人工智能在鉆井工程中的應用現狀與發展建議
2022-01-04 03:15:56王敏生光新軍耿黎東
石油鉆采工藝 2021年4期
王敏生 光新軍 耿黎東
中國石化石油工程技術研究院
人工智能作為新一輪產業變革和科技革命的新引擎和核心驅動力,已成為引領未來發展的戰略性新興技術,正在對各行業產生深刻影響。人工智能技術是油氣勘探開發降本增效的有效手段,也是實現關鍵技術升級換代,提高競爭力的有效途徑[1-3]。近年來,國外嘗試將人工智能應用于鉆井工程領域,開展了基于人工智能的鉆井設計、鉆井參數優化、井眼軌跡控制、風險預警、鉆井程序決策等探索研究,部分技術實現了現場應用,顯示了較好的應用前景。國內在將人工智能應用于鉆井機械鉆速預測、漏失風險預測、隨鉆地質導向智能決策等方面進行了有益探索[4-10]。為了給我國利用人工智能技術實現鉆井提速提效提供借鑒和研發思路,筆者對人工智能及其在鉆井工程中的應用特點、應用進展和應用關鍵進行了分析,提出了攻關思路和研發重點。
1 人工智能在鉆井工程中的發展階段及特點
1.1 人工智能在鉆井工程中的發展階段
人工智能是通過提高機器的計算力、感知力、認知力、推理能力等智能水平,使其具有判斷、推理、證明、識別、感知、理解、溝通、規劃和學習等思維活動,讓機器能夠自主判斷和決策,完成原本要靠人類智能才能完成的工作[11]。按照應用程度,人工智能可以分為弱人工智能、強人工智能和超人工智能3個階段。弱人工智能專注于且只能解決特定領域問題的人工智能,如圖像識別、語音識別、語義分析、智能搜索等;強人工智能能夠和人類一樣對世界進行感知和交互,通過自我學習的方式對所有領域進行記憶、推理和解決問題,如無人駕駛、無人機、智能機器人等;超強人工智能在所有領域全方位超越人類大腦的思維能力,能力和運用范圍仍在一個無法預估的范疇。目前,鉆井工程領域的人工智能研究屬于弱人工智能范疇,即通過人工智能算法將一些不確定的數據輸入來進行不確定性的決策,實現自我學習和演變。人工智能使用較為廣泛的算法包括人工神經網絡、模糊邏輯、遺傳算法、支持向量機、案例推理和混合算法等。
1.2 人工智能在鉆井工程中的應用特點
與傳統建模或數據分析方法相比,人工智能技術在鉆井工程中應用主要具有以下優勢:(1)能夠在輸入和輸出變量之間無關系假設的情況下,對復雜的非線性過程進行建模;(2)計算結果比使用線性或非線性多元回歸預測模型和經驗模型更加準確;(3)能夠通過分析大量數據,在不明確規則的情況下通過進行最終目標模型訓練選取特征,具有自動學習特征的能力,并可以利用不完整或有噪聲的數據;(4)成本效益較好,使用數據集進行系統訓練,而不必編寫程序,因此更具成本效益,也更易于應對變化;(5)降低了對算力的要求,以深度學習算法為例,通過采用多層調參、層層收斂的方式,保證參數的數量始終處于合理范圍內,提高了模型的可計算性。
與其他工具一樣,人工智能技術也有自身的局限性。如人工神經網絡僅根據數據集訓練反映輸出和輸入變量之間的關系,這使人們擔憂其是否能較好地表征數據集。有人提出將多個算法組合成混合算法方案,或將人工智能算法與傳統模型進行集成來解決黑盒子問題;使用遺傳算法很難像使用數學編程方法那樣真正發現問題和解決問題,為了深入發現問題,可能需要多次運行模型,評估解決方案對問題的各種假設和參數的敏感性,缺乏達到“最優”解決方案的能力。其他局限還包括處理時間較長、系統需要更大的計算資源并且有時會產生過度擬合等[12-13]。
2 人工智能在鉆井工程中的應用
