改進的無約束優化3D-DV-Hop定位算法*
2022-01-24 02:21:06張晶,李煜
計算機工程與科學 2022年1期
張 晶,李 煜
(1.昆明理工大學信息工程與自動化學院,云南 昆明 650500;2.云南梟潤科技服務有限公司,云南 昆明 650500;3.昆明理工大學云南省人工智能重點實驗室,云南 昆明 650500;4.昆明理工大學云南省計算機技術應用重點實驗室,云南 昆明 650500)
1 引言
無線傳感器網絡WSNs(Wireless Sensor Networks)是由許多具有感知和通信功能的傳感器節點部署在某個區域中組成的感知網絡[1],隨著科學技術的發展和人民生活水平的日益提高,傳感器的身影已經隨處可見。比如,畜牧業中羊群的檢測與跟蹤,森林火災的檢測,甚至戰爭中敵軍的行動檢測等等。傳感器網絡感知的信息很重要,可是在更多時候,人們更需要信息的發生位置[2]。為此,國內外的一批學者對無線傳感器網絡的定位算法進行了深入研究。由于實際部署的地點往往是三維空間而少有二維平面,因此本文主要研究傳感器網絡的三維定位問題。
目前根據是否需要實際測量節點之間的距離,無線傳感器網絡的定位算法分有2種[3]:一種是需要給傳感器附加額外裝置來獲取節點之間的間距(稱為測距算法)。這種算法更精準,但是由于需要添加額外的硬件設備也使得這種算法的部署對節點成本的要求較高[4],不適合大型區域的監測。另一種是不需要添加任何其他硬件設備對節點間間距進行測量,只需要依靠網絡拓撲結構即可完成定位的非測距算法。這種算法定位精度低,但由于其相對測距算法而言節點造價低,適合于大型無線傳感器網絡的監測,成為近些年研究的熱點。本文要探討的就是非測距算法中的典型算法——DV-Hop三維定位算法。
DV-Hop三維定位算法可以從3個方面進行優化:跳數優化、平均跳距優化以及對未知節點的估計。文獻[5]提出新的平均跳距計算方法,對定位精度有一定優化,但是計算時采用的跳數未經優化,本身就會引入誤差,其次最后采用傳統極大似然估計法對節點進行定位,不能將定位誤差最小化。文獻[6]對平均跳距進行優化,同時升級輔助錨節點以提高定位覆蓋率,但是使用遺傳算法計算節點位置,過多的迭代次數增加了節點計算開銷。文獻[7]的算法在第2階段使用蛙跳算法改進跳距誤差,并在第3階段使用混合遺傳-粒子群算法,提高了定位精度,但大量的仿生計算也極大增加了傳感器節點的功耗和定位所需的時長,對于節點能量有限的傳感器來說是不合適的。文獻[8]使用2種灰狼算法對平均跳距進行優化,對精度有一定提升效果,但是未對跳數進行優化,且使用的最小二乘法沒有考慮到權值誤差最小化問題。
