一種面向散亂點云語義分割的深度殘差-特征金字塔網(wǎng)絡框架
2022-01-13 13:34:22彭秀平仝其勝林洪彬
自動化學報 2021年12期
彭秀平 仝其勝 林洪彬 馮 超 鄭 武
三維點云數(shù)據(jù)理解在計算機視覺和模式識別領域是一項非常重要的任務,該任務包括物體分類,目標檢測和語義分割等.其中,語義分割任務最具有挑戰(zhàn)性,傳統(tǒng)的方法大多是在對點云數(shù)據(jù)進行必要特征提取的基礎上,應用支持向量機(Support vector machine,SVM)一類的分類算法,通過訓練一組特征分類器來完成散亂點云數(shù)據(jù)的語義分割任務[1].顯然,這類方法的性能很大程度上依賴點云特征的設計、特征提取的精度以及特征分類器的性能.雖然國內外學者提出了幾十種點云特征和大量的分類算法,但是依然沒有一種或幾種特征能完全適用于所有語義分割場景,算法適用性、精度和可靠性都得不到保障.
近年來,隨著深度學習技術的發(fā)展,涌現(xiàn)出許多端對端的學習算法,這種端對端的學習方式不依賴于手工設計的特征,只需給定輸入數(shù)據(jù)和對應的數(shù)據(jù)標簽,將其輸入神經(jīng)網(wǎng)絡,即可通過反向傳播算法自動學習一組可以抽象高級特征的權重矩陣,最后再由全連接層(Fully connected layer,FC)對高級特征進行分類,從而完成分割任務.現(xiàn)有的基于深度學習的點云分割研究方法大體可分為如下兩類:
一類是基于散亂點云數(shù)據(jù)結構規(guī)則化的深度學習方法,這類方法通常是先通過體素化處理或八叉樹、KD 樹等樹形結構,將無序和不規(guī)則的散亂點云處理成規(guī)則的結構化數(shù)據(jù),再將結構化數(shù)據(jù)輸入三維卷積神經(jīng)網(wǎng)絡(Convolutional neural network,CNN)進行訓練.基于體素化方法[2-3]的提出首次將深度學習技術應用于三維點云數(shù)據(jù)理解任務,通過將三維點云體素化為規(guī)則的結構化數(shù)據(jù),解決了其無序性和不規(guī)則性問題.但是,使用體素占用表示三維點云帶來了量化誤差問題,為了減小這種誤差必須使用更高的體素分辨率表示,高分辨率的體素表示又會在訓練神經(jīng)網(wǎng)絡過程中帶來大內存占用問題.因此,受限于目前計算機硬件的發(fā)展水平,基于體素化的散亂點云深度學習方法往往難以完成諸如大規(guī)模室內三維場景一類的復雜、需要細粒度的三維場景的語義分割和場景理解任務.基于八叉樹[4-5]和KD樹[6]結構方法的提出解決了直接體素化點云所帶來的大內存占用問題,但是這種樹形結構對三維點云旋轉和噪聲敏感,從而導致卷積內核的可訓練權重矩陣學習困難,算法的魯棒性往往不夠理想.
另一類是基于參數(shù)化卷積設計的深度學習方法,這類方法以原始三維點云作為輸入,通過設計一種能夠有效抽象高層次特征的參數(shù)化卷積,再使用堆疊卷積架構來完成點云分割任務.PointNet[7]是這類方法的代表,其首先使用共享參數(shù)的多層感知機(Multi-layer perception,MLP)將三維點云坐標映射到高維空間,再通過全局最大池化(Global max pooling,GMP)得到點云全局特征,解決了點云的無序性問題;此外,文獻[7]還提出了一種Tnet 網(wǎng)絡,通過學習采樣點變換矩陣和特征變換矩陣解決了散亂點云的旋轉一致性問題,但是由于缺乏點云局部特征信息局限了其在點云分割任務中的性能.隨后PointNet++[8]提出一種分層網(wǎng)絡,通過在每一圖層遞歸使用采樣、分組、PointNet 網(wǎng)絡來抽象低層次特征和高層次特征,再經(jīng)過特征反向傳播得到融合特征,最終使用全連接層預測點語義標簽,解決了文獻[7]方法對點云局部特征信息提取不足的問題.RSNet[9]通過將無序點云特征映射為有序點云特征,再結合循環(huán)神經(jīng)網(wǎng)絡(Recurrent neural network,RNN)來提取更豐富的語義信息,從而進行語義標簽預測.PointCNN[10]則定義了一種卷積,通過學習特征變換矩陣將無序點云特征變換成潛在的有序特征,再使用堆疊卷積架構來完成點云分割任務.
總體而言,基于參數(shù)化卷積設計的深度學習為散亂三維點云場景的理解提供了具有廣闊前景的新方案.然而,目前該領域的研究尚處于萌芽階段,許多切實問題尚待解決,如:由于卷積方式的局限性,用于二維圖像處理的主流深度神經(jīng)網(wǎng)絡構架(如:UNet[11],ResNet[12],Inception V2/V3[13],DenseNet[14]
等)無法直接用于三維散亂點云數(shù)據(jù)的處理;由于針對點云特征提取設計的參數(shù)化卷積的局限性,現(xiàn)有的方法普遍存在特征抽象能力不足、無法將用于二維圖像處理的一些主流神經(jīng)網(wǎng)絡框架適用于三維點云分割任務等問題.
基于此,本文設計了一種立方體卷積運算,不僅可以通過二維卷積實現(xiàn)三維表示點的高層特征的抽取,還可以解決當前參數(shù)化卷積設計通用性差的問題;其次,將定義的立方體卷積計算和殘差網(wǎng)絡相結合,構建面向散亂點云語義分割的深度殘差特征學習網(wǎng)絡框架;進一步,將深度殘差網(wǎng)絡與特征金字塔網(wǎng)絡相結合,以實現(xiàn)三維表示點高層特征多尺度學習和語義分割.
