基于BiLSTM+Self-Attention的多性格微博情感分類
2022-01-24 08:36:30馮媛媛劉克劍李偉豪
西華大學學報(自然科學版) 2022年1期
馮媛媛,劉克劍,李偉豪
(西華大學計算機與軟件工程學院,四川 成都 610039)
近年來,微博已成為最受歡迎的社交網絡平臺之一。人們可以通過微博隨時、隨地分享和交流信息,表達情感和發表觀點,實現信息的即時分享、傳播互動。截至2020 年10 月,微博月活躍用戶已達5.23 億。微博所攜帶的大量信息流尤其是公眾情感,對輿論起著重要作用。
情感分類是情感分析的研究主題之一,根據情感極性對文本進行分類。一般地,情感極性分為3 類:積極、中性和消極。現有的情感分類技術主要分為:基于情感詞典的分類方法、基于傳統機器學習的分類方法和基于深度學習的分類方法。基于詞典的方法主要利用情感詞典和語言規則進行情感分類。Turney 等[1]計算評論中的情感極性均值,并將其作為評論整體的情感極性。同時,有研究[2-4]表明,否定詞、程度副詞等對于判斷整個句子的情感極性有相當大的影響。王銀等[5]在大連理工大學的情感詞匯本體庫基礎上,構建了程度副詞詞典、否定詞詞典、網絡用語詞典、表情符號詞典以及關系連詞詞典5 個詞典,通過權值計算微博文本情感值。張公讓等[6]通過建立程度副詞詞典、否定詞詞典和情感詞典,對各家快遞服務的客戶評價實現了情感預測。雖然基于詞典的方法可以獲得很好的分類效果,但是該方法嚴重依賴于情感詞典,靈活性和適應較差。
基于傳統機器學習的方法通常是從語料庫中提取有效的文本特征,實現情感分類。Zhang 等[7]將條件隨機場(CRF)運用到文章句子的語境分析中,通過分析句子的語境,有效提取情感特征,實現情感分類。Gao 等[8]調查了用戶容忍度和商品知名度對情感分類的影響,提出了一種近似解碼算法(approached decoding algorithm)對商品評論進行情感分類。馮成剛等[9]比較了常用的3 種機器學習算法(SVM、NB 和K最鄰近算法)、3 種特征選擇方法(信息增益、互信息、加權似然對數)以及特征權重方法(布爾權重、詞頻權重,詞頻-逆詞頻)對中文微博情感分類的影響。Haque 等[10]利用線性SVM、梯度下降和隨機森林等機器學習方法對亞馬遜3 個種類的商品評論進行情感分類,其中SVM 在音樂領域的分類效果最好。基于傳統機器學習的情感分析方法分類效果趨于更準確,但它依賴于帶有標記的語料庫的質量。
基于深度學習的方法主要是利用詞向量對文本中的詞語進行表示,進而構建句子級或篇章級的語義表示,通過采用深度學習模型學習文本中的情感特征,實現情感分類。目前大多數情感分類主要采用基于深度學習的方法。胡榮磊等[11]將長短記憶網絡(LSTM)與注意力機制結合,對酒店評論文本進行了情感分析。Xu 等[12]在LSTM的基礎之上,引入了一種緩存機制來幫助循環單元更有效地保存情感信息。貴向泉等[13]提出將時序卷積網絡(TCN)與BiLSTM+Attention 模型相融合的文本情感分類方法,利用TCN的因果卷積和擴張卷積結構獲取更高層次的文本序列特征,并通過雙向長短期記憶網絡進一步提取全局特征,最后,引入自注意力機制(self-attention)幫助模型優化特征向量,提高情感分類的準確度。
由于微博有字數限制,文本偏口語化、生活化,使用網絡流行語和表情符,因此,對于實現微博文本情感分類來說是一個挑戰。學者們提出了一些方法來提高情感分類的準確率。金志剛等[14]結合表情符和文本情感特征,通過CNN 捕獲局部特征,并將其作為情感分類器的輸入,訓練出微博情感分類器。李勇敢等[15]從中文微博觀點句識別、情感傾向性分類和情感要素抽取3 個方面實現了中文微博情感自動分析。針對現有大多數微博文本情感分析未結合深度學習模型和情感符號的情況,張仰森等[16]提出了一種雙重注意力模型的方法,構建了一個包含情感詞、否定詞、程度副詞、網絡詞和微博表情符的微博情感符號庫,通過將注意力模型和情感符號相結合,有效增強了捕獲微博情感語義的能力。Barbosa 等[17]在普通文本特征的基礎上,提取了微博文本特有的一些特征,包括轉發、回復、hash-tag、URL、標點符號、表情符號以及以大寫字母開頭的單詞數目等,采用有監督的方法實現Twitter 文本的情感分類。
