基于SRNN+Attention+CNN的雷達輻射源信號識別方法
2021-11-29 05:51:16高詩飏董會旭田潤瀾張歆東
系統工程與電子技術 2021年12期
高詩飏, 董會旭, 田潤瀾, 張歆東,*
(1. 吉林大學電子科學與工程學院, 吉林 長春 130012;2. 空軍航空大學航空作戰勤務學院, 吉林 長春 130022)
0 引 言
雷達輻射源識別[1]是通過分析處理截獲的對方雷達信號,獲取對方雷達的工作參數和信號特征參數,通過與已知雷達數據庫對比,判斷雷達的型號、工作模式、位置,進而掌握其作戰平臺、工作狀態、威脅等級等信息,為戰場電磁態勢感知[2]、威脅告警[3]、作戰計劃制定等提供情報支持。隨著戰場電磁環境的日漸復雜,傳統的基于脈沖描述字(pulse description words, PDW)參數[4]的識別方法已經不能很好地滿足低信噪比條件下雷達輻射源信號識別的要求。而低截獲概率(low probability of intercept,LPI)雷達[5]的出現使雷達輻射源信號識別更加困難。因此,對雷達輻射源信號的準確識別,具有十分重要的現實意義。
雷達輻射源識別的關鍵是特征提取[6]。近年來,基于機器學習的雷達輻射源識別技術因其具有更強的泛化性和智能性受到研究學者的廣泛關注[7]。作為機器學習領域的一個重要研究分支,深度學習及其應用也是人工智能領域的研究熱點,在諸如機器翻譯[8]、問題回答[9]、圖像分類[10]、語音識別[11-12]、文本分類[13]等領域已經取得了很好的效果。深度學習與傳統模式識別方法最大的不同在于其能夠從數據中自動提取特征。通過逐層特征變換,將樣本在原空間的特征變換到一個新特征空間,用簡單模型即可完成復雜的分類任務,從而使分類或預測更容易。
國內外的許多學者將深度學習方法引入到雷達輻射源識別中,以期達到比傳統人工識別方法更好的識別效果。文獻[14]提出了一種基于卷積神經網絡(convolutional neural networks, CNN)和基于樹結構的機器學習過程優化識別方法,對二維時頻圖進行識別,在信噪比為-4 dB的條件下對12種信號的總體識別率達到94.42%。文獻[15]提出了一種混合分類器,包括CNN和埃爾曼神經網絡兩個相對獨立的子網絡,在信噪比為-2 dB的條件下,12種信號的總體識別率達到94.5%。文獻[16]提出利用深度卷積網絡遷移學習的識別方法,將信號轉化為時頻圖并進行預處理后,輸入到CNN預訓練模型中進行特征提取,最后用支持向量機分類器得到分類結果,在信噪比為-2 dB的條件下,對9類調制信號總體識別率可達97%。
上述方法主要的問題在于:第一,在低信噪比條件下,識別準確率不高,上述文獻的實驗結果多是在較高的信噪比下得出的,而在戰場電磁環境中,這樣的信噪比條件是很難達到的;第二,各類信號的識別準確率不平衡,特征不明顯、不容易識別的信號也是最有可能被對方采用、威脅最大的信號,這種不平衡可能會造成嚴重的后果。由此也限制了這些網絡的實際應用。