綜上所述,現有大多數三維定位算法都是采用仿生算法或者機器學習[9]的算法進行優化,雖然取得了一定的效果,但是對于能量有限的傳感器而言,計算任務過于繁重。然而最小二乘法[10]的整體誤差最小化思想又無法對未知節點進行精確求解。本文針對傳統DV-Hop三維定位算法定位精度低,且傳感器節點能量有限不適合進行大量計算和通信的特點,對DV-Hop算法進行改進。針對DV-Hop三維定位算法的定位方式,本文從3個方面對其進行優化:(1)采用二通信半徑(分別為R和0.5R)優化跳數值;(2)采用平方代價函數計算跳距,并對其進行加權優化;(3)使用Lagrangian乘子法求解未知節點方程組,將最小二乘的整體誤差最小化轉換加權誤差最小化,使用加權誤差最小化的思想來對未知節點進行定位計算。最后通過4種算法進行實驗,結果表明,本文算法在不需要進行大量計算的基礎上,能夠大大提高節點定位精度,降低誤差率。
2 傳統DV-Hop三維定位算法和誤差原因探討
2.1 傳統DV-Hop三維定位算法
傳統DV-Hop三維定位算法包括3個步驟,分別是:
Step1確定最小跳數值。在開始組網過程中,每個錨節點使用通信半徑R將包含自身編號id、所處GPS定位信息和跳數值為0的數據包發送給鄰居節點,并且每經過一次鄰居節點的轉發就對跳數值增加1。當鄰居節點(可能是未知的節點或錨節點)接收到該類數據包之后,分2種情況處理:若自身已經接收到該id編號的數據包,則對比路由表中具有相同id編號的數據包和接收到的數據包的跳數值大小,如果接收到的數據包中的跳數值比存儲的小,則用接收到的跳數值替換已存儲的跳數值;若接收到數據包中的跳數值大于存儲在路由表具有相同id編號的跳數值,則舍棄本次接收到的數據包。如此重復,便能得到對于各錨節點而言的最小跳數值。
Step2計算錨節點的平均跳距值和未知節點與各錨節點的距離。通過Step 1獲取到與各錨節點之間的最小跳數值之后,在傳統算法中,錨節點的平均跳距值的計算如式(1)所示:
HopSizei=
(1)
其中,j=1,2,…,m且i≠j,m為錨節點數量,(xi,yi,zi)和(xj,yj,zj)是由GPS定位出的錨節點i和錨節點j的三維位置信息,hij為錨節點i距錨節點j的最小跳數(由Step 1得出)。
計算出所有HopSizei后,每個錨節點使用通信半徑R對其計算出的HopSizei進行廣播,未知節點p只存儲第1次接收到的平均跳距值。當未知節點p接收到錨節點i傳來的HopSizei時,使用式(2)計算其與各錨節點的估計距離:
dp,j=HopSizei×hpj
(2)
其中,dp,j表示未知節點p與錨節點j在三維空間中的估計距離,j=1,2,…,m。
Step3未知節點坐標估計。本文令未知節點p的三維位置信息為(x,y,z),由GPS定位的第i個錨節點的三維位置信息為(xi,yi,zi),其中i=1,2,…,m,根據Step 2計算出的p與各錨節點的估計距離d1,d2,…,dm,可以利用極大似然估計法列出如式(3)所示的方程組:
(3)
式(3)的矩陣形式為AX=B,其中,
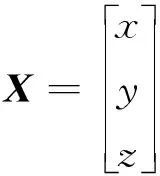
B=
使用最小二乘法,可以解得:
X=(ATA)-1ATB
(4)
2.2 算法誤差產生原因
在傳統DV-Hop三維定位算法中,對跳數的估計是不精確的,如圖1所示。

