基于BP神經網絡的重油催化裂解模型
2021-12-14 05:53:12王志宏龔劍洪魏曉麗
石油煉制與化工 2021年12期
王志宏,龔劍洪,魏曉麗,首 時
(中國石化石油化工科學研究院,北京 100083)
目前,我國煉油產能嚴重過剩,油品結構不盡合理,而化工產能(尤其是高端產品產能)不足,煉油企業的結構轉型升級是實現我國煉化行業綠色、低碳、可持續發展的必然選擇。催化裂解技術作為油品與化工品的橋梁必將成為煉化一體化的核心部分。
為了指導催化裂解裝置操作和工藝優化,研究人員進行了大量的試驗研究,并建立了催化裂解集總動力學模型,描述重油催化裂解的內在化學反應規律,以期預測各種工藝參數和原油組成變化對應的產物產率變化[1]。但是,催化裂解過程的原料組成與反應體系非常復雜,依靠集總理論建立的機理模型基于一些理想化的假設,不能完全模擬出工業過程中的不確定性和干擾因素,而這些不確定性和干擾因素會降低機理模型的預測精度。
神經網絡作為智能建模方法的代表,區別于以往的機理模型,具有強大的非線性擬合能力、并行信息處理能力和自學習能力,在催化裂解過程的動力學模擬中得到越來越多的應用。神經網絡可以用于生產過程中工藝參數控制、數據收集與篩查、結果預測等方面[2],并表現出了巨大的潛力。Serrano等[3]利用神經網絡預測生物質在流化床反應器中氣化生成焦油的過程,發現預測結果準確性良好;崔陽等[4]發現BP神經網絡對煤催化氣化過程的預測效果優于回歸公式方法;Keyvanloo等[5]以神經網絡結合遺傳算法預測石腦油熱裂解的主要產品收率,提高了預測精度。目前,雖然神經網絡方法在煉化過程的預測方面應用廣泛,但鮮有將其應用在重油催化裂解領域的研究報道。
