英語學習者作文自動評分特征選擇及模型優(yōu)化研究
2021-12-14 01:37:28劉磊
計算機應用與軟件 2021年12期
劉 磊
(燕山大學外國語學院 河北 秦皇島 066004)
0 引 言
作文是評測英語學習者語言能力的重要指標。目前,在英語教學和測試領域,學習者作文通常依靠人工審閱,耗費大量人力和物力,同時很難保證評測結果的可信度和有效性[1]。為了改善這一狀況,近年來國內外學者開始借助機器學習和自然語言處理技術,利用計算機自動評測學習者的作文質量[2]。作文自動評分(Automated Essay Scoring,AES)系統(tǒng)可用于TOEFL和GRE等大規(guī)模、高影響力的語言水平測試,作為輔助手段驗證人工評分的信度,如果二者相差較大,則需重新評估作文質量[3]。此外,AES系統(tǒng)也適用于非考試環(huán)境下的網(wǎng)絡自主學習平臺,在學生提交作文后提供實時反饋,通過動態(tài)評估督促其修改作文,提高二語寫作水平[4]。本文結合計算機科學和語言學領域的研究方法,采用基于機器學習的統(tǒng)計算法,提取學習者文本的詞匯、語法和語篇特征,從文本復雜度、語法正確度和語篇連貫度等層面構建評分模型,提高現(xiàn)有AES系統(tǒng)的性能。
1 相關工作
AES研究始于20世紀60年代,在當時的技術條件下,計算機并不對輸入文本進行語言學分析,只采用簡單的表層特征,如平均詞長、句長和標點符號數(shù)量等評測作文質量[5]。但是,由于當時計算機普及程度較低,運算能力有限,導致AES研究一度陷入沉寂。直至20世紀90年代,隨著計算機軟硬件性能的提高和自然語言處理技術的進步,AES研究重新煥發(fā)生機,出現(xiàn)了一批面向商業(yè)應用的英語作文自動評閱系統(tǒng)[6],如Measurement Inc.公司的Project Essay Grader、美國教育考試處的E-rater和Pearson Knowledge Technologies公司的Intelligent Essay Assessor。然而,由于版權原因,上述商用AES系統(tǒng)均未公開訓練和測試數(shù)據(jù),文獻中也未涉及詳細的算法介紹。因此,雖然這些系統(tǒng)聲稱機器評分信度已達到甚至超過人工評分,但研究者無法在相同數(shù)據(jù)的基礎上對比不同評分方法的優(yōu)劣,繼續(xù)提高AES系統(tǒng)的性能。為了改善這一狀況,近十年來,從事AES研究的學者陸續(xù)建立了一批可供研究者免費使用的英語學習者語料,如劍橋FCE和TOEFLL11考試作文語料庫,使得基于公開數(shù)據(jù)集的系統(tǒng)評測成為可能[7]。現(xiàn)有的基于FCE數(shù)據(jù)集的AES系統(tǒng)如表1所示。

表1 現(xiàn)有基于FCE數(shù)據(jù)集的AES系統(tǒng)
