多聯式空調制冷系統堵塞故障位置辨識仿真
2021-12-10 08:32:18冉均均
計算機仿真 2021年11期
冉均均,袁 磊
(成都理工大學工程技術學院,四川樂山 614000)
1 引言
多聯式空調是公共基礎設施中必不可少的設備,一般用于調節公寓、商場、寫字樓等公共場所的溫度。當設備在不間斷使用的情況下,如果沒有及時進行清理,制冷系統就會出現堵塞故障,該故障初始期表現為不同程度的部分堵塞,在檢修時很容易被忽略,時間久了就會導致堵塞面積擴大,不僅會影響多聯式空調正常運行,還有可能帶來嚴重的安全隱患[1]。因此,消除多聯式空調制冷系統的堵塞故障具有重要意義,需要對堵塞故障位置的辨識方法進行深入研究。
王占偉[2]等人首先將DR機制融入貝葉斯網絡中,將制冷系統堵塞故障位置辨識轉化為一類劃分問題,然后通過小波變換法提取故障特征向量,并使用數據訓練模型對其進行分類,完成辨識。實驗表明,該方法具有很高的辨識準確率,但該方法在辨識之前沒有對相關數據進行預處理,導致辨識過程中出現空值,誤報率過高。姜陳[3]等人采用BP神經網絡算法建立室溫預測模型,并設置故障位置辨識閾值,以此構建堵塞故障位置自動辨識系統,實現制冷系統中堵塞故障位置的自動辨識。