本研究基于實驗室中重油催化裂解過程數據,構建基于BP神經網絡的重油催化裂解產物產率預測模型,通過對不同重質原料、不同工藝參數、不同活性催化劑條件下重油催化裂解產物產率的數據進行訓練,優化了預測模型的網絡結構及算法,驗證了其預測的準確性,以期為重油催化裂解新工藝研發、工程方案優化設計和工業裝置優化操作等提供指導。
1 BP神經網絡
BP神經網絡以適當的數據樣本集為基礎,在輸入變量和輸出變量之間建立關聯[6]。網絡以實際輸出值和期望輸出值之間的均方誤差為判據,調整神經網絡的權值、閾值,最終使均方誤差達到預期。一般BP神經網絡由輸入層、隱含層和輸出層組成,其學習過程包括輸入信息的正向傳遞和誤差信息的反向傳遞兩個過程,如圖1所示。由圖1可知,輸入信息從輸入層進入后,經過隱含層變換傳遞到輸出層,計算均方誤差。如果均方誤差值超過要求,則誤差開始反向傳遞,經過隱含層傳向輸入層。然后,調整輸入變量參數進行再次訓練,經多次訓練后使均方誤差達到要求。
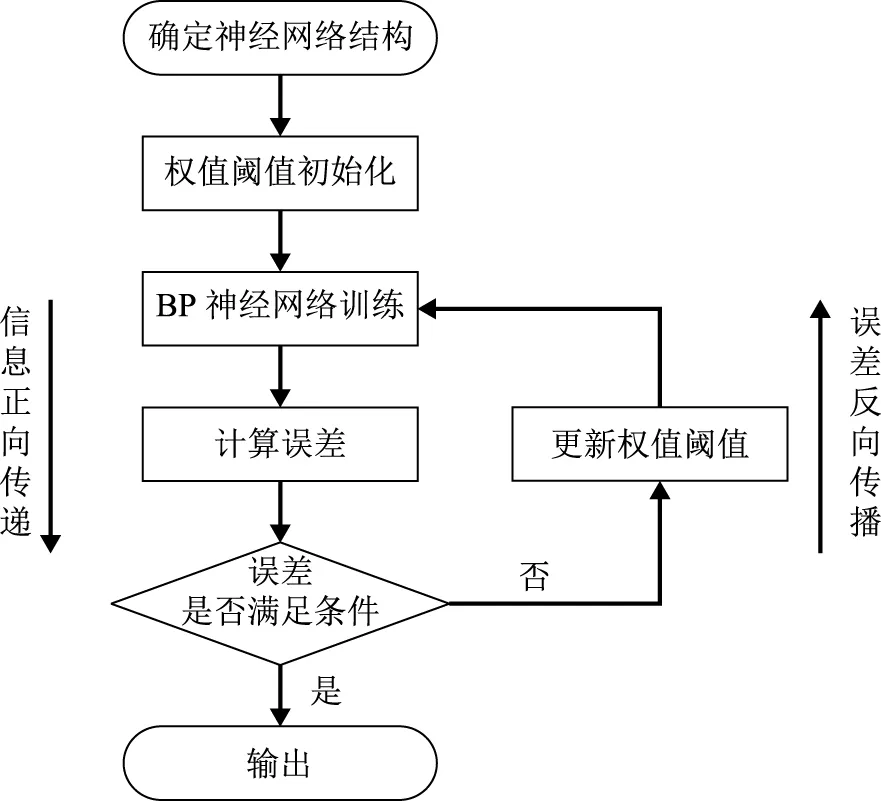
圖1 BP神經網絡訓練過程示意
2 模型的建立
2.1 數據收集
構建模型的數據為小型固定流化床裝置上重油催化裂解的試驗數據,該裝置由中國石化石油化工科學研究院自行設計制造,其原料為典型的重油催化裂解原料,催化劑為工業用催化劑DMMC-2。部分原料油的主要性質如表1所示。

表1 部分原料油的主要性質
