中國名人人臉數據集①
2022-01-05 10:20:58杜潘飛李雄偉賈永杰
計算機系統應用 2021年12期
杜潘飛, 李雄偉, 賈永杰
1(陸軍工程大學 石家莊校區, 石家莊 050003)
2(中國人民解放軍 93498 部隊, 保定 071000)
1 引言
隨著深度卷積神經網絡的快速發展, 近來有很多關于收集大尺度人臉識別數據集的工作, 總的來說這些數據集大多是由其他國家的機構收集的, 如YTF[1]、CACD2000[2]、SFC[3], 其中的人臉圖像大多都是國外的人臉, 國內的一些機構在實驗室條件下采集的人臉圖像數量較少. 相關文獻表示人臉的面部特征包含有民族、年齡和性別等基本屬性, 其中民族屬性在人臉認知過程中先于性別和年齡特征, 是判斷人臉的重要依據, 人類學研究表明: 由于受到文化、遺傳、地域等諸多客觀因素的影響, 不同民族面部特征之間確實存在差異[4-9]. 在人臉識別的應用中, 算法的性能嚴重地依賴于數據, 而歐美國家的人臉特征和中國人的特征是有很大差異的, 為此我們在本文中提出一個新的數據集, 其中的人物全部都是中國人, 該數據集包含豐富的姿態、寬廣的年齡范圍.
本工作的主要貢獻有: 首先, 收集了一個尺度較大的國人人臉數據集, 命名為CCFace, 可以公開使用. 第二, 介紹了一種半自動化的數據集生成流程, 它極大地減少了手動標注的工作量, 這種方式為以后收集更大規模的人臉識別數據集提供了借鑒. 第三, 統計了這個數據集的關于性別、年齡、地域、民族等相關信息,并通過實驗說明了不同民族和地域的人臉特征具有獨特性, 本文涉及的代碼實現以及數據集下載地址為:https://github.com/xiayule518/CCFace.
2 相關工作
到目前為止, 在人臉識別中經常使用的公開數據集有很多, 它們中的大多數都是關注于人臉的姿態、年齡、光照、遮擋的多樣性, 很少關注于民族多樣性,在這部分中我們介紹一些相關的數據集, 并分析他們的優缺點.
CAS-PEAL數據集[10], 2004年由中國科學院發布的, 通過高清攝像機拍攝的它是在限制場景下多姿態、表情、配飾、光照的人臉圖像, 包含1040人物(595個男性、445個女性), 99 594張人圖像, 作為國內較早的國人人臉圖像數據集, 其數據集規模較小, 由于一些版權因素的考慮, 其中只有一部分可以公開使用,且是限制場景下收集的, 因此不適合現在流行的非限制場景下的人臉識別的模型訓練使用.
Labeled Faces in the Wild (LFW) 數據集[11], 它于2007年發布, 是人臉識別中使用的最廣泛的數據集之一, 包含5749個人物, 13 000張圖像, 非限制場景下戶外的人臉圖像數據, 由于所包含的圖像數量較少, 故主要作為人臉驗證、識別的性能評價標準.
CASIA-WebFace[12], 2014由溫森塞公司的Yi 和中國科學院的Lei 等人發布的大尺度人臉識別數據集,作者從IMDb網站上爬取的名人圖像, 通過一種半自動的方法進行了標注. 其中包含10 575個不同的人物,共計494 414張人臉圖像, 每個人物的人臉圖像平均大約500個, 但大多都是其他國家的人臉.
CelebA (CelebFaces Attribute)數據集[13], 2015年由香港中文大學發布的大型人臉屬性數據集, 其包含了共計202 599張亞洲名人圖像, 其中每張圖像由40種屬性注釋, 該數據集中的圖像覆蓋了大量的姿勢和背景, 可用于人臉屬性標識訓練、人臉檢測訓練以及landmark標記等.
Glint360K[14], 2020年發布的全球最大最干凈的人臉公開數據集, 包含360 232人物總計17 091 657張來自全世界的人臉圖像. 截止目前為止, 其類別數和圖片數目比主流訓練集的總和還多, 通過采用空間FC訓練策略, 在Glint360K上訓練的基線模型可以很容易地獲得最先進的性能. 該數據集的規模雖然較大, 但其中包含的人物多為國外人物, 其人臉特征和國人相差較大.