1 提出的方法
本文方法以原始三維點云作為輸入,首先,將定義的立方體卷積運算和殘差網(wǎng)絡(ResNet)相結合,構建面向散亂點云語義分割的深度殘差特征學習網(wǎng)絡框架;其次,將深度殘差網(wǎng)絡與特征金字塔網(wǎng)絡(Feature pyramid network,FPN)[15]相結合,以實現(xiàn)三維表示點高層特征多尺度學習;最后,通過全連接層對融合特征進行分類得到語義標簽輸出,整體分割網(wǎng)絡框架如圖1 所示.
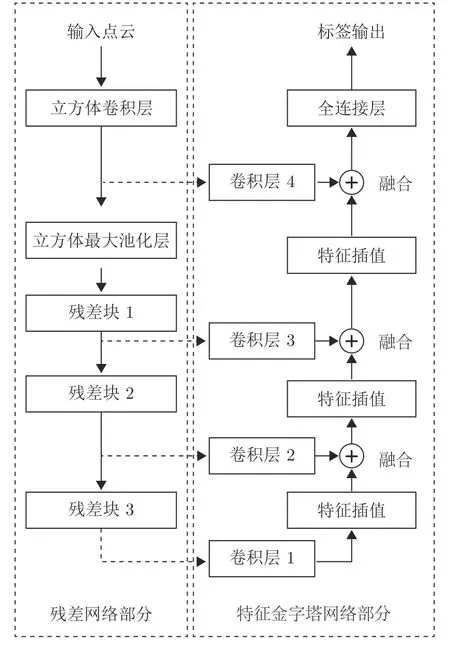
圖1 深度殘差-特征金字塔網(wǎng)絡框架Fig.1 Depth residual-feature pyramid network framework
1.1 立方體卷積
殘差網(wǎng)絡自2015 年提出以來,一經(jīng)出世,便在ImageNet 競賽中斬獲圖像分類、檢測、定位三項的冠軍.隨后許多基于殘差網(wǎng)絡的研究在圖像分割領域也取得了巨大的成功[16-20].然而,殘差網(wǎng)絡是專門為二維圖像類的規(guī)則化數(shù)據(jù)設計的深度網(wǎng)格結構,在處理類似散亂三維點云等非規(guī)則、無序化散亂數(shù)據(jù)時遇到困難;另一方面,現(xiàn)有的基于深度學習的用于點云特征提取的參數(shù)化卷積設計普遍存在卷積計算通用性差、無法拓展至現(xiàn)有二維圖像處理的深度學習框架的問題.為此,本文在深入研究現(xiàn)有二維圖像卷積計算的基礎上,基于局部點云結構規(guī)則化思想,提出一種新的適用于散亂三維點云的立方體卷積計算模型,旨在通過二維卷積運算實現(xiàn)散亂三維點云數(shù)據(jù)高層次特征的抽象;同時,該立方體卷積計算模型具有良好網(wǎng)絡框架適用能力,使現(xiàn)有大多數(shù)二維圖像處理深度神經(jīng)網(wǎng)絡可用于散亂三維點云分割中.
本文提出的立方體卷積計算模型設計思路如下:
考慮一幅二維圖像,集合表示為S={sx,y∈R3|x=0,1,2,···,h;y=0,1,2,···,w}.對于任意像素點sx,y(1≤x ≤h-1;1≤y ≤w-1),當大小為3×3的卷積核作用于該點時,將其局部感受野表示為集合Nx,y={sa,b∈R3|a=x-1,x,x+1;b=y-1,y,y+1},將學習權重矩陣表示為
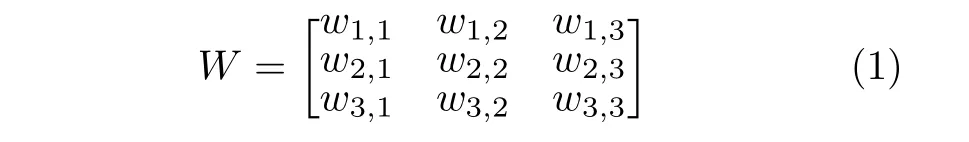
其中,w∈R3.在二維圖像分割任務中,卷積神經(jīng)網(wǎng)絡可通過端對端的方式學習得到權重矩陣W,實現(xiàn)圖像高層次特征抽取,其最重要的原因之一在于:在固定視角下,感受野所包圍的像素點是關于給定表示像素點的歐氏距離鄰近點,且權重值和像素點具有位置對應關系,如圖2 所示.然而,由于散亂三維點云具有無序性和不規(guī)則性,同一點云模型可用多種不同的集合表示,當直接把二維卷積神經(jīng)網(wǎng)絡應用到三維點云上時,并不能保證感受野所包含的點與表示點是這種歐氏距離鄰近關系,也無法保證權重值和點是位置對應的.
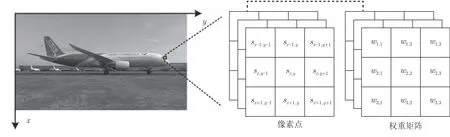
圖2 二維卷積Fig.2 The 2D convolution
為此,基于局部點云結構規(guī)則化的思想,本文提出一種適用于三維點云特征提取的立方體卷積運算,具體過程描述如下:設三維點云表示為集合P={pi∈R3|i=0,1,2,···,n-1},n為點的個數(shù),其對應的特征集合為F={fi∈Rc|i=0,1,2,···,n-1},c為點的特征維度.對于表示點pi,定義一個邊長為s的立方體.以pi中心,將立方體按網(wǎng)格劃分為27 個子立方體,每個子立方體以固定順序進行索引,如圖3 所示.
