基于Transformer神經(jīng)網(wǎng)絡(luò)模型的網(wǎng)絡(luò)入侵檢測(cè)方法
2021-12-21 03:07:50郭志民周劼英
重慶大學(xué)學(xué)報(bào) 2021年11期
郭志民, 周劼英,王 丹,呂 卓,楊 文
(1.國網(wǎng)河南省電力公司電力科學(xué)研究院,鄭州 450000;2.國家電網(wǎng)有限公司,北京 100031; 3.國網(wǎng)河南省電力公司,鄭州 450000)
當(dāng)今網(wǎng)絡(luò)安全形勢(shì)日益嚴(yán)峻,網(wǎng)絡(luò)攻擊者利用巧妙的攻擊手法避開防火墻,入侵網(wǎng)絡(luò)系統(tǒng)獲取隱私信息、破壞網(wǎng)絡(luò)系統(tǒng)或?qū)е路?wù)器癱瘓,關(guān)于網(wǎng)絡(luò)入侵檢測(cè)研究已成為當(dāng)今網(wǎng)絡(luò)安全最重要的研究方向之一。網(wǎng)絡(luò)入侵檢測(cè)通過對(duì)計(jì)算機(jī)系統(tǒng)和網(wǎng)絡(luò)事件分析,檢測(cè)入侵和攻擊行為。在一個(gè)網(wǎng)絡(luò)系統(tǒng)中,任何未經(jīng)授權(quán)的活動(dòng),以及企圖繞過網(wǎng)絡(luò)安全機(jī)制的行為,都可視為網(wǎng)絡(luò)入侵行為[1]。網(wǎng)絡(luò)入侵檢測(cè)可被分為基于異常的檢測(cè)和基于誤用的檢測(cè)2種[2-3]。基于異常的檢測(cè)系統(tǒng)通過觀察網(wǎng)絡(luò)、系統(tǒng)或用戶的異常行為來檢測(cè)攻擊行為,基于誤用的檢測(cè)系統(tǒng)則使用先驗(yàn)的攻擊模式和簽名來檢測(cè)攻擊行為。
隨著人工智能和機(jī)器學(xué)習(xí)的發(fā)展,越來越多研究開始嘗試使用機(jī)器學(xué)習(xí)的方法解決網(wǎng)絡(luò)入侵檢測(cè)的難題。Chowdhur等人[4]以互聯(lián)網(wǎng)上的流量數(shù)據(jù)為訓(xùn)練集,一次性選取任意3組特征作為SVM的輸入進(jìn)行訓(xùn)練,給予了SVM一定檢測(cè)任意網(wǎng)絡(luò)異常行為的能力。Mohsen等人提出了用于入侵檢測(cè)的最小-最大K均值聚類方法[5]。該算法試圖最小化簇的最大內(nèi)部方差,而不是像K均值算法那樣最小化內(nèi)部方差的和。每個(gè)集群都有一定的權(quán)重,并將較高的權(quán)重分配給內(nèi)部方差較大的集群,該算法獲得了81%的檢測(cè)率。Li等人[6]提出了2階段的“智能入侵檢測(cè)方法”。第一階段包括使用隨機(jī)森林算法,通過權(quán)衡特征的重要性來獲得特征的子集。第二個(gè)階段是一種基于特征子集作為輸入的分類器“基于混合聚類的Adaboost算法”。Jaiganesh等人[7]提出一種基于神經(jīng)網(wǎng)絡(luò)的入侵檢測(cè)算法,通過專門選取入侵?jǐn)?shù)據(jù),使用反向傳播算法訓(xùn)練神經(jīng)網(wǎng)絡(luò)權(quán)重,使算法具有檢測(cè)入侵行為的能力。Sinapiromsaran等人提出了多屬性框架決策樹[8],將數(shù)據(jù)分為左、中、右3個(gè)區(qū)域,從最遠(yuǎn)的一對(duì)中選擇一個(gè)核心向量來對(duì)入侵行為進(jìn)行分類。李俊等人[9]考慮了網(wǎng)絡(luò)入侵?jǐn)?shù)據(jù)的時(shí)序特點(diǎn),使用GRU_RNN網(wǎng)絡(luò)結(jié)構(gòu)在KDD數(shù)據(jù)集上進(jìn)行訓(xùn)練,獲得比其他非時(shí)序網(wǎng)絡(luò)更好的識(shí)別率與收斂性。
