
基于改進Mask R-CNN的越南場景文字檢測
2022-01-05 02:31:44俸亞特文益民
計算機應用 2021年12期
俸亞特,文益民
(1.桂林電子科技大學計算機與信息安全學院,廣西桂林 541004;2.廣西圖像圖形與智能處理重點實驗室(桂林電子科技大學),廣西桂林 541004)
(?通信作者電子郵箱ymwen2004@aliyun.com)
0 引言
越南文字是越南官方使用文字,目前約有9 300 萬人使用。越南場景文字檢測就是從復雜場景中定位越南文字區域,是進行越南場景文字識別的前提。隨著中國-東盟自由貿易區的發展,有相當多的領域需要利用圖像中的越南文字信息。實現從真實場景中檢測越南文字,對推動中國與東盟國家的人文交流具有重要意義。
世界上的語言,從有無聲調的角度看,大概可分為兩大類:聲調語言與非聲調語言[1]。非聲調語言多為印歐語系的語言,如英語、法語、德語等,聲調語言多為漢藏語系的語言。聲調語言的文字書寫有兩種形式:第一種為表意文字,如漢字、老彝文字,文字使用不同的象形文字書寫表示不同的意義;第二種為表音文字,如越南文、泰文、寮文,使用不同字母與不同聲調符號的組合表示不同的意義。
由于當前的場景文字檢測算法[2-4]大多都關注于如英文、法文、中文等非聲調語言或是聲調語言文字中表意文字的檢測。聲調語言表意文字的字形中不會出現聲調符號,非聲調語言文字的字形中也幾乎不會出現聲調符號,即使出現聲調符號也僅表示語氣變換而不會影響到其語義,所以是否檢測到聲調符號并不會影響后續對文字語義的識別。這導致鮮有文字檢測的研究工作關注到聲調語言表音文字中的聲調符號。作為聲調語言表音文字中的重要組成部分,聲調符號往往被現有場景文字檢測算法忽視。與其他語言文字相比,表音文字在字形上最主要的區別在于其使用聲調符號區分文字含義。作為聲調語言中表音文字的代表,越南文字借用拉丁字母,在字母上下區域增加了6 種不同的聲調符號,相同字母的主體和不同的聲調符號組合會導致語義信息的改變,如:“M?”和“Mà”就分別表示著“代碼”和“但是”兩種意思。所以實現越南場景文字檢測的關鍵在于設計的算法是否可以檢測到文字的聲調區域。
目前,依賴于大量人工標注的訓練樣本,基于深度學習的場景文字檢測算法可以很好地實現對各種復雜場景中文字的檢測;但是,人工標注的越南場景文字數據非常稀缺,所以在標注樣本少的情況下完成深度學習模型的訓練以實現如越南文字等小語種文字的檢測是件不容易的事情。通過對越南場景文字檢測的研究,可以促進如泰文、寮文,緬文等其他聲調語言表音文字檢測的研究,同時對其他小語種場景文字檢測識別的研究也具有很好的借鑒意義。
隨著目標檢測技術的發展,已經有越來越多的場景文本檢測采用目標檢測技術,如單點多盒探測器(Single Shot multibox Detector,SSD)[5]、YOLO(You Only Look Once)[6]、Faster-RCNN[7]等。TextBoxes[8]提供了一種簡單直接的神經網絡結構,通過優化SSD 目標檢測器,減少了場景文本檢測步驟;TextBoxes++[9]通過增加SSD的輸出和優化卷積核大小,使算法可以檢測任意方向的文本區域;Liao 等[10]提出了一種基于定向響應網絡[11]的場景文本檢測算法,該算法在SSD 基礎上進行了改進,利用輸出的四點坐標偏移量預測檢測傾斜文本;Zhou 等[12]基于兩階段文本檢測方法消除了中間過程的冗余性,減少了檢測時間,檢測到的形狀可以是任意形狀的四邊形,也可以是旋轉的矩形;Shi 等[13]基于SSD 算法通過連接小規模候選框,通過后處理方法連接檢測到的文字區域。