針對上述問題,本文提出了基于切片循環神經網絡(sliced recurrent neural networks, SRNN)、注意力機制和CNN的雷達輻射源信號識別方法。通過SRNN網絡提取雷達輻射源信號更高層次的信號特征,將輸入的幅度序列轉化成一個固定長度的向量,產生的特征向量經過Attention層處理后輸入到CNN網絡中,將特征向量轉化成分類結果輸出。在CNN中引入批歸一化(batch normalization,BN)層,進一步提升網絡的識別能力。
1 相關技術
1.1 SRNN
循環神經網絡(recurrent neural networks, RNN)[17-18]是一類專門用于處理序列數據的神經網絡。RNN中引入了循環結構,可以利用上下文信息,但是每一個狀態都依賴前一狀態的輸入,這種串行結構訓練需要花費大量的時間,這就限制了RNN的應用。
2018年,Yu等人提出了SRNN算法[19]。將輸入的雷達輻射源幅度序列分割成幾個具有相同長度的最小子序列并在每一個子序列上應用循環單元同時工作,信息通過多個網絡層進行傳遞。將長度為T的序列劃分成n個等長的子序列,重復劃分操作K次,直到最底層的最小子序列長度合適為止。將每個子序列的輸出合并為一個新的序列作為下一層的輸入,即:
(1)
(2)

(3)
網絡結構如圖1所示。以一個1 024輸入的SRNN計算模型為例,共劃分2次,每次劃分為8個子序列,則最小子序列長度為16。

圖1 SRNN網絡結構Fig.1 SRNN network structure
相較于標準RNN結構,SRNN在訓練時間上具有優勢。設每個循環單元花費的時間為r,對于標準RNN結構,訓練所需時間為
tRNN=Tr
(4)
對于k+1層的SRNN網絡,訓練時間為
(5)
比較SRNN與RNN的訓練時間:
(6)
序列長度T通常為定值。理論上,只要調整劃分的份數n和劃分的次數k,就可以調整SRNN相對于RNN的訓練速度優勢的大小。
1.2 注意力機制
注意力機制[20-22]最早應用于視覺圖像領域,來源于人類的視覺注意力。通常人類視覺在感知物體時,會將更多的注意力聚焦到當前任務目標更關鍵的部分,從眾多信息中選擇出對當前任務目標更關鍵的信息。注意力機制本質上是一種權重概率分布機制,對重要的內容分配更大的權重,對其他內容減少權重。這樣的機制更專注于找到輸入數據中與當前輸出顯著相關的有用信息,發掘信號中的自相關性,突出與預測相關的部分特征,從而提高輸出的質量,使得訓練更為高效。工作原理[23]如圖2所示。

圖2 注意力機制工作原理Fig.2 Working principle of attention mechanism
注意力狀態轉換的實現如下所示:
(7)
(8)
(9)
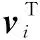
注意力機制的實現如圖3所示。
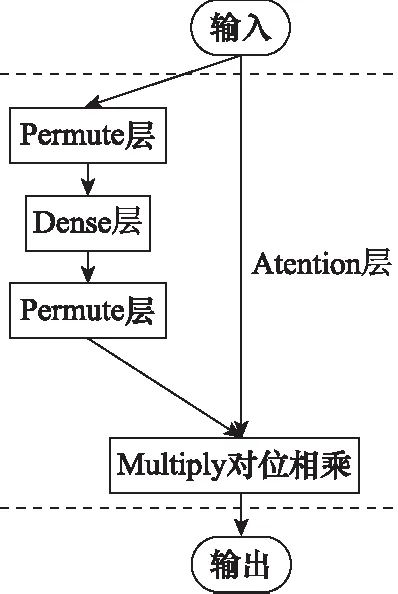
圖3 Attention層結構Fig.3 Attention layer structure
1.3 BN
在訓練時某一層的參數更新后,會導致該層網絡的輸出分布改變,使訓練變得復雜。使用較小的學習率及較好的權重初值,會導致訓練很慢,同時也導致使用飽和非線性激活函數時訓練很困難。
BN層[24]是一種特殊的歸一化層,由Ioffe等人于2015年提出,其目的是對神經網絡中間層的輸出進行標準化處理,使得中間層的輸出更加穩定[24]。其出現解決了在訓練過程中,中間層數據分布發生改變的問題。BN層的作用主要有3點[25]:① 加快網絡訓練和收斂的速度;② 防止梯度爆炸和梯度消失;③ 防止過擬合。BN層可以使優化環境更加平滑[26]。這種平滑性會導致漸變的預測性和穩定性更好,從而可以更快地進行訓練。BN過程如下:
(10)
(11)
對于在神經網絡中應如何使用BN層這一問題,一些學者也進行了研究。文獻[24]認為BN層應該放在卷積層之后非線性激活層之前。而在目前的實踐中,更傾向于把BN層放在激活函數層后面。文獻[27]中對卷積層、BN層和激活函數層組成的3種網絡方式進行了分析對比,得出結論:在復雜數據集和深度網絡上卷積+BN+激活函數的組成表現更好,這樣的組合使輸入數據的范圍更契合激活函數的定義域。在本身網絡比較簡單的情況下,BN+卷積+激活函數的結構能夠更好地加速網絡收斂,把輸入映射到正態分布,加快當前層卷積網絡的收斂。而卷積+激活函數+BN的組合方式將上一層的輸出歸一化,能夠加快下一層的卷積的收斂。在不同的應用場景下,需要具體實驗確定。
1.4 CNN
CNN[28-30]是一種深度學習模型,具備良好的表征學習能力,能自主學習雷達輻射源信號的特征,實現低級特征到高級特征的抽象提取。
傳統的CNN模型由卷積、池化和全連接層構成。假設輸入為x,卷積核為w,偏置為b,則卷積算子可以表示為
h=f(w*x+b)
(12)
式中:*代表卷積運算;f(·)表示卷積層的激活函數。
在CNN中,對卷積操作得到的局部特征采用池化方法提取的特征代替整個局部特征,可以大幅降低特征向量的大小。池化主要分為兩種:平均池化和最大池化。
經過多個卷積-池化層提取雷達輻射源信號特征后,通過全連接層進行分類:
Output=softmax(W*X+b)
(13)
式中:W表示全連接層的權重;b為全連接層的偏置;softmax(·)為全連接層的激活函數,輸出的每一個值都在[0,1]區間內,且和為1。這就將多分類的輸出數值轉化為概率,更容易理解和比較。
2 模型結構及訓練流程
2.1 模型結構
模型結構如圖4所示。

