基于嵌入式數據挖掘的大學生心理管控分析系統
2022-01-06 12:33:06韋芬
電子設計工程 2021年24期
韋芬
(西安航空職業技術學院,陜西西安 710089)
大學生在個性、學習方式、情商、社會責任感、生活方式等方面有著不同的特征,這些特征可以塑造學生在教育過程中的行為[1-2]。在情緒層面用風險指標識別學生是較為重要的,因為這些因素會影響學生的幸福感和學業成績。因此,預測大學生消極情緒和心理問題已成為當前的一個重要研究課題[3-6]。
數據挖掘是一種數據處理技術[7-8],能將原始數據及時轉換為有用的信息。這些信息代表頻繁的行為,可以預測可能發生的事件,可用于制定具有重大影響的決策。
文獻[9-10]從一個普遍的角度概述了教育中的數據挖掘技術。文獻中提到教育數據挖掘是一個新興的跨學科研究領域,被稱為教育數據挖掘(Education Data Mining,EDM)。其涉及到開發分析任何支持學習或教育的信息系統生成的數據方法,主要尋找滿足數據集的最小支持和最小置信度的關聯規則。其中,Apriori 算法是在關聯規則挖掘技術中使用頻率最高的方法之一,實際利用價值高。但傳統Apriori 算法[11-13]需要在數據集中對事物進行多次搜索,能耗較大,且可能會得出數量較多的候選集,使得運行過程中能耗負擔不斷加重。
該文以心理管理系統中的嵌入式數據挖掘技術為研究對象,闡述了Apriori 挖掘技術在心理數據挖掘系統中的設計與實現過程,討論了影響學生心理健康的因素。基于CM_Apriori 和PM_Apriori 算法[14-16],改進了壓縮矩陣的Apriori 算法,并將改進后的Apriori 作為一個數據挖掘技術嵌入到現有的心理健康管理控制系統中,對包含學生學習心理發展特征的數據進行數據挖掘和特征提取。通過實驗可以證明,利用改進的Apriori 算法能夠方便、迅速地從海量數據庫中挖掘各種信息之間的關系,提供更具價值的結果。
1 系統設計原理
1.1 過程和需求分析
目前,有幾種方法可以分析、轉換和利用結構良好的數據。這些方法被分組在一個稱為KDD(Knowledge Discovery in Databases)的數據庫中,這一過程旨在將低級數據轉換成其他更緊湊、抽象或便于使用的形式。根據數據的性質和應用步驟的不同,過程可能會較為復雜。該過程從獲取數據開始,逐步驗證所獲得的結果(模式),這些步驟和階段將作為該系統設計的指導思想。
1)數據庫建設:在這一過程中最主要的任務之一就是創建數據庫,將盡可能多的有用信息源包含在數據庫中。在這一項目中,其是通過在線調查或儀器測量來獲取學生心理特征。