然而,上述方法并不適用于越南文字。首先,由于聲調符號的存在,導致越南語文本的形狀不規則,目標檢測算法用四邊形作為網絡輸出的方法很難準確標注越南語文本區域。這是因為:1)如果用四邊形來標注越南語文本區域的形狀,會導致如圖1(a)所示的情況,即用橢圓標注的多余區域會被包含在檢測框中,從而導致文本識別的惡化;2)使用四邊形表示的檢測框有可能忽略越南字符的重音符號或音調符號,如圖1(b)所示。

圖1 使用四邊形檢測框標注越南文本區域時存在的問題Fig.1 Problems in labelling Vietnamese texts areas with quadrangular bonding boxes
近年來,隨著圖像分割算法的發展,場景文字檢測的研究重點已從水平場景文本轉向更具挑戰性的曲面或任意形狀場景文本。Wang 等[14]對文本行不同核大小做預測,然后采用漸進式擴展算法擴展小尺度內核到最終的文本行大小,這使算法可以有效區分相鄰的文本;Liu 等[15]基于Mask R-CNN[16]分割的思想,通過平面聚類得到最終的檢測框;Long 等[17]將文本表示為圓形的組件的集合,因此可以檢測任何形狀的文本實例,包括水平文本實例、傾斜文本實例和彎曲文本實例;Lyu 等[18]在Mask R-CNN 的改進基礎上,提供了檢測各種形狀文本的框架,可以識別10個數字和26個字母;Liu等[19]使用貝塞爾曲線表示文本邊界,自適應地擬合任意形狀的文本,但是越南文字的文本邊界由于聲調符號的存在呈現鋸齒狀,簡單的二次、三次曲線不能很好地擬合文字邊界。理論上,使用實例分割的方法可以有效地檢測越南文字,但是這需依賴于大量人工標記的分割數據,而獲取這些像素級標注的樣本會面臨高額的成本問題。
Mask R-CNN是一種典型的實例分割算法[16],將檢測過程分為目標檢測和語義分割兩個部分。目標檢測可以視為一個Faster R-CNN[20],生成包括一個目標區域的候選框,語義分割部分可視為利用全卷積神經網絡(Fully Convolutional Network,FCN)[21]在候選框內的語義分割。在COCO、VOC 等常規實例分割數據集和ICDAR 2013、ICDAR 2015、MLT 等文字檢測數據集上,Mask R-CNN 都被證明有較優的效果,但它不能被直接應用于越南場景文字的檢測,主要有如下原因:
1)如果模型使用MLT 中的拉丁文字數據集訓練,模型的輸出會出現如圖2 所示的情況,越南文字的聲調符號部分往往會被忽視;

圖2 使用MLT中拉丁文字數據訓練的模型對部分越南文字的檢測結果Fig.2 Detection results of some Vietnamese texts using the model trained by Latin data in MLT dataset
2)因為越南場景文字數據缺乏,Mask R-CNN 的網絡結構又十分復雜,使用少量手工標記的越南場景文字數據集訓練網絡會導致過擬合現象的出現;
3)用于常規目標檢測的非極大值抑制算法不能過濾大量由于文本特征的相似性和連續性導致的冗余候選框。