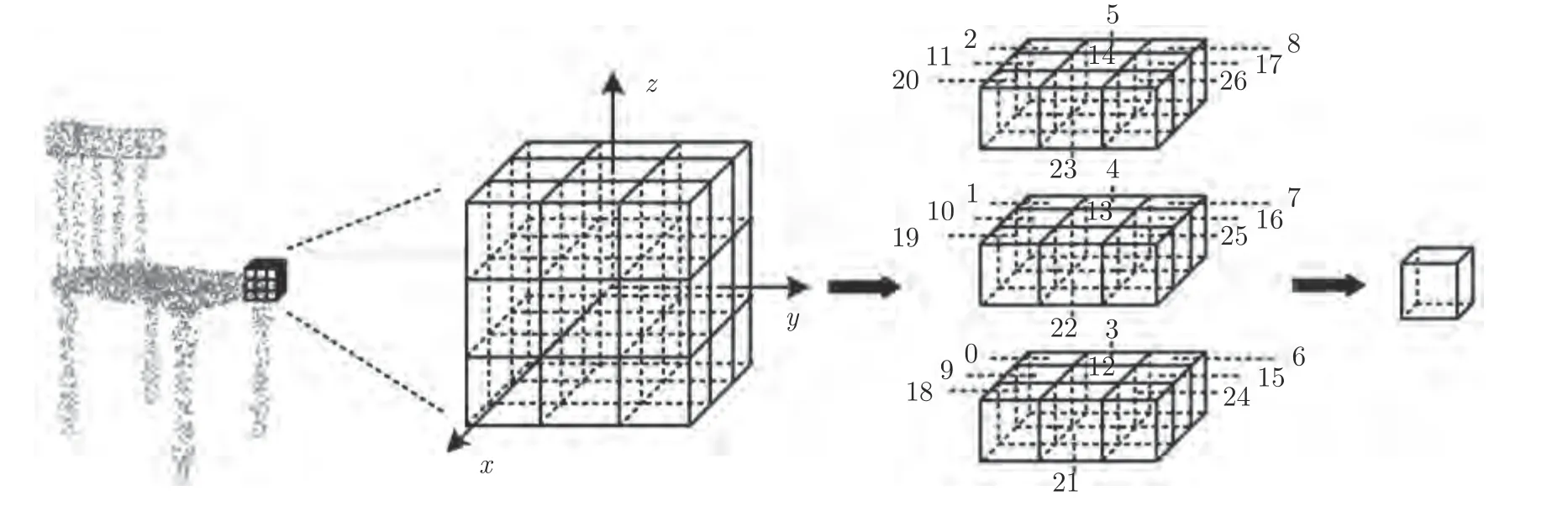
圖3 立方體卷積Fig.3 The cube convolution
首先,定義點云局部特征集合V={vi∈R27×c|i=0,1,2,···,n-1},其中,vi={vi,j∈Rc|j=0,1,2,···,26}.對于第j個子立方體,選取離子立方體中心歐氏距離最近的一個點作為表示點pi的一個鄰近點,vi,j設置為該鄰近點的特征.當集合F等于P(即輸入點云的特征為其三維坐標)時,vi,j設置為該鄰近點相對表示點的相對坐標值,如果子立方體內沒有點,則設置為 0.遍歷所有表示點得到特征集合V,然后,再通過二維卷積對特征集合V進行卷積來抽象輸入三維點云的高層特征.那么卷積輸出即可表示為:F′=Conv(V,1×27,c′),其中V為卷積輸入,1×27 為卷積核和移動步長大小,c′為輸出特征通道數(shù).對于表示點的鄰近點選取,另一可行方案是:首先計算子立方體內包圍點到其中心的距離,再對包圍點的特征進行反距離加權平均得到的值,但是隨著網(wǎng)絡層數(shù)的加深以及特征維度的升高將會帶來計算量的大幅增加.因此,為平衡性能本文選取距離子立方體中心最近的一個點作為表示點的一個鄰近點這一近似方案.
本文提出的立方體卷積運算主要有兩個關鍵點:立方體網(wǎng)格劃分和子立方體固定索引排序.我們給出分析如下:在二維圖像理解領域中,許多主流網(wǎng)絡框架(如U-Net[11]、ResNet[12]、Inception V2/V3[13]和DenseNet[14]等)都是采用大小為3×3的卷積核來提取特征.文獻 [13] 中指出大卷積核可以通過小卷積核的疊加獲得相同大小的感受野,并且小卷積核的疊加引入了二次非線性,其實驗結果證明了精確率會得到提升.其次,相比大卷積核,小卷積核具有更小的參數(shù)量.鑒于此,本文采用將空間劃分為網(wǎng)格的方式來感知表示點的局部三維空間結構,從而可以以較小的參數(shù)量獲得較高的精確率;另外,由于三維點云具有無序性,直接使用二維卷積進行卷積運算會導致神經(jīng)網(wǎng)絡在訓練過程中無法學習到有效的權重矩陣來抽象高層特征.因此,本文也是基于常用于二維圖像理解任務中的二維卷積特點,通過將子立方體以固定索引進行排序的方式來保證在固定坐標系下二維卷積核的可學習權重矩陣和無序點云有一一對應的關系,以此通過二維卷積有效地抽象三維點云的高層特征,使得用于二維圖像處理的主流神經(jīng)網(wǎng)絡框架可以適用于三維點云理解任務中.
1.2 立方體最大池化
在二維圖像中,最大池化是對鄰域內特征點取最大值運算,可以學習某種不變性(旋轉、平移、尺度縮放等).為了使殘差網(wǎng)絡完全適用于三維點云分割任務從而可以學習三維點云的旋轉、平移、尺度縮放不變等特性,本文提出一種基于局部點云結構規(guī)則化思想的立方體最大池化方法,具體過程描述如下:
給定三維點云集合P={pi∈R3|i=0,1,2,···,n-1},n為點的個數(shù),以及對應的特征集合F={fi∈Rc|i=0,1,2,···,n-1},c為點的特征維度.首先用文獻[7]中迭代最遠點采樣算法得到采樣點集合P′=R3| l=0,1,2,···,m-1},m為采樣點的個數(shù),定義點云局部特征集合V={vl∈R27×c|l=0,1,2,···,m-1},其中vl={vl,j∈Rc|j=0,1,2,···,26}.對于采樣點,使用本文提出的立方體卷積運算中鄰近點搜索方法在P中搜索其鄰近點,得到鄰近點特征集合vl.遍歷所有采樣點得到特征集合V.然后,再通過二維最大池化對特征V進行最大池化處理.最大池化輸出即可表示為F′=max(V,1×27),其中,V為最大池化輸入,1×27為卷積核和移動步長大小.