在數據采集、傳輸技術發展的協同下,人工智能技術在鉆井設計、鉆井參數優化、鉆井井眼軌跡控制、井筒完整性監控、風險預警、程序決策等方面正在發揮積極作用,部分技術已經實現現場應用并取得良好效果。
2.1 鉆井優化設計
鉆井的優化設計是保證安全、高效和低成本的鉆井作業的基礎,人工智能技術可用于井眼軌道優化、鉆頭優選、地層破裂壓力和漏失壓力預測、套管下深優化、水泥漿性能預測等,可以提高鉆井設計的準確性和可靠性。國民油井公司采用人工神經網絡對鉆頭選擇數據庫的數據進行訓練,數據庫中包括鉆頭編碼、巖石強度數據、地質力學、地層壓實特征和對應于巖石的常規機械鉆速值等信息,輸入地理位置、地質特征、巖石力學數據后,即可輸出選擇的鉆頭類型、效果預測及使用指南。科威特大學采用廣義回歸神經網絡,輸入深度、上覆地層壓力梯度和泊松比等參數,即可預測破裂壓力,精度在1%以內,比傳統方法(Eaton等方法)精確度更高[14]。卡爾加里大學采用反向傳播神經網絡,輸入地理位置、深度、孔隙壓力、套管腐蝕速率、套管強度等參數,預測套管失效的深度和概率,但該方法仍然需要進一步開展關鍵數據的提取,提高其預測結果的準確性[15]。斯倫貝謝采用人工神經網絡(ANN),根據水泥的漫反射紅外傅里葉變換光譜、粒度分布等來預測水泥漿性能[16]。
2.2 鉆井參數優化
鉆井過程參數的優化主要通過對井下機械鉆速、井底鉆具組合響應特性、鉆柱振動、鉆頭性能、鉆遇地層特性等參數的監測,來降低鉆井作業的不確定性,并提高預測的置信度。
鉆井過程中經常會遇到不同的地質條件,如巖性的變化、地層壓力的變化等,實時了解鉆頭周圍巖石的物理及力學性質對于優化鉆井參數非常重要。盡管隨鉆測井可以提供這些信息,但其傳遞到地面的信息與鉆頭實際性能之間存在深度滯后。奧克拉荷馬大學以機器學習工作流程中的鉆頭與鉆柱性能數據為基礎,來預測隨鉆鉆頭處的巖性。工作流程如下:首先利用盒形圖和交叉圖對裸眼測井資料進行分析,并生成相關系數表,剔除異常值,并準備數據聚類;第2步對測井數據進行主成分分析,去除相關變量,用不相關主成分代替相關變量,利用K-均值、SOM和層次聚類3種聚類技術對巖性變化進行分離;第3步通過觀察3個巖群的測井數據和巖心特征,確定這些巖群(或巖相)的巖石物理意義;最后,利用已清理和準備好的MWD數據,采用隨機森林、梯度增強和神經網絡等技術,對不同巖性群進行預測,工作流程如圖1所示[17]。該方法在挪威Volve油田現場進行了測試,預測準確率達75%。

圖1 機器學習預測地層巖性Fig. 1 Prediction of formation lithology by machine learning
鉆井機械鉆速的預測對于優化鉆井參數起著至關重要的作用,可用于檢查鉆井數據,優化機械鉆速,降低機械比能,提高鉆頭壽命。基于傳統線性統計的方法無法獲得理想的鉆速預測結果,需要采用非線性方法和先進的集成技術。德克薩斯A&M大學采用人工智能算法進行網絡機械鉆速的預測[18],首先建立包括層間厚度、鉆井液密度、鉆壓、轉速、流量、鉆進深度等參數的鉆速特征集合;繪制不同特征參數隨時間的變化值,檢查是否有特定參數控制響應;利用不同參數之間的相關性對數據集合中的缺失值進行補全,同時剔除由于測量誤差或者卡鉆等事故造成的數據誤差;利用主成分分析法對特征數量進行降維,以此來提升模型的預測精度以及降低計算的復雜程度,繼續通過特征分析推導出每個特征屬性的相對權重和貢獻;再選取支持向量回歸模型、梯度增強模型、神經網絡模型、K值最近鄰模型、隨機森林與梯度增強集成模型等5種人工智能預測模型,多種模型的訓練有助于提高精度和減少誤差,最終隨機森林算法以10%的均方差成功預測和優化了鉆井參數,鉆速預測效果最好。
