自然場景下烏金體藏文的檢測與識別①
2022-01-05 10:21:00高定國三排才讓
計算機系統應用 2021年12期
洪 松, 高定國, 三排才讓, 取 次
(西藏大學 信息科學與技術學院, 拉薩 850000)
1 引言
目前深度學習廣泛應用于計算機視覺的各個領域,基于深度學習的自然場景文字檢測與識別一直都是一項具有挑戰性的研究. 但是目前針對自然場景文字檢測與識別的相關研究主要集中在中英文中, 且取得了不錯的成績. 在自然場景文字檢測的研究中, 對于水平文本的檢測, Tian等人提出的CTPN[1]網絡, 該網絡結合了CNN與LSTM深度網絡, 該網絡可以學習字符的上下文關系從而提高文本檢測的準確率. 對于傾斜文本的檢測, Shi等人提出了SegLink網絡[2], 該網絡首先將文本分解成片段和鏈接這兩個局部可檢測的元素,然后通過端到端訓練的全卷積神經網絡, 可以在多個尺度上密集地檢測這兩個元素, 最終通過鄰近連接方法將各小文字塊連接成單詞. Yang等人提出了IncepText網絡[3], 該網絡提出了一種基于變形的 PSROI池化模塊來處理多方向的文本檢測, 能更好的提高大尺度以及扭曲變形文字圖像的文本檢測正確率, 使模型具有更好的魯棒性. 隨后也有一些研究人員提出了DMPNet網絡[4]、EAST網絡[5]、PixelLink網絡[6], 支持傾斜文本的檢測. Liao等人提出了一個可微二值化模塊[7], 它可以在分割網絡中執行二值化過程, 通過與DB模塊的優化, 分割網絡可以自適應地設置二值化閾值, 既簡化了后處理, 又提高了文本檢測的性能. 在自然場景文字識別的研究中, 對于規則文本的識別, 應用最廣泛的主要是Shi等人提出的一種基于序列的文字識別網絡CRNN[8], 該網絡能夠處理任意長度的序列, 且不涉及字符分割和水平尺度歸一化, 能進行端到端的訓練. 對于非規則文本的識別, 主要是Shi等人提出的RARE網絡[9], 該網絡由空間變換網絡STN和序列識別網絡SRN組成, 網絡模型能夠識別多種類型的不規則文本,包括透視文本和彎曲文本.
目前自然場景下的中英文檢測與識別相關的研究已經取得了不錯的成果, 但是自然場景下烏金體藏文的檢測與識別的相關研究仍處于起步階段. 為了給藏文識別的相關研究奠定基礎, 早期一些研究人員主要研究了印刷體和手寫體藏文的識別. 在印刷體和手寫體藏文識別的研究中, 一些研究人員針對藏文字符的特點在藏文字符輪廓特征提取[10,11]、印刷體藏文字符特征提取[12,13]、手寫體藏文字符特征提取[14]等方面取得了不錯的成果, 隨后相關研究人員在此基礎上進一步研究了印刷體和手寫體藏文的識別[15-17]. 但是在印刷體和手寫體藏文識別的研究中主要是采用傳統的圖像處理方法對藏文文本圖像進行二值化、去噪等預處理操作, 再對圖像中的藏文字符行進行切分, 然后將切分后的藏文字符圖片進行歸一化后送入特征提取模塊提取單個藏文字符的特征, 最后通過傳統的模式分類方法得到識別結果. 從中可以看出傳統的藏文識別方法存在多個中間環節, 同時要求藏文圖像質量較好且能切分出藏文字符. 而自然場景下的烏金體藏文圖像質量較差且文字存在透視變換、噪聲干擾大, 傳統的藏文識別方法顯然不適合自然場景下烏金體藏文的識別.
