
基于預訓練和多層次信息的中文人物關系抽取模型
2022-01-05 02:32:12姚博文曾碧卿丁美榮
計算機應用 2021年12期
姚博文,曾碧卿,蔡 劍,丁美榮
(華南師范大學軟件學院,廣東佛山 528225)
(?通信作者電子郵箱15797680180@163.com)
0 引言
關系抽取(Relation Extraction)是自然語言處理(Natural Language Processing,NLP)的熱點研究方向之一,該任務的目的是判斷自然語言文本中兩個實體之間的潛在語義關系,比如從句子“[華盛頓]是[美國]的首都”中,可以從兩個實體[華盛頓]和[美國]抽取出特定關系事實,獲得關系三元組〈華盛頓,首都,美國〉。目前的大型知識庫Freebase、DBpedia 以及國內的百度百科等,都存儲了大量的關系事實三元組,但距離反映現實世界中的所有關系還遠遠不夠。而關系抽取能夠從非結構化文本提取關系事實三元組,達到擴充知識庫中關系事實數量的目的,對知識圖譜的構建與補全起到重要的推動作用。
關系抽取主要包括基于模式匹配、基于傳統機器學習和基于深度學習的方法。其中,深度學習方法具有較強的特征學習能力,并且不需要復雜的特征工程,因此是目前關系抽取領域使用最廣泛的方法,比如卷積神經網絡(Convolutional Neural Network,CNN)、循環神經網絡(Recurrent Neural Network,RNN)等被廣泛應用于關系抽取。
目前,大部分關系抽取領域的研究都針對英文語料庫來開展,由于中文與英文在語言學上具有一定的差異性,因此一些在英文語料庫上表現良好的方法對中文語料并不適用。中文語料中存在著更為復雜的語法結構,進行中文關系抽取更具有難度和挑戰性,而且由于目前中文自然語言處理研究基礎相對薄弱等原因,導致現在針對中文人物關系抽取語料的研究還不夠全面和徹底。同時,傳統文本表示方法的局限也制約著關系抽取的性能,比如傳統的詞向量模型Glove、Word2Vec 等為每個詞生成固定的靜態向量表示,生成的詞向量表示不包含語境上下文相關的語義信息。BERT(Bidirectional Encoder Representations from Transformers)[1]、生成式預訓練(Generative Pre-Training,GPT)[2]等大規模預訓練模型的出現能克服該缺點,解決一詞多義的問題,學習到更加豐富的詞特征表示,提升模型的性能。
針對中文語料語法結構復雜、傳統文本表示方法存在局限性的問題,本文提出了一種基于預訓練和多層次信息的中文人物關系抽取模型(Chinese Character Relation Extraction model based on Pre-training and Multi-level Information,CCREPMI),其中選取了BERT 預訓練模型,將原始輸入數據初步建模成上下文語境相關的向量化表示。面對中文人物關系抽取文本語料中復雜的語法結構,CCREPMI 首先在句子信息提取層使用雙向長短時記憶(Bi-directional Long Short-Term Memory,BiLSTM)網絡和注意力機制的融合網絡捕捉句子的句法結構特征,并且深入考慮句子中實體詞與鄰近詞之間的復雜依賴關系,例如句子“小明雇小紅為其提供勞動服務”,“雇”字對關系類型的判斷產生較大影響,揭示了兩個人物的上下級關系,于是CCREPMI在實體鄰近信息提取層捕捉并利用這種依賴關系,同時在實體信息提取層挖掘實體詞含義,最后在信息融合層將多個層次的信息融合成更具代表性的樣本特征向量,最終使用Softmax函數進行關系的判斷。
