基于ARMA-LSTM組合模型的鐵路客流量預測
2021-12-14 01:37:38宋曉宇金莉婷
計算機應用與軟件 2021年12期
孫 越 宋曉宇 金莉婷 劉 童
(蘭州交通大學電子與信息工程學院 甘肅 蘭州 730070)
0 引 言
近年來,由于全球地鐵、高鐵和磁懸浮列車等方面的高速發展和建設,國內外在客流量預測方面也做了大量的研究與應用。文獻[1]提出了一種基于神經網絡和起止點矩陣估計的分治方法,實現了對到達各站或離開各站的旅客數量的短期客流預測,并得到了短期內的OD矩陣。文獻[2]構建了BP神經網絡與灰色預測模型的組合預測模型,彌補了單個模型預測時的不足之處,得到的預測結果均優于傳統灰色預測模型。文獻[3]研究了ARIMA模型在航空市場需求預測中的應用,對濟南至廈門航線的客流進行了分析。文獻[4]通過塞爾維亞鐵路網實現的月旅客統計的歷史數據,得出時間序列具有較強的季節特征自相關。采用了季節性差分自回歸滑動平均模型(SARIMA)來擬合并預測,結果表明該方法具有較好的預測性能。文獻[5]提出了一種基于深度學習長短期記憶(LSTM)網絡結構的地鐵站短時客流預測方法。將預測結果與典型時間序列預測算法MLR和BP神經網絡進行對比,驗證了LSTM網絡在地鐵站短時客流量預測中具有更高的準確性和很好的適用性。文獻[6]用小波變換將處理后的民航客流量信號分解,得到復雜信號的波動特征,再將其輸入到BP神經網絡中進行預測,效果較好。
如今機器學習發展迅速,研究表明機器學習算法能夠很好地處理季節性和非線性的數據[7]。其中有應用于眾多領域的人工神經網絡ANN(Artificial Neural Networks)模型,它具有很強的自適應和非線性函數逼近能力,不過ANN也存在一定的局限性,比如它在訓練過程中易陷入局部極小值,從而出現過擬合和收斂速度過慢的現象[8]。此外,前饋神經網絡的預測方法基本是通過前面的部分數據來預測的,它沒有記憶和利用歷史數據的功能,但對于時間序列而言前后數據之間可能存在密切的依賴關系模式沒有被充分利用[9]。