基于遺傳算法的虹膜卷縮輪提取方法①
2022-01-05 10:21:10朱立軍鄧天嬌
計算機系統(tǒng)應用 2021年12期
朱立軍, 鄧天嬌
1(沈陽化工大學 計算機科學與技術學院, 沈陽 110142)
2(遼寧省化工過程工業(yè)智能化技術重點實驗室, 沈陽 110142)
卷縮輪[1]是位于虹膜腸環(huán)周邊的一個環(huán)狀曲線,將虹膜區(qū)域分割為瞳孔區(qū)和睫狀體區(qū)兩部分. 根據(jù)卷縮輪的膨脹或收縮, 可以判斷人體的腸道功能是否出現(xiàn)異常[2,3]. 因此, 準確地檢測出ANW的邊緣是進一步進行病理分析測的及檢前提. 另外, 在基于虹膜的計算機輔助診斷[4]系統(tǒng)中, 由于ANW的位置是實現(xiàn)虹膜圖譜覆蓋的主要依據(jù), 所以卷縮輪邊緣的準確檢測也是判斷計算機輔助診斷系統(tǒng)性能優(yōu)劣的前提.
目前虹膜卷縮輪的提取方法主要包括: 石勇濤等[5]利用圖像紋理元的灰度模式及統(tǒng)計特征完成虹膜圖像的卷縮輪分割, 黃靜等[6]利用紋理基元統(tǒng)計出紋理變化規(guī)律, 通過定義邊界模式與非邊界模式, 統(tǒng)計每種模式出現(xiàn)的頻數(shù), 最后通過頻數(shù)的變化規(guī)律找到包含卷縮輪的窗口提取卷縮輪. 苑瑋琦等[7]提出梯度極值法和辛國棟等[8]提出的最大灰度梯度法, 兩種方法都是通過在圖像中搜索最大灰度梯度來確定卷縮輪邊界,利用水平和垂直方向梯度之和來提取卷縮輪. 馬琳等[9]和辛國棟等[10]通過利用Snake方法提取虹膜卷縮輪,通過蛇點之間區(qū)域的平滑程度來確定內部函數(shù), 根據(jù)區(qū)域邊緣點的密度來確定外部能量函數(shù)來得到卷縮輪.但是上述提取方法在對卷縮輪圖像進行提取的過程中易受光斑、眼瞼、坑洞等因素的影響, 且提取虹膜卷縮輪需要手動定位初始位置, 對于卷縮輪在虹膜中位置分布過大或過小的圖像和卷縮輪內部紋理不清晰的圖片不能很好的進行定位, 導致卷縮輪的提取效果有時并不理想.
為了解決上述方法中卷縮輪檢測結果抗干擾性差、內部紋理不清晰、檢測精度不理想等問題, 本文提出一種基于遺傳算法的虹膜卷縮輪提取方法, 通過特有的適應度選取和比較交叉選擇機制提高優(yōu)秀父本的選取, 進而提取出較理想的卷縮輪輪廓. 該算法無需利用窗口中心作為卷縮輪的輪廓點, 不容易受到附近坑洞或色素斑紋理的干擾, 對卷縮輪內部紋理不清晰的圖像可以準確進行定位, 無需手動定位初始點, 所得到的卷縮輪邊緣效果較好, 所提取出的卷縮輪結果較接近于實際的卷縮輪.
1 基于遺傳算法的虹膜卷縮輪提取
1.1 虹膜預處理
由于人眼獨特的結構特點, 虹膜提取易受到光照,采集角度, 環(huán)境等因素的影響, 為了糾正由此造成的彈性變形問題, 消除平移和旋轉等對虹膜特征提取造成的影響, 需要對采集到的圖像進行預處理操作, 包括虹膜定位和歸一化. 具體提取過程如圖1所示.
