基于無人機多時相遙感影像的冬小麥產量估算
2021-12-08 03:32:40申洋洋陳志超周洪奎婁衛東沈阿林
麥類作物學報 2021年10期
申洋洋,陳志超,胡 昊,盛 莉,周洪奎,婁衛東,沈阿林
(1.河南理工大學測繪與國土信息工程學院,河南焦作 454000;2.浙江省農業科學院數字農業研究所,浙江杭州 310021;3.浙江省農業科學院環境資源與土壤肥料研究所,浙江杭州 310021)
冬小麥為我國的主要糧食作物之一[1],其播種面積占我國糧食播種面積的1/5[2],因而冬小麥是農作物研究的主要對象[3]。作物的產量關乎人民的生活水平和國家的糧食安全,收獲前及時、準確地監測預報作物產量對于后期田間作物管理、糧食安全、災害評估等具有重要意義[4-6]。實地統計調查是傳統預測農作物產量的主要方法[7-8],不僅工作量大、效率低,且對作物破壞性大,難以滿足大范圍作物產量預測的需求[9]。遙感技術以其覆蓋面積大、受地面條件限制少、非破壞性、信息量豐富等優點,在農作物監測方面得到廣泛應用[10]。目前,遙感估產的方法主要是基于經驗模型、物理模型和半經驗模型[11-14]。與衛星和地面遙感相比,無人機遙感可以獲得更高空間分辨率、時間分辨率和光譜分辨率的影像[15-17],在農作物監測方面得到迅速發展,已成為農業遙感數據獲取的重要途徑[18]。
近年來,國內外學者利用遙感技術對多種農作物產量估測開展了研究[19-23]。隨著研究的不斷深入,越來越多的統計分析方法和機器學習算法被用于估測作物產量[24-27]。王愷寧等[28]選取灌漿期的衛星遙感數據計算4種植被指數,并建立植被指數與小麥產量的線性及非線性回歸模型,其中非線性回歸模型精度較高,以非線性支持向量機(SVM)模型精度最好(R2=0.79)。陶惠林等[29]采集冬小麥拔節期、挑旗期、開花期無人機高光譜影像,用三種方法回歸建模,其中用偏最小二乘法(PLSR)建立的回歸模型估產最準確(R2=0.77)。Han等[30]結合無人機影像和四種機器學習算法(多元線性回歸、支持向量機、人工神經網絡和隨機森林)估測玉米生物量,其隨機森林算法模型具有較高的精度和較低的誤差(R2=0.94,RMSE=0.50)。劉昌華等[31]以無人機多光譜影像為基礎,提取冬小麥返青期、拔節期、孕穗期、揚花期冠層多光譜數據并建立產量估算模型,其中返青期估算效果較差,拔節期、孕穗期、揚花期估算效果相近且較好(R2分別為 0.93、0.96、0.94)。趙鑫[32]基于小麥揚花期、灌漿期、成熟期冠層影像提取15種植被指數和3種顏色特征,使用6種機器學習算法建立產量估測模型,其中隨機森林算法模型精度最高(R2=0.74),灌漿期產量反演模型精度最高。