在保證模擬效果的前提下,神經網絡模型輸入變量的維數應盡可能小。由采用Pearson相關系數法對催化裂解原料油性質特征間的相關性分析[7]可知,原料油性質特征數間相關性較高時會造成不同性質特征間相互影響。因此,神經網絡模型的輸入變量應選擇原料油性質中相關性較小的特征。通過對催化裂解原料油性質特征的相關性分析,選擇密度(ρ)、殘炭(CR)、氫質量分數(wH)、飽和烴質量分數(wSH)、(膠質+瀝青質)質量分數(wRH)、鎳質量分數(wNi)、釩質量分數(wV)等原料油性質特征作為輸入變量;并選擇催化裂解工藝中常用的關鍵操作參數反應溫度(T)、劑油質量比(mC/mO)、水蒸氣與原料質量比(mW/mO)、催化劑微反活性(MR)作為輸入變量;乙烯、丙烯、BTX(苯、甲苯、二甲苯)的產率作為輸出變量。綜上所述,本研究中神經網絡的輸入變量共11個,包括7個原料油性質和4個操作參數,輸出變量為3個主要產物的產率。通過試驗共采集91組數據樣本,將數據樣本進行隨機分類,其中70組數據樣本歸入訓練集,12組數據樣本歸入驗證集,另外9組數據樣本用于檢驗模型的預測性能。
2.2 數據歸一化
數據歸一化是指通過運算將不同范圍的有量綱的數據經過變換轉變為無量綱的數據,并映射到固定范圍(例如0~1或-1~1等)中,從而避免大數值數據將小數值數據的影響掩蓋,同時解決因數據變化范圍特別大而導致神經網絡收斂慢、訓練時間長的問題,使數據落在激活函數的敏感區域內[8]。數據歸一化計算式如式(1)所示。
(1)
式中:xi為原始數據,x′i為xi歸一化的數據,xmin為原始數據中的最小值,xmax為原始數據中的最大值。