針對Mask R-CNN對檢測越南場景文字的不足,本文提出了一個改進的Mask R-CNN算法,并設計了一個模型聯合訓練方法靈活地使用不同規模、不同標注類型的數據,最大化利用現有數據的信息。本文主要工作如下:
1)收集了用于越南場景文字檢測的數據集,包括200 幅圖像,每幅圖像都使用像素級標注;
2)改進了區域分割模塊網絡的特征表示,僅使用P2特征層來分割文本區域,且將文本區域的掩碼矩陣大小從14×14調整為14×28,以更好地適應文字區域的橫縱比,使分割模型對文字邊界的判斷更加準確;
3)考慮到場景文字特征的連續性,設計了一個文本區域過濾模塊,可以有效地消除由于回歸框算法對連續文本區域判斷錯誤而產生的大量冗余檢測框;
4)為了保持網絡規模和數據集規模的一致性,本文提出了模型聯合訓練的方法,使算法對越南文字的檢測具有高召回率的同時也保證了算法對文本區域的準確檢測。
1 越南場景文字檢測算法
本文提出的越南場景文字檢測網絡結構如圖3 所示。圖3中,箭頭表示數據的流向,5個實線框分別表示網絡的5個主要組成部分:包括提取全局圖像特征的特征金字塔網絡(Feature Pyramid Network,FPN)[22];包含生成文本區域候選框的區域生成網絡(Region Proposal Network,RPN)[20];使用候選框坐標和對應圖像特征生成準確候選框坐標的候選框坐標回歸模塊(box branch)[20];使用候選框坐標信息以及圖像特征完成文本分割的區域分割模塊(mask branch)[16];對重復檢測的文本區域進行剔除的文本區域過濾模塊(text region filtering branch)。
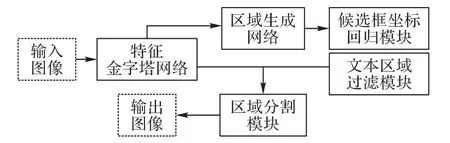
圖3 總體網絡結構Fig.3 Overall network structure
1.1 改進的區域分割模塊網絡特征選取
卷積神經網絡(Convolutional Neural Network,CNN)[23]作為一種提取圖像特征最有效的方法已被大量研究[24-26]證明。對于一個多層CNN 結構而言,不同網絡層的特征圖輸出會提取到不同的圖像特征:淺層網絡特征圖由于感受野小,主要提取的是圖像細節信息和較小區域的特征;隨著網絡的加深,高層特征圖由于擁有更大的感受野,主要提取的是圖像整體信息和較大區域的特征。因此不同的特征層適用于不同的任務,正確地使用特征可以有效提高網絡模型的性能。本文使用特征金字塔網絡輸出的特征圖作為模型的特征來源。特征金字塔網絡對不同網絡層的特征進行了融合處理,可以為模型提取更多有效的信息。特征金字塔網絡使用ResNet101[27]作為網絡主干,對ResNet101 中的5 個不同的大小的特征圖C1、C2、C3、C4、C5 進行上采樣融合后輸出5 個不同尺度的特征圖P2、P3、P4、P5、P6。
Mask R-CNN 的區域分割模塊根據輸入的候選框大小,自適應地選擇特征金字塔網絡的特征圖作為Roi-align[16]進行歸一化的特征來源,越大的候選框會選擇越高層的特征圖。然而高層的特征圖由于分辨率低、細節特征少,不利于區域分割模塊分割有聲調符號的越南文字。為了使區域分割模塊輸出的二值掩碼更加準確地表示聲調符號區域,本文對Mask RCNN模型的特征選取進行以下了改進:
1)使用特征金字塔網絡中的低層高分辨率特征圖(P2)作為Roi-align進行歸一化的特征來源。因為與其他的特征圖相比,P2 特征圖擁有局部細節特征的同時集成了P3~P5 特征圖的高層語義信息,更利于分割文字,而且P2 特征圖的高分辨率更高,更適合于Roi-align進行下采樣。
2)本文的區域分割模塊與Mask R-CNN 使用的區域分割模塊不同,本文候選框坐標回歸模塊生成的候選框經過Roialign 后,會被規范化到14×28×256 大小的特征塊上以適應文本較大的橫縱比,而不是Mask R-CNN 所使用的14×14×256大小。特征塊經過四個卷積層和一個反卷積上采樣層后,得到大小為28×56的二值掩碼矩陣來表示真實文本區域。
改進后的區域分割模塊可以生成更好的二值掩碼矩陣用于文本區域分割。
1.2 文本區域過濾模塊
在常規的目標檢測中,同一目標在一個位置上會出現大量重疊的候選框。非極大值抑制(Non-Maximum Suppression,NMS)算法可以有效地消除冗余候選框,但是非極大值抑制算法是基于候選框交并比(Intersection over Union,IoU)進行設計,IoU為兩個候選框的交集面積除以它們的并集面積。當兩個候選框的IoU 只有大于某一個特定閾值(通常設為0.5)時才會剔除其中的一個候選框,這導致部分文本重復檢測的文字區域無法完全濾除,如圖4(a)中的5 號框將四個單詞檢測為一個單詞區域,圖4(c)中1 號框將單詞的部分區域視為一個單詞區域檢測,這些重復檢測的候選框與任意候選框的IoU小于0.5,所以無法被非極大值抑制算法剔除。造成文本區域重復檢測的原因是場景文本檢測屬于單一目標檢測,且相鄰文本區域的特征類似,這些區域往往被檢測為一個完整的、獨立的文本區域。

圖4 文本區域過濾模塊效果Fig.4 Effect of Text region filtering branch
針對圖4(a)、(c)這兩種現象,本文提出了兩個針對文本區域的過濾算法,兩個過濾算法串行執行以過濾錯誤檢測的區域:1)如果一個檢測框中包含兩個以上的檢測框子集,則將檢測框視為重復的檢測區域并剔除該檢測區域;2)如果一個檢測框是另一個檢測框的單一子集,則剔除單一子集檢測框。
假設存在兩個檢測框分別為A和B,則判斷A檢測框是否為B 檢測框子集的條件是A 與B 檢測框的相交區域面積占A檢測框面積的80%以上,且A 檢測框的高度大于B 檢測框高度的50%。圖4(a)、(c)這兩種重復檢測的情況經過文本區域過濾方法處理后的結果如圖4(b)、(d)所示。本文的文本區域過濾模塊會在檢測到的有限個檢測框內進行迭代過濾,每個檢測框需要和剩下的檢測框進行比較,假設檢測框數量為N,則時間復雜度約為O(N2)。
1.3 訓練方法
本文提出的實例分割算法需要使用像素級標注的數據集進行訓練,但獲取大量像素級標注的圖片需要高額的成本,只利用少量像素級標注的越南場景文字圖片訓練模型則無法達到較好的泛化能力。隨著場景文字檢測研究的發展,公開了大量四邊形標注的拉丁場景文字檢測數據,如MLT2017[28]、MLT2019[29]等,所以如何有效利用這些數據是解決越南場景文字檢測問題的關鍵。本文提出了一種多種數據對模型聯合訓練的方法,能有效解決缺少標注數據導致的模型泛化能力弱的問題。