本文使用CCREPMI模型在中文人物數據集上進行實驗,實驗結果表明本文提出的CCREPMI 模型相比其他一些Baseline模型在性能上有所提升,驗證了所提方法的有效性。
本文的主要工作有:
1)提出了一種結合預訓練和多層次信息的中文人物關系抽取模型CCREPMI,將多層次信息和BERT 預訓練模型整合到關系抽取的架構中。
2)在中文人物關系數據集上對CCREPMI 模型的有效性進行了測試,并通過與其他現有方法的實驗對比,驗證了本文CCREPMI 模型在中文關系抽取任務上的先進性。還在SemEval2010-task8 數據集上對CCREPMI 模型在英文語料上的適應性進行了測試,驗證了該模型對英文語料也具有一定的泛化能力。
1 相關工作
在當今時代中,面對互聯網上海量的數據,如何挖掘并利用其中的有價值信息是一個重要的問題。其中關系抽取任務能從無結構或半結構文本中抽取結構化三元組,促進后續的信息檢索和知識圖譜構建,因此得到了不少科研工作者的關注。目前的實體關系抽取研究工作主要圍繞深度學習方法展開,并且根據語料中的實體關系是人工標注還是對齊知識庫自動標注,可以簡單分為有監督學習方法和遠程監督學習方法兩個大類。
有監督的學習方法是目前關系抽取領域應用最為廣泛的方法,通過在人工標注樣本上訓練模型以實現對關系的分類和預測。Socher 等[3]使用一種遞歸神經網絡模型來學習一個用于計算任意類型的多詞序列的向量和矩陣表示,并在SemEval2010-task8 數據集上取得了良好的效果。Zeng 等[4]在CNN 的基礎網絡結構上引入了位置編碼信息作為特征,提升了模型的表現。dos Santos 等[5]在此基礎上進行改進,提出了基于排序進行分類的卷積神經網絡(Convolutional Neural Network that performs Classification by Ranking,CRCNN)模型,并針對關系類型中的other 類做了特殊處理,在針對Semeval-2010 task8 數據集的評價指標中取得領先。Xu 等[6]使用長短時記憶(Long Short-Term Memory,LSTM)網絡和最短依賴路徑(Shortest Dependency Paths,SDP)進行關系抽取取得了良好效果。Lee等[7]設計了一種新的端到端遞歸神經模型,能有效地利用實體及其潛在類型作為特征,取得了更高的關系抽取準確率。
由于有監督的方法采用的人工標注需要大量人力物力,Mintz 等[8]提出一個假設,如果文本中的實體對和外部知識庫中的實體對一致,就假設它們擁有一樣的關系。遠程監督(Distant Supervision)便是基于這種假設,通過對齊外部知識庫自動獲得標注好的訓練數據;其缺點在于自動標注會產生很多噪聲數據,影響模型性能。Lin 等[9]提出基于選擇性注意力機制(Selective Attention)的CNN+ATT和PCNN+ATT模型方法來完成遠程監督關系抽取任務,通過選擇性注意方法削弱噪聲實例的影響,以解決遠程監督中的錯誤標簽問題。Peng等[10]對PubMed Central 中約100 萬篇醫學論文依靠遠程監督方法獲取訓練數據集,并提出了一種基于圖LSTM 的關系抽取方法,可以實現跨句子的N元關系提取。Ji 等[11]提出的基于分段卷積神經網絡的句子級注意模型(sentencelevel Attention model based on Piecewise Convolutional Neural Network,APCNN)用句子級注意力機制在一個包里選擇多個有效實例,并且引入實體描述信息進行遠程監督關系抽取。Li 等[12]提出的SeG(Selective Gate)模型克服了選擇性注意力機制框架的缺陷,在NYT 數據集上的實驗表明,該方法在AUC和Top-n精度指標上都達到了新的水平。