圖4 模型結構Fig.4 Model structure
本文采用的模型主要由SRNN層、注意力層、3個相同的BN-卷積-池化層和Dense層組成。參數如表1所示,除表中提及的參數外,其他參數均為默認值。
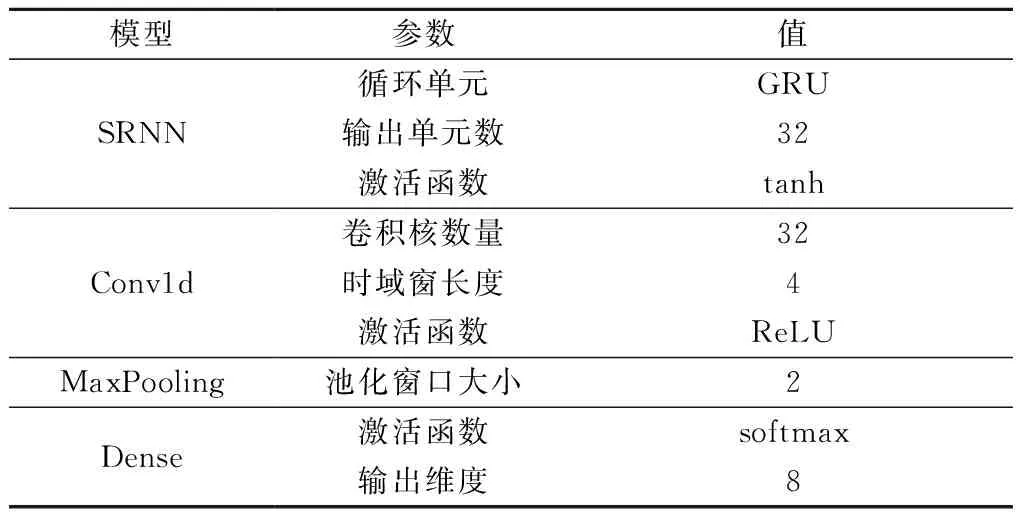
表1 模型參數
2.2 訓練流程
模型訓練流程如下。
步驟1數據預處理。對讀入的雷達輻射源信號數據進行Min-Max歸一化處理。歸一化處理后數據的值在[0,1]內,特征向量中不同特征取值的差相對減小,降低了奇異樣本數據導致的不良影響,可以加快梯度下降求最優解的速度。Min-Max轉換函數如下:
(14)
步驟2建立訓練集、驗證集和測試集。將數據和標簽對應隨機打亂,按照60%、20%、20%的比例劃分訓練集、驗證集和測試集。
步驟3對所有數據的標簽進行one-hot編碼[31]:one-hot編碼針對離散型特征,將屬性值轉化為二元特征,在任意時刻只有其中一位有效。
步驟4對輸入數據進行切割分片,滿足SRNN對輸入數據的維度要求。
步驟5設置優化器、損失函數、早停和學習率衰減。優化器采用AdamOptimizer;采用交叉熵損失函數;為了避免過擬合的發生以防止網絡的泛化能力降低,引入早停機制,以驗證集損失作為標準,在驗證集損失連續10輪不減小時停止訓練;引入學習率衰減,當驗證集損失連續3輪不減小時,學習率下降為原來的10%。
步驟6訓練網絡。將訓練集數據輸入到網絡模型中訓練。設置初始學習率為 0.001,最大訓練輪數為200輪,batch_size大小為200。
3 實驗及結果分析
為了驗證第2.1節構建的模型的性能,設計實驗如下。首先,探究第1.1節SRNN相對于GRU的速度優勢,并確定基本模型。其次,探究第1.2節注意力機制在網絡中的效果。然后,探究第1.3節BN層對訓練時間和識別準確率的影響,確定模型。最后,在前3個實驗的基礎上,對照經典網絡模型,對第2.1節所構建的模型進行評價。實驗環境如表2所示。

表2 實驗環境
為了驗證模型的性能,本次實驗采用Matlab仿真的時域下雷達脈沖幅度序列數據得到的原始數據集,包括二進制相移鍵控(binary phase shift keying, BPSK)、科斯塔斯碼(Costas)、調頻連續波(frequency-modulated continuous wave, FMCW)、弗蘭克碼(Frank)、P相碼(P1、P2、P3和P4)共8種信號,其中弗蘭克碼與P相碼統稱為多相碼。信號信噪比范圍-20~10 dB,步進2 dB;每種信號每種信噪比產生2 000個樣本,每個樣本長度為1 024。信號參數如表3所示。
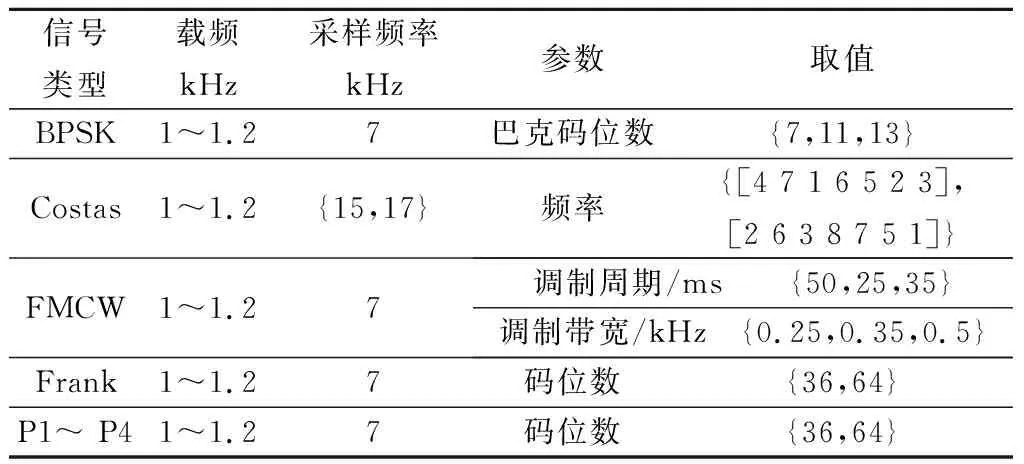
表3 仿真信號參數
