基于聯邦學習的無線網絡節點能量與信息管理策略
2022-01-14 03:02:24楊文琦聶江天楊和林康嘉文熊澤輝
計算機工程 2022年1期
楊文琦,章 陽,2,聶江天,楊和林,康嘉文,熊澤輝
(1.武漢理工大學計算機科學與技術學院,武漢 430063;2.武漢理工大學交通物聯網技術湖北省重點實驗室,武漢 430063;3.南洋理工大學計算機科學與工程學院,新加坡 639798;4.新加坡科技設計大學信息系統技術與設計學院,新加坡 487372)
0 概述
無線通信網絡的許多新興智能應用都是基于機器學習技術,機器學習模型的訓練通常需要大量數據集,而數據的收集在很大程度上依賴于分布分散的邊緣用戶節點[1]。由于傳統的機器學習技術需要集中儲存大量原始數據,因此數據持有用戶會有隱私泄露的風險。隨著大數據的日益發展,重視數據隱私和信息安全已成為了全球性趨勢[2-4],數據的隱私問題已影響到無線通信系統中數據的有效收集,大多數行業數據已出現數據孤島現象[5],如何在保護隱私的前提下高效收集分布式的數據成為研究熱點[6]。
聯邦學習是一種通過聚集局部計算的梯度來訓練共享模型的分布式學習方法,這種新的機器學習范式使資源受限的客戶端節點可在中央服務器的協調下訓練數據并分享梯度信息,同時保持訓練數據分散在本地,避免上傳原始數據以致隱私泄露[7]。目前,研究人員對聯邦學習的探究主要集中在提高差分隱私[8]、安全多方計算[9]等隱私保護技術[10]和降低通信開銷[11-13]方面。文獻[14]提出一種聯邦強化技術,通過聯邦學習減少移動邊緣用戶個性化的時間。文獻[15]在仿真通信網絡中部署聯邦學習系統,說明聯邦學習參與者的模型訓練進度和貢獻率。傳統的聯邦學習框架嚴格禁止原始數據共享,一般使用安全級別較高的差分隱私等方法進行加密,但聯邦學習對于隱私保護的過分嚴苛也降低了訓練數據的可用性,從而降低模型的部分準確率[16]。文獻[17]指出,在部署聯邦學習框架的無線通信網絡中,數據隱私性與可用性的平衡是亟待解決的問題。除此之外,能量供給是客戶端節點在信息感知和數據處理方面完成高質量服務的關鍵[18],如果選擇節點作為聯邦學習的參與者,則需消耗自身大量的能量以確保采集到合適的數據并在本地順利訓練模型[7]。隨著無線能量收集和傳輸技術的發展,客戶端節點可以通過無線能量源充電[19],但同時也需向能量源支付相關費用。隨著互聯網的高速發展,節約能源并使之可持續性發展早已成為主要問題[20]。因此,聯邦學習雖然減輕了傳統機器學習集中式訓練方法帶來的隱私風險和開銷[21],但對客戶端節點的能量、計算能力以及模型訓練效果提出了挑戰,在一定程度上影響了無線通信系統數據收集與使用的效率。
分布式數據的收集與訓練除了需要滿足保護隱私和降低能耗的要求,還面臨著無線網絡中的不確定性。在下一代5G 通信網絡[22]不斷發展的背景下,分布式系統訓練模型借助移動信息采集設備對較為偏僻的數據持有用戶進行數據收集與訓練已經成為主要方式。類似無人機[23]、無線傳感車輛[24]的高移動性新型網絡成員,在輔助無線通信網絡收集信息和訓練數據的同時,它們移動靈活的特性也給無線通信網絡的信息收集和機器學習訓練帶來了不確定性和安全隱患,例如,客戶端節點一般只有當信息采集設備在其通信范圍內才能傳送數據,當信息采集設備有其他任務離開后,該節點則無法傳送數據[25],這給通信網絡的管理增加了一定的難度。此外,移動信息采集設備在無線傳輸中的消息可能會被攻擊者竊聽,從而導致敏感信息泄露[26]和自身信譽下降,影響其與邊緣用戶節點的合作。如果無線通信網絡無法應對移動信息采集設備帶來的不確定性和隱私安全挑戰,就無法吸引擁有高質量和大型數據集的邊緣用戶傳輸自身的數據,使某些邊緣用戶的數據處入孤島狀態。因此,在無線通信網絡中,資源受限的客戶端節點亟需一種可克服無線網絡信息傳輸帶來的不確定性、兼顧數據可用性和隱私性的能量與信息管理策略。