可以看出,Yannakoudakis等[8]使用FCE語料庫,從中提取N元序列、句法復雜度和語法錯誤數(shù)量等文本特征,使用支持向量回歸(Support Vector Regression,SVR)算法訓練AES模型,系統(tǒng)機評與人評分數(shù)的Pearson相關系數(shù)r和Spearman相關系數(shù)ρ分別達到0.741和0.773。Yannakoudakis等[9]和Zhang等[10]在上述研究基礎上增加了語篇連貫特征,改進后的評分模型將Pearson和Spearman相關系數(shù)提升為0.761和0.790,均方根誤差為3.988。Farag等[11]采用基于詞向量和卷積神經(jīng)網(wǎng)絡(Convolutional Neural Network,CNN)的深度學習算法構建評分模型,但其準確率低于基于語言學特征的SVR模型。因此,本文著重探討如何細化語言學特征的選取及優(yōu)化SVR模型,從以下三方面提高現(xiàn)有AES系統(tǒng)的性能。
(1) 降低詞袋特征維度。現(xiàn)有AES系統(tǒng)通常采用由單詞和詞性N元序列構成的詞袋(Bag of Words,BOW)特征訓練評分模型。假設訓練集的詞匯數(shù)量為V,則可能的N元序列多達VN,造成維度災難,影響系統(tǒng)性能。現(xiàn)有研究多采用頻率閾值降低特征維度。本文利用互信息值(Mutual Information,MI)篩選詞袋特征,選取與作文分數(shù)高度相關的特征子集。
(2) 細化語言學特征。文本復雜度、語法錯誤數(shù)量和語篇連貫度等深層語言學特征與英語學習者書面語質量關系密切[12]。現(xiàn)有研究只使用了平均詞長和句長等表層特征測量文本復雜度,未涉及詞匯豐富度和詞匯難度等指標。Yannakoudakis等[8]采用RASP句法分析器自動剖析學習者作文的句法結構,通過計算主語-謂語、謂語-賓語等語法關系間的平均距離評測句法復雜度。但這種方法未考慮句子的層級結構,如簡單句、復雜句、從句和復雜名詞短語比例等指標,無法全面反映學習者書面語的句法復雜性。此外,現(xiàn)有研究的語法錯誤檢測模塊多采用統(tǒng)計方法,借助外部語料庫計算作文中的二元或三元詞組概率,如果概率低于設定閾值則判定為語法錯誤。但這種方法只能分析相鄰序列的概率,無法檢測涉及長距離語法關系的語誤(如主謂不一致錯誤)。語篇連貫包括局部連貫和整體連貫兩個層次,分別考察語篇句子間和段落間的語義關聯(lián)[13]。現(xiàn)有研究通過計算作文中相鄰句子的語義相似度評測作文連貫性,忽略了文本的整體連貫度。為解決上述問題,本文從文本表層特征、詞匯多樣性、文本可讀性和句法復雜度四個方面評估文本復雜度;采用基于語法規(guī)則的鏈語法分析器檢測語法錯誤;從局部和整體兩個維度考察語篇連貫性。
(3) 融合稀疏和非稀疏特征。使用詞袋特征構建AES模型時,需要將文本表征為一個包含N元序列頻數(shù)的向量。N元序列數(shù)量龐大,每個文本只包含少數(shù)序列。因此,詞袋特征向量的多數(shù)元素為0,屬于稀疏特征。而由文本復雜度、語法錯誤數(shù)量和語篇連貫度構成的語言學特征為連續(xù)性數(shù)值變量,屬于非稀疏/稠密特征。現(xiàn)有研究構建評分模型時,將詞袋向量vbow和語言學向量vling合并為向量v=(vbow_1,vbow_2,…,vbow_m,vling_1,vling_2,…,vling_n),其中,m和n為詞袋和語言學特征的數(shù)量。由于m?n,經(jīng)過數(shù)據(jù)標準化處理的語言學特征權重降低,無法體現(xiàn)其重要性。因此,本文使用Stacking集成學習算法[14]將詞袋特征轉換為非稀疏的實數(shù)值后構建AES模型。