循環神經網絡RNN(Recurrent Neural Network)中的隱含層具有記憶功能,通過回憶過去來對當前作出判斷,但在實際的應用中RNN容易產生梯度消失和梯度爆炸的問題[10]。Hochreiter等[11]在RNN的基礎上做了改進后提出了LSTM模型,目前LSTM多用于語音識別、手寫識別和自然語言處理等方面。本文提出一種基于LSTM模型和ARMA模型相結合的方法來解決鐵路客流量的預測問題,研究結果表明這種組合模型預測方法比單一預測方法的準確性要高。
1 數據集與預處理
1.1 數據預處理
本文所采用的數據是某個區段內客運專線2015年1月至2016年3月的旅客列車梯形密度表。該數據集中包含了每天每個車次在所經過站點的上下車人數,所以需要從中提取出有用的信息,得到一個每天各個站點的客流量數據。對數據表進行數據清洗,主要包括缺失值和異常值的處理。缺失值處理選用了拉格朗日插值法來進行補值,首先從原始數據中確定因變量和自變量,取出缺失值前后3個數據(前后數據中遇到數據不存在或者為空的,直接將數據舍去,將僅有的數據組成一組),將取出來的6個數據組成一組,然后采用拉格朗日多項式插值公式:
(1)
(2)
式中:x為缺失值對應的下標序號;L(x)為缺失值的插值結果;xi為非缺失值yi的下標序號。對所有的缺失數據逐個做插補操作,直到沒有缺失值為止。對于數據集中的異常值主要采取以下兩種處理方法:視為缺失值進行插補和取前后數據平均值進行修正。
1.2 特征提取
本文以ZD111-01站點為例,對其數據序列進行特征提取,所用方法為移動平均法,它是根據時間序列逐項推移,依次計算包含一定項數的序列平均數,以此構造出原始序列的特征的向量。類似地,用移動方差算法和移動標準差算法,其具體做法是根據不同的移動窗口M計算出了窗口中M個數據的方差和標準差,然后窗口進行逐一移動,將得到的一系列方差和標準差作為特征序列。
Adaptive-Lasso變量選擇方法[12]是1996年被提出的將參數估計與變量選擇同時進行的一種正則化方法,這里用該方法從構造的特征序列中篩選識別出關鍵特征。篩選結果如表1所示,其中移動窗口為7天、10天、14天的移動平均序列(分別用JZ7、JZ10、JZ14表示)和移動標準差序列(分別用BZ7、BZ10、BZ14表示)的影響較高,y代表原始客流量自身,相關度為1。