本文針對移動信息采集設備輔助的無線通信網絡場景,提出一種基于聯邦學習的信息傳輸與能量管理組合優化策略。將通用性較高的移動信息采集設備作為學習服務器,將客戶端節點作為學習參與者,并為客戶端節點構建馬爾科夫決策模型,通過平衡數據可用性、用戶隱私以及能量消耗之間的關系,得出客戶端節點的信息傳輸與能量管理組合優化策略。
1 問題描述
1.1 系統模型
聯邦學習因其嚴格的隱私保護機制成為解決無線分布式系統數據無法有效收集問題的有效框架。針對基于傳統聯邦學習框架工作的客戶端節點存在數據可用性較低以及能耗較大的問題,本文在無線通信網絡場景下提出一種將聯邦學習與傳統集中式學習相結合的優化架構,如圖1 所示。
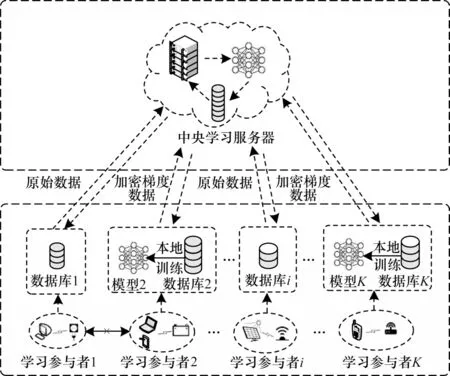
圖1 基于聯邦學習的優化架構Fig.1 Optimization framework based on federated learning
傳統的聯邦學習和集中式學習架構都是由上層的中央學習服務器和下層的學習參與者兩個類型的實體組成。在傳統的聯邦學習架構中,每個學習參與者在本地模型訓練后僅向學習服務器發送訓練后得到的加密梯度數據,再由服務器解密聚合后統一將梯度數據回傳給學習參與者。在此過程中服務器不接觸原始數據,因此,聯邦學習架構起到了保護用戶隱私的作用。本文所提架構通過保留聯邦學習的基礎分布式架構和工作原理以保護客戶端節點的隱私。但聯邦學習需要能量有限的客戶端節點消耗自身算力訓練數據,數據加密壓縮的過程對于數據的可用性也有一定的損耗。在傳統的集中式學習中,學習參與者將自身的原始數據直接交由服務器訓練。此過程中學習參與者需要承擔泄露隱私的風險,并且傳輸大量原始的數據對信道的要求較高,數據最終傳輸成功概率受外部環境的影響,但這種學習方式僅在傳送數據時消耗自身能量,且原始數據的可用性較高,因此,傳統的集中式學習起到了降低能耗、保證數據可用性的作用。
本文為探究無線網絡場景下信息采集的隨機性對客戶端節點的信息傳輸以及學習選擇的影響,為聯邦學習架構中的學習服務器加入了移動屬性,將移動信息采集設備作為學習服務器。對于客戶端節點,在移動服務器隨機的信息采集場景下得到可平衡自身能耗、數據可用性和隱私性的信息傳輸與能量管理策略,但最終所得的策略也更具通用性,傳統的云服務器穩定的信息收集過程可作為其中的一種特例處理。本文圍繞一個移動信息采集設備(學習服務器)及與其可能發生交易的K個客戶端節點(學習參與者)進行研究并建立系統架構,如圖2 所示。
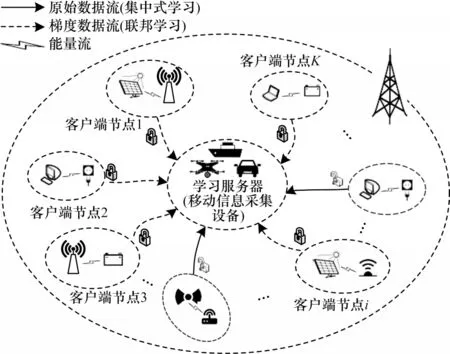
圖2 本文系統架構Fig.2 Framework of the proposed system
移動信息采集設備在本文系統中作為一個可移動的學習服務器,不僅可以在不同的客戶端節點處收集數據,還可以將收集的數據進行訓練以構建模型。本文假設移動信息采集設備在一個時隙內僅停留在一個區域收集與處理該區域中客戶端節點的數據或梯度。每個節點可以不斷地產生原始數據,擁有的電量和原始數據量都不完全相同,根據自身情況選擇參與到移動信息采集設備組織的聯邦學習或者傳統的機器學習中。
若客戶端節點選擇參與分布式的聯邦學習,則先在本地訓練模型,局部計算梯度參數,再將加密過的梯度參數發送給移動信息采集設備。移動信息采集設備得到所有客戶端節點的數據之后,在不了解任何節點信息的情況下執行安全聚合,并計算總梯度。最后將結果分別傳送給參與的客戶端節點,節點再使用解密的梯度參數更新各自的模型。
客戶端節點還可以選擇傳統的集中式機器學習,其僅作為數據提供者,直接發送原始數據給移動信息采集設備。在這種情況下,客戶端節點選擇放棄保護隱私并完全信任移動信息采集設備,以節省訓練過程中的計算開銷。移動信息采集設備得到所有客戶端節點的數據之后,在了解節點信息的情況下執行數據聚合和訓練。