本文提出的模型聯合訓練方法的訓練過程主要為兩個部分:第一個部分為特征金字塔網絡和區域生成網絡的訓練,使模型能夠擁有提取圖像特征和準確生成文本區域候選框的能力。越南文字與拉丁文字有著相似的特征,可以看作是拉丁文字與聲調符號的組合,其主體部分可視為拉丁文字。使用拉丁文字數據對模型的特征金字塔網絡和區域生成網絡的參數進行訓練,可以使特征金字塔網絡提取文字特征的能力增強,同時使區域生成網絡更準確地生成候選框。訓練使用MLT2017和MLT2019中的拉丁文字數據,共包含7 200張四邊形標注圖像。盡管MLT 中的數據使用四邊形標注,但是四邊形標注不影響區域生成網絡的真實值的獲得。通過計算區域生成網絡輸出的預測與真實值之間差值,使用反向傳播算法對特征金字塔網絡和區域生成網絡的參數進行學習訓練,訓練參數的設置將在實驗部分進行詳細說明。特征金字塔網絡和區域生成網絡的參數大小約為240 MB,約占總模型參數的94%,適用大規模數據訓練以增強模型的泛化能力。
第二部分為候選框坐標回歸模塊和區域分割模塊的訓練,使模型擁有檢測并分割帶聲調符號越南文字的能力。由于區域分割模塊需要使用像素級標注的數據作為真實值進行訓練,本文使用像素級標注方法對200 張越南場景文字圖像進行了標注。盡管越南場景文字數據量與MLT 相比要少,但由于區域分割模塊和候選框坐標回歸模塊具有較淺的網絡結構且參數量較少,可以使用少量像素級標注的越南場景文字數據參數進行訓練,同樣可以得到良好的泛化能力。在第二部分的訓練中,將第一部分訓練好的模型參數進行凍結,只使用越南場景文字數據訓練,模型通過越南場景文字數據集訓練,候選框坐標回歸模塊可以準確地生成包括聲調符號的越南文字候選框,訓練參數的設置同樣在第二章進行說明。通過第二部分的訓練,可以使這兩個模塊分別擁有獲取準確的候選框坐標信息并可以在候選框內準確分割文字區域的能力,從而使網絡可以檢測到越南文字的聲調符號區域并進行逐像素的分割。
在推理部分,將之前訓練的兩個模塊結合,使模型具有較好的泛化能力。本文訓練雖然采用了模型聯合訓練方法,在網絡模型訓練階段的時間復雜度會提升,但不會影響網絡模型在推理部分的時間復雜度。
1.4 評估方法
為了評估本文提出算法的性能,使用檢測到的文本區域與真實文本區域的IoU 數值是否大于某一設定的閾值作為判讀文本區域是否被正確檢測的指標。IoU 計算方法如式(1),其中:X是檢測到的文本區域掩碼矩陣,Y是對應的真實文本區域掩碼矩陣,areas()表示區域大小。本文使用準確率(P)、召回率(R)和F 值(F1)作為檢測算法的性能評估指標。準確率為檢測正確的樣本總數與檢測到的樣本總數的比值,召回率的計算為檢測正確的樣本總數與真實樣本總數的比值。最終評價的指標使用F 值,它是準確率和召回率的調和平均值,計算如式(2)所示。
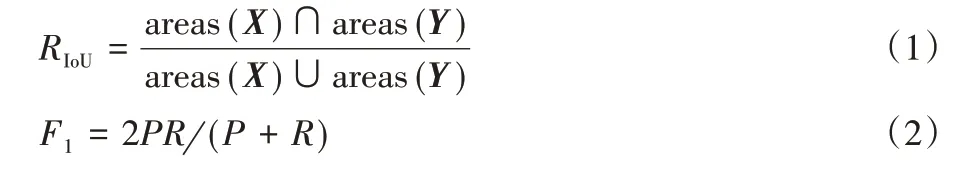
本文將IoU閾值設置為0.7以適應不規則文本實例,這意味著檢測到的文本區域與真實區域的IoU 需要大于70%才被視為正確檢測。為了計算兩個任意形狀文本區域之間的IoU,本文使用區域分割模塊得到的掩碼矩陣與對應真實區域掩碼矩陣的內積作為兩個區域交集的計算方法。假設掩碼矩陣X與掩碼矩陣Y分別為:
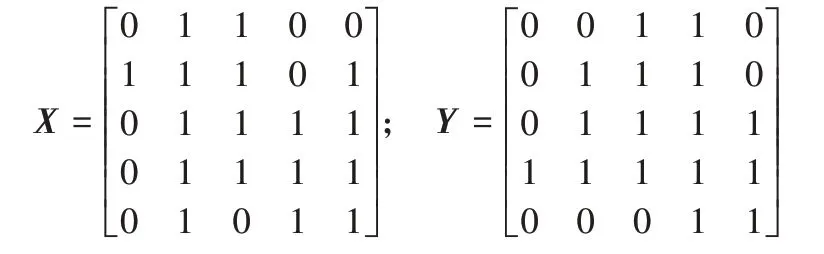
其中掩碼矩陣中文本區域的元素值設置為1,其余部分元素值設置為0。可以進行如下計算:
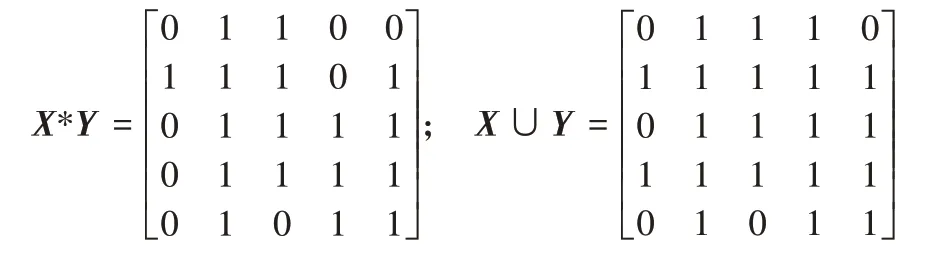
這樣檢測到的文本掩碼矩陣和真實的掩碼矩陣的矩陣對應元素的乘積中元素值為1 的部分就是兩個文本區域之間交集的大小;并集大小為兩個掩碼矩陣中值為1 的元素數量減去掩碼塊交集的大小;得到兩個區域的交集和并集大小后可以通過式(1)得到IoU的值。在本例中IoU大小的計算如下:
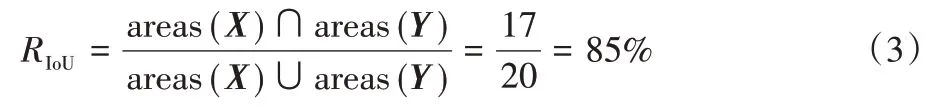
2 實驗及結果分析
為了驗證本文算法的有效性,進行了以下實驗分析:
1)為了證明模型聯合訓練方法的有效性,將本文算法與未使用模型聯合訓練方法進行了5 折交叉驗證對比實驗,計算IoU閾值為0.7時的F值來對算法進行評價。
2)本文提出的實例分割算法為先檢測、后分割的兩階段算法。為了驗證在同一階段進行檢測與分割的單階段實例分割模型是否可以通過少量數據獲得良好的效果,本文算法與較為先進的單階段實例分割算法YOLACT[30]和YOLACT++[31]進行了比較。
3)對提出的文本區域過濾模塊與文本分割模塊的優化進行了兩次消融實驗,并對實驗結果進行了分析。
實驗配置環境為:Ubuntu16.04 操作系統,CPU 為E5-2698v4,GPU 為NVIDIA Tesla V100 ×4,使用Python3.6 作為開發環境,深度學習框架為Keras。
2.1 數據集獲取
為了實現越南場景文字的檢測及模型評估,本文創建了一個用于越南場景文字檢測的數據集,總共包括200 張圖片,全部來源于越南真實場景拍攝。越南場景文字數據集的標注方式全部使用像素級標注。不同于矩形或四邊形區域表示文本區域的方式,像素級標注是指圖像中的每一個像素被分為背景和文字兩種類型,其中每個文本實例使用不同掩碼值表示不同的掩碼塊。由于越南文字中聲調符號的存在,文字區域的形狀并不規則,使用像素級標注可以精準地表示每一個包括聲調符號的越南文字區域。
由于越南文字的主體是拉丁字母,與拉丁文字在字形上的特征相似度高,本文在實施模型聯合訓練時還使用了自然場景多語言文本檢測數據集(MLT)。該數據集是國際文檔分析與識別大會舉辦的一個多國場景文字檢測識別競賽中使用的數據集,其圖片來源于世界各地的各種不同場景,其中包含了10 個國家的7 種不同字體類型,所有文本區域都使用四邊形標注。本文使用了其中7 200 張只包括拉丁文字類型的圖片作為輔助數據用以提升模型的泛化能力。
2.2 模型聯合訓練有效性實驗
為了證明使用模型聯合訓練方法的有效性,首先使用MLT數據集對特征金字塔網絡和區域生成網絡的參數進行訓練,并使用隨機梯度下降法(Stochastic Gradient Descent,SGD)作為優化方法。初始學習率設為0.001,權值衰減設為0.001,動量設為0.9,在MLT 數據集上訓練10 個epoch,每個批次有兩張訓練圖片。在訓練候選框坐標回歸模塊的參數和文本區域分割模塊的參數時,其他已訓練參數被凍結,使用越南場景文本數據集訓練10個epoch 后得到一個完整的模型。對比方法使用越南場景文本數據集對整個模型參數進行訓練,一共訓練20個epoch,訓練優化參數與模型聯合訓練方法相同。