與本文提出的立方體卷積運算相似,立方體最大池化的關鍵點也在于 3×3×3 網(wǎng)格劃分,所獲取的鄰近點對表示點的局部點云幾何結構表示完整性將直接影響最大池化的輸出.因此,我們同樣基于局部點云結構規(guī)則化的思想,通過將局部空間劃分為網(wǎng)格來獲取表示點更加合理的鄰近點,以此再通過常用于二維圖像處理的最大池化操作對輸入特征進行最大池化處理.
1.3 三維點云特征殘差學習結構
殘差網(wǎng)絡由文獻[12]提出,其核心思想是一種特殊的殘差結構.這種結構通過將神經(jīng)網(wǎng)絡中特征映射近似問題轉化為殘差學習問題,不僅解決了隨著神經(jīng)網(wǎng)絡層數(shù)的加深出現(xiàn)的梯度退化問題,而且能夠以更少的模型參數(shù)實現(xiàn)更高的準確率.為了將這種結構適用于三維點云分割任務,本文提出一種三維點云特征殘差學習結構,如圖4 所示.
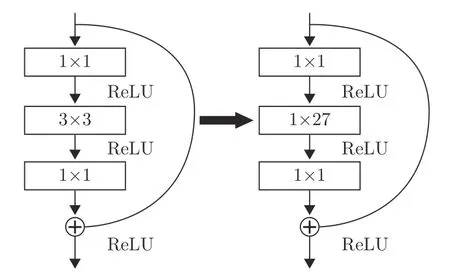
圖4 三維點云特征殘差學習結構Fig.4 The residual learning structure for 3D point cloud feature
本文提出的三維點云特征殘差學習結構和文獻[12]提出的殘差結構都由三層卷積和一次跳躍連接組成,第1 層和第3 層同為卷積核大小為1×1的二維卷積.不同之處在于:對于二維圖像,當輸入輸出維度不匹配時,文獻[12]通過第1 層卷積核大小為 1×1、移動步長為 2×2 的卷積層進行下采樣.針對三維點云,我們則先使用文獻[7]中迭代最遠點采樣算法進行下采樣,再通過卷積核大小為1×1、移動步長為 1×1 的卷積層進行卷積;另外,在文獻[12]中第2 層為卷積核大小為 3×3、移動步長為 1×1 的卷積層,我們將其替換為本文提出的立方體卷積運算層.
1.4 三維點云特征金字塔網(wǎng)絡
在文獻[19]中,特征金字塔網(wǎng)絡的組成結構是首先使用最鄰近上采樣法把高層特征做2 倍上采樣,然后與對應的前一層特征相加融合.考慮到特征金字塔網(wǎng)絡是為具有規(guī)則像素網(wǎng)格結構排列的二維圖像設計的,而三維點云數(shù)據(jù)具有不規(guī)則性,當表示點的局部點云分布密度不均時,最鄰近點的特征并不能夠準確近似表示點的特征.因此,我們采用文獻[8]中的基于K 鄰近的反距離加權插值法進行特征上采樣,如圖5 所示.反距離加權插值可表示為