表1 各特征與原始客流量的相關系數
在對原始序列的分析過程中,采用statsmodels工具包中的seasonal_decompose方法得到了它的周期為7天,如圖1所示,這與經驗分析也相符,因此將用與原始序列對應的上個7天的所有數據作為一列特征向量。
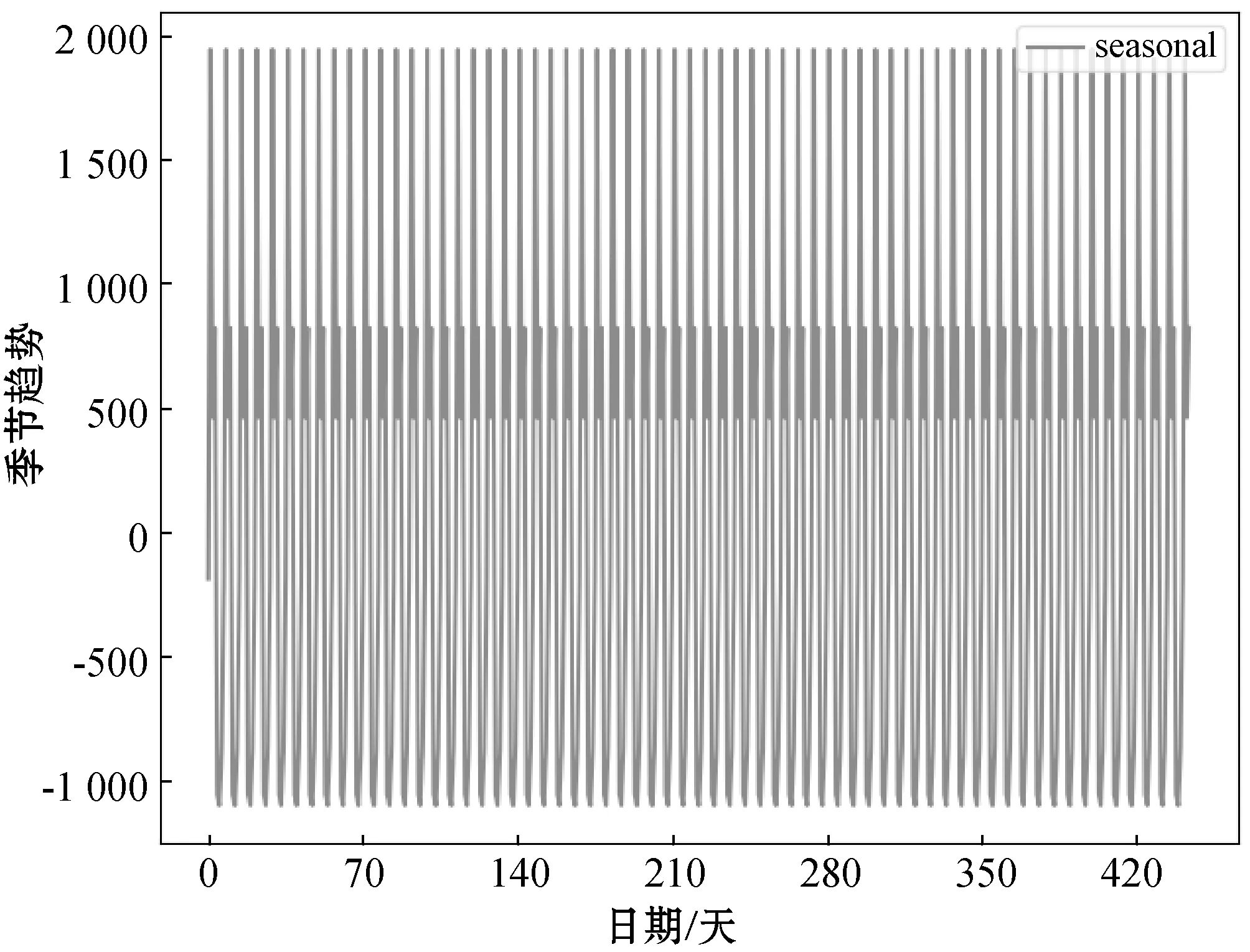
圖1 序列周期圖
2 基于ARMA-LSTM的鐵路客流量預測模型
2.1 ARMA
ARMA模型的全稱是自回歸移動平均模型,它和自回歸模型(AR模型)、移動平均模型(MA模型)是目前比較常用的擬合平穩時間序列的模型。顯然,AR模型和MA模型都是ARMA模型的特例,而且它們也可看作是多元線性回歸模型。自回歸移動平均模型,簡記為ARMA(p,q)模型[13]。模型結構可表示為:
χt=φ0+φ1χt-1+φ2χt-2+…+φpχt-p+
εt-θ1εt-1-θ2εt-2-…-θqεt-q
(3)
式中:φ表示AR的系數;θ表示MA的系數;當在t時刻時,隨機變量Xt的取值xt是前p期xt-1,xt-2,…,xt-p和前q期εt-1,εt-2,…,εt-q的多元線性函數;εt是誤差項在t時刻的隨機干擾,那么可以得出xt主要是受過去p期的序列值和過去q期的誤差項的兩方面影響。當q=0時,則為AR(p)模型;當p=0時,為MA(q)模型。
所研究的時間序列經過預處理后,如果經過白噪聲監測后被判定為平穩非白噪聲序列,那么就可以用ARMA模型來對平穩非白噪聲序列進行建模:首先計算平穩非白噪聲序列的自相關系數(ACF)和偏自相關系數(PACF);然后進行模型的定階,由AR(p)、MA(q)和ARMA(p,q)的自相關系數和偏自相關系數的性質來選擇合適的模型,識別原則見表2;再估計模型中未知參數的值并檢驗模型;最后優化模型進行預測。上述模型要求時間序列為平穩序列,而實際上遇到的絕大部分序列是非平穩的,對這種序列可以使用ARIMA模型進行擬合。ARIMA模型的原理是把差分運算與ARMA模型相結合[14]。