盡管許多現(xiàn)有研究探索了機(jī)器學(xué)習(xí)在網(wǎng)絡(luò)入侵檢測(cè)中的應(yīng)用,這些研究對(duì)正常行為和攻擊行為進(jìn)行分類,基于機(jī)器學(xué)習(xí)方法構(gòu)建入侵檢測(cè)模型,具有一定檢測(cè)效果,但仍存在一些問題。主要體現(xiàn)在:1) 訓(xùn)練樣本中標(biāo)簽為正常行為的數(shù)據(jù)量遠(yuǎn)大于非法行為,數(shù)據(jù)特征分布嚴(yán)重不均,導(dǎo)致模型難以訓(xùn)練且泛化能力不足。2) 網(wǎng)絡(luò)入侵通常是時(shí)間上的一段連續(xù)行為,大多數(shù)模型不具備時(shí)序?qū)W習(xí)能力而丟失了時(shí)序特征,部分基于循環(huán)神經(jīng)網(wǎng)絡(luò)的方法雖能夠?qū)W習(xí)時(shí)序特征,但其基于序列的串行訓(xùn)練方式存在訓(xùn)練耗時(shí)長且收斂效率較低等問題。
Transformer[10]最初應(yīng)用于自然語言處理(NLP)任務(wù)中,其結(jié)構(gòu)完全拋棄了RNN和CNN等網(wǎng)絡(luò)結(jié)構(gòu),而僅采用Attention機(jī)制來進(jìn)行機(jī)器翻譯任務(wù),且取得了很好效果,其網(wǎng)絡(luò)結(jié)構(gòu)如圖1所示。Devlin等人提出的BERT[11],Brown等人提出的GPT-3[12],這些基于Transformer的模型都在NLP領(lǐng)域取得了重大突破。Transformer與基于RNN的時(shí)序神經(jīng)網(wǎng)絡(luò)有明顯不同,RNN的訓(xùn)練是迭代的、串行的,而 Transformer 的訓(xùn)練是并行的,即所有特征是同時(shí)訓(xùn)練的,大幅增加計(jì)算效率。

圖1 Transformer網(wǎng)絡(luò)結(jié)構(gòu)Fig. 1 Transformer network structure
通過分析網(wǎng)絡(luò)入侵行為的數(shù)據(jù)特征,提出基于Transformer神經(jīng)網(wǎng)絡(luò)模型的入侵檢測(cè)方法。通過在多個(gè)數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn),選取最優(yōu)的損失函數(shù)和網(wǎng)絡(luò)結(jié)構(gòu),最后在測(cè)試數(shù)據(jù)集上,相較于對(duì)比機(jī)器學(xué)習(xí)方法,提升訓(xùn)練效率和識(shí)別率。主要貢獻(xiàn)包括:
1) 針對(duì)網(wǎng)絡(luò)入侵行為數(shù)據(jù)的時(shí)間相關(guān)性,提出了一種基于Transformer的網(wǎng)絡(luò)入侵檢測(cè)方法,進(jìn)一步提升網(wǎng)絡(luò)入侵檢測(cè)的準(zhǔn)確性。