在越南場景文字檢測數據集上進行了3 組5 折交叉驗證實驗,模型聯合訓練的方法在使用越南場景文字檢測數據訓練之前已使用MLT 數據集對特征金字塔網絡和區域生成網絡的參數進行訓練。第1 組交叉驗證設置使用越南場景文字檢測數據集的圖片數為160,剩下的40張圖片作為驗證集;第2 組交叉驗證設置使用越南場景文字檢測數據集的圖片數為100,剩下的100張圖片作為測試集;第3組交叉驗證設置使用越南場景文字檢測數據集的圖片數為40,剩下的160 張圖片作為測試集。每組實驗都分割出5 組不同的訓練與驗證數據用于5折交叉驗證。
實驗結果如表1 所示,可以看出本文提出的模型聯合訓練方法可以獲得更好的檢測效果。即使使用圖像數量較少的訓練集,如40 張圖片來訓練候選框坐標回歸模塊和區域分割模塊,也可以得到很高的F 值。部分與使用MLT 數據集訓練方法對比的實驗結果如圖2和圖5所示,模型聯合訓練的方法與僅使用MLT 數據集訓練的方法相比可以有效檢測到越南文字的聲調符號區域。通過本次實驗可以得到以下結論:
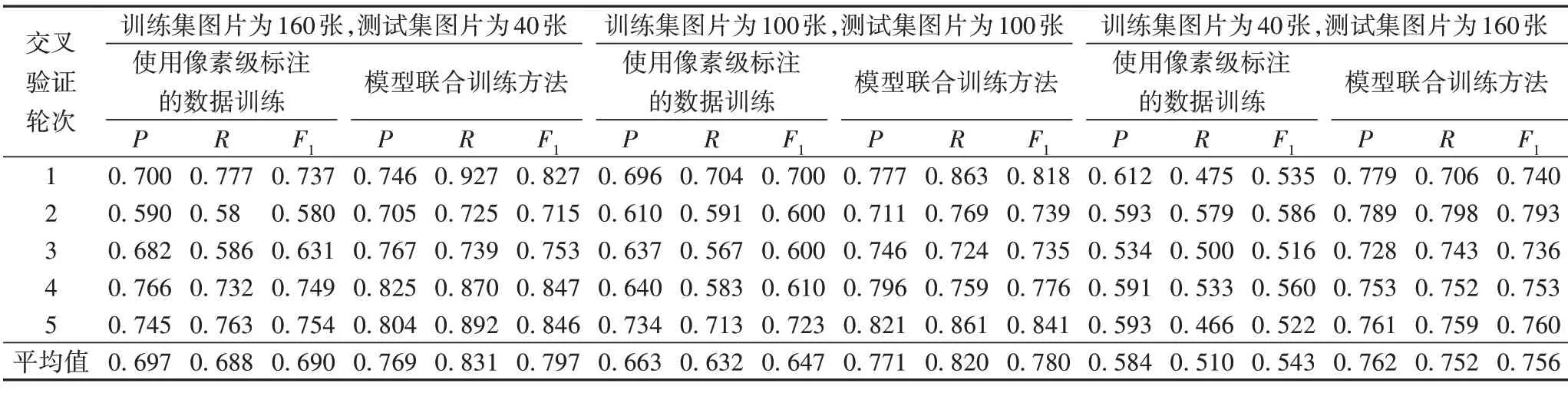
表1 使用與未使用模型聯合訓練方法在越南場景文本數據集上的對比Tab.1 Comparision between using and not using model joint training method on Vietnamese scene text dataset

圖5 模型聯合訓練方法對部分越南文字的檢測結果Fig.5 Detection results of some Vietnamese texts using model joint training method
1)用四邊形標注的拉丁文本數據集訓練特征金字塔網絡和區域生成網絡,可以幫助網絡更準確地判斷場景文本區域。
2)使用模型聯合訓練的方法可以有效利用不同規模和不同標注方式的數據集。
3)區域分割模塊和候選框坐標回歸模塊不需要大量數據集進行訓練也可以獲得很好的性能。
2.3 與其他單目標實例分割算法的比較實驗
本文算法基于兩階段實例分割的思想,為了驗證單階段實例分割的算法是否可以使用小規模數據達到更好的泛化能力,使用最新的單階段實例分割算法YOLACT 和YOLACT++與本文算法進行了比較,結果表明其他單階段實例分割模型也無法通過少量數據獲得良好的效果。使用越南場景文字數據集訓練這兩種實例分割算法,為了達到這兩種方法的最佳性能,算法的主干網絡均使用與本文算法相同的ResNet101網絡,使用SGD 作為優化方法,使用早停法(early stopping)訓練模型。對比結果如圖6 所示,本文算法的查準率、查全率和F 值在規模為160、100 和40 大小的訓練集上都具有較大的優勢。實驗結果表明,由于兩階段方法天然對目標檢測中正負樣本不平衡的問題存在優勢,Mask R-CNN 兩階段實例分割算法對于小規模數據的準確率要高于YOLACT 和YOLACT++的單階段實例分割算法。
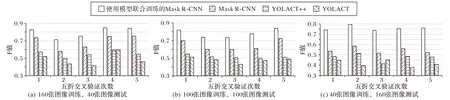
圖6 四種實例分割算法在三種不同規格訓練集、驗證集上的F值對比Fig.6 F-mesure comparison of four instance segmentation algorithms on three different specifications of training sets and validation sets
2.4 消融實驗