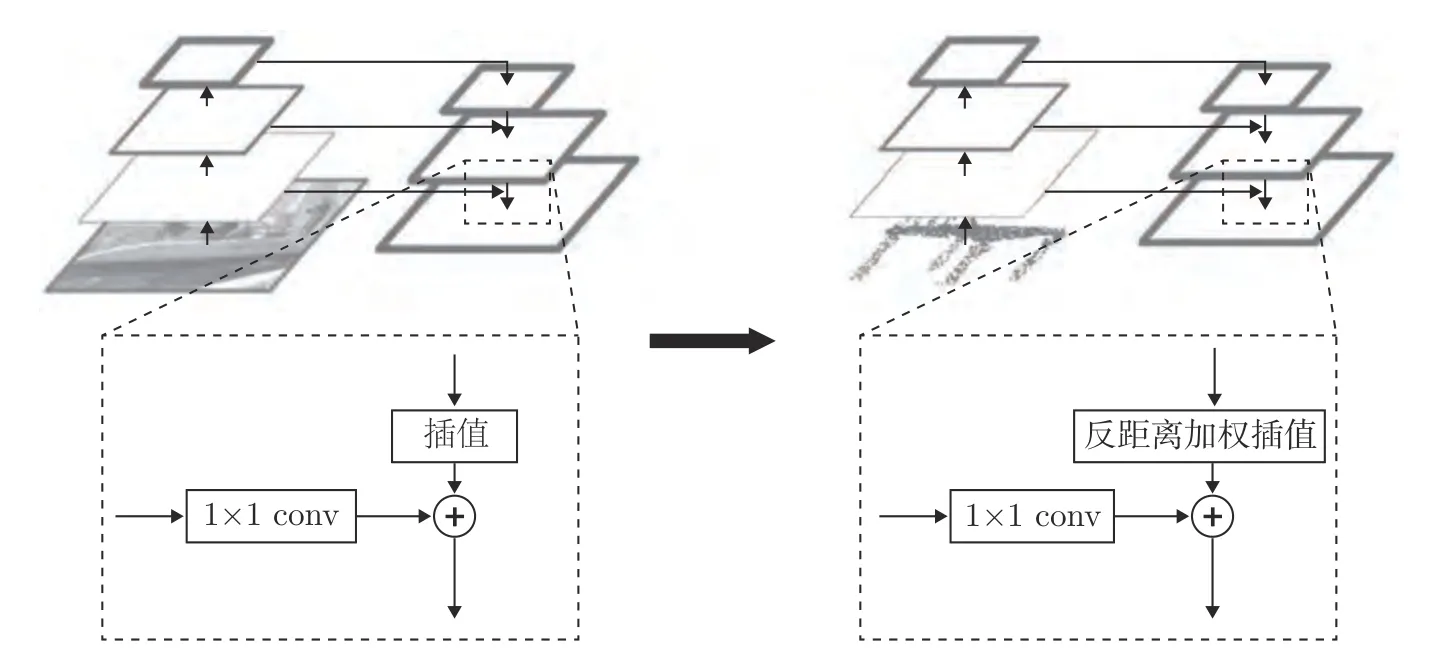
圖5 三維點云特征金字塔網(wǎng)絡Fig.5 The feature pyramid network for 3D point cloud
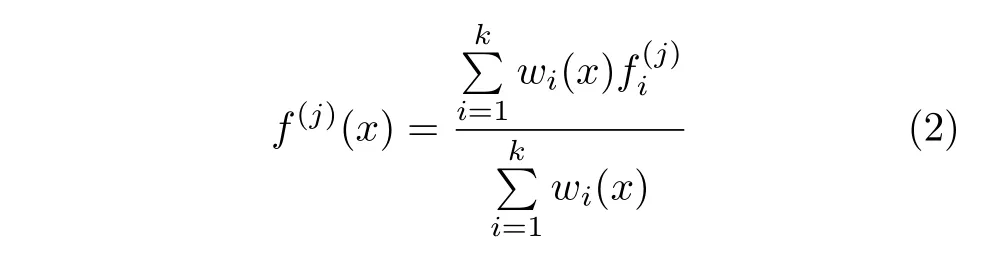
2 實驗結果與分析
本文實驗環(huán)境為Intel(R)Core(TM)i7-7800X CPU @ 3.50 GHz,16 GB×4 內存,NVIDIA GTX 1080Ti×2 GPU,系統(tǒng)為Ubuntu 16.04.
2.1 實驗數(shù)據(jù)集
實驗數(shù)據(jù)集為S3DIS 數(shù)據(jù)集[21]和ScanNet 數(shù)據(jù)集[22].
S3DIS 數(shù)據(jù)集總共包含271 個由Matterport 掃描儀從真實室內場景掃描得到的場景數(shù)據(jù),包含在6 個文件夾中.本文采用與S3DIS 官方相同的K 折交叉驗證策略進行數(shù)據(jù)集劃分.采用與文獻[10]相同的訓練方法,將原始場景沿著x軸和y軸分成大小為1.5 m×1.5 m 的小塊,使用點的位置和顏色信息用于訓練和測試,并在訓練期間將塊點云沿Z軸隨機旋轉一定角度進行數(shù)據(jù)增強處理.
ScanNet 數(shù)據(jù)集總共包含1 513 個從真實室內環(huán)境掃描并重建得到的場景數(shù)據(jù).本文按照Scan-Net 官方劃分標準將數(shù)據(jù)集分為訓練集和測試集兩部分.采用和S3DIS 數(shù)據(jù)集相同的訓練方法.另外,由于其他方法沒有使用顏色信息用于訓練,因此,為了公平比較,本文也不使用顏色信息.
2.2 參數(shù)設計
為了驗證本文提出的立方體卷積運算的有效性和本文方法的可行性,我們基于文獻[19]提出的用于二維圖像分割的殘差網(wǎng)絡-特征金字塔網(wǎng)絡結合本文提出的立方體卷積運算構建一種面向散亂點云語義分割的殘差網(wǎng)絡-特征金字塔網(wǎng)絡框架(下文中以ResNet-FPN_C 表示),網(wǎng)絡結構參數(shù)設計如表1 所示.所有程序由開源框架TensorFlow 及其Python 接口實現(xiàn),采用ADAM (Adaptive moment estimation)方法進行訓練.