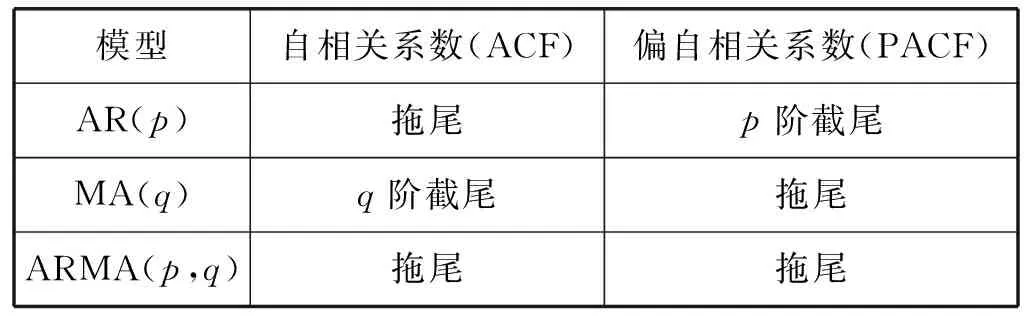
表2 ARMA模型識別原則
模型定階(確定p和q)的方法有很多,常用的一種是通過序列的自相關函數和偏自相關函數來定階,如果無法得到p和q準確的最優值,可利用赤池信息量準則(Akaike Information Criterion,AIC)或貝葉斯信息準則(Bayesian Information Criterion,BIC)進行定階[15]。
2.2 LSTM
循環神經網絡RNN近些年在時間序列預測分析方面也是一種比較常用的模型,與普通神經網絡相比,RNN的隱含層的每次計算結果都與當前輸入以及上一次的隱含層結果有關,而普通神經網絡的計算結果之間是相互獨立的[16-18]。通過這種結構,RNN的計算模型具備了對先前數據的記憶能力。圖2為基本的RNN結構,右側的展開結構更加詳細地說明了RNN的原理。其中:x為輸入層,o為輸出層,s為隱含層,t是指第幾次的計算;V、W、U為權重,在計算第t次的隱含層狀態時為St=f(UXt+WSt-1),這樣便可以使得當前節點的輸入結果與之前結果產生關聯。
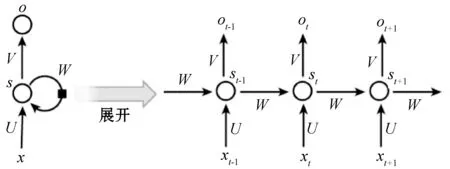
圖2 RNN模型結構
如果需要對數據序列進行長期記憶的話,那么RNN模型里面當前隱含層的計算結果要與前n次的計算產生聯系。這樣會使得計算量呈指數式增長,導致模型在訓練時消耗大量時間,而對RNN進行改進后的LSTM模型能夠很大程度上避免該問題。LSTM模型的特點就是在RNN的每個神經元內部增加了三類控制記憶單元狀態的門結構,分別是輸入門(input gate)、遺忘門(forget gate)和輸出門(output gate)。輸入門決定保存哪些信息到存儲單元中。遺忘門決定何時忘記輸出結果,從而為輸入序列選擇最佳的時間間隔。輸出門獲取所有計算結果并為cell生成輸出[19]。典型的LSTM結構如圖3所示。

圖3 典型的LSTM結構