2.4.1 優化文本區域分割模塊的有效性驗證實驗
為了驗證本文對區域分割模塊中改動的有效性,將優化前與優化后的方法進行比較實驗。實驗在模型聯合訓練的第二階段,進行了優化前和優化后兩種模型在三組不同規模訓練數據集的交叉驗證實驗,得到在IoU 閾值分別為0.7、0.8、0.9情況下的對比實驗結果如圖7所示。圖7結果表明,P2層包括高層語義信息的同時也包含了圖像的細節信息,擁有更多利于文本分割的特征,采用P2作為文本區域分割模塊特征提取層和使用14×28×256大小的掩碼特征塊可以得到更準確的掩模區域。在IoU閾值設置為0.9時,使用規模大小為160、100 和40 的訓練數據集進行第二階段訓練,本文的優化方法對比優化之前的方法分別提高了32.3%、19.6%和16.3%。圖8 展示了使用兩種方法的部分結果,可以看出本文的優化方法可以更準確地分割越南文字區域。

圖7 區域分割模塊優化前后在三種不同規格訓練集、驗證集上的F值對比Fig.7 F-mesure comparison before and after optimization of Mask branch on three different specifications of training sets and validation sets

圖8 區域分割模塊優化前后的部分檢測結果Fig.8 Partial detection results before and after optimization of Mask branch
2.4.2 文本區域過濾模塊有效性驗證實驗
本文通過計算每個交叉驗證實驗中文本區域過濾模塊消除的錯誤檢測區域個數,驗證了提出的針對文本實例的區域過濾模塊的有效性。文本區域過濾模塊對檢測結果的提升如表2所示。
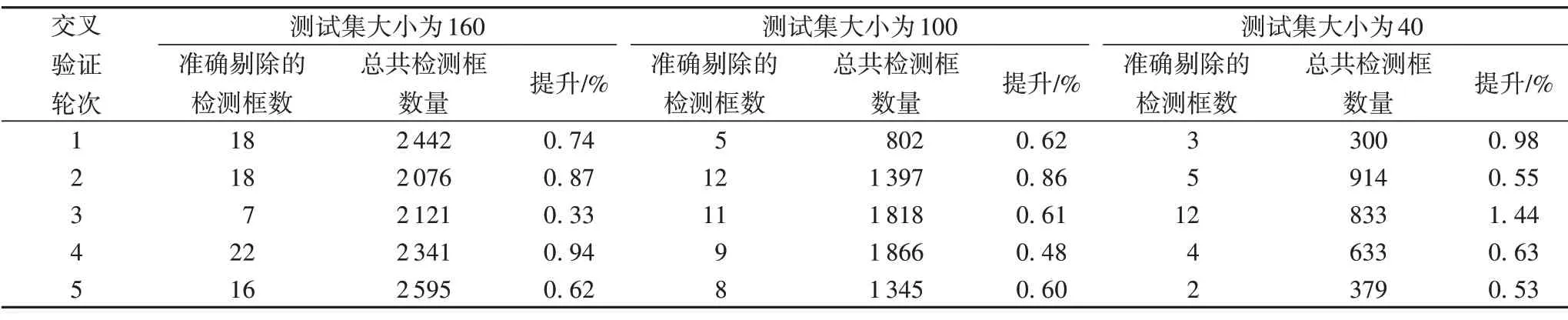
表2 使用和不使用文本區域過濾模塊的在越南場景文本數據集上的性能對比Tab.2 Performance comparison between using and not using the proposed text region filtering module on vietnamese scene text dataset
3 結語
本文首先說明了目前場景文字檢測算法在檢測越南文字時存在的問題,并基于這些問題提出一個基于Mask R-CNN模型的越南場景文字檢測方法。對于缺乏像素級標注的實例分割數據帶來的問題,提出使用模型聯合訓練的方法提高了模型的泛化能力;針對越南場景文字檢測中大量存在的聲調符號區域漏檢測現象,通過優化文本區域分割模塊和使用像素級標注的數據訓練,使得模型能準確地分割包括聲調符號的越南文字區域;此外,還提出了針對文本的文本區域過濾模塊有效解決了由文本連續性導致的重復檢測的問題,實驗結果表明本文提出的算法可以有效使用少量像素級標注的數據集實現越南場景文字的實例分割,與Mask R-CNN 模型相比,本文算法在準確率與召回率上都具有優勢。之后的工作將對模型進行簡化處理,降低算法的時間復雜度。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
小學教學參考(2015年20期)2016-01-15 08:44:38
電測與儀表(2015年5期)2015-04-09 11:30:52