目前, 得益于深度學習技術的發展, 利用深度學習技術對自然場景下藏文的檢測與識別進行研究是當下的發展趨勢. 趙棟材[18]在傳統的文字識別方法基礎上,增加了基于BP網絡的訓練方法, 通過對大量的木刻藏文經書字符的訓練, 實現了普通干擾情況下木刻經文的識別. 梁弼等人[19]提出了一種基于HMM分類器的聯機手寫藏文識別的方法, 并設計了3種不同的HMM分類器對藏文字丁進行識別. 王維蘭等人[20]提出了一種新的多層聯系子層遞歸神經網絡模型并融合藏文字丁的空間結構特征來進行聯機手寫藏文識別, 實驗結果說明該方法可以更好地表征藏文字的各筆劃特征以及筆劃間的空間結構關系. 雖然這些學者在早期利用深度學習技術對木刻藏文經書、藏文字丁、手寫體藏文進行了研究, 但是公開發表的自然場景下藏文的識別文章只有仁青東主[21]等人研究的基于深度學習的自然場景下藏文的識別, 在該研究中雖然采用了基于深度學習的序列識別方法CRNN[8]與二維串識別技術的結合, 但是在該研究中對自然場景藏文文本行進行識別時仍然要對藏文文本行圖像進行塊切分, 并沒有完全體現出CRNN算法的優勢, 同時在該研究中對自然場景下藏文的檢測只是一筆帶過, 沒有做藏文檢測實驗.
因此本文在沒有開源的自然場景烏金體藏文圖像的情況下, 人工收集和標注了自然場景烏金體藏文圖像數據集, 并在此基礎上探究適合自然場景烏金體藏文檢測與識別方法. 本文在自然場景烏金體藏文檢測階段對比了不同的場景文字檢測算法, 最后采用可微分的二值化網絡DBNet[7], 在烏金體藏文識別階段采用基于序列的端到端文字識別算法CRNN[8], 在該階段采用算法合成的全藏字作為字典庫, 并采用修改后的MobileNetV3 Large[22]作為特征提取網絡. 最后在該方法上做了基礎性實驗, 實驗表明在自然場景下烏金體藏文的識別中CRNN算法可以進行端到端的識別, 并不需要對藏文文本行進行塊切分, 簡化了識別流程.
2 算法思想
本文中自然場景下烏金體藏文的識別系統主要分為兩個階段, 一是烏金體藏文文本檢測, 在該階段中采用可微分的二值化網絡DBNet[7]; 二是烏金體藏文文本識別, 在該階段中采用基于序列的文字識別算法CRNN[8].
2.1 烏金體藏文文本檢測理論
如圖1所示, 在烏金體藏文檢測階段將圖片輸入網絡后, 經過特征提取網絡ResNet-18提取特征和上采樣融合并通過con-cat操作后得到圖1中藍色的特征圖F, 然后使用F預測出概率圖P和閾值圖T, 最后通過可微分的二值化算法計算出近似二值圖, 從而得出烏金體藏文檢測結果. 在烏金體藏文檢測階段, 采用了Liao等人[7]在中英文檢測實驗中在傳統的ResNet-18網絡[23]的conv_3_x, conv_4_x, conv_5_x后加入可變形卷積增大感受野的范圍, 以此來適應縱橫比較大的烏金體藏文檢測.
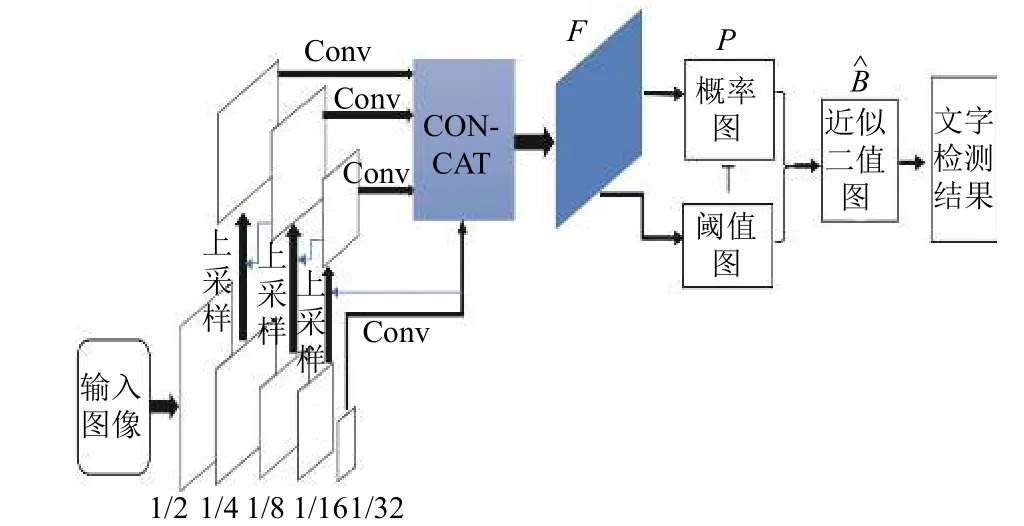
圖1 DBNet網絡結構圖
烏金體藏文檢測階段中可微分的二值化過程如式(1)所示, 其中B? 表示近似的二值圖, (i,j)表示概率圖中的坐標,P、T是網絡學習的概率圖、閾值圖,k是一個梯度縮放因子. 式(1)之所以會改善網絡性能, 可以從梯度的反向傳播來解釋, 定義一個f(x)如式(2)所示,其中x=Pi,j-Ti,j. 在使用交叉熵損失的情況下, 正樣本的損失記為l+如 式(3), 負樣本的損失記為l-如式(4).正、負樣本的損失對于輸入x的偏導數分別為式(5)、式(6)所示. 從微分式子可以看出k是梯度增益因子, 梯度對于錯誤預測的增益幅度很大.