2) 設(shè)計(jì)一種基于降維特征的多頭自注意力機(jī)制Transformer網(wǎng)絡(luò)模型,以解決傳統(tǒng)串行化時(shí)序神經(jīng)網(wǎng)絡(luò)模型不易收斂且時(shí)間開銷較大問題,通過選取最優(yōu)損失函數(shù)和訓(xùn)練參數(shù)進(jìn)行并行化訓(xùn)練,從而實(shí)現(xiàn)網(wǎng)絡(luò)入侵行為檢測(cè)。
3) 在多個(gè)數(shù)據(jù)集上進(jìn)行對(duì)比實(shí)驗(yàn),結(jié)果表明,提出的基于Transformer網(wǎng)絡(luò)模型的網(wǎng)絡(luò)入侵檢測(cè)方法在多個(gè)數(shù)據(jù)集上均獲得了99%以上的精度和檢出率。
1 數(shù)據(jù)分析及預(yù)處理
1.1 數(shù)據(jù)分析
實(shí)驗(yàn)采用的數(shù)據(jù)集為KDD-Cup-99和NSL-KDD網(wǎng)絡(luò)入侵?jǐn)?shù)據(jù)集。KDD-Cup-99數(shù)據(jù)集[13]是第三屆國際知識(shí)發(fā)現(xiàn)和數(shù)據(jù)挖掘工具競(jìng)賽所使用的數(shù)據(jù)集,共計(jì)23種標(biāo)簽、4898431條數(shù)據(jù),包含正常和22種攻擊類型標(biāo)簽。NSL-KDD 數(shù)據(jù)集[14]是KDD-Cup-99數(shù)據(jù)集的改進(jìn)版本,包含125973條網(wǎng)絡(luò)連接記錄。數(shù)據(jù)集如表1所示。

表1 網(wǎng)絡(luò)入侵?jǐn)?shù)據(jù)集
分析了KDD-Cup-99及NSL-KDD數(shù)據(jù)集的數(shù)據(jù)分布,分析結(jié)果如圖2所示。

圖2 KDD-Cup-99及NSL-KDD數(shù)據(jù)分布Fig. 2 Data distribution of KDD-Cup-99 and NSL-KDD
分析結(jié)果表明,KDD-Cup-99數(shù)據(jù)集分布不平衡,這種不平衡數(shù)據(jù)分布會(huì)導(dǎo)致模型性能欠佳,導(dǎo)致漏檢率升高,而NSL-KDD數(shù)據(jù)存在信息冗余的問題[15]。為解決這一問題,引入特征提取模型,通過數(shù)據(jù)表征和降維,避免因數(shù)據(jù)冗余造成收斂性能降低。
1.2 數(shù)據(jù)特征提取
1.2.1 字符數(shù)據(jù)編碼
由于原始數(shù)據(jù)集包含了字符串特征,不利于直接向量化,為了方便計(jì)算,將數(shù)據(jù)標(biāo)簽進(jìn)行One-hot編碼。One-hot編碼是機(jī)器學(xué)習(xí)分類任務(wù)中常用的數(shù)據(jù)編碼方式,它可以將原數(shù)據(jù)中離散的值轉(zhuǎn)化為歐式空間的點(diǎn),使各標(biāo)簽之間保持合理的特征距離。數(shù)據(jù)集中的每條數(shù)據(jù)被分為正常或異常2種類別,正常編碼為01,異常編碼為10,具體編碼方式見表2所示。

表2 數(shù)據(jù)標(biāo)簽編碼
1.2.2 歸一化
由于原始數(shù)據(jù)中數(shù)據(jù)范圍相差較大,不利于網(wǎng)絡(luò)訓(xùn)練。所以需要對(duì)原始數(shù)據(jù)的每一列進(jìn)行歸一化處理。將同一列數(shù)據(jù)歸一化到(0,1)之間。其歸一化公式為
(1)