從保護隱私的角度分析,客戶端節點更傾向于在本地訓練數據,以避免發送大量的原始數據帶來隱私泄露的風險。但從提高模型訓練效果和減少能源消耗的角度分析,客戶端節點傳送原始數據有助于最大程度地保留數據的可用性,有利于對模型進行訓練,同時也可避免因在本地進行模型訓練而消耗較多的能量。因此,本文基于聯邦學習中的用戶合作訓練模型,設計一種客戶端節點的信息傳輸機制。該機制基于馬爾科夫決策過程(Markov Decision Process,MDP)構建隨機優化模型,并通過求解MDP 模型得到客戶端節點的最優信息傳輸與能量管理組合優化策略。
1.2 馬爾科夫決策模型
為確定無線網絡場景下客戶端節點的信息傳輸與能量管理組合優化策略,本節將客戶端節點的信息傳輸與能量管理問題建模為一個MDP 模型,以描述與分析節點在移動信息采集設備帶有不確定性的信息采集過程中的狀態變化與行為模式。
1.2.1 狀態空間
狀態S是一個復合狀態變量,由數據狀態、能量狀態和移動信息采集設備區域狀態這3 組離散狀態表示,如式(1)所示:
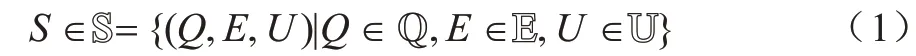
其中:數據狀態Q∈Q={0,1,…,Q}為客戶端節點在其數據緩存池中當前滯留的數據量;Q為最大數據量。本文假設每個客戶端節點訓練和發送數據所需要的能量是由外部設備提供的,單個客戶端節點配備儲能設備和無線充電設備,從可訪問的能源中充電并儲存在自身的儲能設備中。能量狀態E∈E={0,1,…,E}為客戶端節點儲能設備中的剩余電量,E為最大電量。移動信息采集設備區域狀態U∈U={0,1}表示移動信息采集設備是否處于該客戶端節點的數據可傳送區域范圍中,U=0 表示移動信息采集設備不在節點傳送區域中,即移動信息采集設備未到該節點處,該節點無法與移動信息采集設備產生任何交易,U=1 則表示移動信息采集設備在該節點處。
1.2.2 動作空間
客戶端節點在每個時隙中根據所觀測到的當前狀態做出相應的動作決策。動作空間A 為節點在每個時隙內可選擇執行的動作集合,如式(2)所示:

其中:A=0 為節點決定不執行任何操作;A=1 為節點決定參與聯邦學習,僅向移動信息采集設備傳送在本地訓練后的加密數據,消耗自身算力,并保護數據隱私;A=2 為節點決定直接向移動信息采集設備傳送原始數據,以避免由于本地訓練計算量過大而可能產生的能源中斷等問題。
1.2.3 狀態轉移矩陣
狀態轉移矩陣H為節點在一個時隙內,從當前狀態S轉移到下一個狀態S'的整體狀態轉移矩陣,矩陣橫坐標代表節點當前狀態S,縱坐標代表下一狀態S'。該矩陣描述客戶端節點所觀測系統狀態的變化過程。該矩陣由3 個狀態分量的轉移矩陣通過Kronecker 乘積?推導得出,如式(3)所示:
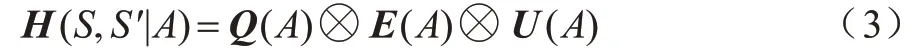
狀態轉移矩陣包括數據狀態轉移矩陣、能量狀態轉移矩陣、區域狀態轉移矩陣。
1)數據狀態轉移矩陣Q(A)
為節點從當前數據狀態Q轉移到下一個狀態Q'的分量轉移矩陣。為方便解釋,本文將數據的流動模式分為消耗和產生兩步推導:在一個時隙開始時,根據節點所做出的不同決策,節點消耗對應的數據量;在一個時隙結束前,節點會重新收集k個單位的數據,若當前數據緩存池的數據存儲已經達到最大容量,則其數據量不變。當A=0 時,節點的數據狀態轉移矩陣如式(4)所示:
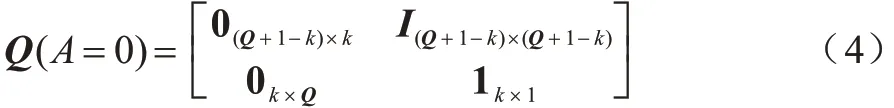
其中:0 為全0 矩陣;I為單位矩陣;1 為全1 矩陣。當A=1 時,即節點在本地訓練模型更新梯度參數并傳送給移動信息采集設備。在能量充足的情況下,節點可以在一個時隙內向移動信息采集設備傳送v個單位的數據,若數據緩存池中當前的數據量大于等于v,則上傳v個單位的數據;小于v則上傳當前所有數據。本文假設在上傳梯度數據過程中不會發生數據丟失的情況,且上傳過程中數據的損耗忽略不計,則此時節點的數據狀態轉移矩陣如式(5)所示:
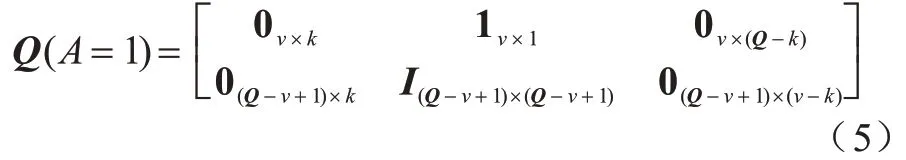
