據的處理與分析
1. 確定最優主題數和主題的方法
數據獲取字段包括學生個人信息、評論時間、評論文本和回復文本等。為產生理想的主題建模效果,篩選與課堂內容相關的帖子并控制帖子長度在4個字符以上。經過文本數據分詞、去停用詞、過濾無關字符等操作,并利用Python語言的gensim庫計算困惑度(Perplexity)。當主題之間相似度最小時,主題建模最優,困惑度值可用于確定最佳主題數。困惑度值越小,模型的效果越好。困惑度計算如公式(1)所示。
Perplexity(D)為數據集的困惑度,式中M表示一共M篇文檔,Nd表示語料庫中第d個文檔所包含的詞數,p表示文檔d中的詞的生成概率。結果表明當主題數為19時,困惑度數值最小,因而選擇19作為最佳主題數。確定主題數后利用Python語言的gensim庫實現LDA主題抽取,形成文檔—主題和主題—詞的概率分布。
2. 隱馬爾可夫模型方法
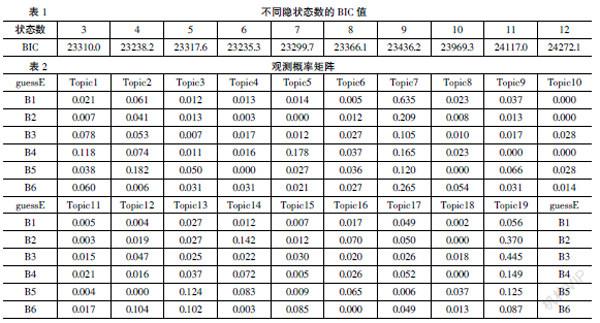
HMM模型既能發現隱狀態和觀測值之間的對應關系,也能發現狀態間的概率轉移關系。通過訓練,HMM可以自動構造和識別模型,從而得出參數。首先要確定隱狀態的個數。研究使用LDA主題建模結果,通過在Matlab中輸入不同的隱狀態數值進行HMM訓練,依據BIC值確定最終隱狀態的個數。BIC的計算方法如公式(2)所示。
其中L是模型似然函數值,P是自由參數的個數,N是數據點的數量。BIC的數值最小時,模型結果最優,結果見表1。當狀態數取值為6時,BIC的值最小,因此設置隱狀態數即學習行為分類數為6。將隱狀態數6,主題數19輸入到HMM中生成了轉移和觀測概率矩陣,見表2。轉移矩陣表示行為之間的轉移概率情況,而觀測概率矩陣則表示在y的情況下,輸出為x的概率。通過觀測概率矩陣找出每個主題在行為(B1-B6)中對應的最大概率,從而確定主題所對應的學習行為分類。
四、研究結果與分析
(一)主題建模結果
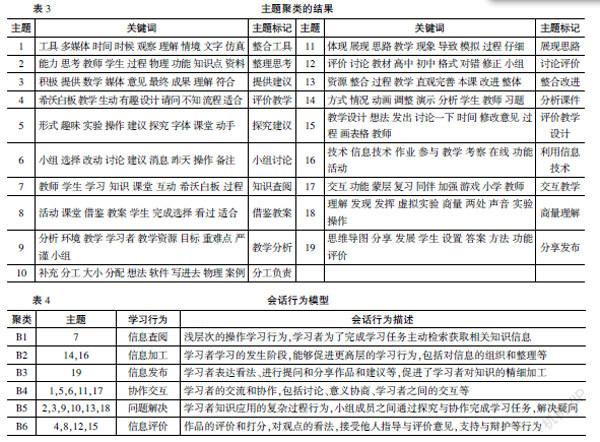
以19個主題的前9個高頻詞為代表,依據主題詞匯進行語義分析和主題內容歸納,生成主題標簽,19個主題的關鍵詞和主題標記結果見表3。依據表2觀測概率矩陣,參考王海麗對在線學習行為的分類,將行為與主題進行對應。會話行為模型見表4。
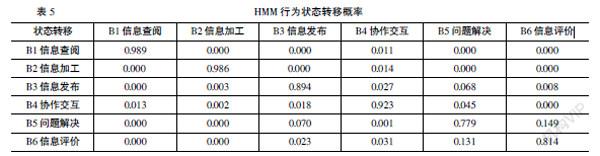
(二)基于HMM的學習行為轉移概率矩陣
HMM 計算不同行為間的轉移概率,結果見表5。從整體來看,行為間轉移的概率較小,基本維持狀態穩定。盡管B1向其他行為轉移的概率很小,但仍可能向B4轉移;B2也以一定的概率轉移到B4;說明經過信息查閱和信息加工后,小組會進入協作交互階段。B3和B4向B5轉移的可能性較大,目的指向問題解決。B5向B6和B3轉移的概率較大。B6以一定的概率轉移到B5、B4、B3。在行為狀態中,處于低層次的行為(B1,B2,B3,B4,B5)以一定的概率向高層次的行為轉變,而高層次的行為(B6)會隨著時間的變化部分轉移到低層行為(B5,B4等),這些都體現了學習者會話行為的過程和規律。
(三)不同績效組學生的學習行為轉移特征分析
對小組成員的最終成績求均值,確定高績效組和低績效組。分析高績效組和低績效組的行為轉移概率矩陣,并繪制行為轉移圖,結果如圖1所示。在圖中,箭頭指向轉移的行為,數值為轉移的概率,概率越大箭頭越粗。
高績效組的B1信息查閱行為主要轉移到B1信息查閱行為,部分會轉移到B2信息加工行為,而低績效組B1則以0.94的概率轉到B6信息評價行為。高績效組中,B2主要是向B3轉移,部分還會向B6轉移,而低績效組中,B2主要是向B3和B5轉移。高績效組中,B3主要向B4協作交互和B5問題解決轉移,而低績效組中,B3會以較大概率向B1和B3轉移。B4協作交互中,高績效組以0.73的概率會保持此狀態,以0.27的概率向B2信息加工轉移,低績效組則以0.91的概率保持此狀態,向信息查閱和信息加工轉移的概率很小。高績效組以0.75的概率停留在問題解決行為,仍有0.16和0.09的概率向B2和B1轉移,而在低績效組中,B5完全轉移到B2信息加工行為。在B6信息評價行為中,高績效組會以0.83的概率維持,另外分別以0.08和0.09的概率轉向B2信息加工和B4