Fu等[33]使用多旋翼無人機采集江蘇省三個地區的影像數據,使用5種線性和非線性方法構建小麥產量估算模型,其中在拔節期、抽穗期、開花期和灌漿期,用歸一化植被指數(NDVI)構建的隨機森林算法模型表現最佳(R2為0.78,RMSE為0.10)。由以上研究結果可知,不同研究得出的小麥最優估產模型不同,因而利用無人機光譜影像進行小麥估產研究需要進一步的深入。本研究以冬小麥拔節期、孕穗期、抽穗期、灌漿期、成熟期的無人機多光譜影像為數據源,并基于植被指數采用統計分析方法(逐步多元線性回歸、偏最小二乘回歸)和機器學習算法(BP神經網絡算法、隨機森林算法、支持向量機算法)對不同時期的產量估算模型進行構建和效果評價,以確定最優模型,以期為冬小麥高效、快速的產量估算提供技術和方法。
1 材料與方法
1.1 研究區概況與試驗設計
試驗地點位于浙江省寧波市寧海縣茶院鄉(29°18′N,121°34′E),屬于亞熱帶季風性濕潤氣候,地勢西北高東南低。全年的平均氣溫約 16 ℃,年平均降雨量1 000~1 600 mm,年日照約1 900 h,平均相對濕度78%,氣候溫暖濕潤,四季分明。
供試小麥品種為金運麥1號和揚麥20。試驗設置0 kg·hm-2、90 kg·hm-2、180 kg·hm-2、270 kg·hm-24個施氮水平。各處理隨機區組排列,共48個小區,每個小區面積40 m2。氮肥為尿素,磷肥為過磷酸鈣,鉀肥為氯化鉀。其中,氮肥分兩次施用,基施40%,拔節期追施60%。磷肥和鉀肥作為基肥一次性施用,磷肥和鉀肥施用量分別為75 kg P2O5·hm-2和120 kg K2O·hm-2。
1.2 無人機多光譜遙感數據的獲取與處理
本研究采用深圳市大疆創新科技有限公司的四旋翼精靈4無人機為數據采集平臺,該無人機搭載多光譜成像系統,主要參數見表1。多光譜相機有6個影像傳感器,其中1個彩色傳感器用于可見光(RGB)成像,5個單色傳感器用于包含藍(B 450±16 nm)、綠(G 560±16 nm)、紅(R 650±16 nm)、紅邊(RE 730±16 nm)和近紅外(NIR 840±26 nm)波段的多光譜成像。試驗安排在2020年冬小麥生長季,在拔節期(2020年3月16日)、孕穗期(2020年3月26日)、抽穗期(2020年4月2日)、灌漿期(2020年4月24日)和成熟期(2020年5月12日)通過無人機飛行獲取田間多光譜遙感數據。數據采集當日天空晴朗無云、太陽光照穩定。試驗設置無人機航線6條,相對航高30 m,航向重疊率80%,旁向重疊率70%,地面分辨率為1.5 cm,作業過程中可同步獲取研究區RGB和多光譜影像。
