δ-廣義標簽多伯努利濾波算法的非線性擴展
2021-11-29 05:51:44齊美彬胡晶晶程佩琳靳學明
系統工程與電子技術 2021年12期
齊美彬, 胡晶晶,*, 程佩琳, 靳學明
(1. 合肥工業大學計算機與信息學院, 安徽 合肥 230009; 2. 中國電子科技集團第38研究所, 安徽 合肥 230088)
0 引 言
多目標跟蹤的任務是利用傳感器提供的量測數據聯合估計目標數量及其狀態,而這些量測數據通常受到雜波(噪聲)、漏檢、虛警等因素的影響,為多目標跟蹤的實現帶來巨大挑戰。目前實現多目標跟蹤的方法主要分為:聯合概率數據關聯(joint probabilistic data association,JPDA)[1-3]、多假設跟蹤(multiple hypothesis tracking,MHT)[4-6]和隨機有限集(random finite set,RFS)[7]。其中RFS方法可以避免執行傳統多目標跟蹤方法所需的數據關聯,成為當前解決多目標跟蹤問題的研究熱點。其核心是貝葉斯多目標濾波器,采用預測和更新循環迭代計算目標的真實狀態,其三大近似算法分別是概率假設密度(probability hypothesis density,PHD)、勢PHD(cardinalized PHD,CPHD)和多目標多伯努利(multi-target multi-Bernoulli,MeMBer)濾波器。然而都不能嚴格地稱為多目標濾波器,因為其得到的目標是無標簽的,仍不可區分。文獻[8-11]引入標簽隨機有限集的概念解決目標軌跡及唯一性的問題,提出廣義標簽多伯努利(generalized labeled multi-Bernoulli,GLMB)濾波器及其快速實現(δ-GLMB),并得到廣泛應用[12-14]。
隨后很多研究學者提出δ-GLMB濾波器的改進算法。這些改進的多目標跟蹤方法假設量測噪聲協方差先驗信息是已知的,但是在很多場景中量測噪聲協方差是未知且時刻變化的。針對這個問題,研究者引入了變分貝葉斯(variational Bayesian, VB)方法[15]。文獻[15]通過定義未知噪聲方差參數的共軛先驗分布,用VB近似方法分解固定形式分布和構造遞歸表達式來逼近線性高斯系統的狀態估計,解決未知量測噪聲協方差的問題。文獻[16-17]針對量測噪聲協方差未知的多目標跟蹤模型,提出了一種基于VB近似的自適應噪聲協方差PHD濾波。文獻[18]基于基數平衡多目標多伯努利濾波和VB逼近技術提出了一種VB近似的自適應噪聲協方差勢均衡MeMBer(cardinality balanced MeMBer,CBMeMBer)濾波。文獻[19]在δ-GLMB濾波框架中引入VB近似方法,所提自適應VB-δ-GLMB濾波算法針對未知量測噪聲場景下的多目標跟蹤具有很強魯棒性。
上述方法采用高斯混合方式實現,適用于線性運動模型的多目標跟蹤,在非線性場景下跟蹤性能較低。針對這個問題,本文提出一種適用于非線性模型的臨近點容積卡爾曼VB-δ-GLMB濾波算法(簡稱為PCKF-VB-δ-GLMB)。該算法以高斯實現的VB-δ-GLMB濾波器為基礎,將量測噪聲和目標狀態分布表示為逆伽馬和高斯乘積混合形式,結合基于臨近點算法和VB的迭代優化與容積卡爾曼濾波提出一種迭代優化容積卡爾曼方法(簡稱為PCKF-VB),并用該方法對高斯參量進行預測更新,最后為提高濾波精度進行變分貝葉斯容積RTS(VB cubature Rauch-Tung-Striebel)平滑。仿真結果表明本文算法能有效實現非線性系統下多目標跟蹤,其性能與現有VB-δ-GLMB跟蹤算法相比有明顯提高。
1 δ-GLMB濾波算法
1.1 VB近似的非線性濾波
對于量測噪聲協方差未知的非線性目標跟蹤系統,目標狀態方程和量測方程為
xk=f(xk-1)+wk-1
(1)
zk=h(xk)+vk
(2)
式中:xk和zk表示目標狀態和量測值;f(·)和h(·)表示狀態轉移和非線性量測函數;過程噪聲wk~N(0,Qk);量測噪聲vk~N(0,Rk)。假設目標狀態xk和量測噪聲協方差Rk模型相互獨立,則預測和更新后驗密度函數分別由Chapman-Kolmogorov方程和貝葉斯規則給出:

(3)
(4)
式中:Z1:k={z1,z2,…,zk},由于Rk未知,式(4)無法得到解析解,因此引入VB近似來逼近后驗密度函數[20],更新聯合后驗密度可以近似為
p(xk,Rk|Z1:k)≈Qx(xk)QR(Rk)
(5)
通過最小化近似后驗密度和真實后驗密度之間的KL(Kullback-Leibler)散度來確定近似后驗密度:

(6)
當假設目標狀態為高斯分布,噪聲協方差為逆伽馬分布[15]時,近似后驗密度為
Qx(xk)=N(xk;mk,Pk)
(7)
(8)

αk|k-1,i=ρiαk-1,i
(9)
βk|k-1,i=ρiβk-1,i
(10)
退化因子ρi∈(0,1],參數更新估計通過定點迭代法[20]獲得
(11)
(12)
式中:符號(·)i和(·)ii的含義是向量的第i個元素和矩陣的第i個對角元素;Hk為雅克比矩陣。量測噪聲協方差Rk的估計表示為
1.2 標簽隨機有限集與δ-GLMB
隨機有限集是元素和元素的個數均為隨機變量的集合,集合中元素的個數稱為集合的勢。標簽RFS在RFS的基礎上為集合中的每個元素x∈X都被分配了相應的標簽l∈L,即每個目標狀態用(x,l)表示,其中l=(k,i),索引i可以區分同一時刻不同目標。
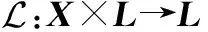
(13)
標準δ-GLMB多目標密度先驗分布有如下形式:
(14)

步驟 1預測
(15)
式中:
L+=L∪B

式中:B為新生標簽空間;f(x|·,l)為轉移密度函數;pB(x,l)為新生目標的狀態空間密度函數;pS(·,l)為目標存活概率。
步驟 2更新
(16)
式中:

式中:Z為量測集合;θ表示目標軌跡到量測的映射關系:L→Z,所有映射關系的集合Θ稱為關聯映射空間;pD(x,l)為檢測概率,g(z|x,l)為量測似然函數;κ表示量測生成過程中的雜波密度。
2 PCKF-VB-δ-GLMB濾波算法
為解決未知量測噪聲協方差的問題,高斯混合實現的VB-δ-GLMB算法提出用VB近似迭代估計量測噪聲協方差和多目標狀態聯合后驗密度。但是該算法僅適用于線性模型的多目標跟蹤場景,在非線性場景下跟蹤性能較低,因此可以將高斯混合實現的VB-δ-GLMB算法與非線性濾波器結合來實現非線性模型下多目標跟蹤。
2.1 PCKF變分近似
用VB方法處理非線性濾波問題[21]時,可以將后驗概率密度p(xk|zk)用一個易于計算的概率密度q(xk|θk)來近似。二者間差異可以用KL散度來度量,KL散度越小表示越接近,KL散度表示為
(17)
式中:q(xk|θk)為假設的高斯分布,其參數θk=(xk|k,Pk|k)。L(θk)為變分證據下界(evidence lower bound, ELBO):
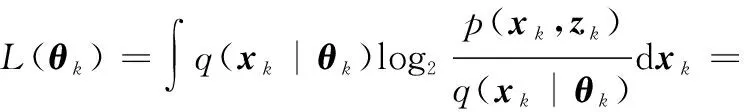
(18)


