一種高效率可重構的CPU驗證平臺
2021-12-02 11:09:08劉春銳張宏奎黃旭東陳振嬌
電子與封裝 2021年11期
劉春銳,張宏奎,黃旭東,陳振嬌
(中科芯集成電路有限公司,江蘇無錫214072)
1 引言
隨著大規模集成電路技術的不斷發展,數字集成電路的規模不斷增大,功能不斷增強,這給完備性驗證帶來了更大的挑戰[1]。在CPU芯片的設計中,高效和完備的功能驗證已成為CPU可靠性的重要依據[2],為了全面驗證CPU的功能,驗證工程師通常需要編寫成千上萬條驗證用例[3],并且需要逐一運行測試并分析結果。據統計,驗證時間通常占到處理器芯片研發流程的60%以上[4]。如果完全采用人工的方法分析和查錯,驗證效率極低,正確性難以保證,驗證周期長且驗證完成時間無法預估。因此,一個快速、完備、系統的功能驗證平臺對于CPU的設計來說至關重要,可有效縮短芯片設計周期并提高設計質量[5]。除此之外,由于CPU指令多,指令組合場景多,驗證用例非常龐大,除了驗證平臺外,通過編寫自動化腳本,批量構建用例和統計驗證結果,對提高整個驗證效率也是至關重要的[6]。本文提出了一種高效率可重構的CPU驗證平臺,可通過自動化腳本構建用例和統計結果,通過代碼覆蓋率標志驗證結束。
2 驗證平臺結構
高效率可重構的CPU驗證平臺采用了模塊化結構,具有更強的可重復使用性和可移植性,有效提高了驗證效率,縮短了芯片驗證周期[7]。不同指令集架構可以使用驗證平臺設計思路修改參考模型后即可重復使用。另外,該設計平臺提供了自動調試功能,自動比較CPU執行指令的結果值和參考模型執行指令的結果值,為分析、調試和定位錯誤提供了有效的手段,可以大大提高設計迭代效率。CPU驗證平臺由驗證用例生成模塊、匯編器模塊、CPU模塊、參考模型模塊、結果比較模塊、參考模型監視模塊、CPU監視模塊、程序RAM和數據RAM構成,該驗證平臺可以實現從驗證程序開發到驗證結果查錯的整個流程,其結構如圖1所示。
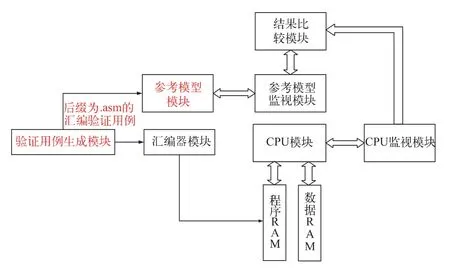
圖1 CPU驗證平臺結構
2.1 CPU模塊
CPU模塊是驗證平臺的驗證主體,本文的CPU為基于TI指令集架構的某CPU微處理器,該CPU微處理器的特性如下:
1)哈佛結構;
2)8級流水線結構;
3)單發射順序執行;
4)支持32 bit單精度浮點計算;
5)支持32 bit定點計算;
6)指令長度支持16 bit和32 bit兩種。
2.2 驗證用例生成模塊
一般CPU的流水線結構包括取指、譯碼、訪存、執行和寫回等階段,其中指令便是CPU的輸入源。為驗證CPU的功能,需要編寫指令并將其加載到CPU的程序RAM,然后啟動CPU,CPU讀取程序RAM中的指令并運行指令,最后根據CPU的指令執行結果驗證設計的正確性。
為完備驗證CPU的功能,在開發CPU的驗證用例前,需要分析CPU的特性,根據CPU的特性進一步將其分解成功能測試點,形成驗證規格表,驗證人員據此開發驗證用例覆蓋所有的測試點。由于CPU指令多,CPU相關流水線結構沖突和數據沖突場景多,驗證用例數量龐大,所以大部分驗證用例通過驗證用例生成模塊的自動化腳本批量生成,邊界驗證用例由人工編寫生成。為全面覆蓋CPU的功能,驗證用例采用匯編代碼編寫,通過驗證用例生成模塊生成后綴為.asm的匯編驗證用例。
驗證用例生成模塊主要由生成驗證用例的Perl(Practical Extraction and Report Language)[8]腳本構成。為保證生成的匯編驗證用例的正確性,在Perl腳本中將CPU的每條指令均單獨構建子函數,每個子函數使用編號命名,子函數內部將該指令的限制用法單獨編程。以UI16TOF32指令為例,其子函數Perl腳本如下:


將待驗證的超過400條CPU指令分類并逐條編寫Perl子函數,Perl主函數通過調用編號隨機的Perl子函數實現各指令間的隨機組合,并按照匯編格式生成匯編驗證用例。
現有CPU驗證平臺的驗證用例通常使用C語言或者高級語言隨機生成,通過編譯器編譯后加載到CPU中進行驗證。使用高級語言編寫的驗證用例由于編譯器的優化,通常不能實現CPU內部資源的高效利用,從而不能覆蓋到CPU數據相關沖突和流水線相關沖突的部分場景,造成CPU功能驗證不全、功能覆蓋率難收斂的情況。本文使用自動化Perl腳本直接構建匯編驗證用例,而匯編驗證用例會直接指定指令使用的CPU內部資源,從而可以覆蓋到CPU數據相關沖突和流水線相關沖突的各種場景。這不僅提高了CPU驗證的可靠性,而且由于無需使用編譯器編譯,提高了仿真效率,縮短了驗證周期。
2.3 匯編器模塊
匯編驗證用例構建完成后,使用TI公司的CCS匯編器編譯,通過格式轉換器轉換成Verilog代碼能識別的存儲器存儲文件,該存儲文件是后綴為.hex的程序機器碼文件。格式轉換器采用Perl語言編寫,可生成多種Verilog能夠識別的文件。
2.4 程序RAM
程序RAM內部通過Verilog的$readmemh系統函數讀取后綴為.hex的存儲器文件,存入程序RAM中,CPU模塊通過存儲器接口讀取該程序RAM空間的程序數據。
2.5 數據RAM
數據RAM主要存儲CPU流水線訪存和回寫的數據。
2.6 參考模型模塊
參考模型模塊是針對CPU模塊提出的,參考模型模塊和CPU模塊是對產品特性的兩個獨立的實現,也就是說,參考模型模塊功能上與CPU模塊等價,但參考模型模塊與CPU模塊的設計不同,兩者區別如下。
1)輸入:參考模型模塊的輸入是匯編驗證用例,而CPU模塊的輸入是存儲在程序RAM中的經匯編器模塊編譯后的二進制指令碼。
2)指令處理流程:參考模型模塊逐行讀取匯編驗證用例中的指令,每條指令執行完成后才會繼續讀取下一條匯編指令,而CPU模塊是基于流水線的設計,讀取當前指令不需要上一條指令執行完成。
3)運算單元:參考模型使用SystemVerilog[9]語言完成指令的乘、加、移位等運算,其具有接口、斷言、受約束的隨機化激勵等特點,能夠大幅提高測試效率,且具有較高的功能測試覆蓋率[10],而CPU模塊的乘、加、移位等運算是基于電路的設計。
根據上述參考模型模塊和CPU模塊設計的主要區別,可以得出參考模型模塊的設計思想:逐行讀取匯編文件中的匯編指令,通過SystemVerilog字符串匹配技術完成匯編指令匹配,從而識別出匯編指令功能,然后實現指令功能。參考模型對指令的串行執行方式巧妙地驗證了CPU模塊的流水線相關沖突和數據相關沖突設計的正確性。同時,由于參考模型模塊和CPU模塊的運算單元設計不一致,CPU模塊運算單元的正確性也可以得到驗證。參考模型的設計流程如圖2所示。
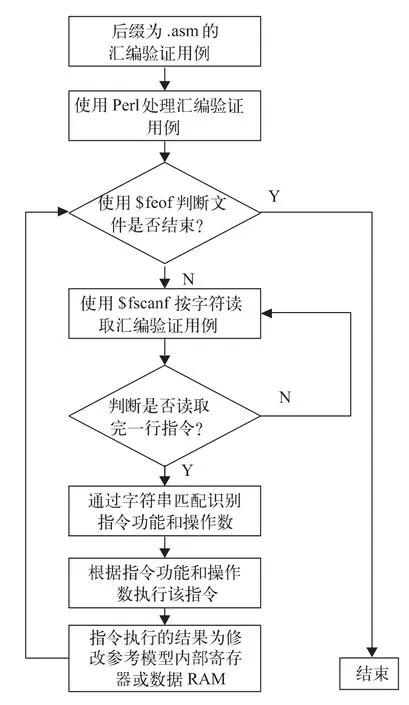
圖2 參考模型模塊設計流程
參考模型模塊的設計流程描述如下:
1)參考模型模塊使用Perl腳本讀入驗證用例生成模塊產生的后綴為.asm的匯編驗證用例,將匯編驗證用例中的注釋去掉,并在匯編驗證用例中的每行指令結束位置添加行結束標志;
2)參考模型模塊讀入Perl腳本處理后的匯編驗證用例,通過SystemVerilog的$feof系統任務判斷該驗證用例是否結束,當驗證用例沒有被讀完時,轉步驟3,否則參考模型模塊的流程結束;