在本文的客流量預測模型中,輸入的時間序列表示為X=(x1,x2,…,xt),隱藏狀態單元表示為H=(h1,h2,…,ht),輸出序列表示Y=(y1,y2,…,yt)。LSTM的計算方法如下:
ht=H(Whyxt+Whhht-1+bh)
(4)
yt=Whyht+by
(5)
上面描述的LSTM結構通過以下計算式實現:
it=σ(Wxixt+Whibt-1+Wcict-1+bi)
(6)
ft=σ(Wxfxt+Whfbt-1+Wcfct-1+bf)
(7)
ct=ft×ct-1+it×tanh(Wxcxt+Whcht-1+bc)
(8)
ot=σ(Wxoxt+Whobt-1+Wcoct-1+bo)
(9)
ht=ottanh(ct)
(10)
式中:σ和tanh表示LSTM模型中特定的激活函數,σ代表式(5)中定義的標準Sigmoid函數,Sigmoid層輸出的數值在0到1之間,表示每個部分會有多少量可以通過,“0”表示不會有任何的量通過,“1”則表示允許任意的量通過;i、f、o和c分別表示輸入門、遺忘門、輸出門和單元激活向量;c需要與隱藏向量h相同;W為權重項;b為各自所對應的偏置項。輸入門可以確定什么樣的新信息向量x被存放在存儲單元狀態中,輸出門能夠使存儲單元對輸出產生影響。最后,遺忘門決定存儲單元記住或忘記其以前的狀態[19]。
2.3 ARMA-LSTM模型
本文所研究的客流量問題中需要預測的時間序列顯然是一種復雜的非線性的序列,其中包含了不止一種數據特征(線性、非線性和周期性等),而對于單一預測模型來說就不能很好地捕獲數據的各個特征[7],具有一定的片面性。模型組合的方法能在一定程度上緩解該問題[20-22],于是本文提出一種基于深度學習方法的ARMA-LSTM模型。該模型主要由三部分組成,第一部分是通過ARMA模型得到預測結果;第二部分是通過LSTM模型得到預測結果;第三部分則是通過優化算法給之前得到的預測結果分配適當的權重系數,再將兩種方法的預測結果相加,從而得到最后的預測結果。假設yt(t=1,2,…,n)是實際的時間序列數據,fit(i=1,2)是兩種方法的預測結果,wi是第i種預測方法的權重系數,那么組合模型的預測值Yt可以表示為:
(11)
(12)