Figure 1 Schematic diagram of hop error圖1 跳數誤差示意圖
從圖1中可以看出,未知節點a與錨節點i的距離大約為0.5R,未知節點b與錨節點i的距離為R,但是由于未知節點a和b在傳統DV-Hop算法中的跳數值均為1,導致節點a估算的距離與實際的距離0.5R差別很大,引入了接近一倍的誤差,降低了定位精度。定位誤差產生過程如圖2所示。

Figure 2 Generation process of positioning error圖2 定位誤差產生過程
在圖2中,錨節點i,k與未知節點a的距離為R,錨節點j與未知節點a的距離略小于0.5R,此時傳統DV-Hop三維定位算法依然將其跳數值處理為1,其與i、k和j的距離本應為1*HopSize,1*HopSize和0.5*HopSize,卻由于跳數值為1變為1*HopSize,1*HopSize和1*HopSize,由此造成了定位誤差。
其次,傳統DV-Hop三維定位算法處理每個錨節點的平均跳距時,采用的代價函數如式(5)所示:
(5)
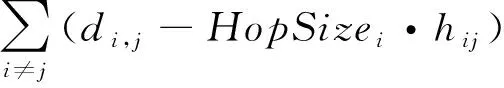
最后,傳統DV-Hop三維定位算法采用極大似然估計[11]的思想列出的方程組并沒有考慮誤差的權值,且使用最小二乘法對方程進行求解,然而最小二乘法在矩陣接近奇異時的求解也十分不理想,因此造成了2方面誤差的產生。
3 改進的DV-Hop三維定位算法
由于傳統DV-Hop三維定位算法的一系列缺點[12],本文結合無線傳感器網絡的特點,從3個方面分別進行改進。
3.1 最小跳數值的修正
傳統DV-Hop三維定位算法在獲取最小跳數值時,只采用了一個通信半徑[13],這樣做的缺點有:若通信半徑過大,則會造成最小跳數值極不準確;若通信半徑過小,則會造成網絡連通性很差,甚至出現盲節點。為此本文提出二通信半徑的思想:
在執行Step 1之前,錨節點使用通信半徑的一半(0.5R)傳播數據包,相鄰節點接收到數據包存儲在數據表中,考慮到傳感器節點特點,相鄰節點并不轉發數據包,隨后,錨節點使用通信半徑R對數據包(同Step1)進行洪泛,以此獲得修正的跳數值,從而使得節點之間的最小跳數值更準確。
3.2 平均跳距的改進
3.2.1 采用平方代價函數計算HopSize
在傳統DV-Hop三維定位算法中,采用代價函數f1的計算方式不理想,所以本文采用平方代價函數f2計算平均跳距值,如式(6)所示:
(6)
對HopSizei求偏導,并令其值為0,即:
(7)
則可以求解出平均跳距值HopSizei如式(8)所示:
(8)
3.2.2 平均跳距的加權