當A=2 時,即節點直接將原始數據傳送給移動信息采集設備,在能量充足的情況下,節點可以在一個時隙內向移動信息采集設備傳送v個單位的數據,但龐大的數據量對信道的要求較高,信道的不穩定性導致數據包有一定傳送失敗的概率。本文假設傳送成功的概率為q,如果數據第一次傳送失敗,可重復嘗試傳輸直到當前時隙結束。如果當前時隙結束時傳送仍然失敗,數據會繼續滯留在數據緩沖池中,造成數據延遲。客戶端節點當前選擇參與集中式學習時,其數據狀態的轉移過程如圖3 所示。
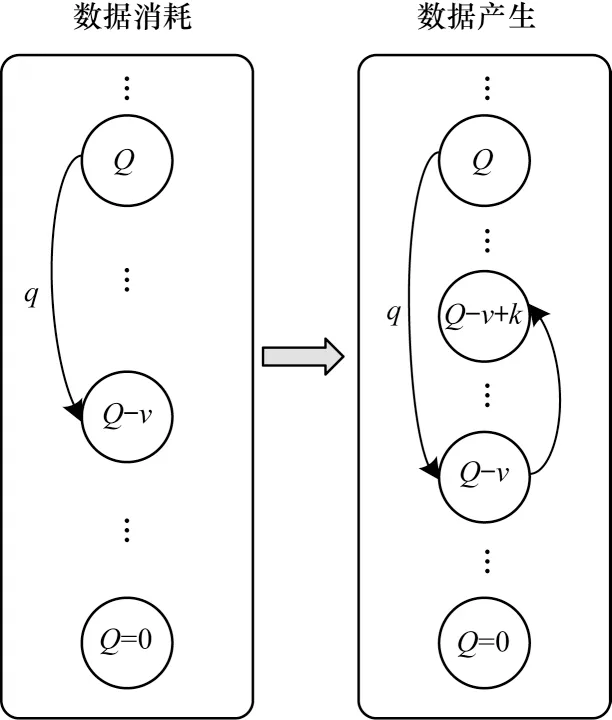
圖3 客戶端節點數據狀態轉移過程Fig.3 State transfer process of client node data
此時數據狀態轉移矩陣如式(6)所示:
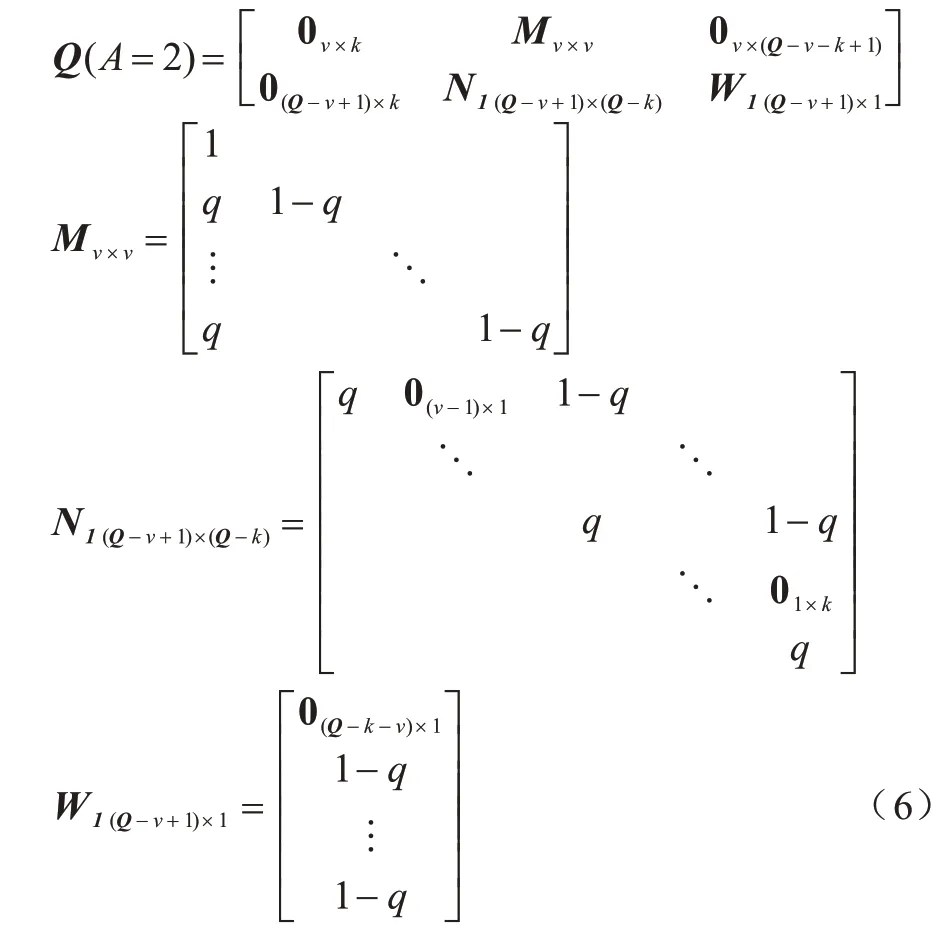
矩陣中q所在位置表示在當前時隙開始時,節點數據量為Q,選擇傳送原始數據后數據傳送成功,則數據量先減少v個單位(若當前節點數據量小于v個單位,則上傳當前所有數據,當前數據量暫時為0),增加新收集的k個單位數據之后,節點在當前時隙結束時擁有的數據量變為Q'。矩陣中1-q所在位置表示節點當前數據量為Q,選擇傳送原始數據后數據傳送失敗,則數據量不會發生變化,節點數據量僅增加新收集的k個單位后變為Q'。
2)能量狀態轉移矩陣E(A)
為節點從當前能量狀態轉移E到下一個狀態E'的分量轉移矩陣。假設能量的補充和傳輸消耗不會同時進行,且在一個時隙內最多只能消耗節點當前已有的能量儲備。本文也將能量的流動模式分為消耗和補充兩步推導,在一個時隙開始時,根據節點做出不同的決策,節點消耗對應的能量;在一個時隙結束前,外部設備會給客戶端節點提供w個單位的能量,補充的能量可供節點下一個時隙使用。若當前儲能已經達到最大容量,則其能量水平不變。當A=0 時,即節點不執行任何操作,節點的能量狀態轉移矩陣如式(7)所示:
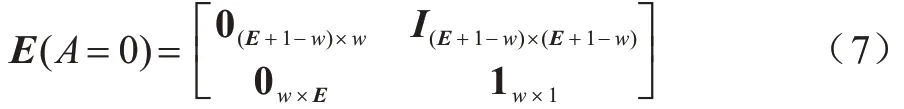
當A=1 時,在一個時隙內,節點訓練模型消耗m個單位的電量,上傳的梯度數據消耗的能量忽略不計,當客戶端節點存儲的能量小于m個單位時,即無法完成模型訓練,當前存儲能量不會被消耗,節點的能量狀態轉移矩陣如式(8)所示:
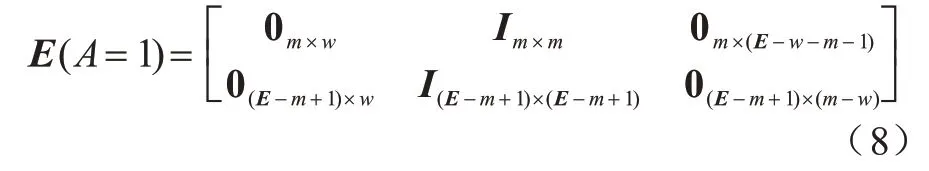
當A=2 時,傳送成功的概率為q,上傳過程消耗n個單位能量,當存儲的能量小于n個單位時,即無法完成數據包的傳送,當前存儲能量也不會被消耗,節點的能量狀態轉移矩陣如式(9)所示:

矩陣中q所在位置表示當前時隙開始時,節點能量為E,選擇傳送原始數據后數據傳送成功,則節點能量先減少n個單位(若當前節點擁有的能量小于n個單位,則無法傳送數據,能量也不會被消耗,即節點能量保持不變),外部設備提供w個單位能量后,節點能量變為E'。矩陣中1-q所在位置表示節點當前能量為E,選擇傳送原始數據后數據傳送失敗,能量未因此發生變化,節點能量僅增加新收集的w個單位后變為E'。
3)區域狀態轉移矩陣U
為移動信息采集設備覆蓋區域狀態轉移的概率矩陣。移動信息采集設備當前是否在節點的數據傳送范圍內,直接決定了節點是否可以將數據傳送給移動信息采集設備。只有作為數據接收方的移動信息采集設備停留在節點處時,節點才能夠參與到移動信息采集設備組織的聯邦學習或集中式學習中。因此,移動信息采集設備在節點處的概率越大,節點越有可能獲得訓練局部模型或上傳原始數據所帶來的收益。若移動信息采集設備當前時隙不在節點處,則下一個時隙移動信息采集設備進入區域的概率為p;若移動信息采集設備當前時隙在節點處,則下一個時隙移動信息采集設備繼續停留在傳送區域的概率為P(A),節點的區域狀態轉移矩陣如式(10)所示:
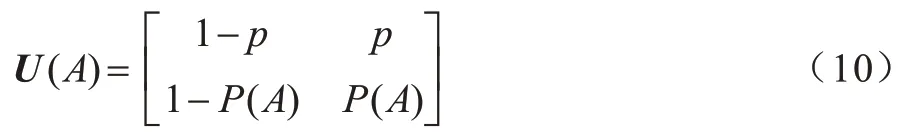
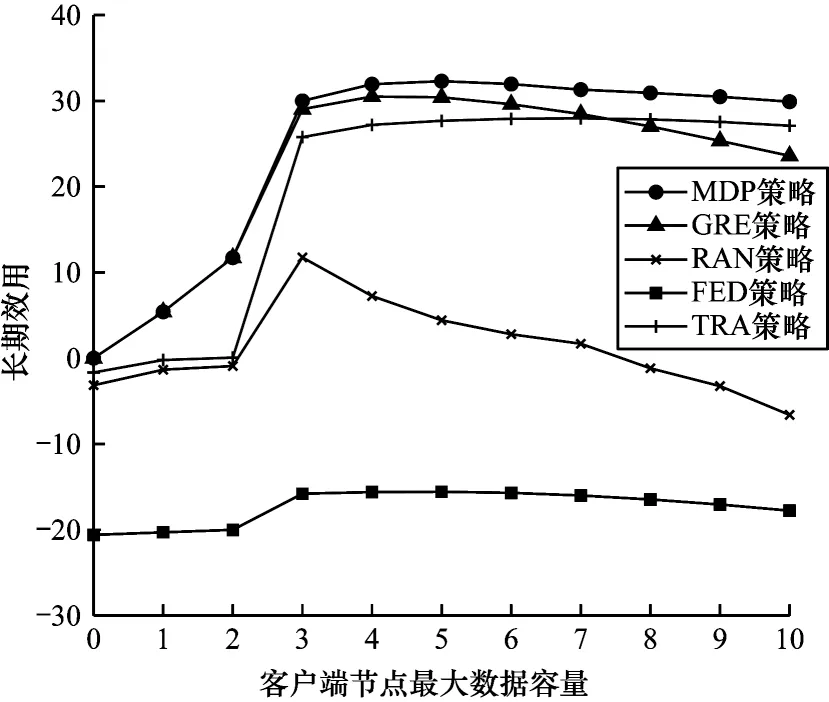
