臨床智能研究平臺建設及相關問題探討
2021-12-16 02:01:00席韓旭XIHanxu孫邦凱SUNBangkai張晨ZHANGChen李維LIWei計虹JIHong
醫院管理論壇 2021年9期
□ 席韓旭 XI Han-xu 孫邦凱 SUN Bang-kai 張晨 ZHANG Chen 李維 LI Wei 計虹 JI Hong
隨著信息技術和數據科學的快速發展,基于多樣化的真實世界數據(real-world data,RWD)形成的真實世界證據(real-world evidence,RWE),已成為醫療衛生決策的重要來源(如藥械監管、目錄制定、指南制定、疾病管理等)[1]。2021 年4 月15 日,國家藥品監督管理局藥品審評中心發布了《用于產生真實世界證據的真實世界數據指導原則(試行)》[2],該指導原則指出,真實世界數據是指來源于日常所收集的各種與患者健康狀況和/或診療及保健有關的數據。根據源數據的產生是否基于預先設定的研究目的,真實世界數據主要分為常規收集的健康醫療數據(routinely collected health data,RCD)和主動收集的健康醫療數據[3]。隨著真實世界研究的廣泛開展和不斷深入,如何利用信息技術提高真實世界數據獲取效率是目前面臨的重要挑戰。本文從RWD到構建研究型數據庫的需求進行分析并提出解決方案,為從信息技術角度支持真實世界研究提供借鑒與參考。
從RWD 到構建研究型數據庫的需求分析
1.從RCD 到構建研究型數據庫。RCD 從本質上講,更多是用于醫療衛生管理目的,存在數據片段化、未標化、未鏈接、大量非結構化數據難以利用等問題[1,4],因此建立研究型數據庫的需求主要包括:(1)基于患者主索引,將患者歷次就診的門急診和住院信息進行整合;(2)利用自然語言處理技術對自由文本病歷、檢查報告等數據進行后結構化處理;(3)搭建平臺實現海量數據的高效檢索和應用。
2.構建包含主動收集數據的研究型數據庫。主動收集的醫療數據是指基于預先設定的研究目的,額外主動收集研究者或決策者所需的關鍵信息(如腫瘤患者生活質量)和其他無法通過既有健康醫療數據獲取的信息[1]。構建包含這類數據的研究型數據庫的需求主要包括:(1)實現院內電子病歷、醫囑、檢查、檢驗等數據智能回填到病例報告表(Case Report Form,CRF)中;(2)對主動收集的患者數據實現高效獲取。
臨床智能研究平臺整體架構
針對以上問題并結合《真實世界數據與研究技術規范》[1,5-6]要求,我院在實時全量數據中心(Hospital Data Repository,HDR)基礎上[7],打造了臨床智能研究平臺以全面支持真實世界研究。
