漢語閱讀中高限制性語境對不可預測詞加工的影響:眼動研究*
2022-01-22 14:24:24趙賽男張俐娟王敬欣
心理與行為研究 2021年6期
趙賽男 李 琳,3 張俐娟 王敬欣,3
(1 教育部 人文社會科學重點 研究基地天津師范 大學心理與行為研 究院,天津 300387) (2 天津 師范大學心理學部,天津 300387) (3 學生心 理發展與學習天津 市高校社會科學實 驗室,天津 300387)
1 引言
閱讀中詞匯的加工和整合會受到語境預測性的影響,表現出語境預測性效應。語境預測性是指根據給定的語境,接下來即將出現的詞能被讀者預測出來的概率(Rayner & Well,1996)。語境預測性效應即相較于不可預測詞,可預測詞的加工更快速容易(劉志方,仝文,張智君,趙亞軍,2020;DeLong,Urbach,& Kutas,2005;Rayner,Li,Juhasz,& Yan,2005;Rayner & Well,1996)。語境預測性取決于語境限制性。語境限制性是指語境對接下來可能出現的所有內容范圍的限制程度。高限制性語境將可能會出現的內容種類限定在很小范圍內,讀者能對可能出現的某一種內容進行較高預測(Frisson,Harvey,& Staub,2017)。低限制性語境中,接下來可能出現的內容種類廣泛,讀者難以對某一內容進行較高預測(Frisson et al.,2017)。在高限制性語境中,接下來出現的詞可能是與較高預測一致的可預測詞,也可能是不一致的不可預測詞。在低限制性語境中,很難對某一內容進行較高預測,接下來出現的均是不可預測詞。
語境預測性效應可能源于高限制性語境對可預測詞的促進(收益),也可能源于對不可預測詞的干擾(成本)。大多數研究通過比較高限制性語境下可預測詞和不可預測詞的加工差異測量語境預測性效應(劉志方等,2020;Rayner & Well,1996;Zhao,Li,Chang,Wang,& Paterson,2021)。但只采用高限制性語境缺乏基線(低限制性語境),難以明確效應來源。也有少數研究通過比較高限制性語境下可預測詞和低限制性語境下同一詞的加工差異來測量語境預測性效應(盧張龍,白學軍,閆國利,2008),此方法由于缺乏高限性語境下的不可預測詞,也無法判斷語境預測性效應中是否存在成本。要想探究語境預測性效應,需要對預測誤差成本進行測量。預測誤差成本(prediction error cost)即相較于低限制性語境,高限制性語境對不可預測詞的加工造成的干擾(Frisson et al.,2017)。目前尚不清楚漢語閱讀中預測誤差成本的表現。
預測誤差成本是否存在關系到對預測加工機制的理解。有關閱讀中的預測加工模式存在兩種假說。詞匯預測觀(lexical prediction)認為,讀者根據語境按照“全或無”的方式首先只激活接下來可能出現的某一個特定單詞(DeLong,Troyer,& Kutas,2014)。當接下來出現的內容違背預測時,高限制性語境會對這些不可預測詞的加工造成干擾,產生預測誤差成本。等級預激活觀(grade preactivation)認為讀者按照完形填空概率對接下來的內容同時進行了不同等級的廣泛預激活,而非對某個特定單詞的離散激活(Staub,2015)。根據這一假說,高限制性語境不會對不可預測詞的加工產生干擾。