2 方法設計
為便于與先前研究展開對比,本文選用FCE語料庫訓練和評測作文評分系統(tǒng)。總體框架如圖1所示,其包括數(shù)據(jù)預處理、特征篩選、模型構建和模型評測四個部分。
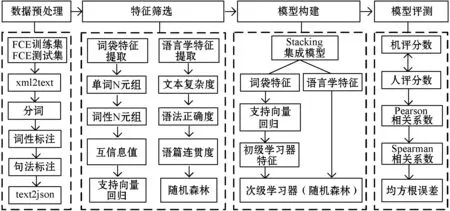
圖1 AES評分系統(tǒng)總體框架
2.1 詞袋特征提取與篩選
1) 特征提取。首先從訓練集提取所有N元序列集合V,然后將訓練和測試集中的每篇作文轉換為|V|維向量,|V|代表序列種類。假設V={v1,v2,…,v|V|},則文本d可表征為向量d=(c(v1,d),c(v2,d),…,c(v|V|,d))。其中c(v,d)是序列v在文本d中的出現(xiàn)頻率。詞袋特征由長度為1~3的單詞和詞性序列構成。例如,作文“What clothes should I taken? How much money should I taken? And how could we meet at the airport? I am looking forward your reply.”中包含的單詞和詞性序列如表2所示。其中,詞性賦碼PRP表示代詞,VB為動詞原形,MD為情態(tài)動詞[15]。

表2 詞袋特征提取
N元序列體現(xiàn)了詞匯間的固定搭配關系;不同水平作文中的序列種類和數(shù)量存在差異,能夠反映學習者英語的準確度和流暢度。如上例中的三元詞性序列“MD PRP VBN”可檢測作文中兩例情態(tài)動詞+動詞的誤用現(xiàn)象“should I taken”。
2) 特征篩選。如式(1)所示,本文通過N元序列長度和互信息篩選原始特征集合BOW,得到特征子集BOWsub。其中:lenv為單詞和詞性序列的長度;tlen為長度閾值;MIv為序列的互信息值;tmi為互信息閾值。tlen和tmi由人工設定取值范圍,最終根據(jù)SVR模型誤差確定最佳值。
BOWsub={v∈BOW|lenv
(1)
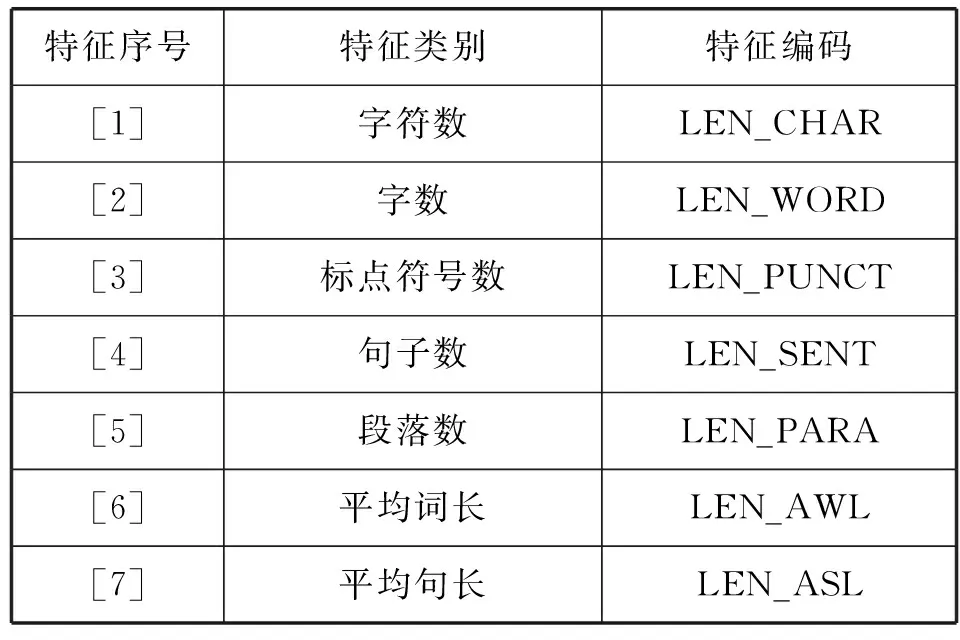
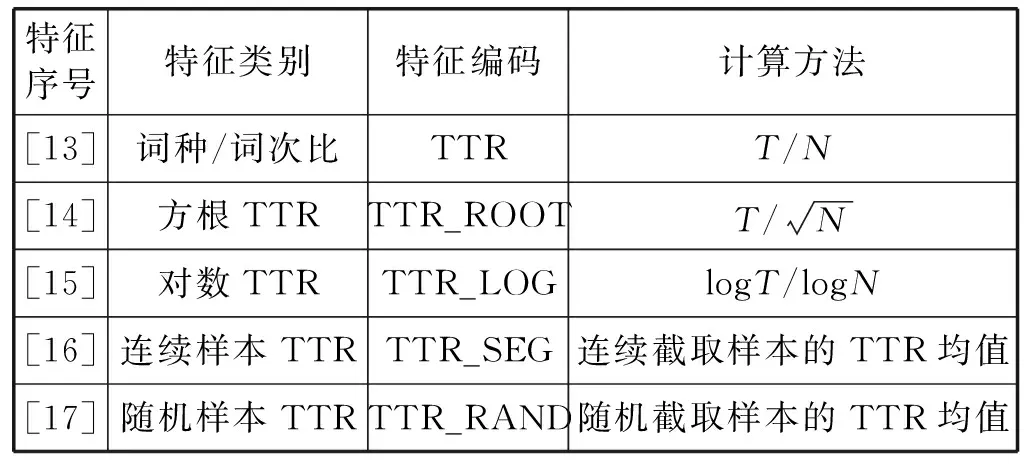
N元序列的種類與序列長度成正比。然而,部分序列只是與訓練作文主題密切相關的特殊詞匯。如果不加篩選,會降低模型在預測不同主題作文時的泛化能力。互信息值用于選取高區(qū)別度的N元序列,計算方法如下:首先統(tǒng)計序列v在高分和低分作文的分布情況,構建表3所示的2×2列聯(lián)表。其中,高分作文Dhigh_score={d∈Dtrain|score(d)≥m},低分作文Dlow_score={d∈Dtrain|score(d) 表3 N元序列分布列聯(lián)表 根據(jù)式(2)計算序列v的MI值: (2) 式中:n=n11+n12+n21+n22,表示訓練集作文總數(shù);n1+=n11+n12,表示包含序列v的作文數(shù)量;n+1=n11+n21,表示高分作文數(shù)量。互信息值測量給定文本類別后序列分布的信息增益,MI值越高表示序列和作文分數(shù)的相關度越高。 SVR模型需要對序列頻率進行加權,以降低常用詞(如get、make等)權重。如式(3)和式(4)所示,本文采用詞頻二值化(Binary)和詞頻-逆文檔頻率(TF-IDF)兩種方式對原始詞頻進行加權。 (3) (4) (5) 1) 特征提取。語言學特征包括文本表層特征、詞匯多樣性、文本可讀性、句法復雜度、語法正確性和語篇連貫度等6個維度,共28個子類。 (1) 文本表層特征。評分員傾向于根據(jù)作文長度評測寫作質量,兩者存在正相關關系[16]。因此,本文選擇7類基于文本長度的表層特征構建評分模型,如表4所示。早期AES系統(tǒng)如PEG完全采用表層特征構建,只考慮文本形式,不涉及文本內容,很容易出現(xiàn)誤判情況。為避免上述缺陷,需要引入其他深層語言學特征提高系統(tǒng)準確率。 表4 文本表層特征 (2) 文本可讀性。本文選用表5所示的可讀性指標評測英語學習者書面語的復雜度。其中:N為作文總詞數(shù);SYL為所有單詞的音節(jié)總數(shù);CW指復雜單詞,即包含兩個以上音節(jié)單詞的數(shù)量;ASL為平均句長;AWS為單詞平均音節(jié)長度。FOG、FLESCH和KINCAID可讀性計算公式中的參數(shù)均由多元回歸方程確定[17]。FOG和KINCAID的值與文本難度成正比,大致對應學習者的語言水平;FLESCH測量文本的易讀性,與文本難度成反比。 表5 文本可讀性特征 續(xù)表5 (3) 詞匯多樣性。如表6所示,詞匯多樣性指不同詞匯類型T與文本總詞數(shù)N的比值。Lu[18]指出,詞匯多樣性在不同水平英語學習者的語言產(chǎn)出中存在明顯差異,并建議使用該指標評測學生的詞匯運用能力。 表6 詞匯多樣性特征 傳統(tǒng)的多樣性計算方法為詞種/詞次比(Type Token Ration,TTR)。然而,這種方法受文本長度影響較大,隨著文本字數(shù)增加,TTR逐漸減小,無法準確測量不同長度文本的詞匯多樣性。為解決這一問題,出現(xiàn)了若干基于TTR的變換形式,如方根TTR、對數(shù)TTR和標準化TTR等[19]。其中,標準化TTR從文本抽取m個長度為n的樣本,然后計算所有樣本的TTR均值。本文采用連續(xù)和隨機抽樣兩種方式計算標準化TTR,樣本長度n=50,隨機樣本數(shù)量m=100,連續(xù)樣本數(shù)量m=N/n。 (4) 句法復雜度。如表7所示,句法復雜度通過分析學習者作文中各句法結構的比例評測寫作質量[20]。首先使用句法分析器自動標注子句(SYN_C)、從句(SYN_DC)、動詞短語(SYN_VP)、復雜名詞短語(SYN_CN)和并列短語(SYN_CN)等語法結構,然后通過計算上述結構的使用頻率與文本總句數(shù)S的比值衡量句法復雜度。 表7 句法復雜度特征 通過編寫例1中(b)和(c)所示的Tregex表達式[21]檢索例句1(a)中的定語從句“which should be filmed”和由從句修飾的復雜名詞短語“l(fā)essons and activities which … …”。 例1 (a) I write this report to suggest some [NP[NPlessons and activities][DCwhich should be filmed ]]. (b) SBAR<(S|SINV|SQ<(VP<#MD|VBD|VBP|VBZ)) (c) NP!