基于YOLO-v5 的星載SAR 圖像海洋小目標檢測
2021-12-15 02:37:56竇其龍顏明重朱大奇
應用科技 2021年6期
竇其龍,顏明重,朱大奇
上海海事大學 智能海事搜救與水下機器人上海工程技術研究中心,上海 201306
合成孔徑雷達(SAR)是根據電磁散射回波的原理對區域進行成像,其成像范圍廣、空間分辨率高,因而在資源勘探、災害監測、海洋管理及軍事領域得到了廣泛的應用。基于星載SAR 圖像,對大范圍的海上目標,尤其是特定區域的船舶目標進行準確的檢測、定位或識別,具有重要的現實需求[1]。
當今國內外的研究機構對于遙感衛星圖像的目標檢測做了大量的相關研究。傳統的檢測手段主要有區域選擇、特征提取和分類器分類3 個步驟。區域選擇即對可能存在目標的區域進行分割,如在星載SAR 圖像里常用的CA-CFAR[2]算法等。特征提取就是在待檢索區域將魯棒性強的特征進行保留,在SAR 圖像中比較常見的有標準差特征提取法(standard deviation,SD)[3]、加權秩填充比特征提取法(weighted-rank fill ratio,WRFR)[4]等。分類器分類就是將提取特征輸入分類器,和已知數據進行比對分類。傳統的檢測方法受圖像噪聲的影響較大,存在選擇區域冗余、特征魯棒性較差、處理時間長等弊端。
自從2014 年Ross Girshick 提出卷積神經網絡深度學習算法(regions with convolutional neural network features,RCNN)[5],并在PASCAL VOC[6]數據集取得突破性進展后,深度卷積神經網絡就進入了迅猛發展的時代,基于深度學習的神經網絡模型也因其強大的特征提取能力而被廣泛應用于各種實體目標的檢測[7-8]。在RCNN 卷積神經網絡提出之后,Shaoqing Ren[9]和郭昕剛等[10]又分別提出了Fast RCNN、Fsater RCNN,使得神經網絡不斷優化和拓寬,訓練速度不斷提高,誤檢率不斷降低。華北電力大學的趙文清等[11]就利用Fsater RCNN 算法對存在缺陷的絕緣子進行準確識別,從而對輸電線路進行故障診斷和修復。上述算法一般都是通過神經網絡提取候選框、分類處理、回歸等操作進行目標特征的學習,從而進行目標檢測與分類。