值得注意的是,目前大多數情感分類研究忽略了用戶性格這一因素。心理學研究表明,性格會影響人們的表達方式。不同性格的人在表達情感時,表達方式會有所不同[18]。心理學領域的“大五”理論,定 義 了5 種 人 格 特 征,分 別 是 開 放 性(openness)、責任性(conscientiousness)、外向性(extroversion)、宜 人 性(agreeableness)、神 經 質(neuroticism)。外向型人格的人在表達時使用的詞語通常與社交活動、家人相關。擁有高宜人人格的人更具有同情心、樂于助人,與人相處融洽。責任型人格的人通常比較可靠,有責任心,自律。劉亦真[19]基于微博平臺,分析研究了不同人格傾向的微博用戶在情緒表達上的特點。Verhoeven 等[20]在短文數據集上訓練性格分類模型,將其輸出作為元特征來預測Facebook 用戶的性格特征。張巖峰等[21]利用微博用戶的文本及行為等特征,使用提升決策樹、支持向量機以及貝葉斯邏輯遞歸3 種機器學習方法進行實驗,得出通過微博的文本特征和非文本特征都能分析出用戶人格特質的結論。
在以上情感分類研究中,大多數在提取文本情感特征時,并沒有考慮到用戶性格特征,但也有研究者結合了用戶性格特征。袁婷婷[22]通過建立性格詞典并利用LTSM 模型對不同性格的文本進行情感預測,但忽略了上下文語境信息也會影響情感分析。賈莉等[23]在結合用戶性格信息的基礎上利用BiLSTM 模型,在微博文本情感預測上雖然有所提升,但未充分利用到文本的局部信息。吳小華等[24]提出了BiLSTM 結合自注意力機制的模型來進行情感預測,但沒有考慮到性格對語句表達有所影響這一因素。為此,本文在結合用戶性格信息的基礎上,提出了一種利用雙向長短期記憶網絡和自注意力機制來實現微博情感分類的方法。該方法通過提取不同性格的用戶情感特征,分別訓練出各自的基本分類器,再采用集成學習策略進行結果融合,進而實現情感分類。
1 相關研究工作
1.1 大五人格模型
大五人格模型是研究者運用最廣的一種模型。大五人格模型將人格劃分為5 個維度:開放型、外向型、宜人型、責任型和神經質型。表1 列出了不同人格的主要表現。
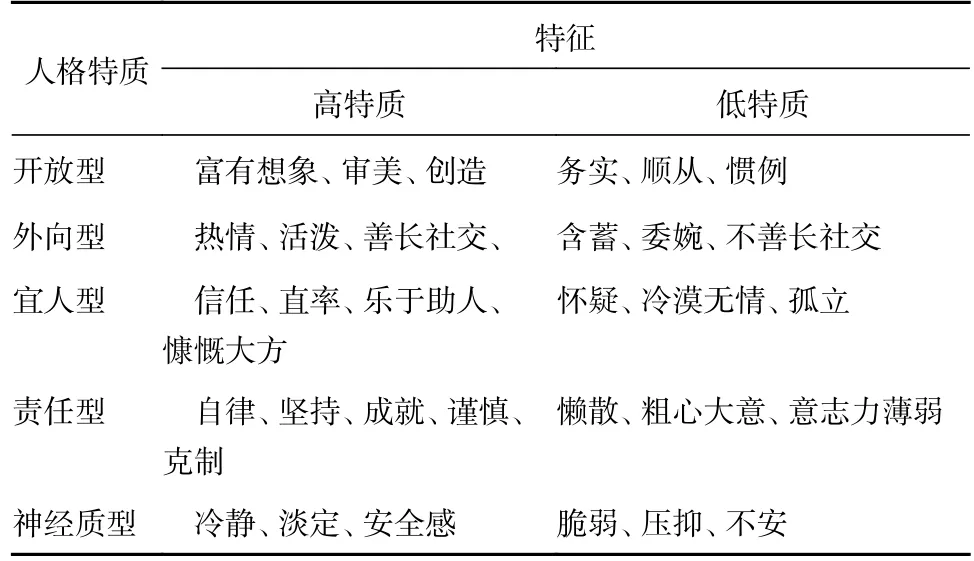
表1 大五人格特征
在對微博文本進行情感分析時,筆者發現不同性格有不同的表達特點,例如:高外向型人格在表達時通常使用“聚會”“團隊”“老鐵們”等與家人、朋友以及社交相關的詞語;低外向型人格則會使用“宅”“安靜”等詞語。為了能夠增強這些詞語對情感表達的貢獻率,更好地提取不同性格的深層次情感特征,本文在BiLSTM的基礎上采用了自注意力機制對微博中詞語的重要程度進行權重分配。
為了有效提取不同性格的情感特征,需要對微博用戶的性格進行預測和分類,因此,本文提出了一種基于規則的性格分類方法來對微博用戶的性格進行預測和分類,根據性格分類結果,將微博文本進行分組,并分別提取不同性格分組的文本情感特征。該方法能夠充分利用用戶性格信息有效提取情感特征。
1.2 雙向長短期記憶網絡(BiLSTM)
循環神經網絡(RNN)是傳統前饋神經網絡的延伸。然而,標準的RNN 卻有梯度消失和梯度爆炸問題。為了解決這2 個問題,Hochreiter 等[25]提出了長短期記憶網絡(LSTM),但是,LSTM 只能獲取正向的信息,無法獲取逆向的信息。對于文本來說,理解前后文信息對其更加有幫助。BiLSTM 由一個正向的LSTM 和一個逆向的LTSM 所組成,能夠同時獲取上下文信息[26]。BiLSTM 結構圖如圖1 所示。