同時可以得到組合模型預測方法的誤差:
(13)
式中:f1t和f2t分別為ARMA和LSTM在t時刻的預測結果;wi(i=1,2)是分配給ARMA和LSTM的權重系數;eit(i=1,2)是ARMA和LSTM在t時刻的誤差。這樣將ARMA與LSTM的預測結果分別乘以各自對應的權重系數,就可以得到組合模型的預測結果。
3 實驗與結果分析
3.1 基于ARMA-LSTM模型的鐵路客流量預測
通過之前的數據提取,得到了2015年1月到2016年3月ZD111-01站點的客流量數據,以下實驗將用此列數據來完成。經過對數據的分析了解到節假日對客流量的影響很大,因此選取了2015年12月27日至2016年1月20日、2016年2月1日至2016年2月20日、2016年2月24日至2016年3月14日的三段數據分別作為測試集,為了簡化表示,在之后內容中簡稱為1月、2月和3月,這其中主要包含了元旦和春節假期。
用ARMA模型來預測時,首先對數據序列進行平穩性檢驗(用的方法是單位根檢驗)和白噪聲檢驗,判定是否為平穩非白噪聲序列。然后進行模型識別,再分別通過BIC和AIC信息準則對模型定階,最后進行預測。在得到的預測結果中選擇出誤差較小的模型,這里所采用的評價指標是平均絕對百分比誤差MAPE(Mean Absolute Percentage Error)。
在進行2015年12月27日至2016年1月20日的客流量預測中,BIC定階的ARIMA(5,1,5)模型要比其他AIC和BIC分別定階的ARMA模型和ARIMA模型的誤差更低,預測結果如圖4所示。
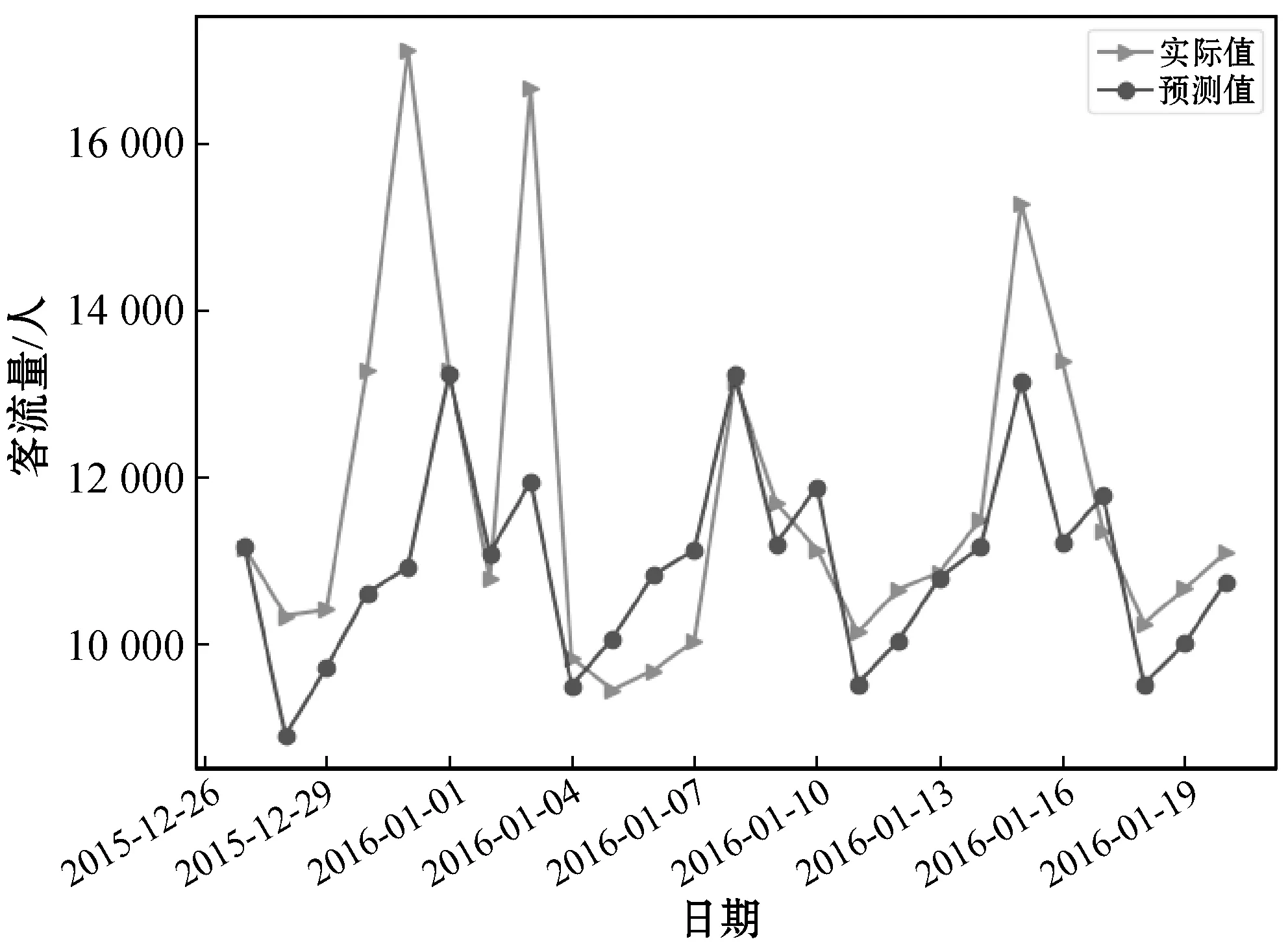
圖4 ARIMA(5,1,5)在2016年1月的預測結果
接著搭建LSTM模型,這里主要調用TensorFlow來實現,采用Python 3.5進行程序編寫,定義的LSTM網絡包含兩個隱層,有10個隱層神經元。輸入的數據是之前經過特征提取得到的移動窗口為7天、10天、14天的移動平均序列和移動標準差序列,以及與原始序列對應的上一個7天的數據序列。經過反復實驗,模型的參數batch_size=1、time_step=7、learning_rate=0.000 6、訓練次數為1 000次時預測效果最好。2015年12月27日至2016年1月20日的客流量預測結果如圖5所示。