協作交互轉移。低績效組中,B6會以0.69的概率轉移到B1信息查閱,以0.31的概率轉移到B5問題解決。
(四)學習行為與學習成績的關系
1. 單個行為與學習成績的關系
(1)相關分析
采用Spearman相關分析法探討學習行為和學習成績的關系。結果表明,在0.01水平上,六種行為均與學習者成績相關:B1(r=0.480)、B2(r=0.405)、B3(r=0.402)、B4(r=0.444)、B5(r=0.336)、B6(r=0.429)。
(2)回歸分析
回歸分析用于確定學習行為對學習成績的影響大小及方向。對64名學生的行為數據與學習成績進行中心化處理,然后進行回歸分析。結果見表6。
從表6可以看出,B1對學習成績具有正向的影響作用。B1信息查閱體現了學習者嘗試對知識進行理解和把握,從而提升教學設計和教學課件的質量。
(3)高低績效組學生學習行為頻數的差異分析
采用6(行為)×2(績效組)交叉表卡方檢驗,分析高、低績效組中六種行為的頻數差異,結果見表7。從行為的總數看,高績效組學生的行為頻數明顯高于低績效組學生。行為類別中與學習成績成正相關的信息查閱行為,高績效組頻數明顯高于低績效組。高績效組中協作交互行為占比最高,體現了廣泛的協作。此外,高績效組的信息評價行為也較多。在低績效組中,問題解決行為的頻數最高,其次是信息發布行為,而協作交互行為較少,在體現高階認知的信息評價行為方面則最少。
2. 行為序列與學習成績的關系
(1)相關分析
將一個行為之后緊接著出現另一種行為稱為行為序列,如B1B2編碼表示B1行為之后緊接著出現B2行為。本研究利用SPSS21.0對六種行為所產生的36個行為序列與學習成績進行相關分析。結果表明,行為序列總頻次和學習成績有較高的正相關性(r=0.522,p<0.001),這與李爽的結果相一致。相關分析結果表明,在0.01水平上與學習成績相關的行為序列有:B4B6(r=0.412)、B4B5(r=0.410)、B5B1(r=0.408)、B2B4(r=0.407)、B2B3(r=0.403)、B5B4(r=0.391)、B1B1(r=0.386)、B4B1(r=0.378)、B1B5(r=0.375)、B4B4(r=0.360)、B6B5(r=0.359)、B2B1(r=0.347)、B6B1(r=0.342)、B1B6(r=0.341)、B5B3(r=0.324)。在0.05水平上與學習成績相關的行為序列有:B6B4(r=0.403)、B6B3(r=0.395)、B3B1(r=0.361)、B6B6(r=0.344)、B3B6(r=0.336)、B4B3(r=0.336)、B4B2(r=0.306)、B3B3(r=0.303)、B5B6(r=0.293)、B2B2(r=0.283)、B5B5(r=0.277)、B3B5(r=0.263)、B1B2(r=0.258)、B1B3(r=0.247)。但在行為序列對學習成績的回歸分析中,單個行為序列的系數都沒有達到顯著性。
(2)高低績效組學生學習行為序列頻數的卡方檢驗
對高績效組和低績效組的行為序列頻數進行卡方檢驗。高低績效組行為序列分布具有顯著性差異(χ2=73.718,p=0.04)。
五、討? ?論
高績效組在課程的學習行為轉移上體現出漸進型和平滑型。高績效組的學習者通過查閱相關資料更深入地理解和內化新知識,之后通過分析比較、組織整理完成信息加工。此外,高績效組的學習者的低階行為表現較多,信息查閱行為停留概率較高,問題解決和信息評價行為停留的概率也較大,這表明高績效組學生對知識有著更好的理解。低績效組的學習行為轉移則具有非線性和突變性。例如從信息查閱直接轉移到信息評價,從問題解決直接轉移到信息加工等。這可能是由于學習者只注重完成學習任務而不注重知識的整合與應用。