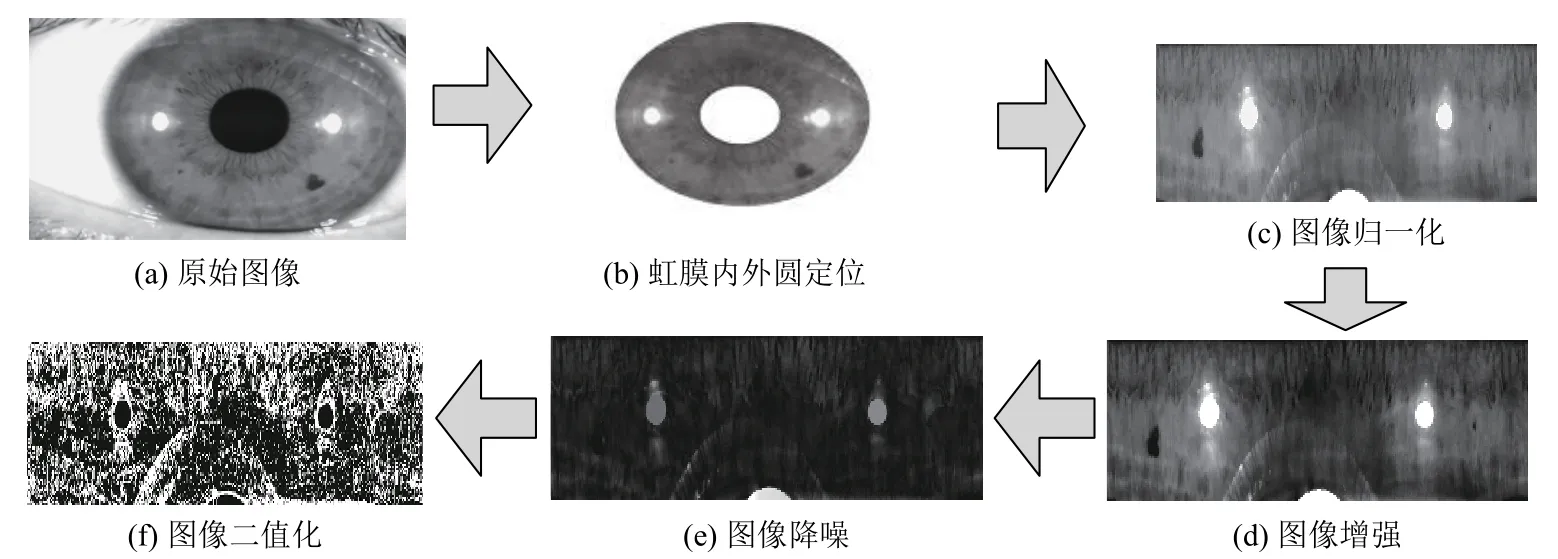
圖1 圖像預處理過程
本文首先采用文獻[11]中的方法對虹膜進行內外邊界的定位. 再利用文獻[12]中的虹膜歸一化方法將環(huán)狀虹膜進行歸一化處理, 歸一化的目的是為了使處理的問題簡單化, 將環(huán)狀的虹膜歸一化成W×H的矩形, 其中角度方向的采樣數(shù)W=540, 半徑方向的采樣數(shù)H=150. 歸一化后矩形圖像的左上角坐標為(0, 0),右下角坐標(539, 149).
將得到的矩形圖片進行圖像的灰度變換, 把原圖像的灰度值變換到新圖像中. 原圖像中灰度值低于最低亮度值的像素點, 該點在新圖像中灰度值被賦值為最低亮度值, 同理, 原圖像中灰度值高于最高亮度值的像素點, 該點變換到新圖像時其灰度值也被賦值為最高亮度值, 將灰度圖像中的亮度值映射到新圖像中, 使得圖像中的部分數(shù)據(jù)飽和至最低和最高亮度, 增加輸出圖像的對比度值. 對圖像進行開運算去除孤立的小點、毛刺, 并對圖像進行減法運算來降低噪聲的影響,求得特征處理后圖像e.
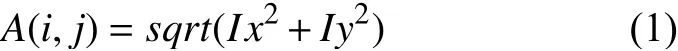
接下來對圖像e采用式(1)求得梯度圖像A(i,j),式(1)中特征處理后圖像e的水平和豎直方向的梯度分別為Ix,Iy.平方根函數(shù)為sqrt.
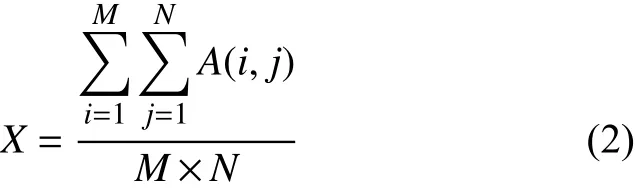
梯度圖像A(i, j)的均值X, 計算如式(2)所示, 式中M為圖像的列數(shù),N為圖像的行數(shù).