但該方法沒有對數據進行預處理,導致需要辨識過程中所需的數據量龐大,召回率也低。黃倩云[4]等人利用支持向量機算法建立了制冷系統堵塞故障檢測與診斷模型,然后采用網格搜索和十折交叉驗證方法優化該模型,完成制冷系統堵塞故障位置辨識。但該方法未消除對堵塞故障位置辨識貢獻較低的數據,導致漏檢率過高,不能廣泛使用。
為了解決上述方法存在的問題,本文提出一種多聯式空調制冷系統堵塞故障位置辨識方法。
2 基于時間序列的堵塞故障數據清洗方法
在多聯式空調制冷系統中,由于其實際運行數據采樣間隔短、時間長、測量點多,導致數據量過于龐。再加上在龐大的數據中,經常會存在死值、空值等對堵塞故障位置辨識貢獻較低的數據,影響辨識的準確率,因此,堵塞故障數據進行預處理的環節非常重要[5]。
所提方法將待辨識的堵塞故障位置設為觀測點,利用迭代檢驗方法對堵塞故障位置的時間序列進行清洗[6]。具體方法共為六個步驟,如圖1所示。
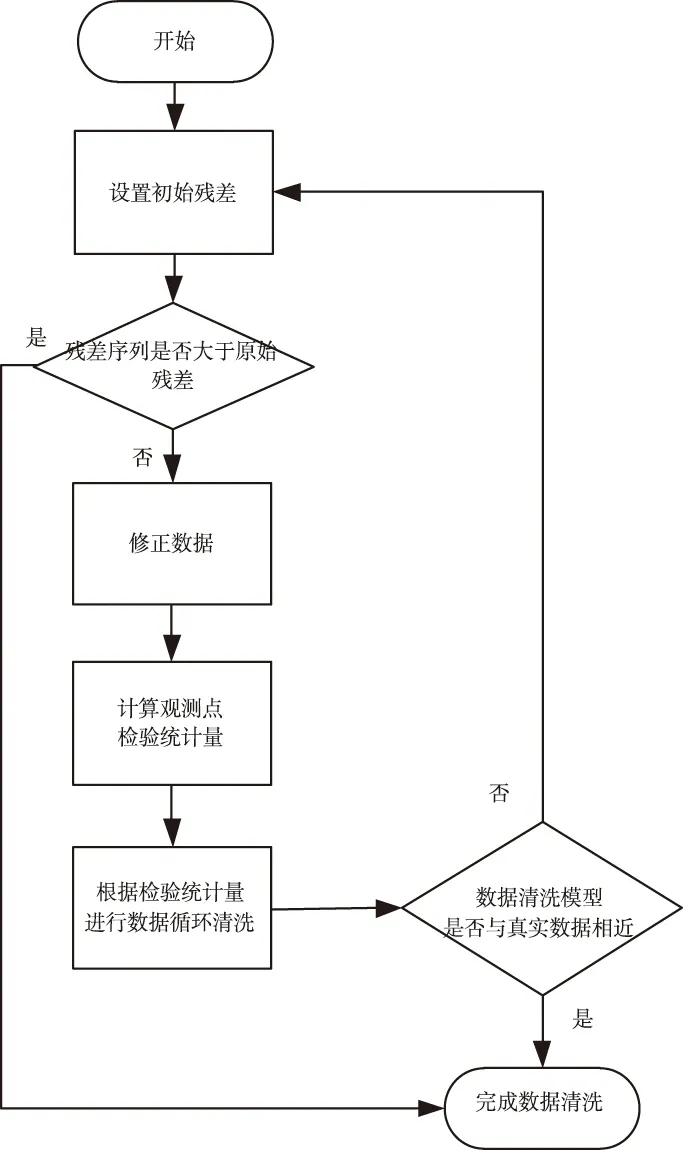
圖1 數據清洗具體流程
1)計算初始殘差
假設多聯式空調制冷系統運行數據中不存在異常值,對觀測點序列Zt建立時間序列模型,計算初始殘差[7]。具體如式(1)所示