2.3 神經網絡結構的優化
確定BP神經網絡結構的關鍵是選擇合適的隱含層節點數。隱含層節點數選取過大,會導致網絡結構過于復雜,可能出現過擬合,網絡的容錯性和泛化能力變差、對信息的處理能力降低;隱含層節點數選取過小,會導致網絡結構過于簡單,輸入信息不能被網絡充分學習,進而影響訓練效果[9]。隱含層節點數計算式見式(2)。
(2)
式中:H為隱含層節點數;m為輸入變量數;n為輸出變量數;L為1~10的常數。
為選擇合適的神經網絡結構,采用試錯法探究隱含層節點數為4~14時BP神經網絡模型的擬合效果,如表2所示。良好神經網絡的擬合相關度應盡可能大,均方誤差應盡可能小。由表2可知,當隱含層節點數為12時,驗證集數據的相關系數(R)最大,為0.919 87,均方誤差最小,在20 000次迭代后達到0.006 849。因此,構建BP神經網絡模型的輸入層、隱含層和輸出層節點數分別為11,12,3,其結構為11-12-3。
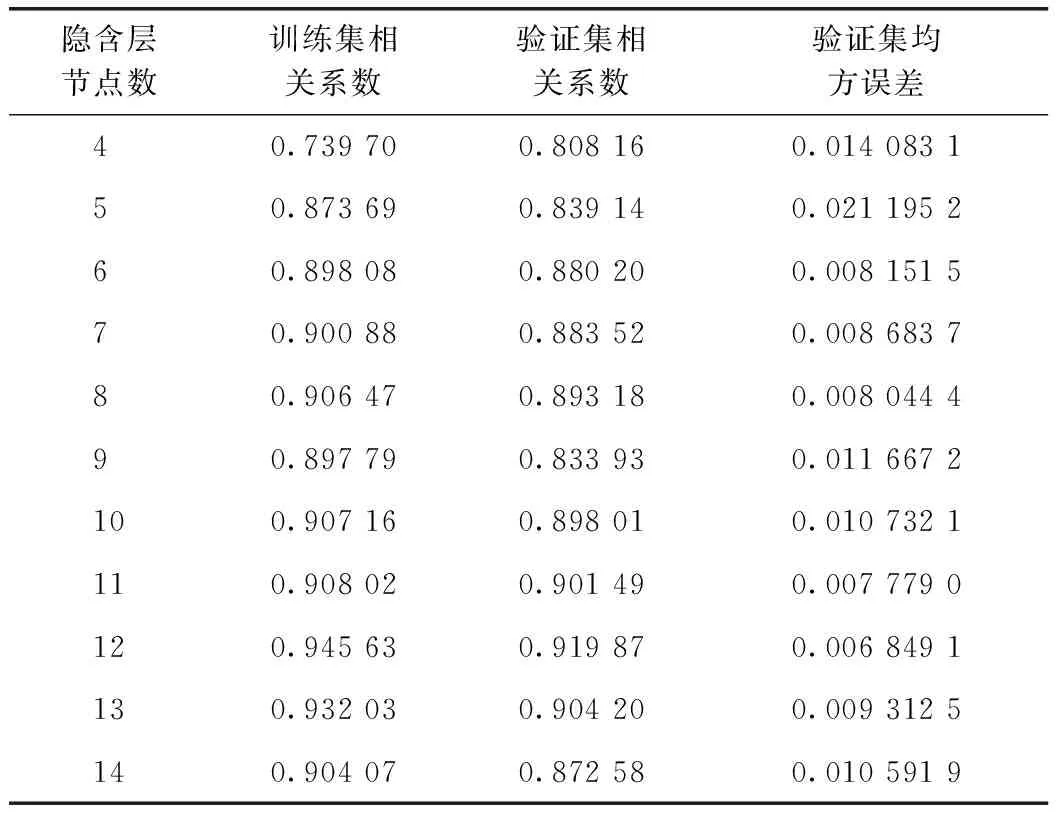
表2 不同隱含層節點數BP神經網絡的擬合效果
2.4 算法的優化
BP神經網絡的梯度下降法收斂速率低、易陷入局部極小點,因此需用其他學習算法改善其運算性能。可以選用的算法有L-M算法(Trainlm)、共軛梯度法(Trainscg)、擬牛頓法(Trainbfg)、貝葉斯法(Trainbr)、自適應學習率的梯度下降法(Traingda)、帶動量的梯度下降法(Traingdm)、帶動量的自適應梯度下降法(Traingdx)等共7種。