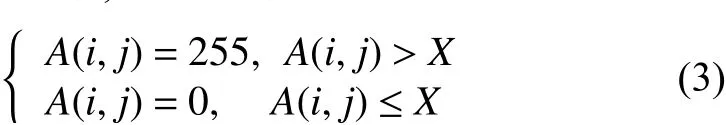
依據(jù)式(3)對梯度圖像A(i,j)進行二值化處理. 二值化的目的是為了使圖片結果更清晰, 可以直接通過點密度的方式進行遺傳算法的適應度選取.
1.2 基于遺傳算法的虹膜卷縮輪提取
遺傳算法(Genetic Algorithm, GA)[13]是模擬達爾文的遺傳選擇和自然淘汰的生物進化過程的一種計算模型. 遺傳算法把問題的參數(shù)用基因代表, 把問題的解用染色體代表, 從而得到一個由具有不同染色體的個體組成的群體. 具體提取過程如圖2所示.
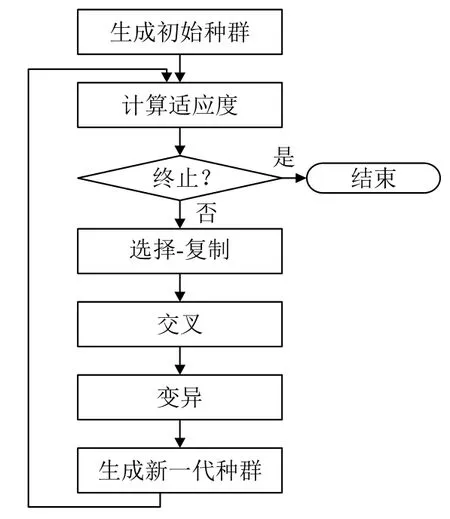
圖2 遺傳算法提取過程
本文在預處理得到的圖片基礎上, 通過使用遺傳算法來進行卷縮輪的提取. 具體步驟如下: 首先利用隨機算法來生成初始總群, 采取以區(qū)域內點密度之比作為適應度挑選出優(yōu)秀個體進行比較, 將相鄰兩個體間同一位置基因進行比較, 將點適應度高的基因作為優(yōu)質基因保持不變, 并在該點附近一定步長選取基因代替另一個體原有點適應度低的基因. 將得到的個體隨機選擇一定數(shù)量的變異點進行變異, 將新生成的個體作為新一代父本, 將上述步驟進行一定次數(shù)的循環(huán), 直至找到符合要求的個體.
1.2.1 種群的選擇和個體適應度函數(shù)的確定
種群的選擇包括初始種群的選擇和父本的選擇,初始種群的選擇利用隨機算法來生成初始總群, 父本的選擇由適應度函數(shù)[14]挑選出一定數(shù)量的優(yōu)秀個體并通過選擇算子(輪盤賭選擇[15])選擇最優(yōu)個體作為新種群. 適應度值越大, 被選擇成為優(yōu)秀個體的幾率就越大,通過個體適應度的大小可以確定該個體被選中的幾率進而使結果趨近最優(yōu)解. 常規(guī)適應度函數(shù)會直接通過采用待求函數(shù)進行選取, 本文則采取以區(qū)域內點密度之比作為適應度的方法, 結合卷縮輪的實際情況, 個體適應度函數(shù)定義如下:
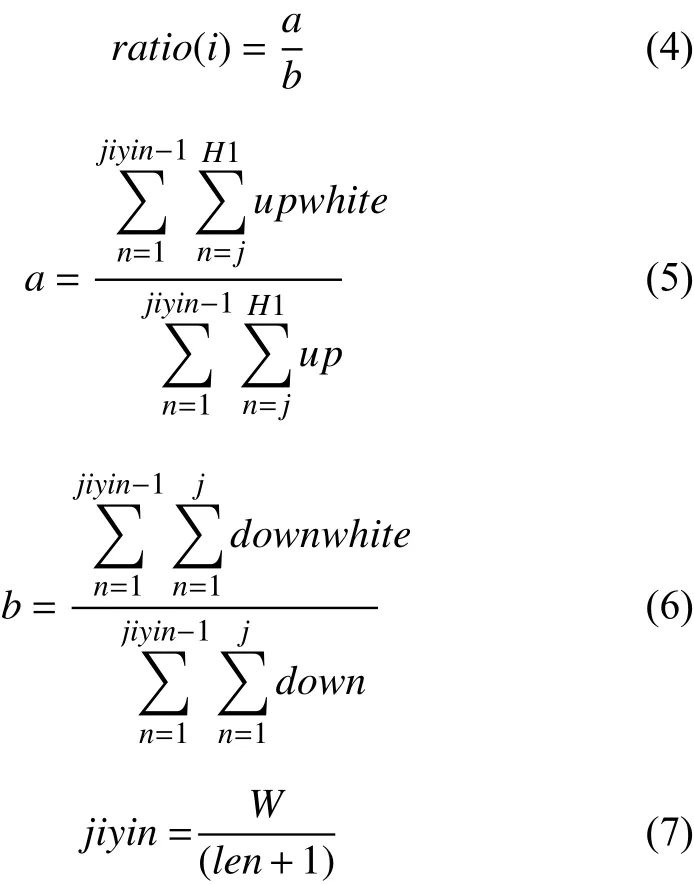