近些年,基于端到端(end to end)學習的實例檢測算法被提出,典型的代表為 單步多框預測(single shot multibox detector,SSD)算法和YOLO(you only look once)家族[12]。文獻[13]針對行人檢測方法誤檢率高的問題提出了基于改進SSD 網絡的行人檢測(pedestrian distinction,PDIS)模型。文獻[14]提出了基于YOLO-v2 和支持向量機(support vector machine,SVM)的船舶檢測分類算法,在網絡模型最后一步全局特征池化后,利用SVM 實現船型的分類,有效地實現了不同種類船只的識別。中國科學院的陳科峻等[15]提出了基于YOLO-v3 模型壓縮的衛星圖像實時檢測,采用K-means 聚類算法選取初始錨點框(anchor),然后用多尺度金字塔圖像進行模型訓練,采用壓縮后的模型大幅度減少了系統計算的時間,節約了計算機的計算空間。
SAR 圖像目標檢測的關鍵是加強對船舶等被檢測目標的注意力,忽略無用信息的干擾。隨著SAR 圖像分辨率的不斷提高和不同工種模式下圖像獲取的極化方式、照射角度、干擾因子不同,因此對SAR 圖像目標的自適應檢測并不理想[16]。本文將YOLO-v5 深度神經網絡模型應用于星載SAR 圖像中的船舶目標檢測。針對船舶目標在星載SAR 圖像中占比很小的特性,進行圖像預處理和數據增強,采用K-means 改進錨點框的尺寸大小,并優化神經網絡模型,嵌入GDAL 模塊,對星載SAR 圖像目標的位置信息等進行讀取。
1 YOLO-v5 的網絡結構
1.1 輸入端Mosaic 數據增強
參考文獻[17]的CutMix 數據增強方式,將重新組合圖像的數量由2 張增加到4 張。首先從數據集中取出不重復的4 張圖像;然后對圖像依次進行隨機的縮放、裁剪和拼接;最后需要將圖片進行灰色填充的操作,以獲得符合網絡特征訓練的大小統一的檢測圖像。
圖1 為采取數據增強處理后的圖像效果。圖1 中的灰色填充部分對神經網絡的學習并沒有幫助,因此灰色部分越少,訓練時間越少,訓練效果越好。我們采用式(1)~(3)的計算方法進行灰色填充。
