基于多特征LSTM-Self-Attention文本情感分類
2021-12-10 08:32:22謝斌紅董悅閏潘理虎張英俊
計算機仿真 2021年11期
謝斌紅,董悅閏,潘理虎,2,張英俊
(1.太原科技大學計算機科學與技術學院,山西 太原 030024;2.中國科學院地理科學與資源研究所,北京 100101)
1 引言
文本情感分析又稱意見挖掘或觀點分析[1],是運用自然語言處理技術對帶有情感色彩的主觀性文本進行分析、處理、歸納和推理的過程。情感分類作為其中一項最基本的任務,旨在根據(jù)文本表達的情緒進行自動分類[2]。它對輿情控制、民意調查及心理學研究[3]等具有重要的意義,因此,近些年受到了眾多研究者的密切關注,并取得許多進展[4]。
文本情感分類方法的研究經歷了基于詞典的方法、基于機器學習的方法和基于深度學習的方法三個階段[5]。其中,由于基于深度學習的方法具有更強的特征表示,而且還能更好地學習從數(shù)據(jù)到情感語義的復雜映射函數(shù),最重要的是解決了傳統(tǒng)機器學習方法的數(shù)據(jù)稀疏和維度爆炸的問題。因此,越來越多的學者將深
度學習應用到文本情感分類領域。Bespalov等[6]提出利用潛在語義分析(latent semantic analysis)來進行初始化詞向量,然后使用帶權重的n-gram特征的線性組合表征整篇文檔的情感特征。但是利用n-gram特征必須具備關于整個文獻庫和分類的知識,且需要大量人工進行處理。Glorot 等[7]使用除噪堆疊自編碼器(stacked denoising autoencoder,SDA)來解決大量評論數(shù)據(jù)情感分類中在不同領域中的適應性問題(domain adaptation)。Socher等[8-10]使用一系列基于遞歸神經網絡(Recursive Neural Network,RNN)的分類模型來解決文本情感分類問題,但是遞歸神經網絡在訓練過程中存在一些梯度爆炸和消失問題等缺點。Kim Y[11]則利用卷積神經網絡(Convolutional Neural Networks,CNN)來對英文電影評論進行分類,實驗結果表明,CNN的分類性能明顯優(yōu)于遞歸神經網絡。為了解決RNN梯度消失和梯度爆炸的問題,Zhu[12]提出使用長短期記憶網絡(Long Short Term Memory,LSTM),將評論語句建模成詞序列來解決情感分類問題,該網絡可以學習長距離依賴信息,對時間序列中間隔或延長較長的事件處理和預測時比較適用。梁軍等[13]將LSTM模型變型成為基于樹結構的遞歸神經網絡,并根據(jù)句子上下文詞語間的相關性引入情感極性轉移模型。如今LSTM 已經被應用在了許多領域,如機器翻譯[14]、圖像分析[15]、語音識別[16]等。由于LSTM解決了梯度爆炸和梯度消失的問題;此外,它更加真實地表征了人類行為、邏輯發(fā)展的認知過程,并且具有對詞向量依賴小的特點,能夠處理更加復雜的自然語言處理任務,成為當下解決自然語言處理問題的主流探究方向。
由于自注意力機制具有可減少神經網絡訓練時所需要的文本特征,降低了任務的復雜度,并且能夠有效捕獲遠距離的特征等優(yōu)點,已廣泛應用于機器翻譯[17,18]等自然語言理解任務中,并取得了較好的效果。另外,詞性作為詞語的關鍵信息,包含了較豐富的情感信息,通常作為一種輔助特征與詞語等特征相結合[19,20],并利用CNN或LSTM網絡對文本進行情感分類,使性能得到了一定提升。
綜上所述,本文將詞語、詞性特征相融合,以LSTM網絡作為主干網,并引入自注意力機制,提出了一種改進的基于多特征LSTM-Self-Attention模型對文本情感進行分類。實驗表明,自注意力機制和詞性特征可以提高情感分類的效果,比經典的LSTM網絡模型取得了更高的準確率。
2 基于多特征LSTM-Self-Attention文本情感分類模型
基于多特征LSTM-Self-Attention模型主要由文本預處理、Word2vec、LSTM、自注意力機制和SoftMax分類器5部分組成,其模型結構如圖1所示。其中,文本預處理模塊是將文本處理成詞語的形式,Word2vec模塊是將詞語訓練成計算機可以理解的稠密向量,LSTM模塊提取出稠密向量中的特征,自注意力機制模塊是進一步提取出特征中對分類結果更有影響的特征,最后,使用SoftMax分類器按照提取的重要特征對文本情感進行分類。