其中, 個體適應度即上下區(qū)域的點密度之比用ratio表示, 如式(4)所示. 個體適應度的值越大, 則該個體被選擇成為優(yōu)秀個體的幾率就越大. 上部分點密度為a, 如式(5)所示. 下部分點密度為b, 如式(6)所示. 其中, 每條染色體的基因個數(shù)為jiyin, 如式(7)所示, 其中, 染色體上相鄰基因點間的間隔為len, 本文len=5.H為總半徑方向的采樣數(shù), 經(jīng)過多次實驗結果對比得到當實際半徑方向的采樣數(shù)H1取總半徑H的上2/3時所得結果準確率最高. 直線y上部分符合條件點個數(shù)為upwhite,直線y上部分整體點數(shù)用up表示, 直線y下部分符合條件點個數(shù)為downwhite, 直線y下部分整體點數(shù)用down表示.
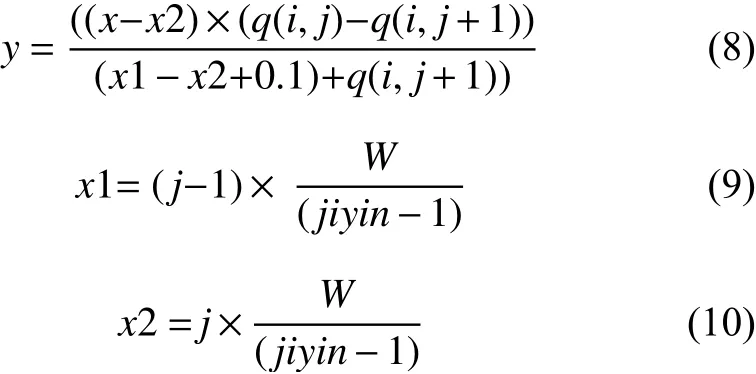
已知相鄰兩基因點橫坐標及縱坐標, 通過兩點式求得直線y, 如式(8)所示. 其中, 染色體前一個基因的橫坐標是x1, 如式(9)所示. 染色體后一個基因的橫坐標是x2, 如式(10)所示. 基因的個數(shù)為j. 自變量和因變量分別為x和y, 第i條染色體上第j個基因的縱坐標為q(i,j), 第i條染色體上第j+1個基因的縱坐標為q(i,j+1). 通過直線y可得到相鄰兩基因點間橫坐標和縱坐標的值.
1.2.2 選擇算子的選取
選擇操作是指利用選擇算子從種群中選擇優(yōu)秀個體, 在交叉變異后遺傳給下一代的一種選擇機制, 也是遺傳過程中使結果趨向最優(yōu)解的重要一環(huán). 本文通過使用輪盤賭選擇來進行父本的選擇, 對于種群X有X={x1,x2, …,xn},xi∈X的原有目標函數(shù)值為ratio(xi), 因為所得的染色體適應度相差不多, 因此用原有目標函數(shù)值減去最小目標函數(shù)值來提高選擇精度, 如式(12)所示. 新目標函數(shù)值用ratio1(xi)表示, 最小目標函數(shù)值用minratio(xi)表示. 將所得新目標函數(shù)值ratio1(xi)和總新目標函數(shù)值比較, 得到p(xi)為選擇xi染色體的概率, 如式(11)所示. 再選取一個小于1的隨機數(shù), 從隨機點出發(fā), 按順時針方向依次累加, 當累加值剛好大于或等于隨機數(shù)時輸出, 則此個體為此次賭盤的贏家,以這種方式選擇所有下一代的個體.