實驗 1驗證第1.1節提出的SRNN相較于GRU的速度優勢,并確定基本模型。通過比較測試集損失和識別準確率、訓練輪數、訓練總時間以及測試集測試的運行時間來衡量網絡的訓練效果。實驗結果取多次實驗的平均值,如表4所示。
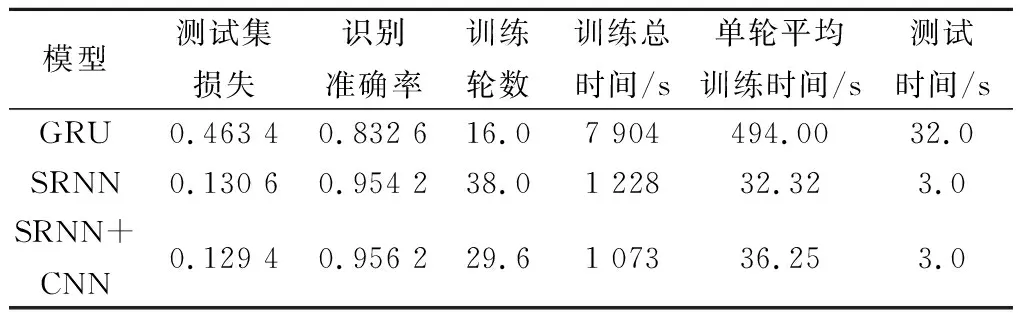
表4 實驗結果
從SRNN與GRU的比較中可以看出,無論是從訓練總時間還是單輪平均訓練時間,SRNN均優于GRU,單輪平均訓練時間僅為GRU的6.54%,證明了并行化結構的SRNN能夠大大加快訓練速度,解決訓練時間過長的問題。進一步,在SRNN的基礎上,與CNN結合,雖然單輪平均訓練時間上相比SRNN有略微提升,但訓練輪數有明顯減少,網絡收斂速度加快,訓練總時間下降,識別準確率也略有提升。從測試時間上來看,與CNN結合并沒有過多的增加模型的復雜程度,對測試集的測試時間幾乎沒有影響。因此,將SRNN+CNN確定為基本模型。
實驗 2在實驗1中SRNN+CNN基本模型的基礎上探究注意力機制對訓練時間和識別準確率的影響。
為了探究注意力機制對網絡性能的影響,實驗將是否使用Attention層作為自變量,分別訓練網絡模型。通過比較測試集損失和識別準確率、訓練輪數、訓練總時間以及測試集測試時間來衡量網絡的訓練效果。實驗結果取多次實驗的平均值,如表5所示。
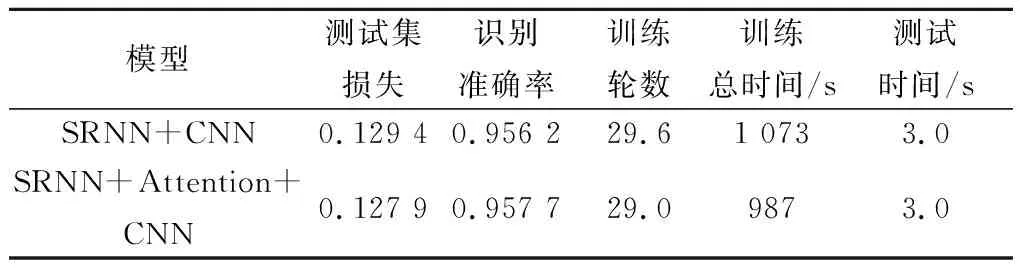
表5 Attention層對網絡識別的影響
由表5可以看出,注意力機制能夠在一定程度上降低損失,提高識別準確率,加快訓練速度,訓練時間相比不使用Attention層的網絡減少了9%。Attention層將注意力更多地分配到需要關注的特征上,在一定程度上加快網絡訓練,提升網絡的識別準確率。
為了觀察Attention層關注了哪些特征,使得訓練時間減少和準確率提高,設計實驗探究Attention層的輸入與輸出特征向量的變化。實驗步驟如下。
步驟 1在數據集中任取1個長度為1 024的信號,輸入保存的模型中,獲得Attention層的輸入特征向量Feature1和輸出特征向量Feature2。
步驟 2將Feature1和Feature2按統一的標準進行Min-Max歸一化。取Feature1最小值與Feature2最小值中較小的作為歸一化的最小值;同理,取二者最大值中較大的作為歸一化的最大值。
步驟 3取歸一化后Feature2與Feature1的差值FeatureDIF。
實驗算法偽代碼如下所示。

算法1中,FeatureDIF的正負代表Attention層對某一特征賦予更多或更少的關注,分配更大或更小的權重。
在FeatureDIF中截取長度為100的樣本可視化輸出,將結果繪制成火柴圖,如圖5所示。

圖5 可視化輸出結果Fig.5 Visual output