(1)
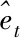

(2)
2)觀察擬合殘差序列
若從任意時間點開始,殘差序列呈現水平遷移,并且遠遠大于初始殘差值,直接跳至步驟七,反之則進入步驟三,開始循環計算。
3)外循環
計算1,2,…,n中每個觀測點的檢驗統計量TtAO和TtIO。設最大發生時刻為λTmax,其表達式如下
λTmax=max{|TtAO|,|TtIO|}
(3)
式中,預先設定的常數為C,通常取3和4之間的值,當λTmax>C時,表明存在異常數據,需要進入下一步內循環修正數據。
4)內循環


(4)
修正后的時間序列如式(5)所示

(5)
修正后得到的新殘差如式(6)所示
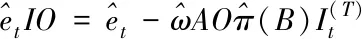
(6)
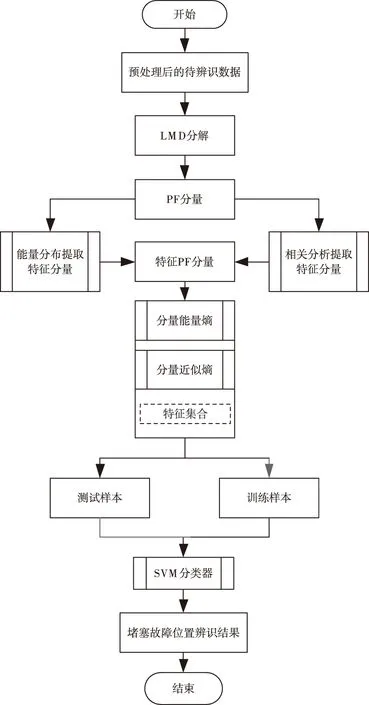
通過上述計算可知,在修正后的殘差的基礎上,再次計算每個觀測點的檢驗統計量Tt′IO和Tt′AO,并重復步驟四,直到辨識出所有的異常數據,當λTmax 5)時間序列模型殘差 (7) 根據時間序列參數計算檢驗統計量,當λTmax 6)聯合估計 (8) 為了消除多聯式空調制冷系統的堵塞故障,需要對其位置進行辨識。首先將處理后的堵塞故障數據進行局部均值分解(Local Mean Decomposition,簡稱LMD),得到若干個乘積函數(PF)分量,然后結合相關分析法選取有效PF分量,對其能量熵和近似熵兩個指標的特征進行提取,構建分類特征集,通過基于交叉驗證(CV)的SVM故障分類模型完成對堵塞故障位置的辨識。 為了降低誤報率,利用LMD對堵塞故障數據特征進行提取[8]。首先從含有堵塞故障的原始數據中,將正常數據ai(t)與故障數據si(t)分離,并將二者進行相乘得到有物理意義的乘積函數(PF),如式(9)所示: PFi=ai(t)si(t) (9) 1)能量熵 當制冷系統中的某部分出現堵塞故障時,數據中的能量分布也會因此做出相應的改變。所以需要在LMD分解的基礎上,通過計算各PF分量的能量分布來進一步獲取信號能量熵特征,并以此構建堵塞故障特征向量。 為了避免出現特征向量冗余的情況,所提方法利用相關分析法與能量分布法選取有效的PF分量。首先選取所占能量較多,且與原始信號相關度大于15%的分量計算能量熵,具體計算步驟如下所示: ①首先計算k個PF分量能量,并且將所有分量的能量相加得到總能量,如式(10)所示 (10) ②具有k個特征的PF分量在總能量中所占比重如式(11)所示 (11) ③則具有k個特征的PF分量能量熵的計算結果如式(12)所示 (12) 通過上述計算即可提取特征的PF分量的能量熵。 2)近似熵 如果僅用能量熵進行特征提取,正常數據和堵塞故障數據的能量熵會出現部分重疊的現象,因此為了彌補能量熵提取方式的不足,所提方法以數據的隨機性特征為基礎,提取堵塞故障數據特征。 近似熵能夠檢測時間序列中新的子序列產生概率,所以近似熵的數值越大,數據的隨機程度越大。首先,設時間序列如式(13)所示 |X(i),i=1,2,…,N| (13) 設m為子序列維數,r為能量熵相似度,則近似熵值的計算方法如式(14)所示 (14) 通過上述計算,得到了有效分量的近似熵與能量熵,經過分析表明二者為平行的特征,能夠共同構成堵塞故障數據特征,得到特征集合。 當獲取到優質的特征向量集合后,堵塞故障位置的辨識關鍵即變為選擇一個合適且高效的分類器進行分類的問題。目前的故障辨識分類器有很多,在眾多的分類器中,SVM在解決小樣本辨識問題中表現最為突出,因此所提方法采用的故障分類模型是基于交叉驗證的支持向量機(SVM)。