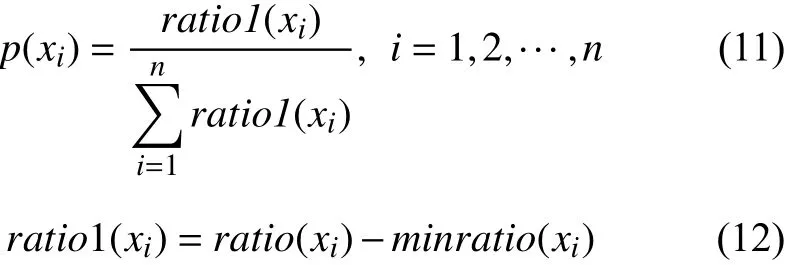
1.2.3 交叉和點適應度的選取
交叉[16]是遺傳算法中生成優(yōu)秀個體的主要手段,交叉機制的選擇直接影響遺傳算法的質量, 只有通過合理的交叉機制才能提高算法的搜索能力, 提高結果的準確性. 傳統(tǒng)的遺傳算法交叉模式是同代交叉即從父代種群中隨機選擇一部分個體進行交叉生成新種群,通過選擇機制選取一定個體代替原有個體. 本文對傳統(tǒng)遺傳算法交叉模式進行了改進, 即將相鄰兩染色體間同一位置基因的點適應度進行比較. 返回該點的適應度用density表示, 如式(13)所示. 點適應度的值越大, 則該基因被選擇成為優(yōu)秀基因的幾率就越大. 其中z為矩形內部一點縱坐標,c為上部分點密度, 如式(14)所示.d為下部分點密度, 如式(15)所示.upwhite為z上部分符合條件的點個數(shù),up為z上部分整體點個數(shù),downwhite為z下部分符合條件的點個數(shù),down為z下部分整體的點個數(shù).
如果第1條染色體上基因的點適應度高于第2條染色體上基因的點適應度, 則第1條染色體上該基因不變, 并在第1條染色體該基因附近一定距離選擇兩點進行比較, 將點適應度高的基因作為優(yōu)質基因, 代替第2條染色體上原有點適應度低的基因. 點適應度選取如下:
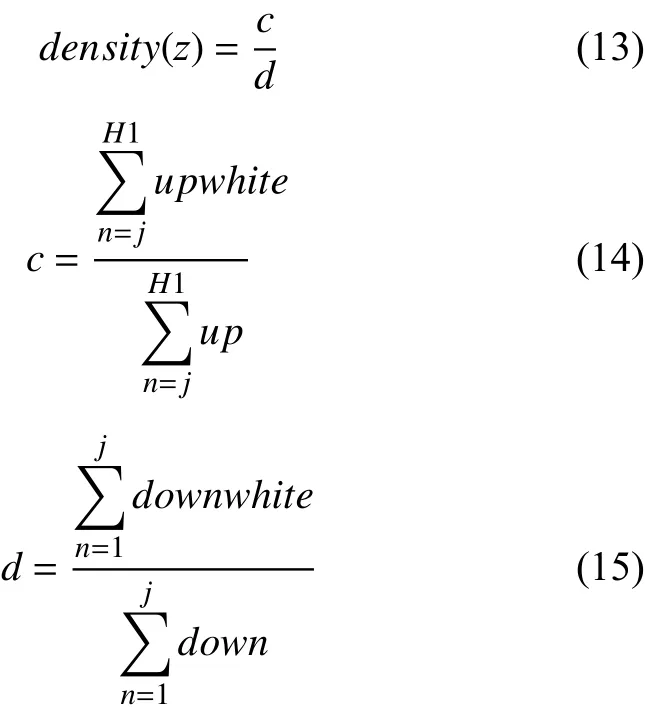
具體交叉算法如下:
步驟1. 在種群X={x1,x2, …,xn}中選擇個體xi和個體xi+1;