>NP [< Tregex表達式用于匹配句法樹各節(jié)點間的支配、從屬和相鄰關系:如符號<和>分別表示父節(jié)點和子節(jié)點,$++表示兄弟節(jié)點,可檢索表6所示各語法結構的使用頻率。 (5) 語法正確度。如表8所示,本文通過檢測拼寫(SPELL_E)和復雜語法錯誤(GRM_E)評估學習者作文的語法正確性。其中,復雜語法錯誤檢測基于鏈語法[22]。鏈語法由詞典和算法兩部分組成,詞典包含詞匯的句法搭配方式;算法根據(jù)詞條的搭配方式對句子進行切分,符合語法的句子形成完整的鏈接,反之,則表明包含語法錯誤。 表8 語法正確度特征 以檢測例句2(a)中的語法錯誤為例,鏈語法首先讀取由詞條和鏈接子表達式構成的詞典,然后分析各鏈接子之間是否能形成完成的鏈條,分析結果如圖2所示。 例2 (a) I’m looking forward your reply. (b) I: S+; ’m: S- & Pg+; looking: Pg- & MVa+; forward: MVa-; your: D+; reply: O- & D- 圖2 鏈語法語誤檢測示例 (6) 語篇連貫度。如表9所示,本文根據(jù)詞匯銜接理論[23],通過計算語篇的詞匯連接數(shù)量評估作文的整體和局部連貫度。其中:Linkslocal和Linksglobal是作文中相鄰和任意兩個句子間的詞匯連接數(shù)量,Nsent是作文總句數(shù)。 表9 語篇連貫度特征 詞匯連接數(shù)量的計算方法如下:首先使用Word2vec詞嵌入模型[24],將句子中的代詞和名詞表征為實數(shù)值向量,然后通過式(6)計算詞匯的語義相似度。 (6) 式中:w1和w2為Word2vec詞向量;分子為向量點積,分母為向量模的乘積。若詞匯相似度大于0.25,則判定為存在詞匯連接。如圖3所示,例3中的兩個句子包含4條詞匯連接。 例3 I like doing sports. I would like to play basketball and golf when I am at the Camp. 圖3 詞匯連接示例 2) 特征篩選。提取語言學特征后,使用隨機森林(RF)算法篩選特征。RF回歸采用自助抽樣法(Bootstrap sampling)和CART算法構建n個決策樹,每個決策樹節(jié)點從隨機選取的m個特征中挑選一個最優(yōu)特征劃分數(shù)據(jù),最終結果由n個決策樹預測值的均值決定。使用自助抽樣法選取決策樹訓練集時,大約有35%的樣本未出現(xiàn)在數(shù)據(jù)集中,構成包外樣本(oob),用于評測特征的重要度[25],具體計算式為: (7) 式中:x為語言學特征;Ntree為決策樹數(shù)目;MSE為第i個決策樹模型預測包外樣本(oobi)分數(shù)的均方誤差;permutate(·)函數(shù)用于隨機排列包外樣本中特征x的值。本文選取重要度大于0的語言學特征構建評分模型。 使用公開數(shù)據(jù)集FCE英語學習者語料庫訓練并測試評分模型。如表10所示,該語料庫由劍橋FCE考試作文構成,包含訓練集作文1 141篇,測試集作文97篇,共95萬詞,每篇作文均有人工批改分數(shù)。此外,F(xiàn)CE訓練和測試集語料選自不同年份的FCE考試作文,寫作主題并不重合。 表10 FCE訓練集和測試集情況 FCE中的語法錯誤均為人工標注,有助于研究英語學習者的二語寫作能力與語法錯誤之間的關系[26]。