針對預測誤差成本這一問題,在拼音文字(如英語)中,大多數采用快速系列視覺呈現范式(RSVP)的研究發現,與低限制性語境相比,高限制性語境中的不可預測詞誘發了更大的晚期額部正波(LPC)(刺激呈現后500~900 ms),存在預測誤差成本(Federmeier,Wlotko,De Ochoa-Dewald,& Kutas,2007)。但在少數自然閱讀中沒有發現預測誤差成本(Frisson et al.,2017;Luke & Christianson,2016)。不同范式下的結果差異可能是材料呈現方式的差異造成的。預期雙加工理論認為,語境對詞匯加工既有促進,也有抑制。早期無意識的自動激活擴散加工迅速引發了語境促進作用,不會產生抑制。抑制作用只發生在后期意識-注意加工階段(Posner & Snyder,1975;Stanovich & West,1979)。在RSVP 范式中,刺激以固定速度呈現,通常每個單詞呈現500~1000 ms,是自然閱讀中平均注視時間(250 ms)的倍數。長時間的視覺呈現可能在后期誘發出了預測誤差成本。但在詞匯正常呈現的自然閱讀中未產生預測誤差成本。
與拼音文字相比,漢語沒有空格,無法利用視覺信息獲取詞的邊界,但在閱讀相同內容時速度卻相似(Liversedge et al.,2016),這表明讀者可能利用了額外的語境資源提升了詞切分加工效率,促進了詞匯加工(Li & Pollatsek,2020)。另外,Rayner 等人(2005)發現,雖然拼音文字和漢語中的語境預測性效應有很大相似性,但也存在一些差異。在拼音文字中,中、低等預測性詞在跳讀上沒有差異,但在漢語中兩者卻有差異。這表明漢語閱讀中的語境預測性效應更明顯。最后,漢語閱讀中發現了較早的語義預視加工優勢(王穗蘋,佟秀紅,楊錦綿,冷英,2009)。漢語與拼音文字的認知加工既有相似性,也有獨特性,但尚不清楚漢語的獨特性是否會對預測加工產生影響。
綜上,本研究利用眼動技術考察漢語閱讀中的預測誤差成本,探究漢語閱讀中的預測加工方式。研究假設:若讀者采用特定詞匯預測方式,高限制性語境會對不可預測詞的加工造成干擾,存在預測誤差成本;若讀者采用等級預激活方式,高限制性語境不會對不可預測詞的加工造成干擾,不存在預測誤差成本。
2 實驗1:高限制性語境對不可預測詞加工的影響
2.1 研究方法
2.1.1 被試
從天津市某大學招募了42 名被試,年齡18~24 歲(M=20.10 歲,SD=1.46 歲)。被試均以漢語為母語,視力或矯正視力正常,結束后獲得一定的報酬。
2.1.2 實驗設計
實驗1 為單因素三水平(高限制性語境可預測詞、高限制性語境不可預測詞、低限制性語境不可預測詞)被試內設計。材料如表1 所示。

表1 實驗1 材料舉例
2.1.3 實驗材料
實驗1 共135 組實驗句,每組包含三個句子,代表三種水平。可預測詞和不可預測詞在詞頻和筆畫數上沒有差異(詞頻:t=0.42,p=0.68;筆畫數:t=0.09,p=0.93)。詞頻統計基于SUBTLEXCH(Cai & Brysbaert,2010),單位為次/百萬。12 名大學生對材料進行了完形填空。研究將填寫目標詞人數占總人數的比率作為目標詞的預測性指標。可預測詞的完型概率高于67%,不可預測詞的概率低于17%。高限制性語境中可預測詞和不可預測詞的預測性差異顯著(t=81.88,p<0.001),但高限制性語境不可預測詞和低限制性語境不可預測詞的預測性沒有差異(t=0.63,p=0.53)。