DV-Hop的定位實質上與節點的拓撲有著密切的關系,當未知節點與多個錨節點之間的距離和跳數均相差不大時,單單依靠一個錨節點的平均跳距就會產生相當大的誤差,但是若采用全部錨節點進行加權,則會增加不必要的計算量,因此應當有選擇性地選擇錨節點的個數。為此,本文采用對距未知節點最近的3個錨節點引入權值的思想,僅對距離未知節點最近的3個錨節點引入權值1,其余錨節點權值均為0,即只使用3個錨節點的平均跳距信息。由于這3個錨節點與未知節點的距離是有區別的,越靠近未知節點的錨節點越能反映出未知節點周圍的拓撲情況,使用該錨節點的平均跳距的權重也應當越大。本文使用Wi來表示錨節點i的平均跳距對于未知節點的權重比例,如式(9)所示:
(9)
其中,i、j和k分別是與未知節點距離最近的3個錨節點,Ni、Nj和Nk分別是未知節點與錨節點i、j和k經過最小跳數修正后得出的跳數值。
在本文中,未知節點p平均跳距采用式(10)進行計算:
(10)
3.3 無約束的Lagrangian乘子法
3.3.1 構造無約束方程組
傳統DV-Hop三維定位算法,幾乎都是使用蛙跳算法、差分進化算法和遺傳算法等一類仿生算法來求解式(3),不可否認這些算法都相當優秀,但是過多的迭代次數和龐大的計算量加劇了傳感器網絡的能量消耗。本文使用無約束的Lagrangian乘子法對未知節點進行求解。

(11)
用前m-1個方程依次減去最后一個方程并展開得到式(12):
(12)
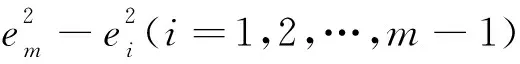
(13)
令:
ai=2(xm-xi)
bi=2(ym-yi)
ci=2(zm-zi)
αi=-2di
β=2dm
則式(13)可以寫成如式(14)所示形式:
(14)
式(14)的矩陣形式為CY=D,其中,
Y=[x,y,z,e1,e2,…,em]T
D=[D1,D2,D3,…,Dm-1]T
經過上述一系列步驟,求解問題轉換為式(15)所示的約束問題:
s.t.CY=D
(15)

為體現出誤差的權值性,本文在此引入權值矩陣Q對誤差項進行加權,從而將問題轉化為權值誤差最小化問題:
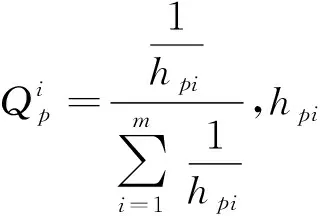
于是約束問題轉換為式(16)所示形式:
mineTQe
s.t.CY=D
(16)
使用Lagrangian乘子法將式(16)的約束問題轉換成無約束問題,如式(17)所示:
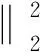
(17)
其中,λ為Lagrangia乘子,λ>0且為常數。
3.3.2 無約束方程的求解
首先令f對矩陣Y求梯度矩陣為:
(18)
f對矩陣Y的Hessian矩陣為:
H[f]=2(Z+λCTC)
(19)
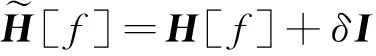
H[f]=2(Z+λCTC+δI)
(20)
其中,δ為擾動因子且δ>0,I為m+3階單位矩陣。
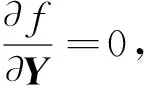
Y=(Z+λCTC)-1λCTD
(21)
由于H[f]為正定矩陣,所以Y=(Z+λCTC+δI)-1λCTD,至此,可以解得未知節點的坐標 。
4 仿真結果及分析
4.1 仿真環境及評價指標