3)參考模型模塊使用$fscanf系統任務按字符讀取匯編驗證用例,并存入指令字符數組中,然后通過步驟1添加的行結束標志判斷該行指令是否結束,如果該行指令未結束,則重復步驟3,否則,跳轉至步驟4;
4)參考模型模塊讀取指令字符數組,通過字符串匹配功能識別匯編指令的操作碼和操作數,如MOV32 R0,R1,操作碼是MOV32,目的操作數是寄存器R0,源操作數是寄存器R1;
5)參考模型模塊根據步驟4識別出的指令功能和操作數執行該指令,如MOV32 R0,R1,將寄存器R1的值送到R0中,然后開始下一條指令的讀取,跳轉至步驟2。
參考模型模塊對比驗證CPU模塊的方式為:將驗證用例生成模塊生成的同一驗證用例送入參考模型模塊和CPU模塊,然后比較參考模型模塊和CPU模塊所有指令的執行結果,如果參考模型模塊和CPU模塊的行為不一致,或者CPU模塊的功能實現出現錯誤,或者參考模型模塊的功能實現出現錯誤,或者兩者實現功能均出現錯誤,通過定位修改參考模型模塊和CPU模塊的錯誤。如果CPU模塊和參考模型模塊的行為一致,或者兩者都對,這是希望的結果;或者兩者犯同樣的錯誤,那么需要想辦法減小這種情況出現的可能性,比如參考模型模塊的設計人員不能為CPU模塊設計人員,或者引入第三方,例如VIP、FPGA[11]原型等。本文采用參考模型模塊設計人員不為CPU模塊設計人員的方法降低參考模型和CPU模塊設計同時出錯的可能性。
參考模型模塊是該驗證平臺中最重要的組件,參考模型模塊是保證功能驗證正確性的核心[12],也是該驗證平臺實現高效率和重構優勢的核心組件。現有CPU驗證平臺參考模型的設計基本分為兩類,一類是使用編譯器自帶的由高級語言編寫的軟件參考模型,軟件參考模型復雜難懂,某些軟件參考模型的核心代碼甚至是加密的,這增大了驗證人員的調試難度。搭建基于軟件參考模型的驗證平臺通常工作量大,人力投入高,且調試周期長。另一類是基于指令碼匹配技術設計的參考模型,該類參考模型通常會遵照CPU流水線時序編寫,其工作量與CPU設計工作量相當,人力投入和調試周期依然較長。本文通過SystemVerilog的字符串匹配技術串行識別匯編文件,無需嚴格按照流水線時序設計,參考模型的工作量大大減少,人力投入和周期均減少,不僅提高了CPU的驗證效率,而且縮短了驗證周期。
2.7 CPU監視模塊
CPU監視模塊主要完成CPU模塊指令執行結果的監測功能,CPU模塊通常的指令執行結果是修改CPU模塊內部資源和數據RAM,CPU模塊內部資源包括通用寄存器和輔助寄存器等,CPU監視模塊主要將CPU模塊對寄存器和數據RAM的執行結果打印到日志中。
2.8 參考模型監視模塊
參考模型監視模塊主要完成參考模型模塊指令執行結果的監測功能,參考模型模塊模擬CPU模塊的行為,參考模型模塊內部的通用寄存器、輔助寄存器和數據RAM資源也同樣參照CPU模塊定義,參考模型監視模塊主要是將參考模型模塊對寄存器和數據RAM的執行結果打印到日志中。
2.9 結果比較模塊
結果比較模塊通過對比CPU監視模塊和參考模型監視模塊提供的指令運行的打印結果,給出比較結果,幫助驗證人員快速完成CPU驗證結果的分析和判斷。
3 驗證流程
本文采用Synopsys公司的VCS作為仿真工具,為實現批量驗證,編寫了基于Perl的批處理程序,該程序可一次批量驗證多個用例,并統計驗證結果,生成驗證報告。批量驗證流程如圖3所示。
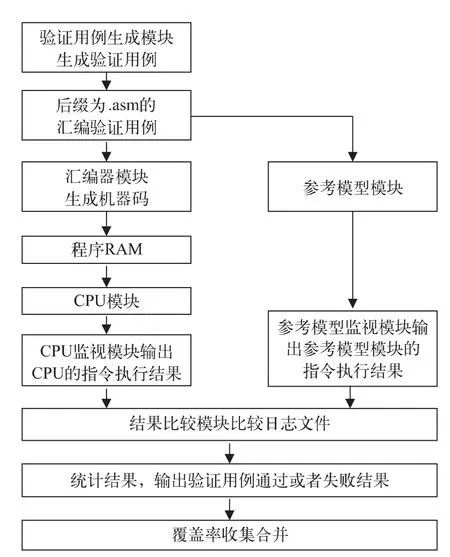
圖3 批量驗證流程
批量驗證流程描述如下:
1)通過驗證用例生成模塊批量生成驗證用例,即后綴為.asm的匯編驗證用例;
2)將匯編驗證用例傳入匯編器模塊,跳轉至第3步,將匯編驗證用例傳入參考模型模塊,跳轉至第6步;
3)匯編器模塊將匯編驗證用例編譯成指令碼之后,程序RAM將指令碼讀入RAM中;
4)CPU模塊讀取存在程序RAM中的指令碼指令,并執行指令;
5)CPU的監視模塊監測CPU模塊的執行結果,并將CPU模塊的執行結果輸出;
6)參考模型模塊讀取驗證用例生成模塊產生的匯編指令,并執行指令;
7)參考模型監視模塊監測參考模型模塊的執行結果,并將參考模型模塊的執行結果輸出;
8)結果比較模塊比較參考模型的監視模塊和CPU監視模塊的輸出結果,如果結果一致,則輸出該驗證用例測試通過的信息,否則輸出驗證用例測試失敗的信息;
9)重新開始下一個驗證用例的仿真驗證,依次循環直到所有的驗證用例全部運行結束,批處理程序顯示本次批量驗證的統計信息,并輸出驗證用例通過或者失敗的信息;
10)所有驗證用例仿真均通過后,收集并合并驗證用例覆蓋率。
4 結果分析
運用該功能驗證平臺進行了32位CPU的驗證。根據該CPU的特性,分別驗證了5類共計1044條驗證用例,驗證結果均通過,驗證結果如表1所示。
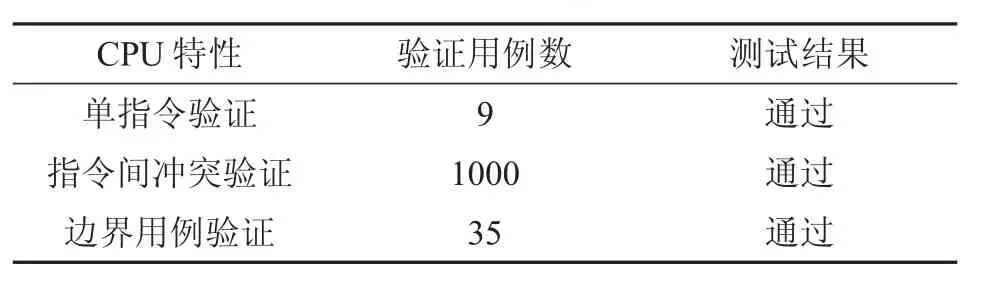
表1 驗證結果
除此之外,為保證驗證的充分性,對所有驗證用例進行了代碼覆蓋率收集和合并。通過分析覆蓋率,定向構造用例,提高驗證的完備性。
本驗證平臺的代碼覆蓋率結果如下。
1)行覆蓋率:CPU的行覆蓋率為100%。
2)翻轉覆蓋率:CPU的翻轉覆蓋率為99.81%,覆蓋率較低的原因是輸入和輸出數據信號的翻轉覆蓋率低,本文主要關注控制信號的翻轉覆蓋率,對不能達到100%的控制信號均進行了分析,確認是否是CPU不能進入的值,對于CPU可能會翻轉的值,定向構造用例,進行覆蓋。
3)條件覆蓋率:CPU的條件覆蓋率為83.17%,未覆蓋的條件分支是設計中不會出現的分支。
4)狀態機覆蓋率:本文的DUT內部無狀態機。
5)分支覆蓋率:CPU的分支覆蓋率為100%。
5 結束語
在CPU的設計中,高效和完備的功能驗證已成為CPU是否可靠的重要參考依據,本文設計并實現了一種基于SystemVerilog的CPU驗證平臺,論述了驗證平臺的整體設計結構、實現流程和批量驗證的實現方式。該驗證平臺有較好的通用性和可移植性,對于不同的指令集架構,稍加修改參考模型便可使用。該驗證平臺已成功應用于32位CPU芯片的功能驗證,相比該CPU之前的驗證方法,驗證周期從預估的10個月縮短到3個月,大大提高了驗證效率,縮短了CPU交付周期。另外,該設計平臺可以通過參考模型模塊和監視模塊快速定位CPU的設計缺陷,縮短設計人員迭代開發的周期。
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
中華詩詞(2022年6期)2022-12-31 06:41:24
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
藝術啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
中國科技論壇(2017年7期)2017-07-25 08:49:53
Coco薇(2017年5期)2017-06-05 08:53:16
中國中醫藥現代遠程教育(2014年22期)2014-03-01 04:32:55
中國中醫藥現代遠程教育(2014年16期)2014-03-01 04:28:54