每個句子中的最高完型概率值為語境限制性指標。最高概率值越低,語境限制性越低。高、低限制性語境間的語境限制性差異顯著(t=60.60,p<0.001)。24 名大學生對材料合理性進行了7 點量表評定。不同條件下的合理性存在差異,F(2,402)=35.13,p<0.001。事后比較發現,高限制性語境可預測詞的合理性與其他兩種條件均存在差異(0.19<MD<0.23,ps<0.001),高限制性語境不可預測詞與低限制性語境不可預測詞間沒有差異(MD=0.04,p=0.15)。材料參數見表2。最后,將所有實驗句按拉丁方順序分成3 組,每組135 句,每個水平下45 句。

表2 實驗1 材料屬性參數描述
2.1.4 實驗儀器與程序
采用加拿大SR Research 公司生產的EyeLink 1000 Plus 型號眼動儀,采樣頻率為1000Hz。刺激呈現在刷新頻率為144Hz、分辨率為1920×1080 像素的ASUS 液晶顯示屏上。材料為28 號宋體字,被試眼睛距離屏幕60cm,每個漢字視角約為0.9°。
實驗時,首先調整和固定被試位置。然后,呈現指導語,進行校準。校準成功后進入練習,被試對呈現的句子進行自然閱讀,并對隨后隨機出現的問題進行“是”“否”判斷,以確保被試認真閱讀。被試練習并理解后進入正式實驗,正式實驗中每三個試次進行一次重新校準,25%的句子后有問題。整個實驗大約需要30 分鐘。
2.2 結果
被試作答正確率80%以上,對句子進行了認真地閱讀。數據分析前按照以下標準對數據進行了刪除:(1)追蹤丟失試次(0.05%);(2)注視時間短于80ms 或長于800ms 注視(8.0%);(3)句子總注視點個數低于5 的試次(1.28%)。
利用R 軟件下的Lme4 包(1.1-25)(Bates,M?chler,Bolker,& Walker,2015)進行了線性混合模型分析。分析指標有跳讀(SKIP:第一遍閱讀中目標詞被跳過的概率)、首次注視時間(FFD:第一遍閱讀中在目標詞上首個注視點的持續時間)、凝視時間(GD:第一遍閱讀中從開始注視目標詞到首次離開目標詞期間所有注視點的持續時間總和)和總注視時間(TRT:目標詞上所有注視點持續時間的總和)(閆國利等,2013)。t/z值大于1.96 時,差異顯著(p<0.05)。有關目標詞的描述性統計見表3,統計分析結果見表4。

表3 實驗1 眼動指標平均值和標準誤
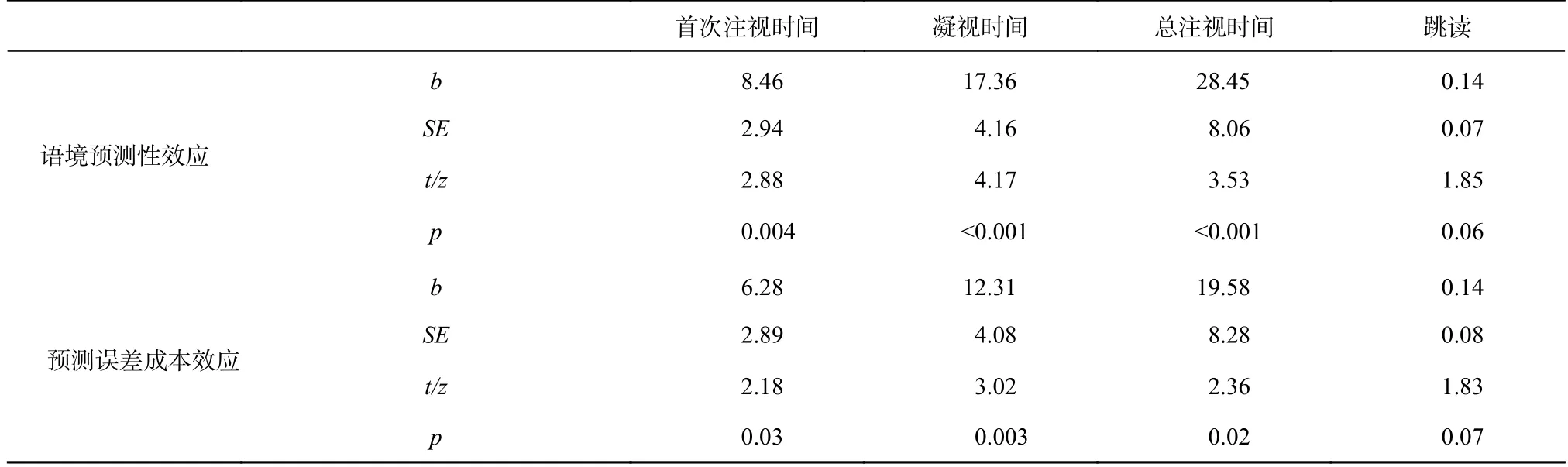
表4 實驗1 統計分析結果
由表3、表4 結果可知,注視時間上語境預測性效應顯著(|t|s>2.88,ps<0.004),跳讀上邊緣顯著(z=1.83,p=0.06)。在高限制性語境中,可預測詞的注視時間短于且跳讀高于不可預測詞。更重要的是,不可預測詞在高限制性語境中的注視時間顯著短于(|t|s>2.18,ps<0.05)且跳讀高于(z=1.83,p=0.06)低限制性語境,未表現出任何預測誤差成本。