此外,開放域關系抽取是有別于傳統領域關系抽取的一種新形式,無需預定義好的關系類型,自動抽取關系三元組。Banko 等[13]首次提出了開放信息抽取的概念,并設計了TEXTRUNNER 系統進而提取更加多樣化的關系事實。Akbik等[14]提出一個專門用來捕獲N元事實的開放域關系抽取系統KrakeN,并通過實驗表明,該系統能達到較高精度,相比現有其他開放域關系抽取方法能捕獲更多更具完整性的關系事實。
在中文人物關系抽取方面,王明波等[15]結合雙向門控循環單元(Gated Recurrent Unit,GRU)和分段卷積神經網絡(Piecewise Convolutional Neural Network,PCNN),分別利用二者處理序列和提取局部特征的優勢,在人物關系語料庫上取得了較優的效果。劉鑒等[16]提出基于LSTM 和結構化自注意力機制的方法來解決訓練數據中存在的噪聲問題,能有效提高中文人物關系抽取的準確率與召回率。
上述模型都表現出了出色的性能,但是如RNN、CRCNN等模型使用的是靜態詞向量,忽略了文本的上下文語境化信息;SeG 和APCNN 等模型雖然深入挖掘了實體信息特征,但對實體詞和鄰近詞的依賴特征考慮得還是不夠。為了克服上述模型的缺點,本文提出的CCREPMI 模型通過BERT 預訓練模型獲取文本的語境化表示,并同時考慮實體詞含義、實體詞與鄰近詞依賴關系、句子整體結構三個方面,即從詞、局部、整體三個層次提取有效特征信息,取得了較好的效果。
2 基礎技術
2.1 數據預處理
本文針對語料庫數據的預處理策略共分6 步,如圖1所示:
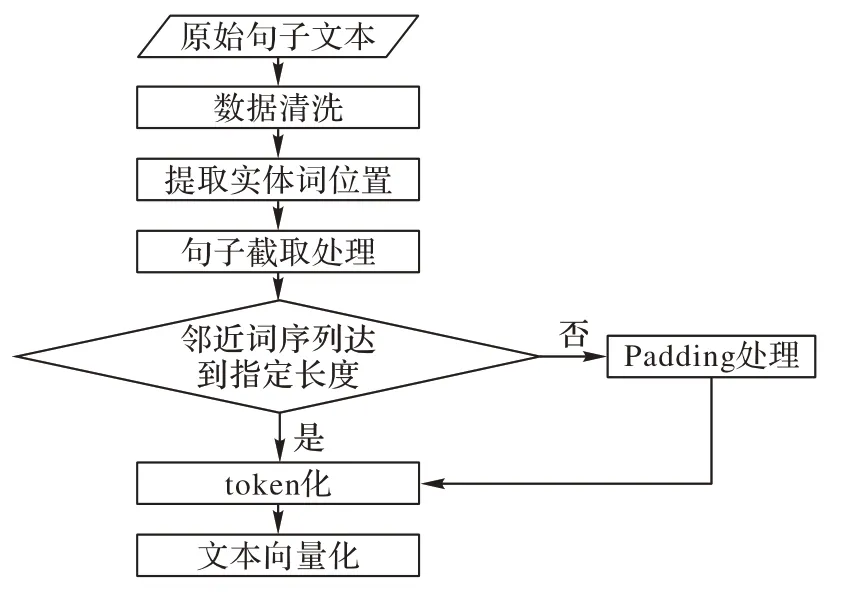
圖1 數據預處理流程Fig.1 Process of data pre-processing
1)進行數據的清洗,比如無效字符的刪除。
2)提取兩個實體詞在句子中的位置。
3)進行截取處理。對于輸入的原始文本句子S={w1,w2,…,wn}以及實體對e1和e2,根據實體詞位置將實體的前c個詞以及后c個詞組成的序列截取出來,并稱之為實體鄰近 詞 序 列Seqi={wpos(ei)-c,…,wpos(ei)+c}(i∈{1,2}),其 中 的pos(ei)是指第i個實體在句子中的位置,c為鄰近詞窗口值,可通過超參數設置。具體截取方式如圖2 所示,若鄰近詞窗口值c=2,對于圖中實體e1而言,w2、w3、w4、w5皆為其鄰近詞,這些鄰近詞與實體詞組成的序列為實體鄰近詞序列,將該序列截取出來。
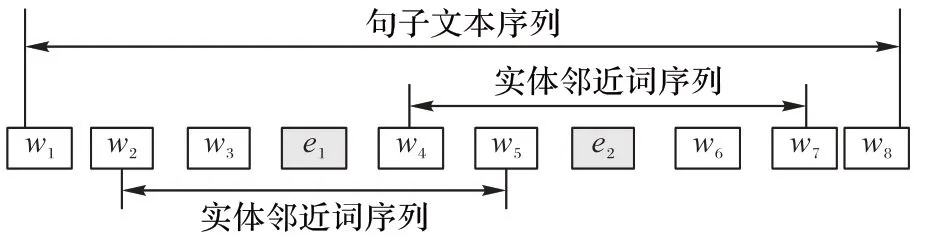
圖2 句子截取方式示例Fig.2 Example of sentence segmentation
4)若截取后實體鄰近詞序列沒有達到指定長度,則進行Padding處理填充到指定長度。
5)將句子、實體詞、實體鄰近詞序列進行token化處理,預訓練模型通過詞表將token序列進行向量化。
2.2 BERT預訓練模型
BERT模型具備學習到詞的上下文相關信息的能力,有力地克服了Word2Vec、FastText、Glove 等密集的分布式詞向量表示方法無法解決“一詞多義”問題的缺點,在多個方面的NLP任務上都大幅刷新了精度,具備較強的泛化能力。