相關分析和回歸分析的結果表明六種行為均與學習成績存在相關性,且信息查閱行為對學習成績具有正向影響。因此有必要引導學生針對具體問題查找相關的知識信息,從而去解決問題。在行為序列方面,在0.01水平上與學習成績相關的學習行為序列有15個,并且高績效組的這些行為序列的頻次明顯高于低績效組。卡方檢驗的結果表明高低績效組在學習行為和學習行為序列上存在著顯著差異。高績效組學生的主動性比較強,小組每位成員能夠很好地參與到協作學習中。高績效組的學生個體先進行新知識的內化,隨著任務的推進,每位成員能夠更深程度地理解知識,在協作學習的過程中較多的協作交互和信息評價行為能夠觸發學習者的高階認知。相關研究表明,高績效組在學習過程中對信息的有效處理以及表現出的綜合認知思維模式更有助于其取得學業上的成功。因此,在協作學習過程中,教師要及時干預,在教學設計和教學課件制作上針對性地提供幫助,從而促進學生高階思維的發展。
六、結論和展望
(一)數據驅動的在線學習分析方法
相較以往研究關注可被觀測的、反映學生學習投入的行為數據相比,聯合LDA和HMM對會話行為建模具有一定的代表性,為分析學習者的內隱學習行為提供了一個新的視角,它能更加細致反映學習者的學習狀態,更深層次發現學生的學習規律,促進個性化教學的實現。結合自然語言處理技術和協作學習理論實現對學習者內隱學習狀態的自動分析和評估,有助于大規模在線學習行為的分析,并提供適應性支持服務。
(二)幫助學習者進行監控與調節,促進高階思維發展
學習活動具有復雜性,自我調節和共享調節是協作學習成功的關鍵。高績效組的學生在會話行為轉變過程中具有漸進性,在學習過程中能夠適應性地進行自我監控與相互調節。教師在教學活動中可以制定針對性的教學干預策略幫助低績效組學生實現監控與調節。例如,教師可以引導學生觀察和模仿更強的小組來提高自身成績。
在線協作學習中的言語活動能夠促進學習者的高階思維,進而幫助學習者獲取高階知識并進行深度學習。教師為學生提供問題引導,鼓勵學生在小組討論時從多視角出發對問題進行互動分析,在沖突解釋中實現對知識的建構與協商,培養學習者的高階思維。此外,積極關注課程材料的學生會有更多的學習收益,學習效率更高。因此要注重學習者的信息查閱行為,引導小組在協作交互過程中進行問題解決和信息評價。成績高的學生在課程中具有主動性,成績低的學生學習過程中表現不夠積極,且對課程內容的關注不夠,教師可以適當給予一定的壓力以提高其認知深度。
(三)不足與展望
本研究也存在著一些不足。首先,在進行LDA主題建模時,一些雖具有代表意義但頻率很小的詞匯及詞匯之間的語義關聯被忽略。其次,采用的SPOC論壇功能有限,不能獲得學生學習每個部分知識的時間,比如觀看視頻的次數和時間,以及學生在更細微層次上的操作。最后,我們只考慮了“信息技術教學應用”這一門課程討論的數據,研究結果的一般化受到限制。未來研究將從時間維度,即在課程學習的不同階段分析學習者的行為轉移情況,同時結合多模態數據,例如結合文本數據與語音數據,實現對會話行為的更全面、準確的理解。
[參考文獻]
[1] 左明章,趙蓉,王志鋒,李香勇,徐燕麗. 基于論壇文本的互動話語分析模式構建與實踐[J]. 電化教育研究,2018,39(9):51-58.
[2] MESSICK S. The nature of cognitive styles: problems and promise in educational practice[J].Educational psychologist,1984,19(2):59-74.
[3] 何皓怡,劉清堂,吳林靜,鄧偉,郝怡雪.教師工作坊中學員話題挖掘方法及應用[J].中國電化教育,2018(10):79-86.
[4] 劉智,張文靜,孫建文,劉三女牙,彭晛,張浩. 云課堂論壇中的學習者互動話語行為分析研究[J].電化教育研究,2016(9):95-102.
[5] HUANG J, PENG M, WANG H, et al. A probabilistic method for emerging topic tracking in microblog stream[J]. World wide web-internet & web information systems,2017,20(2):325-350.