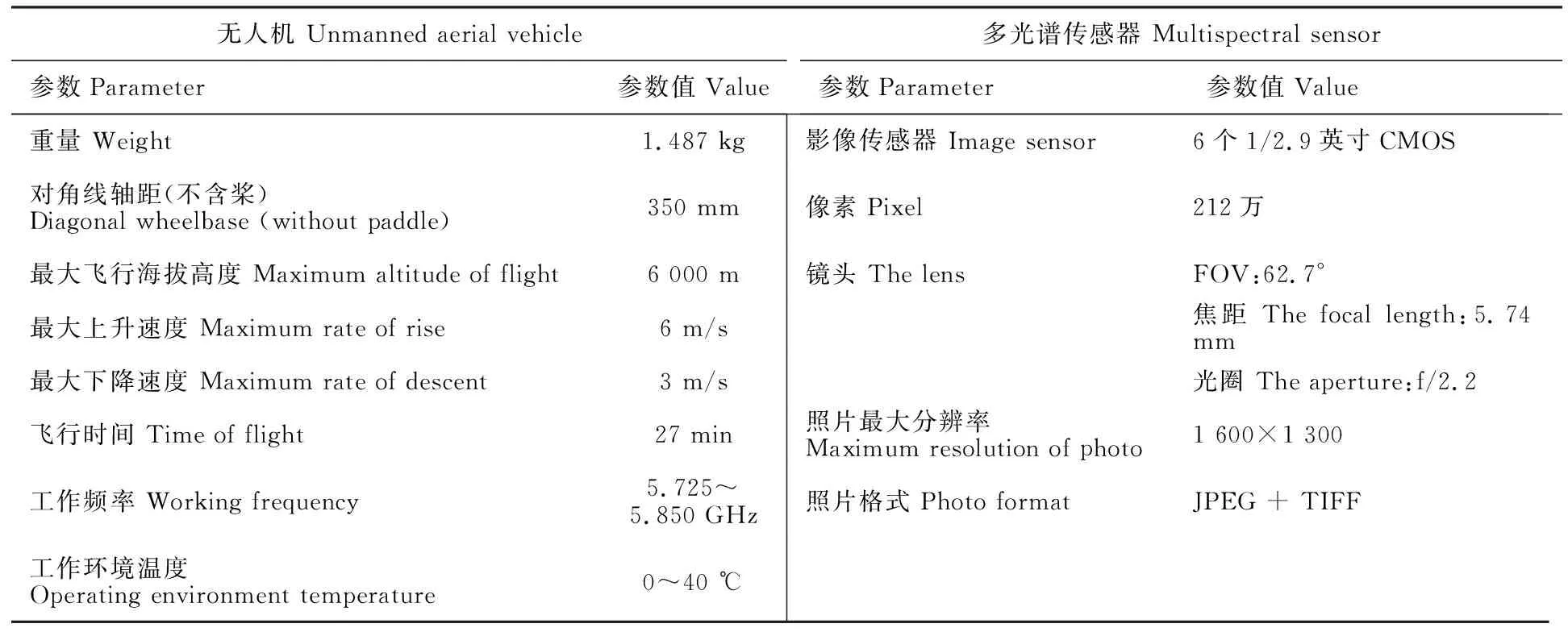
表1 無人機和多光譜傳感器的主要參數Table 1 Key parameters for UAV and multi-spectral sensors
將獲取的多光譜影像檢查無誤后進行處理。使用大疆智圖(DJI Terra)進行建圖航拍,將采集的照片數據導入DJI Terra,選擇農田場景進行二維重建,得到基于單個波段的正射影像。將拼接完成的單個波段影像導入ENVI 5.3,進行波段合并,得到5個生育時期的多光譜影像。灌漿期的多光譜影像如圖1所示。基于Python 3.6 提取每個小區1 m×1 m樣方的平均光譜值并計算72個植被指數。

圖1 無人機多光譜影像圖Fig.1 UAV multi-spectral image
1.3 地面數據獲取及處理
小麥成熟期選取每個小區均勻且有代表性的1 m2區域進行采樣,樣品帶回實驗室脫粒,籽粒曬至恒定重量后測定水分含量并稱重,獲得各個小區冬小麥產量。
1.4 模型構建與驗證
依據多光譜相機五個特征波段數據計算利用72個植被指數值(計算方法等信息主要來源于文獻[34]),分別基于逐步多元線性回歸(stepwise multiple linear regression,SMLR)、偏最小二乘回歸(partial least squares regression,PLSR)、BP神經網絡(back-propagation neural network,BPNN)、隨機森林(random forest,RF)和支持向量機(support vector machine,SVM)五種方法建立小麥估產模型[35-38]。首先,對72個植被指數與冬小麥產量間及這些植被指數之間分別進行Pearson相關分析和偏相關分析,然后根據植被指數與產量間以及植被指數間的相關性,對植被指數進行排序。將排序的72個植被指數作為輸入因子依次減少植被指數的個數進行向后逐步回歸分析,最后建立產量多元線性回歸估測模型。偏最小回歸二乘模型構建時使用的是逐步多元線性回歸篩選出來的植被指數。基于機器學習算法建立模型前,從72個植被指數中剔除與產量相關性較低(未達0.05顯著水平)、與其他植被指數間相關性較高的植被指數,將剩余的植被指數作為機器學習算法輸入因子(20個左右),建立產量估測模型。
相關性分析使用軟件IBM SPSS Statistics 21,統計分析使用The Unscrambler X和SPSS,機器學習算法在Matlab環境中實現。隨機選擇五個生育時期的67%數據作為建模集,剩余數據作為驗證集。采用交叉驗證方法建立實測產量與預測產量之間的關系,依據決定系數(R2)、均方根誤差(RMSE)和相對誤差(RE)對估算模型的預測能力進行評價。