整個臨床智能研究平臺利用人工智能及大數據相關技術,從醫院數據中心、外部公開數據庫采集相關數據,以應用場景為驅動建立數據深度治理體系,搭建數據應用模型。在數據模型和數據應用層面之間通過敏感數據脫敏、資源監控管理、多層級賬號權限和安全體系保障數據安全,以支持科研、臨床、管理方面的應用,整體架構見圖1。
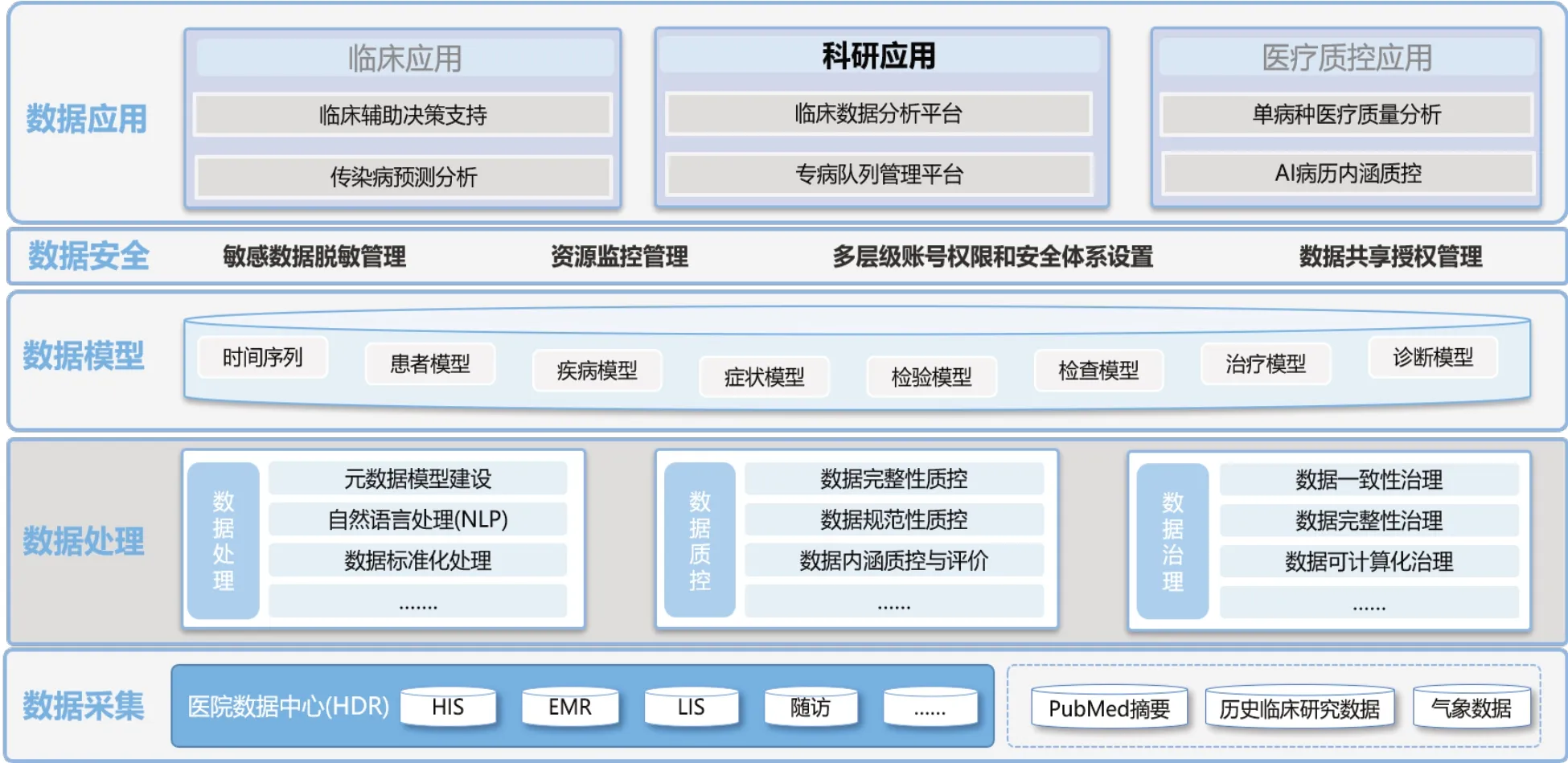
圖1 臨床智能研究技術架構圖
面向科研應用的平臺功能特點
根據原始數據是否基于特定研究目的收集,我院打造了臨床數據分析平臺和專病隊列管理平臺以支持真實世界研究,下文將詳細介紹每種平臺功能并對兩者特點進行對比分析。
1.臨床數據分析平臺。臨床數據分析平臺是一種面向全院、通用的科研工具,是一種回顧性數據庫,是在研究開始前已經存在的,并非針對特定研究問題收集數據而形成,因此如何從海量醫療數據中高效地提取出研究所需要的人群和變量則是臨床數據分析平臺建設的核心內容,主要包括:
(1)人群檢索。運用多層級語義分析模型,通過大數據、機器學習、自然語言處理技術將病歷文書中大段的文本后結構化成可以直接利用的變量,并支持對處理后的變量進行多重語義篩選以高效建立研究人群。
(2)特征分析。對建立的研究人群特征利用數據可視化引擎進行多維度分析,包含人群特征、疾病特征以及癥狀表現等,為研究人員的探索性研究提供思路。
(3)實時數據質控和溯源。對研究人群全部變量的完整度、異常值等情況進行分析,并實時溯源到原始數據,以幫助研究人員從整體上快速了解數據質量。
(4)數據沙箱輔助進一步數據清洗。通過數據沙箱實現對數據極端值、異常值、缺失值的處理,以幫助研究人員根據具體的研究問題進一步進行數據清理,最終建立一個能夠直接進行統計分析的數據集。
通過搭建臨床數據分析平臺,改變了傳統的數據獲取模式,基于分布式計算、搜索引擎、語音分析等技術,實現研究者自助式地進行數據檢索、清洗和分析,從而提高數據獲取效率。目前臨床數據分析平臺已支持18 個科室105 名醫生使用,基于平臺已開展16 項科研課題研究(其中國家自然科學基金2 項,院臨床重點項目1 項[8])。
2.專病隊列管理平臺。專病隊列管理平臺是一種面向院內大型研究團隊,針對專科疾病的隊列管理平臺。是一種根據明確的研究目的和計劃,至少部分數據需要前瞻性主動收集而形成的數據庫。專病隊列管理平臺的建設主要包括兩方面內容:
(1)數據的收集與管理。專病隊列管理平臺中的數據既包括RCD,也包括前瞻性主動收集的數據。對于RCD,專病隊列管理平臺通過直接映射、自然語言處理及歸一、邏輯判斷等數據加工策略,實現對既有數據的智能化提取;對于需要主動收集的數據(如患者生活質量等數據),專病隊列管理平臺支持多種數據錄入方式,包括手動錄入、移動端(如微信、APP)錄入、智能語音錄入、物聯網設備數據對接等,以提高CRF 回填率,減少手工錄入工作量。
以胃癌專病隊列建設為例,方法學團隊、臨床醫生與信息團隊共同確定了10 大類(基本信息、病史特點、術前檢驗檢查等)168 個數據項,通過對每個數據項來源及提取規則的分析驗證,最終確定可以直接映射的變量31 個,需要自然語言處理后再進行歸一處理的變量48 個,需要進行邏輯加工的變量47 個,手工錄入的變量42 個,數據回填率達75%。
(2)研究對象的隨訪與維持。專病隊列管理平臺支持對專病隊列中的全部或部分研究對象進行隨訪。可以根據訪視計劃自動展示每天應隨訪的研究對象,形成隨訪日歷,并通過移動端(如微信、APP)的用藥提醒、用藥指導、留言咨詢、宣教推送等方式,輔助提高患者依從性。
臨床數據分析平臺與專病隊列管理平臺的對比分析
臨床數據分析平臺與專病隊列管理平臺作為支持真實世界研究的兩個重要工具,兩者在數據類型、采集方式、治理程度等方面均不同(見表1),在實際工作中研究者應根據基于研究目的,選擇在現有資源條件下最適合的工具。

表1 臨床數據分析平臺與專病隊列管理平臺的對比分析
結語
信息技術的快速發展,為開展真實世界研究提供了更高質量的數據基礎和更高效的數據獲取效率。利用不同科研平臺構建的數據庫并不代表數據質量的絕對高低,科學的設計、嚴格的實施和分析才是高質量研究數據的關鍵[5]。隨著信息技術和人工智能的快速發展,真實世界證據生產涉及的多個專業領域(包括臨床醫學、流行病學、統計學、信息學等)之間的交叉融合將更為明顯,對醫院信息技術專業人員也提出了更高的要求,一方面應該掌握和應用前沿信息技術,如Hadoopd 大型集群技術、Hbase 非關系型數據庫技術、Map-Reduce、Spark Streaming 高效并行計算框架等技術[9];另一方面應熟悉臨床業務流程,熟知數據來源,數據之間交互情況;除此以外還應對流行病學、統計學以及人工智能等方面深入了解,這樣才能更好地支持醫院科研發展。
猜你喜歡
今日農業(2022年15期)2022-09-20 06:56:20
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
雜文月刊(2016年1期)2016-02-11 10:35:51