圖1 BiLSTM 模型結構

1.3 自注意力機制(self-attention)
自注意力機制[27],就是將注意力集中在需要重點關注的目標上,分配更多的權重,獲取目標的更多細節信息,忽略不重要的信息。自注意力機制是對自己本身的詞語進行Attention 計算,不用考慮直接距離長短,能夠充分考慮句子之間、不同詞語之間的語義及語法聯系,捕獲句子的內部結構。其計算公式為

式中:Q,K,V為模型中計算得到的向量矩陣;f(Q,KT)計算Q和K的相似度;dk為詞向量維度;起調節作用,通過Softmax 函數進行歸一化。
2 結合BiLSTM 和自注意力機制的微博情感分類模型(P-BiLSTM-SA)
基于性格特征,結合雙向長短記憶網絡和自注意力機制,本文提出了一種BiLSTM 和自注意力機制相結合的微博情感分類模型(P-BiLSTM-SA 模型),總體結構如圖2 所示。首先,將用戶性格相似的文本歸為一類,因為相同性格的人,其表達方式具有相似性;接著,對文本進行預處理并利用word2vec 訓練出詞向量,形成詞向量矩陣;然后,將各組詞向量矩陣分別作為BiLSTM的輸入,經過BiLSTM 層輸出后進入Self-Attention 層,對特征進行權重賦值,提取深層次的情感特征,從而訓練出5 個基于不同性格的情感分類器和一個通用情感分類器;最后,根據集成學習融合分類器預測結果,輸出最終情感分類結果。圖2 中:E、A、C 分別表示外向型、宜人型、責任型;H 和L 表示性格的高、低特質,例如HE 為高外向型,LE 為低外向型;All 表示通用文本,即數據集中所有微博用戶的文本。