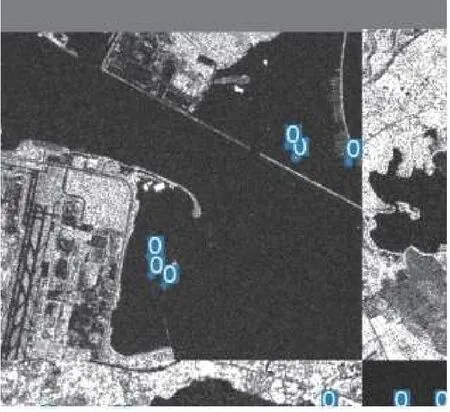
圖1 Mosaic 數據增強(包含灰色填充)
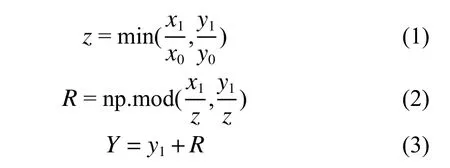
式中:x0、y0(x0≥y0)為原始圖像尺寸的長度與寬度;x1、y1為圖像縮放后的長度與寬度;z為縮放系數;R是x1/z整除y1/z的余數,R表示灰色填充的數值。最終得到寬度為Y的圖像。
這種方法根據圖像原尺寸和縮放尺寸中較小的縮放系數來使得填充的灰色盡可能的小,從而減少計算時的內存占用,達到加快訓練速度的目的。
在YOLO 算法中,初始錨框是針對VOC[12]等數據集計算得到的,本文中YOLO-v5 的錨點框大小的選擇與星載SAR 圖像中的目標尺寸有關,為此,通過數據集和實驗來進行設定。網絡在初始錨框(anchor)的基礎上輸出預測框,進而和真實框(ground truth)進行對比,計算損失函數,再反向更新,迭代網絡參數。由于YOLO-v5 采用的CNN卷積網絡對特征圖像分別進行了32 倍、16 倍和8 倍的下采樣,每次下采樣對應3 個錨點框。32 倍的下采樣用較大的錨點框去檢測感受視野較大的特征圖像,16 倍和8 倍的下采樣分別采用中等的和較小的錨點框去檢測感受視野中等和較小的特征圖像,從而降低模型在訓練的時候尋找被檢測目標的盲目性,有助加快模型尋找被檢測目標的速度。
在YOLO-v5 中加入了自適應錨框的計算,在進行每次訓練之前,通過K-means 算法在訓練集中對所有樣本的真實框進行聚類,從而找出高復雜度和高召回率中最優的那組錨點框。K-means算法步驟如下。
1)K-means 聚類法即先輸入k的值,即我們所希望得到的k個類別。
2)從數據集中隨機選取k個二維數組作為質心(centroid)。
3)對集合中的每一個二維數組進行計算,與哪一個質心接近則與其分為一組。
4)在每一組中選出一個新的質心使其與每個點的距離更接近。
5)當新的質心與舊的質心的直線距離小于設定的閾值時,則算法收斂,聚類區域穩定。
6)當新的質心與舊的質心差距較大時,重復迭代步驟3)~5)。