(19)


(20)

(21)
(22)

在過程噪聲和量測噪聲為高斯假設時,維數同為d的變分分布q(xk|θk)~N(xk|xk|k,Pk|k)和p(xk)~N(xk|xk|k-1,Pk|k-1),因此式(18)展開為
(23)

(24)
(25)
本文將基于臨近點算法和VB的迭代優化與容積卡爾曼濾波(cubature Kalman filtering, CKF)結合,提出變分逼近的PCKF算法。該算法在傳統CKF[25]的更新步驟中結合臨近點算法與VB近似進行迭代優化,具體步驟如下。
步驟 1輸入初始狀態x0和初始協方差矩陣P0。
步驟 2時間更新
(26)

(27)
(28)
量測噪聲動態模型參數預測值由式(9)和式(10)得出。
步驟 3量測更新
(29)

(30)
(31)
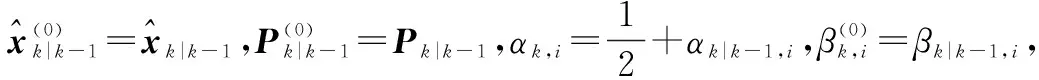
(32)
(33)
(34)
(35)
(36)
(37)


因此為解決非線性場景下多目標跟蹤問題,可以將非線性濾波方法PCKF-VB與VB-δ-GLMB結合,形成PCKF-VB-δ-GLMB多目標跟蹤算法。
2.2 PCKF-VB-δ-GLMB的高斯實現
針對非線性高斯多目標模型預測與更新步驟中帶有有限集積分運算而無法求得解析解的問題[26],PCKF-VB-δ-GLMB濾波算法用多個高斯項加權求和的方式,代替傳遞的伯努利參數來獲得閉合解。新生目標為標簽多伯努利模型,概率密度函數如下所示:
(38)
式中:J(ξ)為高斯項個數。則基于PCKF-VB-δ-GLMB濾波算法的高斯混合(Gaussian mixture,GM)[27]實現具體步驟如下。
步驟 1預測
假設多目標密度函數π(X)如式(14)形式,其中用高斯和逆伽馬積混合形式表示單目標密度p(ξ),表示如下:
(39)
則預測多目標密度π+(X)如式(15)形式,其中預測單目標密度函數為
(40)

步驟 2更新
假設多目標預測密度π+(X)如式(15)形式,其中單目標密度函數為
綜上所述,分析英美文學在英語教學的重要性是非常必要的。世界間的交際來往愈來愈多,英語也越發重要,而將英美文學引入課堂中可以有效地促進學生的英語學習效率,使其能接觸到最地道的英語,還能體會到當時當地的風俗文化。英語教學模式應如何引入文學教學有待進一步的探討。希望本文能為當前的相關研究起到借鑒作用。
(41)
量測為Z,則多目標更新密度如式(16)所示,其中單目標密度函數為
(42)

步驟 3修剪和截斷
對于預測更新步驟得到的高斯-逆伽馬分量,設置剪枝閾值;修剪權重低于指定剪枝閾值的分量,并將高斯總個數控制在最大限度內。
步驟 4目標個數及目標狀態估計
目標個數從勢分布中由最大后驗估計方法得出;通過最佳基數提取狀態估計,從具有與映射基數估計相同基數的所有分量中選取最高權重分量,提取其標簽和均值。
2.3 VB-CRTS平滑
為了改善濾波效果,可通過平滑對狀態向量做進一步處理,以此提高精度。CRTS平滑算法基于三階球面-徑向容積規則,是高斯平滑范疇內的一種平滑算法[28-29],由前向濾波和逆向平滑兩部分組成。對于一般的CRTS平滑算法,量測噪聲協方差為常數,不適應實際情況。對于上述非線性模型,結合CRTS平滑算法和VB估計方法,采用VB-CRTS平滑算法實現量測噪聲協方差的自適應估計。式(21)和式(22)、式(26)~式(37)組成VB-CRTS前向濾波過程,逆向平滑過程算法如下。
(43)
(2) 平滑增益:
Gk=Dk(Pk|k-1)-1
(44)
(3) 平滑后均值與協方差:
(45)
(46)
3 仿真分析
為更好地仿真機動目標運動狀態,本實驗采用勻速直線(constant velocity,CV)運動模型和協同轉彎(cooperative turning,CT)運動模型來對目標進行建模。在該場景下,我們采用VB-δ-GLMB、本文提出的PCKF-VB-δ-GLMB及其二者分別通過VB-CRTS平滑得到的4種濾波器來實現多目標跟蹤,并綜合比較性能。
3.1 實驗場景設置