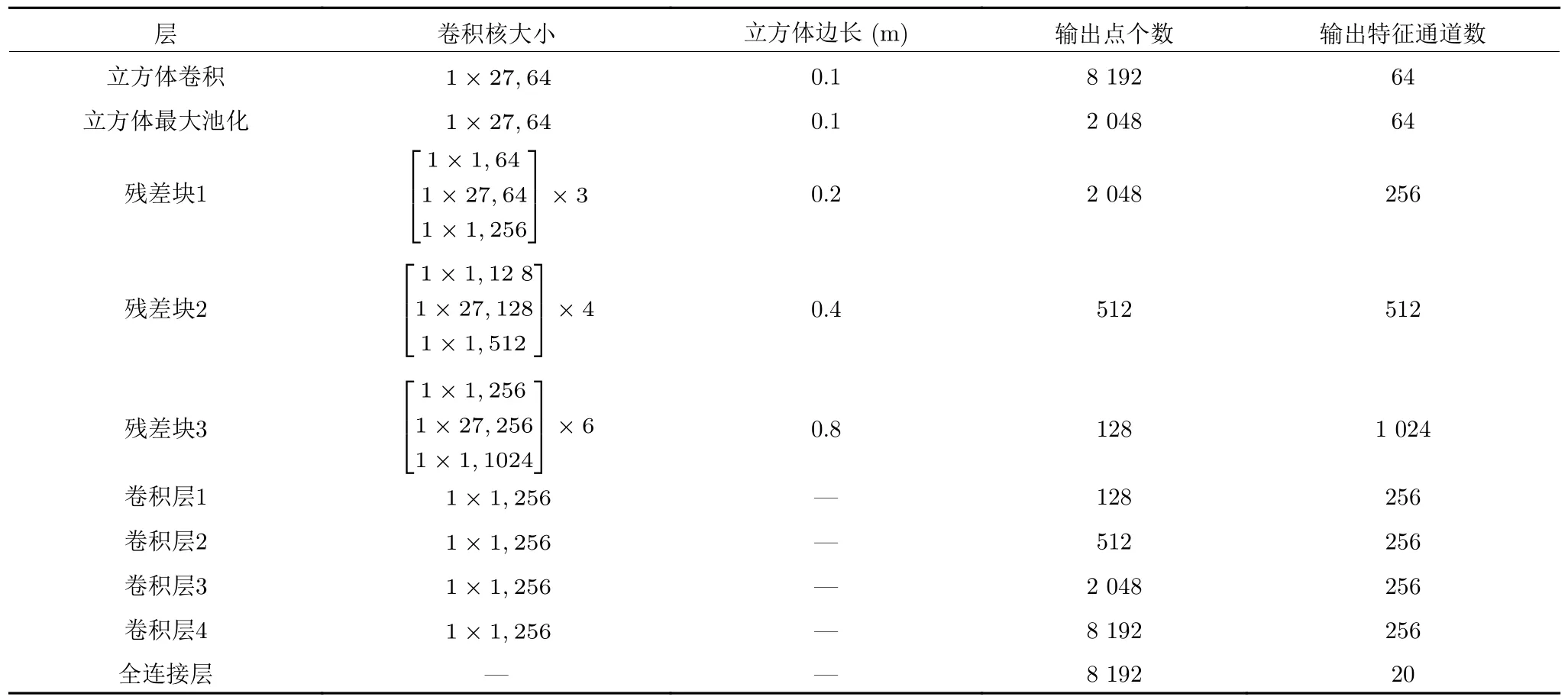
表1 參數(shù)設計Table 1 The parameter design
2.3 評價指標
本文采用總體精確率(oAcc)、類別平均精確率(mAcc)和類別平均交并比(mIoU)評價指標對試驗結果進行評估,并與其他方法進行對比.假設共有k個類別,定義pii表示類別i的預測標簽等于真實標簽的個數(shù),pij表示類別i的標簽預測為類別j的個數(shù).則oAcc可表示為
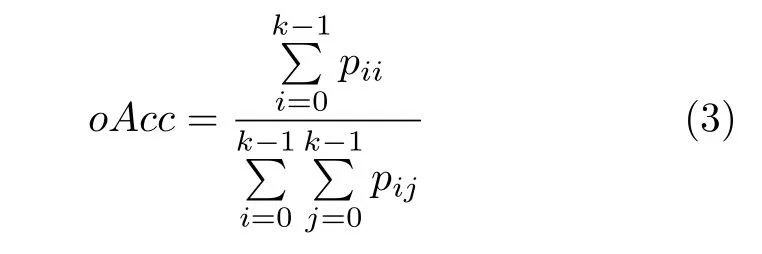
mAcc表示為

mIoU表示為
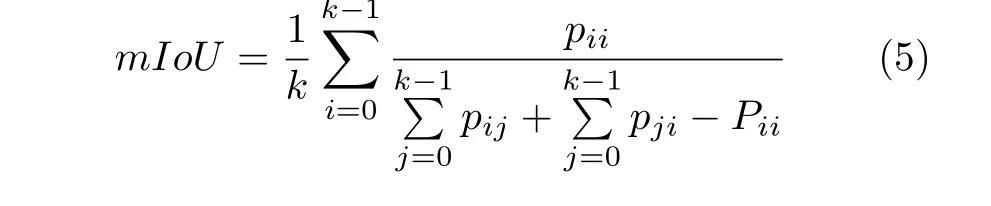
另外,由于ScanNet[22]提供的全卷積神經(jīng)網(wǎng)絡基線方法以體素化數(shù)據(jù)作為輸入,其預測標簽是基于體素統(tǒng)計的,因此我們采用與文獻[8]相同的方法將點預測標簽轉化為體素預測標簽來統(tǒng)計預測結果的oAcc、mAcc和mIoU指標.
2.4 實驗結果分析
為驗證本文方法的有效性,我們在S3DIS 數(shù)據(jù)集和ScanNet 數(shù)據(jù)集上進行了測試.同時,為進一步證明本文提出的立方體卷積運算的通用性,我們基于文獻[11]提出的用于醫(yī)學圖像分割的U-Net網(wǎng)絡搭建了適用于三維點云語義分割的U-Net網(wǎng)絡框架(下文中以U-Net_C 表示).
我們統(tǒng)計了在S3DIS 數(shù)據(jù)集上的6 折交叉驗證結果,如表2 所示,本文ResNet-FPN_C 方法和U-Net_C 方法在oAcc、mAcc和mIoU評價指標上均優(yōu)于其他方法.各類別IoU統(tǒng)計結果如表3所示,其中,本文ResNet-FPN_C 方法有7 個優(yōu)于其他方法,U-Net_C 方法有8 個優(yōu)于其他方法.