從圖5可以明顯的看出經過Attention層后特征的變化。Attention層對6/17/49/55/70/81等圖中值為負的位置的特征分配了更少的注意力甚至不分配注意力;對39/53/85/96等圖中值為正的位置特征分配更多的注意力,說明這些特征是對訓練網絡更重要的。
實驗 3在實驗2的基礎上,探究BN層對訓練時間和識別準確率的影響。
為了探究BN層對網絡性能的影響,在實驗2中SRNN+Attention+CNN模型的基礎上,將是否在CNN中使用BN層以及BN層與卷積層和池化層的相對位置作為自變量,分別訓練網絡模型。通過比較測試集損失、識別準確率、訓練輪數、訓練總時間以及測試集測試時間來衡量訓練效果,進而確定BN層在模型中的位置。實驗結果取多次實驗的平均值,如表6所示,表中Conv表示卷積層,AF(activation function)表示激活函數。
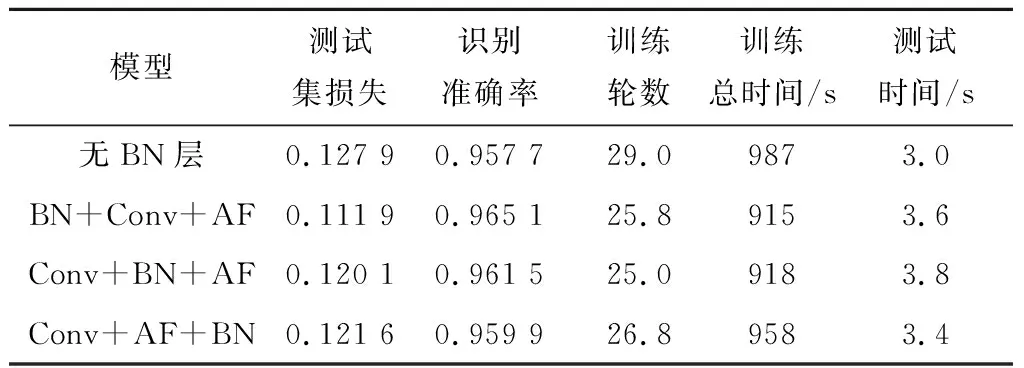
表6 探究BN層對網絡識別的影響
從訓練輪數與訓練總時間可以看出,對于SRNN+Attention+CNN模型來說,BN層的使用使訓練輪數明顯減少,訓練總時間減少,最多減少近8%,收斂速度加快。從測試集的測試時間上看,使用BN層會使測試集測試時間略微增加。
Conv+AF+BN的組合方式將上一層的輸出歸一化,第一層卷積輸入并沒有被歸一化,因而相對于其他兩種組合方式訓練時間更長,理論上這種差異在卷積層數較少的網絡中尤為明顯。綜合衡量測試集損失、識別準確率以及訓練時間等方面,BN+Conv+AF的組合方式更有優勢,損失低,識別準確率更高且訓練時間和測試時間與Conv+BN+AF組合基本持平,因而本文選定這種組合方式作為最終方案。
實驗 4在實驗3選定的BN+Conv+AF的組合方式的基礎上,首先探究SRNN+Attention+CNN模型在不同信噪比條件下對8種信號的識別情況。利用訓練保存的模型對8種信號識別,在不同信噪比下識別準確率結果如圖6所示。從圖6中可以看出,信噪比大于等于-10 dB情況下基本可以達到100%的準確率;在-20 dB時全部信號的識別準確率均大于60%,BPSK和FMCW準確率超過70%,其他5種多相碼信號準確率超過85%。

圖6 SRNN+Attention+CNN模型在不同信噪比條件下對8種信號的識別準確率Fig.6 Recognition accuracy of SRNN+attention+CNN modelfor 8 kinds of signals under different SNR
8類信號的混淆矩陣如圖7所示。

圖7 SRNN+Attention+CNN模型混淆矩陣Fig.7 Confusion matrix of SRNN+Attention+CNN model