表1 不同目標初始狀態及起始結束時刻
仿真中目標的運動方程如式(1)和式(2)所示,其中:

3.2 仿真結果與分析
仿真共設置10個目標,目標真實運動軌跡和估計軌跡如圖1所示,○和△分別表示起始位置和結束位置,x軸和y軸分別為二維平面內的水平位置和豎直位置。圖1中黑色軌跡為機動目標真實運動軌跡,從圖中可以看出目標軌跡出現交叉,目標量測混合會導致難以區分。本文算法對機動目標的跟蹤效果如圖1中紅色軌跡所示,圖中目標估計軌跡與目標真實運動軌跡幾乎重合,因此本文提出濾波器的能準確地實現多目標運動軌跡的估計。
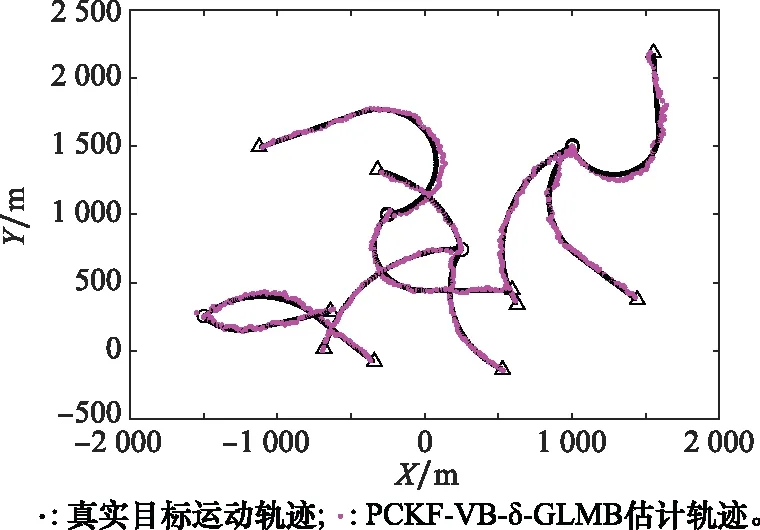
圖1 真實運動軌跡與估計軌跡Fig.1 Target tracks and estimated tracks
圖2表示上述4種濾波算法的單次勢估計與平均勢估計。圖2(a)為隨機抽取的單次蒙特卡羅實驗的勢估計,從圖中可以看出本文提出算法估計的目標數目更加接近實際目標數目。單次實驗計算量小,減少目標跟蹤的時間,但是不能消除數據隨機性。圖2(b)為100次蒙特卡羅實驗的平均勢估計。
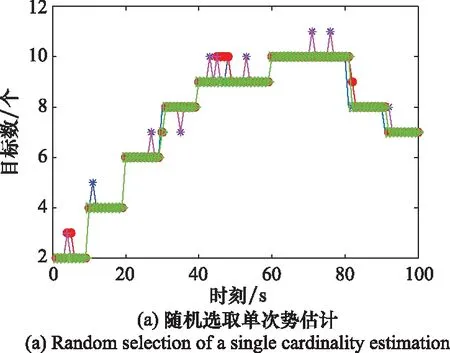
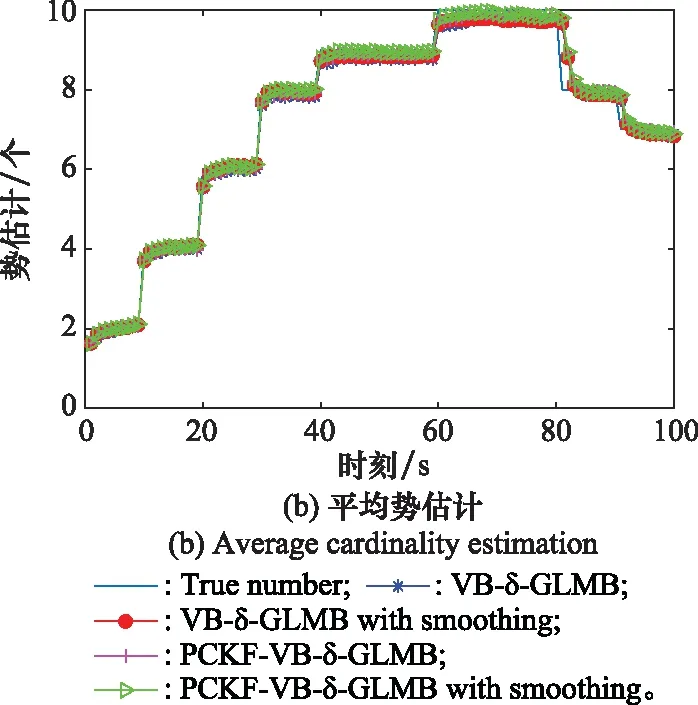
圖2 勢估計Fig.2 Cardinality estimation
本實驗采用最優子模式分配(optimal subpattern assignment,OSPA)距離[30]作為評價算法性能的準則指標。OSPA距離綜合考慮目標數目估計和目標位置估計,其值越大表明算法的綜合精度越差,維數分別為m、n的集合X和Y之間的OSPA距離定義為