(1)
(2)
(3)
2 結果與分析
2.1 基于SMLR和PLSR小麥估產建模和模型驗證效果
從建模效果(表2和表3)看,從拔節期到灌漿期,SMLR和PLSR模型的擬合精度均較高,以抽穗期最佳,R2、RMSE、RE分別為0.86、0.46 kg·hm-2、11%和0.86、0.49 kg·hm-2、13%;成熟期的擬合精度較差。經獨立數據驗證,兩類模型的預測精度在不同時期也均表現不同(圖2和表3)。拔節期和成熟期的預測精度均較差,其他時期的預測精度均較高,均以灌漿期表現最優,R2、RMSE和RE分別為0.85、0.91 kg·hm-2、23%和0.83、0.97 kg·hm-2、19%。
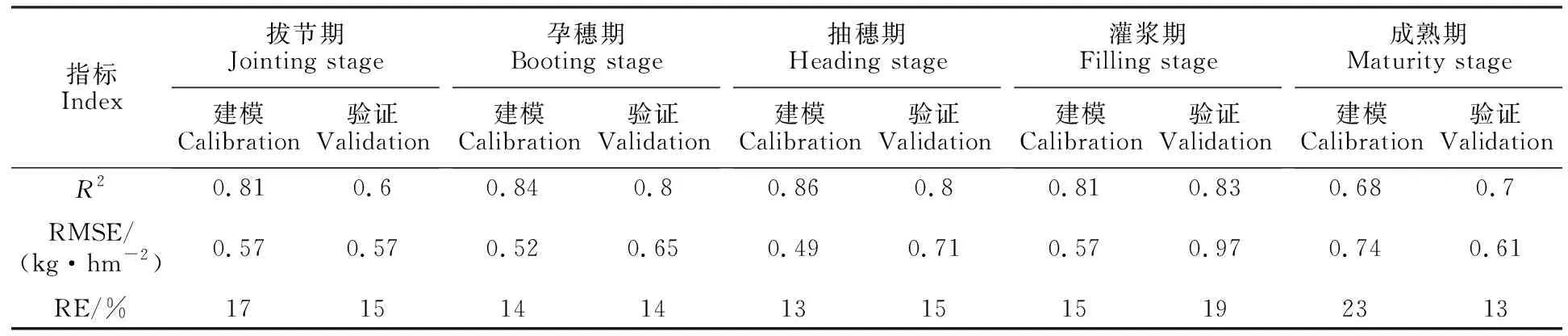
表3 基于偏最小二乘回歸的冬小麥不同生育時期產量模型與模型驗證Table 3 Models and model validation of yield estimation at different wheat growth stages based on partial least squares regression
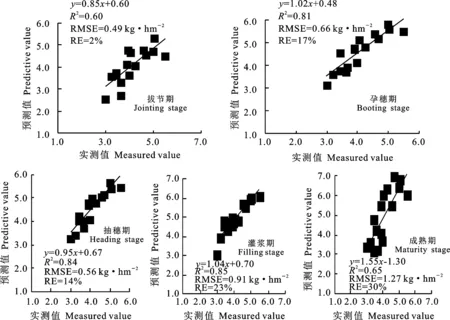
圖2 基于逐步多元線性回歸的冬小麥實測值與預測值的關系Fig.2 Relationship between measured and predicted winter wheat values based on stepwise multiple linear regression

表2 不同生育時期植被指數與小麥產量的逐步多元線性回歸模型Table 2 Stepwise multiple linear regression model of vegetation indices and wheat yield at different growth stages
2.2 基于機器學習算法的產量模型及精度驗證
基于BP神經網絡算法、RF算法、SVM算法三種機器學習算法建立的模型對于不同生育時期反演精度表現為RF算法>BP神經網絡算法>SVM算法(表4)。經驗證,不同算法模型的預測精度在不同時期表現不盡相同(表5)。孕穗期、抽穗期、灌漿期和成熟期,RF算法預測精度最高,BP神經網絡算法次之,SVM算法預測精度最低。拔節期RF算法預測精度最高,BP神經網絡算法預測精度最低。三種算法建立的模型成熟期預測精度最差,拔節期略高(R2>0.63),孕穗期、抽穗期和灌漿期預測效果接近,且有較好的預測能力。