針對本文的數據集,經過YOLO-v5 自適應錨點框計算后所得錨點框設置如表1 所示,四舍五入取整后得到表2 的錨點框數據,更新模型中的原始錨點框進行神經網絡訓練。從表2 中可見,海面船舶小目標框也有明顯的大小分別,主要分布在5×5~25×21 pixel。
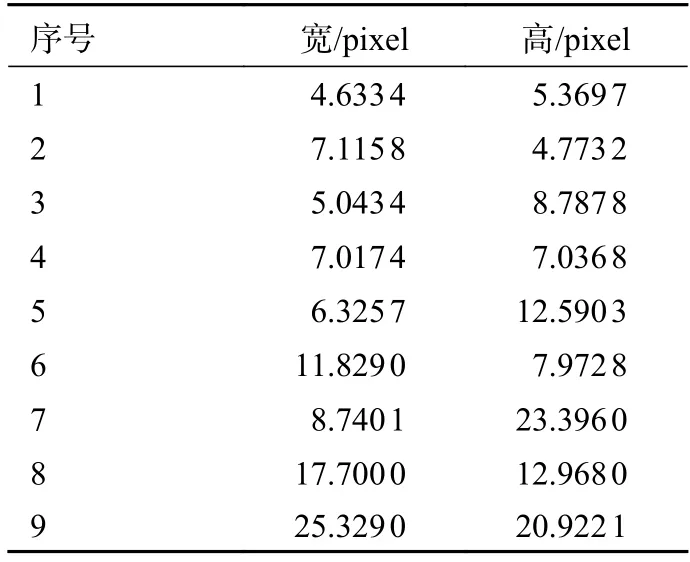
表1 K-means 聚類結果

表2 星載SAR 圖像錨點框聚類
1.2 YOLO-v5 主干網絡(Backbone and Neck)
圖2 為YOLO-v5 的主干網絡結構,該模型主要由注意力(FOCOUS) 模塊、卷積歸一化(convolution and batch normalization,CBL) 模塊、跨階段局部網絡(cross stage partial,CSP) 模塊、跨階段縮放局部網絡(scaling cross stage partial,SPP) 模塊和張量拼接(Concat) 模塊構成。
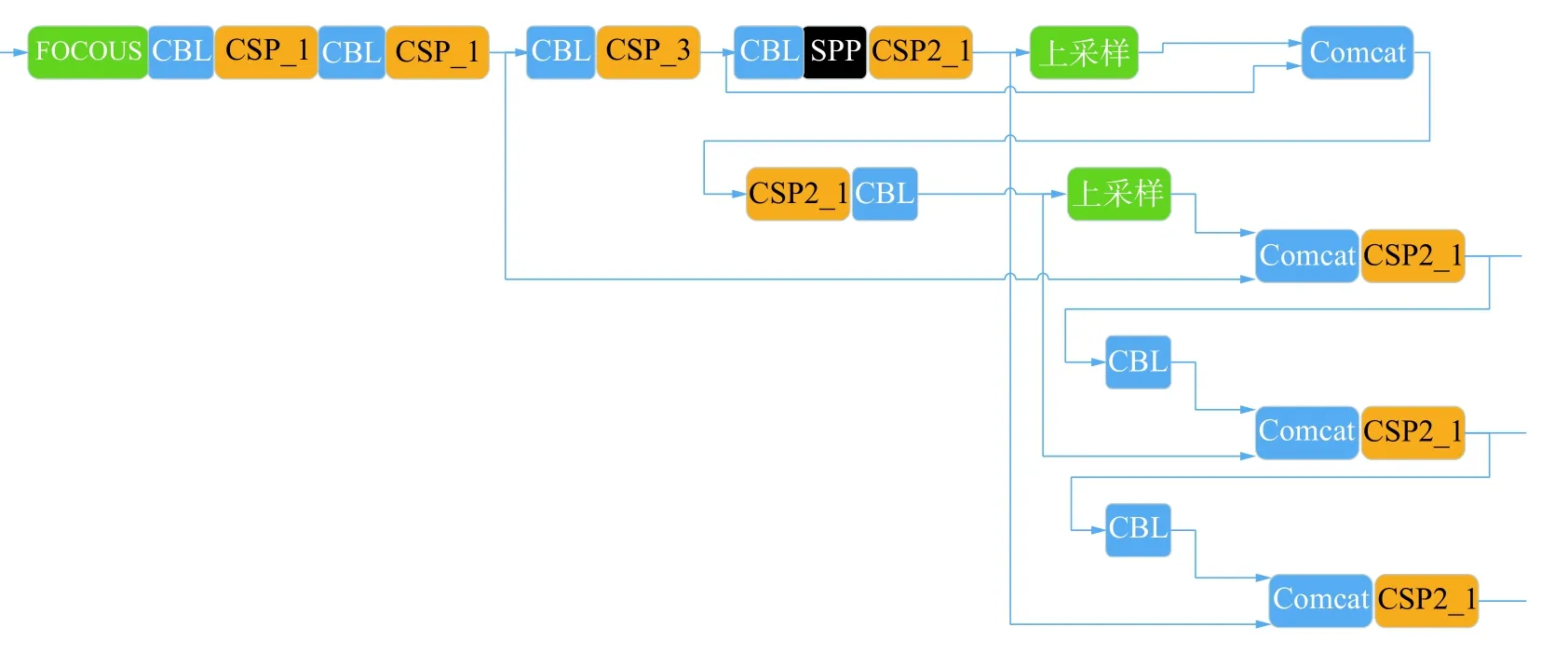
圖2 YOLO-v5 思維Backbone 和Neck 結構
其中FOCOUS 是圖像切片操作。如圖3 所示,將圖像按照像素格進行分割再融合。當原始圖像輸入為608×608×3 pixel 時,通過切片操作進一步提取特征變成304×304×12 pixel 的圖像,再經過32 個卷積核的操作最終變成304×304×32 pixel的特征圖像。
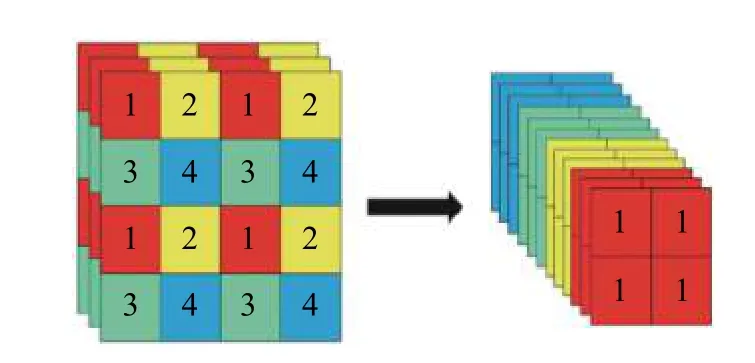
圖3 切片操作
CBL 是由卷積(convolution)、批量歸一化(batch normalization,BN)和激活函數(Leaky_relu)等3 部分構成。由于輸入的分布逐漸向非線性函數的兩端靠攏,神經網絡收斂速度較慢,BN 層將輸入的分布通過式(4)拉回到均值為0、方差為1 的正態布,從而使輸入激活函數的值在反向傳播中產生更明顯的梯度,避免了梯度消失的問題。
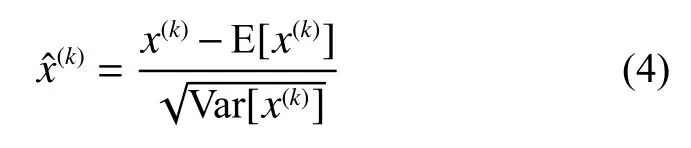
式中:x(k)為經過該層線性變換后的損失函數值,Var 為均方差操作符。
將輸入分布變為標準狀態分布后,輸入的值靠近中心的概率變大,此時采用sigmod[18]函數,即使輸入存在微小的變化,也能夠在反向傳播時產生較大的變化。Leaky relu 激活函數如式(5)所示。