圖2 模型總體結構
2.1 基于微博用戶性格的文本分組
本文采取基于規則的方法來對用戶性格進行預測。在進行性格預測時,由于開放型和神經質型較難區分[28-29],所以本文只考慮了其余3 種人格:外向型、宜人型和責任型。
2.1.1 特征表示
微博用戶發表的微博內容包括了圖片、視頻、地理位置信息等。同時,用戶在微博中的交互行為[30]會在一定程度上反映出該用戶真實性格。為此,本文結合了文本信息和用戶行為特征綜合預測用戶性格。表2 示出了用戶微博信息中的具體特征表示。

表2 特征表示
2.1.2 性格分類
熵權法是一種確定多因素綜合評價問題中各因素權重系數的有效方法。本文利用該方法計算影響性格判定的指標權重,從而計算出影響性格判定的最終值。具體步驟如下。
1)將各指標進行標準化,得到標準化值Y,其中Ypc,Yv,Yl,Ym,Yli,Yc,Yre,Yf,分別為指標Photo_Comment_Num,Video_Num,Location_Num,Mention_Num,Like_Num,Comment_Num,Retweeted_Num,Follower_Num的標準化值。
2)根據Ej=計算出各指標的信息熵。通過信息熵計算出各指標的權重。Ej表示第j個指標的信息熵;pij表示在第j個指標前提下,第i個用戶在該指標中的概率。其權重計算公式為

式中Wi表示第i個指標的權重,即Wpc,Wv,Wl,Wm,Wli,Wc,Wre,Wf,分別為指標Photo_Comment_Num,Video_Num,Location_Num,Mention_Num,Like_Num,Comment_Num,Retweeted_Num,Follower_Num的權重。
3)計算影響性格判定的最終值,并根據表3進行性格判定。表中:C(u)、J(u)、Y(u)分別表示微博用戶u的微博內容豐富程度、交互主動性以及影響力;k1,k2,k3,k4,k5,k6為判定式的閾值。

表3 判定規則
a.外向型人格。
外向型人格的人一般喜歡參加各類社交活動,與他人分享自己的經歷[17],所以發表的微博數量較多,通常帶有圖片、小視頻或者地理位置信息,并且能獲得較多的點贊和評論。此外,外向型的人與他人的互動也較為頻繁。因此,外向型的人往往會在他們的微博中更多的提及(@)他人,參與互動;具有內向型人格的人發表較少的微博,獲得的點贊、評論以及轉發也非常少。微博用戶u發表的微博內容特征計算公式為

b.責任型人格。
具有責任型人格的微博用戶發表的微博更傾向于表達自律、責任感及條理等內容,發表的微博能夠受到更多的關注,影響力較大,受到轉發數、點贊數以及@數這3 個因素影響。微博用戶u的微博影響力[31]計算公式為

c.宜人型人格。
宜人性型人格的人性格開朗,助人為樂、謙遜、值得信賴,充滿正義感,擁有較多的粉絲,由于比較重視自己的形象,所發布的微博通常充滿積極性和正能量。被轉發微博的數量越多,該用戶的交互主動性[30]就越高,同樣的,粉絲數量對交互主動性也有影響。微博用戶的交互主動性計算公式為

各閾值的確定依據了微博用戶分別在外向型、責任型和宜人型3 類性格計算中得到的各類性格最終值的平均值和標準差。為了平衡數據,取標準差的算術平方根。如果其值高于平均值與算術平方根之和,則該用戶為高特質;如果其值低于平均值與算術平方根之差,則該用戶為低特質。
2.2 結合BiLSTM 和self-attention的情感分類器構建
在本文中,基于用戶性格以及通用文本的情感分類器皆是由BiLSTM+self-attention 機制訓練得到,網絡結構如圖3 所示。

圖3 基于性格分類的情感分類器構建
2.2.1 BiLSTM 層
對于微博文本,為了更準確地理解詞的語義信息,需要考慮前后文本聯系,且詞與詞之間具有長程相關性。雖然LSTM 能夠捕獲較長距離的語義依賴關系,但是普通的LSTM 只能捕捉正向的語義信息,忽略了逆向的語義信息。BiLSTM 模型由一個正向的LSTM 和一個逆向的LSTM 組成,能夠同時捕捉句子的前后文信息。因此,本文采用BiLSTM 模型對微博文本進行語義信息編碼。對于一條微博文本{v1,v2,···,vt}(vt∈Rd,vt為詞向量矩陣,d為詞向量維數),則BiLSTM 模型輸出為h={h1,h2,···,hN},H∈RN×d,N為句子長度,d為隱藏層維度。
2.2.2 self-attention 層
自注意力機制通過對BiLSTM 每一個輸出狀態hi加權,從而得到一個既聯系上下文信息又重點突出不同性格情感特征的微博句子表示向量矩陣,為