表3為采用不同學習算法的BP神經網絡擬合效果。由表3可知,選用貝葉斯算法的BP神經網絡性能最好,驗證集數據的相關系數最大,為0.967 08,均方誤差最小,在17次迭代后為0.002 497 8。因此,構建BP神經網絡模型優選貝葉斯算法。
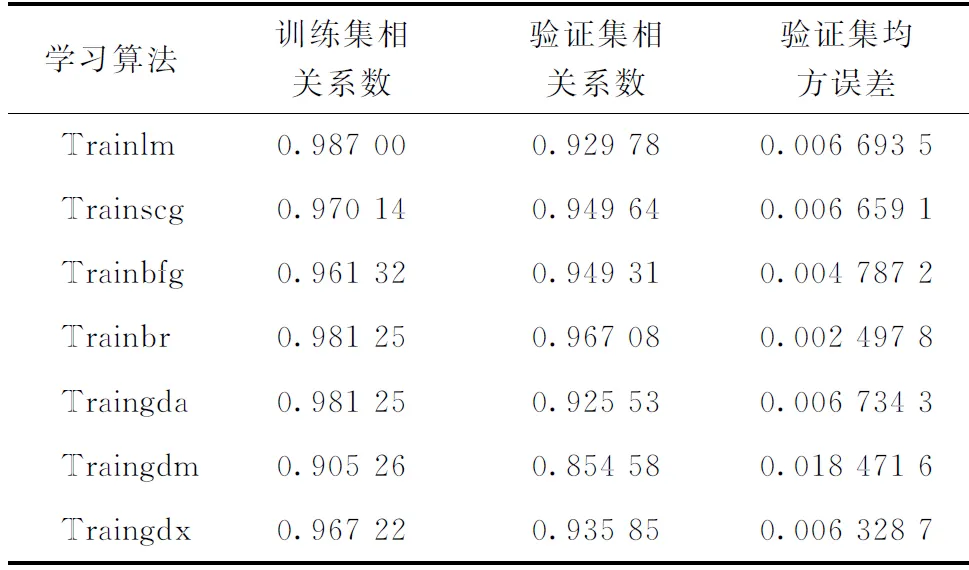
表3 采用不同學習算法的BP神經網絡擬合效果
因此,本研究基于BP神經網絡構建的重油催化裂解預測模型的結構為11-12-3,模型采用數據歸一化方法提高網絡收斂速率、縮短訓練時間,并用貝葉斯算法優化了其運算性能。表4為優化前后BP神經網絡模型的性能。由表4可知,與優化前相比,優化后的BP神經網絡迭代次數由20 000次降為17次,訓練集數據和驗證集數據的擬合相關系數分別提升了0.241 55和0.158 92,驗證集的均方誤差減小了0.011 585 3。這表明,通過對模型網絡結構和學習算法優化后,BP神經網絡的相關性增強,均方誤差大幅下降,網絡模型的收斂速率提高,訓練效果良好,預測結果更加接近真實值。
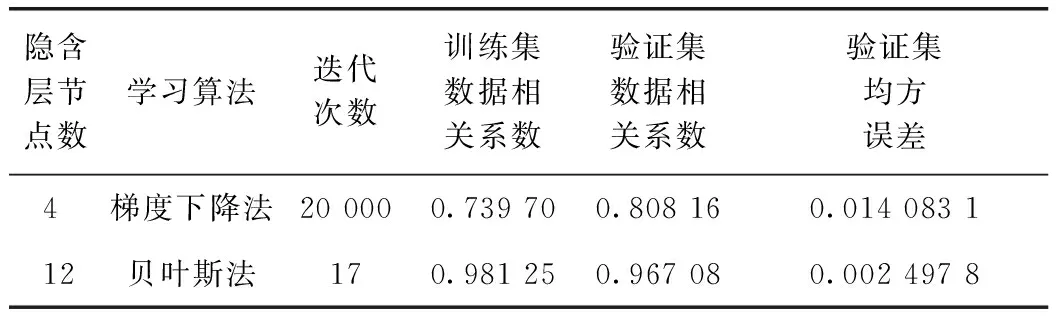
表4 優化前后BP神經網絡模型性能
3 模型的預測性能
3.1 模型的訓練效果
圖2為優化后BP神經網絡模型對輸出變量(乙烯、丙烯和BTX的產率)的預測值與其實際試驗值的關系。由圖2可知,該BP神經網絡模型訓練集的預測值與實際試驗值的相關系數為0.981 25,驗證集的預測值與實際試驗值的相關系數為0.967 08,均接近1,數據均勻分布在Y=X線(圖中虛線)兩側,說明神經網絡模型的預測值與試驗值偏差很小,網絡模型的訓練效果良好。