它是一種適用于二分類的分類算法,即使在樣本數量較少的情況下也能夠獲得很好的分類結果。 首先給定一個訓練集合,如下所示 G={xi,yii=1,2,…l} (15) 其中,每個樣本xi∈Rd屬于一個分類,分類標簽為d。設分類的曲線為y=w*x+b,分類函數如式(16)所示 f(x)=sgn(wx+b) (16) 式中,權重向量為w,閾值為b。 獲取SVM的最優分類平面,可以表示為優化問題,如下所示 (17) 將上述問題轉化為對偶問題 (18) 則分類函數變為 (19) 若線性不可分,則轉換為高維問題,令Φ(x)為變換函數,K(x,y)為核函數,則 K(x,y)=Φ(x)Φ(y) (20) 將核函數代替內積運算,最終的分類函數如式(21)所示 (21) 為了使分類辨識結果更為可靠、穩定,引入K-CV方法,將數據均分為K組,每一組分別做一次測試組,其余作為訓練組,由此就會獲得K個模型,SVM的分類指標為此K個模型的最終分類準確性所對應的值,且K取10。 綜上所述,多聯式空調制冷系統堵塞故障位置辨識主要流程包括兩個方面:一是提取經過預處理后數據的能量熵、近似熵特征,構建堵塞故障數據特征集合,完成特征提取;二是在構建的融合特征集的基礎上采用K-CV的方法優化SVM分類器進行制冷系統中堵塞故障位置的辨識。該方法的具體流程圖如圖2所示。 圖2 制冷系統堵塞故障位置辨識流程圖 為了驗證所提的多聯式空調制冷系統堵塞故障位置辨識方法的整體有效性,需要對其進行測試。實驗分別對文獻[3]方法、文獻[4]方法與所提方法的召回率、誤報率和漏檢率對比測試。實驗參數如表1所示。 表1 實驗參數 召回率表示在所有故障樣本中,被正確辨識出故障類別的比例,圖3為不同方法的召回率對比結果。 圖3 不同方法的召回率對比結果 由圖3可知,多聯式空調制冷系統堵塞故障位置辨識方法的召回率最高,表明所提方法能夠有效對制冷系統中的堵塞故障位置進行辨識。原因在于該方法在辨識前對觀測點的時間序列進行了清洗,消除了死值、空值等對堵塞故障位置辨識貢獻較低的數據,進而提高了該方法的召回率。 誤報率表示在所有正常樣本中,被錯誤辨識為故障類別的比例,圖4為不同方法的誤報率對比結果。 圖4 不同方法的誤報率對比結果 分析圖4的結果可知,多聯式空調制冷系統堵塞故障位置辨識方法的誤報率是三種方法中最低的。原因在于該方法對數據進行了預處理,并利用LMD對堵塞故障數據特征進行了融合提取,選取了有效的PF分量,避免了特征向量冗余出現的情況,因此誤報率明顯下降。 漏檢率表示在所有故障樣本中,被錯誤辨識為正常樣本的比例,圖5為不同方法的漏檢率對比結果。 圖5 不同方法的漏檢率對比結果 從圖5的對比結果可知,與文獻[3]方法、文獻[4]方法相比,多聯式空調制冷系統堵塞故障位置辨識方法的漏檢率最低。原因在于該方法首先利用迭代檢驗的方法對觀測點的時間序列進行了清洗,然后引入了基于交叉驗證的支持向量機的故障分類模型進行故障位置辨識,即使出現樣本數量較少的情況,也能夠獲得較優的分類辨識結果,所以漏檢率也是三種方法中最低的。 多聯式空調系統作為必不可少的公共基礎設施,對其進行安全維護至關重要,而制冷系統中堵塞故障是維修中最棘手的問題之一,針對制冷系統出現堵塞故障導致設備無法正常運行的問題,需要對堵塞故障位置辨識進行深入研究。當前方法在對堵塞故障位置進行辨識時,存在召回率低、誤報率高和漏檢率高的問題,因此提出多聯式空調制冷系統堵塞故障位置辨識方法。實驗結果表明,該方法的召回率高、誤報率和漏檢率較低,充分解決了當前方法中存在的問題,在接下來會進一步結合相關應用研究開銷更小的堵塞故障位置辨別方法。