步驟2. 將個體xi和個體xi+1中相同位置基因j進行比較, 選取點適應度高的基因保留, 第i條染色體上第j個基因的點適應度用density(q(i,j))表示, 第i條染色體上第j個基因的縱坐標為q(i, j), 將兩基因點進行點適應度比較, 將點適應度高的基因坐標用z1表示,并將點z1賦值給子代q子(i,j), 如式(16)所示:
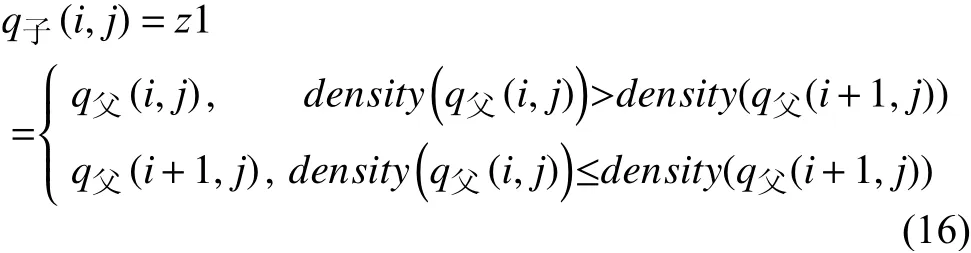
步驟3. 在子代q子(i,j)附近距離一定步長的位置選取兩點作為新的基因并進行比較(若步長超出范圍則隨機生成新基因), 將點適應度高的基因作為優(yōu)質基因坐標, 用z2表示, 步長為d, 并將點z2賦值給子代q子(i+ 1,j), 如式(17)所示:
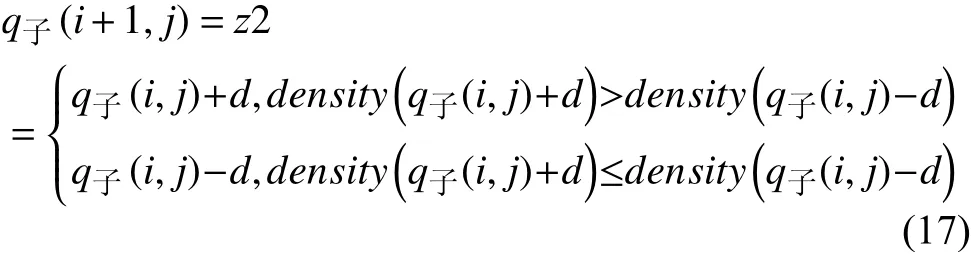
交叉流程如圖3所示.
將個體xi和個體xi+1中相同位置基因j進行比較, 當點q父(i,j)的點適應度大于點q父(i+1,j)的點適應度時, 將點q父(i,j)賦值給q子(i,j), 并在點q子(i,j)基因附近距離一定步長(d=2)選取兩點, 作為新的基因并進行比較. 其中, 當點q子(i,j)+d的點適應度大于點q子(i,j)-d的點適應度時, 如圖3(a)所示. 將個體xi+1中基因j的值q父(i+1,j)替換為點q子(i,j)+d, 如圖3(b)所示.
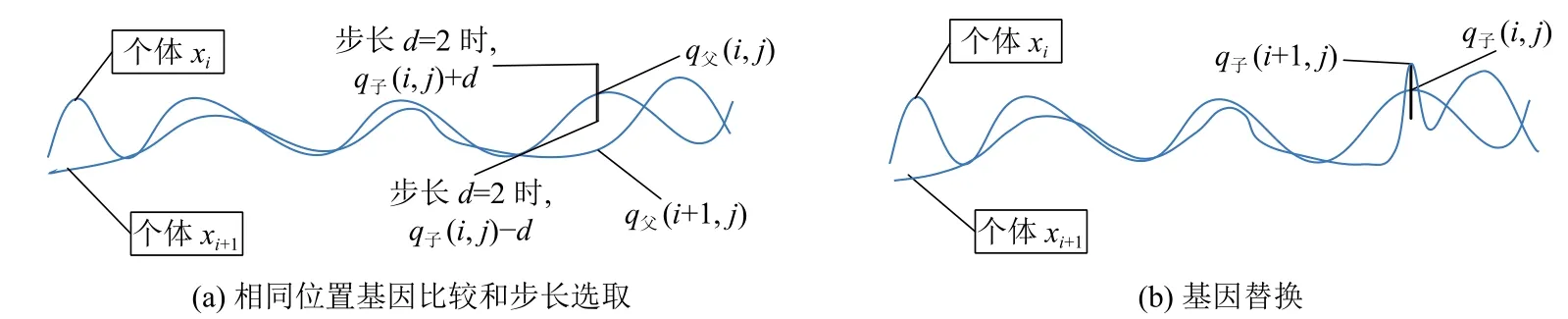
圖3 基因交叉流程圖
1.2.4 變異
變異是通過改變個體結構和特性而生成新個體的一種模擬生物進化過程中基因突變的現(xiàn)象. 當達到變異條件時, 個體將隨機選擇一定變異點進行變異形成新的個體, 是一種生成新個體的有效手段. 變異率通常設置較小值, 本文中變異率為0.01.