但本文通過鏈語法自動檢測語法錯誤評估作文質量,不借助人工標注的數(shù)據(jù)訓練模型,因此需要將語料中的XML標簽刪除,轉換為純文本文件,然后使用斯坦福自然語言處理工具Stanford CoreNLP[27]自動標注文本的詞性和句法結構等語言學信息。 首先采用隨機抽樣法,從訓練數(shù)據(jù)中選取90%的樣本作為訓練集,10%的樣本作為驗證集,然后通過設定N元序列長度和互信息值提取詞袋特征。其中:序列長度取值范圍為1≤lenv≤3;互信息取值范圍為10≤-log2MIv≤20。采用Binary和TF-IDF兩種方式對訓練和驗證集數(shù)據(jù)加權,使用LIBLINEAR[28]構建SVR模型。模型的損失函數(shù)為: (8) 式中:(xi,yi)為訓練集樣本,i=1,2,…,m,xi∈Rn,w∈Rn;超參C為約束代價參數(shù),ε為不敏感損失參數(shù)。本文選用LIBLINEAR的默認參數(shù)設置訓練模型,令C=1,ε=0.1。求得模型參數(shù)w后,使用驗證集計算模型的均方誤差,進而篩選特征。 圖4是詞袋類型(type)、MI值與模型誤差的關系圖示。其中:t為單詞序列,p為詞性序列。可以看出:Binary加權模型的誤差低于TF-IDF;由一元單詞序列(t1)和一元到三元詞性序列(p3)構建的模型誤差最低。表11是模型誤差最小的5類特征組合。可以看出,所有特征均包含一元到三元詞性序列,但不包含三元單詞序列。一元到三元單詞序列的種類較多,大多數(shù)序列的頻率都很低,不利于模型的泛化。與之相比,詞性序列的出現(xiàn)頻率較高,同時能夠反映學習者書面語的詞匯和句法搭配關系,具備更強的泛化能力。 圖4 詞袋特征-模型誤差圖 表11 詞袋特征篩選結果 篩選詞袋特征后,使用統(tǒng)計軟件R構建隨機森林模型,通過式(7)計算語言學特征的重要度。模型參數(shù)設置如下:決策樹數(shù)目Ntree=1 000;隨機選取特征數(shù)m=9。如圖5所示,篩選結果顯示段落數(shù)(LEN_PARA)和并列短語比例(SYN_CP/S)的重要度小于0。排除這兩類特征后,最終選取26類語言學特征構建評分模型。 圖5 語言學特征篩選結果 圖6 集成學習評分模型框架 如表12所示,評測結果表明,基于集成學習的評分模型準確率明顯高于基于SVR的模型。Pearson相關系數(shù)r、Spearman相關系數(shù)ρ和均方根誤差RMSE等評測指標顯示,模型Ⅱ以詞袋特征BOW_A和26類語言學特征LINGUA構建的集成評分模型均優(yōu)于現(xiàn)有基于FCE數(shù)據(jù)集的基準模型。 表12 集成評分模型評測 為了更全面地與現(xiàn)有研究展開對比,本文使用Python深度學習工具Keras,嘗試了兩種基于CNN深度學習算法的評分模型。如圖7所示,模型Ⅲ實驗參數(shù)如下:輸入層單詞序列的長度為最大作文字數(shù)dinput_length=900;詞嵌入層選用Word2vec預訓練詞向量,維度dword_embedding=300;卷積層的濾波器數(shù)量h=20,卷積窗口長度m=3;最大池化層窗口長度n=2;全連接層維度ddense=128。模型Ⅳ除單詞序列外,在輸入層增加了詞性序列,詞性嵌入層維度dpos_embedding=50,通過模型訓練得到詞性向量,然后融合兩類序列在全連接層的輸出預測作文分數(shù)。