2)數據預處理:一旦設計了數據庫,就必須選擇用于構建結構的屬性,這些屬性將允許查找可以動態挖掘信息之間的關聯。在這一步,需要了解學生心理特點的專家介入,確定其最具區別性的屬性,以便識別所處理數據特征之間的相關性。
3)數據挖掘:對前一階段選擇的屬性進行轉換,這涉及到眾多數據挖掘技術,如探索性分析技術、聚類技術和模式挖掘技術。這一步涉及到數據挖掘過程的結果,數據挖掘是一個重復迭代的關鍵步驟。發現的信息取決于輸入數據的類型和質量,故必須事先選擇合適的算法。
4)恢復、可視化和驗證:在數據挖掘步驟之后,必須將新的信息呈現給最終用戶或專家進行評估。通常情況下經過算法篩選出來的信息量較大,無法手動分析。因此系統要根據用戶的需要,向專家提供最相關的信息。另一方面,為了理解信息的語義,有必要提供一些工具。讓專家從研究結果中學習、了解學生的心理狀況,以便做出決策。因此,數據挖掘方法與可視化方法相結合,是該文心理管理系統設計中較為重要的一環。
1.2 結構設計
根據已有的資料和文獻,基于數據挖掘的心理管理系統結構如圖1 所示。該文通過數據挖掘模型層來挖掘目標數據集,用戶界面層可以查看數據挖掘分類結果,評價和分析知識挖掘的條件與規則。

圖1 基于數據挖掘的心理管理系統結構
2 改進Apriori算法
Apriori 算法采用的搜索方式主要思想如下:利用頻繁項集1-{L1} 查找頻繁項集2-{L2} 。相似地,利用{L2} 查找{L3},循環查找頻繁項集。為了使算法可以更加精準地挖掘信息,在心理專家提取數據屬性后,在算法搜索空間的壓縮矩陣中加入了Apriori屬性。該算法的基本思想是,首先確定所有的第一組頻率集,且這些頻率被設定為大于或等于預定義的最小支持度。然后,由頻率集生成可以滿足最小系統支持度和最小置信度的強關聯交易規則。一旦這些規則生成完畢,剩余的即為大于用戶給定的最小置信用戶規則。該文使用遞歸分析方法生成了所有的頻率集。
在實際應用中,由于Apriori 算法可能會產生大量的候選項集,且在算法執行時,Apriori 算法對數據庫進行重復操作。當數據量過大時,讀寫操作過多會大幅降低計算效率。CM_Apriori 算法針對多次反復掃描矩陣的缺點作出了改進,而基于布爾矩陣的PM_Apriori 算法通過壓縮和減少候選項集的產生,有效提高了算法的綜合性能。
該文設計了一種基于CM_Apriori 算法和PM_Apriori 算法的Apriori 改進算法。首先,將關聯規則的來源數據庫D劃分為D1,D2,D3,…,Di(i=1,2,3,…,n),這些子數據庫相互獨立。利用Apriori 算法在數據庫中找到強度集Di和Li,縮短了掃描數據庫所需的時間,然后將所有強度集轉化為數據庫D中的潛在強度集。
