基于集成學習的電費數據異常檢測方法
2021-12-31 01:20:04廣東電網有限責任公司客戶服務中心冼文祥伍廣斌
電力設備管理 2021年13期
廣東電網有限責任公司客戶服務中心 康 峰 冼文祥 伍廣斌 舒 暢
隨著供電企業智能電網的不斷建設發展,智能電網終端能夠采集海量用戶用電數據,采集到的海量電力數據將存儲在供電企業內部的電力營銷系統的服務器中,供電企業通過結合電費核算的人為經驗,建立相應的用戶電費數據異常檢測數學模型,對大批量的用戶電費數據進行處理分析,設計出相關的電費異常檢測規則。供電企業通過對用戶電費數據異常檢測規則的配置與優化,達到過濾排除絕大部分用電正常客戶,篩選出電費數據異常的客戶進行再次復核,從而縮小了電費數據復核的范圍,提高電費復核工作的效率。
據調研,廣東電網公司現有的用戶電費數據異常檢測判斷規則達100多條,如果在電費數據核查過程中每一條電費數據都需要遍歷一次全部的規則,將會給電力營銷部門帶來繁重的工作量,并且核查時間長,極大降低了電力營銷部門的運行效率,并且通過規則篩選出的異常電費數據命中率低,加重了電費復核工作的負擔,急需引入智能化的用戶電費數據異常檢測手段,提高檢出率和準確性。近年來,隨著計算機智能化的機器學習技術的逐漸成熟,電網企業和高校的研究人員開始關注用戶用電數據計算機智能篩選的潛在價值,基于機器學習的用戶用電行為分析逐漸成為電力數據挖掘的一個熱門的應用場景。
周李等[1]利用用電數據的時序特征,使用稀疏編碼的模型方法來挖掘用戶的原始用電數據,通過各個特征的使用頻率來判斷用戶用電行為模式和異常行為。莊池杰等[2]提出局部離群因子檢測算法,計算不同類別的用戶的不同用電模式,按登記的用戶類型事先分類,然后對每一類用戶分別運用離群因子檢測算法檢測用電異常。許剛等[3]建立用戶側行為模式信息簇,利用隨機權網絡的有監督學習得到隨機森林模型,并對其進行稀疏化處理,依據異常積累量指標來判斷樣本是否存在異常。
隨著大數據技術的快速發展,很多學者也在嘗試結合大數據平臺解決海量用電數據處理問題,取得了一定的成果。其中,趙莉等[4]在Hadoop 平臺上實現改進k-means 算法的用電數據分析,提高了數據處理效率。張素香等[5]提出了基于k-means聚類算法的用戶用電行為分析模型在云平臺上的實現方法。ANGELOS 等[6]提出基于模糊集原理與聚類分析的用戶側異常行為檢測方法。DEPURU 等[7]利用歷史數據建立了用戶模式數據集,并對多用戶在線異常檢測技術進行了研究。
本文的主要研究內容包括三方面:首先是對電費數據進行預處理;然后是選取深度森林等機器學習算法對電費數據進行檢測,測試各機器學習算法的檢測性能;最后通過對深度森林等算法的集成學習,測試集成學習的檢測性能。
1 研究模型設計
基于集成學習的電費數據異常檢測方法模型設計流程如圖1所示。在電費數據異常檢測方法研究之前,需要對電費數據進行預處理,由于獲取的電費數據當中異常電費數據占比極低,存在樣本不平衡的問題,若直接采用原始電費數據樣本進行實驗,將會降低電費數據異常檢測的表現性能。
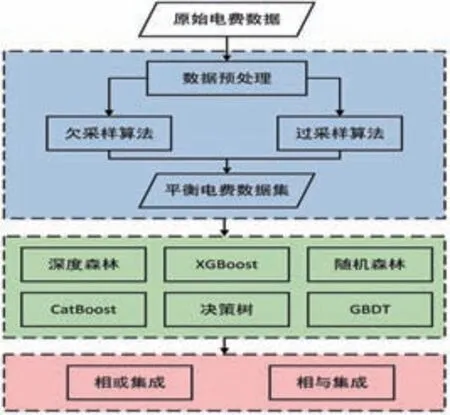
圖1 電費數據異常檢測方法模型設計流程
為解決樣本不平衡的問題,本文采用了過采樣算法和欠采樣算法對電費數據進行處理。欠采樣處理采用了隨機欠采樣算法,隨機欠采樣算法通過隨機抽取多數類電費數據樣本,在本文中為非異常電費數據,異常數據樣本保持不變,最終使得非異常數據與異常數據樣本的比例趨于平衡。過采樣處理采用了SMOTE 算法,它是基于隨機過采樣算法的一種改進方案,解決了隨機過采樣容易產生模型過擬合的問題。經過欠采樣和過采樣算法處理之后,得到了本文實驗所用的某供電局的真實電費數據集,通過對電費數據集進行缺失值補全和對文本類數據進行標簽編碼,進一步使電費數據符合機器學習算法訓練的要求。
從上一步獲取到了經過數據預處理的電費數據集之后,通過實驗選出了表現性能較好的深度森林(DF)、XGBoost、隨機森林(RF)、CatBoost、決策樹(DT)和GBDT 六種機器學習算法進行電費數據異常檢測。后五種機器學習算法在異常檢測分類領域應用較為成熟,深度森林算法于2017年提出,這是一種集合了決策樹的機器學習方法,借鑒了深度神經網絡的結構,由多粒度掃描和級聯森林兩部分結構組成,作為一種基于決策樹的算法,深度森林超參數較少,便于對參數進行調節,從而更易訓練得到較好電費數據異常檢測結果。