模型Ⅲ和模型Ⅳ的各層均選用ReLU激活函數(shù),模型訓練使用Adam優(yōu)化器,訓練批次大小batch=16。如表13所示,評測結果顯示,加入詞性序列的深度網(wǎng)絡模型準確率最高。如前文所述,詞性序列包含一些反映學習者寫作質量的淺層句法特征,融合單詞和詞性序列的模型優(yōu)于單一的詞向量模型。 圖7 深度學習評分模型框架 表13 深度學習評分模型評測 然而,與集成評分模型相比,基于CNN的深度學習評分模型準確率仍有較大差距。可能的原因是參加FCE考試的考生多為初級英語學習者,導致數(shù)據(jù)集中包含較多的語法錯誤。如圖5所示,復雜語法錯誤數(shù)量比例是預測作文質量的重要語言學特征,而基于英語本族語使用者的Word2vec詞嵌入模型不能有效地識別這些錯誤。 本文結合機器學習、自然語言處理和語言學領域的相關研究成果,開發(fā)了英語學習者作文質量自動評閱系統(tǒng)。首先使用支持向量回歸,通過N元序列長度和互信息值篩選出與作文分數(shù)高度相關的詞袋特征子集;然后從文本復雜度、正確度和連貫度入手,提取作文的深層語言學特征;最后,使用基于隨機森林回歸的集成學習算法融合詞袋和語言學特征,構建評分模型。與現(xiàn)有評分系統(tǒng)相比,本文方法減少了詞袋特征數(shù)量,降低了模型復雜度;細化了語言學特征種類,從詞匯、語法和語篇等多個角度評估學習者作文質量。研究結果表明,本文選取的26類語言學特征與作文質量高度相關,基于集成學習的評分系統(tǒng)優(yōu)于現(xiàn)有基于SVR和CNN的評分系統(tǒng)。本文的局限在于FCE語料庫的訓練和評測數(shù)據(jù)較少。主要原因是現(xiàn)有公開的英語學習者作文語料中,大多不包含人工評閱分數(shù),無法構建和評估系統(tǒng)性能。后續(xù)研究將擴大訓練和測試樣本數(shù)量,從在線機考平臺收集更多的學習者數(shù)據(jù),驗證和改善本文的評分模型,以進一步提高學習者作文自動評分系統(tǒng)的準確率。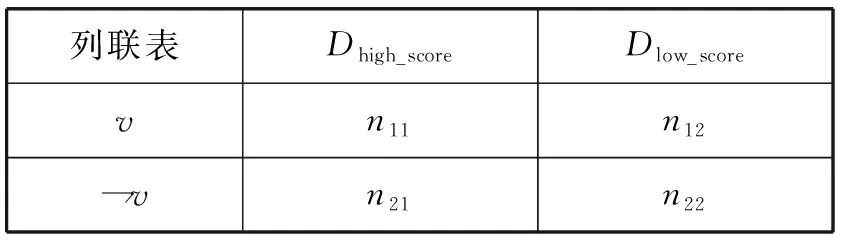


2.2 語言學特征提取與篩選







3 實 驗
3.1 實驗數(shù)據(jù)

3.2 特征提取和篩選



3.3 模型構建和評測





4 結 語
猜你喜歡
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36山東醫(yī)藥(2020年34期)2020-12-09 01:22:24瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28制造技術與機床(2019年10期)2019-10-26 02:48:08中華胰腺病雜志(2019年4期)2019-08-29 08:52:20當代陜西(2019年10期)2019-06-03 10:12:04電子制作(2018年18期)2018-11-14 01:48:06數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54小學教學參考(2015年20期)2016-01-15 08:44:38語文知識(2014年1期)2014-02-28 21:59:13