利用改進的Apriori 算法多線程掃描事務數據庫分割的數據塊,構建1-a 事務集位串和頻繁項集位串。對1-a 邏輯位串進行“與”運算,通過統計結果和給定的支持閾值相比較生成頻繁項集;位串頻繁項集的邏輯“或”運算,統計結果即為事務庫中重復出現候選項集的次數。改進的Apriori 算法具體可以分為以下幾個步驟:
1)定義挖掘規則所需的支持度和置信度閾值。
2)掃描事務庫,依次對庫中的事務項出現在每個事務中的次數進行統計,生成相應的“位串”,事務項出現在事務中被記錄為“1”,不出現則記錄為“0”。統計每個項目的位串可得每個候選項1-項集的支持度計數,根據給定的支持度閾值選取大于或等于支持度閾值的候選項1-項集作為L1 項集的頻繁項集。
3)根據支持度遞增的順序對L1排序,得到序列S。
4)從L1的所有項中生成候選項集合C2。
5)將Ck位串中的所有項進行邏輯“與”運算,生成新位串中的個數為“1”的統計量。統計結果是新生成的支持數滿足候選項集的最小支持閾的項集,同時生成Lk的頻繁項集。根據序列S的二進制碼,Lk中的每一項生成一個位串,形成一個包含 ||Lk個位串的位集。使用兩個邏輯“或”操作執行一個集合中的位字符串,并計算操作結果。運算結果中“1”的個數為k+1,重復次數為C,生成候選項(k+1)項集,按序列S生成候選項(k+1)。
6)循環執行,直到滿足結束條件,最終結束算法。
3 基于數據挖掘的心理數據管理系統
3.1 設計流程
基于眾多科研成果與相關文獻,設計了心理數據挖掘系統的基本框架和功能模塊,并完善評價系統與數據庫。心理數據挖掘是一個迭代的過程,需要有效的工具和高效率的算法,系統數據挖掘的流程設計如圖2 所示。
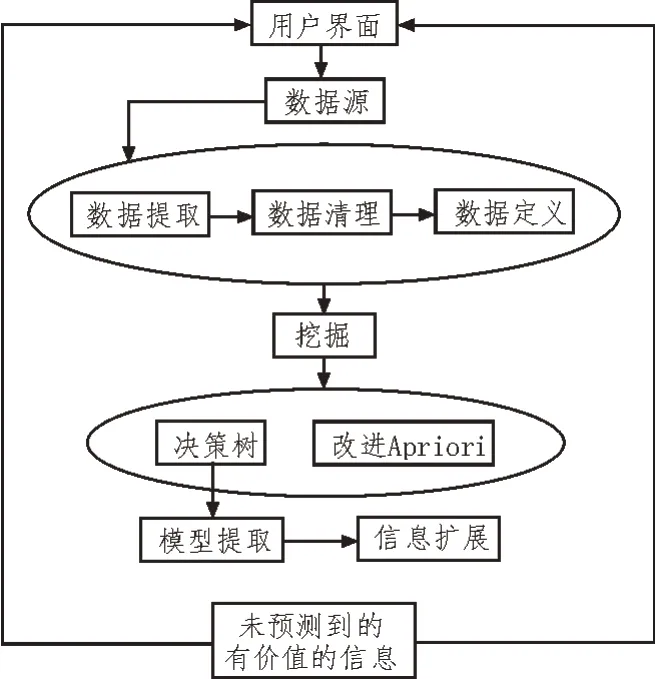
圖2 心理問題數據挖掘系統的流程
3.2 數據處理
通過采用SCL-90 癥狀自評量表(SCL-90)計算得到抑郁(yy)、焦慮(jl)、敵對(dd)、恐怖(kb)、偏執(pz)和精神病(js)等9 個心理因素癥狀。個人心理問題數據表的定義如表1 所示。根據離散化數據的分類規則,將心理癥狀因子和個體基本信息因子分為結合編碼屬性和心理分析等幾個項目。將預處理后的3 000 個原始數據輸出到Excel 中,基于改進的Apriori 算法、布爾矩陣以及建立的大學生心理相關分析模型,進行關聯規則挖掘。

表1 預處理后的部分數據
3.3 關聯規則的挖掘過程