圖7中,主對角線上代表信號被正確識別,同一行的其他格子代表被錯誤識別成其他7類信號對應某一類。格子顏色越深,代表相應的概率越高。可以看出,對角線上的顏色最深,證明大多數信號都能夠被正確識別。BPSK與Costas、Costas與FMCW(圖中紅框)相互識別錯誤率相對比較高,結合圖6可以說明,在低信噪比下以上兩組信號比較接近難以區分。SRNN+Attention+CNN模型對Frank、P1~P4碼5種多相碼有較好的識別準確率,且相互之間錯誤識別的概率也普遍較小,證明模型對多相碼的特征提取效果是比較好的。
在上述實驗的基礎上,進一步將SRNN+Attention+CNN模型與經典模型比較。通過比較測試集損失、識別準確率、訓練輪數、訓練總時間以及測試集測試時間來衡量網絡的訓練效果。實驗結果取多次實驗的平均值,如表7所示。

表7 SRNN+Attention+CNN模型與經典模型比較
從表7的實驗結果中可以看出,SRNN+Attention+CNN模型相比于GRU,在訓練速度方面有著明顯的優勢,在測試集損失以及識別準確率方面也有較大的優勢。相比其他經典模型在識別準確率方面有一定的優勢,在訓練時間方面僅比AlexNet差,與VGG16持平,比VGG19和ResNet18更好。在測試時間方面, SRNN+Attention+CNN模型與AlexNet接近,與其他經典模型相比有很大的優勢。
在表7實驗結果的基礎上,進一步探究6種模型在不同信噪比條件下的表現。用不同信噪比的8種信號對6種模型進行測試。測試結果如圖8所示。

圖8 6種模型在不同信噪比條件下的識別準確率Fig.8 Recognition accuracy of six models under different SNR
由圖8可以看出,SRNN+Attention+CNN模型在低信噪比的條件下的表現相對于其他5種經典模型要更好,在-12 dB條件下識別準確率接近100%,在-20 dB條件下依然達到近80%,證明了SRNN+Attention+CNN模型在低信噪比的條件下有著較好的識別能力。
4 結 論
本文將SRNN模型引入雷達輻射源信號識別領域,提出了SRNN+Attention+CNN模型,對8種常見的雷達輻射源信號進行識別,并與其他5種經典模型進行比較。實驗結果表明,本文提出的模型在低信噪比條件下能夠對8種常見信號有效識別,相比于GRU模型在訓練速度和識別準確率方面有較大的提升,相比于其他4種經典模型也有一定的優勢。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
鴨綠江(2021年35期)2021-04-19 12:24:18
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
電子制作(2018年11期)2018-08-04 03:25:42
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