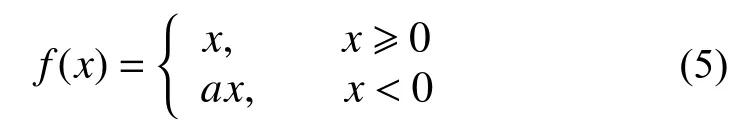
式中a采取一個很小的數值,本文設置為0.01。傳統激活函數直接取值為0,這樣可以保證輸出小于0 的神經元也進行小幅度的更新。
SPP 采用1×1、5×5、9×9 和13×13 的最大池化方式,進行多尺度融合操作。Concat 為擴充維度的張量拼接。YOLO-v5 與YOLO-v4 一樣采用了CSP Darknet53 的網絡結構,與YOLO-v5 不同的是,YOLO-v4 中只有主干網絡中設計了CSP(由卷積層和Res unint 模塊張量拼接而成)結構,而YOLO-v5 在主干網絡Backbone 和Neck 中設計了2 種不同的CSP 結構。CSP 結構主要優點是在網絡模型輕量化的同時保證準確性,同時降低了對計算機設備的要求。新增的CSP2 進一步加強了網絡特征融合的能力。
1.3 損失函數計算
損失函數計算公式如式(6)所示,表示2 個方框所在區域的交并比(intersection over union,IoU)。

如圖4 所示,2 個方框完全重合時,XIoU=1;2 個方框交集為空時,XIoU=0;2 個方框重疊一部分時,XIoU的值在0 和1 之間。但是當2 個框的交集為0 時,不管2 個框相距多遠,IoU 損失函數值恒等于0,無法表示該情況下的損失大小。在YOLO-v5 中采用了IoU 的損失函數公式為
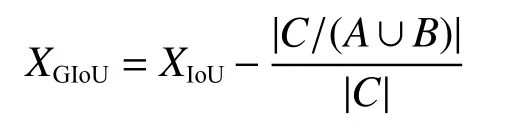
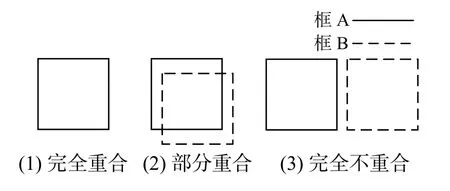
圖4 IoU 損失函數算法
在IoU 的基礎上衍生出的GIoU[19]表示先計算2 個方框的最小閉包區域面積(也就是2 個框重合的交集)。用C和A∪B比值的絕對值除以C的絕對值得到閉包區域中不屬于2 個框的區域的比重,最后計算IoU 與比重的差值,最終得到GIoU的值。在2 個框無限趨近重合的情況下XGIoU=XIoU=1。
如圖5 所示,采用IoU 損失函數時,當2 個框不重合時,無論差距多大,損失函數都為0。與IoU 不同的是GIoU 算法不僅關注2 個框重疊區域的大小,也加入了非重合區域,因此YOLOv5 避免了上述問題。