其中:x為原始數(shù)據(jù)集的任意一列數(shù)據(jù)值;xmin為統(tǒng)計(jì)整列獲得的最小值;xmax為最大值;x*為歸一化后的數(shù)據(jù)值。
1.2.3 特征降維
為了去除數(shù)據(jù)集中冗余信息對(duì)檢測(cè)準(zhǔn)確性的影響,引入一個(gè)特征提取網(wǎng)絡(luò)F作為入侵檢測(cè)模型的前置網(wǎng)絡(luò),該網(wǎng)絡(luò)由2層全連接層構(gòu)成,其目的是將冗余的低級(jí)特征映射為高級(jí)特征。特征提取網(wǎng)絡(luò)F的計(jì)算過程如公式2所示。
y=σ(x′)=σ(F(x*)),
(2)
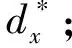
2 基于Transformer網(wǎng)絡(luò)模型的網(wǎng)絡(luò)入侵檢測(cè)
2.1 時(shí)序編碼
首先對(duì)網(wǎng)絡(luò)入侵?jǐn)?shù)據(jù)進(jìn)行時(shí)序編碼,對(duì)于特征數(shù)據(jù)集D,需要將時(shí)序信息嵌入到輸入特征中,通過一層全連接層,對(duì)不同時(shí)間的特征進(jìn)行相應(yīng)的時(shí)序編碼。時(shí)序編碼計(jì)算公式如下
PE(pos,2i)=sin(pos/10 0002i/dx),
(3)
PE(pos,2i+1)=cos(pos/10 0002i/dx),
(4)
其中:pos指的是一段序列中某個(gè)時(shí)刻特征的位置,取值范圍為[0, 最大序列長度];dx是特征維度;i表示在時(shí)序編碼向量中的索引,取值范圍為[0,...,dx]。位置嵌入函數(shù)的周期從2π到10 000×2π變化,而每一個(gè)位置在編碼維度上都會(huì)得到不同周期的sin和cos函數(shù)的取值組合,從而產(chǎn)生獨(dú)一的紋理位置信息,最終使得模型學(xué)到位置之間的依賴關(guān)系和自然語言的時(shí)序特性[4]。
2.2 編解碼模塊
從時(shí)序編碼后的特征序列中取一個(gè)長度為t的連續(xù)序列Xt=x1,....,xt|xi∈Rdx,其中xt是在t時(shí)刻維度為dx的網(wǎng)絡(luò)信息特征向量。輸出為一個(gè)長度為t的Yt=y1,....,yt|yi∈(0,1)狀態(tài)集,其中yt是在t時(shí)刻的狀態(tài)。輸入數(shù)據(jù)經(jīng)過時(shí)序編碼后進(jìn)入編碼模塊,編碼模塊將特征映射到更高維的特征圖(如圖3所示),并將其輸入到解碼模塊中,解碼模塊輸出最終的狀態(tài)集。
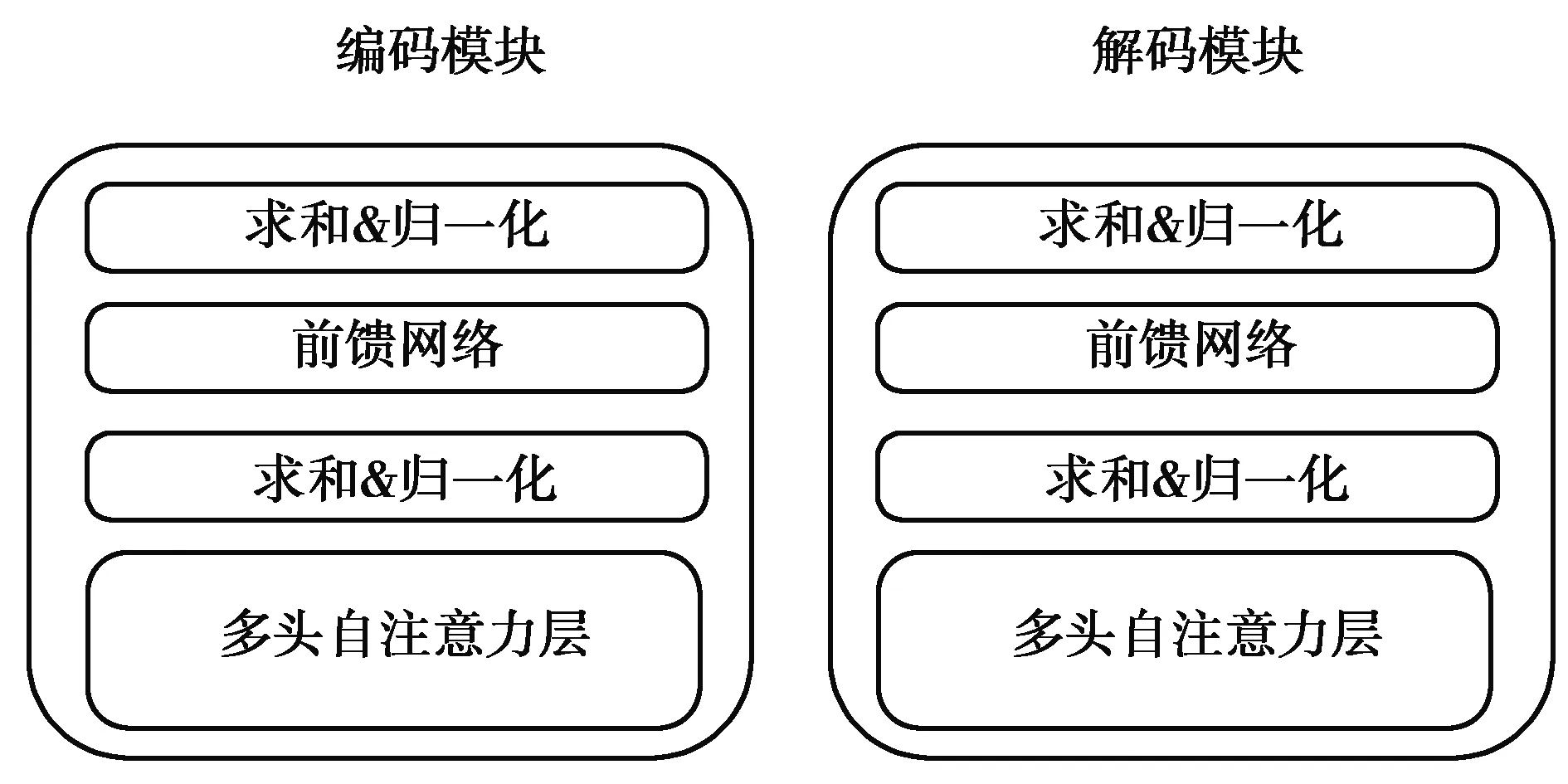
圖3 編碼模塊及解碼模塊結(jié)構(gòu)圖Fig. 3 Structure of encoding module and decoding moudle
編碼模塊與解碼模塊具有相同的結(jié)構(gòu),主要由多頭自注意力層和前饋網(wǎng)絡(luò)組成。為了讓模型去關(guān)注不同方面的信息,采用了多頭自注意力層將注意力模塊分為多個(gè)頭,從而產(chǎn)生多個(gè)子空間,增強(qiáng)模型性能。
2.3 網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計(jì)