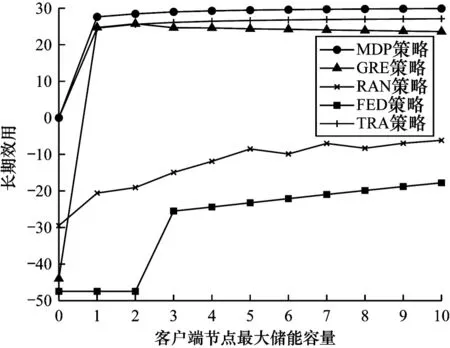
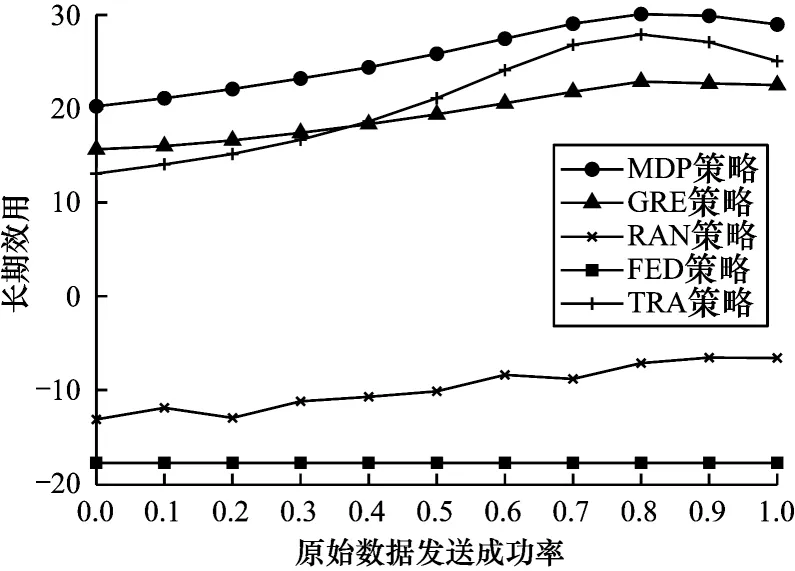
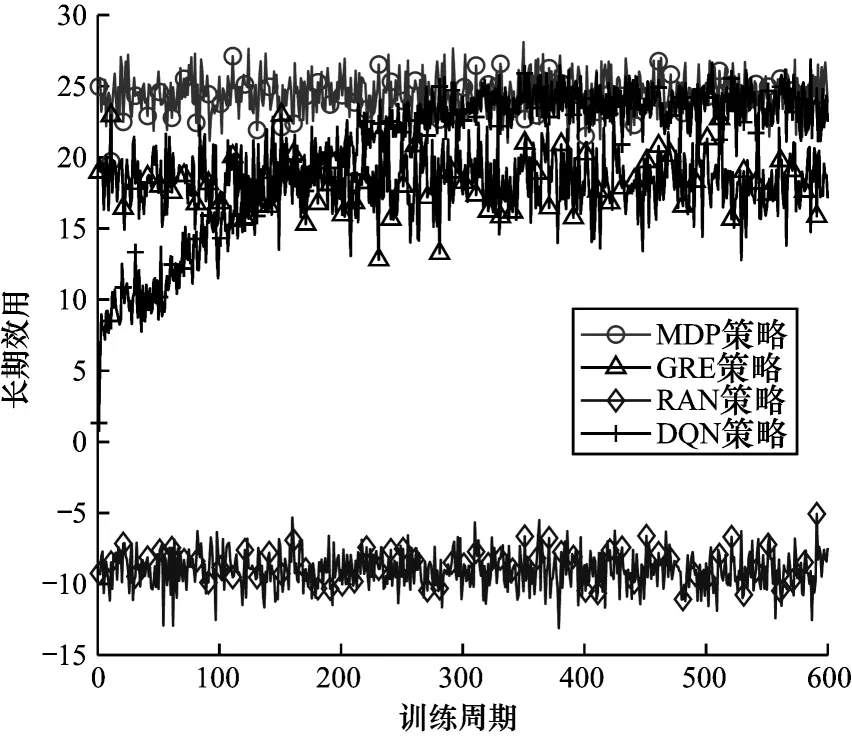
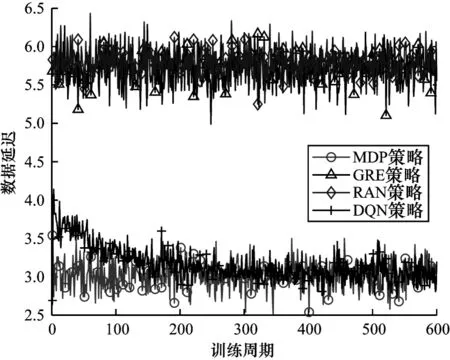
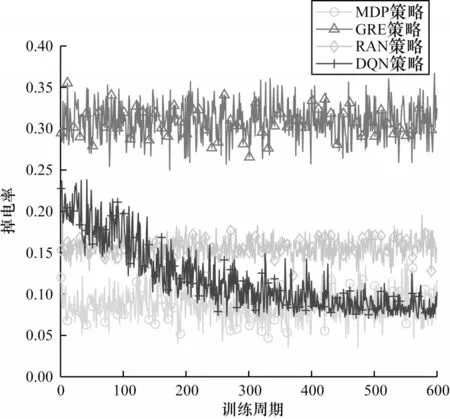
設式中P(A=0) 1.2.4 回報函數 客戶端節點在工作過程中會在不同狀態之間轉換,并相應地采取不同的行動,節點在當前狀態做出動作后,其作為學習參與者將獲得即時獎勵,記為即時效用函數F(S|A),該函數僅與當前狀態有關。本文假設F(S|A)由3 個分量組成,分別為模型收益函數FT(S|A)、數據延遲函數FD(S|A) 和隱私泄露函數FL(S|A),如式(11)所示: 其中:ρT、ρD、ρL為權重系數;FT(S|A)為節點訓練模型所得的收益。機器學習訓練模型的好壞很大程度上取決于訓練集所用數據的質量和數量,一般而言,訓練樣本越多,越有可能通過學習獲得具有強泛化能力的模型。最終所得模型的準確度越高,收益也越大[27],則FT(S|A)如式(12)所示: 其中:ΔQ為節點最終傳送給移動信息采集設備的數據量,訓練模型的最終效果與ΔQ成正相關。但若節點沒有足夠的能量或者移動信息采集設備不在傳送范圍內,節點則無法在本地更新梯度數據或上傳原始數據給移動信息采集設備,因此節點模型收益為0。由于聯邦學習對于隱私保護的嚴苛性,可能會導致數據的可用性降低,因此傳送原始數據可以得到更好的模型訓練效果,即T1(ΔQ) FD(S|A)為數據在節點數據緩存池中滯留的開銷,數據在數據緩存池中滯留的時間越長,傳送給移動信息采集設備的時效性就越低,對總體效用的損耗也越大,則FD(S|A)如式(13)所示: 其中:Q'為當前時隙結束時仍滯留在節點數據緩存池的數據量,滯留開銷僅與Q'成負相關,與節點當前的能量級和移動信息采集設備的區域狀態都無關。 FL(S|A)為隱私泄露的風險開銷,通過分析數據量得出信息量的關系為:當數據量從無到有增加時,可得出的信息量會隨之快速增加。隨著數據量繼續增加,同樣數據量可得的有效信息則逐漸減少,該數量關系符合對數變化規律[28],則FL(S|A)如式(14)所示: 當A=1 時,由于數據是加密上傳的,隱私泄露的風險較小,隱私開銷可忽略不計。當A=2 時,移動信息采集設備得到大量的節點原始數據,從而導致節點隱私有泄露的風險,此時隱私開銷L(ΔQ)與上傳的真實數據量ΔQ呈負相關。如果節點沒有足夠的能量或者移動信息采集設備不在傳送范圍內,即不產生任何信息傳輸,則隱私開銷為0。 在建立MDP 模型的基礎上,本文分別采用值迭代算法以及深度強化學習算法求解MDP,以獲取客戶端節點的優化策略。 在已知完整的系統和環境信息的前提下,值迭代算法根據MDP 模型計算最佳的策略。系統優化的具體目標是在當前系統狀態下,選擇每個決策階段的最佳動作,使節點長期預期效用最大化,從而得到最優策略。由于MDP 模型是由所提出的狀態空間、動作空間、狀態轉移矩陣H(S,S'|A)和即時效用函數F(S|A)實現,因此MDP 優化公式可通過貝爾曼方程迭代求得,如式(15)~式(17)所示: 其中:γ∈(0,1]為折扣因子,公式的解可通過值迭代算法得到。值迭代算法首先初始化所有狀態值函數V(S),分別計算節點在每一個狀態下執行不同動作時所有可能未來狀態的預期效用和,選擇使節點長期預期效用最大化的動作,并將當前狀態的值函數更新為長期預期效用的最大值。當狀態空間里的所有狀態遍歷完畢后,則完成了一次迭代過程,重復上述迭代過程直至前后兩次迭代所得的所有狀態值函數之間的差值均小于設定的某一閾值,所有狀態值函數收斂,此時節點在每個狀態下對應執行的動作即為客戶端節點信息傳輸與能量管理的組合優化策略φ*(A|S)。 