由于高限制性語境可預測詞條件下的合理性與其他條件存在差異,研究將合理性看做協變量納入模型進行了分析,進一步明確合理性對實驗效應的影響。結果發現:跳讀上,合理性未對模型造成影響(χ2=0.27,p=0.60);首次注視時間上,合理性對模型產生了影響(χ2=9.24,p=0.001)。語境預測性效應不再顯著(t=0.22,p=0.83),不可預測性詞在高、低限制性語境中差異仍顯著(t=2.35,p=0.02);凝視時間和總注視時間上,合理性對模型產生了影響(GD:χ2=7.26,p=0.007;TRT:χ2=10.15,p=0.001),合理性效應顯著(GD:t=2.70,p=0.007;TRT:t=3.19,p=0.001),語境預測性效應顯著(GD:t=2.83,p=0.005;TRT:t=2.40,p=0.02),不可預測詞在高、低高限制性語境下差異顯著(GD:t=3.22,p=0.001;TRT:t=2.54,p=0.01)。
綜上所述,合理性主要使首次注視時間上的語境預測性效應不再顯著。凝視時間、總注視時間上語境預測性效應仍顯著。最重要的是合理性未對不可預測詞在高、低語境限制性下的差異表現造成了影響。
實驗1 可預測詞與不可預測詞間的語義相關性可能會促進不可預測詞的加工。因此,難以明確高限制性語境對不可預測詞的促進作用是由于語境對系列相關詞匯的等級平行預激活造成的,還是不可預測詞與特定可預測詞之間的高語義相關造成的。為了排除可預測詞與不可預測詞間語義相關性對不可預測詞的促進作用給預測誤差成本表現帶來的影響,實驗2 操縱可預測詞與不可預測詞的語義相關性,進一步考察了高限制性語境對語義無關不可預測詞加工的影響。
3 實驗2:高限制性語境對語義無關不可預測詞加工的影響
高限制性語境最主要的特征是限制了接來下詞匯的種類,很難在高限制性語境下實現對合理語義無關不可預測詞這一實驗水平的操縱。鑒于高限制性語境特點和操縱合理語義無關不可預測詞的沖突,實驗2 采用語義違背范式(semantic violation paradigm)(王穗蘋等,2009)控制可預測詞和不可預測詞間的語義相關性。不合理的語義違背詞既保證了接下來的詞是不可預測詞,又控制了不可預測詞與可預測詞語義不相關。在實驗2中,語義一致詞為符合高限制性語境預測的可預測詞匯,語義違背詞為不合理的不可預測詞。
實驗2 假設,若高限制性語境對語義無關不可預測詞造成了干擾,即存在預測誤差成本。那么,語義違背詞條件下,目標詞在高限制性語境中的加工慢于在低限制性語境中。若高限制性語境不會對語義無關不可預測詞產生干擾,即不存在預測誤差成本。那么,語義違背詞在高、低限制性語境中的加工沒有差異。
3.1 研究方法
3.1.1 被試
從天津市某大學招募了80 名被試,年齡17~25 歲(M=19.8 歲,SD=1.42 歲),兩名被試作答準確率低于80%,最終78 名被試的數據參與分析。所有被試均以漢語為母語,視力或矯正視力正常。整個實驗約20 分鐘,完成后可獲得一定報酬。
3.1.2 實驗設計
實驗為單因素四水平(高限制性語境語義一致詞、高限制性語境語義違背詞、低限制性語境語義一致詞、低限制性語境語義違背詞)被試內設計。材料舉例見表5。

表5 實驗2 材料舉例
3.1.3 實驗材料