(47)
實驗中設置距離敏感參數p=2,水平調節參數c=100。圖3為4種濾波算法對多目標估計的OSPA距離(見圖3(a))和OSPA勢估計分量(見圖3(b))。觀察圖3(a)和圖3(b)可以看出k=0,10,20時刻OSPA距離和OSPA勢估計出現峰值,這是由于目標新生時刻存在概率低,算法不能立刻跟蹤到目標;k=80,90時刻OSPA距離和OSPA勢估計較大,這是因為目標數目發生變化的時刻算法反應速度延遲時間較長。
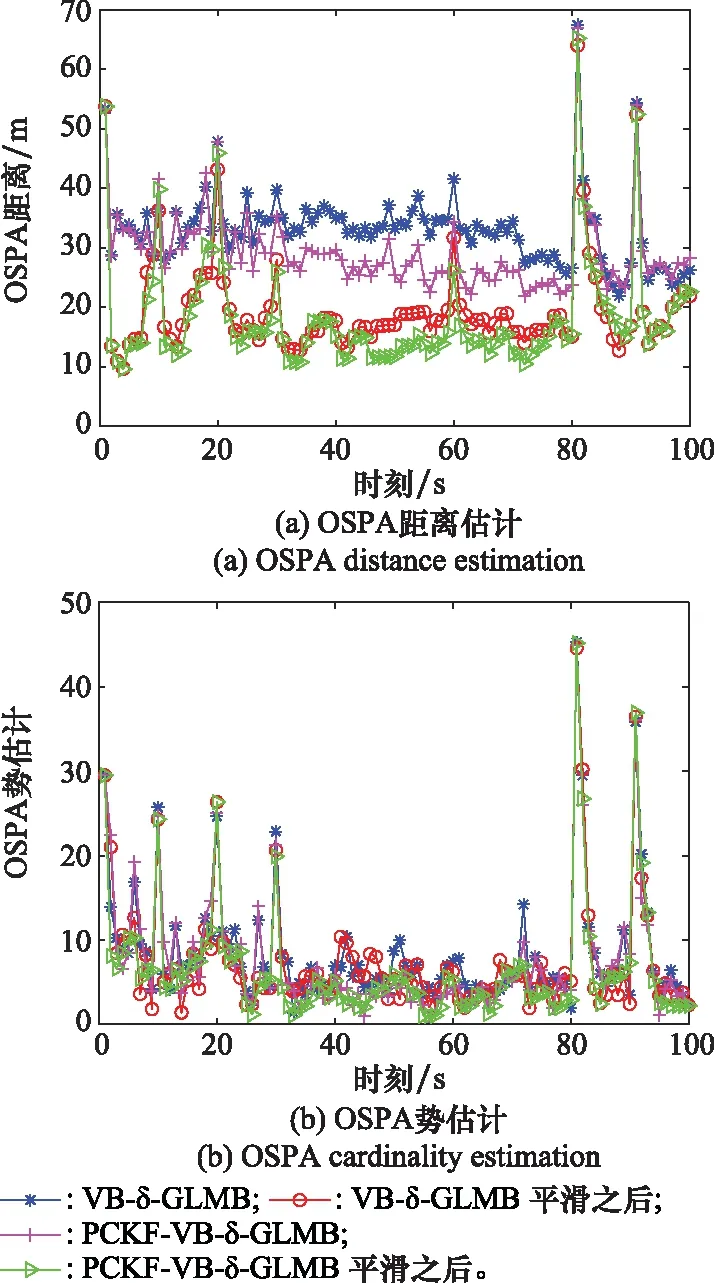
圖3 OSPA距離與OSPA勢估計Fig.3 OSPA distance and cardinality estimation
為減少數據隨機性,本文進行100次蒙特卡羅仿真實驗,4種濾波器OSPA距離和OSPA勢估計如表2所示(重復5組實驗取均值,結果保留4位有效數字)。從表2中數據可以看出,對比現有的VB-δ-GLMB算法,本文提出的PCKF-VB-δ-GLMB算法在OSPA距離和OSPA勢估計上都有顯著改進。其中OSPA距離減少了13.59%,OSPA勢估計減少了12.34%,驗證了本文提出算法采用PCKF-VB進行預測更新,可以更好地適應非線性多目標跟蹤場景。