式中:C表示句子中每個詞加權后的特征表示;?i表示第i個詞對于整條微博文本的重要程度,其計算公式為

2.2.3 情感分類
模型的最后一層為全連接網絡層,采用Softmax 函數作為激活函數,計算微博文本各個情感標簽的預測概率,其計算公式為

式中:W=[w1,w2,···,wn]為全連接網絡層的權值;b=[b1,b2,···,bn]為偏置數。
2.3 情感分類器分類結果融合


圖4 情感分類器預測結果融合
3 實驗與分析
3.1 實驗數據
本文實驗所用的數據來自于從新浪微博爬取的228 個微博用戶數據,包括用戶的微博內容和作者基本信息。數據集中,微博文本共10 萬1 649 條。刪除轉發微博,并進行清洗過后,采用半自動化的方式對文本進行情感極性的標記,其中,積極微博有2 萬5 138 條,消極微博有2 萬3 783 條。本文按照7∶2∶1的比例將微博文本分為訓練集、驗證集和測試集。
同一位微博用戶可能同時具有多種性格,因此會屬于不同的性格集合。根據所爬取微博用戶的基本信息,分別計算微博用戶在外向型、宜人型和責任型的相應數值,在此基礎上分別得到3 類性格類型的均值和標準差,并取標準差的算術平方根。根據2.1.2 節的方法計算得到:外向型的平均值為152.46,標準差的算數平方根為16.22;宜人型的平均值為680.01,標準差的算數平方根為45.27;責任型的平均值為1284.55,標準差的算數平方根為80.16。因 此,閾 值k1,k2,k3,k4,k5,k6分 別 為168.69,136.24,725.28,634.74,1 364.71,1 204.39。其中,在爬取的微博數據集中,低責任型性格的微博文本數量很少,所以在本文中不予考慮。基于微博用戶性格的各文本分組的數據分布詳情如表4所示。

表4 數據集分布
3.2 模型實驗參數設置
在實驗中,詞向量為200 維,優化函數為Adam,損失函數為多元交叉熵。各模型具體參數如表5 和表6 所示。

表5 P-BiLSTM 和P-LSTM 參數設置

表6 BiLSTM-SA 和P-BiLSTM-SA 參數設置
3.3 實驗指標評價
為了驗證本文提出模型的有效性,本文采用以下4 個指標進行評價。
1)準確率(accuracy):被模型正確預測的微博文本數量占所有微博文本數量的比例。
2)召回率(recall):被正確預測為積極(消極)的微博文本數量占實際為積極(消極)的微博文本數量的比例。
3)精確率(precision):被正確預測為積極(消極)的微博文本數量占所有被預測為積極(消極)的微博文本數量的比例。
4)F1值(F1score):由精確率和召回率的加權處理得到。F1值越大,模型效果越好。