實驗2 共80 組實驗句,每個句子平均22 個漢字(字數范圍為18~32 字)。語義一致詞和語義違背詞的詞頻和筆畫數沒有差異(詞頻:t=1.49,p=0.14;筆畫數:t=1.18,p=0.24)。詞頻庫同實驗1。12 名大學生進行了完形填空測驗。高、低限制性語境間語境限制性差異顯著(高限制性語境:M=0.89;SD=0.10;低限制性語境:M=0.23;SD=0.10;t=42.47,p<0.001),高限制性語境語義一致詞和低限制性語境語義一致詞的預測性差異顯著(t=76.84,p<0.001)。24 名大學生對句子合理性進行了7 點評定,語義一致詞分數高于5.5 分,語義違背詞分數低于3.5 分,兩者間合理性差異顯著(t=83.10,p<0.001)。最后,將所有材料按拉丁方順序分成4 組,每組共80 句,每個實驗水平下20 句。材料情況見表6。

表6 實驗2 材料屬性參數描述
3.1.4 實驗儀器與程序
儀器和程序同實驗1。
3.2 結果
數據分析方法和因變量眼動指標同實驗1。被試作答正確率均值80% 以上,說明被試對句子進行了認真地閱讀。按照以下標準對數據進行了刪除:(1)追蹤丟失試次(0.0 2%);(2)注視時間短于80 ms 或長于800 ms 注視(8.00%);(3)句子總注視點個數低于5 的試次(0.02%)。
與目標詞相關因變量指標的描述性統計見表7,統計分析結果見表8。

表7 實驗2 眼動指標平均值和標準誤

表8 實驗2 統計分析結果
語境預測性效應顯著(FFD:t=4.08,p<0.001;GD:t=3.35,p<0.001;TRT:t=3.64,p<0.001;SKIP:z=3.88,p<0.001),高限制性語境下語義一致詞的注視時間短于且跳讀多于低限制性語境條件。預測誤差成本效應不顯著(FFD:t=0.61,p=0.54;GD:t=0.77,p=0.44;TRT:t=0.74,p=0.46;SKIP:z=1.32,p=0.19)。整體結果表現為,相較于在低限制性語境中,語義一致詞在高限制性語境中的注視時間更短、跳讀更多。但對語義違背詞來說,在高、低限制性語境中沒有差異。
4 討論
本研究通過考察高限制性語境對接下來不可預測詞加工的影響,首次探究了漢語閱讀中的預測加工方式。結果發現,不管是在實驗1 中同一高限制性語境下不同預測性目標詞的加工,還是在實驗2 中高、低限制性語境下不同預測性目標詞的加工上,均表現出語境預測性效應。相較于不可預測詞,高限制性語境中可預測詞的注視時間更短、跳讀更多(劉志方等,2020;Zhao et al.,2021)。結果表明,在正常熟練的閱讀過程中,讀者會根據語境提供的信息對接下來的內容進行預測加工,以影響詞匯本身加工和整合效率。
最重要的是,實驗1 中,不可預測詞在高限制性語境中的加工快于低限制性語境;實驗2 中,語義違背詞在高、低限制性語境中的加工沒有差異。兩個實驗的結果均表明不存在預測誤差成本,即高限制性語境并沒有對實際出現的不可預測詞的加工造成干擾。根據等級預激活的觀點,讀者根據語境信息,按照不同的權重同時并行激活了一系列的詞匯(Staub,2015)。由于是不同程度地平行激活了系列詞匯,高限制性語境只會對不同預測程度的詞產生不同程度的促進作用,并不會對出現的不可預測詞造成額外的干擾。但是,根據詞匯預測觀的觀點,讀者根據前文的語境信息,首先激活完型概率最高的特定詞匯,當發現呈現的不是預測到的特定詞匯時,讀者需要首先抑制已經預測的特定內容,再對當前的詞匯進行加工,是一種串行式的詞匯加工過程。因此,高限制性語境不僅能促進可預測詞的加工,還會對意想不到的不可預測詞的加工造成干擾。因此,當前研究結果支持了等級預激活的觀點。實驗1 中,當可預測和不可預測詞語義高度相關時(例如:面包 vs.餅干),高限制性語境促進了不可預測詞的加工。但實驗2 控制語義一致詞和語義違背詞語義不相關后,仍未表現出預測誤差成本效應,這表明實驗1 中高限制性語境對不可預測詞的促進作用是由于平行的等級預激活造成的。