傳統的值迭代算法需要完整的系統和環境信息,適用的狀態和動作空間較小,且沒有泛化能力。隨著系統規模的增加,值迭代的復雜度呈指數級增長。與值迭代算法相比,深度強化學習(Deep Reinforcement Learning,DRL)顯著降低了模型的復雜性,在問題規模增大的情況下算法復雜度也沒有提升。DRL 是強化學習和深度學習的結合,在具有決策能力強化學習基礎上借助深度神經網絡使智能體擁有對復雜環境的理解能力和泛化能力,為智能體動態地提供不斷適應環境變化的決策方案。 深度Q 網絡(Deep Q Network,DQN)是DRL 算法的典型代表。與值迭代算法相比,DQN 利用深度神經網絡逼近值函數,將當前系統觀察到的狀態作為神經網絡的輸入,通過經驗回放打破數據之間的相關性。DQN 通過兩個結構相同但參數不同的神經網絡,從歷史經驗中學習回報和動作之間的關系,優化神經網絡的權重,從環境中最大化獲得累計回報值,最終輸出一組動作的估計Q值。此外,DQN的輸入數量僅由狀態本身性質決定,即使輸入數量改變,DQN 的結構也無需改變,具有一定通用性[29]。因此,本文采用基于DQN 的算法為客戶端節點提供實時決策,以尋找節點信息傳輸與能量管理組合優化策略。具體過程見算法1。 算法1基于DQN 算法的客戶端節點信息傳輸與能量管理組合優化策略 本文通過仿真構建系統模型,并定義了相關性能指標評價所提MDP 策略。 本文設置客戶端節點的最大數據容量Q=10,最大儲能容量E=10。在一個時隙內節點可向移動信息采集設備傳送v=3 個單位數據,新收集k=2 個單位數據。節點在本地訓練消耗m=3 個單元能量,傳送原始數據給移動信息采集設備消耗n=1 個單位能量,每個時隙外部設備給節點補充w=1 個單位能量。移動信息采集設備進入節點傳送范圍的概率p=0.5;節點執行不同動作后,移動信息采集設備繼續停留在節點處的概率P(A=0)=0.5,P(A=1)=0.7,P(A=2)=0.9。節點成功傳送原始數據的概率為q=0.9。對于1.2.4 節中給出的回報函數,本文設置T1(ΔQ)=3ΔQ,T2(ΔQ)=4ΔQ,設置數據滯留開銷D(Q')=Q',隱私泄露開銷L(ΔQ)=lb(ΔQ+1),設置權重系數ρT、ρD、ρL分別為1、-0.5、-2。 對于DQN 算法中的初始參數,本文設置參數θ為0~0.3 的隨機數,該參數隨著每次迭代實時更新,每隔300 步目標值神經網絡的參數θ-更新一次。記憶回放池D=500,學習率α=0.001,ε-貪心策略中的探索率ε=0.95。 為驗證所提策略的性能,本文設置4 種對比策略:1)貪心策略(GRE),節點不考慮未來的長期收益,每次都選擇使即時效用F(S|A)最大化的動作;2)隨機策略(RAN),節點每次在動作空間中隨機選擇一個動作,所有動作被選中的概率相等;3)傳統聯邦學習策略(FED),節點在任何狀態下僅選擇參與聯邦學習,即在本地訓練并上傳梯度數據;4)傳統集中式學習策略(TRA),節點在任何狀態下僅選擇參與集中式機器學習,即上傳原始數據。 為評估所提出策略性能,本文定義相關性能評價指標如表1 所示。 表1 客戶端節點性能評價指標Table 1 Performance evaluation indexs of client node 本文首先基于所提出的值迭代算法進行仿真實驗,通過比較長期效用對客戶端節點的性能進行驗證。本文研究客戶端節點的最大數據容量Q對其長期效用的影響,改變Q為0~10,在不同策略下長期效用隨節點最大數據容量的變化如圖4 所示。隨著數據容量增加,所有策略的效用都呈先增后減的趨勢。這是由于在Q較小時,節點最大數據存儲容量的增加使得節點可以存儲更多的數據以供未來訓練模型使用,從而減少節點參與聯邦學習或集中式學習,數據緩存池中可供訓練的數據短缺問題發生的概率減少。隨著Q增加,訓練模型所帶來的收益逐漸不足以抵消巨大的數據量,滯留在緩存池中的數據延遲開銷,因此長期效用逐漸減少。