2.3 鉆井井眼軌跡控制
在地質導向和旋轉導向施工過程中,需要經驗豐富的專業人員做大量的決策,人工判斷易出現錯誤與誤差。利用人工智能技術,鉆井井眼軌跡導向與控制完全可以離開人的干預,井下信息的測量、傳輸和控制指令的產生、執行完全可以自動進行。殼牌研發了智能定向鉆井系統——Shell GeodesicTM[19]。該系統首先將收集的鉆井參數通過篩選、過濾、歸一化,再選擇適當的參數用于構建和訓練人工神經網絡。人工神經網絡利用強化學習方法來細化訓練歷史數據,通過自主學習模擬施工人員日常操作,訓練后的人工神經網絡可以最大限度地降低實鉆井眼軌跡與預設值的偏差,提高吻合度,減少后期糾正井眼軌跡的工作量,提高機械鉆速,降低作業成本。成熟的神經網絡可以媲美一個定向鉆井專家的決策能力,并保證決策失誤率在3%以內。在美國二疊紀盆地,利用14口水平井定向鉆井數據,通過當前工具面、鉆壓、鉆井液排量、機械鉆速、壓差、旋轉扭矩,預測未來壓差和旋轉扭矩等,經過1 800 000個訓練步驟后,壓差預測誤差為0.21%,扭矩預測誤差為2.72%。
2.4 井筒完整性監控
在鉆井過程中,特別是高溫高壓深井,會遇到井漏等各種井下復雜情況,增加非生產時間。目前,普遍通過電阻率測井、計算井筒溫度剖面和循環當量密度等方式進行井漏預測。然而,這些方法在應用過程中由于成本或技術原因而無法成功。法赫德國王石油與礦業大學采用支持向量機(SVM)的機器學習技術成功實現了井漏預測。該方法在三維特征空間中訓練樣本,在鉆井漏失預測方面具有比人工神經網絡和傳統方法更高的精度,在鉆進漏失層前,可幫助現場鉆井工程師提前預測,從而及早調整鉆井參數或堵漏方案。SVM技術需要井漏記錄數據和相關鉆井參數。井漏數據包括出口流量、漏失井深;輸入的鉆井參數包括井深、大鉤載荷、大鉤高度、機械鉆速、轉速、立壓、扭矩、鉆壓等。再對數據進行處理,去除無效值,并進行過濾和平滑后,將單井的鉆井參數分成兩組,一組用來機器學習和訓練,另一組用來測試預測結果的精度,最終達到鉆井漏失預測的目標。利用SVM技術和基于徑向基的神經網絡技術(RBF)對鉆井漏失情況進行了預測,75%的數據用于訓練,25%的數據用于測試和修正相關模型。結果顯示,RBF技術的預測相關系數為0.981,均方根誤差為0.097,而SVM預測漏失相關度為1,均方根誤差為0,具有更高的精度[20]。 密蘇里科學技術大學采用機器學習的方法,準確預測伊拉克Rumaila油田Dammam地層鉆井過程中的鉆井液漏失體積、ECD和ROP等參數,與傳統方法相比,該方法預測精度與實際情況更吻合[21]。
2.5 鉆井風險識別
意外的溢流和井涌對鉆井作業構成重大風險。常用的溢漏報警系統采用固定的判斷界限,誤報率高,可靠性低。Pason系統公司提出了一種適用于循環系統監測的機器學習算法框架,通過為循環出口流量和泥漿池增量提供預期的安全操作范圍,使其保持非常低的誤報率。該算法可以用圖2中的流程來描述,棕黃色框表示功能,藍色框表示可能的用戶輸入,綠色框表示基于司鉆輸入參數(入口流量和鉆頭運動),使用在線自適應機器學習明確估計出口流量和泥漿池增量的期望值[22]。自適應機器學習算法用于自動和自適應地更新預期的操作范圍,預測指標與預期操作范圍的直接比較用于生成警告,并可將這些警告組合起來生成警報。