BERT 是使用多個Transformer 編碼器堆疊而成的網絡架構,其模型結構如圖3 所示。與傳統的按照文本序列單向訓練的語言模型不同,BERT 通過掩蓋語言模型(Mask Language Model,MLM)的預訓練任務,隨機將部分token 用[MASK]標記掩蓋,以完形填空的形式利用上下文來預測被掩蓋的token,MLM 任務可以同時利用雙向的上下文得到包含單詞語境信息的特征表示。此外,BERT 通過下一句預測(Next Sentence Prediction,NSP)任務預測后一個句子是否應該接在前一句之后,從而使得BERT可以學習到句子間的關系。
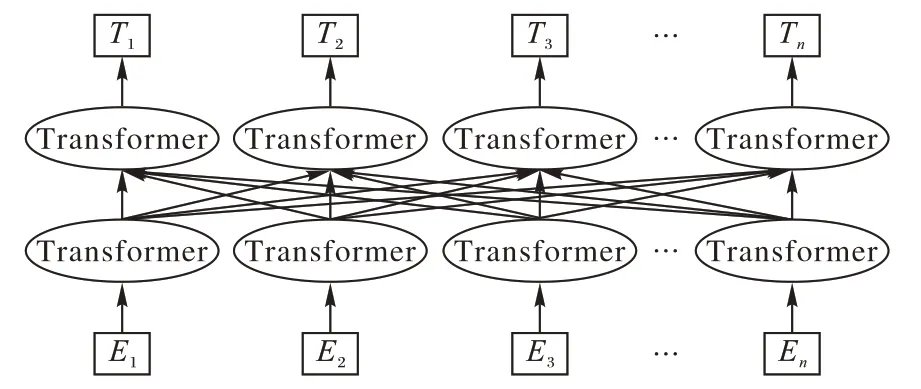
圖3 BERT模型Fig.3 BERT model
2.3 雙向長短時記憶網絡
RNN 在自然語言處理領域常用于序列化非線性特征的學習,針對RNN 無法捕捉長距離信息和梯度消失的問題,LSTM 網絡通過引入記憶單元和門控機制對RNN 作了一定程度的改進,在關系抽取任務中取得了較好的效果。LSTM單元結構如圖4 所示,其中包含了遺忘門、輸入門和輸出門三種門結構,然后通過這種結構來實現長期記憶能力。
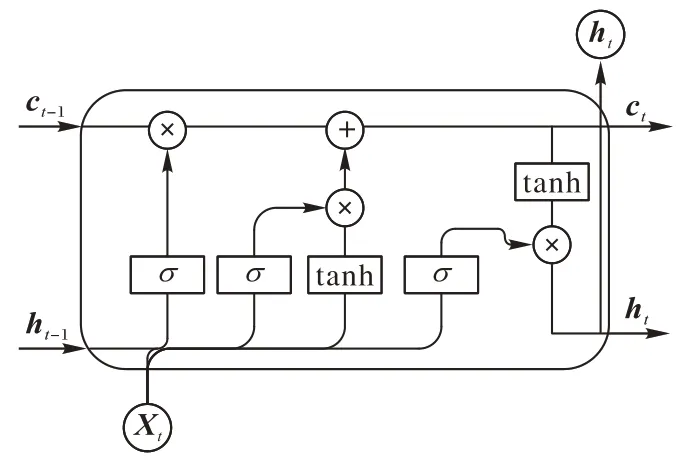
圖4 LSTM結構Fig.4 LSTM structure
LSTM模型公式如下所示:
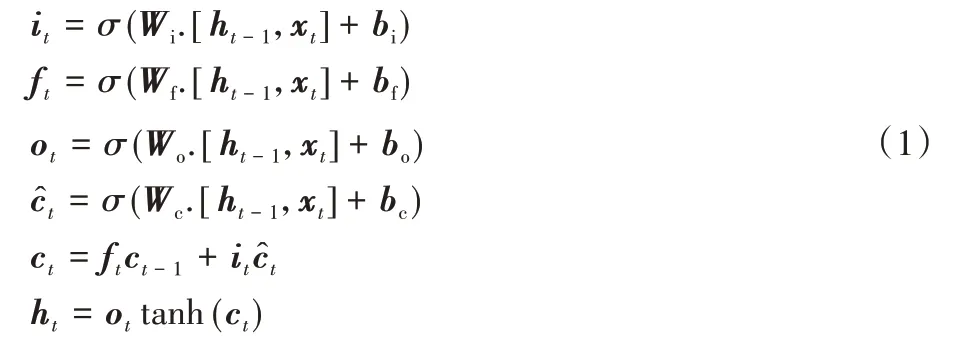
其中:Wi、Wf、Wo、Wc和bi、bf、bo、bc分別表示不同的權重矩陣和偏置量;Xt表示在t時刻輸入的變量;ht-1表示在t-1 時刻的隱藏狀態,ht表示t時刻隱藏層的隱藏狀態;ct表示t時刻的細胞狀態,表示t時刻候選細胞狀態;it、ft、ot分別指輸入門、遺忘門、輸出門;σ是sigmoid 激活函數;tanh 是雙曲正切激活函數。
BiLSTM 網絡如圖5 所示,它包括正向LSTM 和反向LSTM這兩個部分。
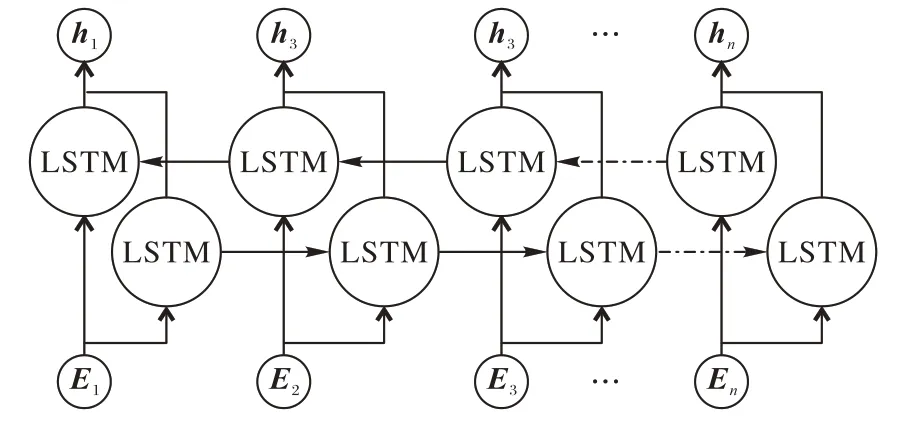
圖5 雙向LSTM層Fig.5 Bidirectional LSTM layer
2.4 注意力機制
注意力機制目前在自然語言處理領域任務中卓有成效,它類似于人類的注意力機制,聚焦目標的關鍵信息,忽略重要程度較低的信息。為了提升信息捕捉效率,本文使用注意力機制使模型聚焦關鍵部分,計算得到注意力分布。

其中:H是輸入特征矩陣,α是注意力權重,O是注意力機制加權之后的特征表示,W是可訓練的權重向量,tanh是雙曲正切激活函數。
3 CCREPMI模型
本文CCREPMI 模型總體結構如圖6 所示。主要分成以下三個部分:
1)輸入層:該層對于每個預定義好實體對的原始句子文本數據,通過預處理操作將其分成三個部分后輸入到預訓練模型中,編碼成分布式向量表示,以初步提取其語義特征。
2)多層次信息提取層:該層結構包括三個并行的單元,單元之間使用不同的網絡結構,分別用于提取句子層次、實體層次和實體鄰近層次的信息。
3)信息融合層:該層將句子層次、實體層次和實體鄰近層次的信息三個方面的深層特征信息合并,獲得蘊含關系特點的特征向量表示,經過一個線性全連接層后最終輸入到Softmax函數中進行最終關系預測。
3.1 輸入層
對于文本序列X={x1,x2,…,xn},在文本序列的開頭加入[CLS]標志,結尾加入[SEP]標志。隨后使用BERT 預訓練模型將該文本序列轉化為相應的BERT 詞向量表示,從而獲得句子詞向量表示V,具體如式(1)所示:
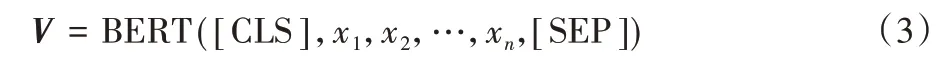