此外,加入VB-CRTS平滑之后,VB-δ-GLMB算法在OSPA距離和OSPA勢估計上分別減少了40.96%和12.97%,PCKF-VB-δ-GLMB算法在OSPA距離和OSPA勢估計上分別減少了38.74%和16.18%。仿真結果表明VB-CRTS平滑對不同濾波算法均帶來了顯著改進。

表2 100次仿真的平均性能
為進一步驗證本文提出算法的有效性,在不同雜波數條件下進行100次蒙特卡羅實驗,綜合比較4種濾波算法的OSPA距離和OSPA勢估計。分析圖4可以得到以下結論:首先,隨著雜波數增多,上述4種濾波算法的OSPA距離和OSPA勢估計都隨之增大,目標跟蹤性能降低;其次,在相同的雜波密度條件下,本文所提算法的OSPA距離和OSPA勢估計均小于現有的VB-δ-GLMB算法。

4 結 論
針對高斯實現的VB-δ-GLMB算法在非線性場景下跟蹤性能較低的問題,本文提出一種適用于非線性系統的PCKF-VB-δ-GLMB濾波算法。該算法將聯合后驗分布表示為高斯-逆伽馬混合分布,利用PCKF-VB方法對VB-δ-GLMB濾波算法中的高斯參量進行預測更新,最后進行VB-CRTS平滑。仿真結果表明對量測噪聲未知的非線性系統,該算法能準確估計目標運動狀態與軌跡,多目標跟蹤精度得到顯著提高。