圖1 基于多特征LSTM-Attention文本分類模型
2.1 文本預處理


表1 部分詞性標準對照表
2.2 Word2vec
在自然語言處理任務中,首先需要考慮文本信息如何在計算機中表示。通常文本信息有離散表示和分布式表示2種方式。文本分類的標簽數(shù)量少且相互之間沒有依存關系,因此,使用離散表示的方法來表示文本情感分類的標簽yi,例如:高興 [0,0,0,1,0]。本文使用Word2vec[21]將詞語表示成一個定長的連續(xù)的稠密的向量(Dense Vector),能夠表征詞語之間存在的相似關系;Word2vec訓練的詞向量能夠包含更多的信息,并且每一維都有特定的含義。它包含了Continuous Bag of Word(CBOW)和Skip-gram 兩種訓練模型(如圖2和圖3所示),兩種模型都包括輸入層、投影層、輸出層,其中CBOW 模型利用詞Wt的上下文Wct去預測給定詞Wt,而Skip-gram 模型是在已知給定詞Wt的前提下預測該詞的上下文Wct。在此,本文使用Word2vec工具的Skip-gram 模型來訓練數(shù)據(jù)集中的每個詞語以及使用詞性標注工具標注好的詞性為計算機可理解的詞向量和詞性向量。

圖2 CBOW模型 圖3 Skip-gram模型

2.3 長短時間記憶網絡LSTM


圖4 LSTM模型單個神經元結構圖
1)遺忘門
遺忘門決定了上一時刻的單元狀態(tài)ct-1有多少保留到當前時刻ct,它會根據(jù)上一時刻隱藏層的輸出結果ht-1和當前時刻的輸入xt作為輸入,來決定需要保留和舍棄的信息,實現(xiàn)對歷史信息的存儲[22],可以表述為
ft=sigmoid(whfht-1+wxfxt+bf)
(1)
2)輸入門
輸入門用于決定當前時刻xt有多少保留到單元狀態(tài)ct。在t時刻,輸入門會根據(jù)上一時刻 LSTM 單元的輸出結果ht-1和當前時刻的輸入xt作為輸入,通過計算來決定是否將當前信息更新到LSTM-cell中【22】,可以表述為
it=sigmoid(whiht-1+wxixt+bi)
(2)
對于當前的候選記憶單元值cint,其是由當前輸入數(shù)據(jù)xt和上一時刻LSTM隱層單元ht-1輸出結果決定的【22】,可以表述為
cint=tanh(whcht-1+wxcxt+bcin)
(3)
當前時刻記憶單元狀態(tài)值ct除了由當前的候選單元cint以及自身狀態(tài)ct-1,還需要通過輸入門和遺忘門對這兩部分因素進行調節(jié)【22】,可以表述為
ct=ft.ct-1+it.cint
(4)
3)輸出門
輸出門來控制單元狀態(tài)ct有多少輸出到LSTM的當前輸出值ht,計算輸出門ot,用于控制記憶單元狀態(tài)值的輸出[22],可以表述為
ot=sigmoid(whoht-1+wxoxt+bo)
(5)
最后LSTM單元的輸出ht,可以表述為
ht=ot.tanh(ct)
(6)
上述所有式中,“· ”表示逐點乘積。
2.4 自注意力機制

自注意力機制是注意力機制的一種特殊情況,其注意力機制的基本思想是用來表示目標文本Target中的某一個元素Query與來源文本Source中的每個元素keyi之間的重要程度,公式表示如式(7)所示。而自注意力機制是表示的是Source內部各元素之間或者Target內部各元素之間發(fā)生的注意力機制,即可以理解為Source=Target。自注意力機制的計算過程如圖5所示,主要分為3個階段。

圖5 注意力機制計算過程
Attention(Query,Source)

(7)

s=wstanh(WwHT+bw)
(8)
階段2是使用SoftMax函數(shù)對階段1得到的權重向量s進行歸一化處理,得到注意力向量u,例如圖5所示的u=[u1,u2,u3,u4],公式如式(9)所示

(9)


(10)
2.5 SoftMax分類器


(11)
最后將特征拼接向量V輸入到SoftMax函數(shù)對文本情感進行分類,并將分類結果轉化為[0,1]之間的概率值。具體計算公式表述為:
yi=softmax(wcV+bc)
(12)
其中:上式中的softmax函數(shù)的計算公式為
(13)
其中xiL為式(13)在L層所計算得到K維矩陣的第i個分量。
3 實驗過程及結果
為了驗證基于多特征LSTM-Self-Attention模型的有效性,本文采用中文電影評論數(shù)據(jù)集進行驗證。實驗分為三組進行,實驗一使用LSTM-Self-Attention模型和經典的LSTM模型做實驗并進行對比分析;實驗二采用經典的LSTM模型和多特征的LSTM模型進行實驗對比;
實驗三采用基于多特征LSTM-Self-Attention模型和經典的LSTM模型進行實驗對比分析。
3.1 數(shù)據(jù)集及實驗環(huán)境
本文的實驗是在 Windows 7系統(tǒng)下進行,編程語言為 Python3.6,開發(fā)工具為PyCharm,使用到的深度學習框架為 TensorFlow。為了證明該模型的有效性,數(shù)據(jù)集是從谷歌公司旗下kaggle網站上提供的豆瓣電影簡短評論數(shù)據(jù)集中選取的《復仇者聯(lián)盟》和《大魚海棠》兩部電影評論,其情感分為5個級別,數(shù)據(jù)形式如表2所示。該數(shù)據(jù)集的情感級別越高代表對該電影的喜愛程度越高,例如5代表非常喜愛該電影,而1代表非常討厭該電影,由于該數(shù)據(jù)集屬于弱標注信息。弱標注信息與評論情感語義有一定的相關性,因此,可以用作訓練情感分類問題。但由于使用弱標注數(shù)據(jù)的挑戰(zhàn)在于如何盡量減輕數(shù)據(jù)中噪聲對模型訓練過程的影響,因此,在進行訓練前還對該數(shù)據(jù)集進行了預處理,包括去燥,修改評論與評分不一致的數(shù)據(jù);替換網絡用語、表情符號等。在實驗時該數(shù)據(jù)集被劃分為3個子數(shù)據(jù)集,其中,訓練集數(shù)據(jù)為11700條,驗證集數(shù)據(jù)為1300條,測試集數(shù)據(jù)為1300條。