本文使用上述公式將訓練數據中樣本句子序列S轉化為向量化表示Vsen={E1,E2,…,En},En為序列中第n個單詞的詞向量表示;同時將樣本中兩個實體轉化為向量化表示,將兩個實體鄰近詞序列轉化為向量化表示。
3.2 多層次信息提取層
本文的多層次信息提取層包括句子層次信息提取單元、實體層次信息提取單元、實體鄰近層次信息提取單元三個單元,具體如圖7 所示。不同的提取單元用于提取不同層次的特征信息,之后輸入到模型下一層進行信息的融合。
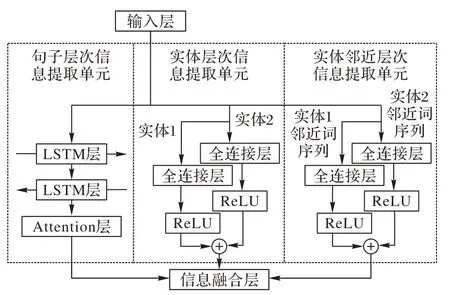
圖7 多層次信息提取層Fig.7 Multi-level information extraction layer
在句子層次信息提取單元,首先將輸入層中的詞嵌入矩陣Vsen={E1,E2,…,En}送入BiLSTM 模型,經過前向傳播和后向傳播的特征學習過程后,得到前向隱藏狀態和后向隱藏狀態,隨后將二者合并起來作為BiLSTM 網絡層最終輸出的特征向量H=Concat(hfw,hbw)。在注意力層對其進行優化,最終得到注意力加權后的特征表示O。
在實體層次信息提取單元,為了更好地利用實體級別語義信息,CCREPMI模型將兩個實體的向量化表示輸入到兩個并行的線性全連接層中進行特征信息學習。
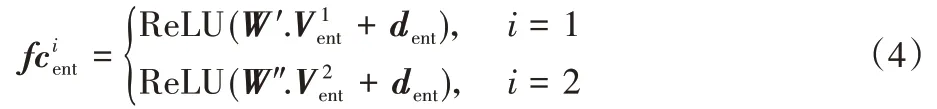
實體鄰近層次信息提取單元同樣包含兩個并行的全連接層網絡,將兩個實體鄰近詞序列的向量化表示輸入到全連接層進行實體詞與鄰近詞依賴信息的提取。
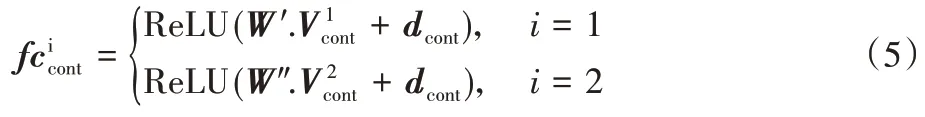
3.3 信息融合層
在信息融合層,模型將上一層提取得到的三個層次信息合并,得到最終特征表示I:

將包含多層次信息的特征表示I送到一個線性全連接層中,并使用Softmax 函數計算關系預測的概率分布,可以用下列式子表示:
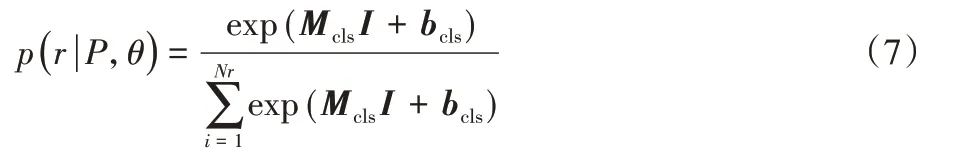
其中:p表示關系預測的概率分布;Nr表示關系類別數量;Mcls是權重矩陣;bcls是偏置量。為了得到模型參數,將訓練目標最小化損失函數定義為:

其中:J表示目標函數;Ns是所有樣本句子數;θ是模型參數,訓練過程中使用Adam 優化器在多次訓練后得到參數最優的模型。
4 實驗與分析
4.1 數據集與評價指標
4.1.1 中文數據集
中文關系抽取實驗數據集目前較為匱乏,本文實驗使用的中文數據集是借助互聯網資源獲得的中文人物關系數據集,其中共包含朋友關系、同事關系等12類人物關系,實驗隨機選取了人物關系語料中的18 000 個實例作為訓練集,3 600個實例作為測試集。
4.1.2 英文數據集
為了充分驗證模型效果,實驗中也使用了英文SemEval2010-task8數據集,它包含9種帶有方向的關系和1種不帶方向的關系。該數據集訓練集共8 000個樣本,測試集共2 717個樣本。
4.1.3 評價指標
本文采用精度Pre(Precision)、召回率Rec(Recall)和F1(F1值)作為模型性能的評價指標。具體公式分別如下所示:
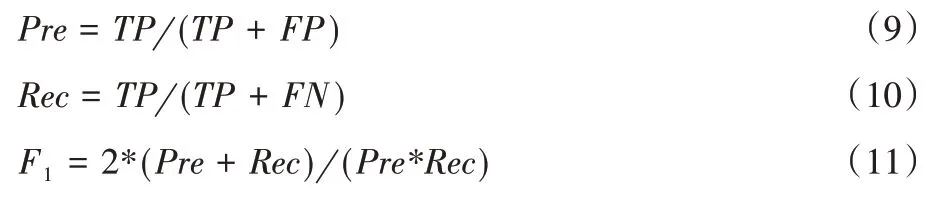
其中:TP是真正例數,FP是假正例數,FN是假反例數;F1是將精度和召回率進行加權調和平均的結果。
4.2 實驗環境和超參數設置
表1列出了本文實驗使用的超參數,實驗環境設置如表2所示。
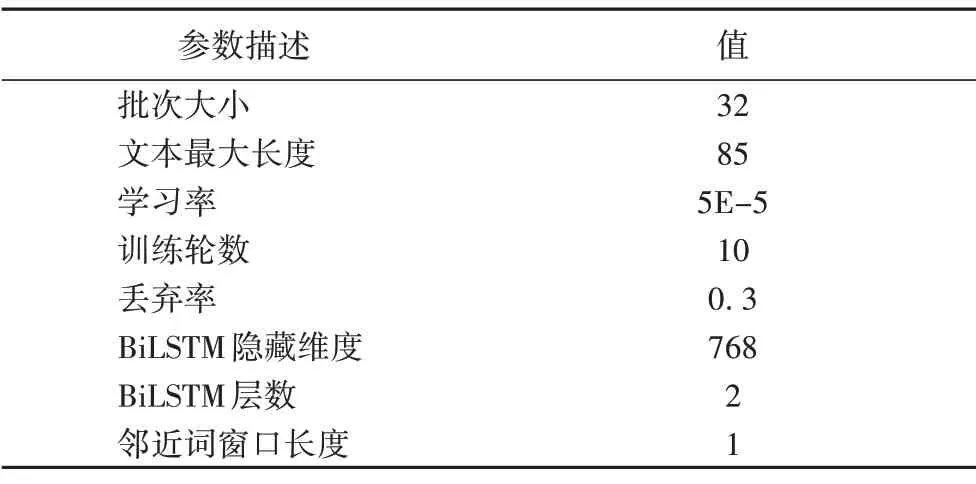
表1 超參數設置Tab.1 Hyperparameter setting