為驗證本文算法與傳統算法、改進算法1、改進算法2的定位精度,在Matlab 2016a中進行仿真實驗。其中改進算法1采用本文提出的跳數、跳距優化及最小二乘法的策略;改進算法2采用本文提出的跳數、跳距優化及粒子群算法的策略。實驗場景為邊長均為100 m的山區地形環境,并于其中隨機投放未知節點和錨節點[14],如圖3所示。
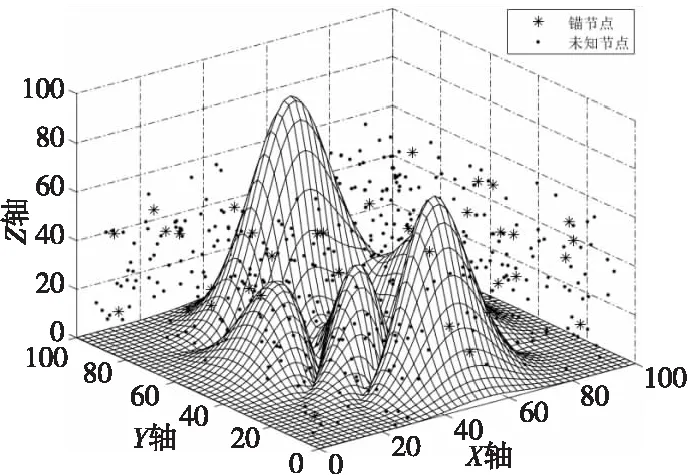
Figure 3 Node 3D distribution map圖3 節點三維分布圖
本文使用式(22)所示的未知節點平均定位誤差作為評價算法優劣的標準[15]:
Avg_error=
(22)
其中,(xi,yi,zi)為未知節點的真實三維坐標,(x′i,y′i,z′i)為通過算法求出的未知節點的三維坐標,n為實驗中未知節點的個數。
4.2 仿真結果分析
本文從錨節點數、通信半徑和節點總數3個方面來對4種算法進行分析討論。
4.2.1 錨節點數與平均定位誤差分析
在邊長均為100 m的山區地形環境隨機投放200個節點,且實驗采用的通信半徑均設置為40 m,觀察當錨節點比例變化時,對4種算法定位誤差的影響,其中錨節點比例分別取0.1,0.15,0.2,0.25,0.3,0.35,0.4,0.45,0.5。實驗結果為各類算法運行100次的均值,并繪制變化趨勢圖,如圖4所示。
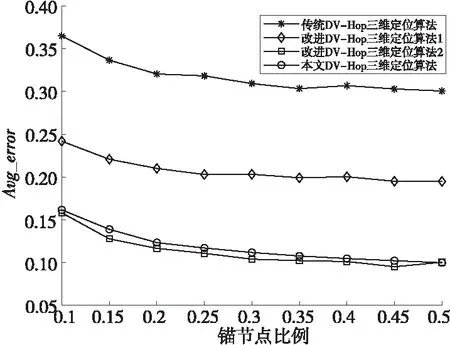
Figure 4 Trend of anchor node proportion and average positioning error圖4 錨節點比例與平均定位誤差的關系變化趨勢圖
從圖4中可以看出,4種算法的平均定位誤差均隨著錨節點比例的增加而下降,且改進算法2的平均定位誤差略低于本文算法的。在整個實驗過程中,傳統算法、改進算法1和改進算法2的平均定位誤差分別為0.318 1,0.207 6和0.113 0,本文算法的平均定位誤差為0.118 6。具體變化情況如表1所示。

Table 1 Average positioning errors under different anchor node proportion
從表1中可以得出,在錨節點比例為0.1時,本文算法相對傳統算法、改進算法1和改進算法2的平均定位誤差分別降低了0.203 2,0.080 2,-0.003 5;在錨節點比例為0.3時,本文算法相對傳統算法、改進算法1和改進算法2的平均定位誤差分別降低了0.197 5,0.091 5,-0.007 8;在錨節點比例為0.5時,本文算法相對傳統算法、改進算法1和改進算法2的平均定位誤差分別降低了0.200 8,0.095 1,0.000 7。由此可知本文算法不論在何種錨節點比例情況下,相對于傳統算法均能將平均定位誤差降低0.20左右,相對于改進算法1均能將誤差降低0.09左右,相對于改進算法2而言,本文算法仍具有與其相當的精度。
4.2.2 通信半徑與平均定位誤差分析