在最大數據容量較小時表現較優的GRE 策略,隨著數據容量的增加逐漸體現出了劣勢。由于GRE 策略是短視的,節點在決策時僅選擇當前時隙能得到最高回報的動作,而忽略了當前所選擇動作對未來的影響。FED 策略的能耗成本始終較大,TRA 策略的隱私泄露成本較大,無法獲得優于MDP 策略的長期效用。在這種情況下,本文提出的MDP 策略相較于其他基準策略的優勢逐漸擴大。MDP 策略在已知全局環境信息的情況下,在盡量保護用戶隱私和保持模型訓練精度基礎上,降低能量開銷的策略,實現性能平衡。 圖4 在不同策略下長期效用隨節點最大數據容量的變化Fig.4 Long-term utility changes with maximum data capacity of client node under different strategies 在不同策略下長期效用隨節點最大儲能容量的變化如圖5 所示,改變節點最大儲能容量E從0~10,隨著E增加,所有策略的效用都呈現增加趨勢后逐漸平緩。當E從0~1 時,MDP、GRE 和TRA 策略的長期效用都有一個較大幅度增加,由于節點上傳原始數據需要n=1 個單位能量,此時最大儲能容量的增加使節點在做決策時有足夠的能量使用,可以減少由于儲能能力不足而造成能量短缺。當E>1 時,上述3 種策略的邊際效用減小,此時最大儲能容量已超過節點執行任何操作所需的能量,因此,最大儲能容量的增加帶來的優勢也逐漸減少。而FED 策略在E=3 時長期效用才有一個較大的提升,但仍低于其他策略的長期效用。在不同的儲能容量E下,由于本文提出的MDP 策略考慮了未來可能會產生的能量短缺,提前做出了有利于提高長期效用的決策,因此MDP 策略的表現優于其他基準策略。在實際系統中可以依照相應的仿真結果設置客戶端節點的最大數據容量和最大儲能容量,以節省成本,例如,在本實驗參數設置條件下,將客戶端節點的最大數據容量設置為3,最大儲能容量設置為1 是較為合適的選擇。 圖5 在不同策略下長期效用隨節點最大儲能容量的變化Fig.5 Long-term utility changes with maximum energy capacity of node under different strategies 本文還研究了節點傳送原始數據的成功率q對長期效用的影響,如圖6 所示。隨著q的增加,除了在任何狀態下都選擇上傳梯度數據的FED 策略的總體效用不受原始數據發送成功率的影響,其他所有策略的效用都呈先增后減的趨勢。在q較小時,若節點選擇了傳送原始數據,隨著q的增大,更多原始數據可直接用于模型訓練,節點所得的訓練收益也隨之增大,且大于節點在其他方面的成本消耗。當q=0.8 時,節點在隱私開銷、模型收益和能量消耗之間達到了最佳平衡。而當q>0.8 時,雖然此時數據傳送成功概率更高,所獲得的模型收益可能更大,但隨著原始數據傳送成功率的提高,當節點選擇傳送原始數據時,隱私泄露的風險開銷也隨之變大,此時三者之間的最優決策所達到的平衡被打破,因此長期效用反而降低。實際系統可以依照相應的仿真結果設置客戶端節點的數據發送成功率。在本實驗參數設置條件下,維持客戶端節點的數據發送成功率約為0.8 較合適。從圖6 可以看出,本文考慮了未來長期效用的MDP 策略優于其他基準策略。 圖6 在不同策略下長期效用隨節點原始數據發送成功率的變化Fig.6 Long-term utility changes with transmission success rate of node original data under different strategies 為驗證部署DQN 策略的客戶端節點在未知信息的高維環境中探索學習的性能,本文進行了仿真實驗。在不同策略下長期效用隨訓練周期的變化如圖7 所示。