表2 實驗環境Tab.2 Experiment environment
4.3 實驗結果
4.3.1 不同預訓練語言模型的影響
為了探究選擇的預訓練模型對CCREPMI的影響,本文設計了以下3個變體模型進行對比。
1)CCREPMI-BERT。
在輸入層以BERT 預訓練語言模型[1]生成詞嵌入矩陣,BERT 使用維基百科數據進行訓練,通過MLM 訓練任務獲得上下文相關的雙向特征。
2)CCREPMI-BERT-wwm。
在輸入層以BERT-wwm預訓練語言模型[17]生成詞嵌入矩陣,BERT-wwm 面向中文語料,使用中文維基百科數據進行訓練,并使用全詞掩蓋機制對BERT進行改進。
3)CCREPMI-ERNIE。
在輸入層以ERNIE 預訓練語言模型[18]生成詞嵌入矩陣,ERNIE面向中文語料,訓練時額外使用了百度百科、百度貼吧等數據,并且將實體向量與文本表示結合。
為了驗證哪一種預訓練模型的有效性最高,將三種模型進行對比,將模型輸出的詞嵌入向量維度E都統一設置為768,并采用精度、召回率、F1 值作為模型的評價指標,預訓練模型對實驗結果的影響如表3所示。
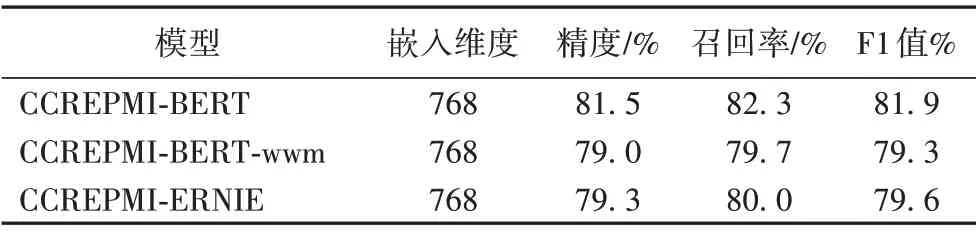
表3 不同預訓練模型的結果對比Tab.3 Result comparison of different pre-trained models
由表3 可以看出,CCREPMI-BERT 模型取得了最好的結果,比另外兩種模型在F1值上分別高出2.3和2.6個百分點。BERT、ERNIE、BERT-wwm 三個預訓練模型各有側重,本文認為實驗中基于ERNIE 的模型和基于BERT-wwm 的模型表現不如基于BERT 的模型的原因可能是不夠貼合訓練數據樣本,并且因為中文分詞存在的錯誤傳播問題,BERT-wwm 的全詞掩蓋和ERNIE 的實體mask 功能可能沒有發揮優勢。此外ERNIE模型引入的外部知識對微博文本等非正式數據的建模會更加有效,在本文數據集上的表現并不突出。因此本文最終選擇了效果最佳的BERT 預訓練模型,將其融入到CCREPMI的整體架構中去。
4.3.2 對比模型
本文模型旨在提升中文人物關系數據集的準確程度,因此將所提出方法分別與當前一些較好的方法在本文實驗環境進行實驗并對比分析。對比方法包括:
1)CNN[4]:使用標準的CNN 模型進行關系抽取,卷積核大小為3,使用了位置編碼(Position Encoding)特征。
2)CRCNN[5]:在標準CNN 基礎上進行改進,在損失函數部分使用ranking-loss機制,提升了關系抽取的效果。
3)BiLSTM-ATT[19]:基于BiLSTM 網絡,同時利用輸入序列的正向和反向信息得到隱藏向量,然后再使用注意力機制捕捉關鍵信息進行關系分類。
4)BERT[1]:基于BERT 預訓練模型的方法,將文本轉化為BERT詞向量,直接輸入到分類器中進行關系分類。
5)BERT-LSTM[20]:基于BERT 預訓練模型的方法,將經過BERT 層的句子向量送入LSTM 層進行編碼,再將隱藏向量送入分類器。
6)RBERT[21]:使用BERT 預訓練模型獲取文本的向量表示,將句子向量與兩個實體的向量表示連接后送入Softmax 分類器。
7)CCREPMI-S:在標準CCREPMI 網絡基礎上簡化了網絡結構,對句子建模過程中移除了在模型中的Attention 層,其余結構與標準CCREPMI網絡相同。
8)CCREPMI-G:在標準CCREPMI 網絡基礎上更改網絡結構,對句子建模過程中使用BiGRU 網絡代替BiLSTM 網絡,其余結構與標準CCREPMI網絡相同。