3 數據集構建
在人臉識別的研究過程中, 快速且高質量地構建大尺度數據集是算法優化的前提, 為此本文提出一種半自動化的構建方法, 在保證數據集質量的同時, 極大地降低時間成本. 數據集的構建流程如圖1所示(其中帶陰影的模塊為自動過程), 數據集的構建過程主要包括人物圖像獲取、人物圖像過濾和人臉圖像標注3個步驟.
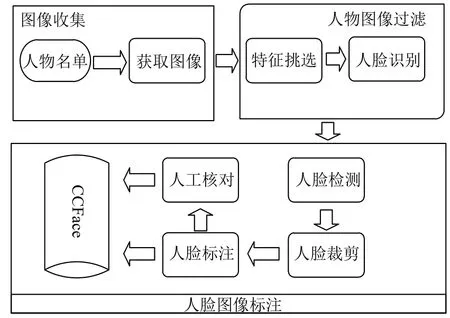
圖1 數據集構建流程
3.1 人物圖像獲取
數據集構建的基礎是獲取包含指定人物人臉區域的圖像, 在這部分中詳細介紹如何從互聯網上獲取指定人物圖像, 主要包括: 確定人物名單和下載人物圖像.考慮到網絡圖片獲取的難易程度和隱私等問題, 也為了盡可能多地獲取人物圖像, 本文選擇國內網絡或電視中出鏡率較高的名人圖像作為獲取對象, 首先在搜索引擎中以“中國名人名單列表”為關鍵字獲取100位公眾人物名單, 之后以知識圖譜的搜索方式搜索于此有關聯的人物, 最后從其中確定了431個作為候選人物.
確定人物名單之后, 使用爬蟲的方法, 從互聯網上通過關鍵字搜索的方式獲取人物圖像, 并全部保存為jpg格式, 下載的每個人物的圖像分別放在該人物的文件夾下. 為加快的下載圖像速度, 在本文中使用多線程的方式(本實驗中采用16線程), 下載過程中獲取的圖像中包含很多錯誤圖像(例如下載錯誤的、不能正常打開的), 故在下載之后首先使用OpenCV過濾下載出錯的圖像. 首次過濾之后, 共獲得498 048張人物圖像,這步獲取的人物圖像中可能包含一張或多張人臉圖像,也可能不包含候選人物的人臉圖像.
3.2 人物圖像過濾
人物圖像下載完成之后, 為過濾掉其中不包含候選人物的圖像以及明星人物圖像化妝過重而不能識別的問題, 在ArcFace[15]提供的模型算法的基礎上, 對圖像進行識別分類, 通過對人物圖像中的人臉進行識別來移除其中不包含候選人物和妝容影響過大的圖像, 主要的流程為: 挑選特征人臉圖像, 使用人臉識別算法分類.
當前人臉識別算法的基礎是構建人臉特征庫, 即對于所有候選人物通過從已下載的人物圖像中挑只包含選該人物清晰的、不同年齡的3~5張無狀或淡妝正臉圖像作為該人物特征. 在手工挑選所有人物的人臉特征圖像完成后, 通過使用卷積神經網絡提取種子圖像的特征, 生成512維的人臉特征向量, 并將其保存為bin格式文件, 所有特征向量便構成人臉特征庫, 以此作為識別過程中的搜索比較的對象.
為了將已下載的所有圖像按其所包含的候選人物人臉圖像移動到對應人物名稱的文件夾內, 我們使用人臉識別算法ArcFace來識別圖像中包含的人物. 在已經構建完成的候選人物人臉特征庫基礎上, 對于下載的每一張圖像, 執行人臉檢測-向量特征化-識別的過程來和該人物挑選的特征向量做比較, 判斷該圖像中是否包含該人物的人臉圖像. 此步完成之后我們移除不包含候選人物的圖像, 此時共包含503 727張人物圖像.
3.3 人臉圖像標注
對原始的人物圖像分類完成之后, 首先要檢測其中的人臉區域(一些圖像中可能含有多個人臉), 并將其保存為指定像素大小的本地圖片, 繼而完成人臉圖像的分類, 最后人工核對人臉圖像, 在完成這些工作之后, 便生成了可用于人臉識別的數據集.