當前主要研究結果與拼音文字眼動研究發現一致(Frisson et al.,2017;Luke & Christianson,2016),即不存在預測誤差成本,主要預測加工方式未受到語言系統之間差異的影響。但不同于拼音文字的研究結果,實驗1 在詞匯加工的早期指標上就表現出了高限制性語境對語義相關不可預測詞的促進作用,在拼音文字的研究中,該效應只發生在了總注視時間等晚期指標上。這可能是因為漢語表意文字屬性使其獲取語義更加迅速,語境預測性對詞匯加工的促進作用發生得更加迅速和顯著。因此,漢語和拼音文字間書寫系統的差異對語境預測性的加工過程造成了量的差異,但卻未產生質的影響,即沒有改變語境預測加工策略。
在日常實際閱讀過程中,限制性很高的語境并不是十分常見,很少遇見預測程度很高的可預測詞。中等或低等預測程度的詞匯加工更為頻繁普遍(Frisson et al.,2017)。因此,高效無成本的等級預激活加工更符合實際的語言認知加工需求。另外,高限制性語境這種無干擾的促進作用也大大提升了閱讀效率和漢語新詞的學習效率(陳寶國,張媛玥,馬騰飛,2019)。
最后,閱讀不僅包含對詞匯的直接注視加工,還能在更早的預視中獲取詞長、正字法、語義以及句法等信息(臧傳麗,鹿子佳,張志超,2019)。跳讀上的語境預測性效應也在一定程度上反應了語境預測性對詞匯早期預視加工階段的影響(劉志方等,2020)。所以,整個詞匯加工過程中(預視加工階段,直接注視加工階段)都有可能產生預測誤差成本。但是,雙加工理論和有關預測誤差成本的ERP 研究結果均表明,語境對詞匯的干擾更可能發生在后期(Federmeier et al.,2007;Stanovich & West,1979)。因此,當前研究首要考察了在詞匯直接注視加工階段的預測誤差成本效應,后期研究可以通過控制實驗材料,測量副中央凹預視中前目標詞上的預測誤差成本效應,對早期的干擾進行進一步檢驗。
5 結論
相較于拼音文字,在漢語閱讀中,語境預測性對詞匯加工的促進作用發生的更加迅速、顯著,但卻采取了相同的預測加工方式—等級預激活。讀者利用高限制性語境以等級預激活的并行預測加工方式促進了對接下來的可預測詞的加工,但是高限制性語境并不會對無關不可預測詞的加工產生干擾。
猜你喜歡
音樂探索(2022年2期)2022-05-30 21:01:37
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫藥(2020年34期)2020-12-09 01:22:24
開放教育研究(2020年2期)2020-03-31 01:54:14
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
小天使·一年級語數英綜合(2019年8期)2019-08-27 02:23:00
小學科學(學生版)(2018年7期)2018-08-13 09:33:04
現代語文(2016年21期)2016-05-25 13:13:44
鄭州大學學報(醫學版)(2015年2期)2015-02-27 14:50:46
大連民族大學學報(2015年2期)2015-02-27 08:28:11