通過對比分析表4 中的實驗結果可知,本文CCREPMI 模型精度、召回率、F1 值分別為81.5%、82.3%、81.9%,相較于其他模型而言具有更優的表現。該結果表明本文融合預訓練模型和多層次信息的CCREPMI 模型對于提升關系抽取任務的性能具有一定的效果。
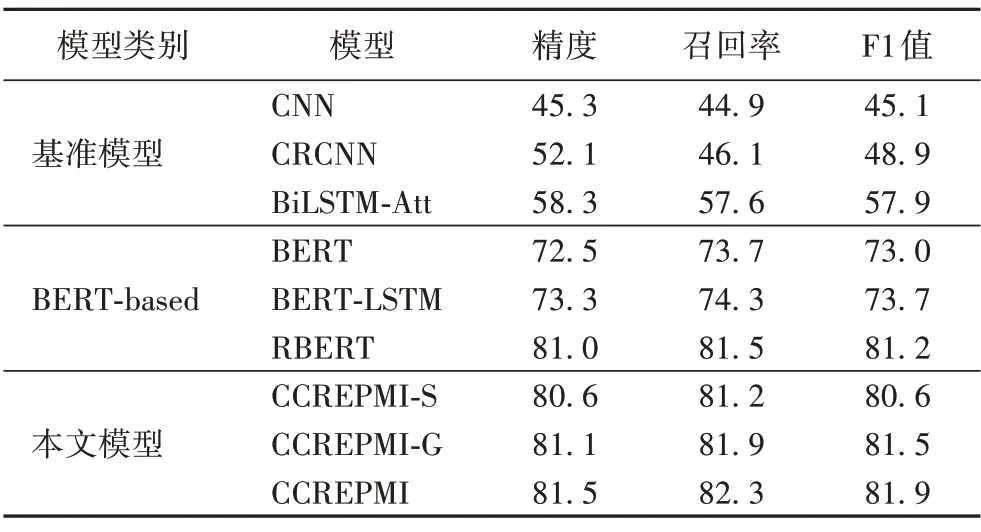
表4 不同模型的性能對比 單位:%Tab.4 Performance comparison of different models unit:%
其中,相比基準模型如CNN、CRCNN、BiLSTM-Att 等模型,BERT-based 模型在精確率、召回率和F1 上均有顯著的提升,本文認為原因是基準模型的詞向量使用的是隨機初始化以及Glove兩種形式,所生成的靜態詞向量無法表征上下文信息,也就難以克服一詞多義現象,而BERT 模型在大規模語料庫進行預訓練,具有更強的文本理解能力,且包含語境上下文信息,能有效解決一詞多義的問題,由此可見,使用BERT 生成詞向量能更好地提升模型的性能,驗證了預訓練模型的重要性。
此外,CCREPMI 與BERT-based 的模型如RERT、BERT、BERT-LSTM 對比分別在F1 值上提高了0.7、8.9 和8.2 個百分點。首先,相對而言,BERT模型的表現較差,筆者認為原因在于BERT 模型僅通過微調的方式進行關系類型的判斷,提取的特征不夠豐富,而BERT-LSTM 模型使用BERT+LSTM 的聯合網絡,有效地提高了模型提取序列信息的精確程度,相比BERT 的F1 值提升了0.7。但BERT-LSTM 單純使用LSTM 對句子結構進行粗粒度的整體分析,隨后輸入分類器進行關系類型判斷,沒有考慮到句子中粒度更細的信息,限制了性能的進一步提升。而RBERT 雖然深入考慮了實體詞的特征信息,但并未有效利用文本中實體詞與鄰近詞的潛在聯系,相比之下CCREPMI 模型在深度語義挖掘層提取三個層次關鍵語義信息,關注句子中實體詞本身的含義,并通過捕捉實體對鄰近詞的依賴關系,得到了相對豐富的特征表示,對提高模型的關系抽取效果起了積極作用,達到81.9%的最佳F1 值,由此可見關注實體詞與鄰近詞的依賴關系可以用于改進關系抽取模型的性能。
最后我們注意到,CCREPMI-G 在F1 值上相比標準CCREPMI 低0.4 個百分點,模型性能表現比較接近。筆者認為BiGRU 網絡的特點是參數量較少,計算速度比較有優勢,但BiLSTM相比之下具有更多的門控單元,在本次實驗中表現出了更加強大的特征學習能力。CCREPMI-S移除了Attention層,結果F1 值比標準CCREPMI 低1.3 個百分點,說明Attention機制對句子層次的信息提取具有良好的增益作用。
4.3.3 模型超參數對性能的影響
本文還探索了批次大小(batch-size)、文本最大長度(maxlength)、BiLSTM 層數(BiLSTM-Layer)以及丟棄率(Dropout)等四個模型超參數對性能的影響,結果如圖8所示。
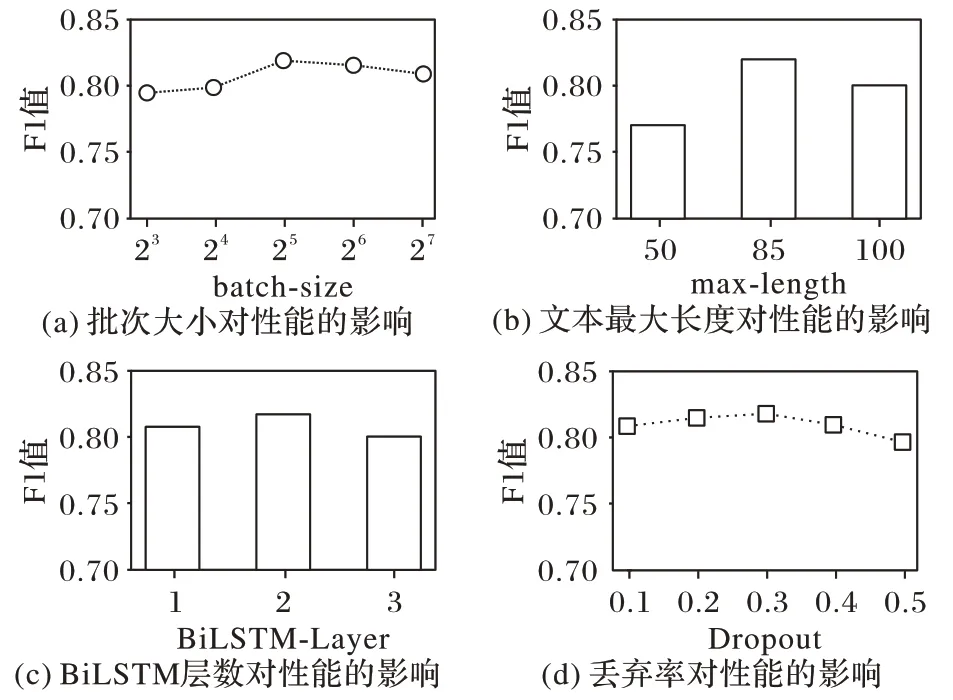
圖8 超參數對模型性能的影響Tab.8 Influence of hyperparameters on model performance