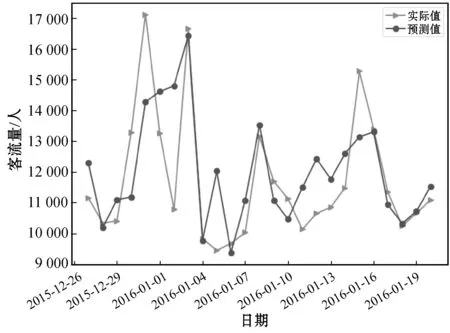
圖5 LSTM在2016年1月的預測結果
最后,選擇用BP神經網絡對權重進行優化,保證組合模型具有最優的擬合效果,進而得出最終的預測結果。經過多次實驗,確定BP神經網絡參數batch_size=7,nb_epoch=5 000,隱含層神經元為10個,ReLU函數作為激活函數。運算后得到2015年12月27日至2016年1月20日的客流量ARMA-LSTM模型預測結果如圖6所示。
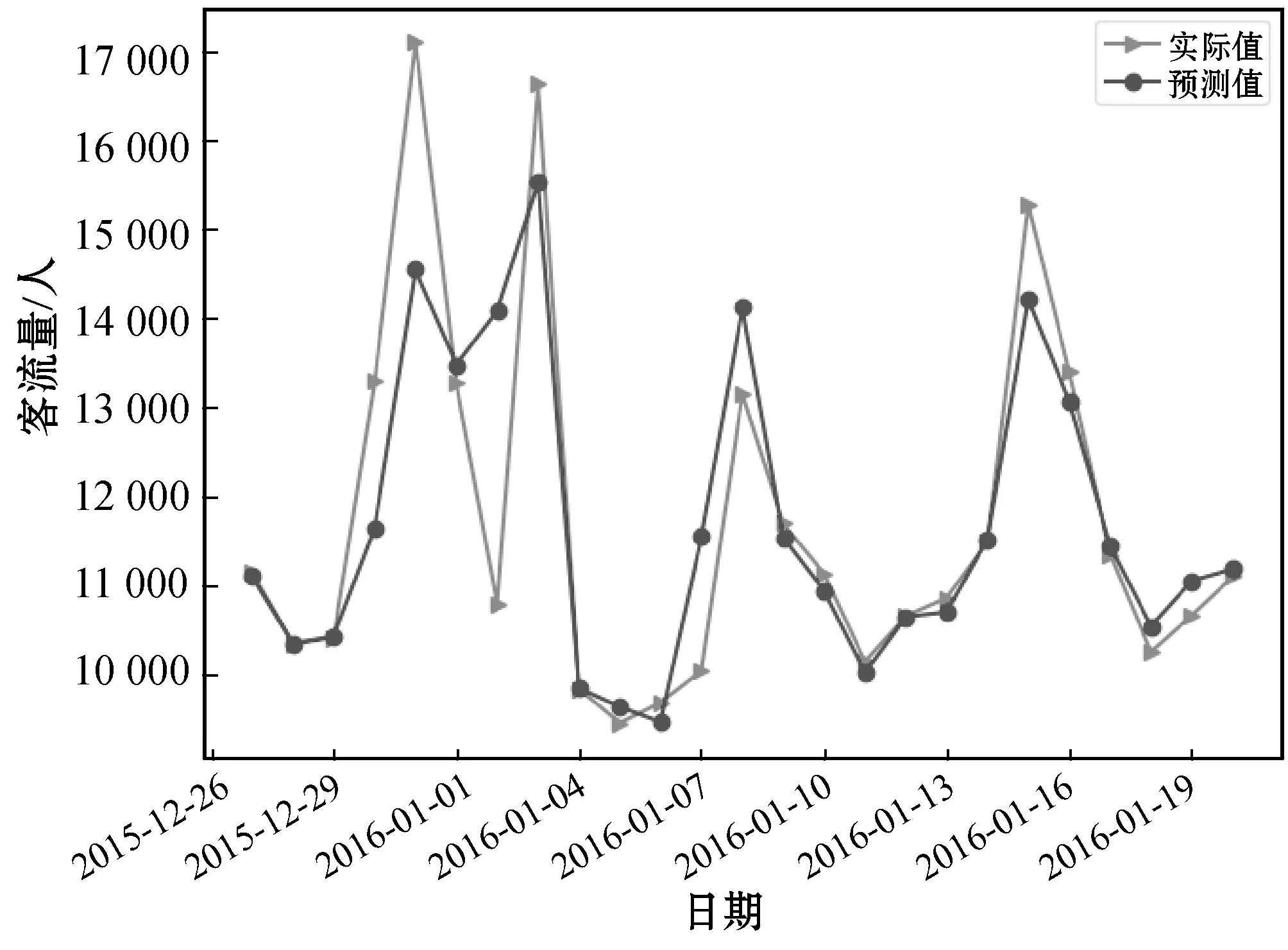
圖6 ARMA-LSTM在2016年1月的預測結果
通過重復上述步驟,圖7-圖12給出了各模型分別對2月和3月的預測結果。
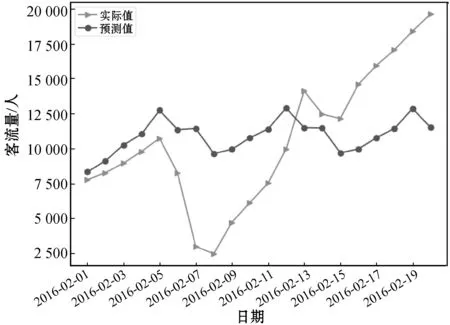
圖7 ARIMA(5,1,5)在2016年2月的預測結果
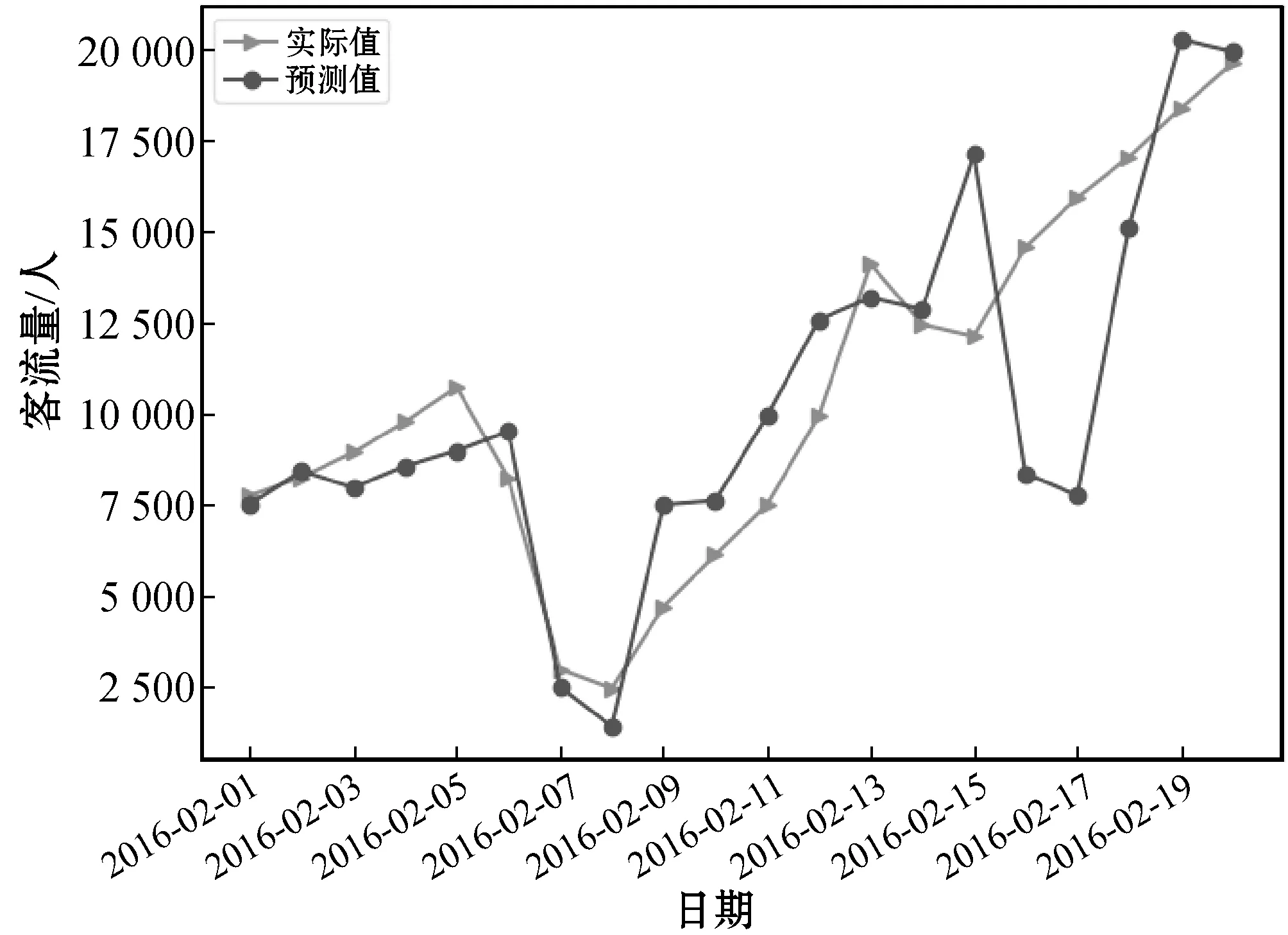
圖8 LSTM在2016年2月的預測結果
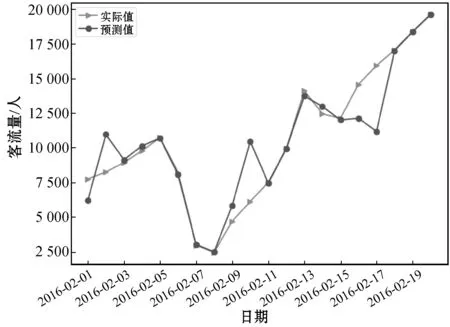
圖9 ARMA-LSTM在2016年2月的預測結果
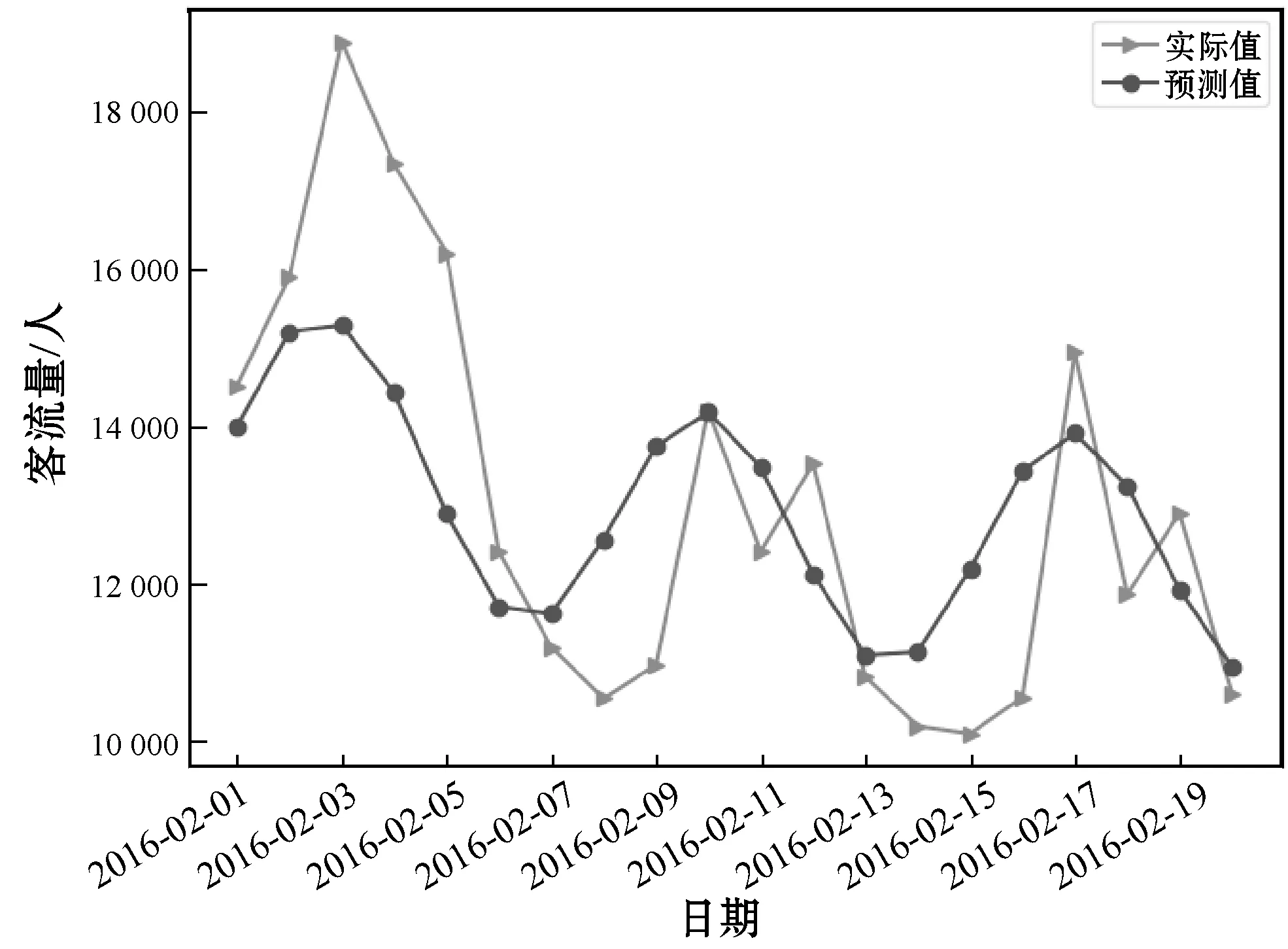
圖10 ARMA(4,2)在2016年3月的預測結果
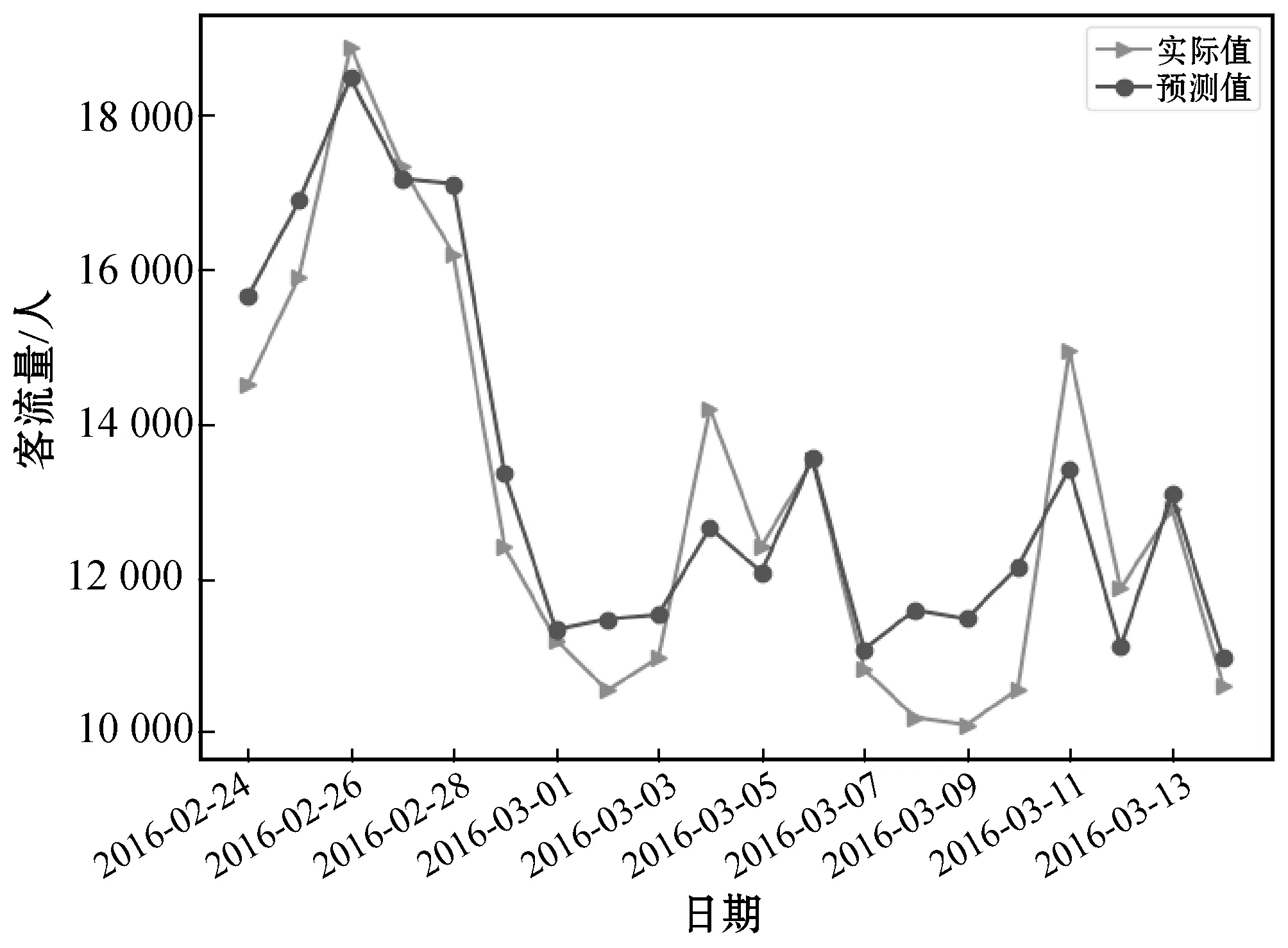
圖11 LSTM在2016年3月的預測結果
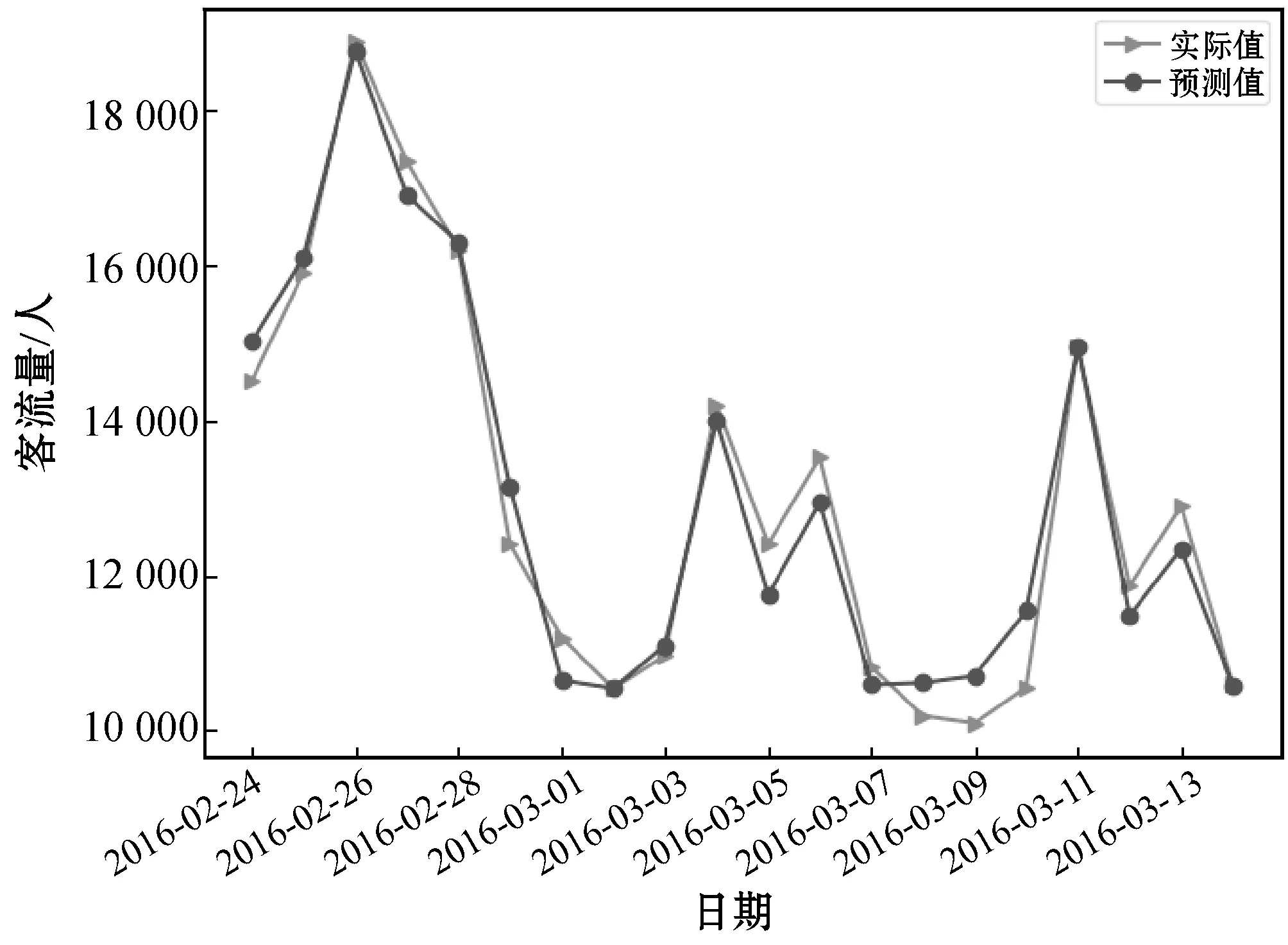
圖12 ARMA-LSTM在2016年3月的預測結果
圖7中的2月7日是農歷除夕,很明顯出現了與實際值較大的誤差,這也驗證了ARIMA模型在處理這類非線性有劇烈增長和降低的數據時存在的不足。
3.2 評價指標