通過使用大量標記的溢流和漏失來評估其研發的系統,結果表明,與現有的溢流和漏失監測的固定范圍方法相比,新方法降低虛報警率,增強監測概率,減少預警時間等方面有顯著改進。經典機器學習算法提供了強大的功能,但是這些方法的內部工作是不透明的,不滿足實際動態應用需求。Pason公司提出的溢漏監測機器學習框架,通過提供明確的安全操作界限和用戶驅動的模型重置,將數據動態分析功能緊密集成到鉆井作業人員中,使得鉆井作業人員能夠將其專業知識與可解釋的機器學習提供的信息結合起來,增強了溢流監測的可靠性與靈活性。
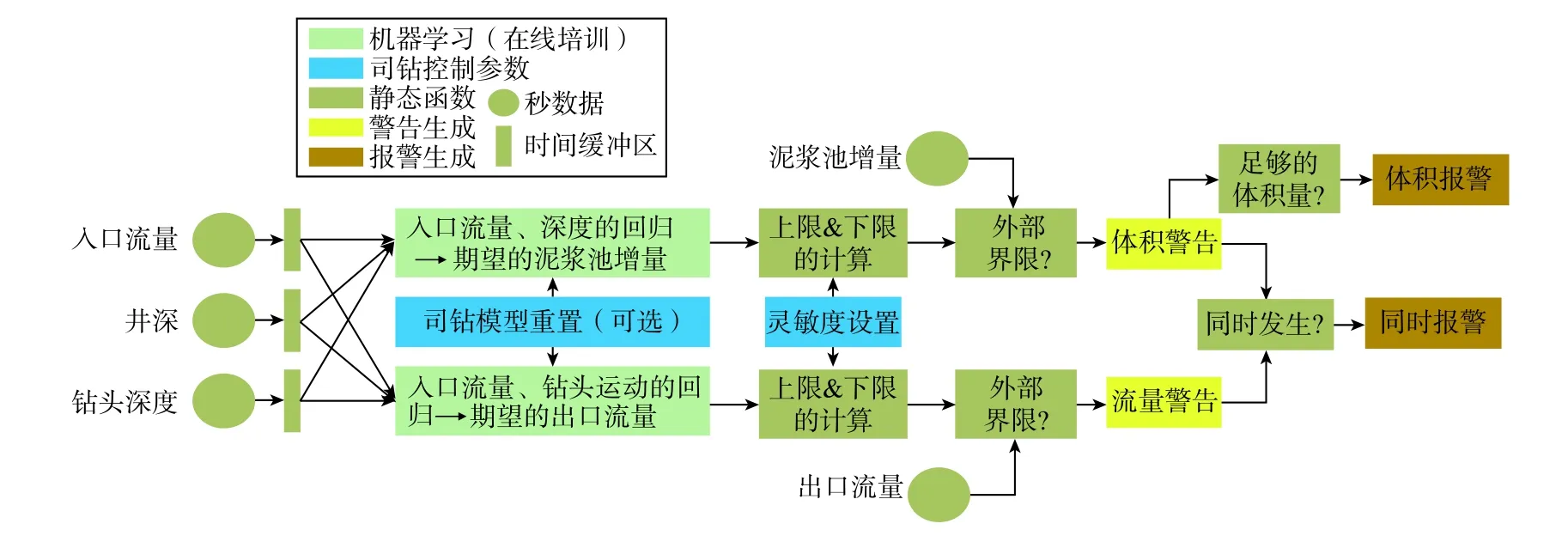
圖2 使用預測變量進行溢漏監測的機器學習示例Fig. 2 Example of machine learning for spill monitoring using predictive variables
鉆井過程中套管下入井中時,管柱在井內會受阻遇卡,導致鉆井延遲,費用昂貴。BP公司運用人工智能技術進行套管卡管預測,讓司鉆在卡管發生前校正管柱下入的方法。該方法通過建立相關數學算法概率模型(如決策樹、神經網絡等),再從大量歷史數據中,識別出過去發生的與靜摩擦事件相關的230個屬性特征,基于歷史模式、預測模型,可在5 s內對靜摩擦事件進行識別。應用該方法后,預測卡管精確度達到85%,大大減少了卡管造成的損失。德克薩斯大學奧斯丁分校采用自主學習(ALM,active learning method) ,通過上千口井的鉆井數據,使用反向傳播學習規則,分析輸入測深、鉆井液參數、鉆壓、轉速等,實時監測可能發生的卡鉆情況,預測精度達到100%,實施流如圖3所示[23]。
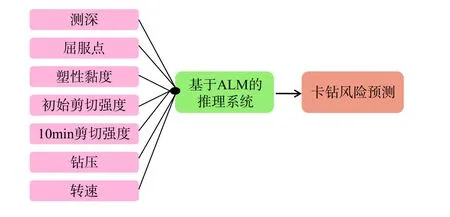
圖3 ALM方法流程圖Fig. 3 ALM method flow chart
2.6 鉆井程序決策
為達到提高產量、降低成本、節省時間的目的,經常要選擇一些特殊的鉆井作業程序,如欠平衡鉆井、過平衡鉆井、噴射鉆井等。為評價所選作業程序的適用性,雪佛龍公司基于案例推理(CBR)進行淺疏松砂巖最佳洗井程序的選擇。為了進行推理評估,建立了包含近5 000口井的生產操作和井筒干預詳細信息的數據庫。通過1組隨機案例的初始測試,表明人工智能工具提出的方法和專家現場指導實施的方法有80%的相似度[24]。在連續油管作業中,作業程序制定主要依據作業者經驗,傳統的連續油管仿真軟件沒有足夠現場數據支撐,無法有效識別風險,在復雜井施工中該作業方式易降低作業質量,甚至損壞作業設備。貝克休斯的CIRCA連續油管軟件則基于過去30年現場數據進行學習和建模改進,將理論模型和以往大量現場經驗數據進行擬合,幫助作業者基于可靠的實際數據進行決策。
3 應用關鍵
在20 世紀八九十年代,油氣領域開始探索引入人工智能技術,由于數據、算力等原因并沒有達到預期的效果,投入削減,研究進度放緩。2010年以來,隨著互聯網、云計算、大數據、芯片、算法快速發展,國外油氣公司、研究機構在人工智能應用于鉆井工程中開展了大量探索,部分技術進行了現場試驗,取得了較好的應用效果,但整體還處于前期研發試驗階段。從應用情況來看,鉆井數據的實時共享、人工智能算法的優選、人工智能內在邏輯規律的解釋和云計算與邊緣計算的協同發展對于鉆井人工智能的成功應用起著至關重要的作用。
3.1 鉆井數據的實時共享