為了獲取質量較好的人臉區域圖像, 通過嘗試幾種人臉檢測算法, 最終決定在第3.2節生成的人物原始圖像基礎上, 使用MTCNN[16]提供的模型進行人臉檢測, 人臉檢測過程檢測到的人臉圖像中仍然可能存在混淆項(例如不屬于該人物的圖像), 故再次使用人臉識別算法對每個人物的人臉圖像作識別, 移除其中不屬于該人物的人臉圖像; 對于移除混淆項后仍然存在的重疊項和未成功識別的混淆項, 采取人工刪除的方法來清洗每個人物的人臉圖像.
在完成所有的數據清洗工作之后, CCFace最終得到431個人物總計506 874張人臉圖像. 由于該數據集的尺度較大, 我們不能完全保證所有檢測到的人臉都被正確標注, 數據集的質量將由以下的實驗說明. 從數據集的構建過程可以看出, 這種構建方法需要人工操作的部分為人物名單挑選、特征人物圖像挑選與人臉標注結果核對, 這部分的工作量約占整個流程的30%左右, 比其它數據集構建過程減少約30%~40%的工作量.
4 數據集統計分析
在人臉識別中, 多個因素會影響識別精度, 在前言部分介紹的當前通用數據集都不同程度的考慮了光照、姿態和遮擋等因素的影響, 其它一些數據集(如IMDBFace[17]、CACD2000和Adience[18])研究了年齡、性別對精度的影響; NIST最新研究結果[19]表示面部識別的表現通常會因為人的種族、性別或者年齡而產生差異. 因此在CCFace數據集收集的人臉圖像中不僅包含姿態、光照、遮擋多樣性, 而且也涵蓋了性別、年齡、地域和民族影響因子, 參考IMDBFace、CACD2000和Adience中的統計方法, 在本部分中我們主要對后4項影響因子做了相關的統計. 為獲取人物屬性信息,本文在參考互聯網人物知識圖譜構建的方法[20]的基礎上, 以人物中文名稱為關鍵字自動從互聯網搜索該人物的相關信息.
4.1 性別
人臉是一種非常重要的生物特征, 具有結構復雜、細節變化多等特點, 同時也蘊含了大量的信息, 比如性別、種族、年齡等, 而男性和女性的人臉特征相差較大, 故而在該部分中我們首先考慮性別因素. 在本數據集中共計431個人物實體, 其中男性185人, 女性246人; 男性人臉圖像193 090張, 女性人臉圖像313 784張, 其分布如圖2所示. 在目前的實際應用中識別男性人臉上的表現要優于女性人臉[21], 從圖2中可以看出男性和女性人數、人臉圖像數的比例約為4:6, 我們用增加女性人臉的數量來提升女性識別的性能.
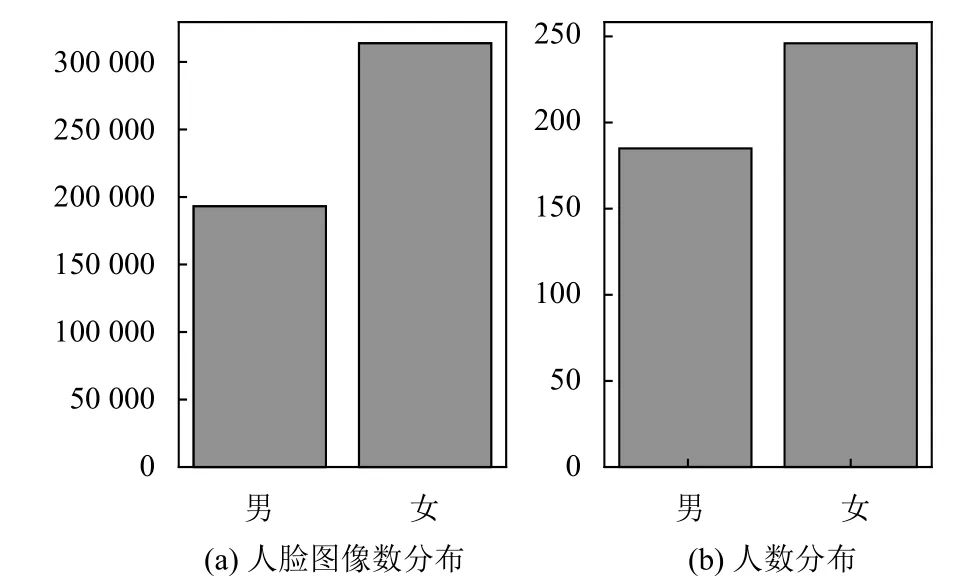
圖2 性別分布
4.2 年齡
隨著年齡的增長, 人臉的特征也將會有較大改變,尤其是青少年, 因而年齡跨度在人臉識別中一直以來是一個技術難點, 近些年來的一些文獻表示年齡因素對人臉識別的精度有較大的影響[22,23]. 在本數據集中我們收集了多個年齡段的人物, 并且每個人物的人臉圖像中包含了其各個年齡的照片, 故而在年齡方面CCFace具有豐富的多樣性, 人物的年齡跨度統計如表1所示.從表1可以看出20~60歲年齡段的人臉數占比超過90%, 這也與當前實際應用中使用人臉識別應用該年齡段人數比例的實際情況基本相符.