在邊長均為100 m的山區地形環境隨機投放200個節點,且實驗采用的錨節點比例均設置為0.25,觀察當通信半徑變化時,4種算法的平均定位誤差變化趨勢,其中,通信半徑分別為40,45,50,55,60,65,70,實驗結果為各類算法運行100次的均值,并繪制變化趨勢圖,如圖5所示。
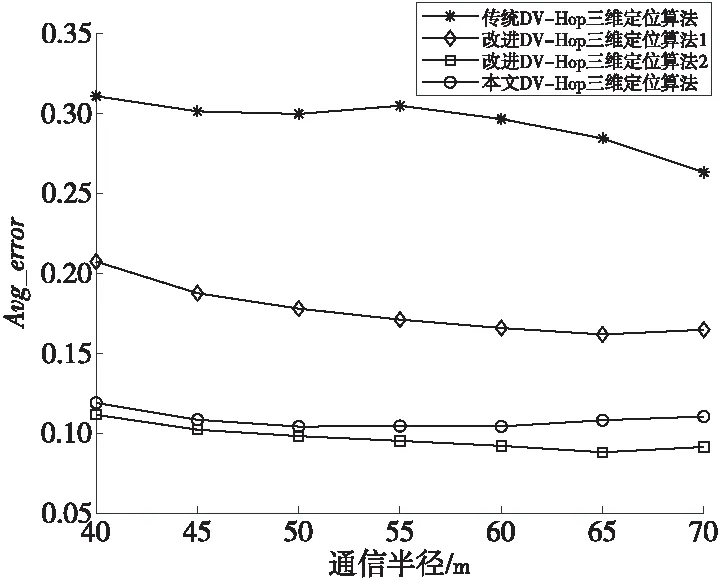
Figure 5 Trend of communication radius and average positioning error圖5 通信半徑與平均定位誤差的關系變化趨勢圖
從圖5中可以看出,傳統算法與改進算法1的平均定位誤差均隨著通信半徑的增加而降低,改進算法2與本文算法的平均定位誤差雖隨通信半徑變化不大,但均處于較高精度水平。整個實驗過程中,傳統算法、改進算法1和改進算法2的平均定位誤差分別為0.294 2,0.176 5,0.096 9,本文算法的平均定位誤差為0.108 3。具體變化情況如表2所示。
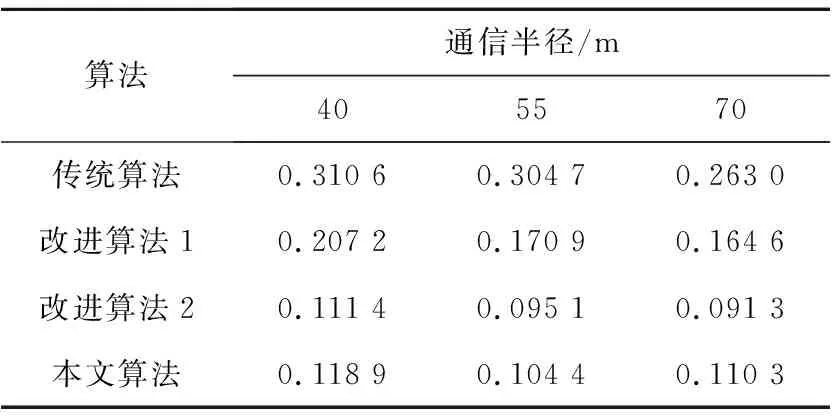
Table 2 Average positioning error under different transmission radius
從表2中可以得出,在通信半徑為40 m時,本文算法相對傳統算法、改進算法1和改進算法2的平均定位誤差分別降低了0.191 7,0.088 3,-0.007 5;在通信半徑為55 m時,本文算法相對傳統算法、改進算法1和改進算法2的平均定位誤差分別降低了0.200 3,0.066 5,-0.009 3;在通信半徑為70 m時,本文算法相對傳統算法、改進算法1和改進算法2的平均定位誤差分別降低了0.152 7,0.054 3,-0.01 9,其中本文算法與改進算法2在通信半徑為65 m時誤差相差最大僅為0.02,故從本文算法與改進算法2在整個實驗中的平均定位誤差均值與其之間的最大誤差差值來看,這種差值仍是可接受的良性水平。
4.2.3 節點總數與平均定位誤差分析
在邊長均為100 m的山區地形環境內,設置錨節點比例恒定為0.4,參與實驗節點通信半徑均設置成50 m,觀察節點總數變化,對4種算法平均定位定位誤差的影響,其中,節點總數分別為100,150,200,250,300,350,400,450,500。實驗結果為各類算法運行100次的均值,并繪制變化趨勢圖,如圖6所示。
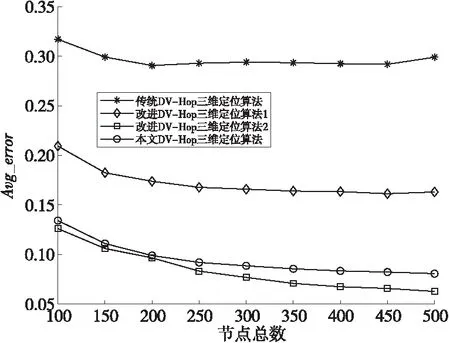
Figure 6 Trend of total number of nodes and average average positioning error圖6 節點總數與平均定位誤差的關系變化趨勢圖
從圖6中可以看出,在節點總數大于250時,改進算法2與本文算法定位精度差距變大。在整個實驗過程中,傳統算法、改進算法1和改進算法2的平均定位誤差分別為0.296 7,0.172 4,0.084 0,本文算法的平均定位誤差為0.095 2。具體變化情況如表3所示。