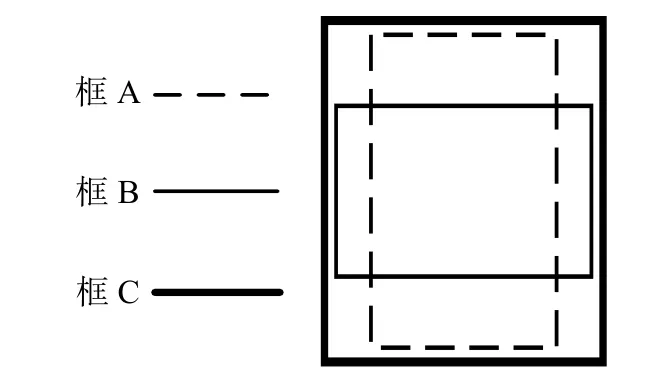
圖5 GIoU 損失函數算法
2 GDAL 模塊
在星載SAR 圖像海洋目標檢測時,本文在檢測頭部分(detect)中嵌入了GDAL 模塊,直接讀取TIF 圖像中每個目標的經緯度坐標,使得目標數據更為直觀、清晰。
GDAL 是一個對遙感衛星等地理圖像進行讀取、寫入和轉換的庫。遙感圖像是一種帶大地坐標的柵格數據,每個柵格點所對應的數值為該點的像元值,像元值包含了該點的大地坐標等空間投影信息,GDAL 通過仿射矩陣的坐標變換將柵格數據轉換為經緯度等信息。
首先使用GDAL 模塊對遙感衛星圖像進行圖像校正(需要指定3 個已知正確的空間坐標點),然后再進行目標經緯度的讀取與顯示。
在截取星載(SAR)圖像的子圖像時保留TIF格式,從而保留遙感衛星圖像的像素格屬性。利用式(7)和式(8)進行柵格數據轉換,從而讀出圖像經緯度信息。
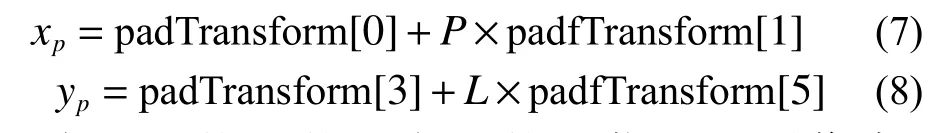
在經過校正的北向上的星載SAR 圖像中,padfTransform[1] 是像素的寬度,padfTransform[5]是像素高度,padTransform[0]和padTransform[3]分別是星載SAR 圖像左上角的經緯度坐標。
3 實驗結果與分析
3.1 實驗平臺
本文中的實驗模型在Pytorch0.8 框架上,采用Darknet53 學習網絡,在PyCharm Community Edition 2020.2.1 x64 平臺上實現。模型訓練在Titan2080Ti(顯存12GB)GPU,CUDA10.0 實驗環境下完成,操作系統為Windows.x64。YOLO-v5 隨著神經網絡寬度和深度的增加分為YOLO-v5s、YOLO-v5m、YOLO-v5l 和YOLO-v5x 這4 個模型,本次實驗采用YOLO-v5l,并加入與YOLO-v3 神經網絡訓練模型的對比。
3.2 數據集