網(wǎng)絡(luò)由編碼器和解碼器組成(如圖4所示),其中編碼器主要由輸入層,時(shí)序編碼層和編碼模塊組成,輸入層通過全連接層將輸入時(shí)間序列數(shù)據(jù)映射到高維的向量,然后將輸入的向量與時(shí)序編碼向量逐元素相加,對(duì)其特征進(jìn)行時(shí)序編碼。然后將結(jié)果輸入到編碼層,在經(jīng)過編碼器后生成的特征向量,將其送入解碼器中。

圖4 基于Transformer網(wǎng)絡(luò)入侵檢測(cè)模型Fig. 4 Network intrusion detection model based on transformer
在推理的過程中采用動(dòng)態(tài)解碼的方式,在經(jīng)過編碼器之后獲得高維特征圖,將其輸出到解碼器中,同時(shí)根據(jù)前面時(shí)刻的預(yù)測(cè)結(jié)果依次進(jìn)行。
2.4 損失函數(shù)
由于數(shù)據(jù)樣本中存在正負(fù)樣本不均衡的問題,采用Focal Loss[16]作為損失函數(shù),如公式(5)所示,其廣泛用于目標(biāo)檢測(cè)任務(wù)中的困難樣本挖掘,通過調(diào)整正負(fù)樣本的權(quán)重,使得模型在訓(xùn)練中更關(guān)注難分類的樣本,有效緩解數(shù)據(jù)分布不均問題。
(5)
其中:y為分類層激活函數(shù)的輸出;y′為真實(shí)值,即編碼后的標(biāo)簽;α和γ為調(diào)節(jié)因子,α取值為0.25,γ取值為2。
3 實(shí)驗(yàn)分析
3.1 實(shí)驗(yàn)環(huán)境
本次實(shí)驗(yàn)中采用的硬件環(huán)境配置為Intel(R) Core(TM) i7-9700 CPU 64位處理器、32 GB內(nèi)存,并采用GTX 3080運(yùn)算加速,操作系統(tǒng)為Ubuntu 16.04。按比例4 ∶1隨機(jī)拆分訓(xùn)練集和測(cè)試集,優(yōu)化器采用Adam,設(shè)置初始學(xué)習(xí)率為0.001,epoch數(shù)為100。
3.2 驗(yàn)證方法
為了對(duì)實(shí)驗(yàn)結(jié)果進(jìn)行有效性能評(píng)估,采用二分類任務(wù)評(píng)價(jià)的標(biāo)準(zhǔn)混淆矩陣,混淆矩陣如表3所示。

表3 混淆矩陣
根據(jù)混淆矩陣,可以得到以下3個(gè)評(píng)價(jià)指標(biāo)包括精度(PRE)、檢出率(TPR)、 F1分?jǐn)?shù),如公式(6)、(7)和(8)所示。
精度(PRE)
(6)
檢出率(TPR)
(7)
F1分?jǐn)?shù)
(8)
3.3 性能評(píng)估
與傳統(tǒng)方法機(jī)器學(xué)習(xí)方法、基于深度學(xué)習(xí)的機(jī)器學(xué)習(xí)方法進(jìn)行對(duì)比分析實(shí)驗(yàn)[17-21]。傳統(tǒng)方法,與基于特征提取的支持向量機(jī)(SVM)算法及基于聚類的最鄰近結(jié)點(diǎn)算法(KNN)算法進(jìn)行對(duì)比。深度學(xué)習(xí)方法,與深度神經(jīng)網(wǎng)絡(luò)(DNN)和基于遞歸神經(jīng)網(wǎng)絡(luò)的長短時(shí)記憶神經(jīng)網(wǎng)絡(luò)(LSTM)進(jìn)行對(duì)比。在不同數(shù)據(jù)集上,采用精度、檢出率和F1分?jǐn)?shù)3個(gè)準(zhǔn)確性指標(biāo)進(jìn)行對(duì)比實(shí)驗(yàn),驗(yàn)證相對(duì)于其他模型,基于Transformer網(wǎng)絡(luò)模型的檢測(cè)方法在檢測(cè)效果上的優(yōu)勢(shì)。圖5、圖6分別展示了與傳統(tǒng)方法和與深度學(xué)習(xí)方法的對(duì)比實(shí)驗(yàn)結(jié)果。