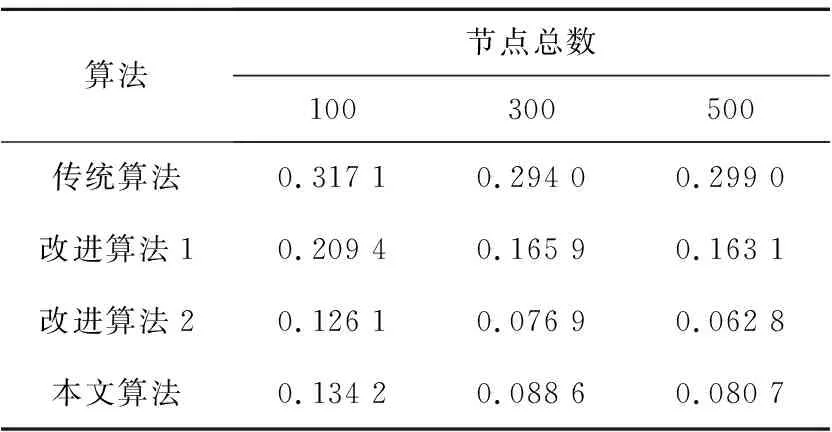
Table 3 Average positioning errors under different total number of nodes
從表3中可以得出,在節點總數為100時,本文算法相對傳統算法、改進算法1和改進算法2的平均定位誤差分別降低了0.182 9,0.075 2,-0.008 1;在節點總數為300時,本文算法相對傳統算法、改進算法1和改進算法2的平均定位誤差分別降低了0.205 4,0.077 3,-0.011 7;在節點總數為500時,本文算法相對傳統算法、改進算法1和改進算法2的平均定位誤差分別降低了0.218 3,0.082 4,-0.017 9,其中改進算法2與本文算法在整個實驗過程中的平均定位誤差差值為0.002 4和0.017 9,節點總數為200時平均定位誤差差值最小,節點總數為500時平均定位誤差差值最大。不論是平均定位誤差還是最大定位誤差差值,本文算法在不進行大量計算的情況下與使用仿生算法的改進算法2之間的誤差差值都是比較小的。
4.3 算法計算復雜度與計算時間分析
算法的計算復雜度與該區域未知節點數相關,令頻度函數為T(η)=(1-δ)η,其中,η為節點總數,δ為錨節點比例,令T(η)的各未知項均為υ,可得T(υ)=υ2,故可知傳統算法與改進算法1及本文算法的計算復雜度均為O(υ2)。改進算法2的頻度函數為T(η)=(1-δ)η·MAXG·NP,其中,MAXG為最大迭代次數,NP為種群數量,令T(η)的各未知項均為υ,可得T(υ)=υ4,因此改進算法2的計算復雜度為O(υ4),遠高于本文算法的計算復雜度。
在一個1.8 GHz Intel Core i7 CPU和8 GB RAM的系統上測試各算法的運行時間,其中錨節點比例為0.3,通信半徑為50 m,改進算法2的MAXG為100,NP為100,時間結果取算法運行100次的均值,如表4所示。

Table 4 Comparison of algorithm average running time under different conditions
不論從計算復雜度還是計算時間來看,改進算法2的計算代價比本文算法都要高,而本文算法與改進算法2之間的最大定位誤差差值卻不到0.02,本文算法在不使用大量迭代運算的前提下,對精度的提升是十分明顯的,也是具有實際應用意義的。
5 結束語
本文指出了傳統DV-Hop三維定位算法在跳數計算、平均跳距計算和最小二乘法的不足3個方面的缺陷,并有針對性地提出了改進方法:采用二通信半徑使得跳數計數更為準確;采用平方代價函數的思想使跳距誤差更小,并針對未知節點與多個錨節點相鄰的情況,提出加權跳距的方案;使用無約束優化并對誤差加權,使得加權誤差最小化。最后通過實驗表明,本文算法在不進行大量計算的前提下能夠大大提升定位精度,具有較好的應用前景。