數據集采用了2020 年1 月—2020 年11 月期間由歐洲航天航空局(European Space Agency,ESA)拍攝的Sentinel-1 星載SAR 圖像,選取長江三角洲、新加坡樟宜港口等船舶較多的碼頭港口地區。數據集包含41 張原始比例尺為1∶3 000 的SAR 圖像,每張圖像包含1~40 個不同的船舶目標,對其中100 張圖像用Labelimg 工具軟件進行坐標標記。該數據集包含了不同分辨率以及不同背景下(港口、近海、遠海)不同尺寸的艦船目標,引入不同的島嶼港口背景是為了增加要素,增強訓練效果。
3.3 實驗參數
本次實驗部分實驗參數如表3 所示。

表3 訓練模型參數
3.4 實驗結果與分析
訓練過程參數如圖6 所示,YOLO-v3-spp 訓練如圖7 所示。圖6 和圖7 中(a)為各類別AP 均值(mean average precision,mAP),作為衡量網絡模型訓練的一個重要參數,其中RAP是以準確率Rprecision和召回率Rrecall為兩軸作圖后圍成的面積,RmAP表示平均,@后面的數表示判定IoU 正負樣本的閾值。圖6 和圖7 中(b)為找對的目標數量與找到的目標數量比值,圖6 和圖7 中(c)為找對的目標數量與實際待檢測目標數量的比值。
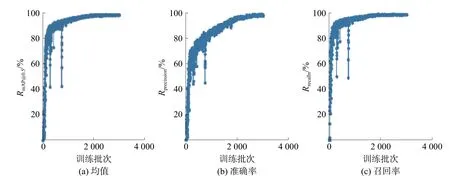
圖6 YOLO-v5l 訓練過程參數
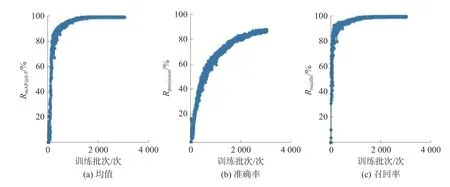
圖7 YOLO-v3 訓練過程參數
從圖6 和圖7 對比可以看出,YOLO-v3 在訓練2 000 epochs 時,準確率逐漸趨于平緩,而YOLO-v5l 的準確率有著進一步的訓練上升空間。YOLOv3 經常出現錯誤的函數迭代方向,如圖7 中的豎型分支,主要原因為:
1)進行了Mosic 數據增強,使得增強后的數據集目標分布更加均衡,并且這種重新組合圖像的方式增強了數據集的豐富性,使得神經網絡訓練的魯棒性更好。
2)加入了CBL 等模塊的YOLO-v5 在反向傳播更新模型參數時失誤較少,有著更為明顯和正確的梯度,訓練參數曲線較為平滑。
最終訓練結果的具體參數如表4 所示。YOLO-v5l 模型的召回率Rrecall為0.994 5,相比于YOLO-v3 提高了1.78%;YOLO-v5l 的召回率RmAP@0.5為0.994 5,相比YOLO-v3 提高了1.18%。