表2 S3DIS 數(shù)據(jù)集分割結果比較 (%)Table 2 Segmentation result comparisons on the S3DIS dataset (%)
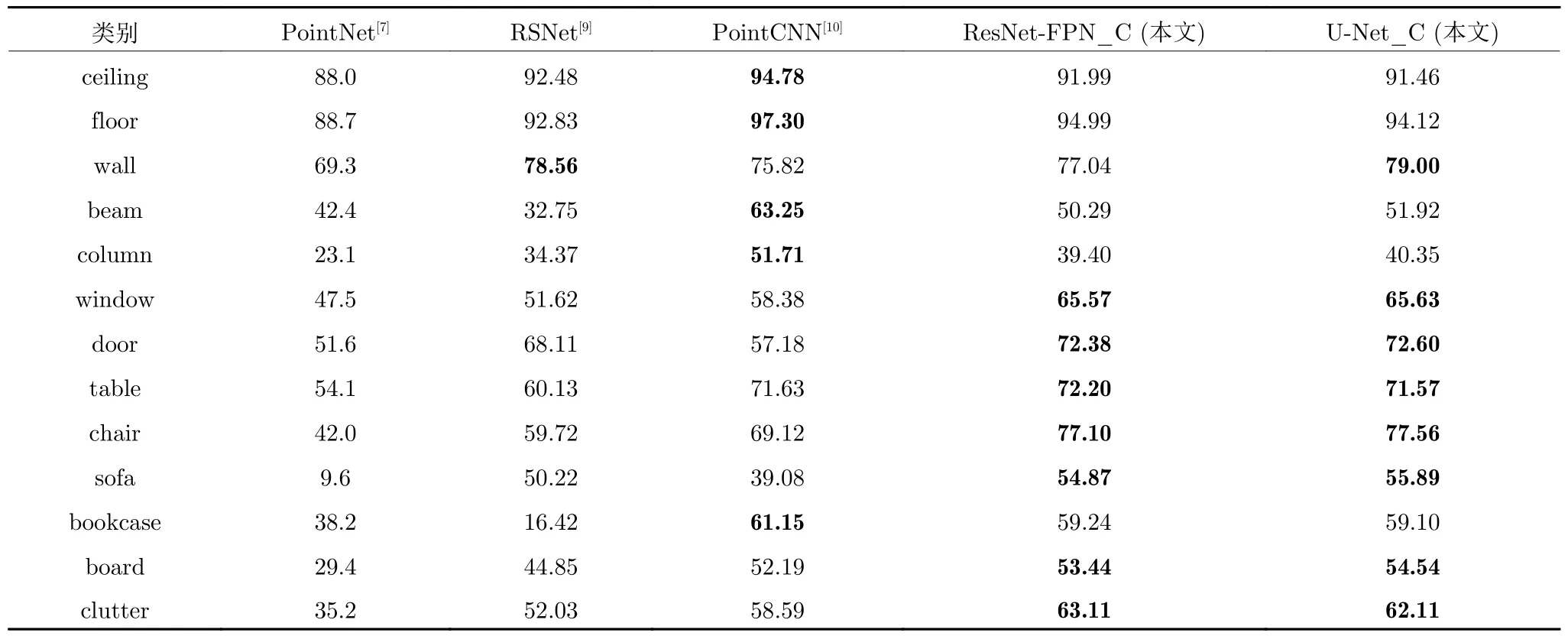
表3 S3DIS 數(shù)據(jù)集各類別IoU分割結果比較 (%)Table 3 Comparison ofIoUfor all categories on the S3DIS dataset (%)
另外,我們在ScanNet 數(shù)據(jù)集上也進行了測試,結果如表4 所示,從中可以看出,本文ResNet-FPN_C 方法和U-Net_C 方法在oAcc、mAcc和mIoU評價指標上均優(yōu)于其他方法.各類別的IoU統(tǒng)計結果如表5 所示,其中,本文ResNet-FPN_C方法有8 個優(yōu)于其他方法,U-Net_C 方法有10 個優(yōu)于其他方法.

表4 ScanNet 數(shù)據(jù)集分割結果比較 (%)Table 4 Segmentation result comparisons on the ScanNet dataset (%)
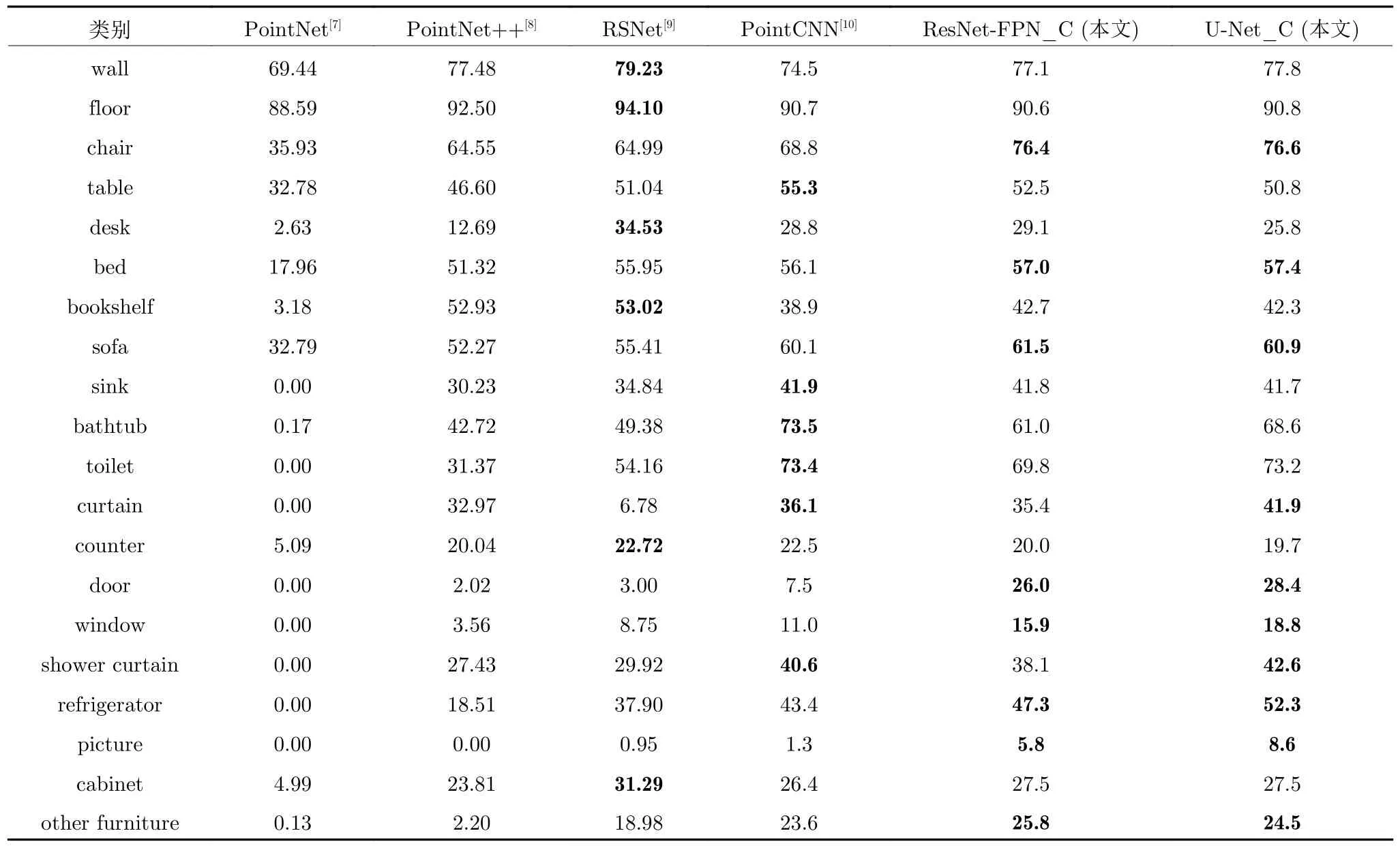
表5 ScanNet 數(shù)據(jù)集各類別IoU分割結果比較 (%)Table 5 Comparison ofIoUfor all categories on the ScanNet dataset (%)
由于ScanNet 數(shù)據(jù)集是由便攜設備從真實室內場景掃描重建得到的,其重建場景中存在大量缺失、未標注、雜亂信息,且相比S3DIS 數(shù)據(jù)集包含更多標注類別,因此其語義分割任務更具挑戰(zhàn)性.從S3DIS 數(shù)據(jù)集和ScanNet 數(shù)據(jù)集測試結果可以看出,本文方法相比其他方法在難以識別的小物體(如picture)和復雜結構物體(如chair、sofa)類別上具有更好的分割性能.值得注意的是door 和window 這兩種類別,它們在空間位置和幾何結構上和wall 很相近,相比于其他類別這兩種類別的分割難度更大,而本文方法較其他方法有較大的分割精度提升.我們分析如下:PointCNN 方法采用的是基于KNN (K-nearest neighbor)的鄰近點搜索算法,由于這種算法對點云分布密度比較敏感,當點云分布密度不均時,所獲取的鄰近點可能全部來自表示點的同一個方向,此時鄰近點不能準確反映表示點的局部特征,且由于其卷積設計的局限性對局部空間幾何結構的微小變化也不夠敏感;Point-Net++提出的MSG (Muti-scale grouping)和MRG (Muti-resolution grouping)方法雖然能夠更加合理地獲取鄰近點,但是由于采用的是Point-Net 中共享參數(shù)的多層感知機結合全局最大池化的特征提取方法,而全局最大池化會丟失信息.因此,同樣不能準確抽象表示點的高層特征;RSNet 則是先將點云數(shù)據(jù)分別沿著x,y,z方向進行切片,再將切片后的點云所對應的特征輸入循環(huán)神經(jīng)網(wǎng)絡提取特征.