最后,通過對六種機器學習算法的預測結果進行集成學習,對不同機器學習模型進行了融合,綜合了六種機器學習算法各自的優點。本文設計了相或集成與相與集成的算法來集成多個機器學習分類器。相或集成算法指的是只要六個機器學習模型中有一個檢測到了電費數據異常,集成學習模型就判斷該條電費數據存在異常;相與集成算法指的是只有當所有六個機器學習模型都檢測到了電費數據異常時,集成學習模型才判斷該條電費數據存在異常。
2 數據來源與評估指標選取
本文選取的是廣東電網某供電局2020年9個月的真實電費數據,為了確保用電用戶隱私,獲取的電費數據均經過了脫敏處理,本文研究所用的電費數據集僅用以學術研究。原始的電費數據集共有1600余萬條,經過數據欠采樣及過采樣算法處理之后,最終獲取了30萬條電費數據用以實驗,其中包括1139條真實異常電費數據,其余均為非異常電費數據。電費數據集包括了88個原始字段,其中包括了一個人為添加的異常標記字段。經過分析發現,這88個字段當中部分字段存在一定的相關性,為了避免電費數據的信息冗余以及模型過擬合,本文采用基尼重要性來對全部電費數據字段進行重要性排序,基尼重要性由隨機森林算法訓練和計算得出。
根據特征重要性排序的結果以及人為經驗的分析,最終刪除了21個字段,保留了67個字段的電費數據進行實驗。電費數據異常檢測基于用戶分類的角度完成異常檢測工作,首先所有的電費數據都是未知異常數據,檢測出為異常數據標記為1,其他非異常數據標記為0。表1所示的誤差矩陣比較清晰的展示了機器學習模型的電費數據異常檢測結果。
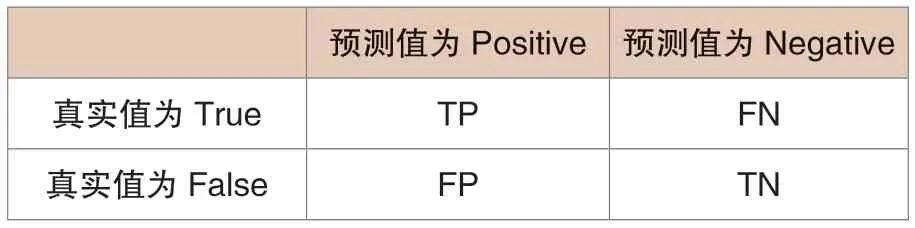
表1 誤差矩陣
本文中將電費異常數據分為正類,電費非異常數據分為負類,機器學習算法在測試集上預測異常或者非異常,最終是為了生成一個泛化程度高的機器學習模型。在誤差矩陣中TP 是正確預測異常電費數據的數量,FN 是正確預測非異常電費數據的數量,FP 和TN 是異常和非異常電費數據錯誤分類的數量。以下介紹本文選取的評估指標:
查準率(Precision)本文中又稱命中率,表示所有預測為異常數據的結果中,真正的電費數據異常的比例,其表達式為;查準率(Recall)本文中又稱檢出率,表示測試集中所有真正的電費異常數據中,被機器學習模型找出來的比例,其表達式為。
F值(F-Score),是命中率與檢出率的加權調和平均值,度量了命中率對檢出率的相對重要性,其表達式為,當α 為1時,就是常用的機器學習模型評估指標F1值,F1值綜合考慮了電費數據異常命中率與檢出率的影響,通常F1值越大說明機器學習模型的檢測效果越好,其表達式為。
3 實驗及結果分析
將電費數據集以8:2的比例隨機抽樣劃分為訓練數據集和測試數據集,并且進行五折交叉驗證,以避免因為電費數據集劃分引起的偶然誤差,保證所得電費數據異常檢測結果的可靠性。首先使用全量數據集分別對深度森林、XGBoost、隨機森林、CatBoost、決策樹和GBDT 六種機器學習算法模型進行實驗驗證,對比各個機器學習算法對電費數據異常檢測的評估指標并對結果進行分析,其查準率、查全率、F1值分別為0.889/0.692/0.778/0.778/0.5/0.583,0.8/0.9/0.7/0.7/0.9/0.7,0.842/0.783/0.737/0.737/0.643/0.636。
通過實驗結果可以看出,深度森林的表現效果在六種機器學習算法中整體最優,GBDT 算法的電費數據異常檢測效果較差。隨后使用相或集成與相與集成的算法來集成多個機器學習模型的電費數據異常檢測結果,查準率、查全率、F1值的相或集成與相與集成學習算法的實驗結果分別為0.357/1、1/0.6、0.526/0.75,可看出二算法分別能夠最大化提高電費數據異常檢測的查全率和查準率,相比當前供電企業采用傳統的規則篩選電費異常數據的方法,雖然可以保證檢出的電費異常數據數量最大化,但命中率低于10%,相或集成算法的實驗結果展示了在測試集中查全率接近100%的情況之下,電費數據異常的命中率能夠達到35%左右,已經高于當前供電企業規則篩選異常電費數據的方法。
相與集成算法結果表明,在舍棄電費數據異常查全率的前提下,電費異常數據的命中率能夠達到將近100%的水平,相與集成算法能夠幫助供電企業發現部分難以發掘的異常電費數據,為供電企業后續電費核算工作的完善提供支持。
綜上,集成學習的應用能夠幫助供電企業在滿足電費異常數據的檢出率最大化的同時提高電費異常數據的命中率,與傳統規則篩選異常電費數據的方法相比,具有更快的響應時間和更高的命中率,能夠滿足當前智能電網的發展要求,有利于減輕電費數據復核部門的工作負擔,為供電企業服務水平的提高提供了新的借鑒價值。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