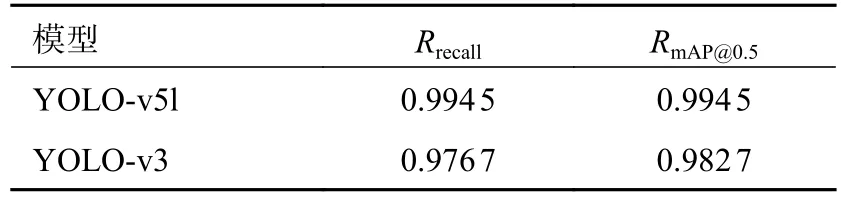
表4 YOLO-v5l 與YOLO-v3 模型訓練結果對比
截取長江口和新加坡樟宜港區域的星載SAR 圖像,采用改進后的YOLO-v5 檢測模型并嵌入GDAL 模塊后,水面船舶目標的檢測結果分別如圖8 和圖9 所示。

圖8 長江口區域的目標檢測結果

圖9 樟宜港區域的目標檢測結果
在表5 和表6 中,包括了目標在圖像中的坐標以及在地理位置上的經緯度信息。表5 和表6中的經緯度信息截取小數點后4 位,用GDAL 模塊讀取的星載SAR 圖像經緯度信息與目標實際地理位置信息一致。目標的經緯度采用目標在圖像中的檢測框的中心位置。
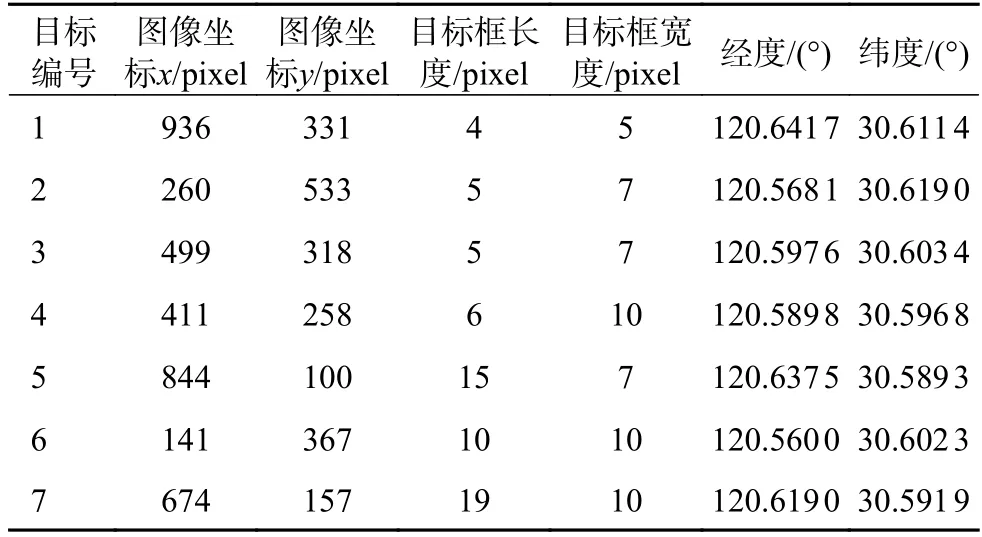
表5 長江口區域目標位置信息
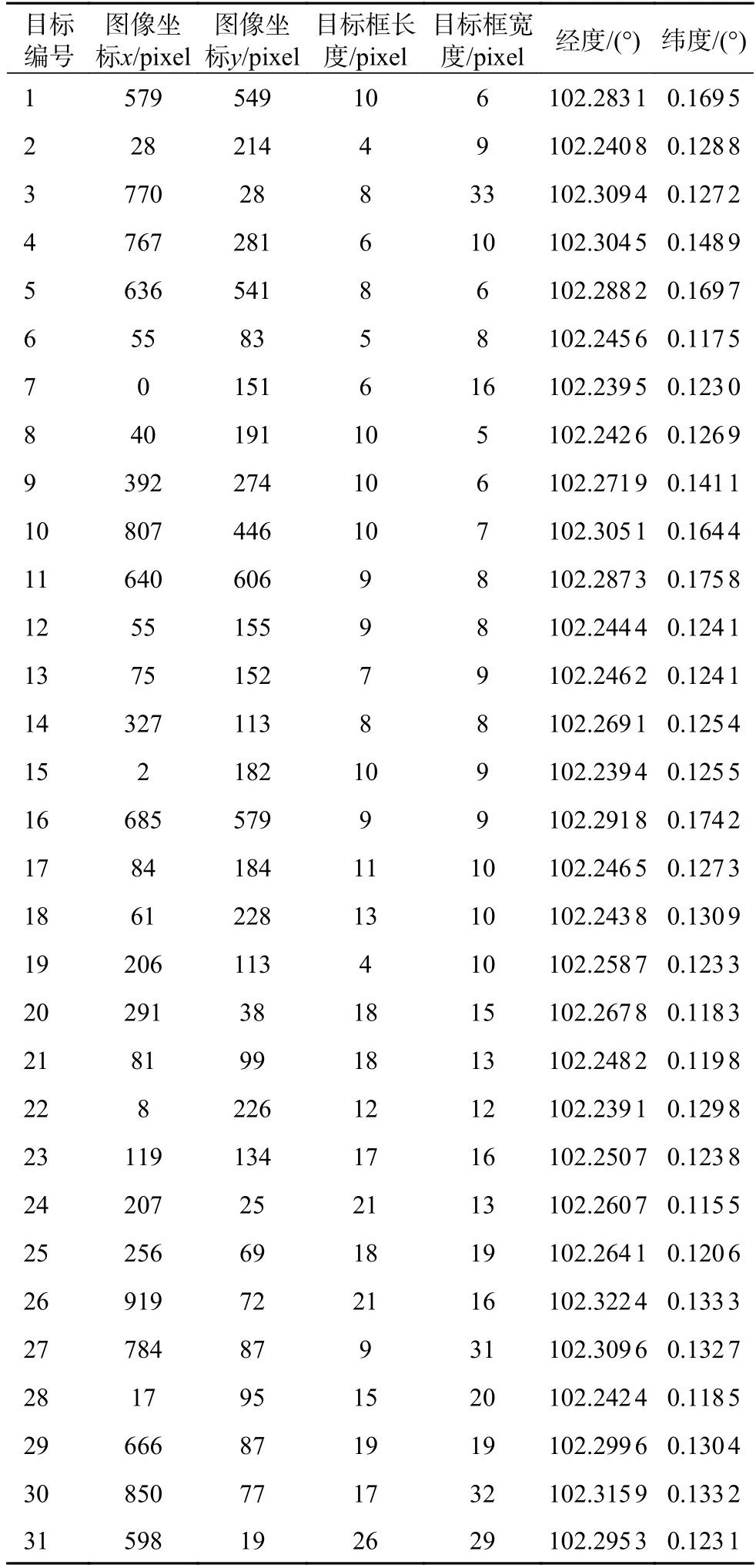
表6 樟宜港區域目標位置信息
可以看出,在圖8 中,對于這種沒有港口、海面開闊和船舶目標數量較少的星載SAR 圖像,改進后的YOLO-v5 檢測模型漏檢率很低,即使目標在圖像中占比較小也能準確地檢測出來。在圖9中,港口沿岸情況復雜、干擾因素較多、目標檢測效果仍然較好,并且該模型能夠有效檢測到動態船舶目標,能夠滿足對于進出港口船舶的動態檢測、定位和跟蹤等應用需求。
4 結論
本文基于Darknet 神經網絡,提出了利用優化的YOLO-v5 網絡模型的目標檢測的算法。
1)本算法泛化性較強,對于大范圍的水面船舶小目標檢測效果較好,并且檢測時間較短,分辨率為720×720 pixel 的圖像平均檢測時間小于1 s。
2)加入CBL 模塊的YOLO-v5 比YOLO-v3 在訓練中的反向傳播更為穩定,更新梯度更為平滑。
3)優化后YOLO-v5 的模型降低了漏檢率,在提高檢測效果的同時并沒有增加檢測模型文件的內存。
在未來的研究中,需要進一步優化網絡模型結構,加快檢測速度,并且用于與其他檢測目標的手段進行實時的數據融合。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