人工智能技術的應用和發展離不開數據基礎的支撐,需要油田分公司、石油公司、科研機構的共同參與,加速大數據平臺的建設,打破“數據孤島”,加強鉆井工程各環節的數據共享,規范數據的采集、傳輸、存儲、轉換、集成和應用,提升數據一致性和可靠性,協同推動鉆井人工智能技術和產品的研發,通過系統集成實現產業化。
3.2 人工智能算法的優選
人工智能應用于鉆井工程的場景包含鉆井設計、鉆井參數優化、鉆井井眼軌跡控制、風險預測等多個作業環節,不同應用場景對人工智能算法的適應性差別較大,因此針對鉆井工程不同應用場景特點對不同的人工智能算法進行比較、優選或組合,對提高人工智能模型的準確性和計算速度非常重要。
3.3 人工智能內在邏輯規律的解釋
人工智能模型根據數據集訓練反映輸出和輸入變量之間的關系,內在邏輯規律無法解釋,未來人工智能的發展需要將“黑匣子”的分析逐步轉化為 “透明匣子”的展示,即讓人工智能技術與鉆井工程的理論、技術深度融合,充分解釋物理、力學、化學機理導致的各種邏輯規律[25-26]。
3.4 云計算與邊緣計算的協同發展
人工智能技術在鉆井工程中的發展離不開強大算力支持,常規油田基地服務器越來越難以支撐大規模數據的計算需求,云計算雖具有強大的計算能力,但無法滿足鉆井工程中近實時、低延時的應用需求,這就要利用邊緣計算形成高效的分布式協調機制和決策模型,以實現鉆井工程作業效率最大化。
4 發展建議
4.1 國內外主要石油公司技術布局與水平對比
國外油公司、油服公司積極開展人工智能技術布局,多采用自主創新與合作研發(與數字巨頭、高校等)并舉、投資小公司的策略。油公司側重通過搭建油田勘探開發大數據分析平臺,將人工智能用于智能油田建設、提高油氣儲層識別、提高油氣采收率、生產設備維護等方面,以提高儲量發現率、油氣采收率,降低作業成本。油服公司側重搭建鉆完井應用平臺,并將相關專業化軟件融入,開展鉆井設計、鉆井優化、鉆井風險預警、完井優化等方面,并與油公司合作開展生產優化、生產監測等方面的研究,共同促進油氣上游技術的智能化發展[27-29]。高校和科研機構更加側重人工智能算法的研究,并與油公司和油服公司合作,將成熟技術集成在油公司和油田服務公司相關應用平臺。表1為國外主要石油公司人工智能技術應用布局及研發策略。

表1 國外主要石油公司人工智能技術布局及策略Table 1 Layout and strategy of artificial intelligence technology of major foreign oil companies
國內大型石油公司在人工智能技術研究方面也取得了一定進展,中國石油搭建了勘探開發夢想云平臺,正在開展人工智能頂層設計,全面推動人工智能在勘探開發中的應用研究;中國石化開發了覆蓋公司內各油田勘探開發業務的協同平臺,研發了鉆井專家決策支持系統,探索了人工智能鉆井參數優化、風險預警和智能導航等研究;中國海油搭建了鉆井遠程專家支持系統,并開展了鉆機系統故障的智能診斷等研究。總體上,我國油氣勘探開發大數據平臺建設方面與國外水平相當,但是人工智能應用場景還不明確、不系統,其發展目標和技術路線不清晰[30]。在鉆井人工智能應用平臺建設、算法優化、智能決策子系統等方面與國外還有一定的差距。
4.2 發展建議