表2 電影評論數(shù)據(jù)
3.2 評價指標
為了評價本文提出的分類模型的效果,本文采用文本分類領域常用的評級指標——準確率(Accuracy,A)、精確率(Precision,P)和召回率(Recall,R)以及F1值對模型進行檢驗。根據(jù)分類結果建立的混合矩陣如表3所示。

表3 分類結果混合矩陣
準確率是指正確分類的樣本數(shù)與樣本總數(shù)之比率,其計算公式如下

(14)
精確率衡量的是類別的查準率,體現(xiàn)了分類結果的準確程度,其計算公式如下

(15)
召回率衡量的是類別的查全率,體現(xiàn)了分類結果的完備性,其計算公式如下
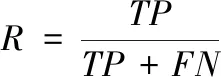
(16)
F1衡量的是查全率和查準率的綜合指標,以及對它們的偏向程度,其計算公式如下

(17)
3.3 實驗結果及分析
本文對經過預處理的電影評論進行實驗,經過過多次訓練獲取模型的最優(yōu)超參數(shù)集合如表4所示。

表4 模型訓練參數(shù)
在模型訓練完成后對實驗結果進行分析,為了直觀觀察分析準確率和損失值隨著訓練次數(shù)迭代的變化情況,本文運用Origin工具將訓練結果可視化處理。圖6、圖7分別為本模型在中文電影評論情感分類的準確率和損失值的變化圖,其中黑色曲線表示訓練集的訓練結果,紅色曲線表示驗證集的結果。由圖中可以看出,在中文電影評論情感分類的準確率最終平穩(wěn)在51.0%左右,損失值平穩(wěn)在1.31附近。

圖6 中文電影評論情感分類準確率

圖7 中文電影評論情感分類損失值
三組對比實驗的結果如表5所示,從表中可以得出,LSTM-Self-Attention模型[22]的準確率為50.23%,比LSTM模型[12]的準確率49.50%提高了0.73%,證明了自注意力機制能夠提高情感分類的準確率。基于多特征LSTM模型[19]的準確率50.00%,對比LSTM模型的精確率提高了0.05%,說明加入詞性特征能夠些微地提高電影評論情感分類效果。而本文提出的基于多特征LSTM-Self-Attentionde 的方法準確率為51.24%,相比經典的LSTM模型提高了1.74%,說明本文在LSTM模型上加入自注意力機制和詞性特征能提高電影評論情感分類的準確率。

表5 中文電影評論情感分類結果
從圖8各個評價指標的直方圖可以更加直觀的看出,本文提出的基于多特征LSTM-Self-Attention模型取得更高的分類準確率,證明本文提出的方法是有效的。

圖8 中文電影評論情感分類直方圖
4 結論
針對傳統(tǒng)循環(huán)神經網絡存在的梯度消失和梯度爆炸的問題,本文使用LSTM模型對文本情感進行分類,為了減少任務的復雜度,本文還將自注意力機制加入到LSTM模型中;此外,為了提高最終的分類效果,文本還將文本的詞性特征作為模型的輸入,并在最后使用中文電影評價數(shù)據(jù)集進行實驗驗證。實驗結果表明了本文提出的多特征LSTM-Self-Attention方法的可行性,可以更準確對文本情感進行分類。但是注意力機制的缺點也不容小覷,計算成本的增加使得時間和空間復雜度增加,在計算過程中如若輸入的文本長度過長,計算量呈爆炸式增長。此外,相比于經典的LSTM模型,LSTM-Self-Attention模型的實驗結果并沒有提高很多。下一步工作將對自注意力機制進行優(yōu)化,減少計算量,進一步提高文本情感分類效率和準確率。
猜你喜歡
數(shù)學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數(shù)理化·七年級數(shù)學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數(shù)理化·七年級數(shù)學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