在經過約300 輪訓練后,DQN 的仿真結果收斂于MDP 的仿真結果并逐漸趨于穩定,原因是DQN 策略對先前訓練周期的系統狀態、狀態轉換和即時回報都進行了采樣,并將這些歷史數據放入記憶回放池中,之后通過訓練歷史數據不斷調整深度神經網絡中的權重因子,最終調整到趨于穩定且較高的水平,得出節點最優的信息傳輸與能量管理策略。該結果表明DQN 策略在高維復雜的無線通信網絡環境中,仍表現出較強的探索學習能力。 圖7 在不同策略下長期效用隨訓練周期的變化Fig.7 Long-term utility changes with training period under different strategies 在不同策略下節點平均數據延遲隨訓練周期的變化如圖8 所示。基于歷史數據訓練的DQN 策略的平均數據延遲初期隨著訓練周期的增加逐漸降低,可以有效地處理數據傳輸任務,DQN 策略在訓練約300 輪時收斂于MDP 策略,相較于其他基準策略產生的數據延遲最少。由于數據長時間累積存儲在隊列中會導致較大的延遲開銷和較少的長期收益,DQN 策略通過訓練學習過程快速調整策略進行平衡,因此更好地完成了移動信息采集設備和客戶端節點間的信息傳輸。 圖8 在不同策略下平均數據延遲隨訓練周期的變化Fig.8 Average data delay changes with training period under different strategies 在不同策略下節點掉電率隨訓練周期的變化如圖9 所示。基于DQN 策略的掉電率在訓練約300 輪向下收斂于MDP 策略的基準值且遠低于其他策略,相比其他基準策略,對于回報的短視,DQN 策略在學習歷史經驗的過程中已逐漸學會如何規避可能對后續能量造成短缺的選擇,不斷調整策略以最大程度地減少能量短缺。 圖9 在不同策略下掉電率隨訓練周期的變化Fig.9 Energy shortage probability changes with training period under different strategies 本文設計一種基于聯邦學習的信息傳輸與能量管理策略。通過構建馬爾科夫決策模型分析客戶端節點在系統中的行為模式,采用值迭代算法和深度強化學習算法求解馬爾科夫決策模型,得到客戶端節點的能量與信息管理優化策略。仿真結果表明,本文策略能夠實現節點在數據隱私保護、模型收益和能量消耗之間的最優平衡。由于無線通信網絡的實際應用場景通常是層次復雜的網絡拓撲結構,而本文僅研究聯邦學習框架下無線網絡中一對多通信的問題,因此后續將對多層次無線網絡結構下多對多信息傳輸的動態變化進行研究,使信息傳輸與能量管理策略適用于無線通信網絡的實際應用場景。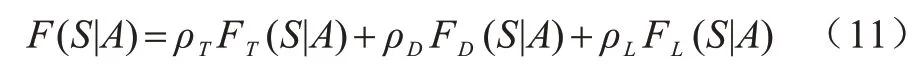
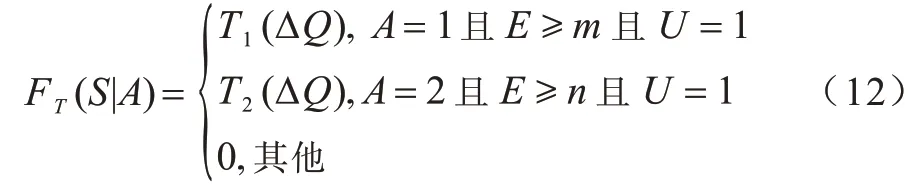

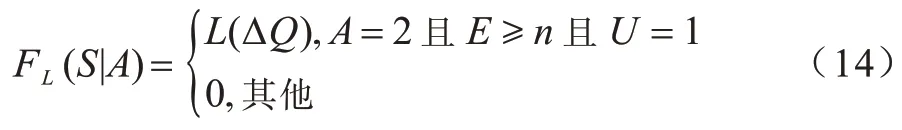
2 無線通信網絡場景下的優化策略
2.1 值迭代算法
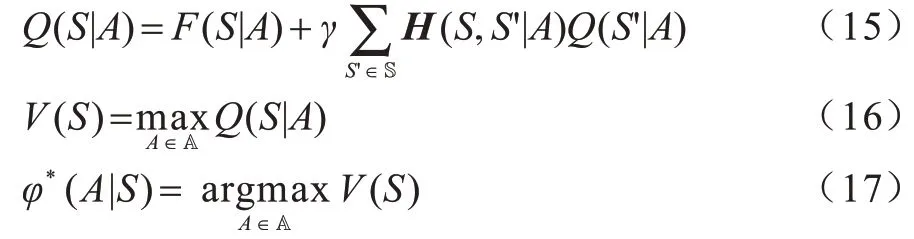
2.2 深度強化學習

3 仿真與結果分析
3.1 仿真環境與參數
3.2 評價指標

3.3 仿真結果分析
4 結束語
猜你喜歡
中國特種設備安全(2022年6期)2022-09-20 02:52:28教學考試(高考化學)(2021年2期)2021-05-30 06:15:52中學生數理化·高一版(2020年3期)2020-04-21 08:03:20中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10經濟技術協作信息(2018年22期)2019-01-19 03:00:18電子制作(2018年11期)2018-08-04 03:26:08數學大世界(2018年1期)2018-04-12 05:39:14工業設計(2016年12期)2016-04-16 02:52:00設備管理與維修(2015年12期)2015-04-09 06:57:00