表1 年齡段分布
4.3 地域
我國是一個地域遼闊人口眾多的國家, 目前可以分為7個行政區, 早些年便存在對各行政區人臉特征的研究[24], 其研究表明中國人的人臉特征由于受到地理環境、氣候等因素的影響, 其所屬行政區的人的臉部特征存在明顯差別, 因而按行政區來說明該數據集的多樣性也是合理的. 在本數據集中收集各個行政區的人物數量與人臉數量, 具體匯總如表2.

表2 地域分布
4.4 民族
我們國家是一個擁有56個民族的大家庭, 而不同民族的人臉特征也存在一定的差異性, 如: 膚色、臉型等. 在當前人臉識別應用中, 不同民族的識別精度也存在差異, 如在膚色較白的人臉上表現優于膚色較深的人臉(11.8%~19.2%的錯誤差別)[21], 當前的人臉識別算法都是數據驅動的, 數據的好壞和多少直接影響其識別性能, 故而本數據集中收集不同民族的人臉, 其數量統計如表3所示. 第六次全國人口普查報告顯示: 漢族占比91.6%、壯族占1.28%、藏族0.78%; 從表3中可以看出本數據集各民族比例與之大致相符.

表3 地域分布
5 實驗分析
為說明使用該方法構建CCFace數據的質量, 在本文中使用和本數據集尺度相當的CASIA-WebFace(以后簡化記為WebFace)數據集分別訓練多個人臉識別模型. LFW與CAS-PEAL分別作為國外、國內人臉驗證集來測試模型的精度. 對于數據預處理我們遵循SphereFace[25]與CosFace[26]的處理方式, 生成歸一化的112×112的人臉裁剪圖像. 由于計算資源的限制, 在本文中選擇CosineLoss[26]與Softmax作為損失函數,ResNet50, ResNet-100[27]和MobileNetV1[28]作為主干網絡, 分別記為CosFaceMobileV1 (CosineLoss+MobileNetV1)、Soft-maxMobileV1 (SoftMax+MobileNetV1)、CosFaceRes50 (CosineLoss+ResNet50)和CosFaceRes100 (Co-sineLoss+ResNet100). 在本文中所有的實驗在Mxnet[29]上實現, 設置batch_size為96,動量為0.9, 權值衰減為0.0005, 初始的學習率為0.1,所有訓練都在260 k次迭代后終止, 使用3×NVIDIA GeForce RTX 2028Ti (11 GB)的GPU完成訓練.
5.1 WebFace實驗結果
作為對比, 首先使用WebFace數據集訓練以上列出的4個人臉識別模型, 模型最終性能如表4所示. 從表4中可以看到文中使用的4個人臉識別模型在使用WebFace作為訓練集時, 識別國外人臉的精度要高于國內人臉的識別精度. CosFaceMobileV1, Softmax-MobileV1, CosFaceRes50, CosFaceRes100模型在LFW上的精度比在CAS-PEAL上的精度分別高3.3%,4.9%, 0.9%, 0.8%.