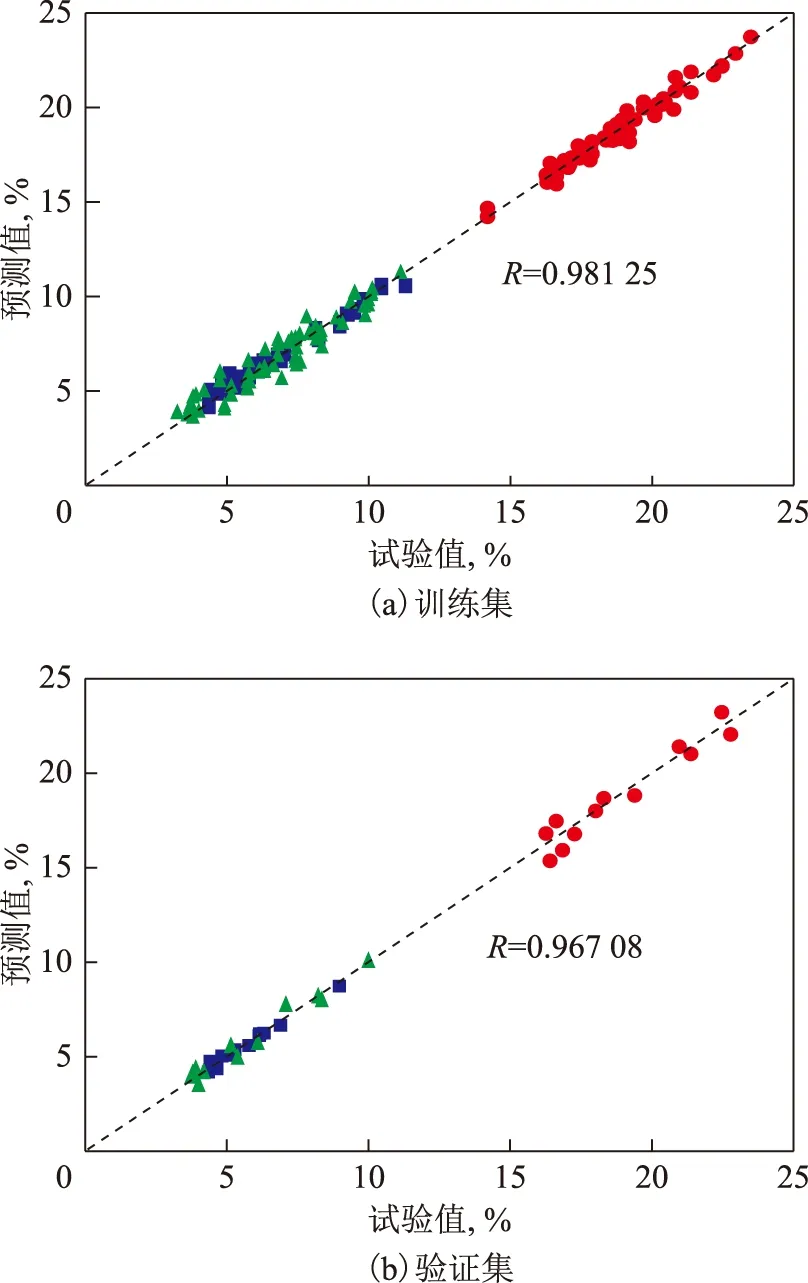
圖2 優化后BP神經網絡試驗值與預測值的關系■—乙烯產率; ●—丙烯產率; ▲—BTX產率
3.2 模型的預測性能
利用構建的BP神經網絡重油催化裂解預測模型,對另外9組試驗數據進行模擬預測,并與試驗值進行比較,結果如表5所示。由表5可知:該模型對乙烯、丙烯、BTX產率預測結果與試驗結果的相對誤差均在10%以內;經過計算,其平均相對誤差分別為4.59%,3.92%,2.28%。表明構建的BP神經網絡模型對重油催化裂解產物產率的預測效果良好,具有較好的實用價值。
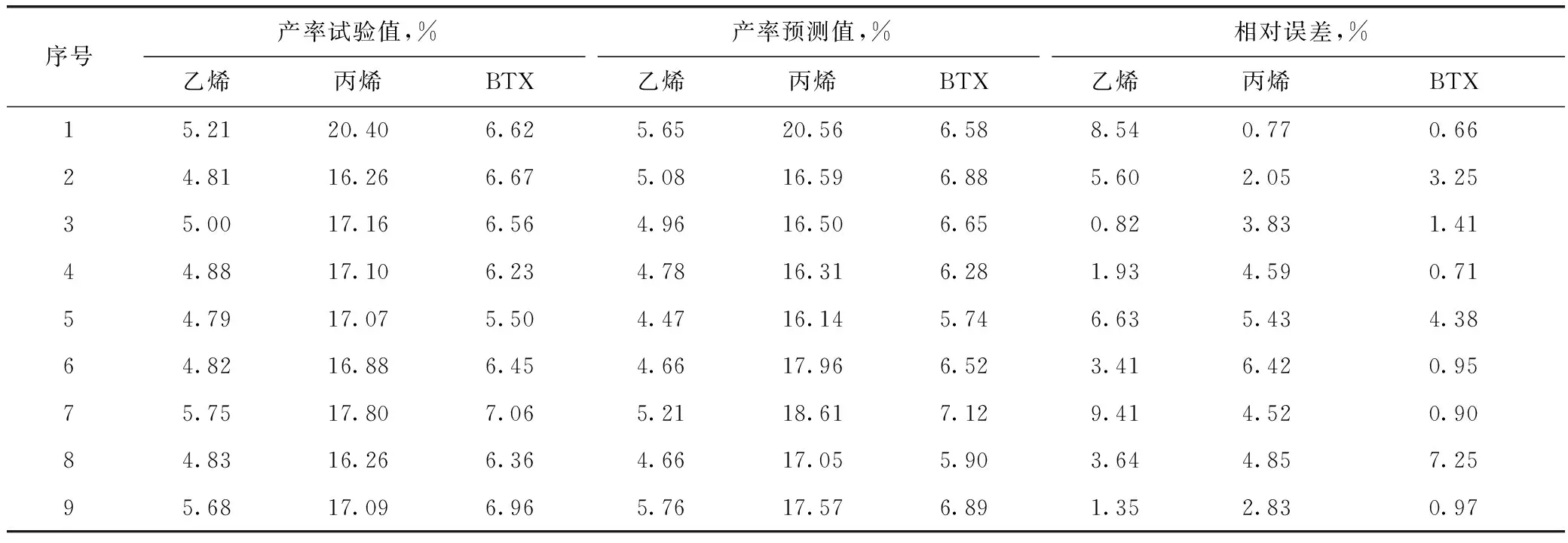
表5 優化后BP神經網絡重油催化裂解模型預測值與試驗值的對比
4 結 論
以對重油催化裂解反應影響較大的11個參數作為輸入變量,以乙烯、丙烯、BTX的產率作為輸出變量,在網絡結構和學習算法優化的基礎上成功建立了結構為11-12-3、以貝葉斯法作為學習算法的重油催化裂解BP神經網絡模型。
利用優化后的BP神經網絡模型預測重油催化裂解產物乙烯、丙烯、BTX的產率,其平均相對誤差分別為4.59%,3.92%,2.28%。表明建立的重油催化裂解預測模型對反應產物產率的預測效果良好,可以為重油催化裂解過程模擬優化提供技術支持。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