基于BP神經網絡算法的模型預測精度在孕穗期表現最優(R2、RMSE和RE分別為0.84、0.68 kg·hm-2、28%),基于RF算法和SVM算法的模型預測精度在抽穗期表現最優,R2、RMSE和RE分別為0.91、 0.35 kg·hm-2、15%;0.79、0.59 kg·hm-2、 15%。

表4 基于機器學習算法的冬小麥不同生育時期產量回歸模型Table 4 Regression model of yield at different wheat growth stages based on machine learning algorithm

表5 基于機器學習算法的冬小麥不同生育時期產量模型驗證Table 5 Verification of yield at different wheat growth stages based on machine learning algorithm
2.3 最優產量估算模型及精度驗證
對比兩種統計分析方法和三種機器學習算法,綜合考慮建模精度和驗證精度以及模型的均方根誤差和相對誤差,五種方法中用RF算法建立的模型精度最高,驗證效果總體最優。從RF模型的預測值與實測值的關系(圖3)看,抽穗期估算效果最好,拔節期、孕穗期和灌漿期估算效果接近,成熟期的估算效果相對較差。
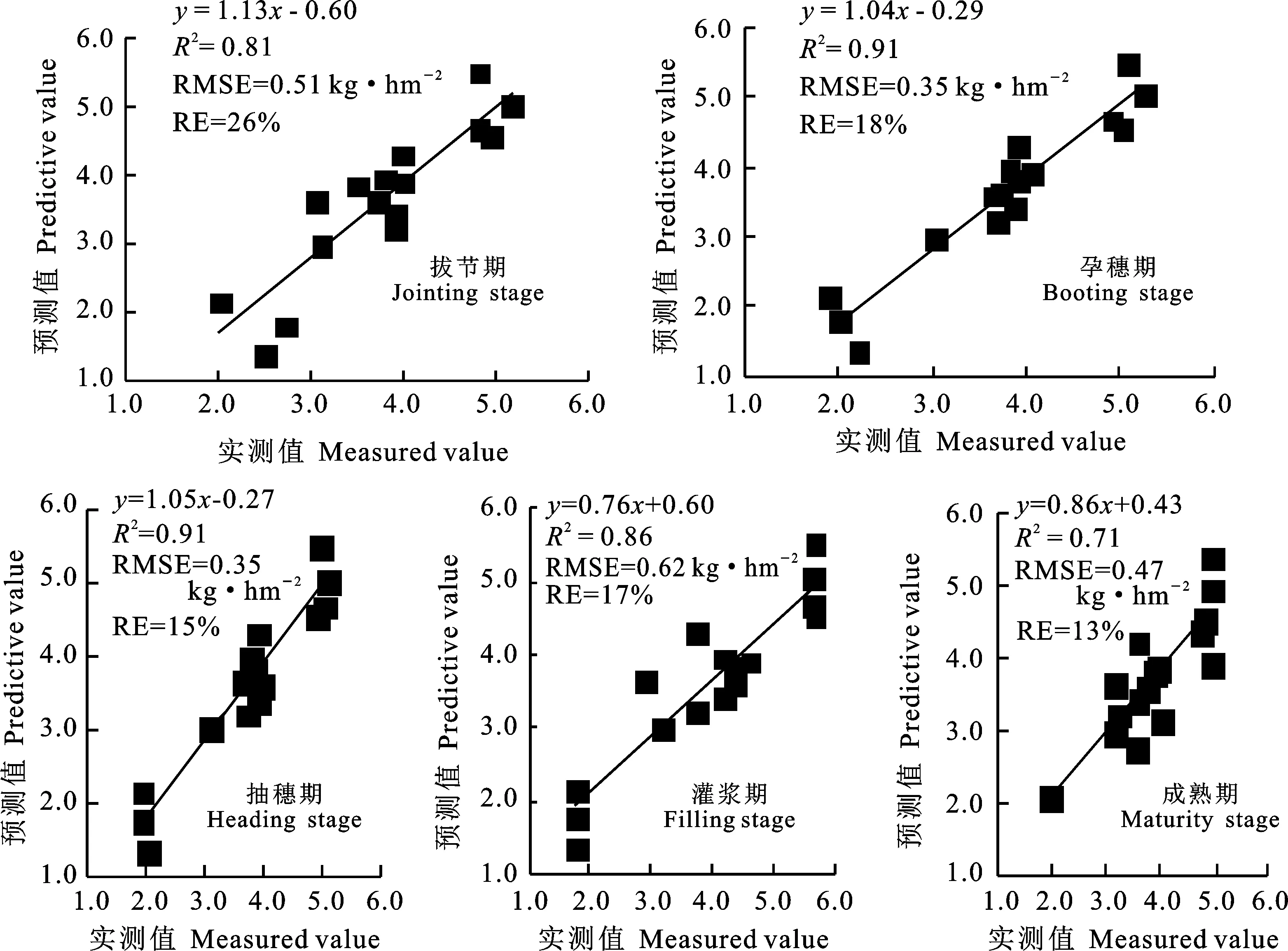
圖3 基于隨機森林算法的冬小麥產量實測值與預測值的關系Fig.3 Relationship between measured and predicted winter wheat yield based on random forest algorithm
3 討 論
無人機作為遙感數據獲取的新平臺,具有更高的分辨率,在監測作物長勢、產量預測等精準農業研究中發揮了重要作用。無人機多光譜數據一般含有紅、綠、紅邊和近紅外等遙感所需的重要波段,而且影像處理相對簡單,在農業遙感的應用上占據一定的優勢。除了數據源,建模算法的選擇對農作物參數的估測精度也有一定的影響,定量評價不同算法建立的預測模型精度以及選出最優的建模方法對農業遙感監測具有重要意義。本研究利用無人機多光譜數據結合統計回歸和機器學習算法估算冬小麥產量。