由圖8 可知,批次大小從8 開始依次增加時,模型效果隨之提升,直到大小為32 時模型性能達到最佳,之后可能因陷入局部收斂效果不升反降;文本最大長度設置為85 是最優選擇,因為設置過長需要將大量樣本填充至該值,設置過短則需要將大量樣本截取至該值,均會導致文本語義的丟失;BiLSTM 網絡的層數設置為2 最佳,僅1 層會因為網絡深度不夠,導致特征提取效果不強,而增加網絡深度至3 層可能因梯度消失問題的加劇,引起性能的下降;模型使用丟棄率來防止模型的過擬合現象,可以看出丟棄率為0.3 的時候模型擬合程度較好。
4.3.4 模型泛化能力分析
本文主要針對中文數據集的特點設計模型結構,為了測試CCREPMI 在英文數據集上的泛化能力,采用F1 值作為評價指標,在SemEval2010-task8 數據集上進行實驗測試模型效果。
根據表5可知,CCREPMI在不借助人工特征的條件下,通過預訓練模型和引入多層次信息特征,增強了模型特征學習效果,在英文數據集上與基準模型CNN、MVRNN 和FCM 等對比仍然存在領先的效果,說明CCREPMI在英文語料上具有一定的泛化能力。

表5 不同模型在英文數據集SemEval2010-task8上的實驗結果對比 單位:%Tab.5 Results comparison of different models on English dataset SemEval2010-task8 unit:%
4.3.5 多層次信息的影響
為了分析本文中多層次信息融合結構對模型性能的影響,設計了在CCREPMI多層次信息提取層中移除實體信息提取單元的CCREPMI-NoE 模型和移除實體鄰近層次信息提取單元的CCREPMI-NoEC 模型,以及將超參數鄰近詞窗口c值設置為2,即采用較長實體鄰近詞序列作為輸入的CCREPMILEC 模型等三種變體模型,并將以上模型與標準的CCREPMI-Standard模型進行對比,結果如圖9所示。
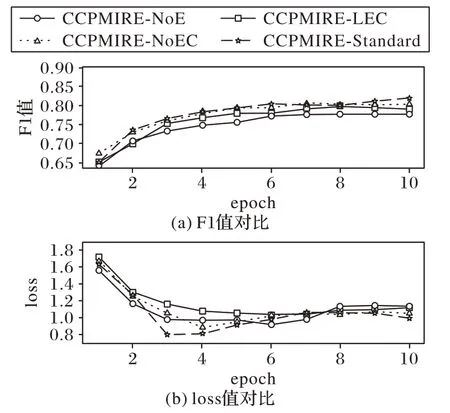
圖9 變體模型對比結果Fig.9 Comparison results of variant models
圖9 是各個變體模型的F1 值和loss 值伴隨著訓練批次的變化情況,可以看出四個模型最后均收斂到恒定值,其中CCREPMI-Standard 在F1 的最高值和loss 的下降情況上都優于不考慮實體層次信息的CCREPMI-NoE 模型及不考慮實體鄰近層次信息的CCREPMI-NoEC 模型,從中可以得出結論:無論是實體層次信息或是實體鄰近層次信息都對模型識別關系的準確程度有益。而模型CCREPMI-LEC 中雖然考慮了實體與鄰近詞的依賴信息,但輸入的實體鄰近詞序列長度較長,造成一些無關的鄰近詞對關系的判斷產生了負面影響,因此該模型的關系抽取效果相對不佳。
5 結語
本文針對中文關系抽取數據集中語法結構復雜的問題,提出了一種使用基于預訓練和多層次信息的中文人物關系抽取模型,該模型先使用BERT 預訓練模型,再結合句子整體結構、實體含義以及實體詞與實體鄰近詞的依賴關系等特征信息進行關系分類。本文在中文人物數據集上對模型進行了實驗,結果表明模型對比基準方法有所提升,并在英文數據集上驗證了模型具有一定泛化能力。本文模型雖然取得了較好的效果,但仍然有一些局限性,使用的特征仍然不夠豐富,未來可能的工作是嘗試引入詞性和依存句法等特征提升模型性能。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
小學教學參考(2015年20期)2016-01-15 08:44:38
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
河南科技(2014年23期)2014-02-27 14:19:15