3.4 微博情感分類實驗
3.4.1 模型對比實驗
在本文模型中,采用了自注意力機制來學習不同性格微博用戶的文本表達特征。在采用相同數據集的基礎上,將本文提出的模型P-BiLSTMSA 與P-LSTM[22]、P-BiLSTM[23]以及未融入性格因素的模型BiLSTM-SA[24]進行了對比。其對比實驗結果如表7 所示。
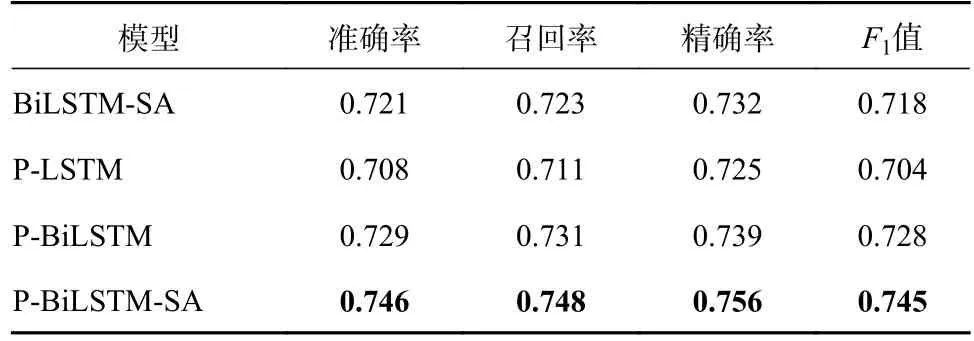
表7 模型實驗對比結果
1)與BiLSTM-SA 相比,P-BiLSTM-SA的情感分類效果更好,說明融入性格因素對于微博情感分類具有一定的幫助。
2)模型BiLSTM-SA 和模型P-BiLSTM,在4 種指標上的表現相接近,說明在模型訓練過程中,自注意力機制能獲取到更深層次的情感信息,而且根據性格對文本分類也有利于模型提取不同性格的特征。2 種方法都對微博文本的情感分類有效。
3)與P-BiLSTM 相比,P-BiLSTM-SA 在準確率、精確率、召回率和F1上平均提升了0.017,說明利用自注意力機制關注文本的局部關鍵信息對情感分類有一定的幫助。
總之,對比其他3 個模型,本文模型在準確率、召回率、精確率和F1值上的效果更優。說明事先根據用戶的性格對微博文本進行分類,使得模型中的自注意力機制能夠有針對性地學習到不同性格的深層次情感特征,從而有利于提升情感分類效果。同時,通過集成學習方法融合各分類器輸出,減少了泛化誤差。
3.4.2 實例實驗結果對比
性格影響人的表達方式。為了驗證性格對情感分類的有效性,本文選取了另外爬取的11 位微博用戶的微博文本(約1 400 條),基于P-BiLSTMSA 模型和BiLSTM-SA 模型再次進行了測試,測試結果如表8 所示,P-BiLSTM-SA 模型在4 個評價指標上的表現明顯優于BiLTM-SA,再次證明了本文所提出模型的有效性。為了更加形象地對比這2 個模型的預測效果,表9 給出了一些實例的具體實驗結果對比。可以看出:HC 性格的用戶通常具有責任心、認真且自律;HE 性格的用戶充滿熱情,活潑;HA 性格的用戶通常直率、大方;“累”“痛苦”往往是LE 性格的用戶在表達消極情緒時所具有的特征;文本(3)和文本(5)雖然都在闡述某人能力不錯,但由于不同性格的表達方式有所差異,所以2 個文本表達的情感完全不同;文本(6)和文本(7)都在表達積極的情感,高特質用戶傾向于積極向上的表達方式,而低特質用戶的表達方式則是恰好相反,說明發表這2 條文本的微博用戶雖然都是宜人型和外向型人格,表達的情感極性也相同,但因為這2 個用戶在兩類性格方面的高低特質不同,各自表達情感的方式也就完全不同。本文提出的模型P-BiLSTM-SA 能在訓練中更好地學習到這些深層次情感信息,從而提升了微博的情感分類效果。

表8 P-BiLSTM-SA 與BiLSTM-SA 實驗結果對比

表9 模型P-BiLSTM-SA 和模型BiLSTM-SA 部分實例預測結果對比
4 結論
本文基于不同性格的微博用戶在表達情感時各不相同的特點,提出了一種結合性格因素的深度學習模型P-BiLSTM-SA。該方法既考慮到BiLSTM能學習文本前后文語境信息,兼顧了全文整體特征的優勢,又利用self-attention 機制表示不同特征的重要性,捕獲了深層次的情感特征。最后通過實驗驗證了本文方法的有效性。
在互聯網上,表情符號、顏文字等也是人們表達情感的途徑之一,未來可考慮將這些因素納入情感分析之中。同時,許多用戶在微博上采用多語言混合的方式表達情感,比如:“我今天very happy”,未來可考慮對此類文本進行語碼轉換以提升情感分類效果。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