對不同生育時期的植被指數進行相關性分析后,采用兩種統計分析方法建立植被指數與產量的回歸模型。本研究通過向后逐步多元線性回歸,以72個植被指數為變量,每建立一個模型就刪除一個對模型沒有貢獻的變量,直至篩選出最優參數建立模型,該方法保留了對模型有顯著貢獻的變量,降低了模型的復雜性。偏最小二乘回歸分析的數學基礎是主成分分析,是一種集典型相關分析、多元線性回歸分析和主成分分析于一體的方法。該方法能最大限度地利用所有有效數據構建回歸模型,且計算量小。兩種統計分析方法的優勢是在自變量存在多重相關性等問題時能建立有效回歸模型,且建立的產量估算模型擬合效果較好,預測效果不相上下。但因其只能建立數據之間的線性關系,估算精度不高。因此,本研究選擇對非線性類型問題有較好解釋能力的機器學習算法進一步研究。
在BP神經網絡、RF、SVM三種機器學習算法中,BP神經網絡有非線性映射能力強、自學習和自適應能力強等特點,是處理復雜非線性問題的有效手段;SVM算法具有完備的統計學理論基礎,基于結構風險最小化原則,在解決小樣本、非線性及高維模式識別等問題中有獨特的優勢;RF算法是一種結合大量回歸樹的嵌入學習算法,具有快速運算、較強的抗噪聲和不易出現過擬合等優點。本研究中,用BP神經網絡、RF算法建立的模型估算效果優于統計回歸模型,用SVM算法建立的模型估算效果與統計回歸建立的模型估算效果接近。而在模型驗證時,只有RF模型的估算能力始終優于SMLR、PLSR和SVM模型。造成這種結果的原因可能是用機器學習算法建模時會出現過擬合現象,而RF算法的魯棒性和泛化能力強于BP神經網絡[34]。用RF算法建立的產量估算模型效果最優,與Han等[30]和Fu等[33]的研究結果一致。用RF算法建立的估算模型中,抽穗期估產效果最好,成熟期估產效果最差,這與劉昌華等[31]得出的無法確定估產關鍵生育時期的結論不一致,與朱婉雪等[39]研究結果一致。雖然應用機器學習算法可更好地利用遙感數據估算作物產量,但需要進行更多的研究進行以便將遙感數據和其他相關的土壤、天氣和管理信息結合起來,用于精確估算作物產量。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
礦山安全信息(2022年40期)2022-04-07 02:16:52
今日農業(2021年14期)2021-11-25 23:57:29
石油與天然氣地質(2021年1期)2021-02-22 14:14:44
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
今日農業(2020年20期)2020-11-26 06:09:10
數學物理學報(2020年2期)2020-06-02 11:29:24
中國果業信息(2019年10期)2019-11-13 01:21:34
聚氯乙烯(2018年9期)2018-02-18 01:11:34
光學精密工程(2016年6期)2016-11-07 09:07:19