結合我國油氣勘探開發降本增效需求以及人工智能技術本身的發展狀況,建議我國鉆井人工智能技術從3個階段發展:(1)基于大數據、云計算和物聯網技術,構建鉆井人工智能應用軟件平臺,為鉆井智能決策支持提供數據基礎和平臺基礎;(2)針對鉆井具體應用場景,基于人工智能技術研發一批能顯著降本增效的新技術、新裝備和新軟件,為構建智能鉆井生態系統提供核心技術基礎。近期重點開展鉆井參數優化、井眼軌跡控制和風險預警等方面的研究,技術成熟后,通過示范帶動效應,再開展人工智能在其他領域研究;(3)構建智能鉆井生態系統,使人工智能技術滲透進鉆井工程的每一個角落。同時,加強鉆井人工智能基礎理論攻關,加大現場先導試驗,盡快形成我國鉆井人工智能技術體系。
4.2.1 鉆井人工智能應用平臺
鉆井人工智能應用平臺總體架構包括感知層、平臺層、應用層3層結構。感知層借助物聯網手段,通過各類終端數據統一標準化接入,實現對歷史和實時地質數據、鉆井數據、完井數據、測錄井數據和其他數據的全景、廣域采集和感知,匯聚形成鉆井大數據;平臺層提供平臺和業務支撐,利用云提供計算平臺,在此基礎上構建人工智能引擎,通過豐富的機器學習算法和模型庫,支持從數據集選擇、開發、訓練到服務的全流程一站式管理;應用層通過人工智能技術與傳統技術優勢互補,應用于鉆井軌跡優化、風險預警、鉆速優化等場景。
4.2.2 鉆井參數優化
結合地層巖性、鉆頭磨損、破巖效率、鉆柱振動等特征,以最大機械鉆速、最長鉆頭壽命、最大鉆井進尺、最低鉆井成本等為多目標,尋找最佳鉆井工程參數組合。基于機器學習方法對機械鉆速模型進行評估,確定不同鉆井方式下最優模型,并使機器學習模型實現在線自適應更新。利用機器學習算法得到地面-井下參數匹配的代理模型,揭示地面-井下參數的動態匹配關系,實現鉆井工程參數的智能調控,提高鉆井機械鉆速。
4.2.3 鉆井智能導航
通過采集相應的鉆井歷史資料,基于隨機森林、梯度增強、神經網絡等人工智能算法,利用隨鉆時間序列信號智能分類處理方法,對不同巖性群進行識別和預測,實現地層的智能識別與分類。再利用人工智能網絡模型,對隨鉆數據進行實鉆處理和識別,定位鉆頭位置。結合地層智能識別結果,綜合判斷鉆頭在地層中的穿行狀態,利用深度學習算法進行軌跡優化,從而實現高效的智能導向鉆進。
4.2.4 鉆井風險預警
從大量歷史數據中,基于機器學習篩選出鉆井風險(井漏、井涌、井塌等)的關聯參數,建立關聯參數邏輯模型。用不同算法模型計算同一個驗證數據集,評價和優選不同算法模型的可靠性和適用性。基于風險智能診斷模型,結合鉆壓、鉆時、排量、鉆井液密度等實鉆參數,實時預測鉆井作業風險,指導現場作業,減少非生產時間。
4.2.5 基礎前瞻研究
開展人工神經網絡、支持向量機、蟻群算法等算法對具體應用領域的適應性,并構建鉆井工程人工智能應用流程規范和標準體系,突破關鍵技術瓶頸;研發鉆井井筒數字孿生系統,使用地面和井下實時鉆井數據,進行實時建模,以監督和優化鉆井過程;開展人工智能用于非常規油氣藏裂縫表征、鉆井設備與工具預測性維護等前瞻研究,儲備下一代鉆井人工智能技術。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
西安航空學院學報(2022年2期)2022-07-04 07:45:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商界(2019年12期)2019-01-03 06:59:05
IT經理世界(2018年20期)2018-10-24 02:38:24
小康(2017年16期)2017-06-07 09:00:59
光學精密工程(2016年6期)2016-11-07 09:07:19
南風窗(2016年19期)2016-09-21 16:51:29
南風窗(2016年19期)2016-09-21 04:56:22