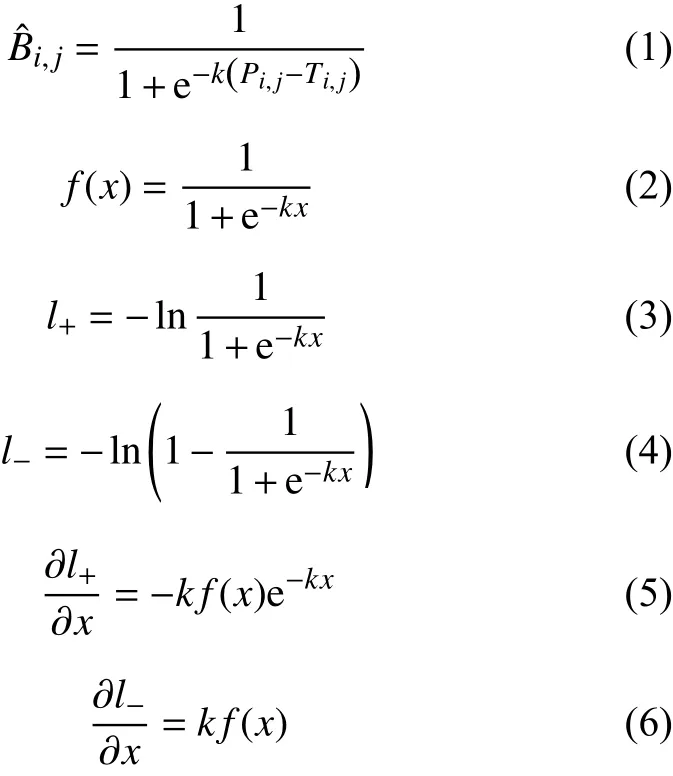
網絡訓練的損失函數如式(7)所示,Ls為概率圖的損失、Lb為二值圖的損失、Lt為閾值圖的損失. 其中α 和β 的取值分別為1.0和10. 其中Ls和Lb采用二值交叉熵損失如式(8)所示, 其中Sl是經過采樣的數據集.Lt采 用的是L1損 失如式(9)所示, 其中Rd為標注框經過擴充后得到的框里的一組像素的索引.
2.2 烏金體藏文文本識別理論
在烏金體藏文識別階段中首先根據檢測結果裁剪出烏金體藏文文本塊, 如圖2所示將裁剪出的烏金體藏文文本塊送入MobileNetV3 Large網絡提取文字特征, 然后使用LSTM對特征序列中的每幀進行預測, 最后采用CTC進行轉錄并輸出最后的識別結果.