在關聯規則挖掘過程中,可以方便地根據Excel數據的需要在某些列中進行選擇,其是一種有效的數據挖掘方法,避免了使用JExcelAPI 來達到數據選擇的目的。通過使用改進的Apriori 關聯規則挖掘算法來發現9 個心理癥狀之間的隱藏關系,其部分結果如表2 所示。
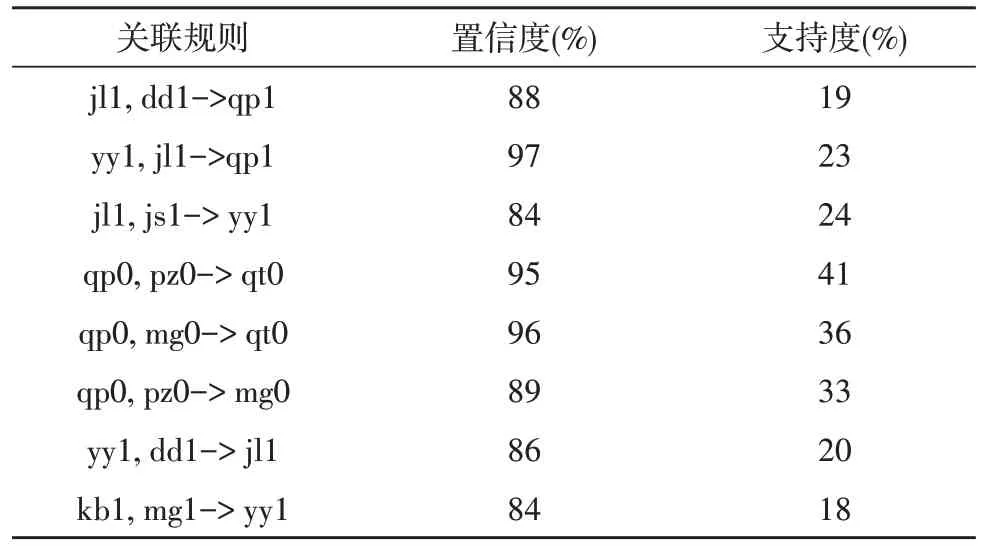
表2 9個心理癥狀因子之間的部分關聯規則
4 實驗結果
根據價值關聯規則和設置不同的參數交易數量,對比測試案例不同數量的事務數據庫。實驗研究所需的原始信息數據由IBM 數據生成器產生,算法的性能通過系統運行工作時間來衡量。不同算法的性能測試結果如表3 和圖3 所示。
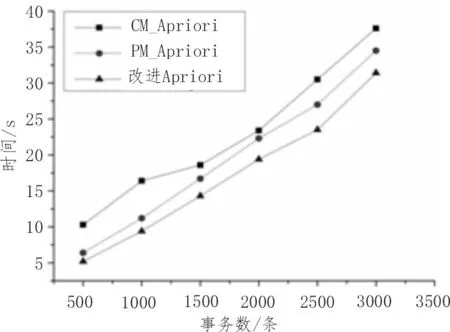
圖3 不同算法下的實驗性能對比
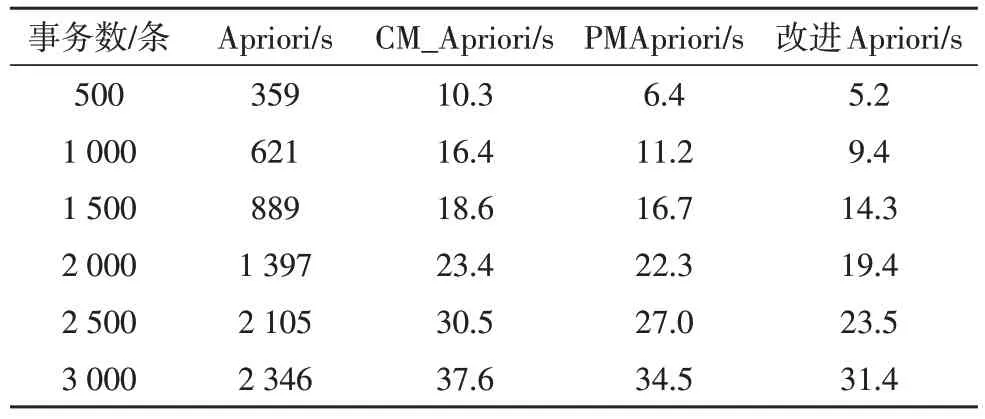
表3 運行時間結果統計
改進Apriori 方法來進一步壓縮矩陣,縮小算法的時間和空間消耗。其使用了多線程進行從事務集到布爾矩陣的轉化過程,并行操作與排序帶來的優勢能夠幫助多事務數的處理。相比于PM_Apriori 算法,改進Apriori 算法的運行時間明顯縮短,運行效率提高了約8.9%~18.7%。
5 結束語
數據挖掘技術在學生心理管理系統中的應用,是現代大學生心理健康教育發展的成果。該文在嵌入式模塊開發期間,結合實際情況進行了相應的驗證。采用SCL-90 心理測量表和UPI 人格測驗項目成績表對大學生進行心理調查,以學生的基本情況,作為訓練集輸入。以高校學生的相關信息作為訓練數據,構建相應的屬性決策樹。根據對常用數據挖掘技術Apriori 的性能分析,提出了改進的Apriori 算法并通過實驗進行改進效果的檢驗。最終,將改進Apriori 數據挖掘技術嵌入到學生心理管理系統中。結果表明,改進Apriori 算法作為數據挖掘技術能夠減少系統運行時間,提高數據挖掘效率。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
大眾投資指南(2021年35期)2021-02-16 01:06:26
學苑創造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
電力與能源(2017年6期)2017-05-14 06:19:37
讀者(2017年5期)2017-02-15 18:04:18
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
信息通信技術(2015年6期)2015-12-26 01:16:46