其試驗結果表明這種方法對平面結構物體(如wall、floor、desk 等)有較高的分割精度,但是將點云切片會嚴重丟失點的空間鄰域關系,從而導致循環(huán)神經(jīng)網(wǎng)絡很難學習非平面復雜結構物體的特征.而本文提出的立方體卷積運算通過將局部空間劃分為 3×3×3 網(wǎng)格來獲取表示點的鄰近點,能對點云分布密度不均具有更好的魯棒性,且能感知空間幾何結構的微小變化.另外,通過對所獲取的鄰近點進行排序可以使得二維卷積能夠感知視角信息,從而準確地抽象表示點的高層特征.因此,相比其他方法本文方法具有更好分割性能.
同時我們也做了耗時統(tǒng)計實驗,所有方法均在相同實驗環(huán)境下以在1080Ti 單GPU 上所發(fā)揮的最大性能統(tǒng)計.如表6 所示,當輸入點云個數(shù)為8 192時,本文ResNet-FPN_C 方法單batch 平均訓練時間和前向傳播時間分別為0.060 s 和0.042 s,略慢于其他方法.雖然U-Net_C 方法在mIoU 指標上可以取得更好的結果,但是其速度也明顯降低.因此,本文提出的ResNet-FPN 網(wǎng)絡具有更為平衡的運行效率和分割精度.由于本文提出的立方體卷積運算具有簡單、通用性強等特點,可以將用于二維圖像處理的一些主流神經(jīng)網(wǎng)絡適用于三維點云分割任務,因此后續(xù)我們將嘗試更多主流的神經(jīng)網(wǎng)絡框架或針對三維點云分割任務對網(wǎng)絡結構進行改進來提高精確率和減少耗時.另外值得一提的是,由于PointCNN 方法中參數(shù)化卷積設計的局限性,限制了其輸入點的個數(shù),而本文方法當輸入點個數(shù)4倍于PointCNN方法時,在訓練時間和前向傳播時間方面依然取得了不錯的表現(xiàn).驗證了本文方法的有效性和可行性.

表6 耗時比較Table 6 Comparison of running time
3 結語
本文分析了二維卷積的特點和現(xiàn)有參數(shù)化卷積設計的局限性,提出了一種通用立方體卷積運算,以通過二維卷積實現(xiàn)三維表示點的高層特征的抽取;基于此,提出了一種面向散亂點云語義分割的深度殘差-特征金字塔網(wǎng)絡,將用于二維圖像處理的神經(jīng)網(wǎng)絡框架適用到了三維點云分割任務中.實驗結果表明,本文提出的立方體卷積運算具有良好的適用性,且本文提出的深度殘差-特征金字塔網(wǎng)絡框架在分割精度方面優(yōu)于現(xiàn)存同類方法.在后續(xù)工作中,作者將結合特征可視化分析,進一步發(fā)現(xiàn)本文方法的不足并做出改進.此外,結合本文提出的立方體卷積運算,將更多主流的二維卷積神經(jīng)網(wǎng)絡框架用于三維點云分割任務也是我們下一步的工作.
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
大連民族大學學報(2015年2期)2015-02-27 08:28:11
河南科技(2014年23期)2014-02-27 14:19:15