3 制冷系統的堵塞故障位置識辨識
3.1 基于LMD的堵塞故障特征融合提取
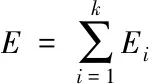
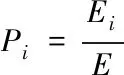


3.2 基于SVM的堵塞故障位置辨識
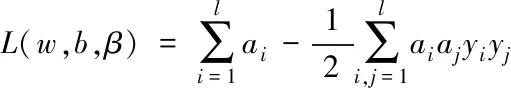

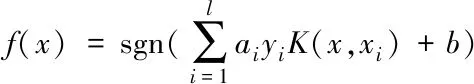
4 實驗與分析

4.1 召回率

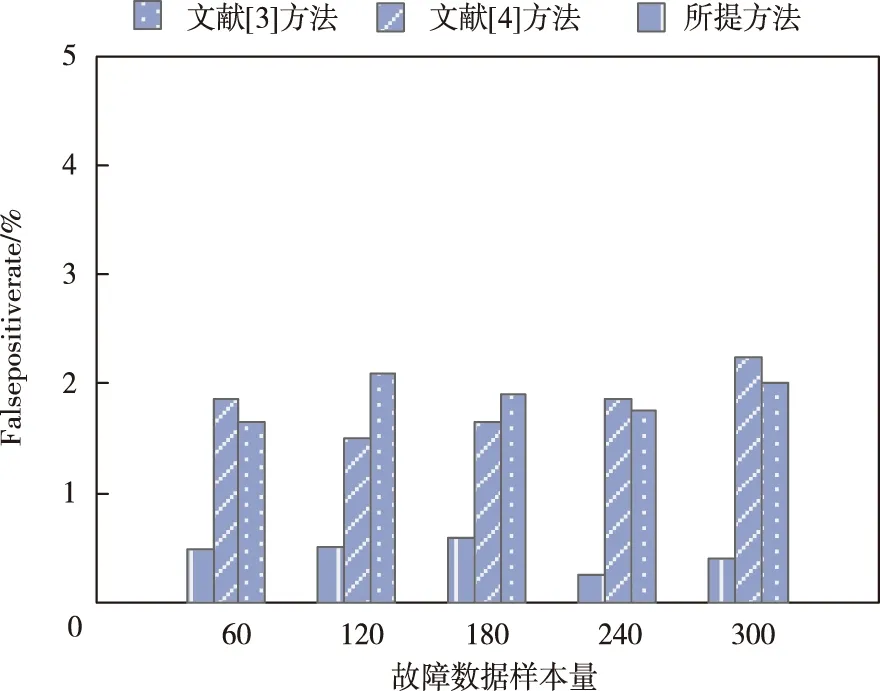
4.2 誤報率
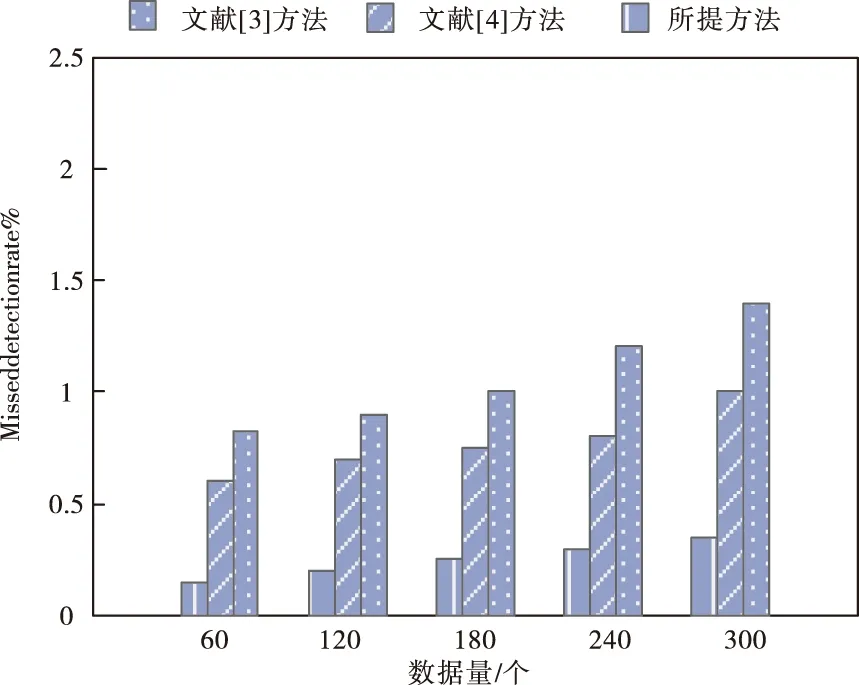
4.3 漏檢率
5 結束語
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56汽車維修與保養(2019年7期)2020-01-06 03:30:42中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06初中生世界·七年級(2017年9期)2017-10-13 22:27:46汽車維護與修理(2016年10期)2016-07-10 08:17:41Coco薇(2016年2期)2016-03-22 02:42:52Coco薇(2015年1期)2015-08-13 02:47:34小雪花·成長指南(2015年4期)2015-05-19 14:47:56汽車維修與保養(2015年6期)2015-04-17 03:31:50