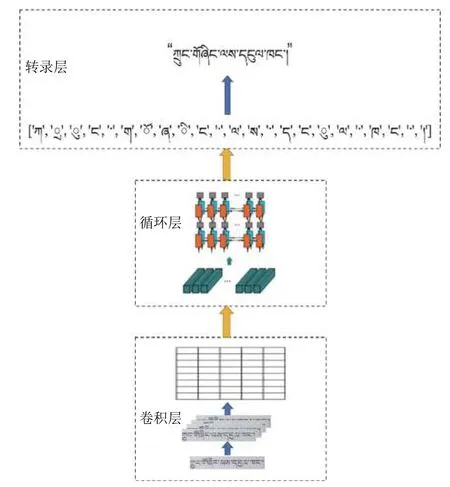
圖2 CRNN結構圖
因為藏文不僅可以橫向疊加, 還可以縱向疊加, 所以在烏金體藏文識別階段借鑒Du等人[24]在中英文識別實驗中MobileNetV3 Large網絡的配置, 該配置修改了原始MobileNetV3 Large中除第一個下采樣特征圖的步幅, 將步幅為(2, 2)修改為(2, 1), 將第二個下采樣特征圖的步幅從(2, 1)修改為(1, 1), 以此來保留更多的水平和垂直方向上的信息. 該網絡配置如表1所示,除了修改下采樣特征圖的步幅, 該網絡配置也調整了最大池化層的窗口大小和步幅, 將原來7×7的窗口改為2×2, 步幅由1改為2. 表1中exp size表示膨脹參數;SE表示Squeeze-and-Excite結構; NL表示非線性,HS表示h-swish激活函數, RE表示ReLU激活函數;s表示步幅; Bneck模塊中包括1×1卷積、3×3卷積或者5×5卷積、SE結構.
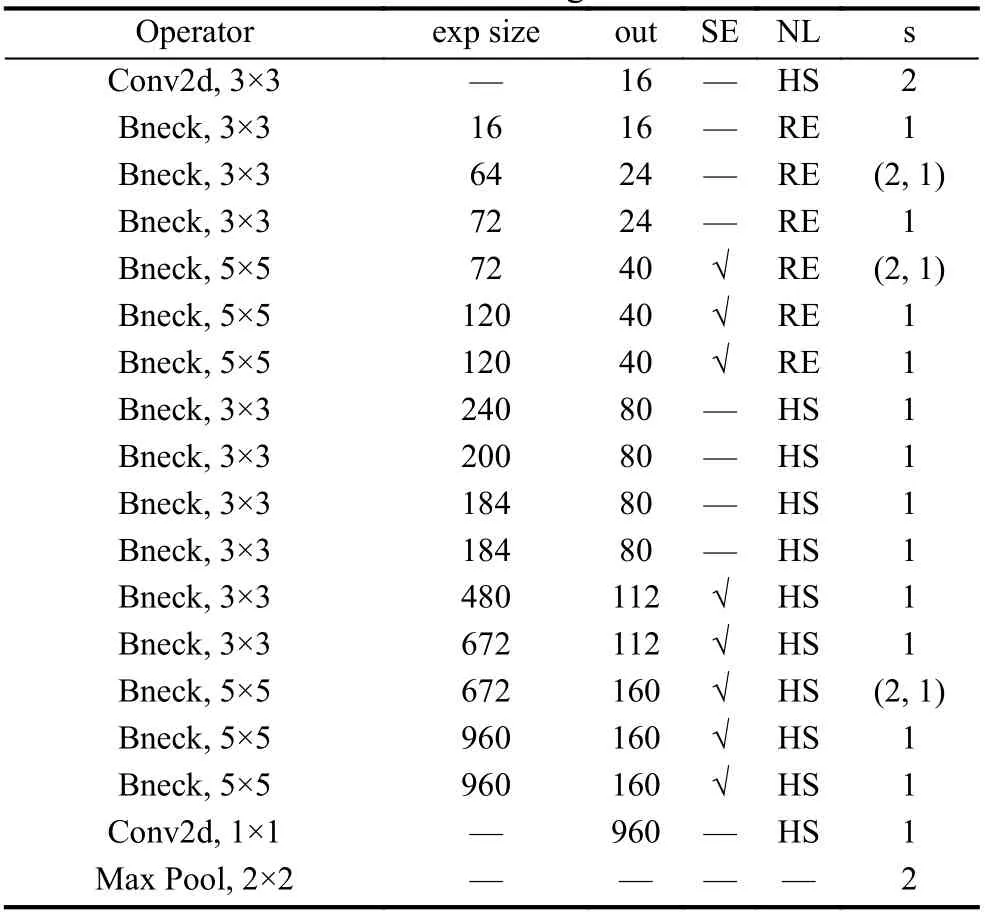
表1 MobileNetV3 Large網絡配置表
用式(10)來表述訓練數據集, 其中Ii表示訓練圖片,li表示圖像中藏文音節序列的ground truth. 目標函數的構建是通過最小化ground truth的條件概率的負對數似然函數, 如式(11)式所示. 其中yi是循環層和卷積層從Ii生成的序列, 該目標函數直接計算輸入圖像和它對應的ground truth之間的損失函數, 因此該網絡可以進行輸入圖像與真實的標簽序列的端到端的訓練.