2 結果
實驗所用圖庫是本研究室自己采集的可見光虹膜圖庫, 共1918張, 分辨率為800×600. 實驗所用計算機處理器為Intel core i7, 內存為8 GB, 其主頻2.60 GHz,開發(fā)工具為Matlab 2018a.
由實驗可得, 步長越小, 則算法對ANW輪廓曲線的變化越不敏感;步長越大, 則算法就會忽略ANW的一些局部細節(jié). 經(jīng)過反復實驗, 最終確定步長取3個像素時, 提取的ANW最接近于真實的ANW. 為了對本文的提取卷縮輪方法進行進一步測試, 選取了圖庫中一些具有代表性的非理想虹膜圖像提取卷縮輪, 結果如圖4所示. 由圖可知: 針對具有不同干擾和不同特點的卷縮輪的虹膜圖像, 本文的算法都可以提取出較理想的卷縮輪輪廓.
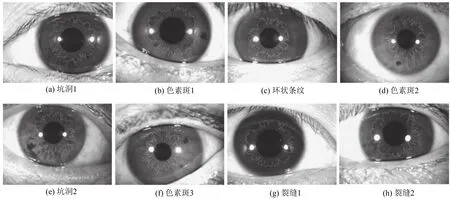
圖4 本文算法提取各種非理想虹膜ANW結果
為了驗證算法的有效性, 本文與snake模型、基元模式方法、梯度極值方法進行了實驗效果對比, 結果如圖5所示. 由圖可知: 在非理想虹膜圖像下, snake模型不能有效的體現(xiàn)卷縮輪的局部細節(jié), 提取的卷縮輪平滑且需人工進行初始位置的確定. 基元模式統(tǒng)計的方法和梯度極值都容易受到卷縮輪附近光斑或色素斑等因素的影響, 所以提取出的卷縮輪結果不理想. 本文算法依據(jù)卷縮輪內部的紋理密度信息, 通過遺傳算法可以很好地克服光斑及色素斑等干擾因素的影響, 由圖片可得所提取出的卷縮輪結果較接近于實際的卷縮輪.
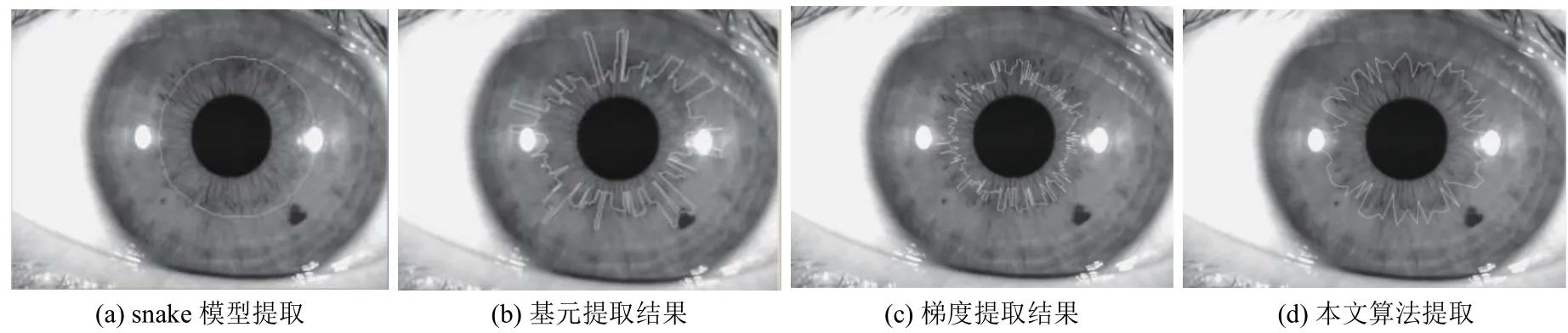
圖5 不同ANW提取方法對比
3 結論
針對非理想可見光虹膜圖像, 本文提出一種基于遺傳算法的虹膜卷縮輪提取方法, 該算法可以有效地避免光斑等因素的影響, 無需手動定位初始點. 實驗結果表明: 本文提出的方法具有較好的檢測效果, 與其他提取ANW的算法相比提取出的ANW更接近于實際的ANW.