圖5 傳統(tǒng)方法對(duì)比實(shí)驗(yàn)結(jié)果Fig. 5 Comparison experimental results of traditional methods

圖6 深度學(xué)習(xí)方法對(duì)比實(shí)驗(yàn)結(jié)果Fig. 6 Comparison experimental results of deep learning methods
1)與傳統(tǒng)方法相比,提出的檢測(cè)方法在精度和檢出率方面都有明顯優(yōu)勢(shì),SVM相較KNN提升一定檢測(cè)效果,但仍不佳。在不同數(shù)據(jù)集上,傳統(tǒng)方法檢測(cè)效果受影響較大,而研究方法無論是在數(shù)據(jù)分布不均的KDD-Cup-99數(shù)據(jù)集上,還是在數(shù)據(jù)相對(duì)分布均勻的NSL-KDD數(shù)據(jù)集上,都能取得好的檢測(cè)效果。
2)與深度學(xué)習(xí)方法進(jìn)行對(duì)比實(shí)驗(yàn),采用相同的模型,使用不同的數(shù)據(jù)集訓(xùn)練,DNN與LSTM的檢測(cè)效果也會(huì)受到影響,各指標(biāo)波動(dòng)明顯大于檢測(cè)模型,這表明方法在模型泛化性能上更具優(yōu)勢(shì)。采用相同的訓(xùn)練集訓(xùn)練,使用不同的模型進(jìn)行對(duì)比,深度學(xué)習(xí)模型均能取得95%以上的精度和檢出率,且具有時(shí)序?qū)W習(xí)能力的LSTM比DNN有更好的準(zhǔn)確性,說明網(wǎng)絡(luò)入侵行為存在可用的時(shí)序信息,提出檢測(cè)方法在各指標(biāo)上取得了99%以上分?jǐn)?shù),優(yōu)于其他深度學(xué)習(xí)模型。實(shí)驗(yàn)結(jié)果表明,針對(duì)數(shù)據(jù)分布、時(shí)序信息學(xué)習(xí)及網(wǎng)絡(luò)結(jié)構(gòu)改進(jìn)都有效提升網(wǎng)絡(luò)入侵檢測(cè)效果。
4 結(jié) 語
提出一種基于Transformer網(wǎng)絡(luò)模型的網(wǎng)絡(luò)入侵檢測(cè)方法。所提出的Transformer網(wǎng)絡(luò)模型基于降維特征,利用多頭自注意力機(jī)制學(xué)習(xí)到網(wǎng)絡(luò)入侵?jǐn)?shù)據(jù)時(shí)序特征,通過選取最優(yōu)的損失函數(shù)和訓(xùn)練參數(shù)進(jìn)行并行化訓(xùn)練,結(jié)合特征提取的數(shù)據(jù)預(yù)處理方式,緩解數(shù)據(jù)分布不均衡問題,有效提高檢測(cè)效果。實(shí)驗(yàn)結(jié)果表明,在不同數(shù)據(jù)集上,相比傳統(tǒng)方法以及深度學(xué)習(xí)方法,采用精度、檢出率和F1分?jǐn)?shù)作為指標(biāo),都取得了最佳檢測(cè)效果。
猜你喜歡
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