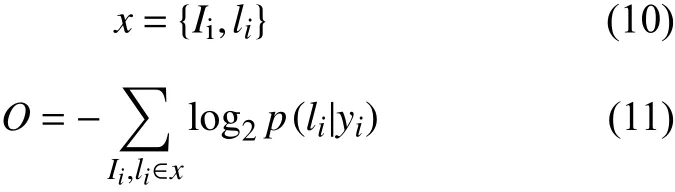
3 實驗與分析
由于缺乏開源的自然場景烏金體藏文文本圖像數據集, 本實驗中網絡訓練所用的數據集全是在拉薩街頭人工拍攝的烏金體藏文文本圖像. 這些烏金體藏文文本圖像主要包括了交通標志牌、店鋪廣告牌、公交站牌等自然場景烏金體藏文文本圖像. 最終收集了449張烏金體藏文文本圖像, 4321張自然場景烏金體藏文文本塊圖像.
3.1 烏金體藏文檢測
在自然場景烏金體藏文檢測實驗中, 將前期收集的449張自然場景烏金體藏文圖像尺寸統一為608×608, 然后將這449張圖片進行數據增強最終擴充為1796張, 并將這1796張圖像隨機分為訓練集1600張和測試集196張, 使用Labelme軟件對實驗數據集進行了標注. 在此基礎上對比了CTPN[1]、EAST[5]場景文字檢測算法與本文所采用的可微分的二值化網絡DBNet在烏金體藏文檢測上的效果, 其中成功檢測到烏金體藏文的部分檢測效果如圖3所示, 圖3(a)為CTPN檢測效果, 圖3(b) 為EAST檢測效果, 圖3(c)為DBNet檢測效果. 在測試集上的性能測試結果如表2所示.

圖3 成功檢測到烏金體藏文的部分圖片展示
因為在本文收集的自然場景烏金體藏文檢測實驗數據集圖像中很多烏金體藏文文本行都是傾斜文本,完全水平的烏金體藏文文本較少. 從圖3中可以看出,本文所采用的可微 分二值化網絡DBNet在真實自然場景下烏金體藏文的檢測效果最好, 且能檢測出傾斜文本. CTPN網絡只對水平文本檢測效果較好, 不適合傾斜文本的檢測. 而EAST算法能檢測傾斜文本, 但是在實際的測試中出現很多誤檢. 所以在表2的性能測試中, CTPN網絡的性能較差, 而相比于EAST網絡本文所采用的檢測網絡的準確率最高.
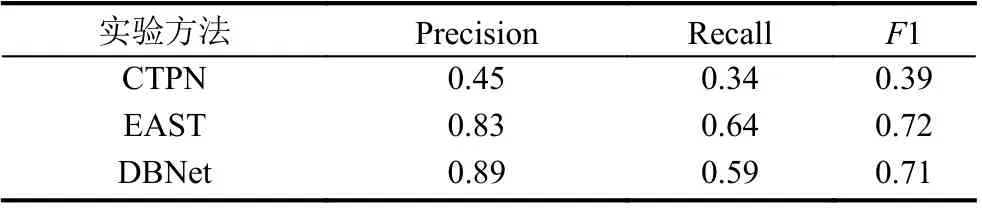
表2 幾種檢測算法在烏金體藏文文本檢測實驗上的性能對比
3.2 烏金體藏文識別
在自然場景烏金體藏文識別實驗中, 將前期收集的4321張自然場景下烏金體藏文文本圖像塊尺寸統一為32×100, 采用算法合成的全藏字作為轉錄的字典,其中包含18 785個藏文音節. 在此基礎上依次進行了3組實驗, 但是該實驗無法與現有相關工作做對比, 主要有以下兩個方面的原因, 一方面因為與自然場景下烏金體藏文識別相關的論文較少, 無法與其他研究成果進行比較; 另一方面因為目前沒有開源的自然場景藏文數據集, 都是基于自制的數據集進行實驗, 沒有可比性. 這3組實驗驗證了本文采用的方法在自然場景烏金體藏文識別上的可行性. 網絡訓練結束后在測試集上的性能測試如表3所示.