為了更好地比較不同模型之間的預測效果,本文采用均方根誤差(RMSE)和平均絕對百分比誤差(MAPE)兩種常見的評價指標來量化模型的性能。計算式分別為:
(14)
(15)
式中:N是樣本的總數;yi和pi分別是第i個樣本數據的真實值和預測值,前者能夠很好地反映測量的精度,后者可以衡量一個模型預測結果的好壞。
3.3 模型對比分析
為了更好地分析和對比ARMA-LSTM模型在本次鐵路客流量預測中的預測效果,加入了灰色模型GM(1,1)用相同數據進行預測,該模型是使用最廣泛的灰色預測模型之一[23]。然后將GM(1,1)與LSTM進行組合,這里同樣用BP神經網絡對權重進行優化,得到GM-LSTM組合模型的預測結果。下面用RMSE和MAPE兩種指標評價五種模型的預測效果,數值越小代表預測效果越好。
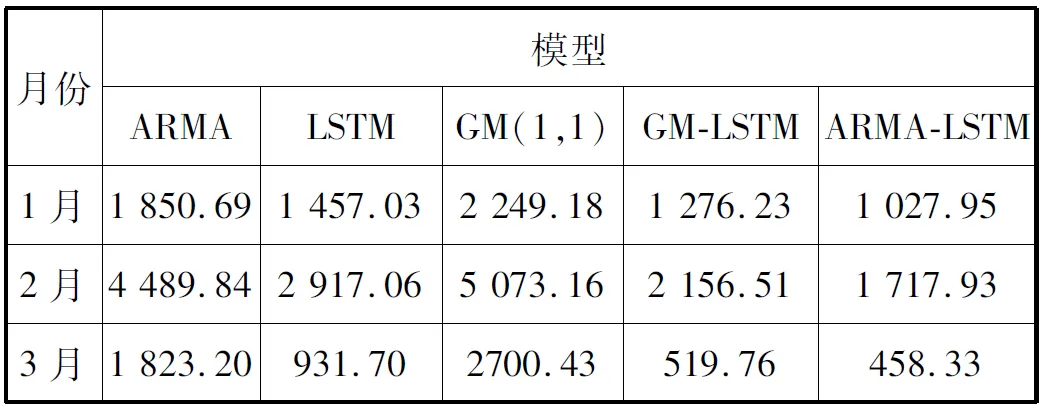
表3 五種預測模型的RMSE值
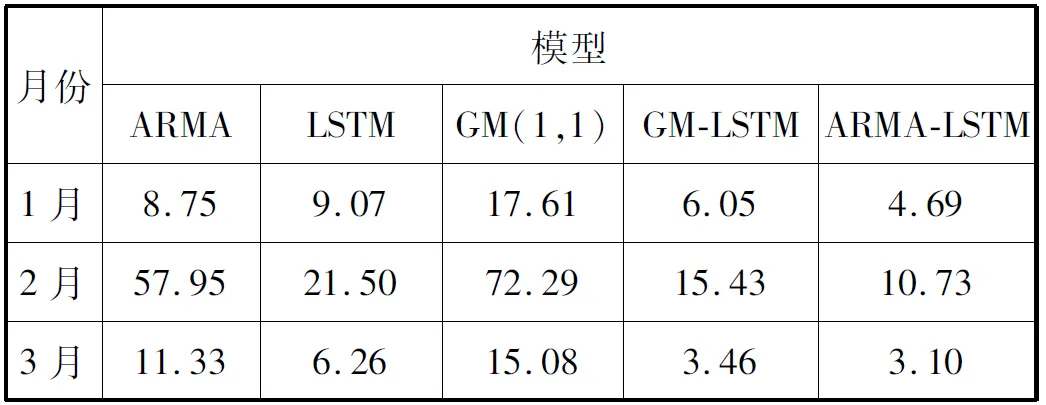
表4 五種預測模型的MAPE值(%)
通過對表3和表4中的數值作比較,可以看出ARMA-LSTM組合模型的預測效果明顯優于其他四種模型。三種單一模型中LSTM模型的預測效果較好,但結合圖4-圖12發現LSTM在一些日期中并沒有ARMA擬合得好,在將兩模型進行組合后預測效果得到明顯提升,因此組合模型ARMA-LSTM不僅在準確性上有了提高,而且在應用場景上吸收了兩種模型優勢后適用性也高于單一模型。
4 結 語
本文針對鐵路客流量問題提出一種基于權重分配的ARMA-LSTM組合模型,利用BP神經網絡算法進行優化,將ARMA模型和LSTM模型進行組合來預測鐵路的客流量。實驗結果分析和比較表明該模型彌補了普通單一模型在實際預測中的不足,提高了客流量預測的準確性以及在該領域中的適用性。而且這種基于神經網絡的模型在參數設置和模型訓練等方面仍有優化空間,在后續的研究中可繼續完善模型以達到更好的預測效果,并且能夠使該模型運用到不同的領域中。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