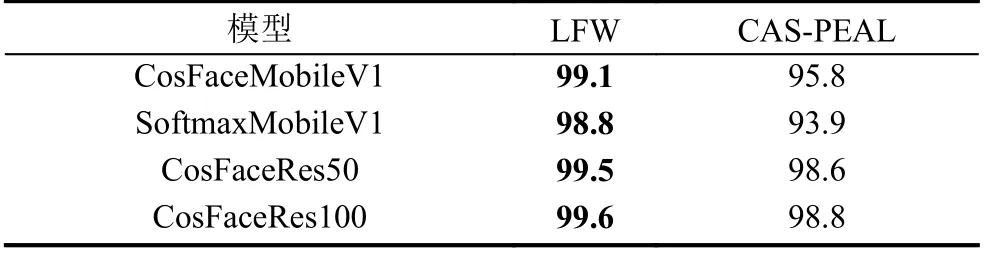
表4 WebFace結果 (%)
5.2 CCFace實驗結果
之后以CCFace數據集訓練相同的人臉識別模型,模型最終性能如表5所示. 從表5可以看出本文選擇的4個人臉識別模型在使用CCFace數據集作為訓練集時, 對國人人臉的識別精度要高于對國外人臉的識別精度. CosFaceMobileV1, SoftmaxMobileV1, Cos-FaceRes50, CosFaceRes100模型在CAS-PEAL上的精度比在LFW上的精度分別高0.2%, 0.9%, 1.1%, 1.5%.
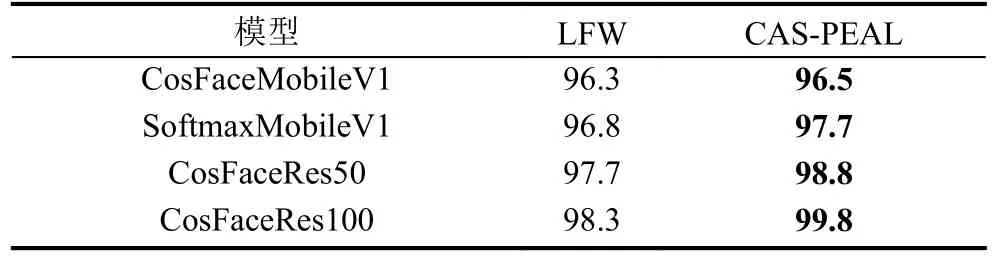
表5 CCFace結果 (%)
5.3 實驗結果分析
綜合表4、表5可以得到, 以CCFace為訓練集訓練的模型在LFW上同樣達到了較高的精度, 這說明該數據集和當前流行的人臉識別數據集一樣, 也可作為通用人臉識別應用的訓練集. 另外分別對比表4、表5的第3列可以發現CosFaceMobileV1, Softmax-MobileV1, CosFaceRes50, CosFaceRes100模型以CCFace為訓練集時, 在CAS-PEAL集上的驗證精度比以WebFace為訓練集的驗證精度分別高0.7%, 3.8%,0.2%, 1.0%, 說明CCFace比WebFace更適合作為國內人臉識別應用的數據集.
6 結論
本文提出一種半自動構建方法, 該方法減少了構建人臉識別數據集的工作量, 通過該方法可以快速構建一個高質量人臉識別數據集, 并以此方法構建一個人臉數據集, 命名為CCFace. 該數據集全部都是中國人的人臉圖像, 其不僅包含了姿態、光照、遮擋的多樣性, 也包含了年齡、地域、民族、化妝等多范圍跨度, 每個人物的人臉圖像平均包含1000多張的人臉圖像. 實驗結果說明該數據集相比于其它包含國外人物的數據集更適合我國人臉識別應用的使用, 證明不同民族之間的人臉特征具有差異性. 下一步的工作內容將詳細研究民族因素在人臉識別中的具體影響, 并進一步增加數據集的人員數量.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
作文中學版(2022年1期)2022-04-14 08:00:34
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
學生天地(2020年31期)2020-06-01 02:32:06
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
計算機工程(2015年8期)2015-07-03 12:19:07