表3 不同特征提取網絡在烏金體藏文文本識別實驗上的性能對比
采用3.1節中DBNet網絡訓練出的烏金體藏文檢測模型和實驗3訓練出的烏金體藏文識別模型在314張自然場景烏金體藏文圖像上的部分正確檢測到烏金體藏文文本并完全識別正確的結果可視化為如圖4所示, 圖4(a)的識別結果為; 圖4(b)的識別結果為; 圖4(c)的識別結果為和. 但是其中也存在一些錯誤識別的結果, 部分特殊示例如圖5和圖6所示. 圖5(a)的識別結果為第3個音節的基字識別錯誤, 正確的應為“?”; 第5個音節中“”不符合藏字構字規則; 圖5(b)的識別結果為第2個音節錯誤, 應為“”, 其中“”是特殊藏字, 第5個音節錯誤, “”不符合藏字構字規則; 圖5(c)的識別結果為“”, 第3個音節后加字下多了一個構件, 第4個音節不符合藏字構字規則.圖6(a)的識別結果為第1音節少了下加字, 第2音節少了下加字“”; 圖6(b)的識別結果為, 第二個音節錯誤, 缺下加字, 應為“??”; 圖6(c)的識別結果為, 后者中第4個音節缺下加字.

圖4 正確的檢測結果和識別結果示例

圖5 識別結果錯誤示例1

圖6 識別結果錯誤示例2
從表3中可以看出, 隨著數據集規模的增大, 最終在測試集上的識別準確率有了很大的提升. 在實驗2和實驗3中采用了不同特征提取網絡進行實驗, 實驗結果表明實驗3采用的特征提取網絡在烏金體藏文識別上的效果更好. 通過分析在314張自然場景下烏金體藏文圖像上的實際識別效果, 從中可以發現本文訓練出的模型對結構簡單的藏文字符能夠識別正確, 如圖4所示, 證明了該方法在自然場景烏金體藏文識別上的可行性. 但是由于實驗數據集規模太小, 實際的測試結果中也存在一些識別錯誤的情況, 部分示例如圖5和圖6所示. 從中發現了一些特殊的現象如下: (1)識別錯誤的結果中有些音節如“”、“”、“”等不符合藏字構字規則, 如圖5所示; (2)下加字漏識別現象比較常見, 其中音譯詞“”也會識別錯誤, 如圖6所示; (3)出現特殊藏字“”時會識別錯誤; (4)一些結構極其相似的藏文字符如“”、“”、“”以及“”、“”等在識別時容易出錯. 其中現象(2)和現象(3)是因為特殊藏字 “”和音譯詞“”不符合全藏字中藏字的構字規則, 但也屬于藏字. 現象(1)和現象(4)是因為訓練集規模太小, 網絡沒有學習到復雜結構藏字和結構相似藏文字符的特征.
4 總結與展望
本文采用基于殘差網絡ResNet-18的可微分的二值化網絡DBNet用于自然場景烏金體藏文的檢測, 采用基于序列的識別算法CRNN用于自然場景烏金體藏文的識別, 在人工收集的烏金體藏文圖像數據集的基礎上進行了初步的實驗, 實驗表明了該方法在烏金體藏文檢測與識別上具有可行性. 通過分析實驗結果在現有方法的基礎上可以改善的方面主要有以下幾點:(1)根據藏文構字特點, 在CRNN的轉錄層中如何將藏文構字規則引入其中, 以避免識別結果中出現不符合藏字構字規則的情況; (2)完善詞典, 加入特殊藏字以及音譯詞; (3)如何合成多樣化的自然場景烏金體藏文文本塊以擴充訓練集提高網絡的識別準確率.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
制造技術與機床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
電子制作(2018年18期)2018-11-14 01:48:06
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
海峽科技與產業(2016年3期)2016-05-17 04:32:12
